




10 фреймворков LLM с открытым исходным кодом, которые разработчики не должны игнорировать в 2025 году
2024 год стал знаменательным для [больших языковых моделей (БЯМ)] (https://zilliz.com/glossary/large-language-models-(llms)), и сейчас, когда мы вступаем в 2025 год, динамика не подает признаков замедления. От GPT-4 и Gemini мультимодальные возможности до адаптивных систем ИИ в реальном времени, LLM больше не просто передовые - они необходимы. На них работают чат-боты, поисковые системы, инструменты для создания контента и даже автоматизация рабочих процессов, с которыми, как мы раньше думали, может справиться только человек.
Но вот в чем дело: наличие мощного LLM - это только половина успеха. Создание масштабируемых, эффективных и готовых к производству приложений LLM может оказаться непростой задачей, и именно здесь на помощь приходят фреймворки LLM. Они упрощают рабочие процессы, повышают производительность и легко интегрируются с существующими системами, помогая разработчикам раскрыть весь потенциал этих моделей с меньшими усилиями.
В этом посте мы расскажем о 10 фреймворках LLM с открытым исходным кодом, которые разработчики ИИ не могут игнорировать в 2025 году. Эти фреймворки - секретное оружие, помогающее разработчикам масштабировать, оптимизировать и внедрять инновации быстрее, чем когда-либо. Если вы готовы повысить уровень своих ИИ-проектов, давайте погрузимся в работу!
LangChain: Обеспечение многоэтапных рабочих процессов ИИ с учетом контекста
LangChain - это фреймворк с открытым исходным кодом, предназначенный для упрощения разработки приложений на основе больших языковых моделей (LLM). Он упрощает построение рабочих процессов, объединяющих LLM с внешними источниками данных, API или вычислительной логикой, позволяя разработчикам создавать динамичные, учитывающие контекст системы для таких задач, как разговорные агенты, анализ документов и обобщение.
Ключевые возможности
Составляемые конвейеры: LangChain позволяет легко соединять в цепочку несколько вызовов LLM и внешних функций, обеспечивая сложные многоэтапные рабочие процессы.
Готовые цепочки: LangChain предлагает предварительно сконфигурированные цепочки, организованные сборки компонентов, предназначенные для выполнения конкретных задач более высокого уровня. Эти готовые цепочки упрощают запуск проектов.
Утилиты для проектирования: Включает инструменты для создания, управления и оптимизации подсказок, предназначенных для выполнения конкретных задач.
Управление памятью: Предлагает встроенные возможности для сохранения контекста разговора во время взаимодействия, что позволяет создавать более персонализированные приложения.
LangChain поддерживает связь со сторонними API, векторными базами данных, LLM и различными источниками данных. В частности, интеграция LangChain с векторными базами данных, такими как Milvus и Zilliz Cloud, еще больше увеличивает его потенциал. Milvus - это высокопроизводительная векторная база данных с открытым исходным кодом для управления и запроса векторов встраивания миллиардного масштаба. Она дополняет возможности LangChain, обеспечивая быстрый и точный поиск нужных данных. Разработчики могут использовать эту интеграцию для создания масштабируемых систем Retrieval-Augmented Generation (RAG), в которых Milvus извлекает контекстно-релевантные документы. LangChain использует генеративную модель для получения точных и глубоких результатов. Для получения дополнительной информации ознакомьтесь с приведенными ниже ресурсами:
LlamaIndex: Подключение LLM к различным источникам данных
LlamaIndex - это фреймворк с открытым исходным кодом, который позволяет большим языковым моделям (LLM) эффективно получать доступ к различным источникам данных. Он упрощает получение, структурирование и запрос неструктурированных данных, облегчая создание передовых приложений ИИ, таких как поиск документов, обобщение и чат-боты, основанные на знаниях.
Ключевые возможности
Коннекторы данных: Предоставляет надежный набор коннекторов для получения структурированных и неструктурированных данных из различных источников, таких как PDF-файлы, базы данных SQL, API и векторные хранилища.
