




Techniques and Challenges in Evaluating Your GenAI Applications Using LLM-as-a-judge
AI is evolving rapidly, with large language models (LLMs) now adopted across various industries and production environments. As these LLM-powered applications become more widespread, we must ensure their outputs are accurate, reliable, and unbiased. Traditional human evaluation methods often fall short, being too time-consuming and inconsistent to handle the complexity and scale of modern LLMs.
One promising approach to this challenge is using LLMs as judges to evaluate their outputs. By leveraging their extensive training data and contextual understanding, LLMs can provide automated, scalable, and consistent assessments.
In April 2024, Sourabh Agrawal, Co-founder of UpTrain AI, spoke at the Unstructured Data Meetup hosted by Zilliz about the real-world difficulties of implementing LLM-as-a-judge techniques. He discussed key strategies used in both industry and academia to make these evaluations effective and demonstrated how UpTrain AI evaluates GenAI applications.
In this blog, we will recap Sourabh’s key points and explore the practicalities of employing LLMs for evaluation. If you want a deeper dive, we recommend you watch Sourabh’s talk on YouTube.
LLM Evaluation - Why Does It Matter?
LLMs have transformed the way we generate content and build applications. However, despite their power, they can sometimes produce hallucinatory answers due to their limited pre-trained knowledge. One popular technique to mitigate this issue is Retrieval Augmented Generation (RAG), which enhances LLMs by providing external data as context using a vector database like Milvus and Zilliz Cloud (the managed Milvus).
While RAG effectively addresses some of LLMs' shortcomings, deploying these applications in production environments for tangible business value remains complex. It requires incorporating more technologies into the workflow for various purposes, adding complexity to the applications and potential challenges in generating the most accurate and relevant answers. Therefore, we must evaluate the outputs of LLM-powered applications and make sure they are correct, accurate, and of high quality.
What Metrics You Should Use to Evaluate Your GenAI Apps
When evaluating LLMs' performance, it's important to focus on key metrics that offer valuable insights into their capabilities. These metrics serve as benchmarks for measuring effectiveness and guiding improvements. During the meetup, Sourabh Agrawal highlighted four primary metrics for assessing LLM performance and discussed methodologies for evaluating them.
Response Quality: A good response should directly answer the user’s questions, be concise without unnecessary information, and cover all aspects of the question. To evaluate the response quality of your LLM applications, you should check if the output is relevant to the prompt, concise, and complete. To dive deeper, check if your LLM application has correct citations or follows custom instructions.
Context awareness is critical for LLM applications that rely on external data sources, also known as retrieval augmented generation (RAG) applications. To evaluate RAG applications, you should check whether the information retrieved from the vector database is accurate, relevant, and optimally used without hallucination; and whether the LLM correctly understands and uses the retrieved context to generate responses. To dive deeper into this metric, you can also check whether the embedding model within the RAG pipeline is well-tuned.
Conversational Quality: LLM applications should maintain coherence and consistency across all interactions in multi-turn conversations. Evaluations in this category check if the user query is resolved and the LLM appropriately retains context from previous turns, responds logically, and stays on topic throughout the conversation to ensure a smooth and natural dialogue experience. Advanced evaluation methods assess coherence across long-form content such as articles or multi-turn conversations. For example, Sourabh mentioned the LLM should not confuse "football" with "soccer" if the context is American football.
Safety: Safety evaluations check if the LLM is susceptible to jailbreaks or prompt injections that could manipulate its behavior. Safety evaluations also ensure the model’s outputs are appropriate and the system is not misused.
Using LLMs as Judges to Evaluate Your GenAI Applications
Today, various evaluation tools and techniques are available to assess the outputs of your GenAI applications, including human reviews, LLM-as-a-judge methodologies, automated scoring systems, and more. While human reviews are reliable, they often lack scalability and can be inconsistent due to subjective biases. On the other hand, automated scoring systems offer consistency but may not capture the nuanced understanding required for certain types of content.
The LLM-as-a-judge approach systematically assesses the relevance, accuracy, and overall quality of your LLM application’s outputs using the LLM itself or a separate LLM as the "judge." LLMs can deliver automated, scalable, consistent evaluations by leveraging their extensive training data and contextual understanding. This methodology allows developers to standardize the evaluation process, quickly identify areas for improvement, fine-tune their models, and ensure high-quality performance while minimizing human bias.
During the meetup, Sourabh discussed two primary techniques for implementing LLM-as-a-judge evaluations, including prompt-based and tuning-based methods.
Prompt-based Evaluations
Prompt-based evaluations are easy to start and typically leverage closed-source LLM APIs. This approach requires you to prompt the judge LLM with specific criteria for response assessment. Below are the four primary methods for implementing prompt-based evaluations.
