




Evaluating Retrieval-Augmented Generation (RAG): Everything You Should Know
Introduction
Retrieval Augmented Generation (RAG) has become a widely adopted approach for implementing Generative AI applications powered by Large Language Models (LLMs). By integrating external knowledge sources, RAG enhances the model’s ability to provide more accurate and contextually relevant responses to specific queries. Despite its potential, RAG-generated answers are not always entirely accurate or consistent with the retrieved knowledge.
In a recent webinar, Stefan Webb, Developer Advocate at Zilliz, explored evaluation strategies for RAG applications, focusing on methods to assess the performance of LLMs and addressing current challenges and limitations in the field.
In this blog, we’ll recap Stefan’s key insights, including an overview of various RAG pipeline architectures, retrieval and evaluation frameworks, and examples of biases and failures in LLMs.
RAG Architecture
Stefan began the talk by introducing the foundational concept of semantic search, a critical component of RAG applications. Semantic search leverages vector databases, such as Milvus or Zilliz, as knowledge base storage systems for vector embeddings. These databases enable efficient searching over unstructured data to retrieve semantically similar contexts relevant to a user's query. This capability forms the backbone of RAG systems, ensuring that the retrieved knowledge aligns closely with the input question, thereby enhancing the quality of generated responses.
Figure 1 below illustrates a basic, naive RAG architecture. In this setup, the system retrieves the most relevant documents based on their semantic similarity to the user's question. The retrieved information is then formatted into a structured prompt, complete with instructions, and passed to the LLM. The model uses this context to generate a well-informed response.
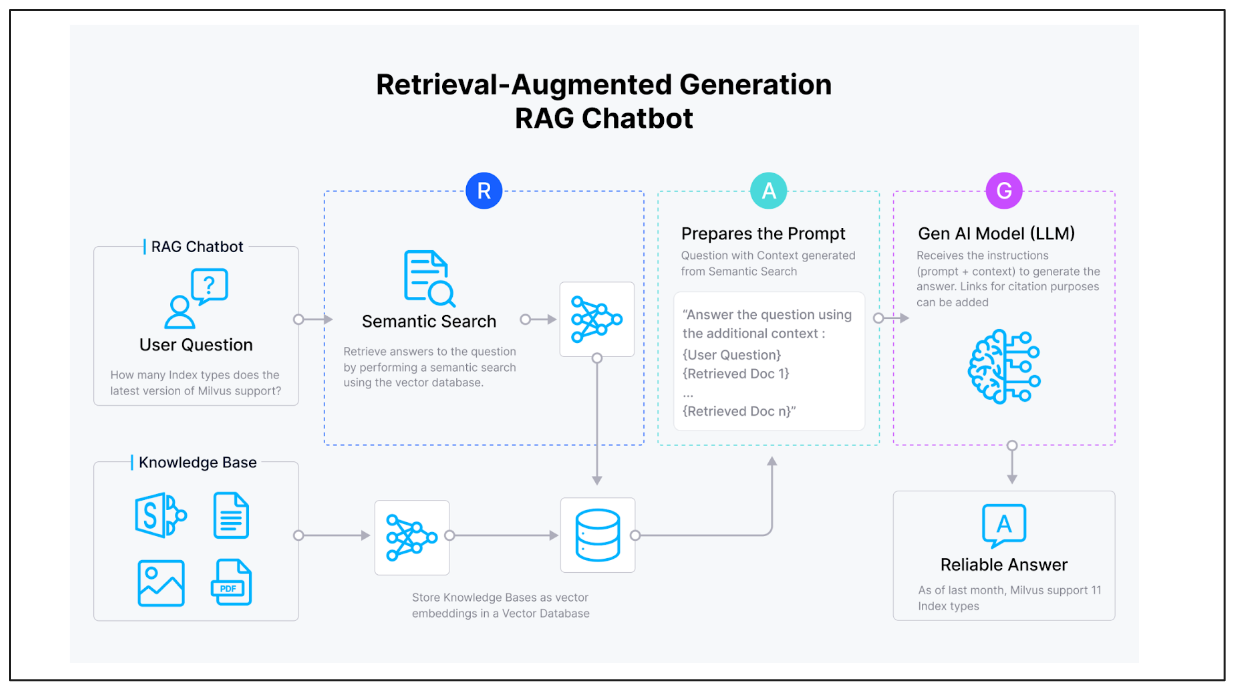 Figure 1: Naive RAG
Figure 1: Naive RAG
Figure 1: Naive RAG
While the basic RAG pipeline can retrieve relevant documents and generate responses, its performance is not always optimal. Some outputs may lack accuracy or relevance. To address these challenges, a modular approach to building the RAG pipeline enables incremental improvements at each stage.
