




Knowledge Injection in LLMs: Fine-Tuning and RAG
Large Language Models (LLMs) are impressive in their ability to store and generate vast knowledge. They draw on massive datasets during pre-training, making them experts across various topics. But they do have their limits. For one, their knowledge is static as it isn't updated as time passes. Additionally, while they excel at general knowledge, they often fall short in providing the deep expertise required for specialized fields like healthcare, finance, or law.
Knowledge injection methods such as Fine-Tuning and Retrieval-Augmented Generation (RAG) are utilized to address these limitations. Fine-tuning involves adjusting a model’s weights with task-specific data, while RAG brings in external knowledge during inference, allowing the model to pull in relevant information when needed. In this study, these two approaches are compared across various knowledge-intensive tasks to evaluate their effectiveness in expanding and refining the factual knowledge of LLMs.
RAG consistently outperformed fine-tuning in knowledge-intensive tasks, demonstrating its superior ability to integrate external information. While fine-tuning improved performance over the base model, it was not as competitive as RAG. Additionally, data augmentation proved beneficial for fine-tuning, as exposing models to multiple variations of the same fact during training enhanced knowledge retention.
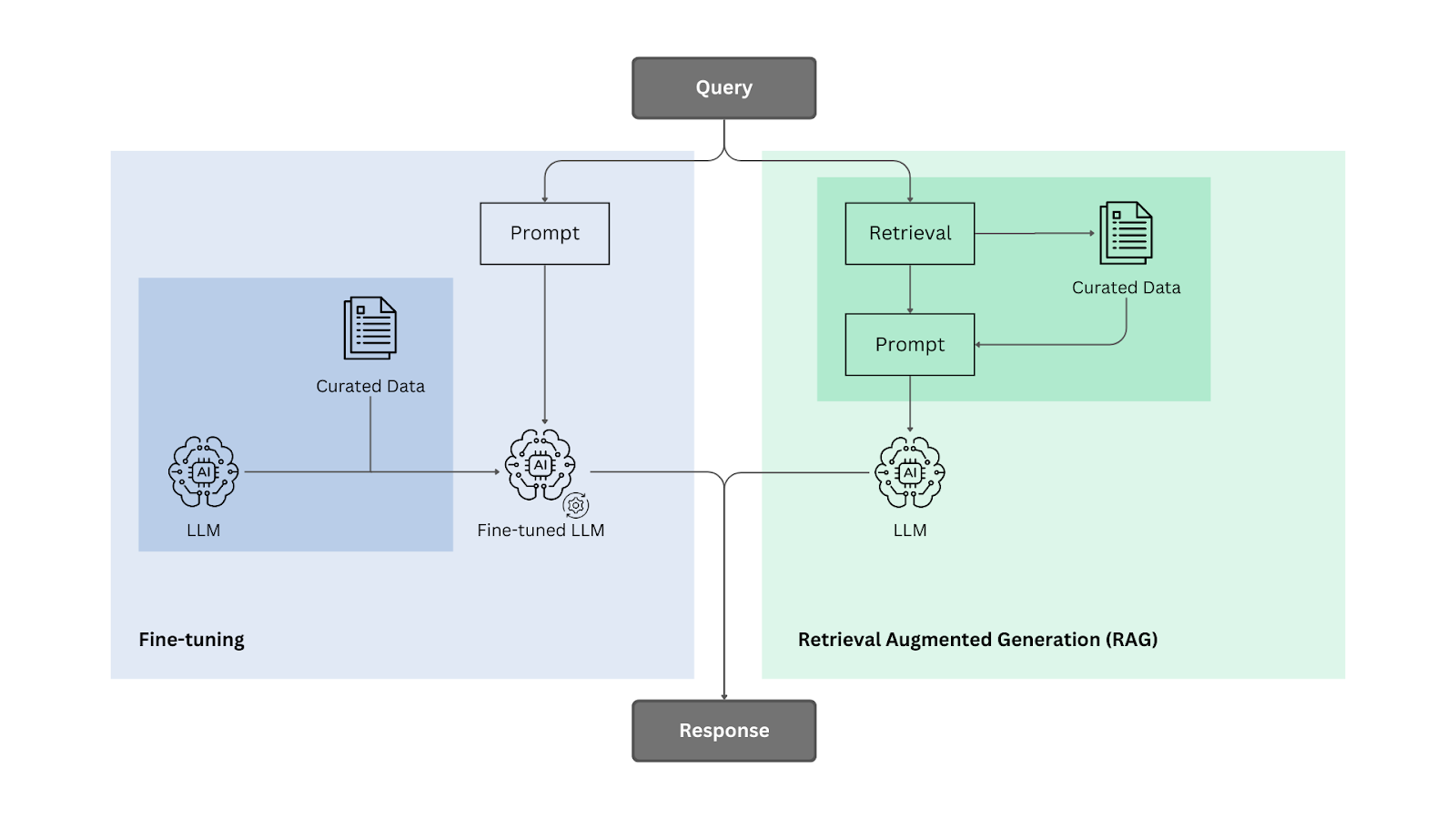
Methodology pipeline of Fine-Tuning and RAG
Let’s take a closer look at the two methods and explore how they stack up against each other when it comes to improving an LLM’s knowledge. To put things in perspective, imagine three students taking a test on a topic they haven’t studied. One had the textbook only during the test, another studied before the test, and the third had no access to materials once the test started. Who do you think would perform best?