Инструменты индексирования**: Позволяют разработчикам создавать пользовательские индексы, включая структуры на основе деревьев, списков и графов, для оптимизации запросов и поиска данных.
Оптимизация запросов: Предлагает усовершенствованные механизмы формирования запросов, позволяющие получать точные и контекстно-значимые ответы.
Расширяемость: Высокая модульность, позволяющая легко интегрироваться с внешними библиотеками и инструментами для расширения функциональности.
LLM-оптимизированный фреймворк: Разработан для работы с LLM, обеспечивая эффективное использование вычислительных ресурсов для крупномасштабных задач.
LlamaIndex интегрирован с различными специально разработанными векторными базами данных, такими как Milvus и Zilliz Cloud, для поддержки масштабируемых и эффективных рабочих процессов RAG. При этом Milvus выступает в качестве высокопроизводительного бэкенда для хранения и запроса векторов встраивания, а LlamaIndex структурирует и организует полученные данные для обработки LLM. Такая комбинация позволяет разработчикам получать наиболее релевантные данные и обеспечивает LLM более точными, учитывающими контекст результатами. Для получения дополнительной информации ознакомьтесь с приведенными ниже ресурсами:
Haystack: Оптимизация конвейеров RAG для готовых к производству приложений ИИ
Haystack - это Python-фреймворк с открытым исходным кодом, предназначенный для облегчения разработки приложений на базе LLM. Он позволяет разработчикам создавать комплексные ИИ-решения путем интеграции LLM с различными источниками данных и компонентами, что делает его пригодным для решения таких задач, как RAG, поиск документов, ответы на вопросы и генерация ответов.
Ключевые возможности
Гибкие конвейеры: Haystack позволяет создавать модульные конвейеры для таких задач, как поиск документов, ответы на вопросы и обобщение. Разработчики могут комбинировать различные компоненты для создания рабочих процессов, отвечающих их специфическим потребностям.
Архитектура Retriever-Reader: Сочетает ретриверы для эффективной фильтрации документов с читателями (например, LLM) для создания точных и контекстно-зависимых ответов.
Агностичность к бэкендам: Поддерживает множество бэкендов векторных баз данных, включая Milvus и FAISS, обеспечивая гибкость в развертывании.
LLM Integration: Обеспечивает бесшовную интеграцию с языковыми моделями, позволяя разработчикам использовать предварительно обученные и тонко настроенные модели для решения различных задач.
Масштабируемость и производительность: Оптимизирован для работы с крупными массивами данных и высокопроизводительными запросами, подходит для корпоративных приложений.
В марте 2024 года Haystack выпустил Haystack 2.0, представив более гибкую и настраиваемую архитектуру. Это обновление позволяет создавать сложные конвейеры с такими функциями, как параллельное ветвление и зацикливание, улучшает поддержку LLM и агентного поведения. Новый дизайн подчеркивает общий интерфейс для хранения данных, обеспечивая интеграцию с различными базами данных и векторными хранилищами, включая Milvus и Zilliz Cloud. Такая гибкость обеспечивает удобный доступ к данным и управление ими в конвейерах Haystack, поддерживая разработку масштабируемых и высокопроизводительных приложений ИИ. Для получения дополнительной информации ознакомьтесь с приведенными ниже ресурсами:
Haystack GitHub: https://github.com/deepset-ai/haystack
Интеграция: Haystack и Milvus
Учебник: Retrieval-Augmented Generation (RAG) with Milvus and Haystack
Учебник: Построение конвейера RAG с помощью Milvus и Haystack 2.0
Dify: Упрощение разработки приложений с использованием LLM
Dify - это платформа с открытым исходным кодом для создания приложений искусственного интеллекта. Она сочетает в себе Backend-as-a-Service и LLMOps, поддерживая основные языковые модели и предлагая интуитивно понятный интерфейс оркестровки подсказок. Dify предоставляет высококачественные движки RAG, гибкий фреймворк для агентов ИИ и интуитивно понятный рабочий процесс, позволяющий как разработчикам, так и нетехническим пользователям создавать инновационные решения ИИ.
