




GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval
Information retrieval is important for many natural language processing (NLP) applications. While traditional lexical methods have been used to search through text content, they suffer from a lexical gap. These methods cannot recognize synonyms or distinguish between ambiguous words.
Dense retrieval methods that map queries and passages into a shared vector space have become popular to address these issues, showing improvement over traditional approaches. However, they require large training datasets and are sensitive to domain shifts. For instance, models trained on MS MARCO perform poorly in COVID-19 literature.
Thus, there is a need to create a method that can effectively adapt dense retrieval models to new domains without requiring large amounts of labeled data. One proposed method is GPL (Generative Pseudo Labeling), an unsupervised domain adaptation technique for dense retrieval models that combines a query generator with pseudo-labeling. GPL uses a T5 model to generate queries for a target domain. It retrieves negative passages using an existing dense retrieval model and uses a cross-encoder to score (query, passage) pairs.
GPL outperforms other domain adaptation methods. It improves performance by up to 9.3 nDCG@10 (normalized Discounted Cumulative Gain at rank 10) over models trained on MS MARCO and up to 4.5 nDCG@10 over QGen (Query generation).
 Figure: GPL for training domain-adapted dense retriever
Figure: GPL for training domain-adapted dense retriever
Figure: GPL for training domain-adapted dense retriever | Source
This article will discuss how GPL addresses the domain adaptation issue, its underlying mechanisms, and the improvements it offers over previous domain adaptation methods. For further details, please refer to the Generative Pseudo Labeling paper.
Why Dense Retrieval Isn't Always Enough
Despite their impressive capabilities, dense retrieval methods have their drawbacks. The most significant issues are the need for large training datasets and their challenges when adapting to new domains. Here's a breakdown of these challenges:
Data Requirements: Dense retrieval models require large amounts of training data to perform effectively. This data requirement poses a significant challenge for applying dense retrieval in specialized domains where large, labeled datasets are unavailable.
Sensitivity to Domain Shifts: Dense retrieval models are extremely sensitive to domain shifts. Their performance decreases when applied to a domain different from the one they were trained on.
Lexical Gap: Traditional lexical methods, an alternative to dense retrieval, suffer from a lexical gap. They cannot recognize synonyms or differentiate between ambiguous words.
Zero-Shot Performance: Dense retrieval models often perform poorly on a given corpus when applied in a zero-shot setting.
Introducing GPL: A Fast and Robust Solution for Domain Adaptation
GPL is an unsupervised domain adaptation technique designed to improve the performance of dense retrieval models when applied to new domains. The method consists of several key steps, including:
Query generation
Negative mining
Pseudo-labeling
Training the dense retriever
Query Generation via T5
The GPL process starts with query generation, where synthetic queries are created for each passage within the target domain. This is done using a pre-trained T5 encoder-decoder model.
The T5 model is trained on large datasets like MS MARCO (Microsoft Machine Reading Comprehension). It generates queries relevant to each passage's content, essentially creating synthetic question-answer pairs.
The number of queries generated per passage is adjusted based on the corpus size to keep the total number of generated queries consistent. This synthetic data creation is important because it provides data for the subsequent training of the dense retriever for the specific target domain.
Negative Mining via Dense Retrieval
The GPL method uses a pre-trained dense retrieval model for each generated query to find the most similar paragraphs within the target corpus. These similar paragraphs are then treated as negative passages, meaning they are irrelevant to the query.
This step is designed to identify "hard negatives." These challenging examples help the model differentiate between similar but irrelevant passages. Two dense retrievers trained on MS MARCO, ‘msmarco-distilbert-base-v3’ and ‘msmarco-MiniLM-L-6-v3’, are used to ensure a diverse set of negative examples.
Finally, one positive and one negative passage is selected from the retrieved passages for each training example.
Pseudo Labeling via Cross-Encoder
The next step includes scoring the (query, passage) pairs using a cross-encoder. Unlike bi-encoders, which map queries and passages independently into a shared vector space. A cross-encoder takes the concatenation of the query and passage and predicts a relevance score using cross-attention.
This step assigns a continuous, fine-grained relevance score to each (query, positive passage) pair and each (query, negative passage) pair. These scores are the pseudo labels. The cross-encoder model used for pseudo labels is ms-marco-MiniLM-L-6-v2. The continuous scores provide more detailed information than binary labels used in other methods.