Let’s find out!
Please refer to the following paper for a detailed understanding.
Why Do LLMs Generate Factual Errors?
Despite their remarkable fluency and versatility, LLMs are inherently prone to factual errors due to several critical factors, including domain knowledge deficits, outdated training data, and reasoning limitations.
- Domain Knowledge Deficit: LLMs may lack deep expertise in specific domains that were underrepresented during training. For example, a model trained predominantly on general news sources may struggle with highly specialized fields like medicine or law if it hasn’t been fine-tuned on domain-specific data.
- Outdated Information: LLMs are restricted by the cutoff date of their training datasets. Any events, scientific advancements, or cultural shifts that occur after this cutoff will not be incorporated, leading to outdated responses. This is especially problematic in dynamic fields such as healthcare, where a model trained before the COVID-19 pandemic would lack information about pandemic-related health protocols and vaccine developments.
- Immemorization: Some knowledge learned by the model during training may not be retained, particularly when it involves rare facts or less frequently seen patterns in the training data. This issue can hinder the model’s ability to consistently recall less common information across different tasks or inputs.
- Forgetting: Catastrophic forgetting occurs during fine-tuning when a model forgets previously learned information, especially less emphasized facts from the original training. This is a common issue with LLMs and can affect long-term knowledge retention.
- Reasoning Failures: LLMs sometimes fail to correctly apply their knowledge, particularly in complex, multi-step reasoning tasks. For example, LLMs may produce incorrect or incomplete answers when asked to solve advanced math problems or multi-stage logical deductions. These failures are often linked to the model’s difficulty in maintaining logical coherence over longer sequences of thought.
These issues primarily stem from the model's training phase, with catastrophic forgetting being the notable exception that arises post-training during fine-tuning.
Injecting Knowledge into Language Models
Factual errors in Large Language Models (LLMs) are often the result of gaps in the model's knowledge base. To address this, knowledge injection is an important technique that helps refine and expand the model's ability to provide accurate answers.
Knowledge injection refers to the process of modifying or augmenting a language model with additional information. Rather than learning entirely new facts, it biases the model’s predictions toward a specific knowledge domain, improving its performance on knowledge-intensive tasks.
Mathematical Formulation
Let’s now explore the mathematical formulation behind knowledge injection and how it leads to an improvement in model accuracy.
Problem
The research focuses on factual knowledge. If a model knows something, it can consistently answer related questions correctly and distinguish true from false statements.
Here’s how it works mathematically:
Q = {qn}n=1N be a set of N factual questions
Each question qn has L possible answers and C = {cn}n=1N is the set of correct answers for these questions.
M represents the model, which predicts an answer for each question. The model’s predicted answer for a question qn is denoted as M(qn) ∈ {an1 , . . . , anL } , and it belongs to a set of possible answers.
We can evaluate the model’s knowledge by calculating its knowledge score (accuracy), which is the percentage of correct answers the model gives out of all the questions:
LM,Q := #{qn| M(qn) = cn} N .
In this equation:
LM,Q is the model's knowledge score.
The numerator counts how many times the model's answer M(qn) matches the correct answer cn for each question qn.
The denominator is the total number of questions N.
Knowledge Injection
General pre-training alone isn’t enough for many knowledge-intensive tasks. To improve performance, we need knowledge injection.
This can be mathematically represented as follows given a pre-trained model M, a set of questions Q, and an auxiliary knowledge base BQ, we aim to find a function for knowledge injection F such that:
M′ := F(M, BQ) s.t. LM',Q > LM,Q.
In simple terms, we aim to make a new model M′ by applying F, which incorporates the knowledge base BQ into the original model M. The goal is for the new model to perform better by answering more questions correctly.
Accuracy Gain
To see how much the knowledge injection (like fine-tuning or RAG) improved the model, we compare the accuracy before and after adding the extra knowledge. The improvement is calculated using this formula:
(LM`,Q-LM,Q) / LM,Q
Where:
LM,Q is the model’s accuracy before adding new knowledge.
LM`,Qis the model’s accuracy after adding new knowledge.
This formula shows the relative accuracy gain, and how much better the model has gotten after incorporating new information.
Frameworks for Knowledge Injection
Two common frameworks for knowledge injection are fine-tuning (FT) and retrieval-augmented generation (RAG). Fine-tuning adapts the model by training it on domain-specific data, while RAG enhances the model by retrieving relevant information from an external knowledge base during inference.
