




Функции активации в нейронных сетях

Функции активации в нейронных сетях
 Функции активации.png
Функции активации.png
Недавние достижения в области искусственного интеллекта (ИИ ) были невероятными, особенно в распознавании изображений, обработке естественного языка (NLP) и беспилотных автомобилях. Ключевым фактором, способствующим этим достижениям, является способность искусственных нейронных сетей оценивать сложные нелинейные функции, часто присутствующие в реальных данных. Эта способность в основном объясняется функциями активации, которые вносят нелинейность в нейронные сети, позволяя им моделировать сложные взаимосвязи и закономерности.
Давайте подробно разберем функции активации, их назначение, как они работают и почему они важны для нейронных сетей.
Что такое функции активации?
Функции активации — это математические функции, используемые в нейронных сетях для определения выхода нейрона и внесения нелинейности в модель. Они применяются к входам узлов (нейронов), фундаментальных единиц нейронной сети, чтобы получить выход узла. Нейронная сеть вычисляет взвешенную сумму входов, добавляет смещение, а затем пропускает эту сумму через функцию активации, которая выдает модифицированное значение. Это значение передается на следующий слой сети или становится конечным выходом.
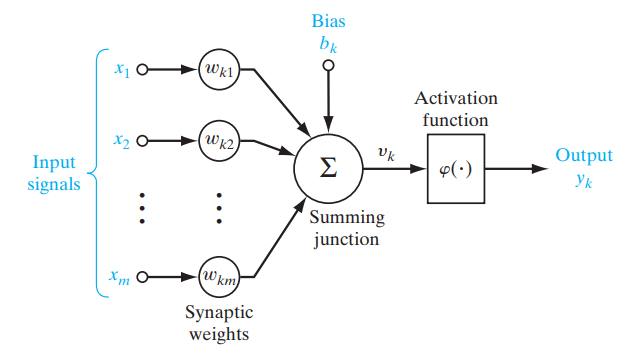 Рисунок- Роль функции активации в нейронной сети. .png
Рисунок- Роль функции активации в нейронной сети. .png
Рисунок: Роль функции активации в нейронной сети. | Источник
Почему нелинейность важна?