Score-based Evaluations: In score-based evaluations, the judge LLM is prompted to provide a score between 1 and 10 for specific aspects of a response, such as relevance or completeness. While easy to implement, this method can be inconsistent due to LLMs' inherent biases.
Classification-based Evaluations: Classification-based evaluations transform the scoring into good, average, or poor categories. This approach reduces variability and improves reliability by providing clear criteria for each category.
Pairwise Comparison: Pairwise comparison presents the judge LLM with two responses and asks it to choose the better one. This method is useful for direct comparisons but can introduce position bias, where the order of responses influences the evaluation.
Ensemble Techniques: Ensemble techniques use multiple judge LLMs or multiple evaluation methods to assess responses. Aggregating the results from various models can mitigate individual biases and improve accuracy. Techniques like majority voting or chain-of-thought prompting are common in ensemble evaluations.
Tuning-Based Evaluations
Tuning-based evaluations leverage open-source LLMs, such as those from HuggingFace, as the judge and fine-tune them for specific evaluation tasks. This method allows for greater control and customization, making it more cost-effective and suitable for specific use cases. By fine-tuning models to act as evaluators, developers can ensure the models are well-suited to their applications' unique requirements.
Challenges Associated with Using LLMs as the Judge
Building reliable evaluations for LLM applications is just as challenging as developing those applications. While leveraging LLMs as judges to assess the outputs of your applications provides scalability and consistency, it also brings forth challenges and complexities that require careful management.
Biases in LLM Evaluations
Order Bias: LLMs can be influenced by the order in which information is presented. For example, if one response is shown at the top and another at the bottom, the model might favor the one at the top. This bias can lead to unfair evaluations.
Egocentric Bias: LLMs often tend to favor their own generated outputs. When asked to judge responses, they might rate their own responses higher than those from other models. This self-preferential treatment can skew results and reduce evaluation fairness.
Length Bias: Some models prefer longer, more detailed responses, while others prefer concise answers. This preference can impact the perceived quality of the response, regardless of its relevance or accuracy.
Consistency Problems
Ensuring that evaluations are consistent across multiple runs is one of the key challenges. Due to their inherent variability, LLMs might produce different scores for the same response in different runs.
Lack of Domain-Specific Knowledge
To provide accurate evaluations, LLMs need to understand the specific domain they are evaluating, including the terminology, context, and nuances of the field. Without this knowledge, evaluations might miss critical aspects of the response.
LLM evaluations must be adaptable to different contexts and user personas. A response that is appropriate in one context might not be in another. Tailoring evaluations to match different user groups' specific requirements and expectations is essential for accurate assessments.
Evaluating Complex Responses
To ensure a thorough and accurate evaluation, it's essential to break down complex responses into smaller, more manageable components. This approach allows for a detailed assessment of each part, enhancing the overall evaluation process. However, it also increases the complexity of the evaluation itself.
Evaluating multi-turn conversations introduces an additional layer of difficulty. The judge LLM must retain context from previous interactions and maintain coherence throughout the dialogue. Addressing this challenge necessitates sophisticated evaluation techniques that effectively manage context retention and ensure seamless conversation flow.
Safety and Security Concerns
LLMs can be vulnerable to prompt injections and jailbreaks, where malicious inputs manipulate the model’s behavior. Detecting and mitigating these security threats is crucial for safe and reliable evaluations.
Cost of Evaluations
Evaluating LLM outputs can be resource-intensive. Balancing the cost of evaluations with the need for accuracy is a significant challenge.
How to Tackle These Limitations?
Since using LLMs as judges to evaluate your LLM applications has limitations, how can we address them? Sourabh shared his strategies during the Unstructured Data Meetup.
Objective Evaluations
Evaluations should be as objective as possible. This strategy helps reduce biases and provides a consistent basis for judging LLM outputs. Developers can create a standard baseline that provides consistent and reliable judgments by establishing clear, measurable evaluation criteria.
Checking for Conciseness
To evaluate conciseness, break down responses into meaningful sub-parts. Each part should be checked individually to see if it answers the user query directly. The final score is then calculated as the ratio of relevant parts divided by the total parts, ensuring a thorough and precise assessment.
Grading Strategy
Sourabh also recommended using a grading system with "YES, NO, MAYBE" options. This approach provides a clearer and more nuanced evaluation compared to a simple binary choice, addressing the edge cases where responses do not fall into the extremes.
Cost-Effective Evaluations
To manage costs, leverage cheaper LLMs as much as possible. Developers can maintain cost efficiency without compromising evaluation quality by using less expensive models for initial evaluations and reserving high-cost models for critical or ambiguous cases.
Domain-Specific Fine-Tuning
Fine-tuning your judge LLM works better than using a general model for specific domains. Fine-tuning models for particular fields, such as legal or medical, ensure that evaluations are more accurate and relevant to the specific context.
