




Milvusによる検索の拡張:大量のデータセットを簡単に扱う
NumPyやFAISSを使えばいいのに、なぜわざわざMilvusのようなベクトルデータベースを使うのですか?"とよく聞かれる。理由はたくさんあります:スケーラビリティ、管理のしやすさ、データの永続性、そして最も重要なものの1つです:スケールである。数百万から数十億のvectorを扱う場合、そのような量を扱うために構築されたソリューションが必要です。
このブログポストでは、Milvusを使用した4,000万ベクターのユースケースの例を見ていきます。また、メタデータフィルタリングのような機能が、検索結果を大幅に向上させることも実証します。これは、非目的別ベクターデータベースにしばしば欠けている重要な機能であり、大きな欠点となっています。
Milvus: 規模に合わせて構築されたベクターデータベース
Milvusは人気のあるオープンソースのベクトルデータベースで、高いパフォーマンスとスケーラブルなベクトル類似検索でAIアプリケーションを強力にサポートします。
スケーラブルなベクトル検索を可能にする主な機能には以下のようなものがある:
- 分散アーキテクチャ:** Milvusは分散アーキテクチャを採用しており、水平方向にシームレスに拡張し、データとワークロードを複数のノードに分散することができます。この機能により、高負荷時でも高い可用性と回復力が保証されます。
- 最適化されたインデックス作成:** MilvusはIVF_FLATやHNSWのような様々なインデックス作成技術をサポートしていますが、検索速度を高速化するためにGPUインデックスもサポートしています。また、ベクターDBのコストを削減する必要がある場合は、DiskANNもサポートしており、検索は少し遅くなりますが、大幅に安くなります。
- Milvusの際立った特徴の一つは、何十億ものベクトルを効率的に処理し、検索できることです。この能力は、高速かつ大量のベクトル類似性検索を必要とするアプリケーションにとって極めて重要である。
- 様々な計算オプション:** MilvusはGPUとCPUのパワーを活用することができ、最適なパフォーマンスを得るために最適なハードウェアにインテリジェントにタスクを割り当てることができます。この機能により、並列処理が可能になり、特に計算量の多い処理において大幅なスピードアップを実現します。
データセット数百万のウィキペディア記事埋め込み
我々は、Cohere Embedding Modelで変換されたウィキペディアのデータセットを使用しています。それはHugging Faceで自由に利用できます。
データセットのプレビュー](https://assets.zilliz.com/Preview_of_the_dataset_acf148b4ba.png)
図1:データセットのプレビュー
それぞれの例には、マークダウンと不要なセクション(参考文献など)を取り除くクリーニングを施した、ウィキペディアの完全な記事が1つ含まれている。
データセットには300以上の言語が含まれていますが、今回のユースケースでは英語に焦点を当てます。クールな点は、埋め込みがクロスリンガルであることです!つまり、複数の言語を横断して検索することができ、異なる言語であっても似たような意味を見つけるモデルの能力に頼ることができます。
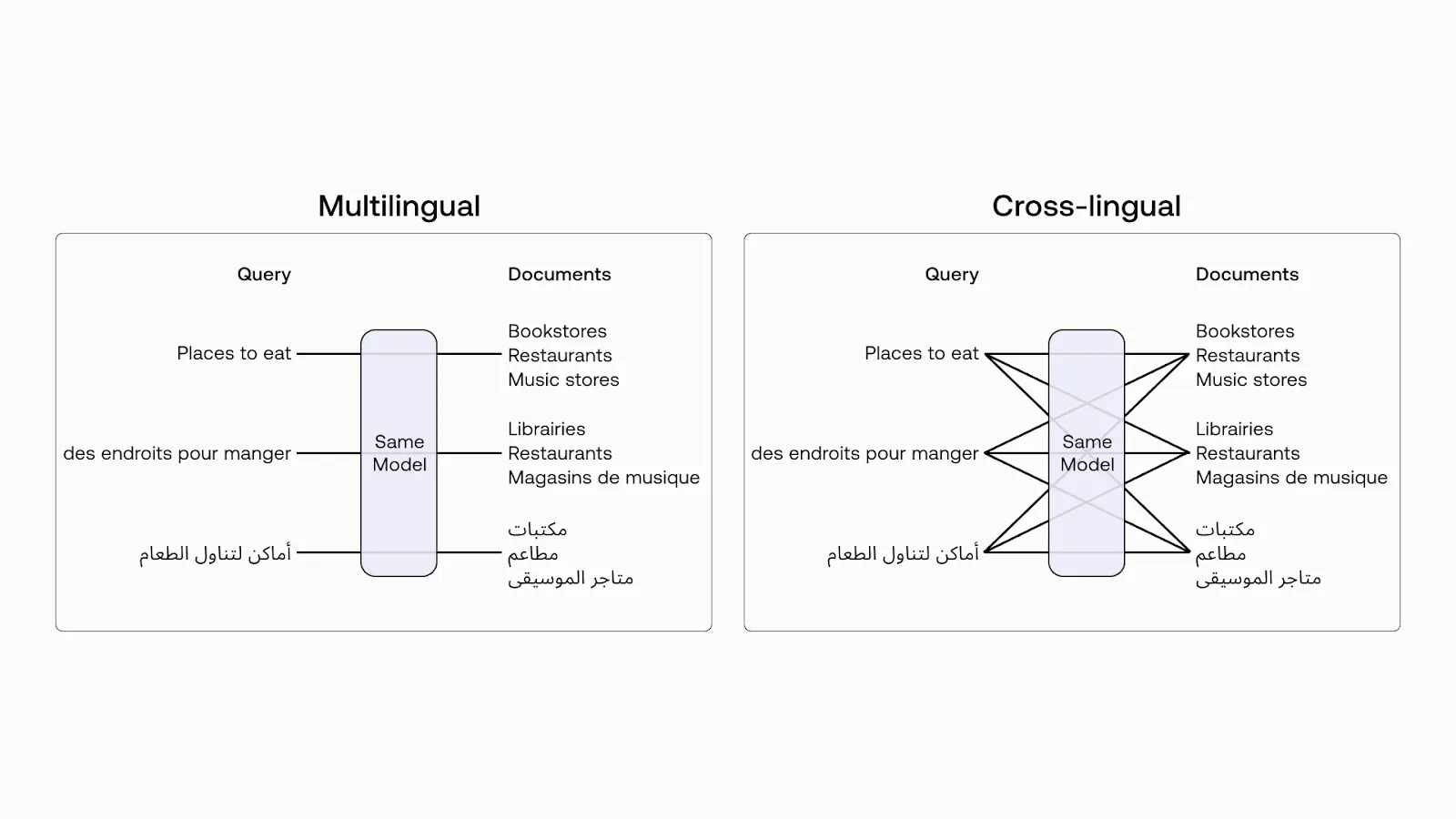 多言語 vs 異言語.png
多言語 vs 異言語.png
図2:多言語 vs 異言語 (画像ソース)
ミルバス入門
このセクションでは、Milvus SDKのインストールやZilliz Cloudのセットアップ、Milvusへの接続、コレクションの作成など、Milvusを使い始める方法を紹介します。
MilvusSDKのインストール
まず、pip install pymilvusを実行してMilvus SDKをインストールします。ここでは簡単のため、Zilliz Cloud(Milvusのフルマネージド版)上にMilvusをデプロイします。利用するデータの規模を考慮すると、Kubernetes上にMilvusをデプロイするか、Zilliz Cloudを利用することになります。
