




Zilliz CloudでMilvus 2.6の機能を探索するための開発者ガイド
Milvus は、最先端のベクトルANN検索機能を備え、スケールを前提に構築された高性能なオープンソースのベクトルデータベースとして始まりました。開発者コミュニティが成長するにつれて、機能リクエストは全文検索、ブースティング、半構造化データ型(JSON、struct など)のサポートへと広がっていきました。これらのリクエストは、AIアプリケーション開発の加速に役立つ、より高度な機能(類似検索以外)へのニーズによって推進される、データベース機能の収束というより大きな潮流を反映しています。
この収束は、機能リクエストに現れるだけではありません — 今やデータベースそのものにも現れています。Milvus 2.6 では、開発者が以前はデータベースの外部で組み合わせる必要があった多くの機能、たとえば減衰ベースのランキング、フィールドレベルのブースティング、構造化データと非構造化データを横断するハイブリッドフィルタリングなどが、今では第一級のプリミティブになっています。
言い換えれば、Milvus 2.6 は「ベクトル検索 + グルーコード」から、より高度な検索エンジンへの移行を示しており、現在は Zilliz CloudでGenerally Available (GA) になっています(Milvus のマネージドサービス)。
この記事では、Milvus v2.6 のクールな機能のいくつか、それらをいつ使うべきか、そしてどのように使うかを紹介します。それでは始めましょう!
Embedding Function(Data In, Data Out とも呼ばれます)
データベースがあなたに代わって埋め込みの生成を処理できるかどうか、気になったことはありませんか?Embedding Functions(「Data in, data out」とも呼ばれます)を使うと、Milvus は OpenAI、VoyageAI、Cohere などの外部サードパーティ埋め込みサービスを呼び出して、生テキストをベクトルに変換できます。
Embedding Functions は Milvus v2.6.0 で初めてリリースされ、私は kafka-milvus-no-code-pipelines demo でそれを紹介しました。現在、Milvus ベクトルデータベースのフルマネージドサービスである Embedding Functions は Zilliz Cloud で利用可能です。