Below (as illustrated in Figure 2) are key techniques that can enhance the pipeline's effectiveness.
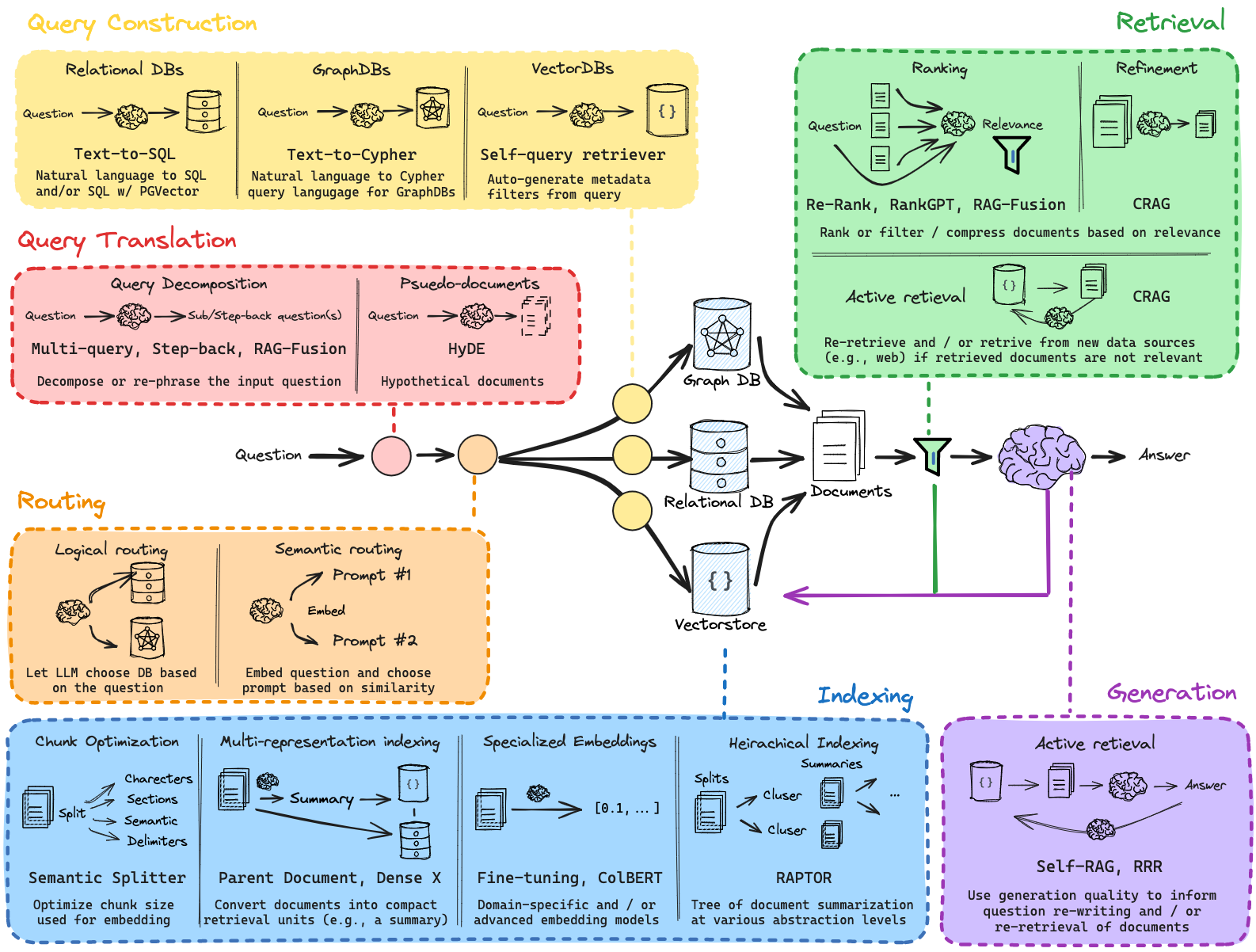 Figure 2: RAG Modular Architecture
Figure 2: RAG Modular Architecture
Figure 2: RAG Modular Architecture (Source)
Query Translation
This step focuses on ensuring that the user’s query is properly understood by the system. It translates queries into a format or representation that aligns with the underlying retrieval mechanism.