Чтобы понять, почему функции активации необходимы, важно знать, почему линейные модели имеют ограничения. Линейная модель представляет прямолинейную зависимость между входами и выходами. Она хорошо работает в простых задачах, но не справляется там, где данные более сложны и имеют нелинейные закономерности.
Нелинейность позволяет нейронным сетям создавать границы решений, которые не являются прямыми линиями. Поэтому нейронные сети могут понимать нелинейные закономерности в данных, которые не могут быть представлены линейными моделями.
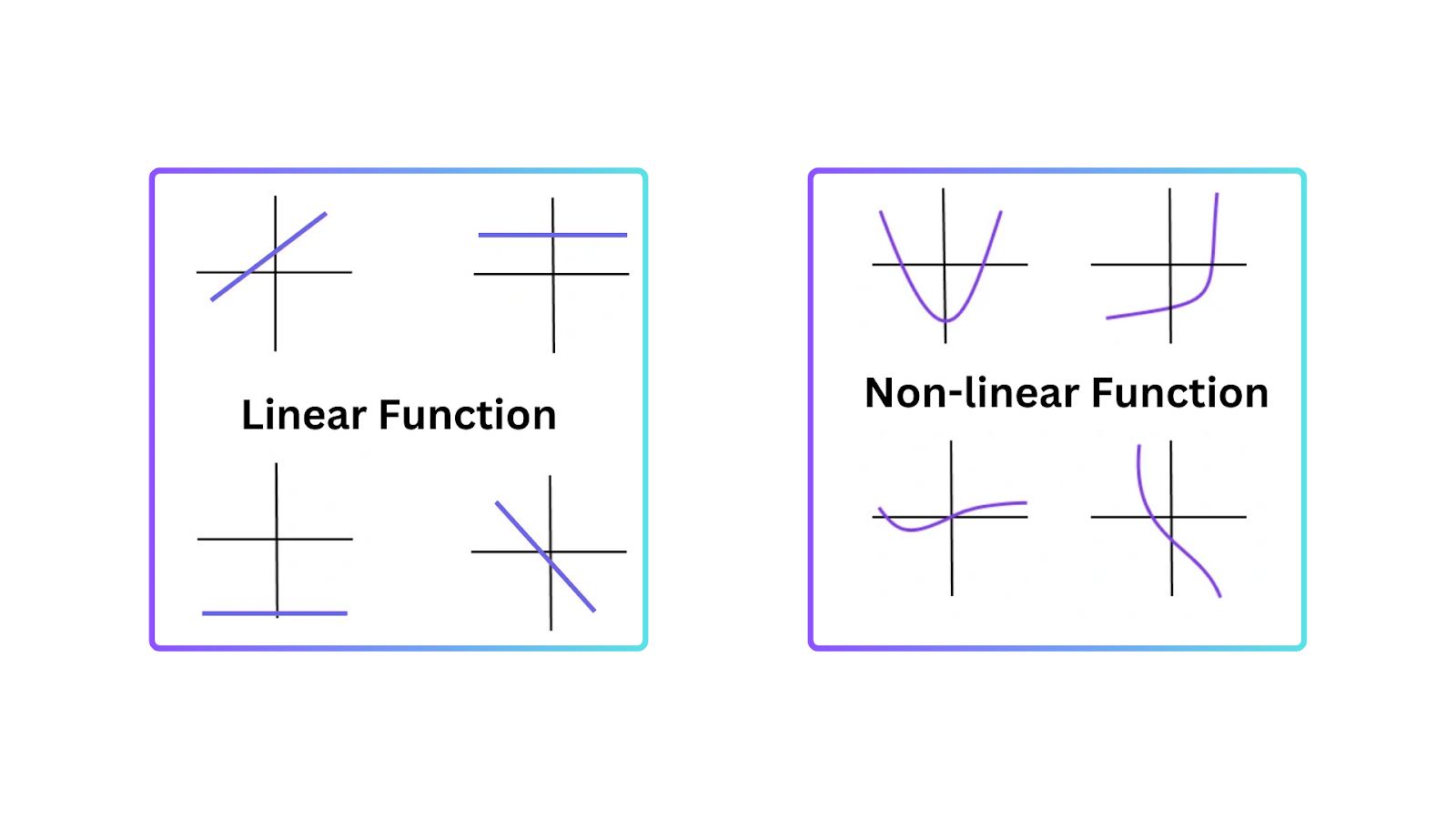 Рисунок- Типы функций.png
Рисунок- Типы функций.png
Рисунок: Типы функций
Как работают функции активации
Теперь, когда мы представили функции активации, давайте посмотрим, как эти функции работают математически, чтобы преобразовать входной сигнал в выходной сигнал, часто в диапазоне между 0 и 1 или -1 и 1. В каждом нейроне нейронной сети данные проходят следующие этапы:
Вход: Каждый нейрон в нейронной сети получает один или несколько входов. Эти входы могут поступать из исходных данных, подаваемых в сеть (в случае входного слоя), или из выходов нейронов предыдущего слоя.
Расчет взвешенной суммы: Входы умножаются на соответствующие веса, чтобы определить их важность. Затем взвешенные входы суммируются, и возвращается одно значение, известное как взвешенная сумма.
Применение функции активации: После расчета взвешенной суммы она пропускается через функцию активации, и результат функции активации становится выходом нейрона.
Этот процесс повторяется в каждом нейроне по слоям сети, чтобы изменять данные более сложными способами.