Ключевые возможности
Backend-as-a-Service для LLM: Управляет инфраструктурой бэкенда, позволяя разработчикам сосредоточиться на создании приложений, а не на управлении серверами.
Оркестрация подсказок: Упрощает создание, тестирование и управление подсказками, предназначенными для выполнения конкретных задач.
Аналитика в режиме реального времени: Предоставляет сведения о производительности модели, взаимодействии пользователей и поведении приложений для оптимизации рабочих процессов.
Расширенные возможности интеграции: Соединяется с API сторонних производителей, внешними инструментами и популярными LLM, обеспечивая гибкость пользовательских рабочих процессов.
Dify хорошо интегрируется с векторными базами данных, такими как Milvus, что повышает ее способность справляться со сложными и масштабными задачами поиска данных. Сочетая Dify с Milvus, разработчики могут создавать системы, которые эффективно хранят, извлекают и обрабатывают вкрапления для таких задач, как RAG.
Учебное пособие: Развертывание Dify с Milvus
Letta (ранее MemGPT): Создание агентов RAG с расширенным контекстным окном LLM
Letta - это фреймворк с открытым исходным кодом, разработанный для улучшения LLM путем оснащения их долговременной памятью. В отличие от традиционных LLM, которые обрабатывают входные данные статически, Letta позволяет модели запоминать и ссылаться на прошлые взаимодействия, обеспечивая более динамичные, контекстуально осведомленные и персонализированные приложения. Она интегрирует методы управления памятью для хранения, извлечения и обновления информации с течением времени, что делает ее идеальной для создания интеллектуальных агентов и разговорных систем, которые развиваются в зависимости от взаимодействия с пользователем.
Рисунок - Как Letta работает с различными инструментами искусственного интеллекта](https://assets.zilliz.com/Figure_How_Letta_works_with_various_AI_tools_05d96d2548.png)
Ключевые возможности
Саморедактирующаяся память: Letta представляет саморедактирующуюся память, позволяющую агентам автономно обновлять свою базу знаний, учиться на основе взаимодействий и адаптироваться с течением времени.
Среда разработки агентов (ADE): Предоставляет графический интерфейс для создания, развертывания, взаимодействия и наблюдения за агентами ИИ, упрощая процесс разработки и отладки.
Сохранение и управление состоянием: Обеспечивает непрерывность работы агентов во время сеансов, сохраняя их состояние, включая воспоминания и взаимодействия, что позволяет получать более согласованные и контекстуально релевантные ответы.
Интеграция инструментов: Поддерживает включение пользовательских инструментов и источников данных, позволяя агентам выполнять широкий спектр задач и получать доступ к внешней информации по мере необходимости.
Агностичная к моделям архитектура: Разработана для работы с различными LLM и RAG системами, обеспечивая гибкость в выборе и интеграции различных поставщиков моделей
Letta интегрирована с основными векторными базами данных для расширения возможностей памяти и поиска информации для передовых рабочих процессов RAG. Используя масштабируемое векторное хранилище и эффективный поиск по сходству, Letta позволяет агентам ИИ получать доступ и сохранять долгосрочные контекстные знания, обеспечивая быстрый и точный поиск данных. Такая интеграция позволяет разработчикам создавать более интеллектуальные, контекстно-ориентированные приложения, адаптированные к конкретным областям, таким как поддержка клиентов или персонализированные рекомендации, при сохранении постоянной и масштабируемой памяти. Ознакомьтесь с ресурсами ниже для получения дополнительной информации.
