




Producing Structured Outputs from LLMs with Constrained Sampling
Large language models (LLMs) have transformed how we interact with unstructured data, enabling systems that generate creative text, extract insights, and automate tasks. However, while these models produce free-form content, they often fall short when the output must follow specific formats—like JSON, XML, or predefined schemas. This limitation is critical for real-world use cases where precision matters, such as coding assistants, decision-making agents, and structured information extraction systems.
At a recent Unstructured Data Meetup in South Bay, Stefan Webb from Zilliz presented a practical solution to this challenge: constrained sampling. In this article, we'll explore key insights from his talk, including the role of semantic search in processing unstructured data, how finite state machines enable reliable generation, and practical implementations using modern tools. We'll also examine how these techniques integrate with vector databases to create robust AI applications that handle both unstructured data processing and structured output generation.
What is Semantic Search and Why It Matters
Semantic search differs from traditional keyword-based search by focusing on the meaning and context behind queries. Instead of matching exact words, semantic search processes the relationships between terms to deliver more relevant results. This capability is essential in a world where the majority of data is unstructured, including text, images, audio, and videos. Here is how unstructured data is turned into actionable insights.
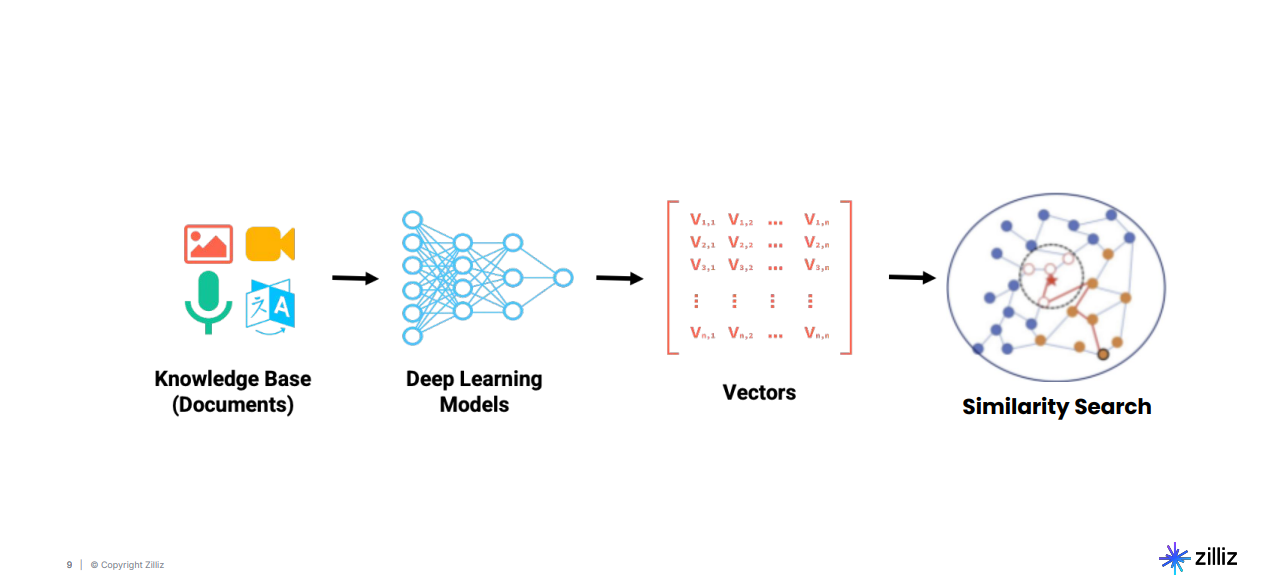
Figure: Pipeline of turning unstructured data into actionable insights
This pipeline begins by ingesting raw data, including documents, images, audio recordings, and videos. The data is passed through deep learning models that generate vector embeddings, which are high-dimensional numerical representations of the data's semantic properties. These embeddings are stored in vector databases such as Milvus for efficient retrieval. Finally, semantic search algorithms operate on these embeddings to identify and rank results based on relevance. Now, let’s see how the vector space looks.