Fine-Tuning
Fine-tuning is a widely used technique for knowledge injection. In this technique, a pre-trained LLM is further trained on a specialized dataset to internalize specific knowledge or improve its performance on particular tasks. This process allows the model to "adapt" its previously learned knowledge to incorporate new facts, domain-specific terms, and reasoning patterns.
Types of Fine-Tuning
- Supervised Fine-Tuning: Supervised fine-tuning (SFT) requires sets of labeled input-output pairs. One common SFT method is instruction tuning, where the input is a natural language task description, and the output is an example of the desired behavior. Many state-of-the-art LLMs undergo instruction tuning after their pre-training phase. Instruction tuning improves the model's overall quality, with a particular focus on zero-shot and reasoning capabilities. However, instruction tuning does not teach the model new knowledge and is not sufficient for knowledge injection on its own.
Reinforcement Learning Fine-Tuning: Reinforcement learning (RL)-based fine-tuning techniques optimize models by rewarding correct responses and penalizing incorrect ones. Examples include reinforcement learning from human feedback (RLHF), direct preference optimization (DPO), and proximal policy optimization (PPO). These methods are useful for improving the overall quality of responses and behavior. However, like instruction tuning, RL fine-tuning does not necessarily address the breadth of knowledge needed for knowledge injection.
Unsupervised Fine-Tuning: Unsupervised fine-tuning does not require labeled data. A common method is continual pre-training or unstructured fine-tuning, where the process is viewed as a continuation of pre-training. The model is trained in a causal autoregressive manner, predicting the next token. A lower learning rate is typically used to prevent catastrophic forgetting. This approach is effective for injecting new knowledge into the model, as it builds upon the knowledge stored during the pre-training phase. This work uses unsupervised fine-tuning to enhance the model’s capacity to learn new information.
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is a form of in-context learning that goes beyond the static knowledge embedded within LLMs by enabling models to retrieve relevant information from external sources before generating a response. Unlike traditional fine-tuning, which modifies the model's internal weights, RAG relies on external knowledge bases to ground the model’s outputs in real-time data. This approach has the advantage of providing access to up-to-date, domain-specific, and authoritative information, ensuring that the generated text remains accurate and relevant.
RAG models consist of two main components:
- Retrieval Component: This part of the model is responsible for searching external databases, document repositories, or even the web for relevant information based on a user query. Before retrieval, documents are converted into vector embeddings using embedding models and stored in a vector database. During retrieval, the query is converted into an embedding and matched against stored embeddings in the vector database to retrieve the most relevant information. Common vector databases like Milvus enable efficient search across large datasets.
- Generation Component: Once the relevant documents or knowledge are retrieved, the generation component synthesizes the retrieved information into a coherent, contextually appropriate response. This allows the model to integrate real-time information and answer questions with greater accuracy, especially for topics that require the latest knowledge.
Experimental Setup
This section outlines the experiment's setup, detailing the knowledge base, model selection, training setup, and evaluation methods used to assess the models' performance.
Knowledge Base
The evaluation is based on three key components: the MMLU Benchmark, Current Event Task, and Paraphrase Generation tasks.
MMLU Benchmark
Four tasks from the Massively Multilingual Language Understanding (MMLU) benchmark were selected to evaluate LLMs' capabilities on knowledge-intensive tasks. These tasks span subjects like anatomy, astronomy, biology, chemistry, and prehistory. The selection was based on their emphasis on factual knowledge, with minimal reliance on reasoning.
MMLU was chosen as a benchmark due to its broad coverage of factual, multiple-choice questions across various domains, providing a diverse and objective test of a model’s factual understanding. Prehistory tasks were included to evaluate the model’s ability to process factual information from non-modern history. This approach tests the model’s proficiency in understanding and manipulating knowledge in isolation from reasoning processes.
Current Event Task
A new dataset was created by focusing on multiple-choice questions about events that occurred after the models’ training data cutoff. Specifically, the task was centered around "current events" from the USA, covering August to November 2023 and drawn from the relevant Wikipedia indexes.
This approach ensures that the models have not been exposed to these facts during their training, allowing for a direct test of their knowledge injection capabilities and ability to handle up-to-date factual information.
Paraphrase Generation
GPT-4 was used to generate augmentations by providing paraphrased versions of the input data after creating the dataset. The model was instructed to retain the original meaning while rewording the sentences. Each paraphrasing iteration used a different seed to ensure diversity in the generated versions.
For each MMLU task, 240 chunks were selected randomly, and two paraphrases were created per chunk, which was set aside for validation during hyperparameter tuning. Ten paraphrases were generated for each chunk used in the fine-tuning process for the current events dataset.
Model Selection
Llama2-7B, Mistral-7B, and Orca2-7B were chosen to evaluate inference performance across different modeling approaches. This lineup includes a mix of widely used open-source base models and an instruction-tuned model, offering a well-rounded basis for comparison.
Additionally, bge-large-en was selected as the embedding model for the RAG component. This embedding model was state-of-the-art among open-source options, according to the Hugging Face MTEB leaderboard.