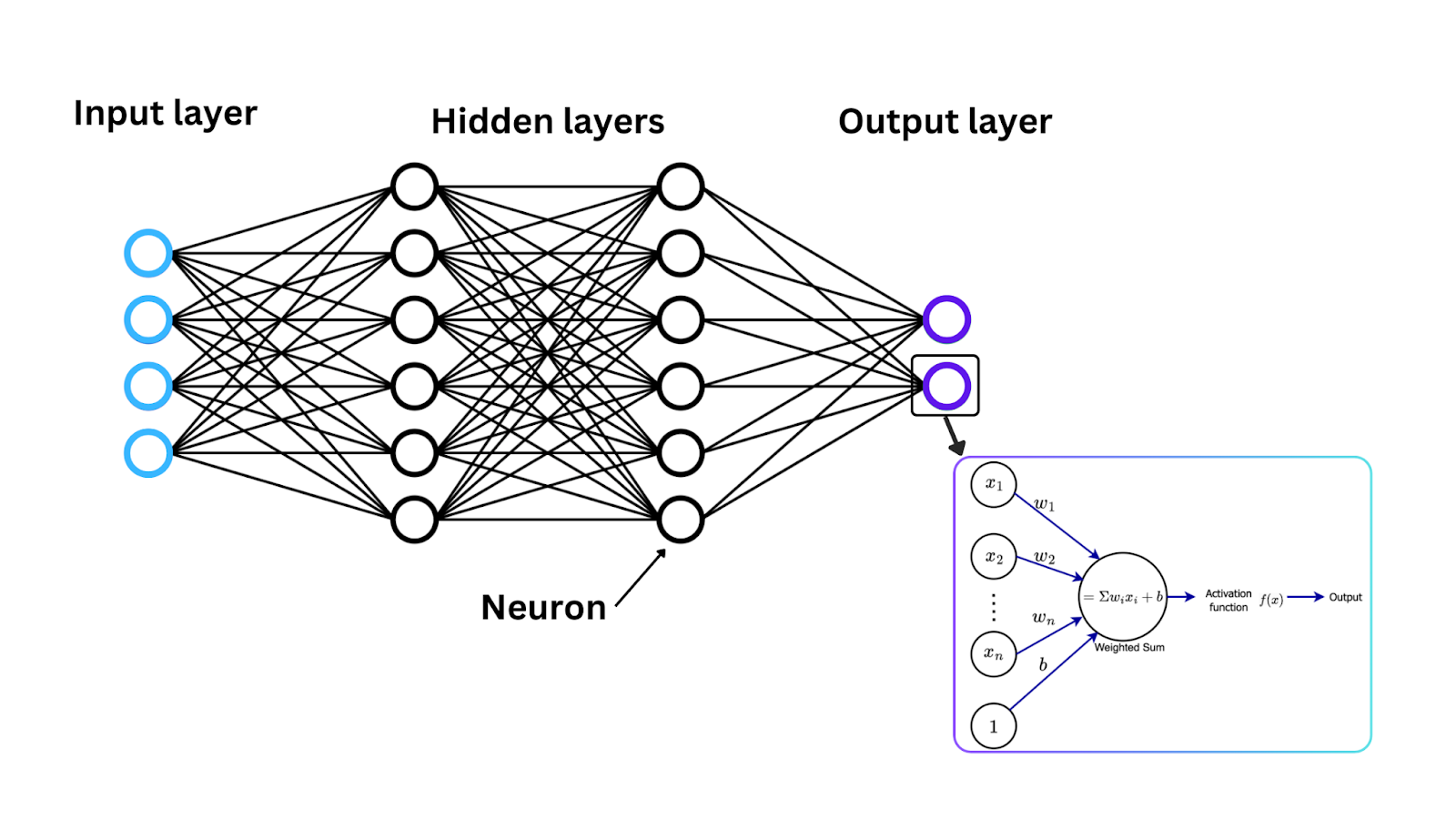 Рисунок- Архитектура нейронной сети, функция активации и обновления весов нейронов. .png
Рисунок- Архитектура нейронной сети, функция активации и обновления весов нейронов. .png
Рисунок: Архитектура нейронной сети, функция активации и обновления весов нейронов.
Нейронные сети используют разные типы функций активации. У каждой функции есть свои сильные стороны, и она лучше подходит для конкретных задач. Например, сигмоидная функция оптимальна для задач бинарной классификации, softmax полезна для многоклассового предсказания, а ReLU помогает преодолеть проблему исчезающего градиента.
