




How Inkeep and Milvus Built a RAG-driven AI Assistant for Smarter Interaction
As developers, searching through technical documentation of various platforms or services can be tedious. Typical technical documentation contains numerous sections and hierarchies that can be confusing or difficult to navigate. Consequently, we often find ourselves spending a significant amount of time searching for the answers we need. Adding an AI assistant to technical documentation can be a time-saver for many developers, as we can simply ask the AI about our queries, and it will provide answers or redirect us to the relevant pages and articles.
In a recent Unstructured Data Meetup hosted by Zilliz, Robert Tran, the Co-founder and CTO of Inkeep, discussed how Inkeep and Zilliz built an AI-powered assistant for their doc site. We can now see this AI assistant in action on both the Zilliz and Milvus documentation sites.
In this article, we will explore the technical details presented by Robert Tran. So, without further ado, let’s begin with the motivation behind integrating an AI assistant into technical documentation pages.
The Motivation Behind AI Assistant in Technical Documentation
Technical documentation is an essential source of information that all platforms must provide to assist their users or developers. It should be intuitive, comprehensive, and helpful in guiding developers of all experience levels to use the features and functionalities available on the platforms.
However, as platforms introduce numerous new features, their technical documentation can become overly complex. This complexity can potentially confuse many developers when navigating through a platform's technical documentation. Developers are often under pressure to deliver results quickly, and the time spent searching for information in technical documentation can distract them from actual coding and development work.
Many platforms offer basic search functionalities in their technical documentation to help developers find the content they need quickly, similar to how we search on Google. Users can type in keywords, and the platform will provide a list of potentially relevant pages to answer their questions. However, these basic search functions often fail to understand the context of a user's query, leading to irrelevant or incomplete search results.
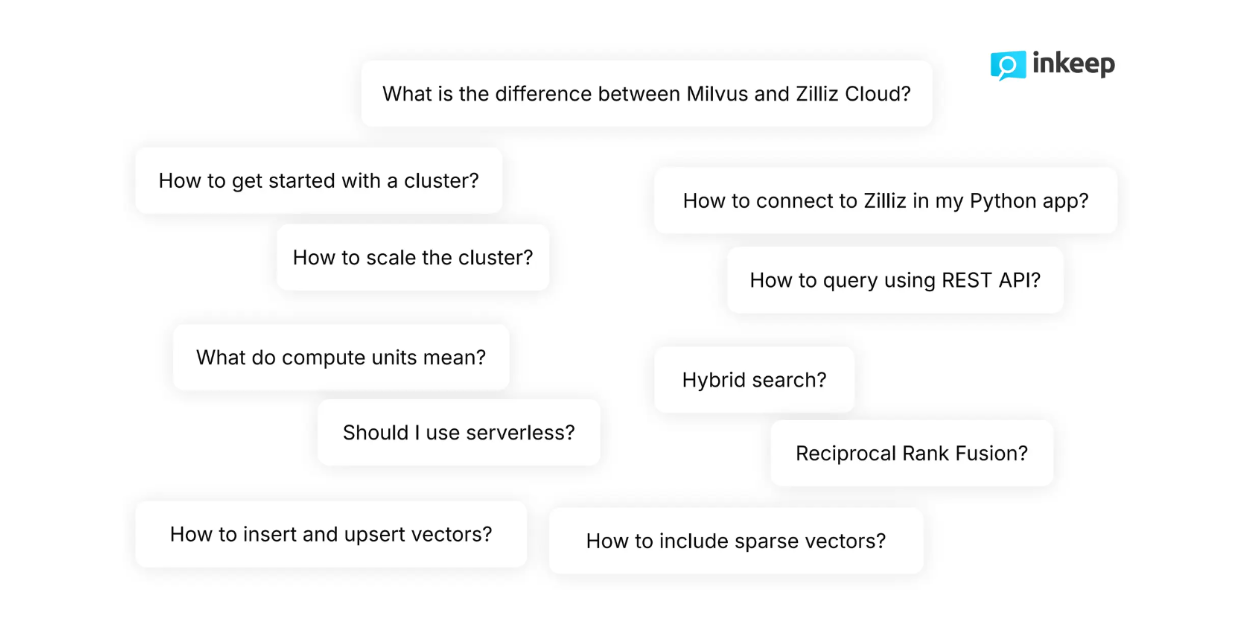 Figure- Typical questions asked by developers about Milvus .png
Figure- Typical questions asked by developers about Milvus .png
Figure: Typical questions asked by developers about Milvus
As developers, we know that our questions are often more nuanced and sometimes too complex for basic search functionalities. For example, when navigating through Zilliz's technical documentation, developers typically ask highly technical questions like "How to include sparse vectors alongside dense vectors during the retrieval process?" or "How to scale the cluster dynamically?" Basic search functionalities often fail to satisfactorily answer such nuanced and complex questions.