Training Setup
The training process includes the following key components:
- Procedure: All models were fine-tuned using an unsupervised training method. The training dataset was divided into chunks, ensuring that each chunk did not exceed a size of 256 tokens. Special tokens
and were used to mark the beginning and end of each chunk.
- Hardware: The models were trained on 4 NVIDIA A-100 GPUs, ensuring the necessary computational resources were available for large-scale fine-tuning.
Hyperparameters:
Learning rates were tested in the following range: 1 × 10-6to 5 × 10-5.
The models were trained for a maximum of 5 epochs with a batch size of 64, selected based on hyperparameter optimization.
Evaluation
The evaluation was conducted using the LM-Evaluation-Harness framework, a popular tool for assessing LLM performance. This framework provides a standardized approach to model evaluation, ensuring consistency across tasks and methods. Models were evaluated in terms of their ability to predict the correct answers to factual questions.
For the experiment, these evaluation approaches are:
- Base Model: The model’s raw performance without any additional knowledge injection.
- Fine-Tuning (FT): The model is fine-tuned on task-specific data to improve its performance on factual knowledge-based questions.
- Retrieval-Augmented Generation (RAG): This method uses an external knowledge base and retrieves relevant information to augment the model’s responses.
- Fine-Tuning + RAG (FT+RAG): A hybrid approach that combines fine-tuning with retrieval-augmented generation, aiming to improve performance by leveraging both knowledge adaptation and retrieval.
In addition to comparing these four approaches, the performance was evaluated in two different settings:
- 0-shot: The model is tested without any prior examples, relying solely on the knowledge it has learned during pre-training and any knowledge injection (fine-tuning or RAG).
- 5-shot: The model is given five examples for each task, providing a context for making predictions. This setting tests the model's ability to generalize from examples in a more practical, real-world scenario.
Comparing the accuracy and performance of the models across these four approaches revealed the impact of knowledge injection, fine-tuning, and retrieval-augmented generation on LLMs' ability to handle knowledge-intensive tasks.
Experiment Results
Now, let's dive into the experimental results across different knowledge bases i.e. MMLU benchmark and current events data, exploring how each approach performed on knowledge-intensive tasks
MMLU Results
Across all tasks, RAG consistently outperformed the base models as seen in terms of the log-likelihood accuracy for all tasks and settings.
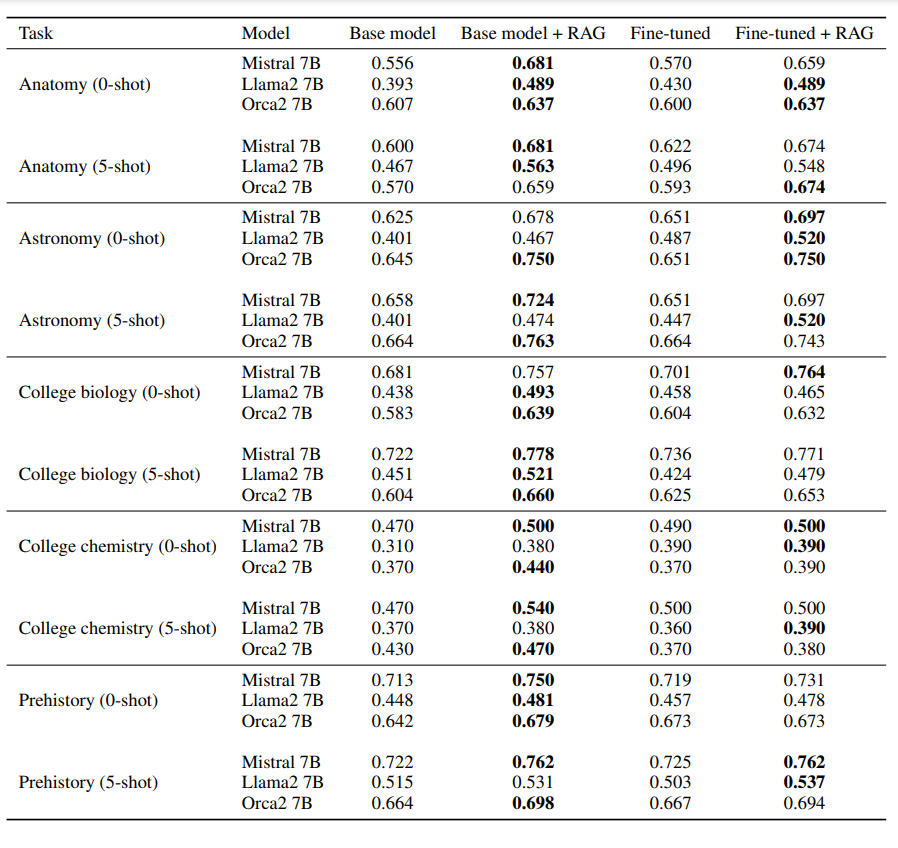
Results for the MMLU datasets in terms of log-likelihood accuracy | Source
Using RAG with the base model as the generator proved superior to fine-tuning alone. In some cases, substituting the base model with a fine-tuned model in the RAG pipeline further improved results. However, the effect was inconsistent and highlighted the inherent instability of fine-tuning. Additionally, five-shot prompting provided a small but consistent boost across all methods.