Выбор правильной функции активации ускоряет обучение и повышает производительность. Теперь давайте рассмотрим некоторые распространенные функции активации:
Сигмоидная активация
Активация ReLU (Rectified Linear Unit)
Активация Tanh (гиперболический тангенс)
Активация Leaky ReLU
Сигмоидная активация
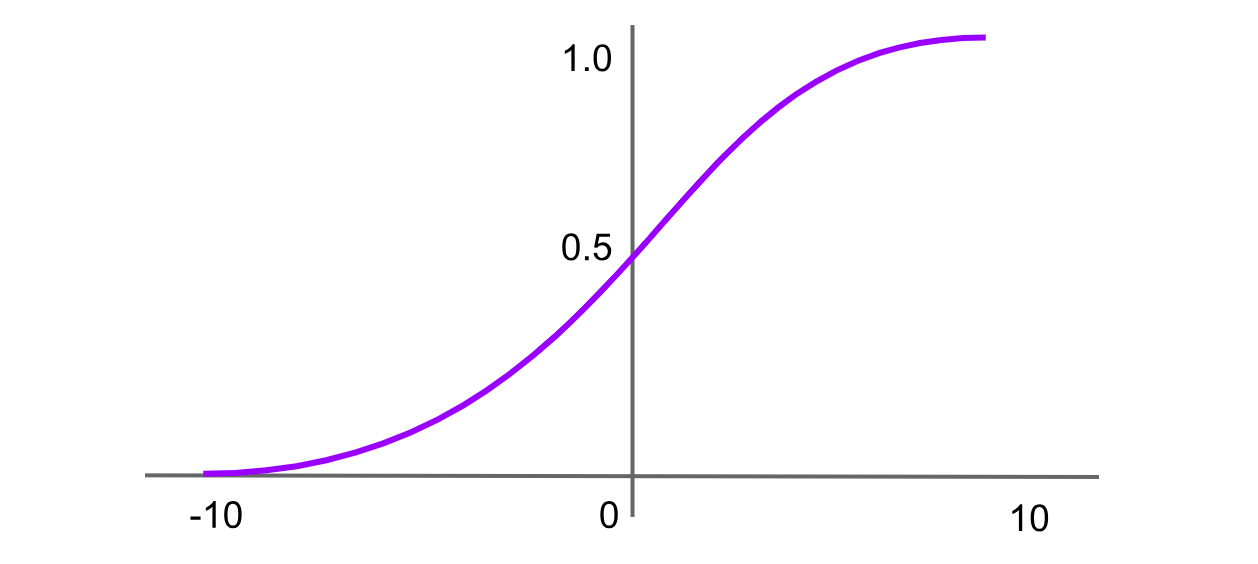 Figure- Sigmoid activation function.png
Figure- Sigmoid activation function.png
Рисунок: Сигмоидная функция активации
Сигмоидная функция, также известная как логистическая функция, является одной из самых ранних и наиболее широко известных функций активации. Она отображает любое входное значение в диапазон от 0 до 1, образуя S-образную кривую. Формула сигмоидной функции:
Sigmoid = σ(x) = 1 / (1 + exp(-x))
Ниже приведен код для определения сигмоидной функции в Python.
import numpy as np
def sigmoid_function(x):
z = (1/(1 + np.exp(-x)))
return z
Сигмоидные функции полезны для моделей, в которых нам нужно предсказывать вероятность в качестве выходного значения. Например, в задачах бинарной классификации мы хотим, чтобы выход интерпретировался как вероятность от 0 до 1.
Однако у Sigmoid есть проблема исчезающего градиента. Во время обратного распространения ошибки (когда сеть обучается, обновляя веса) градиенты sigmoid становятся очень малыми, что вызывает медленное обучение в более глубоких слоях.
Активация Softmax
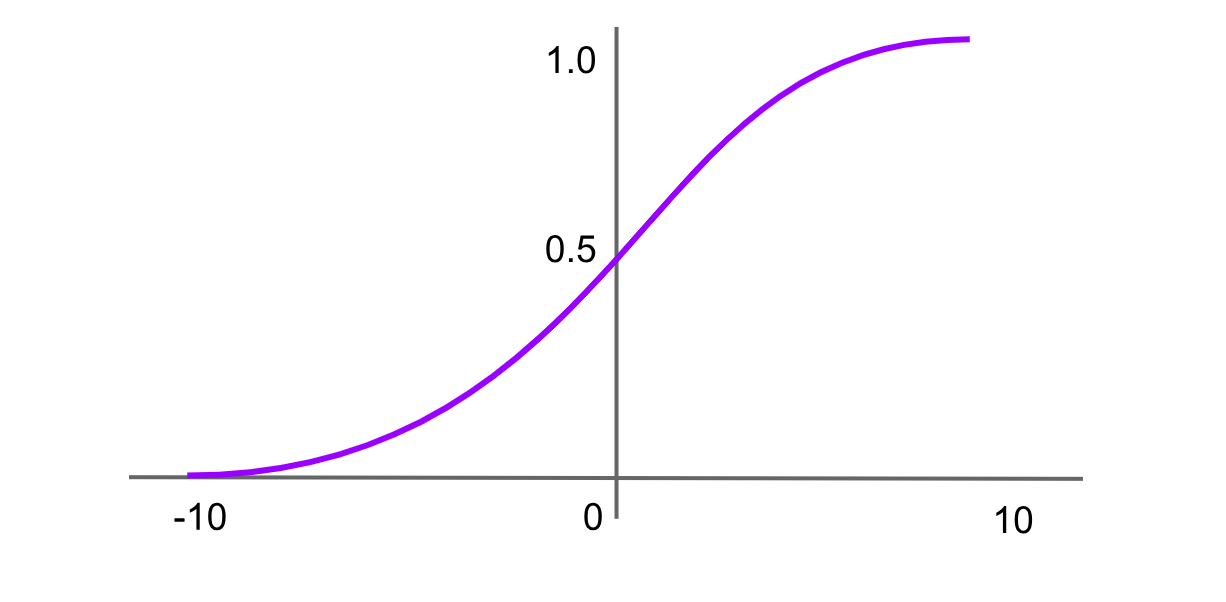 Figure- Softmax activation function.png
Figure- Softmax activation function.png
Рисунок: Функция активации Softmax
Функция softmax обычно используется в выходном слое нейронных сетей для задач многоклассовой классификации. Она принимает на вход вектор действительных чисел и нормализует его в распределение вероятностей по классам. Каждое выходное значение находится между 0 и 1, а сумма всех выходных значений равна 1. Формула функции softmax:
Softmax(x)=f(xi)= exp(x) / sum(exp(x))
Давайте реализуем это на Python.