The addition of an AI assistant solves these problems. An AI assistant can understand developers’ intent behind and the semantic meaning of their queries, allowing developers to get the information they need in seconds. Developers can simply type in their query, and the AI assistant will provide them with an answer or redirect them to the exact relevant page instead of sifting through a lot of content, which is both tedious and time-consuming.
Moreover, AI assistants are typically powered by the latest advancements in natural language processing (NLP), such as Large Language Models (LLMs), vector search, and Retrieval Augmented Generation (RAG). In fact, the RAG approach is at the heart of this AI assistant, enabling it to comprehend the nuances behind users' questions and return accurate and relevant answers in seconds.
In the next section, we'll discuss the methods behind an AI Assistant.
The Concept of Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is a method that combines advanced NLP techniques such as vector search and LLMs to generate accurate answers to users' queries.
 Figure- RAG workflow.png
Figure- RAG workflow.png
Figure: RAG workflow.
In a nutshell, the workflow of a RAG method is quite simple. First, we as users ask a query. Next, the RAG method fetches relevant documents that possibly contain the answer to our query. Then, our query and the relevant documents are combined into one coherent prompt before being sent to an LLM. Finally, the LLM generates the answer to our query using the relevant documents provided.
As we can see, the main concept of RAG is providing an LLM with relevant context to answer our query. There are at least two benefits to this approach: first, it reduces the risk of LLM hallucination, i.e., generating inaccurate and untruthful responses. Second, the response generated by the LLM will be more contextualized and tailored to our query. This is particularly useful when we ask the LLM questions about the content of internal documents.
There are four RAG steps that we need to consider when implementing RAG: ingestion, indexing, retrieval, and generation.
Ingestion: involves collecting and preprocessing the data. Relevant information and metadata of each record might be collected as well.
Indexing: involves the data storing process with an optimized indexing method for quick retrieval. In this step, the preprocessed data are transformed into vector embeddings using an embedding model and then stored inside a vector database like Milvus with advanced indexing algorithms such as FLAT, FAISS, or HNSW.
Retrieval: involves vector search operations to match the users' query with stored data. In this process, the user's query is first transformed into a vector embedding using the same embedding model used to transform stored data. Next, a similarity search is performed between the user's query and stored data to find the most relevant information in the vector database.
Generation: involves the utilization of an LLM to produce the final response. First, the user's query and the most relevant context from the retrieval step are combined into a prompt. Next, the LLM generates a response to the user's query based on the context provided in the prompt.
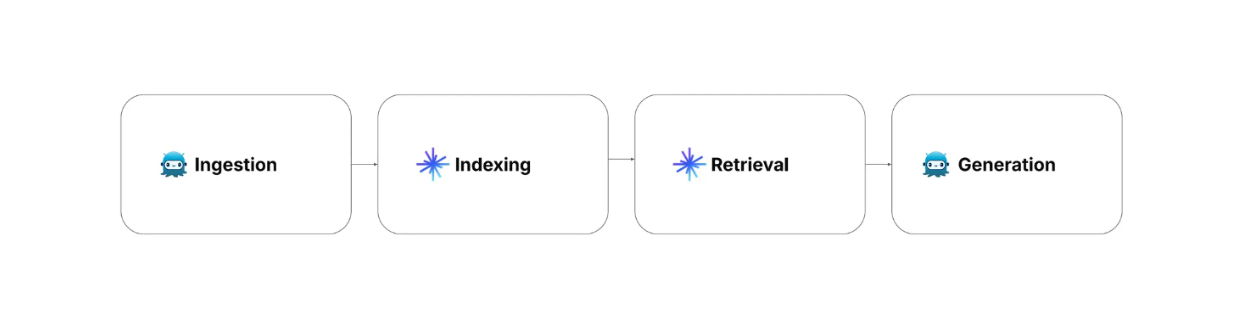 Figure- Steps of RAG..png
Figure- Steps of RAG..png
Figure: Steps of RAG.