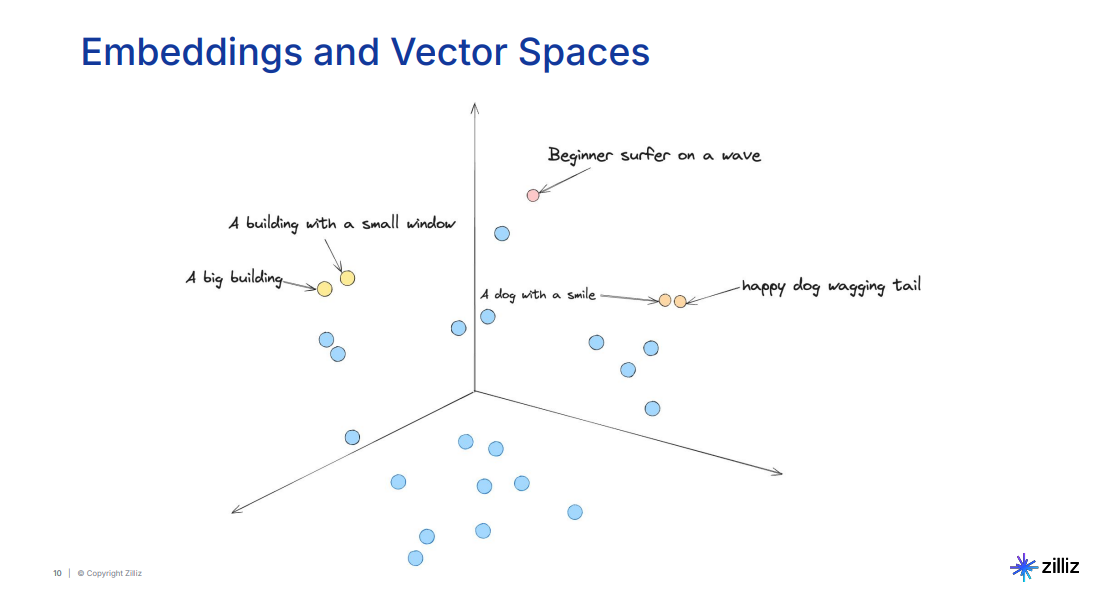
Figure: Visualization of embedding space clustering similar concepts together
In the visualization of embedding spaces, similar concepts are clustered together. For example, phrases such as happy dog wagging its tail and a dog with a smile are grouped closely because they convey similar meanings. On the other hand, unrelated topics like a big building are positioned far apart in the space. This clustering enables systems to retrieve semantically relevant results even when queries use different wording.
Semantic search is increasingly vital as the volume of unstructured data grows. By 2025, it is estimated that over 90% of generated data will be unstructured, underscoring the need for systems capable of semantic understanding.
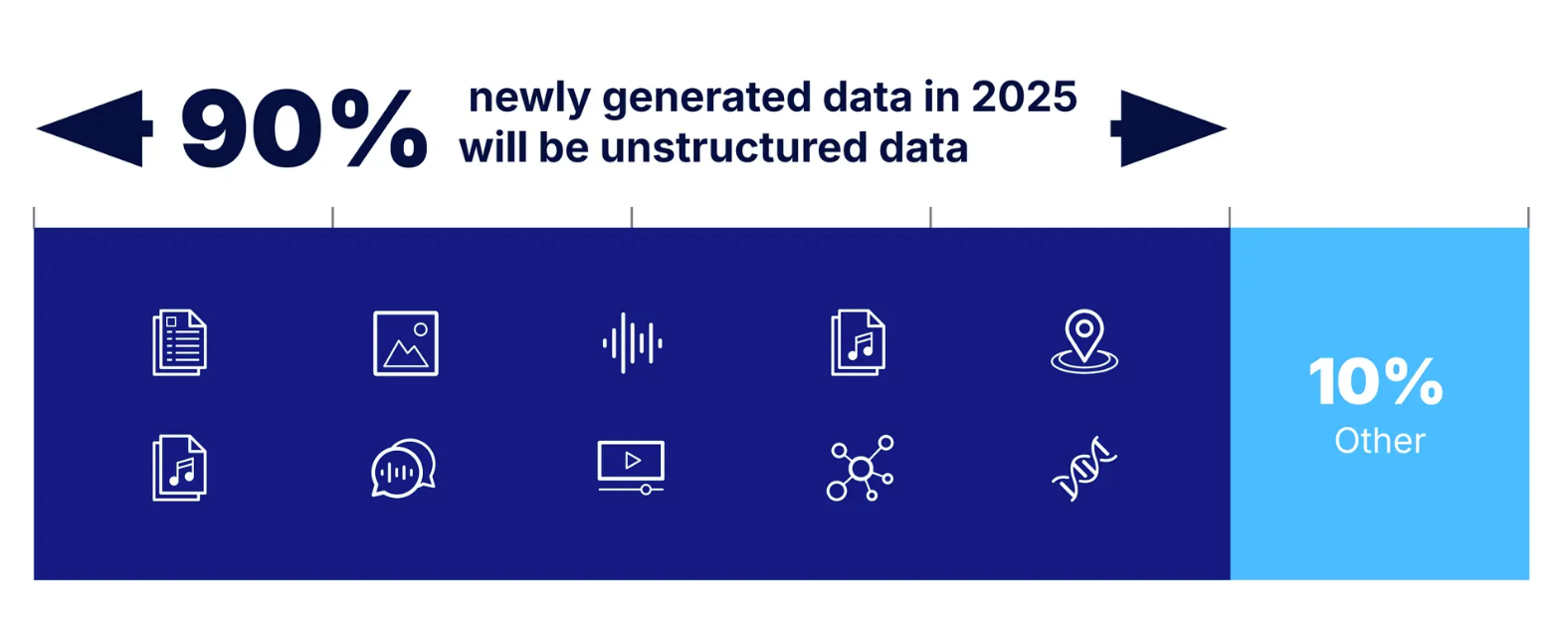
Figure: Over 90% of newly generated data in 2025 will be unstructured.
Multinomial Sampling: The Foundation of Text Generation
Text generation in LLMs is powered by multinomial sampling, a process that generates sequences token by token based on probabilities learned from training data. Each token could represent a word, a character, or a part of a word, and the model selects the next token by sampling from a probability distribution.

Figure: Basic Multinomial Sampling from LLMs
The algorithm begins with an empty sequence and iteratively adds tokens until the sequence is complete or a stopping condition is met. At each step, the model calculates probabilities for all possible next tokens and samples one based on these probabilities. While this method excels at producing free-form text, it lacks mechanisms to enforce structural rules. For example, generating valid JSON or well-formed code often requires post-processing to fix structural errors.
This limitation highlights the need for guided sampling, which incorporates constraints into the generation process to ensure outputs adhere to predefined structures.
Guided Sampling: Enforcing Structural Rules During Generation