def softmax_function(x):
z = np.exp(x)
z_ = z/z.sum()
return z_
Однако Softmax может быть вычислительно затратной, особенно в больших сетях, поскольку требует вычисления экспонент и их нормализации по всем выходным значениям.
Активация ReLU (Rectified Linear Unit)
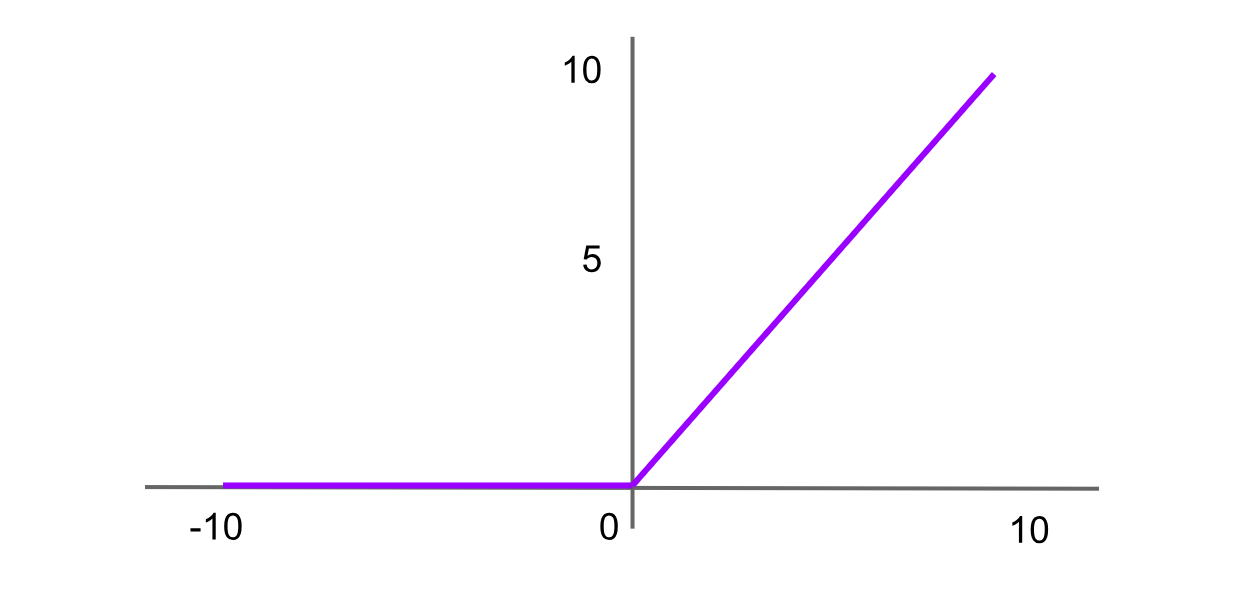 Figure- ReLU activation function.png
Figure- ReLU activation function.png
Рисунок: Функция активации ReLU
ReLU — одна из наиболее широко используемых функций активации в продвинутых нейронных сетях. Она возвращает 0 для любого отрицательного входного значения, а для положительных значений возвращает само значение. Формула функции ReLU:
ReLU = f(x) = max(0,x)
Ниже приведена функция Python для ReLU:
def relu_function(x):
if x<0:
return 0
else:
return x
ReLU используется в скрытых слоях нейронных сетей, особенно в задачах компьютерного зрения. Она вычислительно эффективна, поскольку не содержит операций экспоненты или деления. По сравнению с sigmoid она также меньше подвержена проблеме исчезающего градиента. Однако у ReLU есть один недостаток — проблема “умирающего ReLU”. Если нейрон постоянно выдает ноль для всех входных данных, он становится неактивным и больше не может участвовать в обучении.