Training the Dense Retriever with MarginMSE Loss
Finally, the dense retrieval (student dense retriever) model is trained using the generated (query, positive, negative) tuples and the corresponding cross-encoder scores with MarginMSE loss. The goal is to teach the dense retriever to mimic the score margin between the cross-encoder's positive and negative query-passage pairs. The MarginMSE loss function is defined as:
LMarginMSE()= -1Mi=0M-1|i-i|2
Where:
M is the batch size.
i is the corresponding score margin of the student dense retriever:
i= f(Qi)T f(Pi)- f(Qi)f(P_)
- where f is the dense retriever, Qi is the query, Pi is the positive passage and P_ is the negative passage.
- i is the score margin from the cross-encoder:
= CE(Q, P+)-CE(Q, P_)
This loss function helps the model learn a vector space. In this space, queries are closer to relevant passages and farther from irrelevant ones, as defined by the pseudo labels from the cross-encoder. The MarginMSE loss addresses the shortcomings of previous methods like QGen. QGen uses Multiple Negatives Ranking (MNRL) loss, which only considers the coarse relationship between queries and passages.
Experimental Design for Domain-Adapted Dense Retrieval
The setup for evaluating the GPL is intended to assess its effectiveness in adapting dense retrieval models to specific tasks. Here's a breakdown of the key components of the setup:
Datasets
Two datasets are used: one for the source domain and one for the target domain.
- Source Domain Data: MS MARCO passage ranking dataset is used as the source domain data. This dataset consists of 8.8 million passages and 532.8K query-passage pairs labeled as relevant. The models are trained on MS MARCO and then adapted to a target domain using the GPL method.
- Target Domain Datasets: Six domain-specific text retrieval datasets from the BeIR benchmark are used to evaluate the domain adaptation capabilities of GPL. The number These datasets represent a range of specialized domains and include:
FiQA (financial domain)
SciFact (scientific papers)
BioASQ (biomedical Q&A)
TREC-COVID (scientific papers on COVID-19)
CQADupStack (12 StackExchange sub-forums)
Robust04 (news articles)
These datasets differ in:
Sizes: Variation in corpus sizes.
Query and passage lengths: Each dataset has distinct characteristics.
Relevance labels: The number of relevant passages per query varies.
Some datasets were modified for efficient training and evaluation. For example:
- BioASQ: Irrelevant passages were removed to reduce the corpus size.
Baselines
Several baseline models were included for comparison:
Zero-shot models: These models are trained on MS MARCO or PAQ datasets and evaluated on target datasets without any domain adaptation. A BM25 lexical search system is also included as a baseline.
Previous domain adaptation methods: UDALM and MoDIR are included as baselines representing prior approaches to domain adaptation.
Pre-training-based domain adaptation methods: These methods include pre-training the dense retrievers on the target corpus and then training the model on the MS MARCO dataset. Different pre-training methods, such as CD, SimCSE, CT, MLM, ICT, and TSDAE were used.
Generation-based domain adaptation: QGen models are trained with in-batch negatives and hard negatives. Additionally, TSDAE pre-training combined with QGen is included.
Training
The DistilBERT model is used for all the experiments with a maximum sequence length of 350 with mean pooling and dot-product similarity.
QGen models are trained for 1 epoch, with a batch size of 75.
GPL models are trained for 140k steps, with a batch size of 32.
Pre-training methods such as TSDAE and MLM models were trained for 100K training steps with a batch size of 8.
Evaluation Metric
The performance of the models is evaluated using nDCG@10 (normalized Discounted Cumulative Gain at rank 10). It evaluates the quality of a ranking by considering the relevance of retrieved items. It gives more weight to highly relevant documents appearing at the top of the ranked list.
GPL's Effectiveness and Performance in Domain Adaptation
The GPL method was evaluated against several baselines, and its performance was analyzed under different conditions. The evaluation is done using nDCG@10, which measures the relevance of the top 10 results of a ranked list.
GPL's Overall Performance
GPL significantly outperforms other domain adaptation methods on almost all datasets tested. Specifically, GPL improves over QGen, a previous state-of-the-art method, by up to 4.5 nDCG@10 points on the BioASQ dataset. It also shows an average improvement of 2.7 nDCG@10 points across all datasets.
Combining TSDAE (Transformer-based Sequential Denoising Auto-Encoder) pre-training with GPL (TSDAE + GPL) delivers exceptional results. This approach sets a new state-of-the-art performance, averaging 52.9 nDCG@10 points. Notably, it offers an average improvement of 7.7 points over the baseline out-of-the-box MS MARCO model.
 Figure: Evaluation results using nDCG@10
Figure: Evaluation results using nDCG@10
Figure: Evaluation results using nDCG@10 | Source
Comparison with Baselines
To understand the context of GPL's strong performance, let's compare it to various baseline approaches and alternative domain adaptation methods.