Guided sampling enhances the basic multinomial sampling process by applying constraints that guide the generation. These constraints are enforced through binary masks, which filter out invalid tokens at each step. The masks dynamically adapt based on the current context of the output, ensuring that the generated sequence remains valid.

Figure: Structured Output by Guided Sampling
For instance, when generating JSON, the system might restrict the next token to a field name after an opening brace {. Similarly, in code generation, the constraints could enforce proper syntax by blocking invalid characters or incomplete statements. This approach eliminates the need for extensive post-generation validation or corrections, making it particularly useful for applications like information extraction and decision-making agents.
By introducing structure directly into the generation process, guided sampling bridges the gap between the creative capabilities of LLMs and the precision required for structured outputs. This method is the foundation for implementing finite state machines (FSMs) in text generation.
Finite State Machines: Enforcing Structural Consistency
Finite State Machines (FSMs) take the concept of guided sampling further by providing a formal framework to enforce constraints. An FSM is a computational model with a finite number of states and transitions between them. Each state represents a point in the output generation process, and transitions define valid paths based on the current context. By integrating FSMs into the generation pipeline, it becomes possible to enforce strict structural rules dynamically.
In an FSM, states are predefined, and each represents a specific condition or stage in the generation process. Transitions between states occur based on the input or token being generated. By defining permissible transitions, FSMs dynamically guide the model to produce outputs that conform to a given structure.
For instance, an FSM generating JSON might include states for opening a bracket, writing a key, writing a value, and closing the bracket. The FSM ensures that transitions happen in a logical sequence, such as not closing a bracket before writing a value. This guarantees the structural integrity of the output without requiring post-processing.