Активация Tanh (гиперболический тангенс)
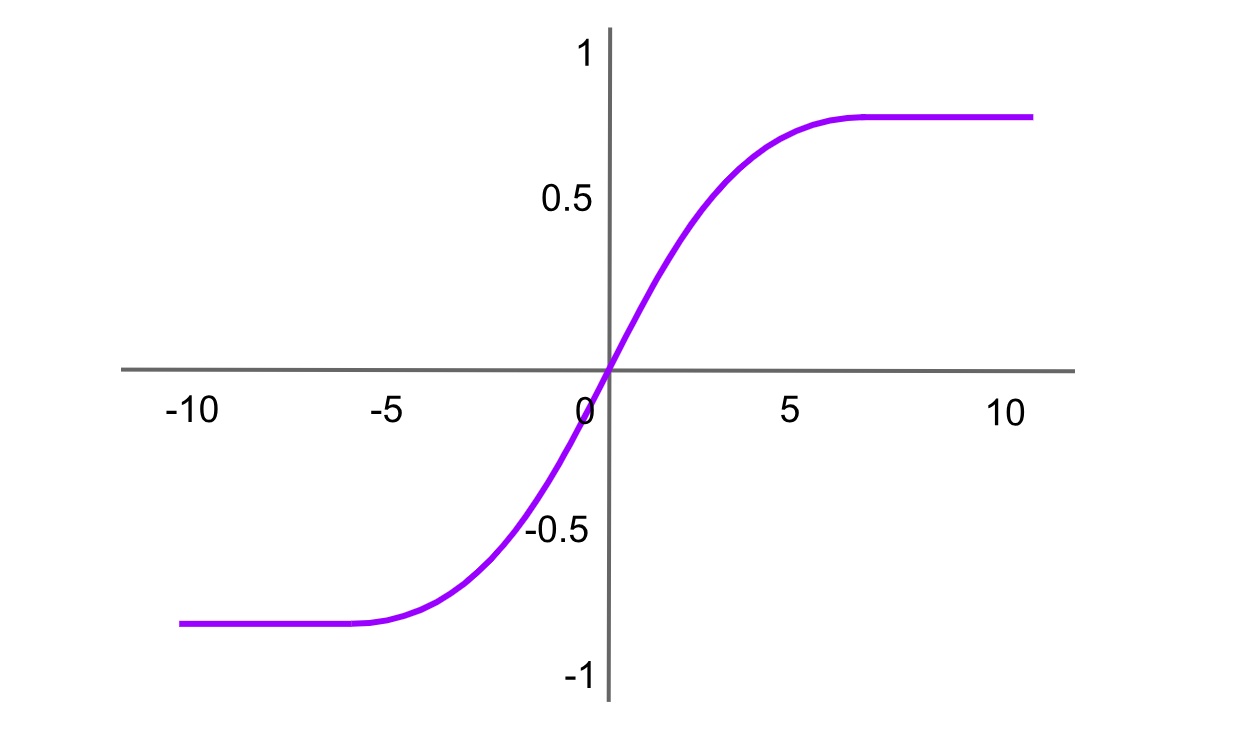 Рисунок- Функция активации Tanh .png
Рисунок- Функция активации Tanh .png
Рисунок: функция активации Tanh
Гиперболическая тангенциальная функция похожа на сигмоидную функцию, но выдает значения в диапазоне от -1 до 1. Формула функции Tanh:
tanh(x)= f(x)= 2 / (1+exp (−2x ))−1
Или
tanh(x)= f(x)=2sigmoid(2x)-1
Вот соответствующий код на Python:
def tanh_function(x):
z = (2/(1 + np.exp(-2*x))) -1
return z
Гиперболический тангенс используется в скрытых слоях нейронных сетей, особенно в задачах обработки естественного языка (NLP). Он имеет некоторые сходства с сигмоидной функцией, но обладает преимуществом центрирования относительно нуля, что может ускорить обучение в определенных сетях. Однако, как и сигмоидная функция, tanh также подвержен проблеме исчезающего градиента.