There are several factors we need to consider when implementing each of the steps mentioned above. For example, during the ingestion stage, we need to think about the source of the data, the data cleaning approach, and the chunking method. Meanwhile, during the indexing stage, we need to consider the embedding model and vector database that we want to use, as well as the indexing algorithms appropriate for our use case.
In the next section, we'll discuss the detailed RAG implementations taken by Inkeep and Zilliz to build an AI assistant for both Zilliz and Milvus documentation pages.
Methods Used by Inkeep and Zilliz to Build an AI Assistant
To build an AI assistant, Inkeep and Zilliz use a combination of different techniques for RAG implementation. Inkeep handles the ingestion and generation parts, while Zilliz provides support to Inkeep in the indexing and retrieval steps.
As mentioned in the previous section, the first step of RAG implementation is the ingestion step. In this step, Inkeep collects Zilliz and Milvus-related textual data from various sources, such as technical documentation, support and FAQs, and GitHub repositories. This textual data is then cleaned and chunked to ensure that each piece of information is neither too broad nor too granular.
The metadata of each chunked record is also collected before moving on to the next step. These metadata include:
Source type: whether the data is taken from a GitHub repo, technical documentation, support and FAQ page, etc.
Record type: such as the version of the data, whether it's text or code. If it's code, the programming language is also noted.
Hierarchical references: including the children, parent, and siblings of each data point. This is important since the data is collected from Zilliz's websites.
URLs, tags, paths: such as the URLs from which the data is taken. This metadata is very useful for providing links to citations or sources in the response generated by the LLM.
Dates: such as the published date of each data.
Once Inkeep has collected the data and their metadata, the next step is the indexing method.
In the indexing method, the preprocessed data needs to be transformed into vector embeddings to enable similarity search in the retrieval step. To transform each data point into a vector embedding, Inkeep and Zilliz use three different embedding methods: one traditional sparse embedding model, one deep learning-based sparse embedding model, and one dense embedding model.
 Figure- Sparse and dense embeddings..png
Figure- Sparse and dense embeddings..png
Figure: Sparse and dense embeddings.
Sparse embedding is particularly useful for simple, keyword-based, and boolean matching processes. Therefore, the relevant documents fetched from a sparse embedding normally contain the keywords of your query. Meanwhile, dense embedding is more useful to capture the nuance or semantic meaning of your query. The fetched documents from dense embedding may or may not contain the keywords of your query, but the content will be highly relevant to it.
There are two different types of models that can be used to transform data into sparse embedding: traditional/statistical-based models and deep learning-based models. For the AI assistant, Inkeep and Zilliz use BM25 as the traditional-based model and SPLADE/BGE-M3 as the deep learning-based model.
To transform data into dense embedding, there are many deep learning models to choose from, such as embedding models from OpenAI, Sentence-Transformers, VoyageAI, etc. For the AI assistant, Inkeep and Zilliz use three different embedding models: MS-MARCO, MPNET, and BGE-M3.
Once all data is transformed into its sparse and dense embedding representations, the embeddings are then stored inside a vector database to enable fast retrieval. To build the AI assistant, Inkeep and Zilliz use Milvus as the vector database. Now the question is: why do we need to use a combination of sparse and dense embedding when choosing one of them might be sufficient?