- 100万ベクトルを超えるような大規模なデータであれば、DockerまたはKubernetes上でよりパフォーマンスの高いMilvusサーバを構築することができます。この場合、URIはサーバのURI、例えば
http://localhost:19530を使用してください。 - MilvusのフルマネージドクラウドサービスであるZilliz Cloudを利用する場合は、Zilliz CloudのPublic Endpoint and API keyに対応する
uriとtokenを調整してください。
ステップバイステップガイド
1.Milvusへの接続: まず、Milvusインスタンスへの接続を確立します:
パイソン from pymilvus import MilvusClient
client = MilvusClient(uri=<ZILLIZ_CLOUD_URI>, token=<ZILLIZ_TOKEN>)
2.**スキーマの作成:** Milvus Collection の作成に使用するスキーマを定義します。
パイソン
# コレクション用のスキーマを定義する。
embedding_dim = 1024
スキーマ = [
{"name":"id", "dtype":"int64", "is_primary":True, "auto_id":true}、
{"name":"text_vector", "dtype":"float_vector", "dim": embedding_dim}、
{"name":"title"、"dtype":"varchar":"varchar", "max_length":5000},
{"name":"varchar", "max_length":5000},
]
3.コレクションを作成する: 次に、埋め込みデータを格納するコレクションを作成します。
パイソン
コレクションが存在しない場合は作成する。
コレクション名 = "cohere_embeddings"
if not client.has_collection(collection_name): client.create_collection(collection_name=collection_name, schema=schema)
4.**インデックスの作成**:ベクトル検索を効率的に行うには、対象となるベクトルフィールドにインデックスを作成する必要があります。ベクトルインデックス](https://milvus.io/docs/index-vector-fields.md)は、ベクトルを格納し検索するために設計された特殊なタイプのインデックスです。
```Python
# インデックスの定義と作成
index_params = {
"metric_type":"COSINE"、
"index_type":"HNSW"、
「params":{"M":8, "efConstruction":64},
}
client.create_index(collection_name=collection_name, field_name="text_vector", index_params=index_params)
# コレクションをロードする
client.load_collection(collection_name=collection_name)
5.**HuggingFaceのデータセットを cohere_embeddings コレクションに投入する。利用可能なリソースに応じて、特定の言語のみなどサブセットをダウンロードしたり、S3やGCPのようなバケットにアップロードしたり、Hugging Faceからストリーミングすることもできます。
データセットがストリーミング・モードであるとき、データセット全体をダウンロードすることなく、それを直接反復することができます。これは、データセットをダウンロードするのに十分なディスク容量がない場合や、使用する前にデータセットがダウンロードされるのを待ちたくない場合に便利です。
パイソン