Multi-query: Splits the main query into multiple focused subqueries to retrieve diverse yet relevant information.
Step-back: Revisits previous steps in the pipeline when insufficient results are found, refining the query for better retrieval.
RAG Fusion: Merges results from multiple queries to provide a cohesive and comprehensive context for the LLM.
Hypothetical Documents (HyDE): Involves generating synthetic documents or hypothetical contexts that can aid in retrieving semantically similar documents from the knowledge base, improving retrieval for abstract or poorly framed queries.
Query Routing
The Query Routing approach directs the query to the most suitable retrieval mechanism or knowledge source.
Logical Routing: Routes queries based on predefined rules or logical operators, such as filtering by metadata or domain.
Semantic Routing: Directs queries based on their semantic characteristics to the database or system best suited to handle them.
Query Construction
Query Construction refines how queries are formulated to match the structure of the underlying databases.
Relational DB: Constructs SQL-like queries for traditional relational databases.
Graph DB: Uses graph traversal Cypher queries to explore nodes and relationships in graph databases.
Vector DB: Leverages embeddings to create vectorized queries for semantic similarity searches.
Indexing
Indexing improves the organization and accessibility of the knowledge base.
Chunk Optimization: Breaks documents into meaningful, retrievable chunks while preserving context.
Multi-representation Indexing: Creates multiple representations (e.g., semantic, syntactic) of data for diverse retrieval needs.
Specialized Embeddings: Uses domain-specific embeddings to enhance the retrieval of highly specialized or technical information.
Hierarchical Indexing: Structures the index hierarchically for faster, more accurate lookups.
Retrieval
Retrieves the most relevant documents or contexts for a given query using advanced techniques.
Ranking: Scores retrieved documents based on relevance, ensuring the best matches are prioritized.
Corrective RAG: Adjusts ranking based on feedback or additional criteria to improve results dynamically.
Re-retrieval: Iteratively retrieves documents if the initial results do not meet quality expectations, refining the process until an acceptable result is found.
This modular approach to building a RAG pipeline fine-tunes each component independently. By addressing specific challenges at every stage, the pipeline becomes more robust, accurate, and adaptable, ultimately enhancing the quality of the generated outputs.
Evaluating Foundation Models
Whether a naive or advanced RAG approach is used, evaluating the performance of each RAG application is essential. This evaluation helps identify strengths and weaknesses, ensuring the system's reliability and relevance. All LLMs, regardless of sophistication, require rigorous performance assessment to address potential limitations, biases, and inaccuracies.
Performance Evaluation
But how do we measure and evaluate the performance of the model? Measuring the performance of a RAG application requires a nuanced approach, as different aspects of the pipeline need to be evaluated. Below are key considerations and methods for effective performance measurement:
Evaluation on a Task vs. Evaluation on Itself
Task Evaluation: Measures the model's performance on a predefined set of tasks, which often include multi-turn (e.g., MT-Bench) or multi-task (e.g., MMLU) scenarios. Each task is associated with specific ground truth questions and reference answers.
Self-Evaluation: Focuses on internal performance metrics, such as how effectively the model retrieves and processes information without necessarily tying it to a practical use case. This is useful for diagnosing pipeline performance.
Comparing Answers to Ground Truth vs. Context
Ground-Truth Comparison: Assesses how closely the generated response matches a predefined, accurate answer (ground truth). This approach works well for objective tasks like fact-based queries.
Contextual Comparison: Examines how well the response aligns with the context provided by retrieved documents. This is particularly important for tasks where ground truth is unavailable or subjective, emphasizing coherence and relevance.
Evaluating Retrieval vs. Evaluating LLM Output
Retrieval Evaluation: Focuses on the quality of the documents retrieved by the pipeline. Metrics might include recall, and precision between the retrieved documents and the query.
LLM Output Evaluation: Examines the quality of the final output generated by the language model, considering factors like factual consistency, and relevance to the query and retrieved context.
Human Evaluation as the “Gold Standard”
- Human evaluation remains the most reliable method for assessing performance, especially for subjective or complex tasks. Humans can assess nuanced aspects such as logical consistency, tone, and creativity. However, this approach doesn’t scale well due to its time and resource requirements.
Using LLMs to Evaluate LLMs (LLM-as-a-Judge)
- More advanced and efficient LLMs (LLM-as-a-Judge) can be employed to evaluate the outputs of other LLMs, particularly when ground truth is unavailable. These models can score responses based on predefined criteria like relevance, and correctness offering a scalable alternative to human evaluation. However, care must be taken to avoid introducing biases from the evaluating model itself.