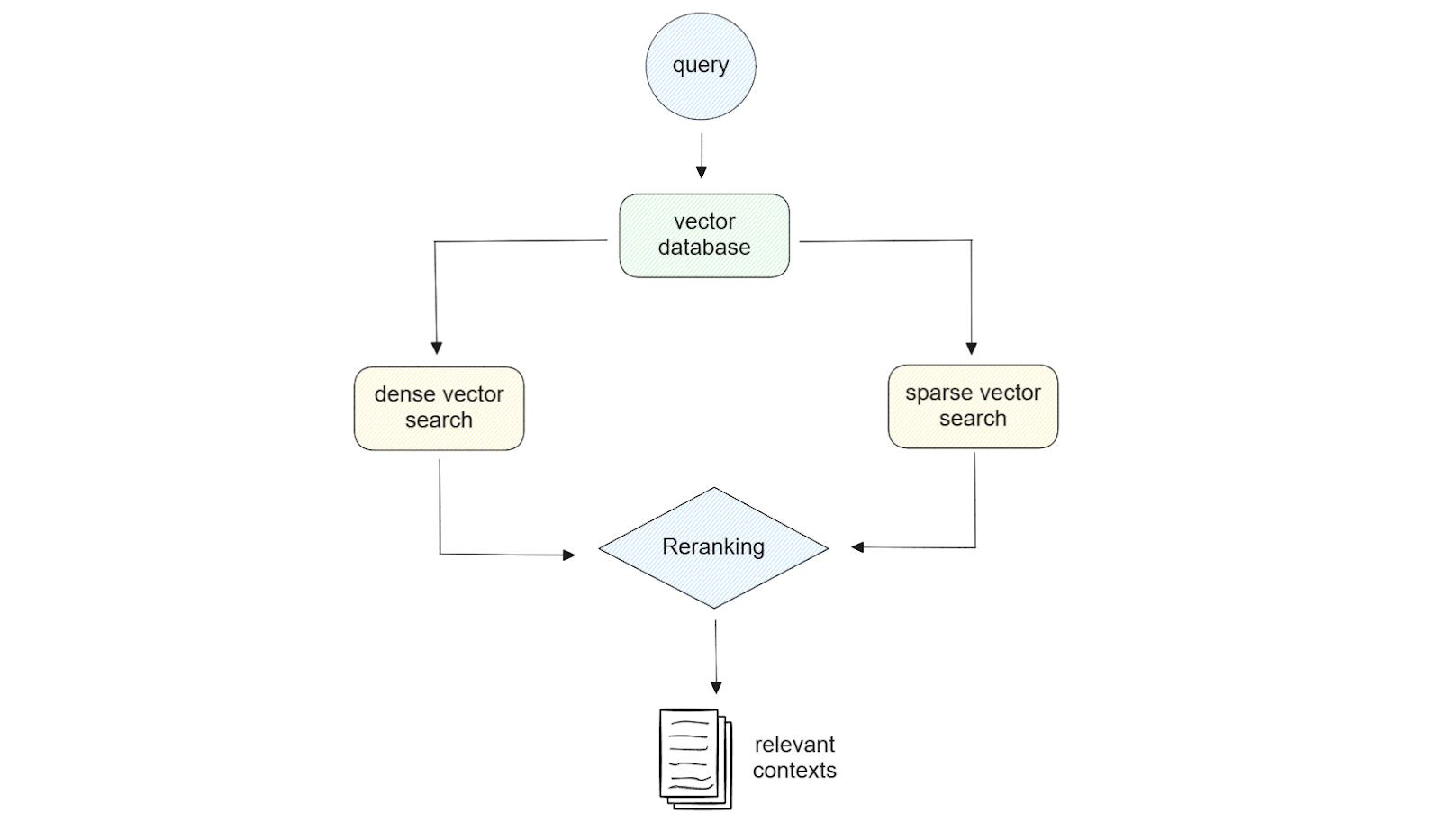 Figure- Hybrid search illustration..png
Figure- Hybrid search illustration..png
Figure: Hybrid search illustration.
Using both sparse and dense embedding provides flexibility in the retrieval step. For example, if our query is short (less than 5 words), then using sparse embedding might be sufficient. Meanwhile, if our query is long, then using dense embedding will in most cases give us better result quality. Also, if we use Milvus as a vector database, we can leverage the power of hybrid search, i.e., similarity search using a combination of sparse and dense embedding. We can also perform a similarity search with dense or sparse embedding with metadata filtering if desired.