コレクションにデータを挿入する
def insert_batch(client, collection_name, batch_data): client.insert(collection_name=collection_name, data=batch_data) batch_data.clear()
HuggingFace からデータを取得し、バッチを作成する。
def insert_data(client, collection_name): batch_size = 1000 # 必要に応じてバッチサイズを調整する batch_data = [] # 必要に応じてバッチサイズを調整する
docs = load_dataset(
"Cohere/wikipedia-2023-11-embed-multilingual-v3"、
"en", # 英語のみ
split="train"、
streaming=True, # データセットを繰り返し処理できるようにする
)
for doc in tqdm(docs, desc="Streaming and preparing data for Milvus"):
title = doc["title"][:4500] # タイトルは非常に長くなる可能性がある
text = doc["text"][:4500] # テキストは非常に長い場合がある
emb = doc["emb"] # 埋め込みベクトル
batch_data.append({"title": title, "text_vector": emb, "text": text})
if len(batch_data) >= batch_size:
insert_batch(client, コレクション名, batch_data)
if batch_data:
insert_batch(client, collection_name, batch_data)
## スカラーフィルタリング:スケールの大きな強力なツール
数百万、数十億のベクトルを扱う場合、フィルタリングは単なる便利な機能ではなく、必要不可欠なものになります。そして、Milvusが本当に力を発揮するのはここからです。
Milvusのフィルタリングへのアプローチがゲームチェンジャーである理由はここにあります:
1.**ビットセットの魔術**:Milvusはコンパクトなビットセットを使って、どのベクトルがフィルタリングの条件にマッチするかを表現します。これらのビットセットは、低レベルのCPU操作のおかげで、「ベクトルの類似性検索」と言うよりも速く操作できる。何十億ものデータポイントを瞬時にソートできるスーパーコンピューターを持つようなものです。
2.**検索スペースの削減他のいくつかのソリューション(例えば[pgvector](https://zilliz.com/blog/getting-started-pgvector-guide-developers-exploring-vector-databases))がポストフィルタリングしか提供しないのとは異なり、Milvusはベクトル類似性検索を実行する前にメタデータフィルタを適用します。これにより、処理に必要なベクトル数が劇的に削減されます。また、数十億のベクトルから、本当に重要な数千のベクトルだけを数ミリ秒で絞り込むことができます。
3.**スカラー・インデックス**(必要なとき):頻繁にフィルタリングを行うフィールドについては、Milvusはスカラーインデックスを作成することができます。これはMilvusにデータのカンニングペーパーを与えるようなものです。デフォルトでは常に存在するわけではありませんが、適切に設定された場合、これらのインデックスはフィルタリングのパフォーマンスを飛躍的に向上させます。
Milvusの優れた点は、これらの機能を単に提供するだけでなく、スケールに応じて機能させることです。4,000万ベクトルでも400億ベクトルでも。
### 厳密なフィルタリングによる検索
特定のタイトルのドキュメントを検索します。
パイソン
FILTER_TITLE = "英国アラブ商業銀行"