Stefan continued the discussion by addressing two approaches to evaluation: task-based evaluation and self-evaluation. Task-based evaluation typically relies on publicly available benchmarks, while self-evaluation focuses more on internal measures or introspection, such as examining the quality of the generated responses and the relevance of retrieved information.
Task-Based Evaluation: The Benchmark Approach
Task-based evaluation is based on using standard, publicly available benchmarks that assess model performance across a variety of tasks. These benchmarks often cover different domains of knowledge, question-answering capabilities, and conversational skills. Some examples include:
Knowledge-based Benchmarks: These benchmarks focus on general knowledge and fact-based question answering.
MMLU: A diverse benchmark that tests language models across multiple domains, including mathematics, science, and history.
HellaSwag: A benchmark designed for measuring commonsense reasoning.
ARC: A benchmark focused on question answering with reasoning capabilities.
Instruction Following Benchmarks: These benchmarks assess the model’s ability to follow instructions and generate relevant responses.
Flan: A series of tasks that assess instruction-following abilities in LLMs.
Self-instruct: Evaluates the model’s ability to generate and follow self-generated instructions.
NaturalInstructions: A large-scale benchmark focusing on the model’s ability to follow natural language instructions.
Conversational Benchmarks: These benchmarks assess the model’s ability to engage in coherent and relevant dialogue.
CoQA: A conversational question-answering dataset that tests models on multi-turn dialogues.
MMDialog: A conversational benchmark that focuses on the quality of dialogue in various scenarios.
OpenAssistant: A conversational AI benchmark that evaluates the model’s ability to hold natural conversations.
While benchmarks provide standardized evaluation criteria, they often fail to capture the nuances of human interaction, such as emotional intelligence, conversational flow, and context sensitivity. For instance, a response might be factually correct according to a benchmark but still fall short in terms of naturalness or empathy, key elements that humans value in real-world conversations. Furthermore, benchmarks may not always reflect the complexity of human preferences, which can vary based on context, user intent, and emotional tone. This is why human evaluation remains a "gold standard" in assessing conversational AI, as it takes into account human preferences that benchmarks often overlook. However, due to the cost and resource-intensive nature of human evaluation, alternative methods, such as introspection-based evaluation, can be considered as more scalable options.
Introspection-based Evaluation
Introspection-based evaluation focuses on evaluating the quality of the responses generated by the model and their alignment with the context, aiming to measure how well the model's outputs adhere to the expectations set by the input. This type of evaluation can be divided into two main categories: Generation-based Evaluation and Retrieval-based Evaluation. Below are some examples of relevant metrics:
Generation-based Evaluation
Faithfulness (Groundedness): This metric measures the factual consistency of the generated answer against the given context. If the model generates claims that cannot be supported by the retrieved context, those claims are penalized. Faithfulness ensures that the model’s output is both consistent and grounded in the information provided.
Answer Relevancy: This metric assesses how well the response directly addresses the user’s question or the given context. A highly relevant response will be both accurate and contextually appropriate, providing the most useful answer to the query.
Retrieval-based Evaluation
Context Relevance: Measures how relevant the retrieved documents or contexts are to the query. Ideally, the retrieved context should only contain information necessary to answer the question. Irrelevant or extraneous information can reduce the quality of the generated response.
Context Recall: This metric assesses how well the retrieved context aligns with the ground truth, often using annotated answers as a reference. It helps evaluate whether the relevant documents were retrieved in the first place, ensuring that the model has sufficient information to generate a meaningful response.
For the metrics of Faithfulness, Answer Relevancy, and Context Relevance, the lack of ground truth presents a challenge for direct evaluation. However, in the absence of ground truth, an alternative method is to employ an LLM-as-a-Judge. A strong LLM can be used to score these aspects by analyzing the coherence, relevance, and factual grounding of the response. By comparing the generated answers against its own understanding of context and relevance, the model can provide an automated evaluation.
Challenges and Limitations of LLM-as-a-Judge
While using an LLM-as-a-Judge can be a useful alternative for evaluating metrics when ground truth is not available, this approach introduces certain challenges and limitations, which must be addressed. The evaluating model itself can introduce biases, which may affect the quality and fairness of the evaluation. Below are some common biases and challenges that must be considered.
Position Bias
Position bias refers to the tendency of the evaluating model to favor responses based on their position in the ranking or the order in which they appear. In many cases, the model may assume that the first or top-ranked response is more relevant or accurate, regardless of its actual quality. This can lead to inaccurate evaluations, especially in cases where the correct answer is ranked lower due to the model's bias toward top-ranking positions.