When implementing hybrid search to find the most relevant content for our query, we also need to consider the reranking method. This is because we'll get similarity results from two different methods, and we need an approach to combine these results. To do this, Inkeep and Zilliz implemented two different reranking methods: weighted scoring and reciprocal rank fusion (RRF).
The concept behind weighted scoring is simple: we assign a weight to each method. For example, we can assign 60% weight to the similarity result from dense embedding and 40% from sparse embedding. Meanwhile, in RRF, the scores of contexts are calculated by summing their reciprocal ranks across two different methods, often with an additional small constant k to avoid division by zero.
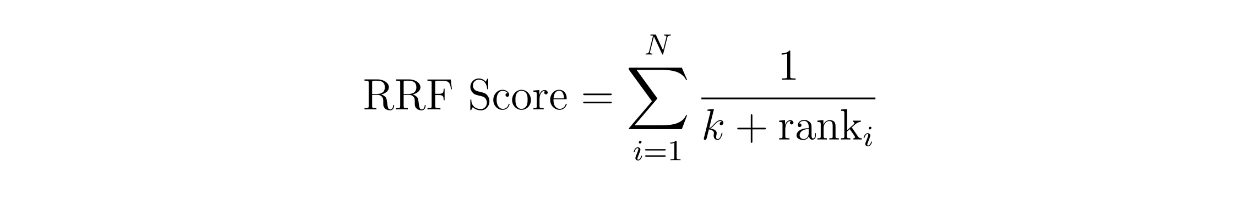 function rrf score.png
function rrf score.png
where N is the number of methods, which should be two since we're implementing a hybrid search between a sparse embedding and a dense embedding. The variable 'rank' is the rank of a context in method i, and k is a constant.
Using the RRF equation above, we can calculate the RRF score for each context. The context with the highest RRF score will be selected as the most relevant context for a query.