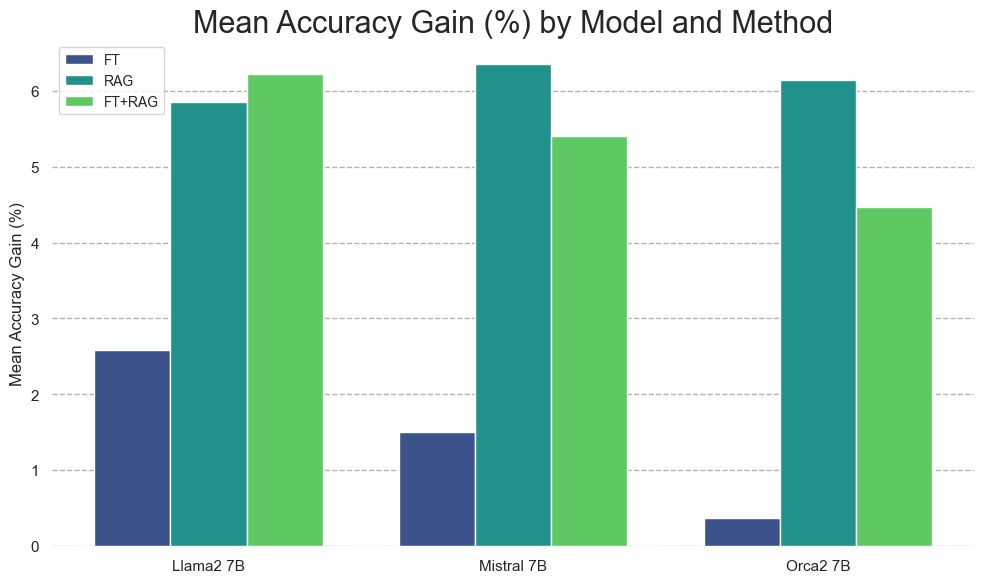
The relative accuracy gain for each knowledge-injection method, averaged (column-wise) across all experiments on the MMLU dataset | Source
Current Event Results
RAG delivered exceptional performance in the Current Events Task thanks to its precise alignment between questions and the auxiliary dataset. While fine-tuning proved beneficial, it fell short of RAG's effectiveness. However, augmenting fine-tuning (FT-par) with multiple paraphrases significantly improved results over the baseline approach (FT-reg).

Current events results. Models that were fine-tuned on the original dataset are labeled as FT-reg, while those trained on the dataset with multiple paraphrases are labeled as FT-par | Source
Fine-Tuning vs. RAG
Results from both the MMLU and Current Events tasks confirm RAG’s superiority over fine-tuning. While fine-tuning enhanced accuracy compared to the base model, it could not match the performance gains from retrieval.
Several factors contribute to this trend:
- Contextual Knowledge Access: Unlike fine-tuning, RAG dynamically retrieves relevant information, ensuring responses are contextually grounded.
- Catastrophic Forgetting: Fine-tuning risks overwriting previously learned knowledge, potentially diminishing the model’s general capabilities.
- Alignment Issues: Fine-tuned models may require additional supervised fine-tuning or reinforcement learning (RLHF) to achieve optimal performance
Key Findings
- RAG Outperforms Base Models: RAG (Retrieval Augmented Generation) consistently outperformed the base models, significantly improving accuracy, especially for knowledge-intensive tasks, by augmenting the model with external data.
- RAG vs. Fine-Tuning (FT): RAG consistently outperformed Fine-Tuning (FT). The combination of RAG and FT showed some improvement when using a fine-tuned model as the generator in the RAG pipeline. Still, results were inconsistent, indicating the inherent instability of fine-tuning compared to RAG.
- 5-shot Boost: Transitioning from 0-shot to 5-shot yielded a small but consistent improvement in performance, with RAG benefiting the most from the added context.
- Data Augmentation Improves Knowledge Retention: The experiments show that paraphrase-based data augmentation leads to a monotonic increase in model accuracy on knowledge injection tasks. Models better comprehend and generalize new knowledge by rephrasing information in multiple ways. As the number of paraphrases increased, model accuracy continued to improve steadily.