 Figure 3: Position Bias
Figure 3: Position Bias
Figure 3: Position Bias (Source)
Verbosity Bias
Verbosity bias occurs when the evaluating model tends to favor longer, more detailed responses, even if these are not necessarily more accurate or relevant. In some cases, the model may incorrectly equate verbosity with quality, assigning higher scores to longer responses that contain unnecessary information. This can skew the evaluation process, especially in contexts where concise, clear answers are more desirable.
 Figure 4: Verbosity Bias
Figure 4: Verbosity Bias
Figure 4: Verbosity Bias (Source)
Wrong Judgement
Another limitation is the possibility of wrong judgments. An LLM-as-a-Judge, like any model, can make mistakes in evaluating the quality or relevance of a response. For instance, it may misinterpret context, overlook subtle details, or fail to recognize nuances in the answer, leading to incorrect or misleading evaluation results
 Figure 5: Wrong Judgement
Figure 5: Wrong Judgement
Figure 5: Wrong Judgement (Source)
Wrong Judgement with Chain-of-Thought
Chain-of-Thought (CoT) reasoning in LLM-based evaluation introduces complex error propagation mechanisms that can significantly compromise assessment accuracy. Each intermediate reasoning step acts as a potential point of failure, where even a minor misinterpretation or logical inconsistency can cascade into increasingly substantial errors in the final judgment. For instance, if an early step in the reasoning chain misunderstands a key contextual nuance or incorrectly weights a particular aspect of the response, subsequent reasoning steps will build upon this flawed foundation, exponentially amplifying the initial error.
 Figure 6: Wrong Judgement with Chain-of-thought
Figure 6: Wrong Judgement with Chain-of-thought
Figure 6: Wrong Judgement with Chain-of-thought (Source)
These biases highlight the importance of adopting evaluation strategies that address the limitations of LLM-as-a-Judge approaches. One solution is to use LLM models specifically fine-tuned for evaluation purposes, such as GroundedAI, or Flow-Judge-v0.1. Another strategy is to combine LLM-as-a-Judge evaluations with human assessments whenever possible. Human evaluators bring nuanced understanding and contextual awareness that automated models may lack. Regular auditing and iterative improvements to evaluating models are also essential for minimizing biases and enhancing reliability.
Open-Source Evaluation Frameworks
In addition to LLM-as-a-Judge techniques, several open-source evaluation frameworks are widely used in the market to assess RAG applications. These frameworks provide structured methodologies and tools to evaluate retrieval and generation performance effectively:
RAGAS: A framework for evaluating RAG systems with metrics tailored to RAG applications.
DeepEval: A flexible and robust tool for evaluating RAG or fine-tuning systems on multiple evaluation metrics.
ARES: Designed for evaluation of RAG models, emphasizing context relevance, answer faithfulness, and answer relevance.
HuggingFace Lighteval: Provides lightweight, extensible tools for evaluating RAG applications across multiple backends (e.g., transformers, tgi, vllm, or nanotron).
These frameworks simplify the evaluation process and help standardize performance metrics across different systems, fostering comparability and improvement.
Conclusion
Retrieval-Augmented Generation (RAG) is a transformative approach to enhancing the capabilities of Large Language Models (LLMs). However, its success relies on robust evaluation and ongoing refinement. As Stefan highlighted in the webinar, the RAG pipeline is complex, encompassing multiple stages from query translation to final response generation. The challenges are significant—ranging from mitigating biases in LLM-as-a-Judge evaluations to ensuring precise retrieval and generating responses that meet user expectations.
The key takeaway is that there is no one-size-fits-all solution for RAG evaluation. Achieving success requires a nuanced, multi-faceted approach that combines diverse evaluation techniques: task-based benchmarks, introspective metrics, open-source evaluation frameworks, and—when feasible—human assessment. Tools like RAGAS, DeepEval, and ARES offer valuable support, but they are not definitive answers. Instead, they represent evolving tools in the ever-advancing landscape of generative AI.
Looking ahead, the future of RAG lies in its adaptability and continuous refinement. As AI systems grow more sophisticated, the ability to evaluate and enhance their performance will be essential for unlocking their full potential. By addressing current limitations and embracing innovative evaluation methods, RAG applications can consistently deliver accurate, contextually relevant, and trustworthy information, driving progress in the field of AI.
Further Reading

Keep Reading

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.