Активация Leaky ReLU
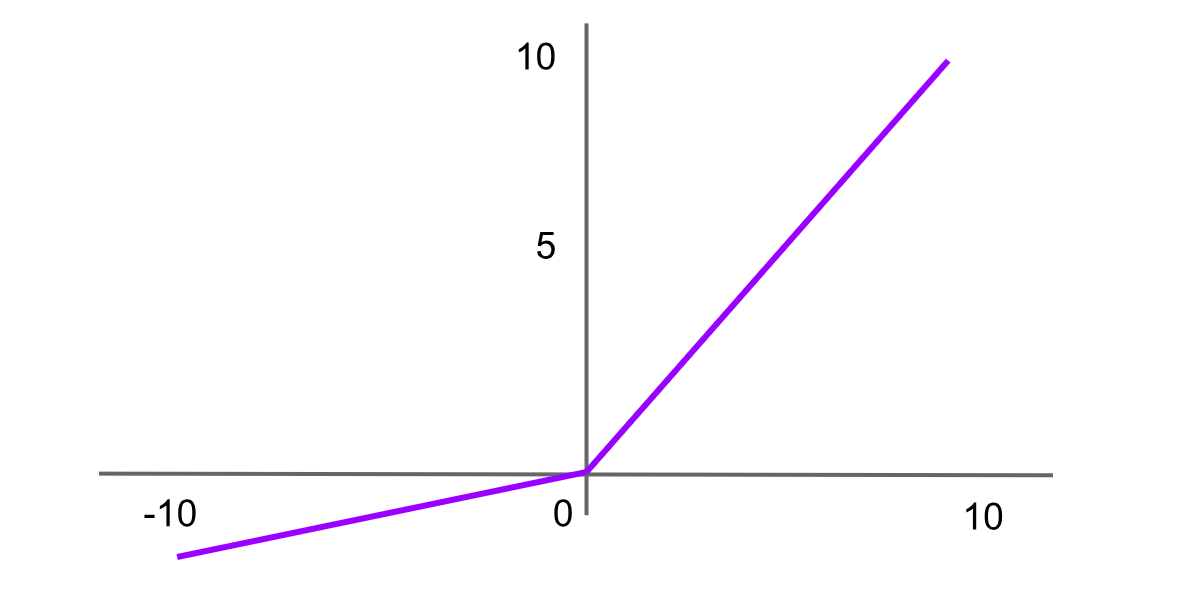 Рисунок- Функция активации Leaky ReLU .png
Рисунок- Функция активации Leaky ReLU .png
Рисунок: функция активации Leaky ReLU
Leaky Rectified Linear Unit, или Leaky ReLU, — это вариант ReLU, разработанный для решения проблемы “умирающего ReLU” путем введения небольшого наклона для отрицательных значений вместо плоского наклона. Это помогает нейронам продолжать обучение, а не становиться постоянно неактивными. Формула функции Leaky ReLU:
Leaky ReLU = f(x)=max(αx,x)
Здесь 𝛼 α — небольшая положительная константа (например, 0.01), обеспечивающая выдачу нейроном небольшого отрицательного значения вместо нуля для отрицательных входных данных. Поскольку Leaky ReLU является вариантом ReLU, код на Python можно реализовать с небольшим изменением.
def leaky_relu_function(x):
if x<0:
return 0.01*x
else:
return x
Сравнение
Чтобы получить более лучшее понимание функций активации, полезно сравнить их с другими ключевыми компонентами нейронных сетей:
Функции активации и функции потерь
Функции активации определяют, как нейроны в сети реагируют на входящие сигналы. Они применяются к выходам нейронов (или слоев), чтобы ввести нелинейность, которая помогает сети понимать закономерности и взаимосвязи в данных.
С другой стороны, функции потерь используются для определения того, насколько хорошо предсказания нейронной сети соответствуют фактическим целевым значениям (истинным значениям). Они вычисляют ошибку между предсказанным выходом и фактическими результатами. Кроме того, алгоритмы оптимизации корректируют веса сети во время обучения, чтобы минимизировать эту ошибку. Функция потерь включает:
Среднеквадратичная ошибка (MSE) обычно используется для задач регрессии.
Кросс-энтропийная потеря используется для задач классификации.
Функции активации и нормализация
Функции активации управляют тем, как данные перемещаются от одного слоя к другому и как нейроны "срабатывают" на основе входных данных.