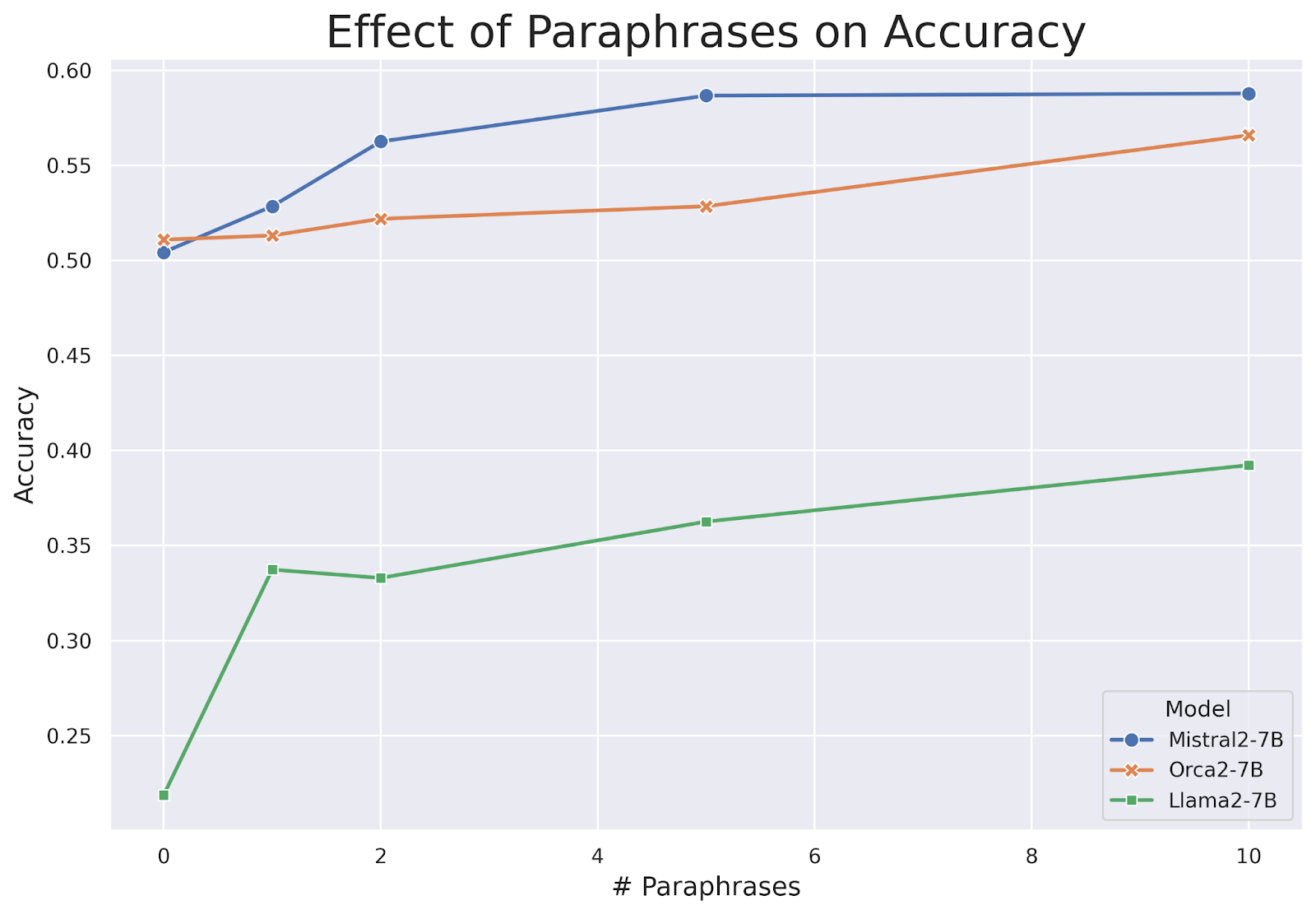
Model accuracy on the current events task as a function of the number of paraphrases | Source
RAG and Vector Databases
RAG (Retrieval Augmented Generation) enhances Large Language Models by integrating retrieved data into responses, improving factual accuracy and contextual relevance.
The Role of Vector Databases in RAG
Vector databases play a crucial role in Retrieval-Augmented Generation (RAG) by enabling efficient storage and retrieval of high-dimensional embeddings. In a RAG system, the retrieval phase depends on identifying the most semantically relevant information from a vast knowledge base, which is where vector databases excel.
These databases index textual or multimodal data as dense vector embeddings, allowing for fast and accurate similarity searches using methods like approximate nearest neighbor (ANN) search. When a query is generated, the vector database retrieves the closest matching embeddings based on cosine similarity or other distance metrics. This ensures that only the most contextually relevant information is passed to the generation model, improving factual accuracy and reducing hallucinations.
Vector databases are particularly valuable in real-time knowledge retrieval for applications such as question-answering systems, chatbots, enterprise search, and recommendation engines.
Milvus/Zilliz as a Vector Database/Cloud Platform
Milvus, an open-source vector database developed by Zilliz, is a powerful solution for managing and querying high-dimensional embeddings in Retrieval-Augmented Generation (RAG) systems. RAG relies on efficient similarity search to retrieve relevant knowledge before generating responses, and Milvus is optimized for large-scale, real-time retrieval tasks.