res = milvus_client.query(
コレクション名=コレクション名、
filter=f'title like "{FILTER_TITLE}"'、
output_fields=["タイトル", "テキスト"].
)
for elt in res:
pprint(elt)
これは British Arab Commercial Bank に関する文書を返す。
``SQL {'id':450933285225527270, 'text': 'The British Arab Commercial Bank PLC (BACB) is an international ' ホールセール銀行で、プルデンシャル規制機構(Prudential Regulation Authority)の認可を受けています。 'プルデンシャル規制局(PRA)によって認可され、''PRA と金融行動''庁によって規制されている。 PRAと金融行動監督機構(FCA)の規制下にある。設立は 1972 年。 1972年にUBAFリミテッドとして設立され、1996年に現在の名称を採用した。 2009年に公開有限会社として登録された。同行の顧客は 中東および''アフリカ''の発展途上市場で取引を行っている。 アフリカ''を取引先としている、 'title':英国アラブ商業銀行} {'id':450933285225527271, 'text':'BACBはロンドンに本店があり、アルジェリアのアルジェ、リビアのトリポリ、アフリカのアビジに3つの駐在員事務所があります。 アルジェリアのアルジェ、リビアのトリポリ、コートジボワールのアビジャンにある。 「ディボワールにある。欧州、アジア、アフリカに17 の姉妹銀行を持つ。 アフリカにある。リビア外資系銀行(87.80%)の3つの主要株主によって所有されている。 銀行(87.80%)、Banque Centrale Populaire(6.10%)、Banque ''Extérieure d'Alvoire(6.10%)である。 "アルジェリア外債(6.10%)"、 'title':英国アラブ商業銀行}
### 接頭辞/接尾辞/接尾辞フィルタリングによる検索
特定の単語を含む文書を検索します。
パイソン
res = milvus_client.query(
collection_name=コレクション名、
filter='text like "%Calectasia%"', # インフィックス
# filter='text like "Calect%"', #接尾辞
# filter='text like "%lectasia"', #接頭辞
output_fields=["title", "text"]、
limit=5、
)
for elt in res:
pprint(elt)
これは "Calectasia "という単語を含む文書を返す。
``SQL {'id':450933285225527360, 'text': 'カレクタシアはダシゴケ科の約15種の顕花植物の属であり、南西部の固有種である。 'オーストラリア南西部の固有種である。 'オーストラリアの固有種である。この属の植物は小さな直立した低木で、' '葉鞘で覆われた枝分かれした茎を持つ。花は星形で、' '薄紫色から紫色で、短い枝の先に一重につく。 '枝先に一重につく、 'title':Calectasia' }. {'id':450933285225527361, 'text': 'カレクタシア属の植物は小型で、しばしば根茎を形成する' '低木で、茎は直立し、枝分かれし、無柄の葉が' '茎に沿って交互に並び、長く、幅はほぼ同じで、基部は茎に密着し、先端は' 茎に密着し、先端は尖っている。花は '枝先に単生し、両性花である。 枚の萼片と3枚の花弁は互いに似ており、基部で結合して' '基部は短い筒状だが広がり、星のような模様を形成する。 金属光沢のある星のような模様を形成する。鮮やかな黄色かオレンジの6本の雄しべは '花の中心で筒を形成し、細い雄しべが筒の中心から''伸びる。 '筒の中心を越えて伸びる、 'title':Calectasia'}.