- Учебник | MemGPT с интеграцией Milvus
Vanna: Обеспечение генерации SQL с помощью искусственного интеллекта
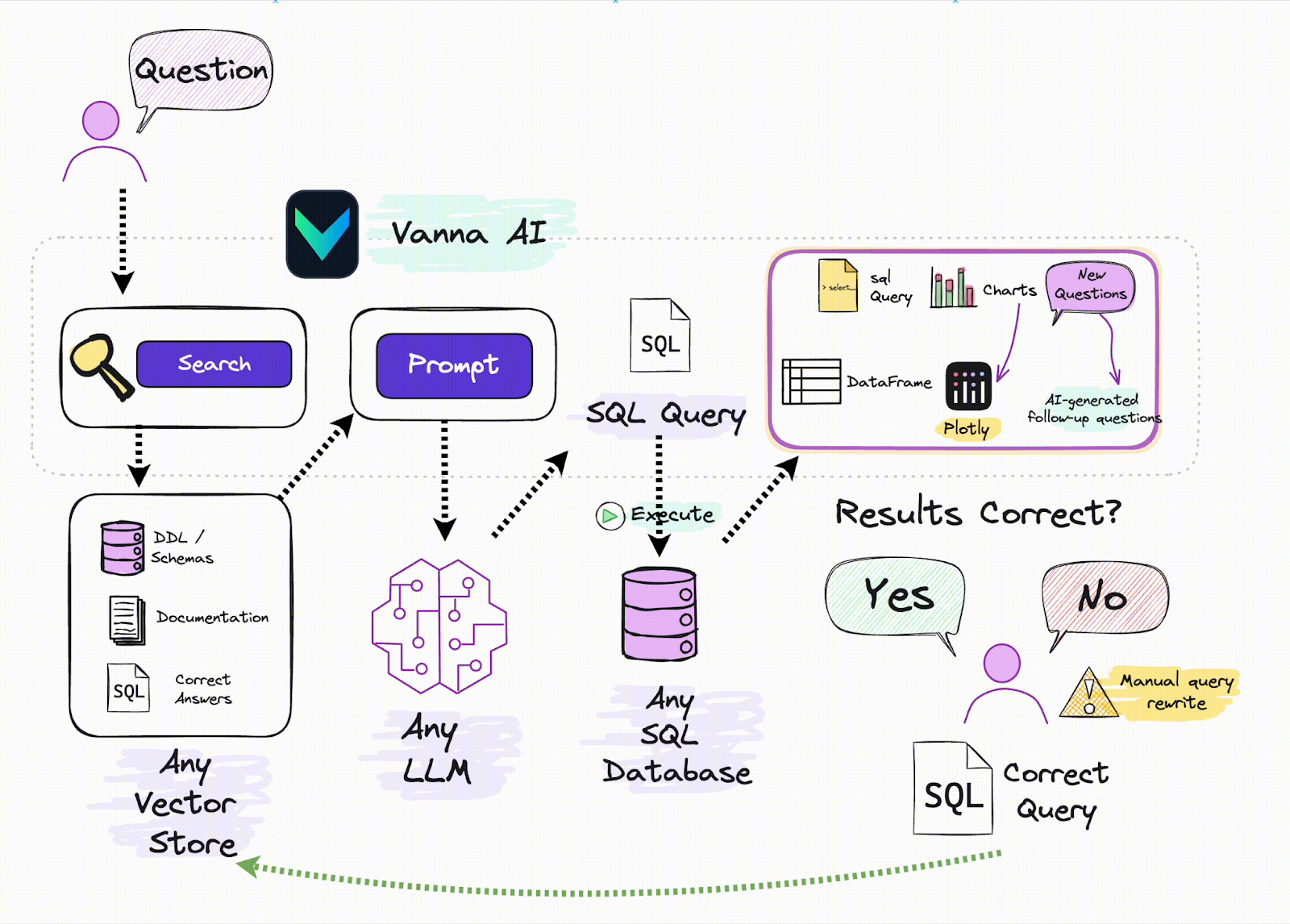
Vanna - это фреймворк на Python с открытым исходным кодом, предназначенный для упрощения генерации SQL-запросов на основе естественного языка. Используя технику RAG, Vanna позволяет пользователям обучать модели на своих конкретных данных, что позволяет им задавать вопросы и получать точные SQL-запросы, адаптированные к их базам данных. Такой подход упрощает процесс взаимодействия с базами данных, делая его более доступным для пользователей, не обладающих обширными знаниями SQL.