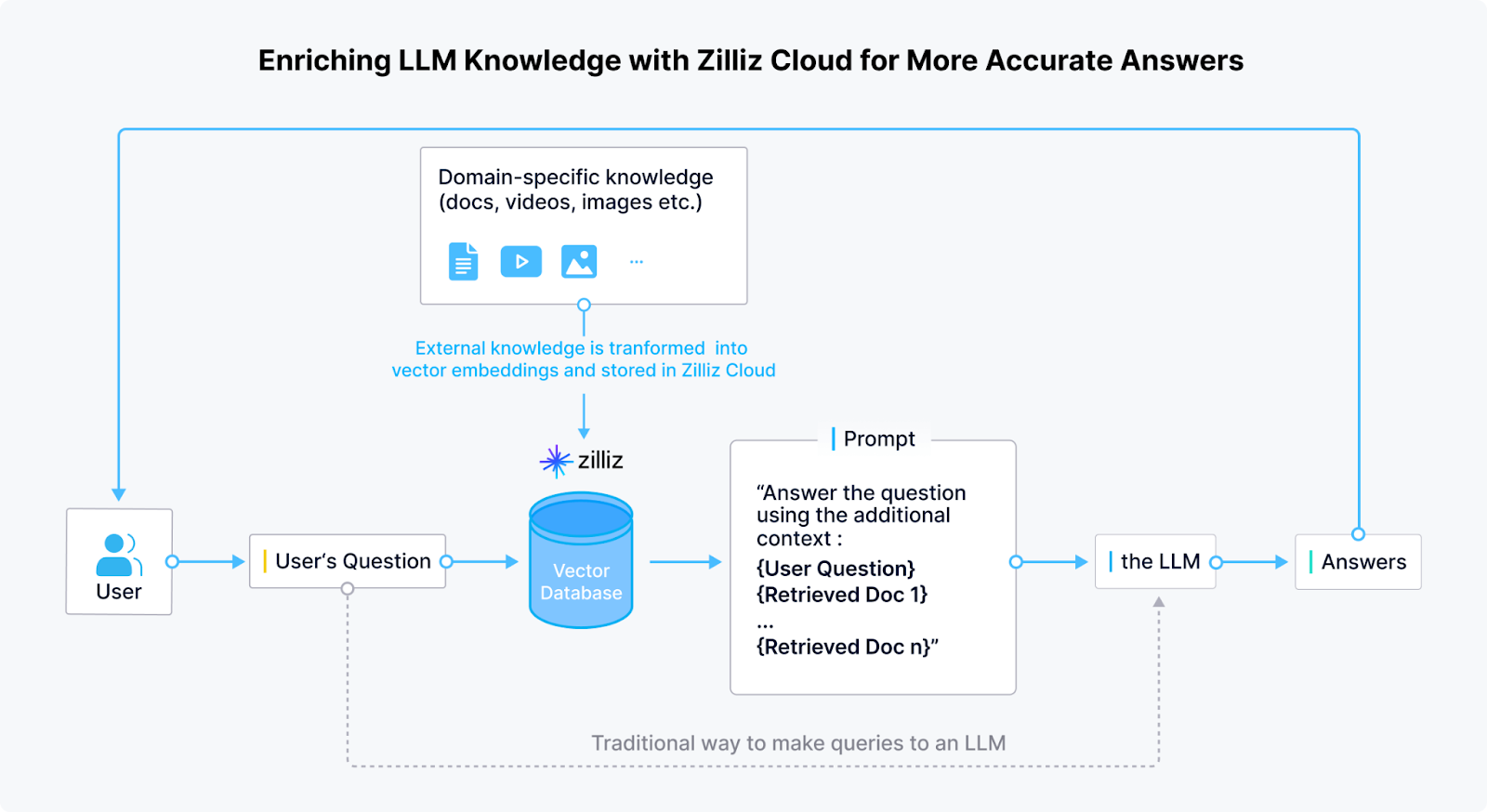
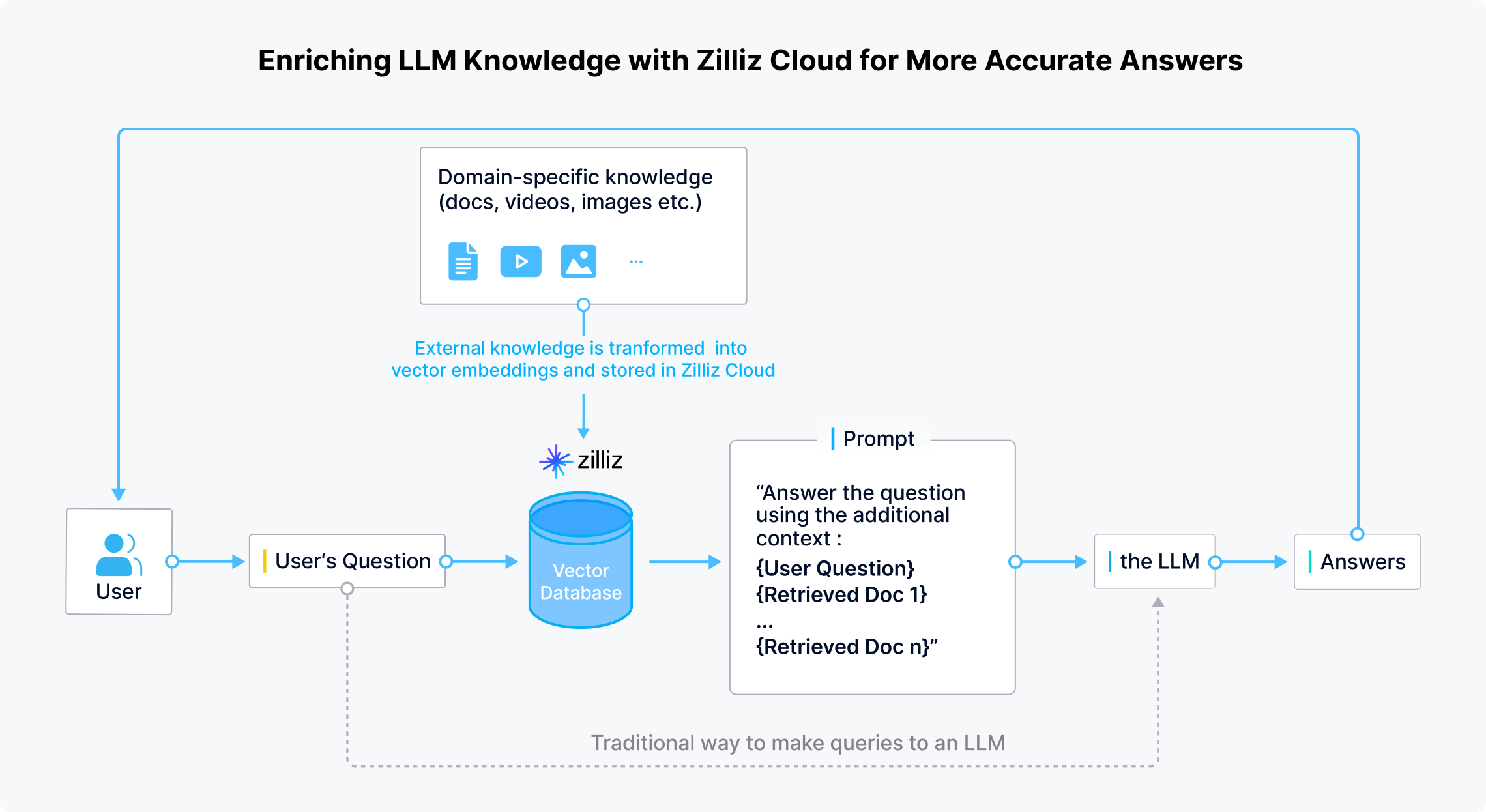
Enriching LLM knowledge with Zilliz cloud for more accurate answers | Source
Milvus enables the storage and indexing of millions or even billions of vector embeddings, allowing RAG models to perform rapid semantic searches across vast knowledge bases. Milvus ensures low-latency retrieval by supporting multiple indexing algorithms. This is critical for applications where real-time information is essential, such as chatbots, search engines, and enterprise AI systems.
Zilliz extends Milvus with cloud-based solutions, making it easier for enterprises to deploy and scale vector search for RAG without managing infrastructure. This cloud-native approach ensures seamless integration with LLMs. It enables organizations to enhance their models with dynamic knowledge retrieval while maintaining performance and scalability.
Potential Future Research Directions
Large Language Models (LLMs) possess vast amounts of knowledge, but their ability to adapt to new, specialized, or unseen information remains a challenge. Fine-tuning and retrieval-augmented generation (RAG) are two prominent approaches for knowledge injection. While fine-tuning can be useful for many applications, RAG has proven to be a more reliable choice for integrating external knowledge.
Several key areas warrant further investigation to enhance our understanding of knowledge injection in LLMs:
- Hybrid Knowledge Integration: Researching combinations of fine-tuning, RAG, and other techniques to improve adaptability. Understanding how these approaches complement each other can lead to more efficient knowledge injection.
- Combining Fine-Tuning Methods: Future research should explore integrating instruction-tuning and reinforcement learning (RL)-based fine-tuning with unsupervised fine-tuning. This could improve knowledge adaptation and retention.
- Evaluating Knowledge Representation in LLMs: Investigating how LLMs internally store and retrieve injected knowledge from a theoretical perspective. A clearer understanding could lead to more interpretable and efficient models.
- Measuring Knowledge in LLMs: Developing new evaluation frameworks beyond empirical approaches to better assess knowledge retention. Establishing standardized benchmarks could improve the comparability of different models.
Further research in these areas will help refine knowledge injection strategies, improving the efficiency and reliability of LLMs in adapting to new information.
Further Resources
Research Paper: Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs

{kind=link}
Keep Reading

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.