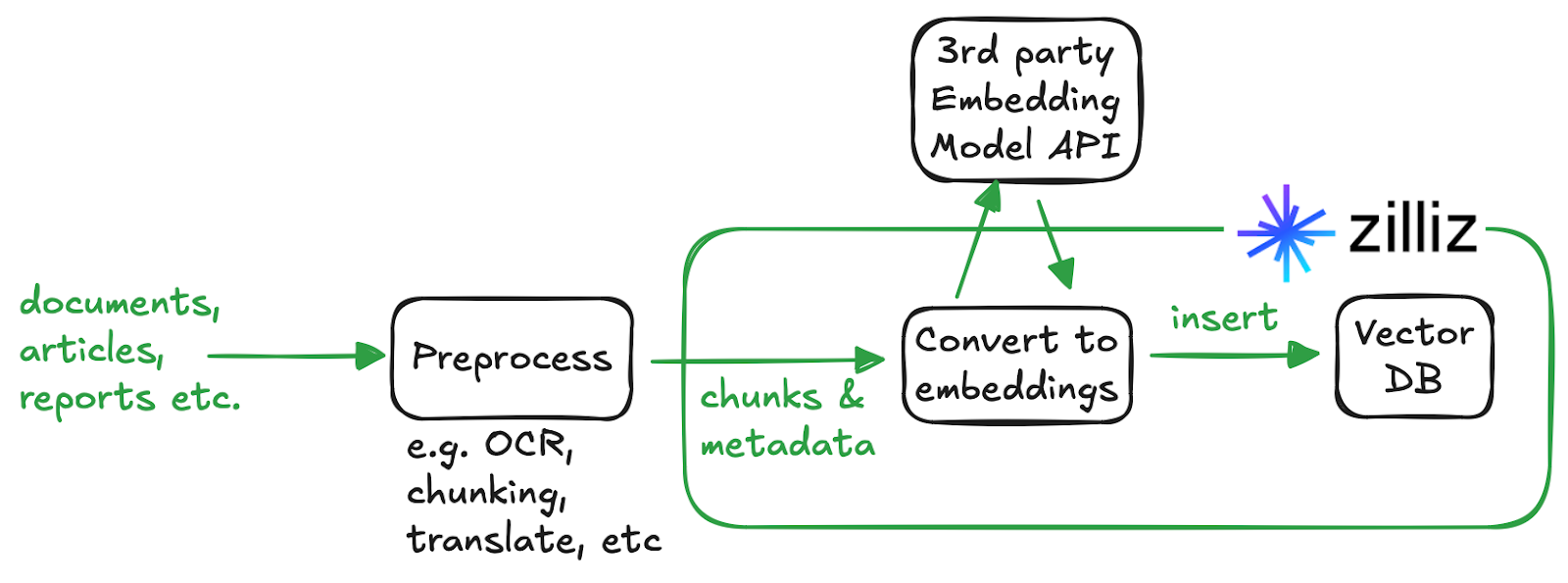
埋め込み関数はどのように動作しますか?
埋め込み関数が設定された状態で、「The quick brown fox jumps over the lazy dog」を Milvus に挿入するとします。Milvus はプロキシ層でそれをインターセプトし、プロバイダー固有の埋め込みパイプラインを通してルーティングし、モデルによって生成されたベクトルを保存します。検索時には同じ変換が逆方向に行われます。クエリテキストは、インデックスに到達する前にベクトルへ変換されます。
この機能は、埋め込みワークフローの管理責任をデータベースにオフロードしたいチームに特に有用です。データベースに取り込み時(サードパーティのモデルプロバイダー経由)に透過的に埋め込みを生成させることで、Zilliz Cloud は API 統合、バッチ処理、リトライ、レート制限、障害処理を引き受けます。
Zilliz Cloud で Embedding Functions を始めるには、次が必要です。
- 任意の埋め込みサービスプロバイダー向けに Model Provider Integration を設定する
- Embedding Function を定義したコレクションを作成する
- データを挿入する。
正しく設定されていれば、Zilliz Cloud コンソールのコレクションスキーマページで埋め込み関数を確認できるはずです。
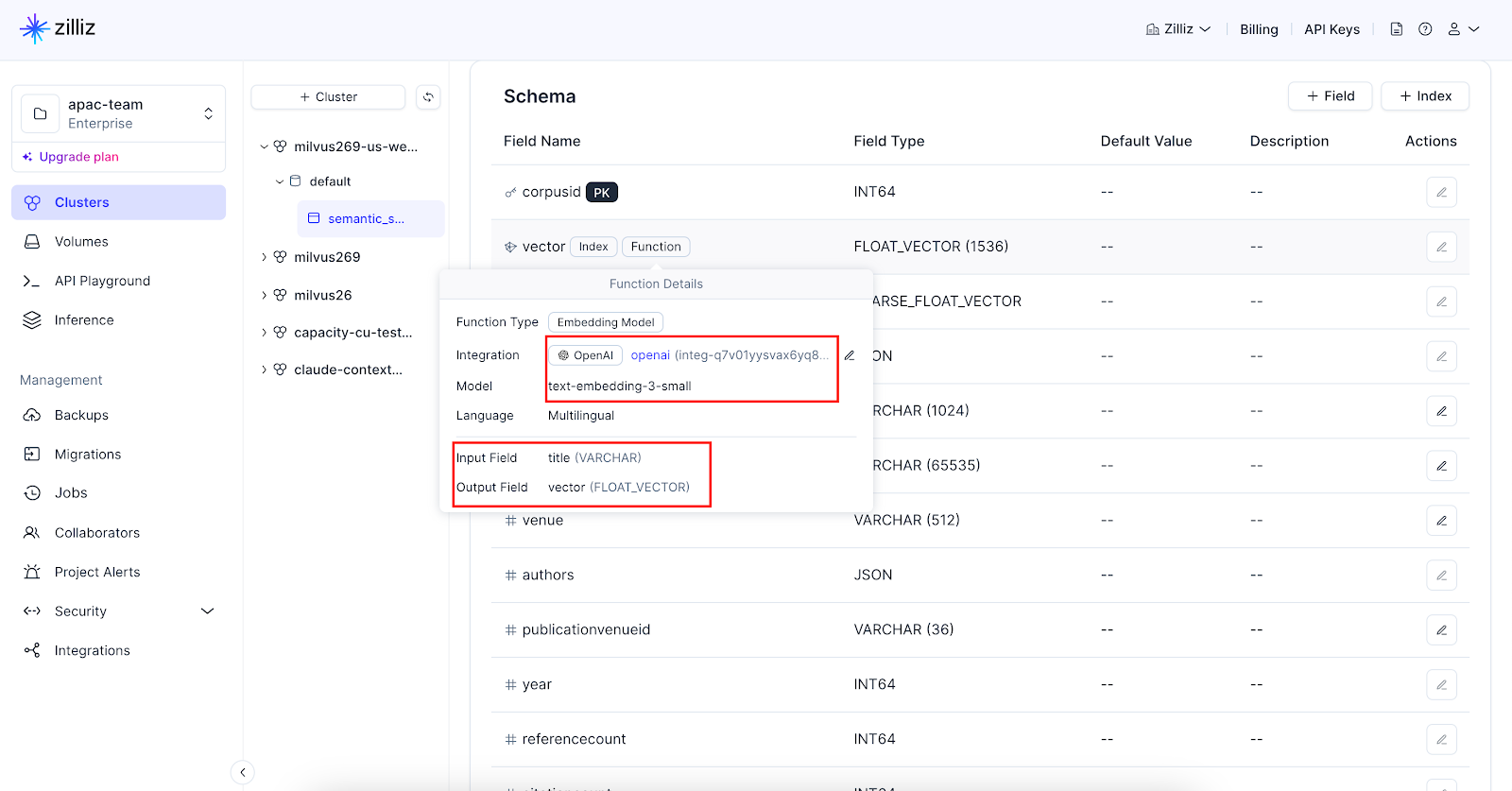
あとは生テキストを挿入するだけで、埋め込みが自動的に生成され、指定した密ベクトルフィールドに保存されます。埋め込み関数を定義しておけば、検索クエリであっても、もう埋め込みを生成する必要はありません。
直面する可能性のある問題としては、埋め込み関数を使用する際に Milvus が課すバッチサイズ制限があります。
2026-01-21 14:03:12,902 [ERROR][handler]: RPC error: [insert_rows], <MilvusException: (code=65535, message=numRows [1000] > function [openai]'s max batch [640])>, <Time:{'RPC start': '2026-01-21 14:03:12.722589', 'RPC error': '2026-01-21 14:03:12.902013'}>