FSMs are particularly valuable in applications like structured data extraction, code generation, and response formatting. By precomputing the valid transitions for each state, FSMs can be implemented efficiently, minimizing runtime overhead. This efficiency, coupled with real-time constraint enforcement, allows FSMs to generate outputs that are both valid and contextually accurate.
Example: Generating Valid Numbers
To illustrate FSM-guided generation, let’s look at a practical example where the task is to generate a valid number. The rules specify that the number must contain only digits and, optionally, a single decimal point.
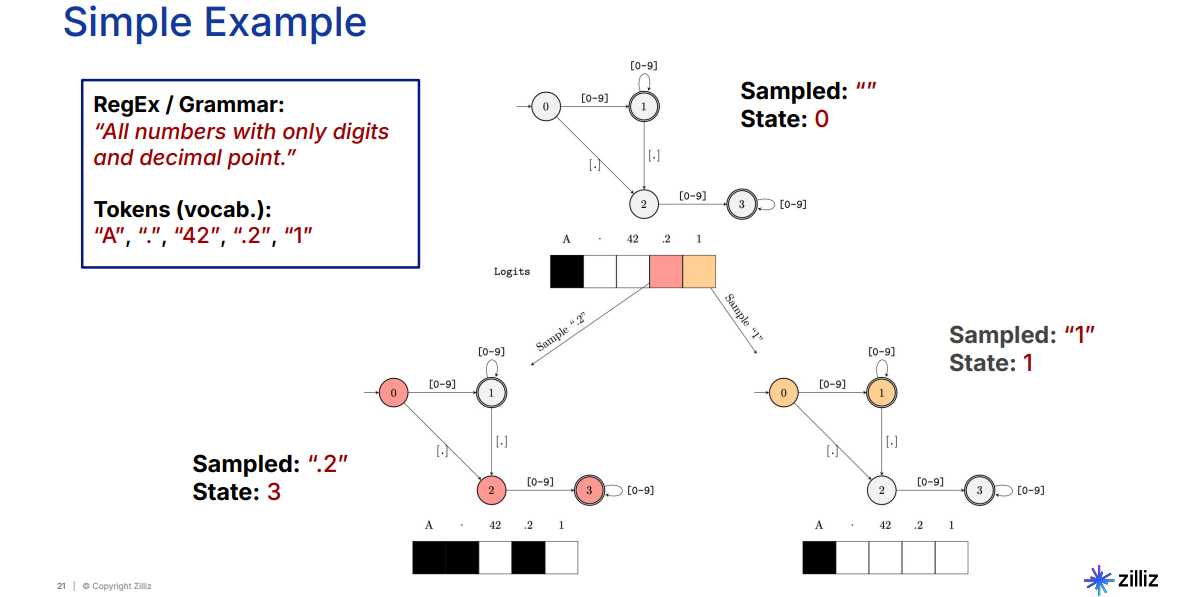
Figure: FSM of Generating Valid Numbers
The FSM starts in State 0, where valid tokens include any digit or a decimal point. If the system generates a digit, such as 1, it transitions to State 1. From this state, additional digits are allowed, or the FSM can transition to State 2 if a decimal point is generated. In State 2, only digits are valid, as multiple decimal points would violate the rules. The FSM dynamically adjusts its state and valid tokens based on the generated sequence, ensuring that the output adheres to the specified format.
This example highlights how FSMs enforce constraints in real-time. By defining the states and transitions for a given task, we can create robust systems capable of generating structured outputs without requiring post-processing or manual validation.
Combining Guided Sampling with Vector Databases
Guided sampling reaches its full potential when combined with vector databases. These specialized databases, like Milvus, are designed to store, manage, and retrieve high-dimensional vector embeddings efficiently. Together, guided sampling and vector databases create a powerful framework for handling unstructured data while producing semantically relevant and structurally precise outputs. Let’s explore how these two components work together to enhance AI applications.
Vector Databases as the Semantic Backbone
Vector databases serve as the foundational layer in applications that involve semantic searches. Embeddings generated by deep learning models are stored in a high-dimensional space within the vector database, where the distances between points signify their semantic relationships, as we saw earlier.