Zero-Shot Models
Zero-shot models trained on MS MARCO perform poorly on domain-specific datasets compared to simple BM25 lexical searches. For example, a state-of-the-art dense retrieval model achieves an MRR@10 (Mean Reciprocal Rank at 10) of 33.2 points on the MS MARCO dataset. However, it performs poorly on the six selected domain-specific retrieval datasets.
TSDAE pre-training on MS MARCO, followed by supervised learning on MS MARCO, performs slightly weaker than the zero-shot MS MARCO model.
Previous Domain Adaptation Methods
UDALM greatly harms performance compared to MLM (Masked Language Modeling) pre-training, with an average decrease of 12.2 nDCG@10 points. This is because direct MLM training conflicts with supervised training.
MoDIR performs on par with the zero-shot MS MARCO model on some datasets but performs much weaker on others.
Pre-Training Based Domain Adaptation
Pre-training on the target corpus with TSDAE, MLM, and ICT (Inverse Cloze Task) can improve performance compared to the zero-shot MS MARCO model. TSDAE is the most effective method, outperforming the zero-shot baseline by an average of 4.0 nDCG@10 points. CD, CT, and SimCSE fail to adapt to the domains and perform worse than the zero-shot model.
Generation-Based Domain Adaptation
GPL outperforms QGen by up to 4.5 points (on BioASQ) and 2.7 points on average. TSDAE-based domain-adaptive pre-training combined with GPL (TSDAE + GPL) further improves performance on all datasets. It achieves a new state-of-the-art result of 52.9 nDCG@10 points.
Re-ranking with Cross-Encoders
Cross-encoders perform well in a zero-shot setting and significantly outperform dense retrieval approaches, but they have a significant computational cost at inference. TSDAE and GPL can narrow but not fully close the performance gap with cross-encoders. The TSDAE + GPL model would be preferable in a production setting due to the much lower computational costs at inference.
Influence of Training Steps
The performance of GPL starts to saturate after around 100K training steps. TSDAE pre-training consistently improves performance throughout the training stage.
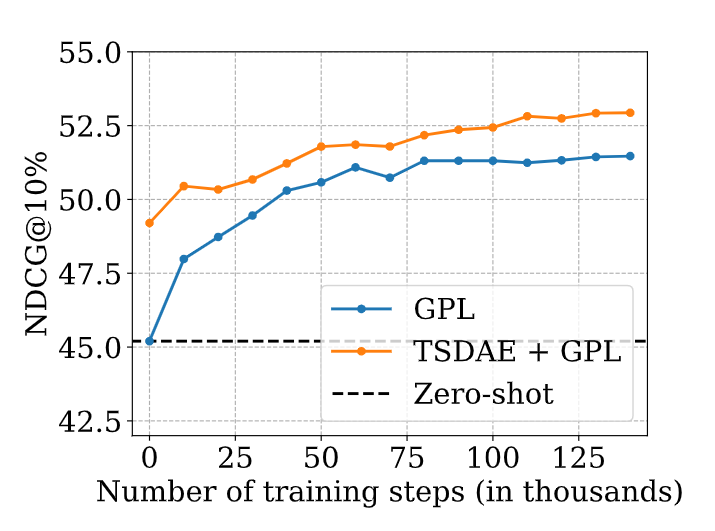 Figure: Influence of the number of training steps on performance
Figure: Influence of the number of training steps on performance
Figure: Influence of the number of training steps on performance | Source
Influence of Corpus Size
GPL can outperform the zero-shot baseline with more than 10K passages, and the performance saturates after 50K passages. However, QGen falls behind the zero-shot baseline for each corpus size.
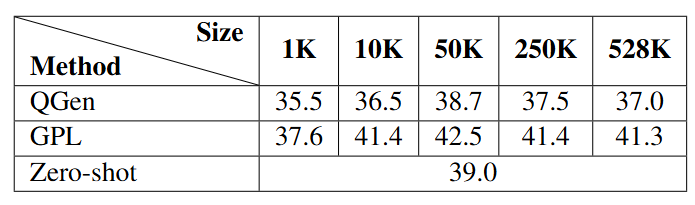 Figure: Influence of corpus size on performance
Figure: Influence of corpus size on performance
Figure: Influence of corpus size on performance | Source
Robustness Against Query Generation
Smaller corpora, such as SciFact and FiQA, require a higher number of generated queries per passage than the larger Robust04 corpus to achieve optimal performance. Additionally, GPL is more robust for low-quality queries than QGen. Even when the generated queries have almost no relationship to the passages, GPL still performs well.