 Vanna
Vanna
Ключевые возможности
Преобразование естественного языка в SQL: Vanna позволяет пользователям вводить вопросы на естественном языке, которые затем преобразуются в точные SQL-запросы, исполняемые в подключенной базе данных.
Поддержка нескольких баз данных: Фреймворк предлагает встроенную поддержку различных баз данных, включая Snowflake, BigQuery, Postgres и другие. Кроме того, он позволяет легко интегрироваться с любой базой данных с помощью пользовательских коннекторов.
Гибкость пользовательского интерфейса: Vanna предоставляет множество вариантов пользовательского интерфейса, таких как Jupyter Notebooks, Slackbot, веб-приложения и Streamlit-приложения, позволяя пользователям выбирать фронт-энд, который лучше всего подходит для их рабочего процесса.
Vanna и векторные базы данных - отличное сочетание для создания эффективных RAG-систем. Когда пользователь вводит запрос на естественном языке, Vanna использует векторную базу данных для получения соответствующих данных на основе предварительно сохраненных векторных вкраплений. Эти данные затем используются для того, чтобы помочь Vanna сгенерировать точный SQL-запрос, облегчая получение структурированных данных из реляционной базы данных. Сочетая возможности векторного поиска и генерации SQL-запросов, Vanna упрощает работу с неструктурированными данными и позволяет пользователям взаимодействовать со сложными наборами данных без необходимости углубленного знания SQL. Для получения дополнительной информации ознакомьтесь с ресурсами ниже:
Kotaemon: Построение проверки документов с помощью искусственного интеллекта
Kotaemon - это настраиваемый RAG-интерфейс с открытым исходным кодом для общения с документами. Он предоставляет чистый, многопользовательский веб-интерфейс для проверки качества документов, поддерживающий локальные и основанные на API языковые модели. kotaemon предлагает гибридный конвейер RAG с возможностями полнотекстового и векторного поиска, что позволяет проводить многомодальную проверку качества для документов с рисунками и таблицами.
Предназначенный как для конечных пользователей, так и для разработчиков, kotaemon поддерживает сложные методы рассуждений, такие как ReAct и ReWOO. В нем есть расширенные возможности цитирования с предварительным просмотром документов, настраиваемые параметры для поиска и генерации, а также расширяемая структура для создания пользовательских конвейеров RAG.
 Kotaemon
Kotaemon
Ключевые возможности
Простое развертывание: Kotaemon предлагает простые интерфейсы для развертывания LLM в производстве с минимальными настройками, что обеспечивает быстрое масштабирование и интеграцию.
Настраиваемые конвейеры: Это позволяет разработчикам легко настраивать рабочие процессы ИИ, объединяя LLM с внешними API, базами данных и другими инструментами.
Дополнительные подсказки: Встроенные инструменты для разработки и оптимизации подсказок, облегчающие тонкую настройку результатов моделирования для конкретных задач.
Оптимизация производительности: Разработанный для высокопроизводительных операций, Kotaemon обеспечивает низкую задержку ответов и эффективное использование ресурсов.
Поддержка нескольких моделей: Фреймворк поддерживает различные LLM-архитектуры, предоставляя разработчикам гибкость в выборе оптимальной модели для конкретного случая использования.
Kotaemon интегрируется с векторными базами данных, такими как Milvus, обеспечивая быстрый поиск релевантных данных для таких задач, как Retrieval-Augmented Generation (RAG). Используя эффективные возможности векторного поиска Milvus, Kotaemon может повысить контекст и релевантность результатов, генерируемых ИИ. Эта интеграция позволяет разработчикам создавать системы ИИ, которые генерируют контент и извлекают релевантную информацию из больших наборов данных, повышая общую производительность и точность.
vLLM: высокопроизводительный вывод LLM для приложений ИИ в реальном времени
vLLM - это библиотека с открытым исходным кодом, разработанная SkyLab Калифорнийского университета в Беркли и предназначенная для оптимизации LLM-инференции и обслуживания. Уделяя особое внимание производительности и масштабируемости, vLLM внедряет такие инновации, как PagedAttention, которая увеличивает скорость обслуживания до 24 раз и сокращает использование памяти GPU в два раза по сравнению с традиционными подходами. Таким образом, vLLM становится переломным моментом для разработчиков, создающих требовательные ИИ-приложения, которым необходимо эффективное использование аппаратных ресурсов.