When a user makes a query, it is transformed into an embedding using the same model that created the database embeddings. The database then performs a similarity search to find the embeddings most relevant to the query. This retrieval process enables systems to provide contextually meaningful results, even when the query does not use exact keywords.
Adding Structure with Guided Sampling
While vector databases retrieve semantically relevant information, guided sampling ensures that the output adheres to specific formats or constraints. After retrieving the relevant embeddings, they are passed as input to a large language model (LLM). Without guided sampling, the LLM might generate responses that deviate from the required structure, such as poorly formatted JSON or invalid XML. Guided sampling addresses this issue by dynamically enforcing rules during the token selection process.
Real-World Applications of This Integration
The combination of vector databases and guided sampling has broad applications across various industries:
Coding Assistants: When a developer queries an AI-powered coding assistant, the system retrieves relevant code snippets or documentation embeddings. Guided sampling ensures that the outputted code adheres to the correct syntax and format, reducing the need for manual correction.
Information Extraction Systems: These systems analyze large datasets, extracting structured information such as names, dates, or locations. Vector databases retrieve relevant segments of data, while guided sampling formats the output into predefined schemas like JSON.
Chatbots for Specialized Domains: In healthcare or legal domains, for example, chatbots retrieve semantically similar case studies or documents. Guided sampling ensures that the generated responses comply with strict legal or medical formatting standards.
Tools for Implementing Constrained Sampling: Outlines and BAML
Several tools simplify the implementation of constrained sampling techniques. The Outlines library, for instance, provides a Python-based framework for defining constraints and generating structured outputs. It enables developers to enforce rules like JSON schemas or regex patterns directly during text generation. Similarly, BAML offers a domain-specific language for writing and testing LLM-based applications, streamlining the process of defining constraints and validating outputs.
Let’s take a look at how we can use the Outlines library to enforce constrained sampling:
Start by installing the required libraries:
pip install outlines transformers datasets
The outlines library will allow us to generate structured outputs. The transformers library will allow us to load pre-trained models . The datasets library is a dependency of the outlines library.
With the environment ready, let’s start coding.
import outlines
import transformers
# Load the model
model = outlines.models.transformers("gpt2-medium")
# For text generation
generator = outlines.generate.text(model)
# Example 1: Basic Continuation
prompt = "Is 1+1=2? "
result = generator(prompt, max_tokens=30)
print("Unguided output:", result)
# Example 2: Structured Generation with Regex
guided_output = outlines.generate.regex(model, r"([Yy]es|[Nn]o|[Nn]ever|[Aa]lways)")(
prompt, max_tokens=30
)
print("Guided output:", guided_output)
# Example 3: Numerical Regex Constraint
prompt = "In what year was Noam Chomsky born?n"
guided_output_year = outlines.generate.regex(model, r"19[0-9]{2}")(
prompt, max_tokens=30
)
print("Guided output (year):", guided_output_year)
In the above code, we start by importing the libraries we installed, then load the GPT-2 medium model for generating text. Initially, we generate an unguided response to the prompt Is 1+1=2? showcasing basic text generation. Next, we use a regex to guide the model in producing only responses such as Yes, No, Never, or Always, ensuring outputs adhere to specific answer formats. Finally, we implement a regex constraint r"19[0-9]{2}" to extract a four-digit year, targeting the birth year of Noam Chomsky. Here is a sample output:

Figure: Output of constrained Sampling using Outlines library
This demonstrates the model’s capability for both free-form and structured text generation, tailored to specific information extraction tasks.
Conclusion
Stefan did a great job showing us how constrained sampling and FSMs represent significant advancements in making large language models more reliable for real-world applications. By enforcing structural consistency and leveraging tools like Outlines and vector databases, we can now build systems that combine flexibility with precision. As the field evolves, these techniques will play a pivotal role in bridging the gap between unstructured data processing and structured output generation, unlocking new possibilities for AI-driven applications.
For more information, watch Stefan’s talk on YouTube.
Keep Reading

How Zilliz Saw the Future of Vector Databases—and Built for Production
An inside look at how Zilliz built vector databases for real-world use, focusing on scalability, stability, and running them reliably at scale.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.