ベストプラクティスとヒント
- バッチサイズの上限(エラーメッセージに表示)内に収めてください。これは、API 呼び出しごとのモデルプロバイダーのトークン上限に達するのを避けるための安全機構です。たとえば、OpenAI には API 呼び出しごとに最大 300,000 トークンという制限があります。
- 長いテキストや大規模ドキュメントのユースケースでは、挿入前にチャンク化する必要があります。たとえば、OpenAI では、すべての embedding モデルについて入力テキストごとに 8192 トークンの上限があります。
- VoyageAI や Cohere のようなプロバイダーはデフォルトで長いテキストを自動的に切り詰めますが、これに依存すると、ドキュメント末尾のコンテンツが気づかないうちに失われる可能性があります。
字句ハイライト
字句ハイライトは、一致を引き起こした正確な用語やフレーズを視覚的にマークすることで、結果がクエリに一致した理由をユーザーに示すのに役立ちます。これにより、検索結果の透明性、解釈可能性、ユーザーの信頼が向上します。
主なシナリオをいくつか示します。
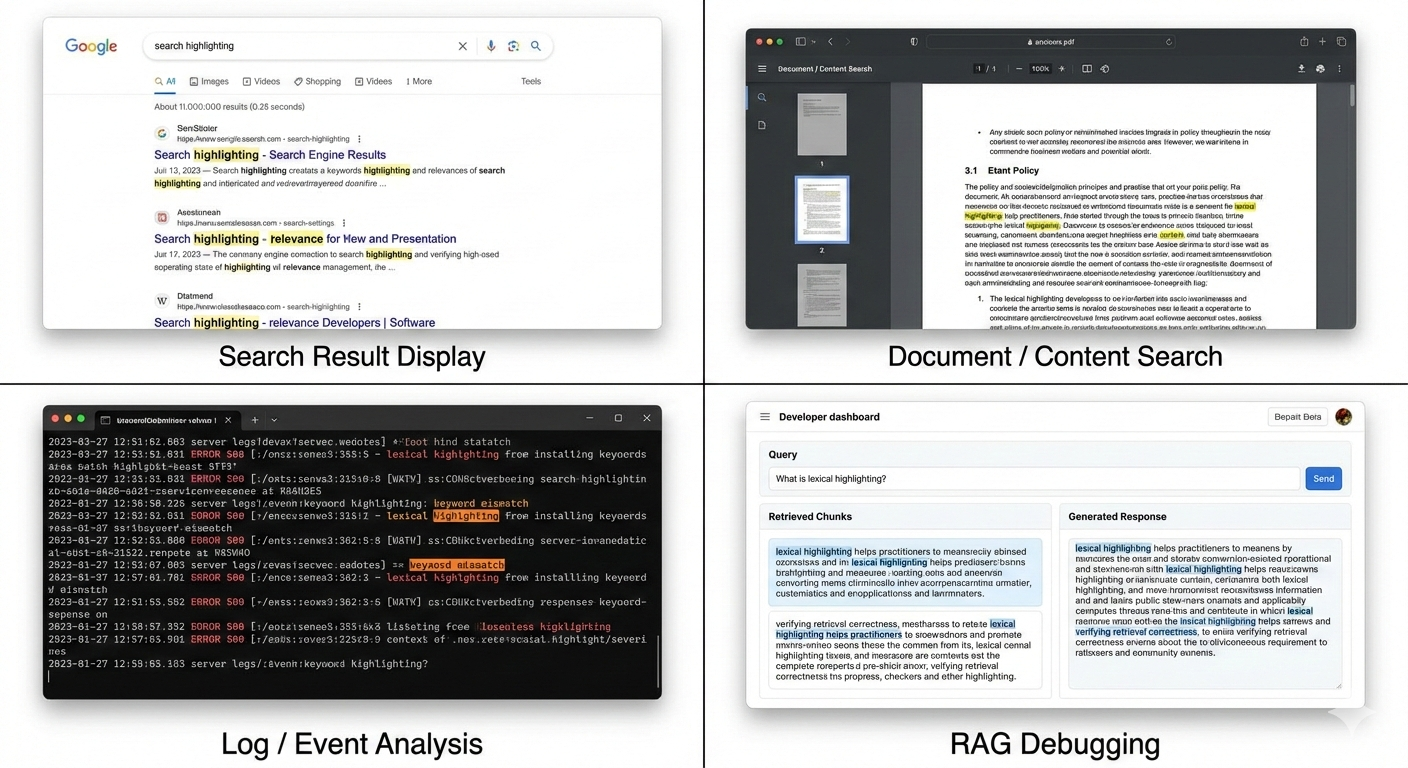
UI 上での検索結果表示。 検索インターフェースを構築する際、ハイライトにより、ユーザーは全文書を開かなくても結果の関連性を素早く理解できます。一致箇所を明示することで認知負荷を減らし、クリック率を向上させます。
ドキュメント / コンテンツ検索。 大規模ドキュメント(例:ナレッジベース、PDF、ポリシー)では、字句ハイライトにより、ユーザーは周辺コンテキスト内の一致したキーワードを即座に見つけられ、情報探索を高速化できます。
ログ / イベント分析。 運用ログやイベントデータでのハイライトにより、特にトラブルシューティングやインシデント対応時に、密で非構造化されたテキスト内の一致パターン、エラーコード、キーワードを見つけやすくなります。
RAG(Retrieval-Augmented Generation)デバッグ。 RAG パイプラインでは、字句ハイライトにより、取得されたチャンクのどの部分が元のクエリに一致したかを実務者が確認できます。これは次の用途に役立ちます。
- 取得の正確性を検証する
- 偽陽性や弱い一致を診断する
- 生成用に特定のコンテキストが選択された理由を理解する
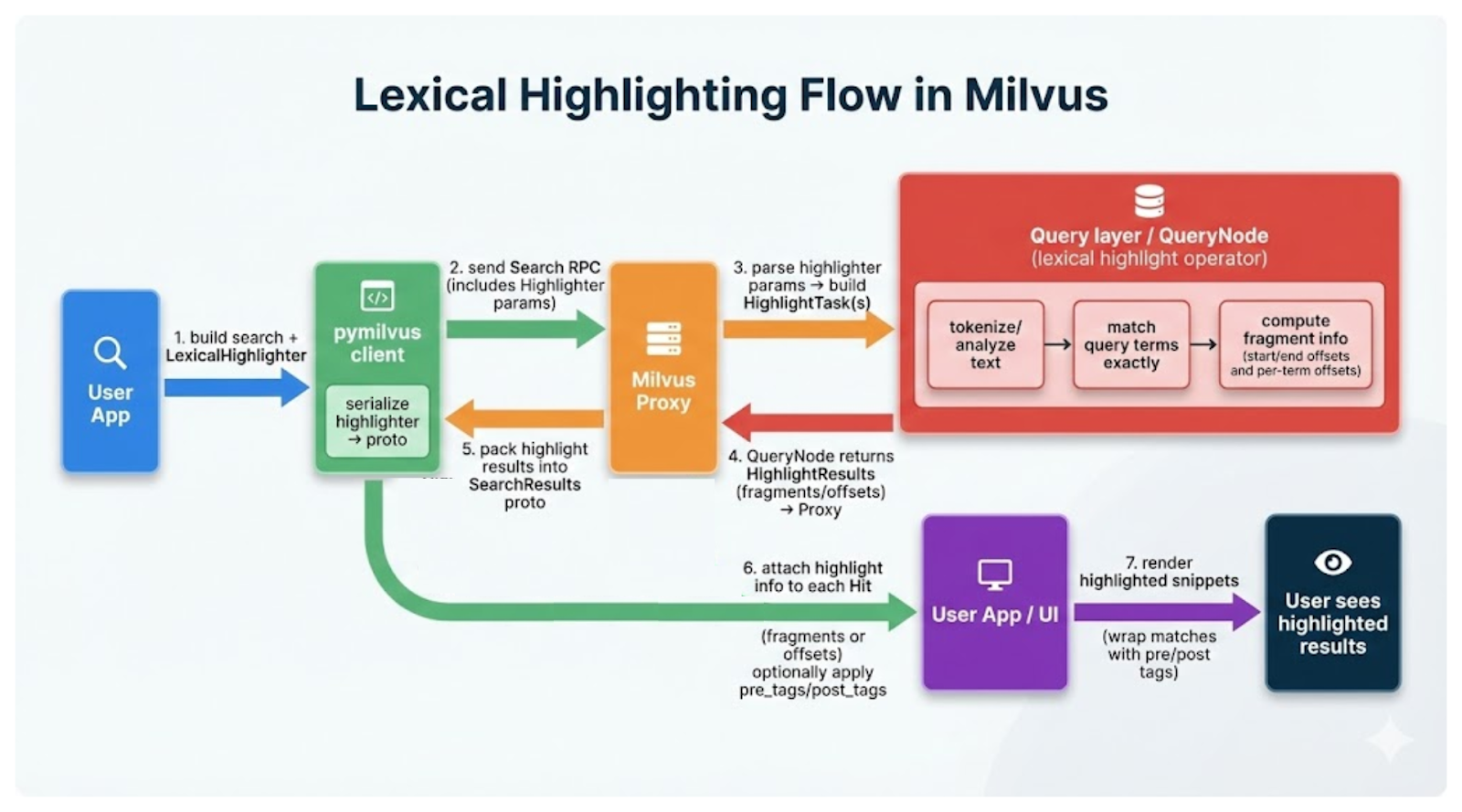
Zilliz Cloud でサーバーサイドの字句ハイライトを実装するには、まず、(ハイライトするクエリテキストと、ハイライトされたテキストの見た目を示すための周辺タグを指定して)LexicalHighlighter をインスタンス化し、それを全文検索リクエストのパラメータとして指定します。
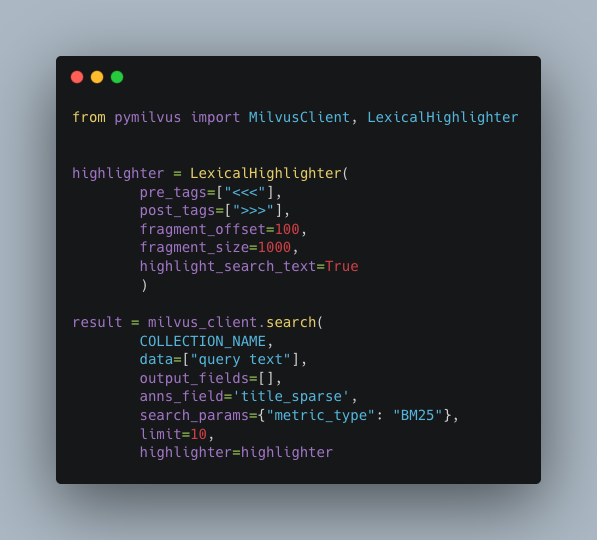
すると、Milvus が検索を実行し、完全一致を見つけるための字句ロジックを実行して、ハイライトすべき部分文字列に関する位置情報を返します。
ベストプラクティスとヒント
- LexicalHighlighter は BM25 全文検索でのみ機能します。dense vector search では機能しません。
- 一致した用語を HTML タグ(例:カスタム CSS クラス、太字、斜体など)で囲み、Web ページ上で直接レンダリングするために、
pre_tagsとpost_tagsを定義できます。
N-gram インデックス
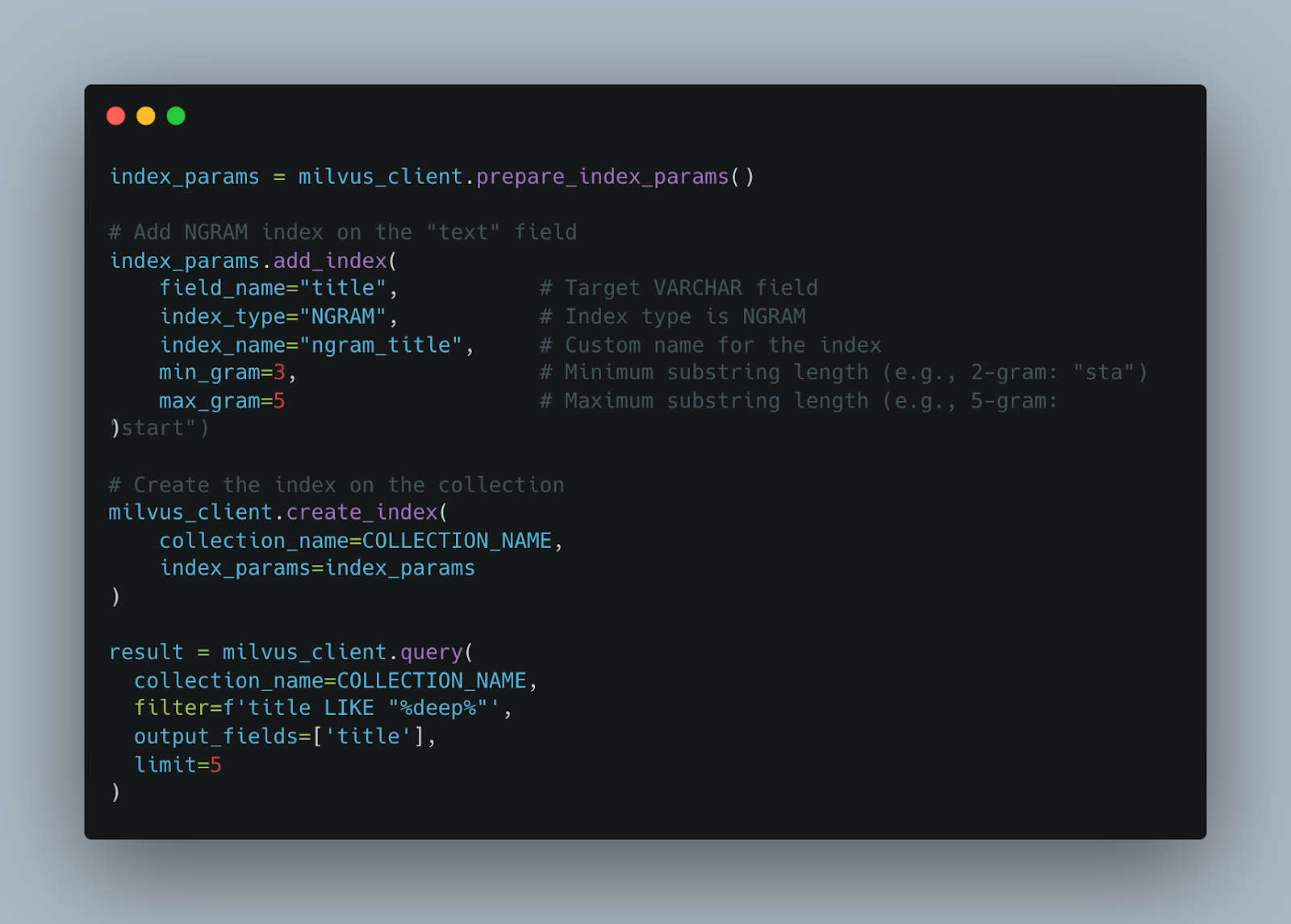
N-gram インデックスは、文字列をより小さく重複する文字列のシーケンス(例:"coffee" を 3-gram に分解 -> "cof", "off", "ffe", "fee")に分解し、部分一致、柔軟な一致、ワイルドカード形式の一致を可能にする強力な検索エンジンのインデックス技術です。
n-gram インデックスが役立つシナリオをいくつか示します。
- 部分文字列検索(例:
LIKE %deep%)のパフォーマンス向上 - Search-as-you-type / オートコンプリート
- あいまい検索
- ドメイン名および識別子検索(例:
example.com,facebook.com)
どのように機能しますか?
指定された n-gram を含むドキュメントは、各 n-gram をその n-gram を含むドキュメントの識別子リストにマッピングするインデックス(多くの場合、転置インデックスと呼ばれます)を使用することで効率的に特定できます。このリストは、効率的な圧縮と効率的なクエリ実行の両方を可能にするため、ソートされた状態で保持されます。Milvus の場合、ngram index は Tantivy の上に構築されており、Tantivy はさらに delta encoding、bitpacking、skip lists などの圧縮技術を使用して転置リストを圧縮し、そのサイズを削減することで、インデックスを軽量化しています。
テキストフィールドをフルスキャンする代わりに、Milvus はまず述語(例:deep)を抽出し、設定された gram サイズに基づいてそれを n-gram に分解し、転置インデックスのルックアップを実行して結果を交差させ、すべての gram を含む候補を特定した後、元の LIKE パターンに対して完全一致を検証します。
Milvus では、生成される n-gram の最小長と最大長をそれぞれ表す min_gram と max_gram を指定できます。ngram index の作成方法と使用方法の詳細については、NGRAM Index documentを参照してください。
これは、Milvus の ngram index 機能を使用して実装されたオートコンプリートの短いデモです。
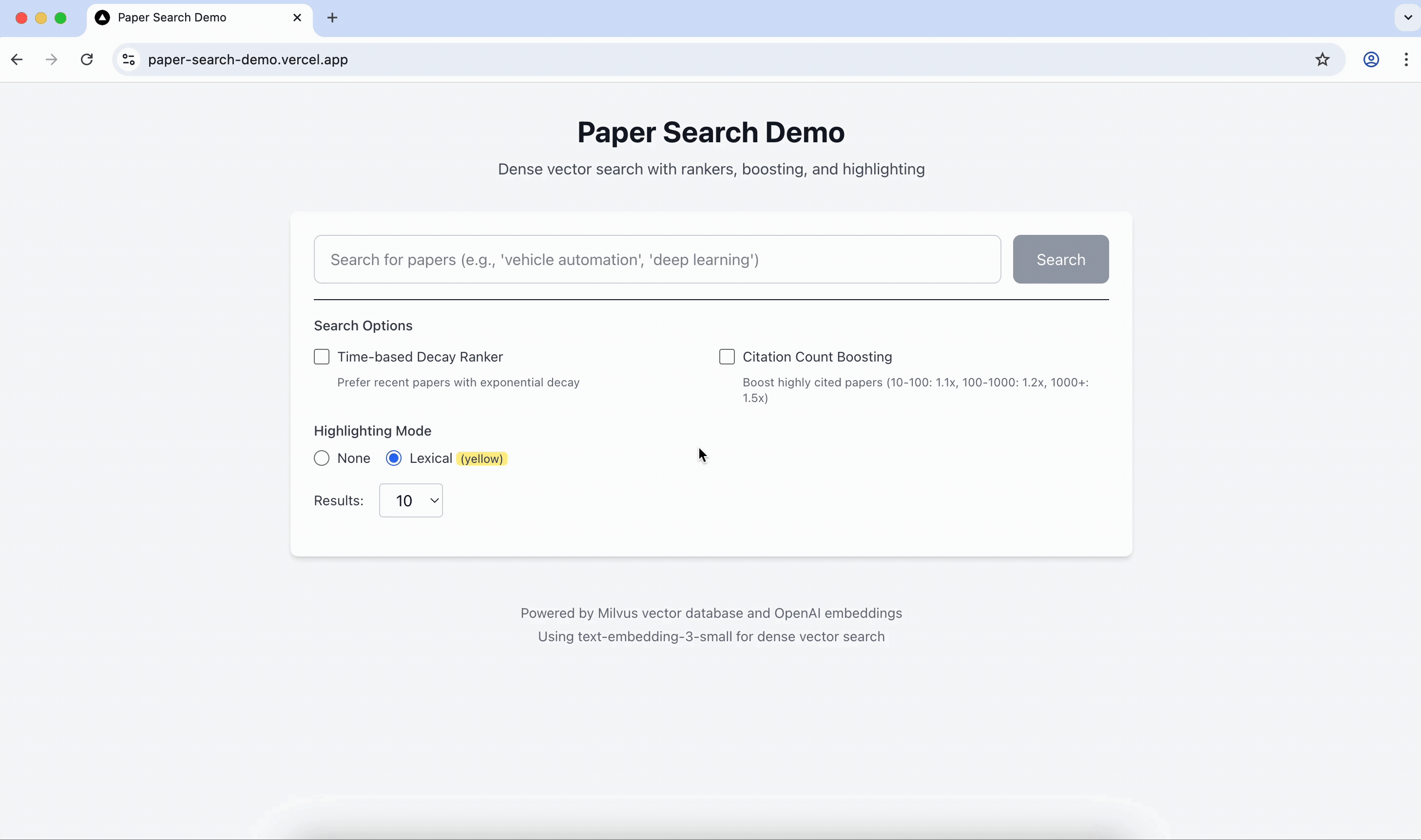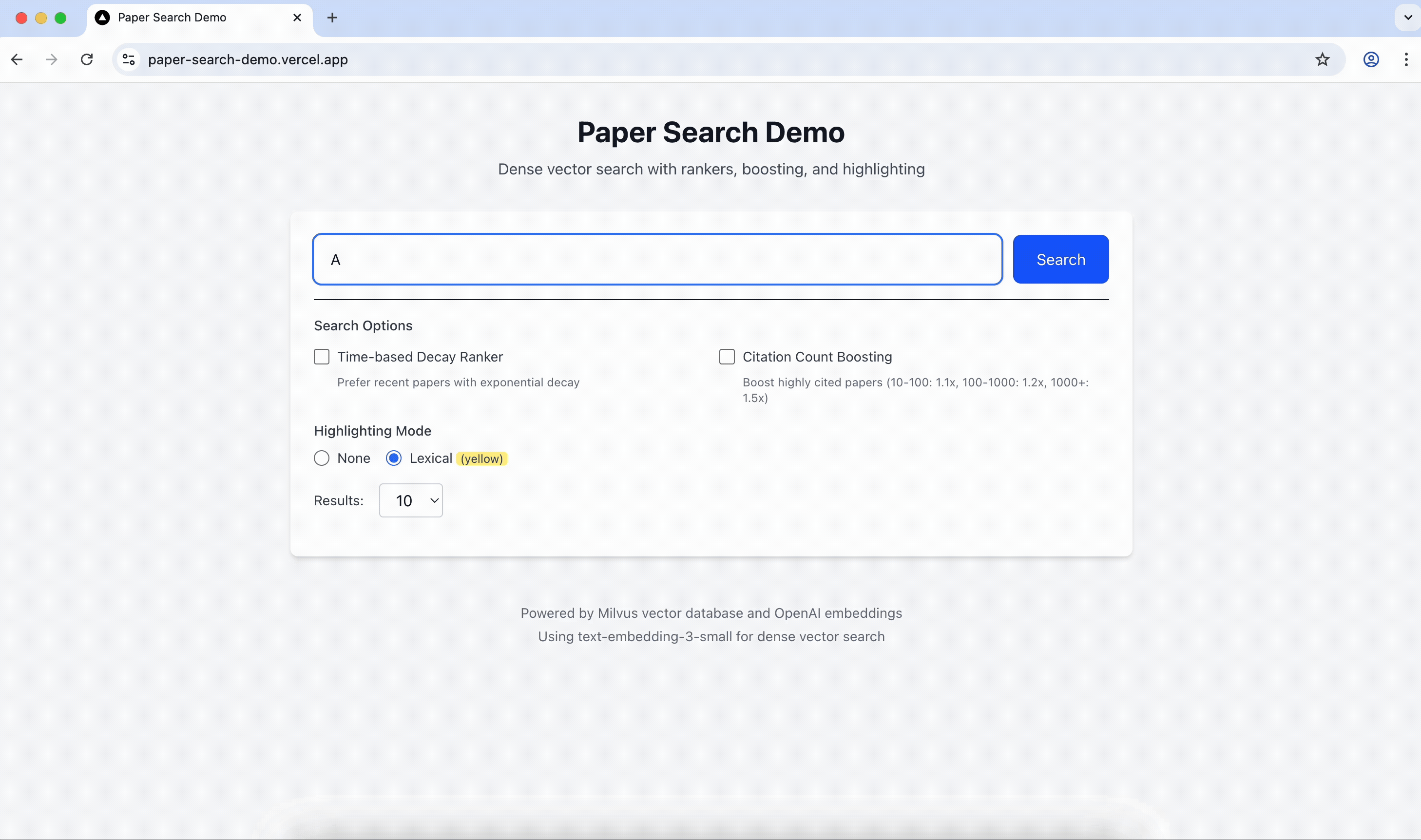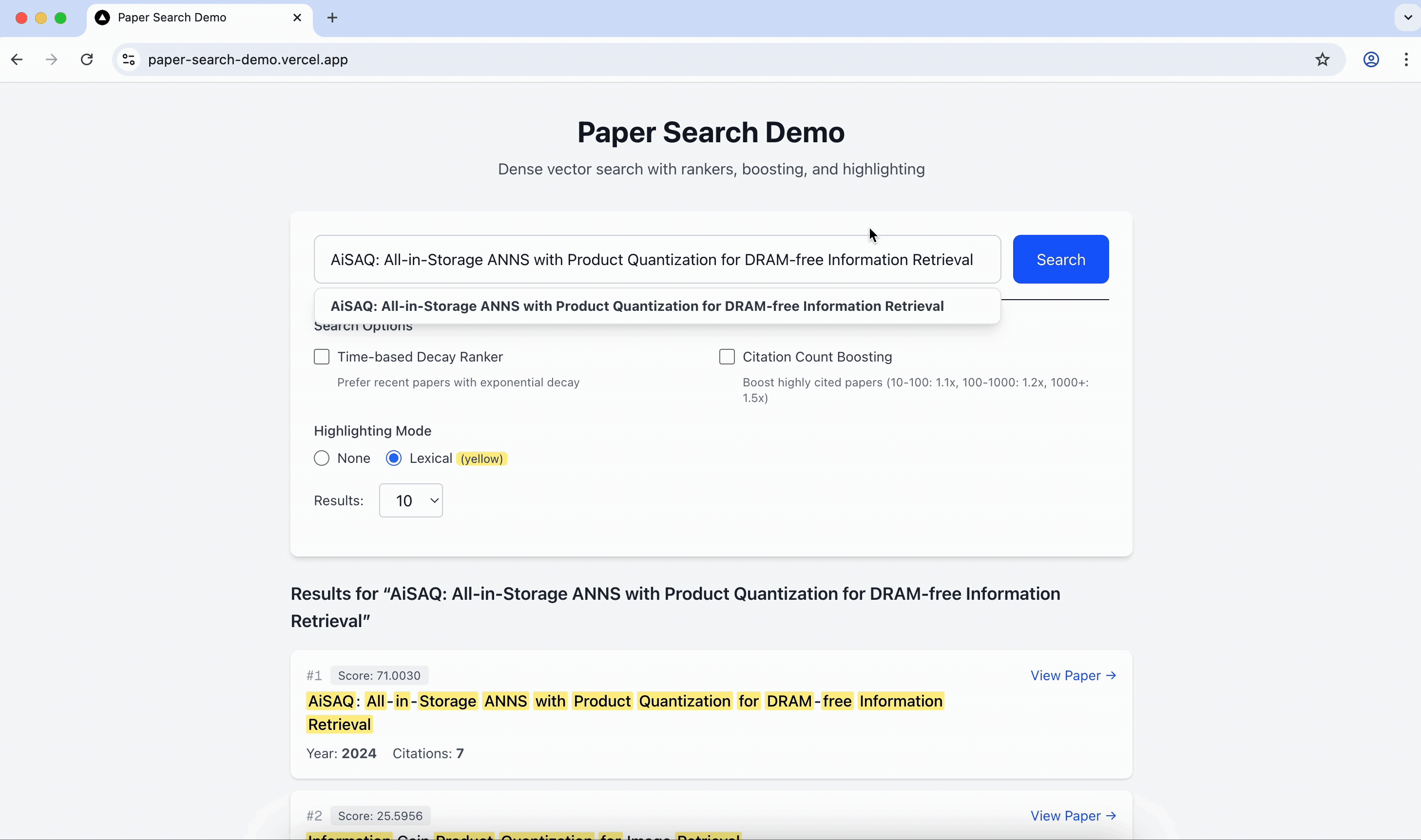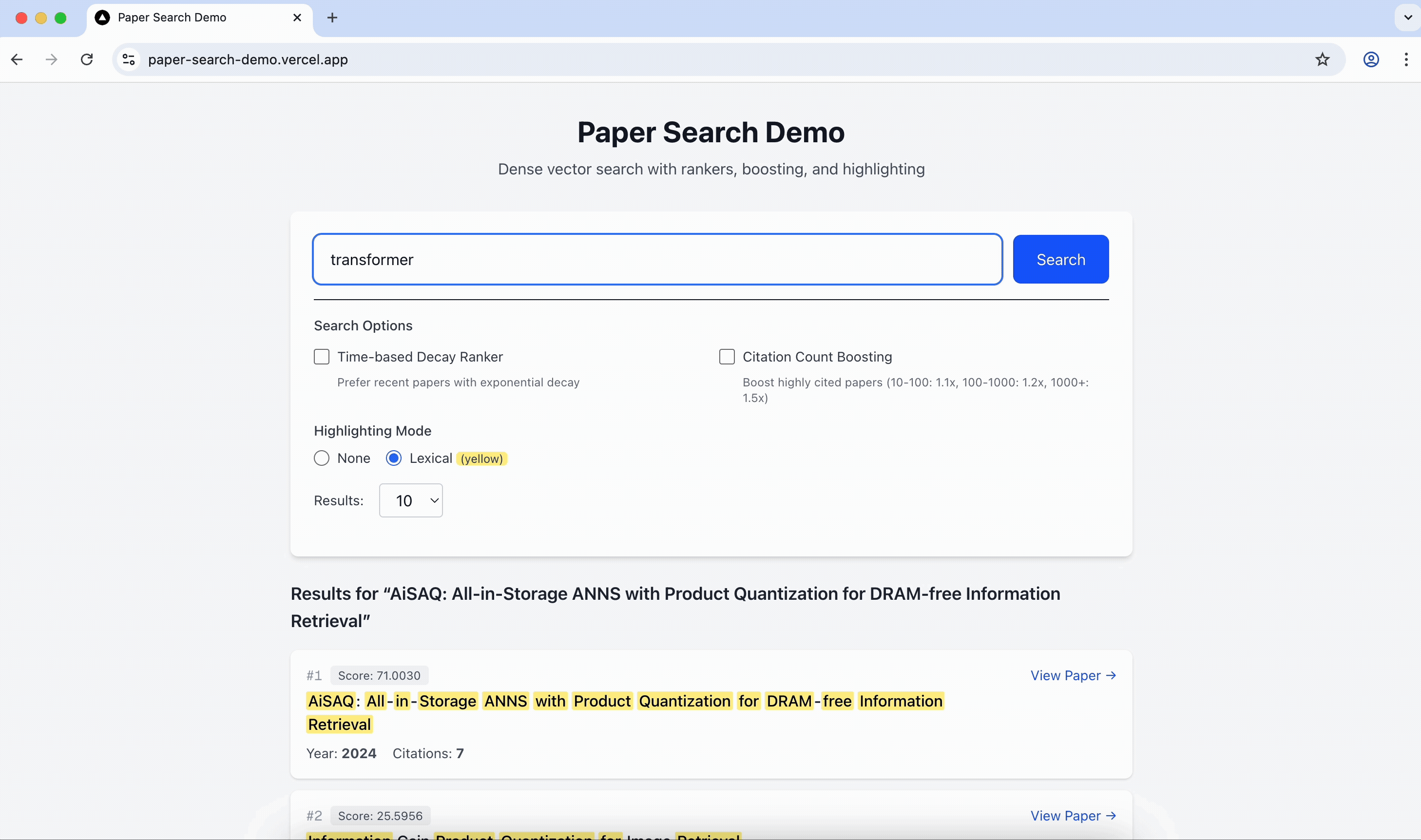
ベストプラクティスとヒント
- 代表的なクエリでベンチマークする: 本番環境にデプロイする前に、現実的なクエリパターンでテストし、
min_gramとmax_gramの設定が実際のユーザー行動に合致していることを検証してください。 - ベクトル検索と戦略的に組み合わせる: ベクトル類似度計算の前に候補集合を減らすための事前フィルターとして NGRAM で高速化されたフィルタリングを使用し、全体的なクエリレイテンシを改善します。
- 過剰なインデックス作成を避ける: すべての VARCHAR フィールドが NGRAM index の恩恵を受けるわけではありません。ワイルドカードパターンを含む
LIKEクエリで頻繁に使用されるフィールドを優先してください。 - n-gram index は 大文字と小文字を区別する ことに注意してください。これは、トークンが元のテキストに表示されるとおりに正確にインデックス化され、大文字と小文字の区別が保持されることを意味します。クエリは、インデックス化されたコンテンツで使用されている正確な大文字小文字と一致する必要があります。
Decay Ranker
過去10年以内に公開された論文を、10年以上前に公開された論文よりも優先する研究論文向けのセマンティック検索エンジンを構築していると想像してください。
Milvus の decay ranker がなければ、おそらく検索結果をベクトルデータベースの外部で、公開年フィールドに基づいて再ランキングする必要があります。これにはアプリケーションサーバー/クライアント側の処理が必要となり、複雑さとレイテンシの両方が増加し、ユーザー体験に悪影響を与える可能性があります。
Milvus の decay ranker の中心にあるのが Decay Function です。Decay Functions は、数値フィールド(タイムスタンプなど)に基づいて関連性スコアを調整します。最終スコアは次のように計算されます。
final_score = normalized_similarity_score x decay_score
現在、Linear、Exponential、Gaussian という3つの異なる decay functions があります。各 decay function は異なるシナリオで有用です。たとえば、Linear Function は、ある一定の点(例:年数、距離など)を超えたエンティティを除外する必要がある場合に使用すべきです。Exponential Function は、より新しいアイテムを結果で優位にしつつ、古い結果も発見可能にしたい場合に使用できます。Gaussian Function は位置情報ベースの検索に有用で、つまり現在地に近いアイテムほど上位にランク付けされます。
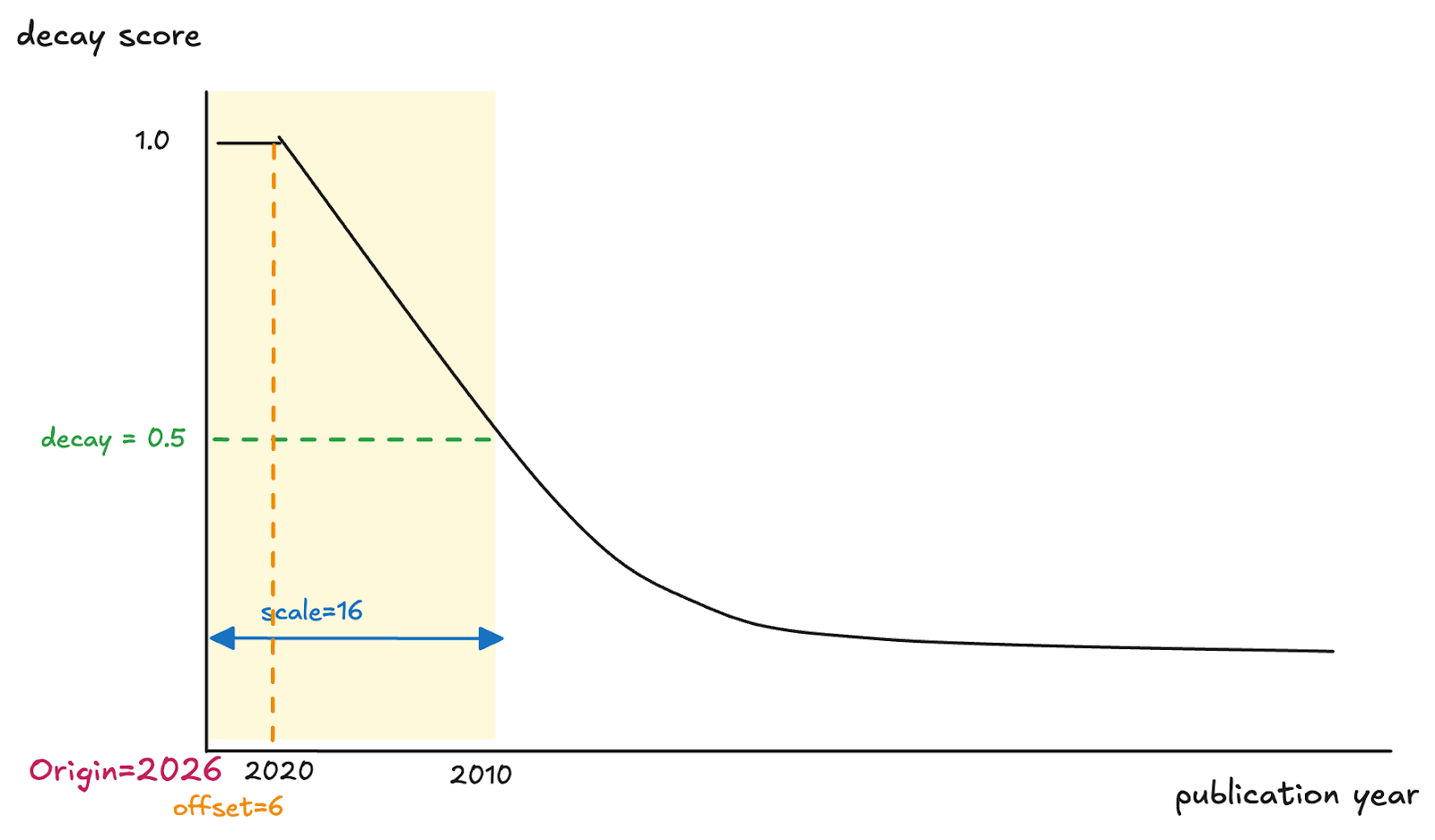
Decay functions は高度にカスタマイズ可能であり、初期化時にいくつかのパラメータを使用してその形状を制御できます。
- origin: 基準点(例: 現在のタイムスタンプ)
- offset: アイテムが満点のスコアを維持する「減衰なしゾーン」を作成します(decay = 1.0)。ごく最近のアイテムや非常に近いアイテムがまったくペナルティを受けないようにするのに役立ちます。
- scale: 値が大きいほど関連性は緩やかに低下し、小さいほど急激に低下します。