Ключевые возможности:
Технология PagedAttention: Улучшает управление памятью, позволяя хранить ключи и значения внимания несмежно, сокращая потери памяти и повышая пропускную способность до 24 раз.
Continuous Batching: Агрегирует входящие запросы в режиме реального времени, максимизируя использование GPU и минимизируя время простоя, что приводит к повышению пропускной способности и снижению задержек.
Потоковый вывод: Обеспечивает генерацию маркеров в реальном времени, позволяя приложениям немедленно выдавать частичные результаты - идеальное решение для взаимодействия с пользователями в реальном времени, например с чат-ботами.
Большая совместимость с моделями: Поддержка популярных архитектур LLM, таких как GPT и LLaMA, что обеспечивает гибкость для многих вариантов использования и бесшовную интеграцию с существующими рабочими процессами.
Сервер API, совместимый с OpenAI: Предлагает интерфейс API, повторяющий интерфейс OpenAI, что упрощает развертывание и интеграцию в существующие системы для разработчиков, знакомых с API OpenAI.
vLLM становится краеугольным камнем для создания высокопроизводительных систем RAG в сочетании с векторными базами данных, такими как Milvus. Векторные базы данных эффективно хранят и извлекают высокоразмерные вкрапления, необходимые для поиска контекстно-значимой информации. vLLM дополняет их, обеспечивая оптимизированный вывод LLM, гарантирующий, что полученная информация будет легко переработана в точные, контекстно-зависимые ответы. Такая интеграция повышает производительность приложений и решает такие проблемы, как галлюцинации ИИ, обосновывая выходные данные полученными сведениями. Ознакомьтесь с ресурсами ниже для получения дополнительной информации.
Развертывание мультимодальной системы RAG с помощью vLLM и Milvus
Эффективное управление памятью при обслуживании больших языковых моделей с помощью PagedAttention
Неструктурированные: Создание доступа к неструктурированным данным для GenAI
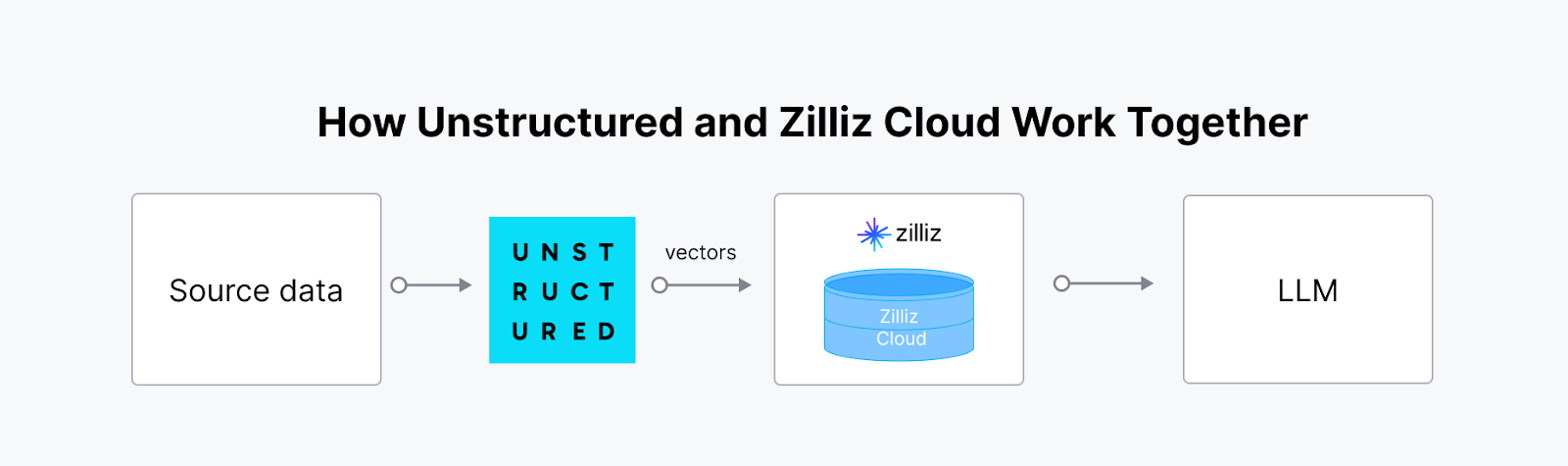
Unstructured - это библиотека с открытым исходным кодом, которая упрощает получение и предварительную обработку неструктурированных данных различных форматов, включая PDF, HTML, документы Word и изображения. Она предлагает модульные функции для разделения, очистки, извлечения, постановки и разбивки документов, облегчая преобразование неструктурированных данных в структурированные форматы. Этот набор инструментов полезен для оптимизации рабочих процессов с данными в приложениях Large Language Model (LLM).