### "Not In "を使ったフィルタリング検索
特定のタイトルを検索対象から除外します。
SQL
res = milvus_client.query(
コレクション名=コレクション名、
filter='title not in ["British Arab Commercial Bank", "Calectasia"]'、
output_fields=["title", "text"]、
limit=10、
)
for elt in res:
pprint(elt)
これは、タイトルが "British Arab Commercial Bank "でも "Calectasia "でもない文書を返す。
``SQL {'id':450933285225527281, 'text': 'コモンウェルス・スカイレンジャーは、最初はリアウィン・スカイレンジャーとして生産された。 'リアウィン・エアクラフトの最後のデザインであった。 '新しいオーナーに買収され、コモンウェルス・エアクラフトと改名される前のリアウィン・エアクラフトの最後の設計であった。 それは' 'サイド・バイ・サイド、2人乗り、高翼のテイルドラッガーであった、 'title':コモンウェルス・スカイレンジャー} {'id':450933285225527282, 'text': 'リアウィン社は小型の' 'スポーツスターやクラウドスターのような小型ラジアルエンジンを搭載した航空機を専門としていた。 'ルブロンド・エンジンズの資産を買い取り、1937年に小型ラジアル・エンジンを' 1937年には社内で製造していた。しかし1940年までには、リアウィンが小型ラジアルエンジンを搭載したデザインを必要とすることは明らかであった。 競争力を維持するためには、小型の水平対向エンジンを搭載したデザインが必要であることは明らかであった。 競争力を維持するために。スポーツパイロットと空飛ぶビジネスマンのために意図された、' 1940年4月9日に初飛行した。当初は' レンジャー」と名付けられたが、レンジャー・エンジン社(同社は' レンジャー」と名付けられたいくつかのエンジンも販売していた)が抗議し、リアウィンは設計を「スカイレンジャー」と改名した。その' '全体的な設計と製造方法により、Rearwinは' スカイレンジャーの注文を受け、10週間以内に納品することができた、 'title':コモンウェルス・スカイレンジャー}
## Cohere 🤝 Milvus: ベクトル類似性検索をより簡単かつ効率的にする強力な組み合わせ
Cohereの埋め込みを使って類似検索を行ってみよう。クエリ `Who founded Wikipedia` を埋め込み、Milvusコレクションを検索する。これはWikipediaの埋め込みをエンコードするのに使われたのと同じ埋め込みモデルです。
PyMilvusモデルを使ってMilvusとCohereを統合します。PyMilvusモデルは `pip install "pymilvus[model]"` . ;
パイソン
from pymilvus.model.dense import CohereEmbeddingFunction
cohere_ef = CohereEmbeddingFunction(
model_name="embed-multilingual-v3.0"、
input_type="search_query"、
embedding_types=["float"] )
)
query = '誰がウィキペディアを創設したか'
embedded_query = cohere_ef.encode_queries([query])
response = embedded_query[0]
print(response[:10])
これはウィキペディアの創設者に関する最も関連性の高いウィキペディアの記事を返します。
Python res = milvus_client.search(data=response, collection_name=collection_name, output_fields=["text"], limit=3)
for elt in res: pprint(elt)
結果は以下のようになる:
パイソン
[{'distance':0.7344469428062439,
'entity':{'text': 'Larry SangerとJimmy Walesは'
'ウィキペディアを立ち上げた人物である。ウェールズは、'
'プロジェクトの目標を定義したとされている。サンガーはウィキを使う戦略を作った。
「ウェールズの目標を達成するために。2001年1月10日、ラリー・サンガー"
'はNupediaメーリングリストでウィキを作ることを提案した。
'ヌペディアの "フィーダー "プロジェクトとしてウィキを作ることを提案した。ウィキペディアは
2001年1月15日。それは'
'英語版としてwww.wikipedia.com、'
'サンガーによってヌペディアのメーリングリストで発表された。'
ウィキペディアの「中立的な視点」という方針は、'
'その初期の数ヶ月で実施され、'
'ヌペディアの以前の "nonbiased "ポリシーに似ていた。それ以外は
「ウィキペディアはヌペディアから独立して運営されていた。
ヌペディアから独立して運営されていた、}
'id':450933285241797095},
{'distance':0.7239157557487488,
'entity':{'text': 'ウィキペディアはもともと、'
ジミー・ウェールズによって設立されたフリーオンライン百科事典である'
'ウェールズを補完するものとして考案されました。
'投稿者によって書かれ、入念な査読''プロセスによって評価される。
'プロセスである。ヌペディアのコンテンツ執筆は''非常に時間がかかることが判明した。
非常に時間がかかり、最初の一年間に完成した記事はわずか12本であった。
'最初の一年間に完成した記事はわずか12本であった。
編集者のメーリングリストがあり、専任の編集長がいたにもかかわらず。
ウェールズによって採用されたラリー・サンガーがいたにもかかわらず。ウィキのコンセプトを知った
'コンセプトを知ったウェールズとサンガーは、''
'共同ウェブサイトを作ってみることにした。
Nupediaで使用するために、''迅速に作成された下書き記事を磨くことができる''。
'ヌペディアで使えるようにするためである、}
'id':450933285225827849},
{'distance':0.7191773653030396,
'entity':{'text':"財団の設立を正式に発表したのは、"
ウィキペディアの共同創設者であるジミー・ウェールズによって正式に発表された。
ウィキペディアの共同創設者であるジミー・ウェールズによって公式に発表された、}
'id':450933285242058780}]
検索クエリのレイテンシを中心に、クラスタのパフォーマンスメトリクスを確認してみましょう。Zilliz Cloud APIを使用して、平均レイテンシと99パーセンタイル(P99)レイテンシの値を取得します。
まず、平均レイテンシを確認します:
シェル
curl --request POST --url https://api.cloud.zilliz.com/v2/clusters/<cluster_id>/metrics/クエリー [...] "metricQueries":[ { "name":"req_search_latency"、 "stat":"AVG" } }'
[{"name":"REQ_SEARCH_LATENCY","stat":"AVG","unit":"millisecond","values":[{"timestamp":"2024-08-26T11:09:53Z","value":"2.0541596873255163"}]}]
このクエリは、**2.05ミリ秒の平均待ち時間を返します。
次に、**P99**レイテンシーをチェックしてみよう:
シェル
> curl --request POST
--url https://api.cloud.zilliz.com/v2/clusters/<cluster_id>/metrics/クエリー
[...]
"metricQueries":[
{
"name":"req_search_latency"、
"stat":"P99"
}
}'
[{"name":"REQ_SEARCH_LATENCY","stat":"P99","unit":"millisecond","values":[{"timestamp":"2024-08-26T11:09:53Z","value":"4.949999999999999"}]}]
P99のレイテンシは4.95ミリ秒と報告されている。
平均クエリ待ち時間は2ミリ秒強で、99%のクエリが5ミリ秒未満で完了しています。この結果は、Milvusクラスタが大規模な検索処理においても効率的であることを示しています。
Milvusで基本的なRAGシステムを構築する
検索拡張生成(RAG)はChatGPTのような大規模言語モデル(LLM)における幻覚を軽減するための高度なAI技術です。
この例では、Milvusの結果を使って簡単なRAGシステムを作ることができます。これにより、LLMはMilvusに格納された情報にアクセスし、利用することができます。
パイソン context = "\n".join( [line_with_distance[0]forline_with_distance in retrieved_lines_with_distances](line_with_distance in retrieved_lines_with_distances) )
question = "誰がウィキペディアを作りましたか?"