- decay: 曲線の急峻さを制御します。低い値(例: 0.3)はより急激な低下を生み、高い値(例: 0.7)はより緩やかな低下を生みます。デフォルトは 0.5 です。
以下は、減衰関数のパラメータを設定する方法を考える例です。
- 現在の年を origin として使用する:
origin=2026 - 2021 年から 2026 年までの研究論文は、減衰が適用されず同等に関連性がある:
offset=6 - scale 距離におけるスコア乗数:
decay=0.5 - 2010 年の論文は、(以前に指定した)減衰スコア 0.5 を持つべきである:
scale=16(2026 - 2010 = 16 であるため)
ベストプラクティスとヒント
- 減衰設定を A/B テストしてください。
scaleとdecayパラメータの小さな変更が、ユーザー体験に大きく影響する可能性があります。 - 時間ベースのすべてのパラメータ(
origin、scale、offset)が、コレクションデータと同じ単位を使用していることを確認してください。 - FunctionScore は、1 つのクエリにつき単一の DecayFunction のみを受け付けます。複数の DecayFunction を連鎖または合成することは、現在サポートされていません。
- 各 decay ranker は 1 つの数値フィールド のみをサポートします。単一の ranker 内で複数の減衰要因を組み合わせることはできません。
- スパースまたは偏ったフィールドでの減衰は避けてください。減衰フィールドに null 値、外れ値、または大きく偏った分布が多数ある場合、減衰ランキングは直感に反する結果を生む可能性があります。
ブースティング
ブースティングは、ドメインシグナルをベクトル検索ランキングに組み込むための実用的な仕組みです。セマンティック検索はクエリが何についてのものかを捉えますが、特定のドメインで何がより重要かはしばしば無視します。ブースティングにより、任意のメタデータフィールドを使って結果を再ランキングでき、ビジネスやドメインの直感を検索レイヤーに効果的にエンコードできます。
たとえば、研究論文検索のワークフローでは、2 本の論文がどちらも「deep learning」に関連している場合がありますが、重要度が同じとは限りません。被引用数の多い論文は、類似度スコアがわずかに低くても、被引用数の少ない論文より上に表示されるべきかもしれません。ブースティングを使うと、類似度スコアが 0.79 で被引用数が 1,200 の論文を、スコアが 0.81 でも被引用数が 10 しかない論文より上位にランク付けできます。
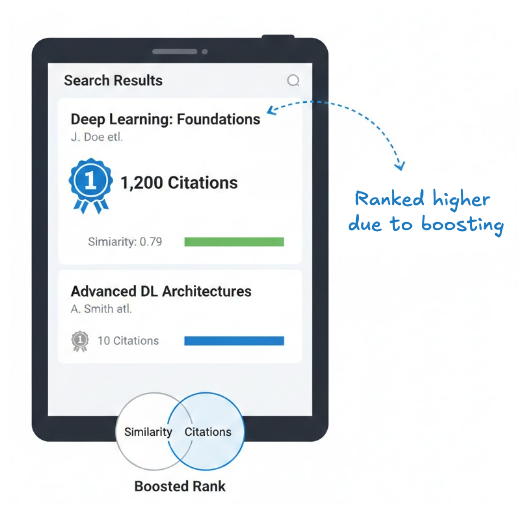
上記は、被引用数に基づいて論文をブーストすることで実装できます。単純な実装は以下のとおりです。
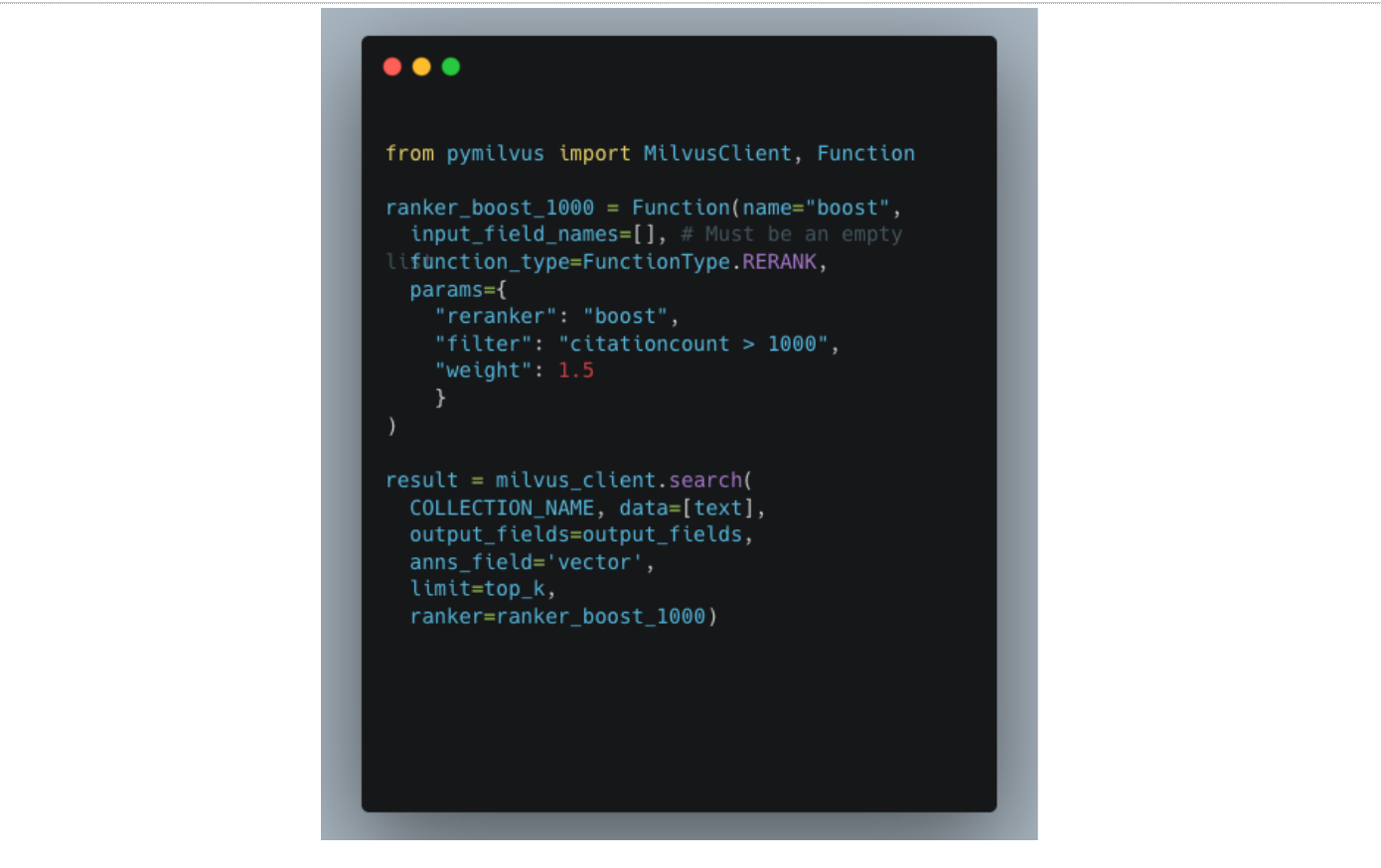
しかし、被引用数が 100 から 1000 の間にある研究論文をブーストし、さらに新しい論文を優先するために減衰関数も含めたい場合はどうでしょうか。実は、FunctionScore class を使用することで、単一の検索リクエスト内で減衰関数と複数の boost ranker を連鎖できます。
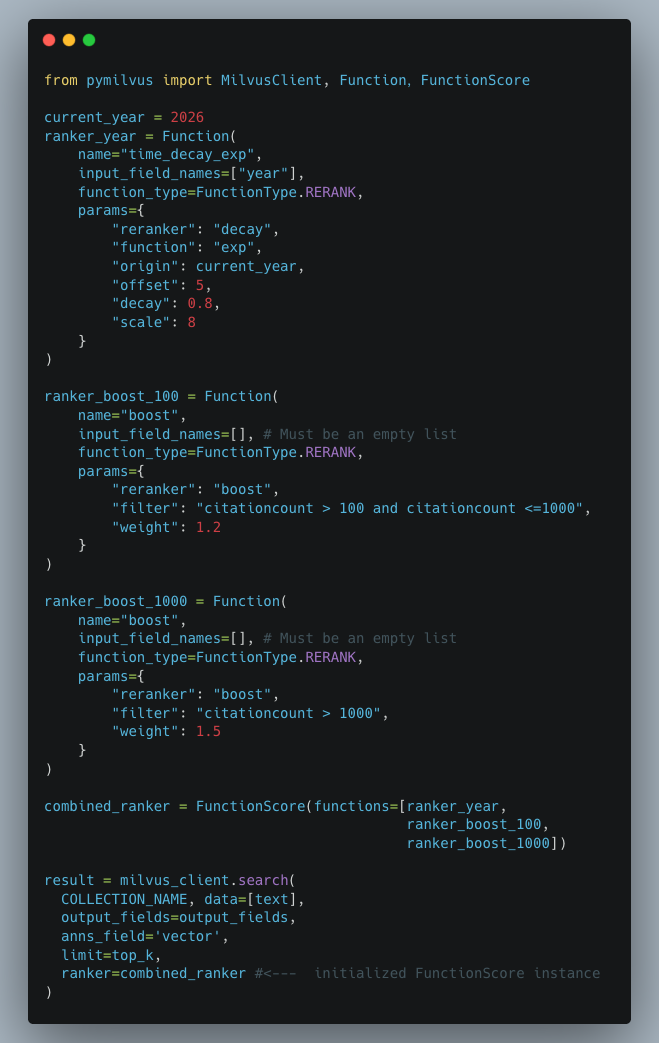
ベストプラクティスとヒント
- FunctionScore は現在、dense vector search のみでサポートされています。Hybrid search は FunctionScore をサポートしていません。代わりに単一の ranker を使用してください。
- 連続値フィールドに基づいてブースティングする場合は、値を離散的なバケットに入れ、各バケットに異なるブースト重みを割り当てることを検討してください。
まとめ
Milvus 2.6 は、ベクトルデータベースが標準で実行できることにおいて、意味のある前進を示しています。上で説明した機能や能力は、単なる「あれば便利」なものではなく、開発者が以前はデータベースの外部で構築し維持しなければならなかったグルーコードを不要にします。
外部の埋め込みパイプライン、カスタムの再ランキングロジック、部分文字列検索の回避策をつなぎ合わせる代わりに、これらを Milvus クエリ内で直接表現できるようになりました。その結果、アプリケーションコードはよりクリーンになり、レイテンシは低下し、問題が発生したときにデバッグすべき可動部分も少なくなります。
Milvusを「単なる」ベクトルストアとして扱ってきたなら、何が可能なのかを見直す時期かもしれません。これらの機能はすべてZilliz CloudでGAになっているため、今日から試し始めることができます。
リソース
読み続けて

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.