Once the relevant context has been fetched, the original query and the most relevant context are combined into one coherent prompt. This prompt is then sent to an LLM to generate the final response. For the LLM, Inkeep uses models from OpenAI and Anthropic.
The Milvus AI Assistant Demo
In this section, we will provide a brief introduction on how to use the AI assistant built by Inkeep and Zilliz. If you want to follow along, you can check it out on the Zilliz or Milvus documentation pages. For this demo, we will use the AI assistant on the Milvus documentation page.
When you open the Milvus documentation page, you will see the “Ask AI” button at the bottom right of your screen. Click this button to access the AI assistant.
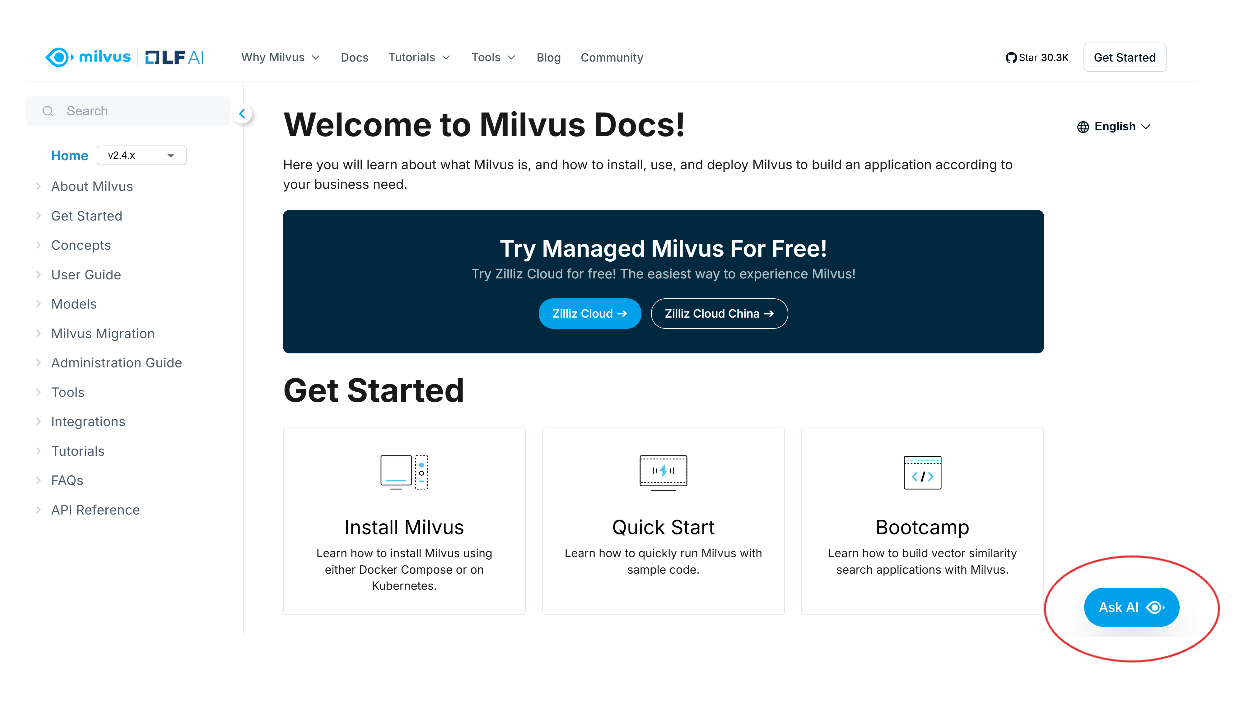 screenshot 1.png
screenshot 1.png
Next, a pop-up screen will appear, prompting you to ask anything you want to find in the Milvus documentation. Optionally, you can also perform a basic search by clicking the “Search” option at the top right of the pop-up screen.
Let’s say we want to know how to transform our data into vector embeddings using BGE-M3 with the Milvus Python SDK. We can simply type our question, and the AI assistant will provide us with an answer.
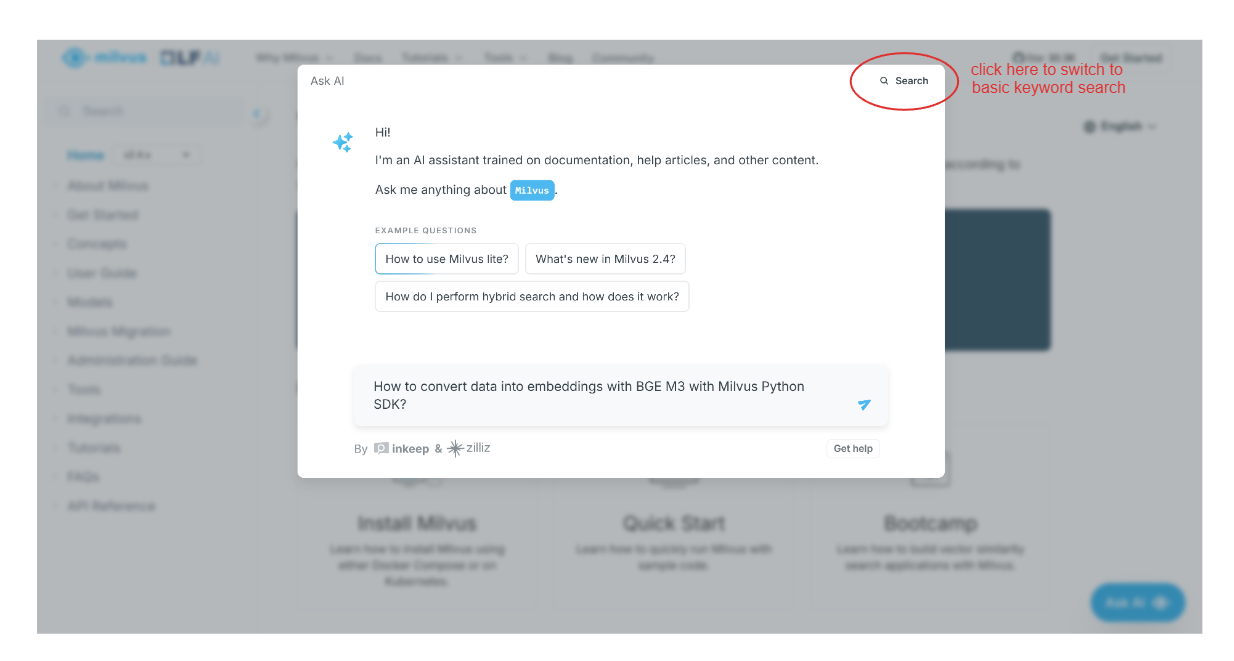 screenshot 2.png
screenshot 2.png
In addition to providing a response, the AI assistant will also give us citations or relevant pages where we can find further information related to the generated answer.