system_prompt = "" 人間:あなたはAIアシスタントです。あなたは提供された文脈の一節から質問の答えを見つけることができます。 """
USER_PROMPT = f""
パイソン
from openai import OpenAI
クライアント = OpenAI(
base_url = 'http://localhost:11434/v1'、
api_key='ollama', # 必須ですが、未使用です。
)
response = client.chat.completions.create(
model="llama3.1"、
messages=[
{"role":"system", "content":system_prompt}、
{"role":"user", "content":USER_PROMPT}、
],
)
print(response.choices[0].message.content)
パイソン 提供された文脈によると、ウィキペディアを始めたのはラリー・サンガーとジミー・ウェールズだ。具体的には、ジミー・ウェールズがプロジェクトの目標を定義し、ラリー・サンガーがその目標を達成するためにウィキを使う戦略を作った。
## 基本を超えて:拡張性を高めるMilvusの高度な機能
Milvusは膨大なデータセットを扱うためにさらに高度な機能を提供します:
- データパーティショニング:**複数のユーザやテナントからのデータを含むコレクションに対して、Milvusはデータを論理的に分離するためのパーティションキーと名前を提供します。この機能により、ユーザIDや組織名による効率的なメタデータのフィルタリングが可能になります。
- 範囲検索**:クエリベクトルから指定された距離範囲内のベクトルを効率的に検索し、高次元空間においてより正確で柔軟な類似検索を可能にします。
- ハイブリッド検索](https://zilliz.com/blog/a-review-of-hybrid-search-in-milvus):** 一つのクエリで複数のベクトル列を検索することができます。例えば、テキストベクトルと画像ベクトルを組み合わせてマルチモダリティデータを検索したり、密なベクトルと疎なベクトルを組み合わせてセマンティック検索や全文検索を行うことができます。この機能は、多用途で柔軟な検索機能を提供します。
詳細は[Milvus Documentation](https://milvus.io/docs)を参照。
## 結論
Milvusは、何十億ものベクトルを扱うための堅牢でスケーラブルなソリューションを提供します。フィルタリングや分散アーキテクチャなどの強力な機能により、要求の厳しいAIアプリケーションに最適な選択肢となっている。
我々のパフォーマンステストは、Milvusの素晴らしい能力を示している:
- 平均クエリーレイテンシー**2.05ミリ秒**。
- 99パーセンタイル(P99)レイテンシ:**4.95ミリ秒**です。
これらの結果は、Milvusが数百万のベクトルを扱う場合でも、一貫して5ミリ秒以下の検索時間を提供できることを示しています。膨大なデータセットを処理し、光速の検索結果を提供するアプリケーションを構築したいのであれば、Milvusは間違いなく検討する価値があります。
このブログ記事が気に入ったら、ぜひ[GitHub](https://github.com/milvus-io/milvus)で私たちを紹介してください。また、私たちの[Discord](https://discord.gg/FG6hMJStWu)に参加して、あなたの経験をMilvusコミュニティと共有することも歓迎します。
## その他のリソース
- Retrieval Augmented Generation (RAG)とは](https://zilliz.com/learn/Retrieval-Augmented-Generation)
- Milvus、vLLM、Meta's Llama 3.1を使ったRAGの構築](https://zilliz.com/blog/building-rag-milvus-vllm-llama-3-1)
- ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
- あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models) ;
- あなたのデータに適した埋め込みモデルの選択](https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data)
- GenAIエコシステムの展望:LLMとベクトルデータベースを超えて](https://zilliz.com/blog/landscape-of-gen-ai-ecosystem-beyond-llms-and-vector-databases)

読み続けて

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.