 Figure: Influence of the number of generated QPPs on the performance
Figure: Influence of the number of generated QPPs on the performance
Figure: Influence of the number of generated QPPs on the performance | Source
Sensitivity to initialization
GPL is less sensitive to the choice of the initialization checkpoint. MS MARCO training has a relatively small effect on GPL's performance, with an average 0.3-point difference. On the other hand, QGen is highly dependent on the choice of the initialization checkpoint, showing a 1.9-point difference.
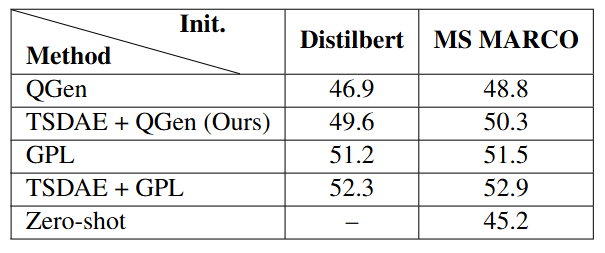 Figure: Influence of initialization checkpoint on performance
Figure: Influence of initialization checkpoint on performance
Figure: Influence of initialization checkpoint on performance | Source
Performance on Full BeIR
On the full 18 BeIR datasets, GPL consistently improves the performance over the zero-shot model. It achieves an average rank of 5.2. TSDAE + GPL achieves an average rank of 4.2. When building on top of the strong zero-shot model TAS-B, GPL yields significant performance gains by up to 21.5 nDCG@10 points (on TREC-COVID) and 4.6 nDCG@10 points on average. This TAS-B + GPL model performs the best overall, achieving an average rank equal to 3.2.
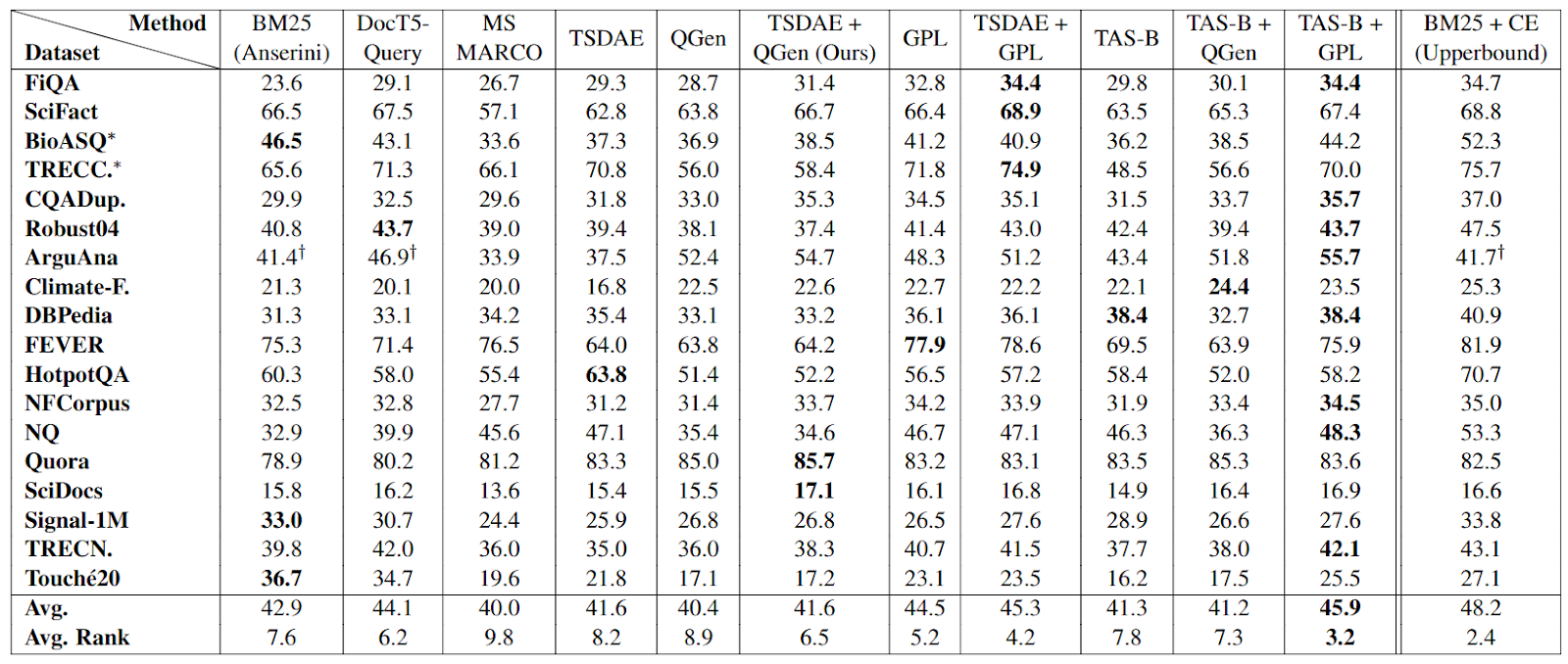 Figure: Performance on all the original 18 BeIR datasets
Figure: Performance on all the original 18 BeIR datasets
Figure: Performance on all the original 18 BeIR datasets | Source
Implications for Generative Pseudo Labeling
The GPL method has several important implications for information retrieval. These include:
Better Domain-Specific Search: GPL improves search results in specialized areas like finance and science. It outperforms previous methods by effectively adapting to new domains.