Using Evaluations to Drive Improvement: Post-Production
LLM evaluations are important for identifying failure cases and blind spots in LLM applications, especially once they are in production. Sourabh provided best practices for using evaluations to drive continuous improvement post-production.
Run key evaluations to monitor performance as evaluation costs can scale up.
Select failure cases and perform root cause analysis on them. This approach helps you understand why certain responses fail and what can be improved.
Determine whether the issue is related to retrieval, utilization, citation, or unclear user queries. This detailed analysis allows for targeted improvements, ensuring that your LLM applications become more robust and reliable over time.
How to Use UpTrain AI to Evaluate Your LLM Applications
In the end, Sourabh showcased UpTrain AI, an open-source framework for evaluating LLM applications. Using pip, developers can install UpTrain and define evaluation models using API keys from OpenAI or Hugging Face.
The evaluation process with UpTrain AI includes defining datasets with questions, context, and responses and then running evaluations for accuracy, completeness, conciseness, and conversation quality. UpTrain provides scores and explanations, breaking down long responses into subparts and evaluating each for a more objective measure of conciseness.
The UpTrain dashboard logs all data, enabling comparison of models and prompts and monitoring performance. It helps identify failure cases and analyze root causes to pinpoint retrieval, utilization, or citation issues.
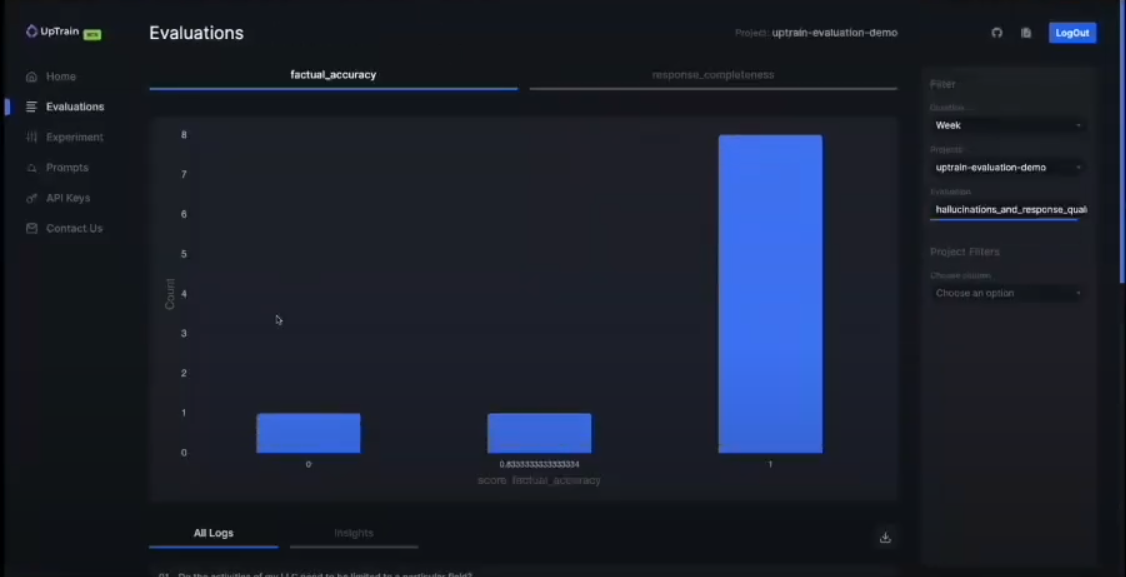 The interface of the UpTrain dashboard
The interface of the UpTrain dashboard
The interface of the UpTrain dashboard
To learn more about UpTrain, you can visit its GitHub project. You can also watch the replay of Sourabh’s talk on YouTube and follow the step-by-step approach he demonstrated during the Unstructured Data Meetup.
Conclusion
Developing reliable and effective LLM applications is not easy and comes with many challenges, including biases, consistency, and lack of domain-specific knowledge. Fine-tuning your LLM for specific tasks or leveraging a vector database like Milvus to provide your LLM with external knowledge are popular methods to fix these issues.
However, it is also essential to employ effective evaluation techniques and tools to ensure that LLM outputs are accurate and meaningful and to refine the LLM applications based on evaluation results. The LLM-as-a-judge approach is a popular technique that can fulfill this role, offering scalability and consistency. Tools like UpTrain AI and many other frameworks like TruLens also play a crucial role in enhancing LLM evaluations, making the process more efficient and reliable.
Further Reading
Learn the following resources if you want a deeper dive into LLM evaluations.
Sourabh Agrawal’s talk on YouTube.
Evaluations for Retrieval Augmented Generation: TruLens + Milvus
Exploring Retrieval Augmented Generation (RAG): Chunking, LLMs, and Evaluations
The Path to Production: LLM Application Evaluations and Observability
How to Evaluate Retrieval Augmented Generation (RAG) Applications
Benchmark Vector Database Performance: Techniques & Insights

Keep Reading

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.