Интеграция Unstructured с векторной базой данных, такой как Milvus, создает мощное, масштабируемое решение для управления и использования неструктурированных данных в приложениях ИИ. Платформа Unstructured получает, обрабатывает и преобразует неструктурированные данные из различных типов файлов в готовые для ИИ векторные вкрапления. Эти вкрапления крайне важны для передовых рабочих процессов ИИ, однако для их хранения, индексирования и эффективного запроса требуется специализированная векторная база данных. Синергия между Unstructured и Milvus (или Zilliz Cloud) позволяет оптимизировать сквозной конвейер, что особенно ценно для Retrieval-Augmented Generation (RAG) и других приложений, управляемых ИИ, таких как умные чат-боты и персонализированные рекомендательные системы.
 Неструктурированный
Неструктурированный
Langfuse: лучшая наблюдаемость и аналитика для LLM-приложений
Langfuse - это инженерная платформа LLM с открытым исходным кодом, которая помогает командам совместно отлаживать, анализировать и итерировать свои LLM-приложения. Она предлагает такие функции, как наблюдаемость, управление подсказками, оценки и метрики, которые интегрированы для ускорения рабочего процесса разработки.
Ключевые возможности
Наблюдаемость от конца до конца: Отслеживает взаимодействие с LLM, включая запросы, ответы и показатели производительности, чтобы обеспечить прозрачность и надежность.
Управление подсказками: Предлагает инструменты для версионирования, оптимизации и тестирования подсказок, упрощая разработку надежных приложений ИИ.
Гибкая интеграция: Работает без проблем с такими популярными фреймворками, как LangChain и LlamaIndex, поддерживая широкий спектр архитектур LLM.
Отладка в реальном времени: Предоставляет действенные сведения об ошибках и узких местах, позволяя разработчикам быстро выполнять итерации.
Интеграция Langfuse с векторными базами данных улучшает рабочие процессы RAG, обеспечивая наблюдаемость качества и релевантности встраивания. Такая интеграция позволяет разработчикам отслеживать и оптимизировать производительность и точность векторного поиска с помощью подробной аналитики, обеспечивая точную настройку процессов поиска и их соответствие потребностям пользователей. Ознакомьтесь со следующим руководством, чтобы начать работу.
Заключение
С началом 2025 года становится ясно, что фреймворки с открытым исходным кодом больше не являются просто полезными дополнениями - они являются основой для создания надежных LLM-приложений. Такие фреймворки, как LangChain и LlamaIndex, изменили способы интеграции и запроса данных, а vLLM и Haystack устанавливают новые стандарты скорости и масштабируемости. Новые фреймворки, такие как Langfuse и Letta, обладают уникальными преимуществами в наблюдаемости и памяти, открывая двери для более умных и отзывчивых систем искусственного интеллекта.
Эти фреймворки позволяют разработчикам решать сложные задачи, экспериментировать со смелыми идеями и расширять границы возможного. С этими фреймворками у вас под рукой 2025 год станет годом создания более умных, быстрых и эффективных приложений GenAI.

Читать далее

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.