Less Need for Labeled Data: GPL adapts models without requiring labeled data from the target domain, using unlabeled passages instead. This reduces the cost and time needed to develop retrieval systems.
Handles Poor Queries: The method is effective for poorly generated queries because a cross-encoder assigns low scores to irrelevant (query, passage) pairs. This ensures that the dense retriever does not learn from bad queries.
Uses Hard Negatives Well: GPL uses a cross-encoder to generate fine-grained relevance scores, making it effective for training with hard negatives. This leads to more robust training.
Efficient and Practical: GPL can be combined with other techniques like TSDAE to achieve even better results. It is more efficient than computationally heavy methods like cross-encoders.
Works Across Many Datasets: GPL shows consistent improvement across 18 datasets, highlighting its general applicability. The method also improves performance when combined with a powerful model like TAS-B.
GPL for Enhanced Semantic Search in Vector Databases
Generative Pseudo Labeling (GPL) is a method that can directly enhance the performance of vector databases such as Milvus by improving the effectiveness of dense retrieval models. These databases rely on dense vector representations for semantic search. GPL helps adapt these models to new domains without requiring labeled data, addressing performance degradation caused by domain shifts.
GPL uses a pre-trained model to generate synthetic queries for unlabeled data, retrieves similar passages, and employs a cross-encoder to score (query, passage) pairs. Ultimately, it trains a dense retrieval model that is more suitable for the target domain.
This method is particularly valuable because it provides a way to improve semantic search in vector databases, which store data as dense vectors. The negative mining process in GPL further refines the training by identifying similar but irrelevant passages, leading to better semantic search distinctions.
Milvus supports various types of searches, such as Approximate Nearest Neighbor (ANN) search, filtering search, range search, hybrid search, and full-text search. Techniques like GPL that improve the underlying vector representations can enhance its performance.
Conclusion and Future Research Direction
GPL is a novel method for unsupervised domain adaptation of dense retrieval models using pseudo-labels generated by a cross-encoder. It significantly outperforms existing domain adaptation methods, particularly when combined with TSDAE pre-training, while demonstrating robustness to query quality variations.
Fine-grained pseudo-labels from the cross-encoder are a key advantage of GPL, allowing the model to learn more effectively than coarse-grained labels used in other methods. When combined with TSDAE pre-training, GPL achieves a better balance between accuracy and computational efficiency than computationally intensive cross-encoders.
Future Research Direction
There are several important avenues for further research aimed at improving domain-adaptation techniques. These include:
Simplification of Training Pipeline: The GPL requires a relatively complex training setup. Future research could focus on simplifying this pipeline to make it easier to use for practical applications.
Exploring other pre-training methods: Future work could explore combining GPL with other pre-training methods beyond TSDAE to see if further performance improvements can be achieved.
Domain-Specific Tuning: Explore ways to fine-tune GPL models for individual domains to improve performance within specific areas. For example, it found that different datasets need different amounts of generated queries per passage.
Investigating alternatives to cross-encoders: The cross-encoder is an important component of GPL, but it is computationally intensive. Exploring other ways to create similarly effective pseudo-labels could further reduce costs.
Adapting GPL to low-resource languages: GPL's success in domain adaptation suggests that it might be beneficial to apply this method to low-resource languages where labeled training data is limited.
Combining GPL with other adaptation methods: It could be interesting to investigate whether combining GPL with other domain adaptation methods can further enhance performance. This includes methods such as adversarial training or multi-task learning.
Further Resources
GPL paper: https://arxiv.org/pdf/2112.07577
Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
Unlocking the Power of Many-Shot In-Context Learning in LLMs
LLM-Eval: A Streamlined Approach to Evaluating LLM Conversations
Dense Vectors in AI: Maximizing Data Potential in Machine Learning

Keep Reading

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.