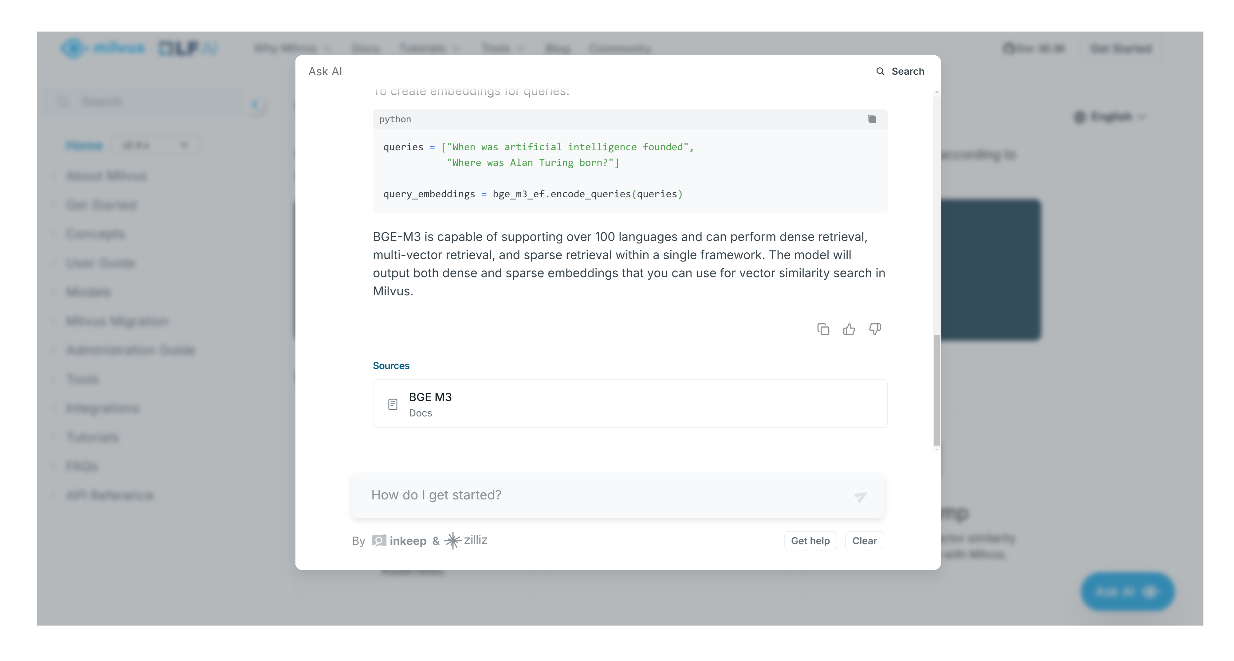 screenshot 3.png
screenshot 3.png
Conclusion
The integration of an AI assistant in technical documentation, as built by Inkeep and Zilliz, demonstrates how advanced AI solutions can enhance developers' productivity and user experience. RAG is the core component behind this AI assistant, as this method helps the LLM provide more accurate and contextualized responses to nuanced and complex queries.
RAG consists of four key steps: ingestion, indexing, retrieval, and generation. Vector databases like Milvus are a key component in the RAG pipeline, performing indexing and retrieval steps. The methods used in each step need to be carefully considered according to the specific use case. In this article, we've also seen an example of how Inkeep and Zilliz implemented various strategies in each RAG step to build a sophisticated AI assistant.
To learn more about how Milvus and Inkeep built this AI assistant, check out the replay of Robert’s talk on YouTube.
Further Reading
Keep Reading

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.