Однако нормализация, такая как Batch normalization, помогает сделать обучение более эффективным. Она работает путем изменения распределения входных данных слоя, чтобы ускорить обучение сети и предотвратить исчезающие или взрывающиеся градиенты. Batch normalization нормализует входные данные каждого слоя так, чтобы они имели согласованные среднее значение и дисперсию, и помогает упростить сходимость сети. Другие методы нормализации включают:
Layer normalization: Нормализует по каждому слою.
Instance normalization: Обычно используется в обработке изображений, она нормализует каждый экземпляр отдельно.
Преимущества и проблемы функций активации
Функции активации дают нейронным сетям несколько преимуществ, но также создают проблемы, которые необходимо решать. Сначала обсудим преимущества функций активации.
Нелинейность: Самое важное преимущество функций активации заключается в том, что они вводят нелинейность в сеть. Это помогает сетям улавливать нелинейные закономерности в данных и идеально подходит для таких задач, как распознавание изображений и понимание естественного языка.
Диапазон выходных значений: Функции активации, такие как sigmoid и softmax, ограничивают выходные значения определенным диапазоном (0–1 для sigmoid и между -1 и 1 для tanh). Это значительно упрощает понимание выходных значений, особенно в задачах классификации.
Эффективные вычисления: Некоторые функции, например ReLU, вычислительно эффективны, что позволяет сетям масштабироваться и применяться к большим наборам данных.
Теперь обсудим проблемы функций активации.
Проблема исчезающего градиента: она часто встречается в глубоких нейронных сетях, главным образом при использовании функций активации, таких как sigmoid и tanh. Во время обратного распространения градиенты могут становиться очень малыми по мере прохождения через несколько слоев сети, что приводит к медленной сходимости сети и мешает эффективному обучению.
Взрывающиеся градиенты: Взрывающиеся градиенты — это проблема, при которой накапливаются большие градиенты ошибок, что приводит к очень большим обновлениям весов моделей нейронных сетей в процессе обучения. Это делает модель нестабильной и неспособной обучаться на обучающих данных.
Выбор функции: Выбор оптимальной функции активации для задачи или нейронной сети может быть сложным и обычно требует некоторых экспериментов. Это зависит от типа проблемы, которую мы пытаемся решить.
Варианты использования функций активации
Функции активации являются важными компонентами различных архитектур нейронных сетей, выполняющих разные задачи. Вот некоторые ключевые применения:
Классификация изображений: Convolutional Neural Networks (CNN) используют активацию ReLU в своих скрытых слоях для обработки пиксельных данных и softmax в выходном слое для многоклассовой классификации.
Обработка естественного языка (NLP): Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) и Transformers используют активации tanh или ReLU в своих скрытых слоях для обработки последовательных данных.
Генеративные модели: Generative Adversarial Networks (GANs) обычно используют ReLU или LeakyReLU в сети-генераторе для введения нелинейности и создания реалистичных выходных данных, а sigmoid — в сети-дискриминаторе.
Несколько фреймворков глубокого обучения, включая TensorFlow и PyTorch, предоставляют широкий набор встроенных функций активации и реализаций для создания собственных.
Часто задаваемые вопросы о функциях активации
- Что такое функция активации?
Функции активации — это фундаментальные строительные блоки нейронных сетей, которые позволяют им изучать сложные закономерности во входных данных. Они преобразуют входной сигнал узла (нейрона) в выходной сигнал, который затем передается на следующий слой нейронной сети.
- Почему используется функция активации ReLU?
Функция активации ReLU вводит нелинейность в нейронную сеть, что помогает уменьшить проблему исчезающего градиента во время обучения модели машинного обучения.
- Какие функции активации используются чаще всего?
ReLU, Leaky ReLU, Softmax и Swish — популярные функции активации.
- Для чего используется функция активации?
Основная цель функции активации — преобразовать суммарный взвешенный вход узла в выходное значение, которое затем передается на следующий скрытый слой или используется как итоговый выход.
- Можно ли использовать несколько функций активации?
Да, в разных слоях нейронной сети часто используются разные функции активации. Например, стандартная конфигурация может использовать активацию ReLU в скрытых слоях и softmax в выходном слое для задачи многоклассовой классификации.
Дополнительные ресурсы
- Что такое функции активации?
- Как работают функции активации
- Сравнение
- Преимущества и проблемы функций активации
- Варианты использования функций активации
- Часто задаваемые вопросы о функциях активации
- Дополнительные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно