




ニューラルネットワークにおける活性化関数

ニューラルネットワークにおける活性化関数
 Activation Functions.png
Activation Functions.png
近年の人工知能(AI)の進歩は、特に画像認識、自然言語処理(NLP)、自動運転車において目覚ましいものがあります。これらの成果に寄与している重要な要因は、人工ニューラルネットワークが、現実世界のデータによく存在する複雑な非線形関数を推定できる能力です。この能力は主に活性化関数によるもので、活性化関数はニューラルネットワークに非線形性を導入し、複雑な関係やパターンをモデル化できるようにします。
活性化関数について、その目的、仕組み、そしてなぜニューラルネットワークにとって重要なのかを深く理解しましょう。
活性化関数とは?
活性化関数は、ニューラルネットワークでニューロンの出力を決定し、モデルに非線形性を導入するために使用される数学関数です。これは、ニューラルネットワークの基本単位であるノード(ニューロン)の入力に適用され、ノードの出力を生成します。ニューラルネットワークは入力の重み付き和を計算し、バイアスを加え、その和を活性化関数に通して、変更された値を出力します。この値は次のネットワーク層に渡されるか、最終出力になります。
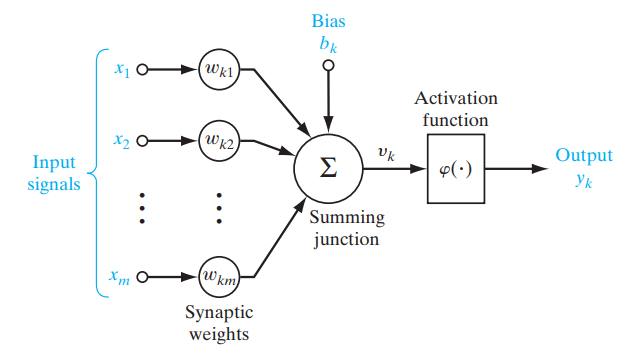 Figure- Role of an activation function in a neural network. .png
Figure- Role of an activation function in a neural network. .png
図:ニューラルネットワークにおける活性化関数の役割。| 出典
なぜ非線形性が重要なのか?
活性化関数が不可欠である理由を理解するには、線形モデルに限界がある理由を知ることが重要です。線形モデルは、入力と出力の間の直線的な関係を表します。単純なタスクではうまく機能しますが、データがより複雑で非線形パターンを持つ場合には失敗します。
非線形性により、ニューラルネットワークは直線ではない決定境界を作成できます。したがって、ニューラルネットワークは、線形モデルでは表現できないデータ内の非線形パターンを理解できます。
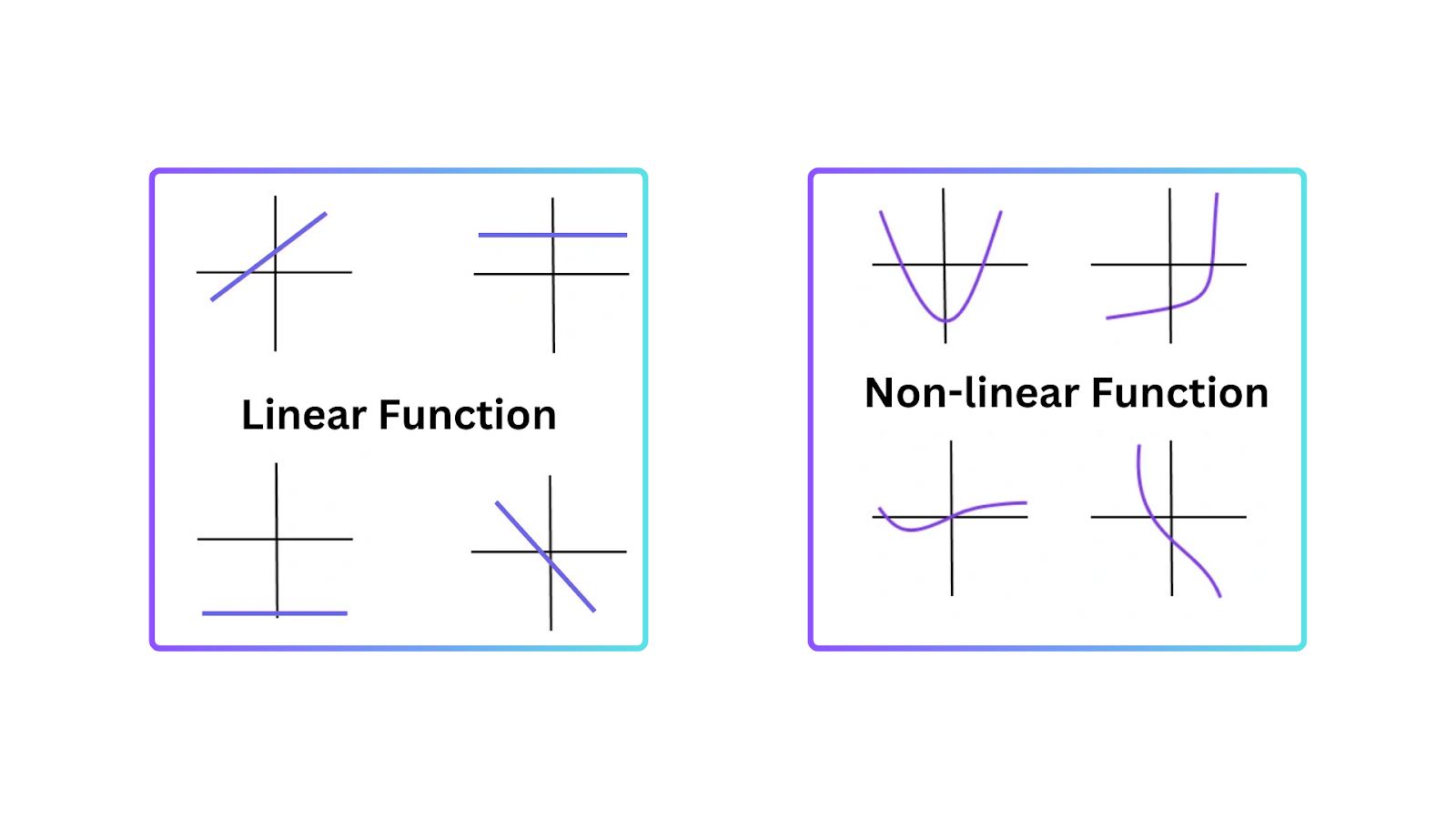 Figure- Types of Functions.png
Figure- Types of Functions.png
図:関数の種類
活性化関数の仕組み
ここまで活性化関数を紹介してきましたが、次に、これらの関数が入力信号を出力信号へ変換するために数学的にどのように機能するのかを見てみましょう。その範囲は多くの場合、0 と 1 の間、または -1 と 1 の間です。ニューラルネットワーク内の各ニューロンでは、データは次の手順で流れます。
入力: ニューラルネットワーク内の各ニューロンは、1つ以上の入力を受け取ります。これらの入力は、ネットワークに供給される元のデータ(入力層の場合)から来ることも、前の層のニューロンの出力から来ることもあります。
重み付き和の計算: 入力は、それぞれの重要度を決定するために対応する重みと掛け合わされます。その後、重み付き入力が合計され、重み付き和として知られる単一の値が返されます。
活性化関数の適用: 重み付き和が計算されると、それは活性化関数に通され、活性化関数の結果がニューロンの出力になります。
このプロセスは、ネットワーク層全体の各ニューロンで繰り返され、データをより複雑な方法で変化させます。
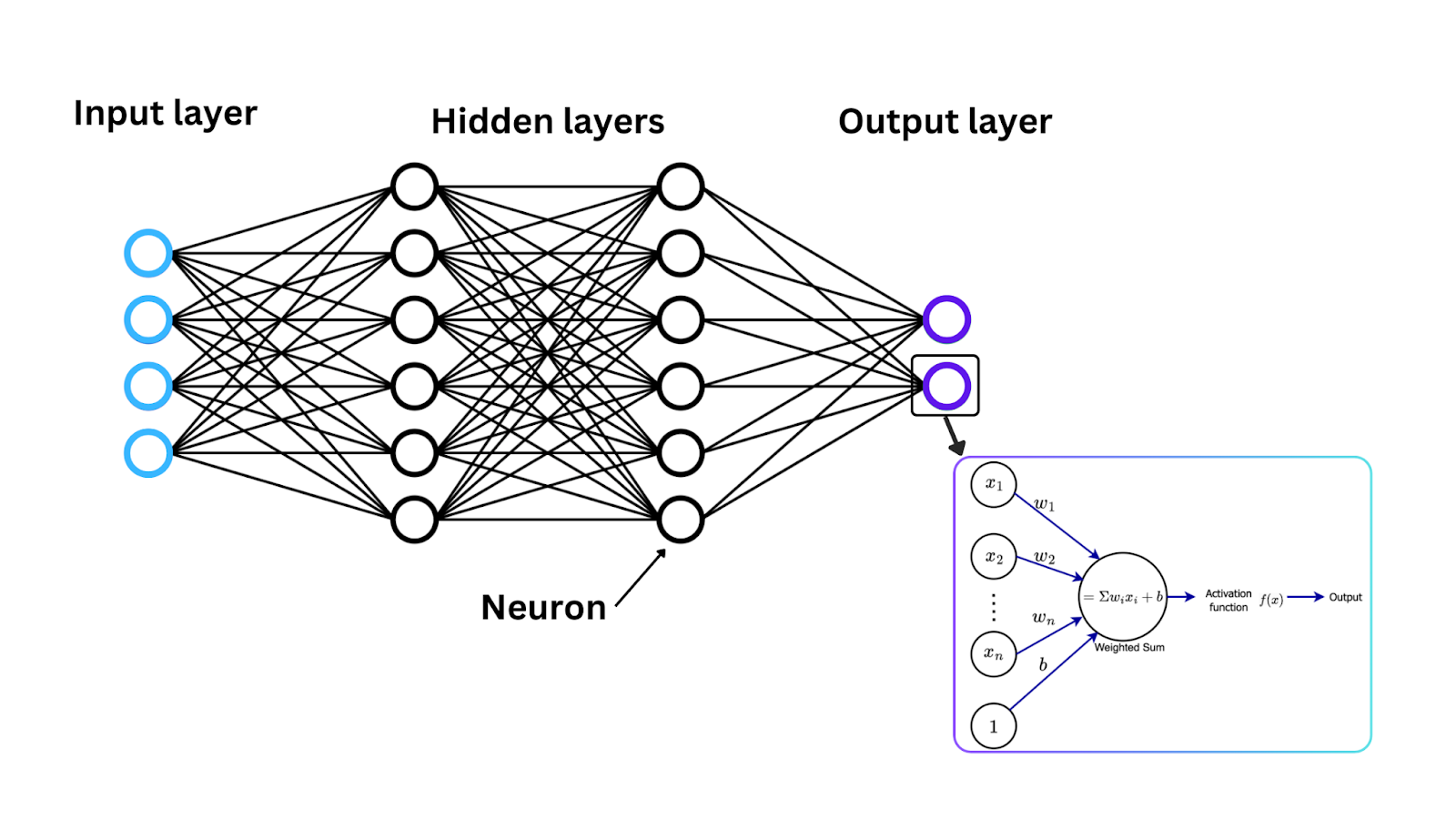 Figure- Neural network architecture, activation function, and neuron weight updates. .png
Figure- Neural network architecture, activation function, and neuron weight updates. .png
図:ニューラルネットワークのアーキテクチャ、活性化関数、およびニューロンの重み更新。
ニューラルネットワークはさまざまな種類の活性化関数を使用します。各関数にはそれぞれの強みがあり、特定のタスクにより適しています。たとえば、シグモイド関数は二値分類問題に最適であり、softmax は多クラス予測に有用で、ReLU は勾配消失問題の克服に役立ちます。
適切な活性化関数を選ぶことで、学習が高速化され、性能が向上します。それでは、一般的な活性化関数をいくつか見てみましょう。
シグモイド活性化
ReLU (Rectified Linear Unit) 活性化
Tanh (Hyperbolic Tangent) 活性化
Leaky ReLU 活性化
シグモイド活性化
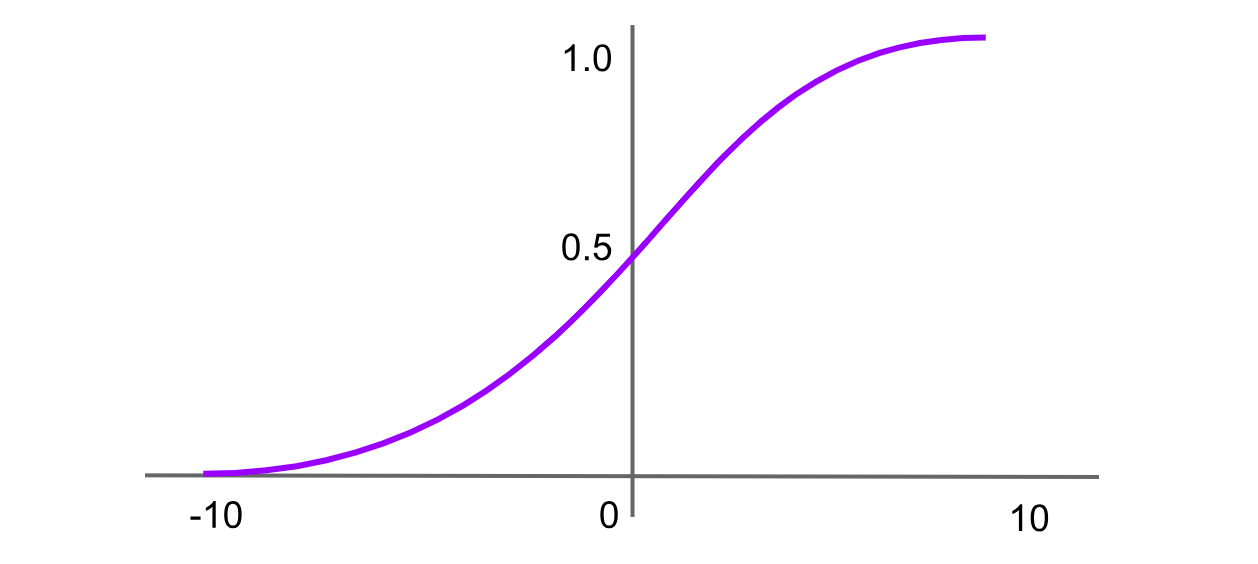 図- シグモイド活性化関数.png
図- シグモイド活性化関数.png
図: シグモイド活性化関数
シグモイド関数は、ロジスティック関数としても知られ、最も初期からあり、最も広く知られている活性化関数の一つです。これは任意の入力値を 0 から 1 の範囲に写像し、「S」字型の曲線を生成します。シグモイド関数の式は次のとおりです。
Sigmoid = σ(x) = 1 / (1 + exp(-x))
Python でシグモイド関数を定義するコードは以下のとおりです。
import numpy as np
def sigmoid_function(x):
z = (1/(1 + np.exp(-x)))
return z
シグモイド関数は、出力として確率を予測する必要があるモデルに役立ちます。たとえば、二値分類問題では、出力を 0 から 1 の間の確率として解釈できるようにしたい場合があります。
しかし、Sigmoid には勾配消失問題があります。バックプロパゲーション(ネットワークが重みを更新することで学習する際)の間、シグモイドの勾配は非常に小さくなり、深い層での学習が遅くなります。
Softmax 活性化
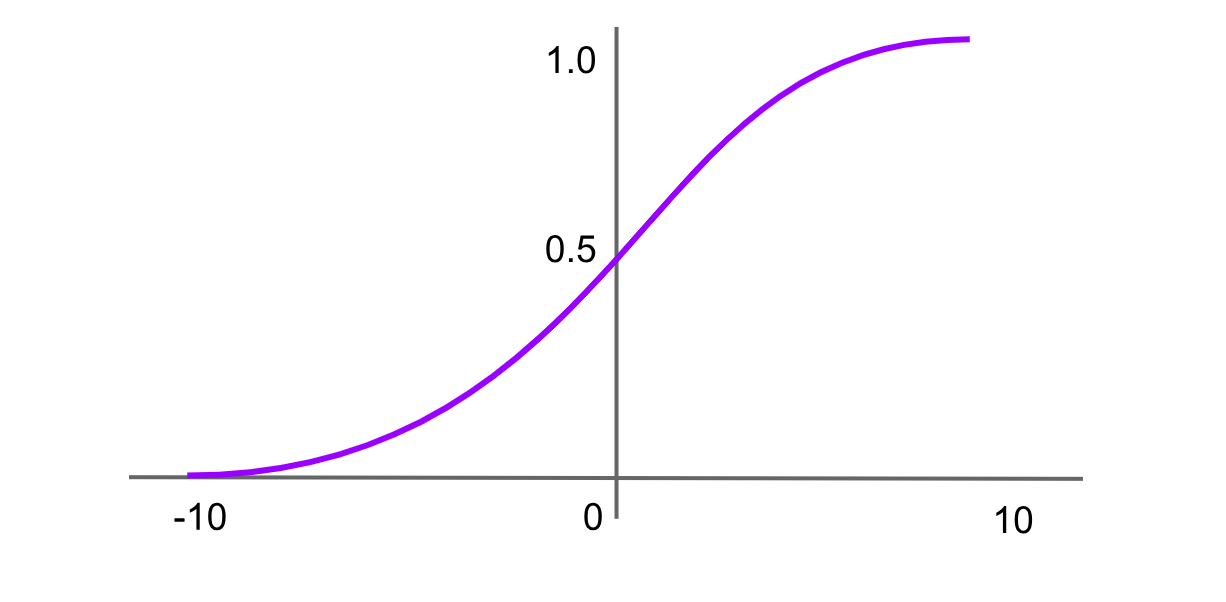 図- Softmax 活性化関数.png
図- Softmax 活性化関数.png
図: Softmax 活性化関数
softmax 関数は、多クラス分類問題におけるニューラルネットワークの出力層で一般的に使用されます。これは実数のベクトルを入力として受け取り、クラス全体の確率分布に正規化します。各出力は 0 から 1 の間であり、すべての出力の合計は 1 になります。softmax 関数の式は次のとおりです。
Softmax(x)=f(xi)= exp(x) / sum(exp(x))
これを Python でコード化してみましょう。
def softmax_function(x):
z = np.exp(x)
z_ = z/z.sum()
return z_
ただし、Softmax は、すべての出力に対して指数関数を計算し、それらを正規化する必要があるため、特に大規模なネットワークでは計算コストが高くなる可能性があります。
ReLU (Rectified Linear Unit) 活性化
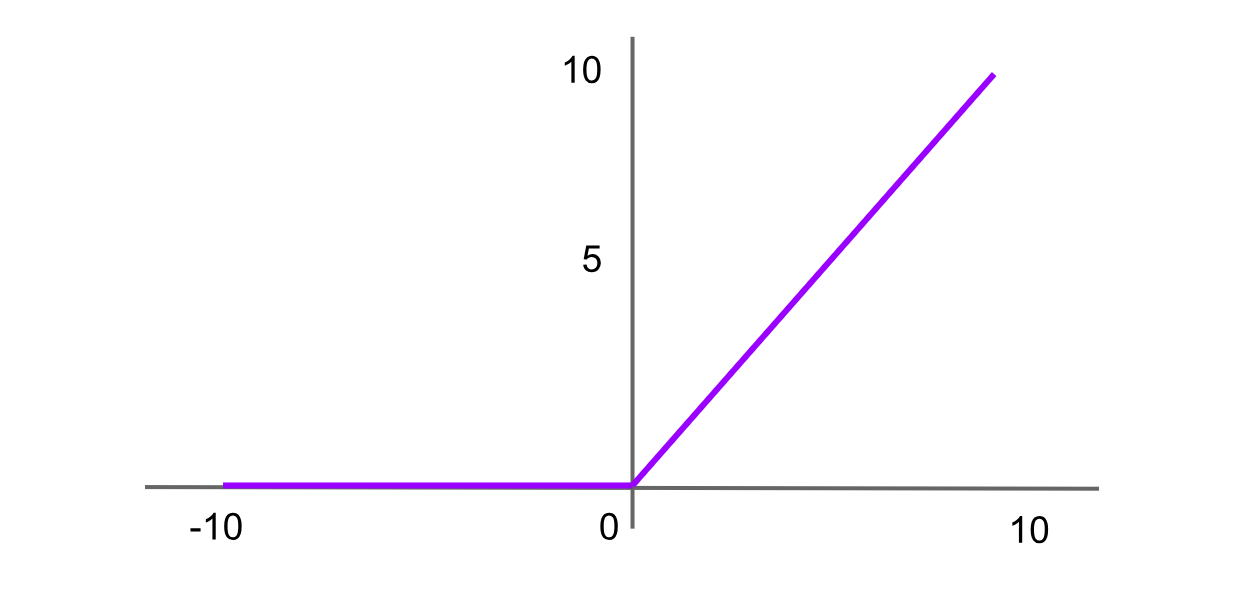 図- ReLU 活性化関数.png
図- ReLU 活性化関数.png
図: ReLU 活性化関数
ReLU は、高度なニューラルネットワークで最も広く使用されている活性化関数の一つです。負の入力に対しては 0 を返し、正の値に対してはその値自体を返します。ReLU 関数の式は次のとおりです。
ReLU = f(x) = max(0,x)
ReLU の Python 関数は以下のとおりです。
def relu_function(x):
if x<0:
return 0
else:
return x
ReLU は、特にコンピュータビジョンのタスクにおいて、ニューラルネットワークの隠れ層で使用されます。指数演算や除算演算がないため、計算効率に優れています。シグモイドと比較して、勾配消失問題の影響も受けにくいです。ただし、ReLU には「dying ReLU」問題という欠点が一つあります。ニューロンがすべての入力に対して一貫してゼロを出力すると、そのニューロンは非アクティブになり、学習に寄与できなくなります。
Tanh (Hyperbolic Tangent) 活性化
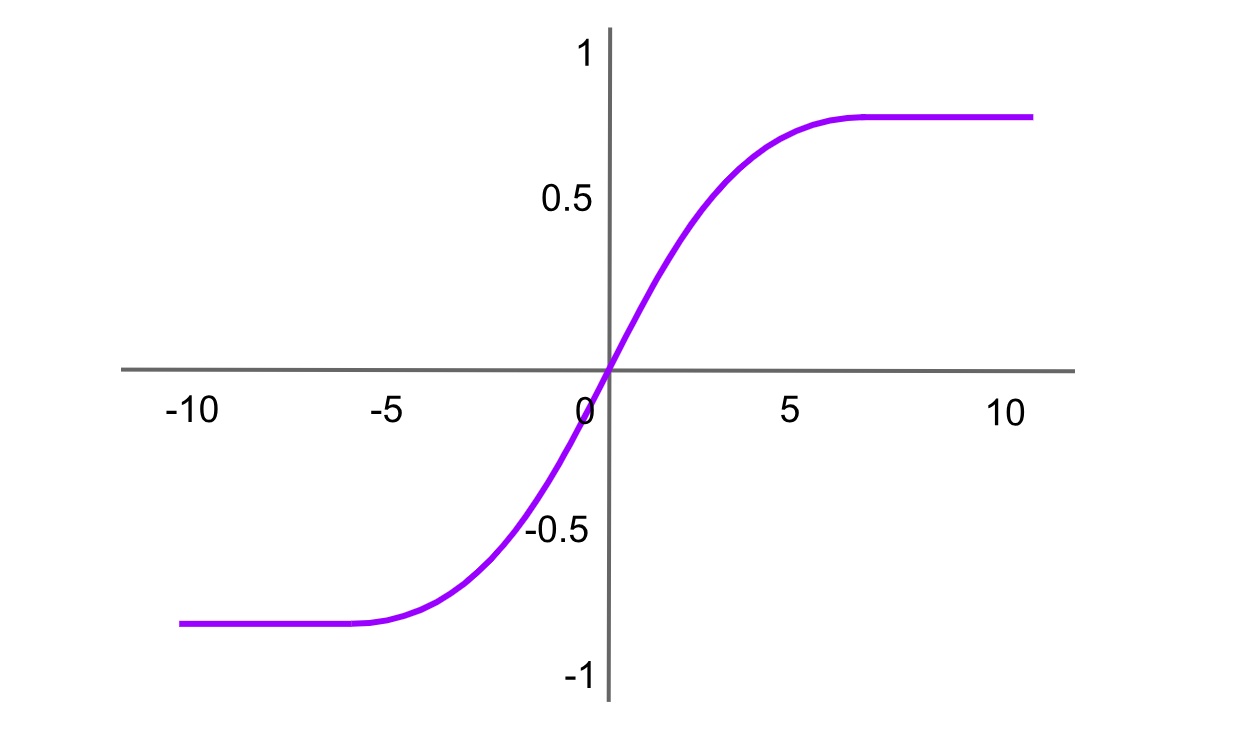 Figure- Tanh activation function .png
Figure- Tanh activation function .png
図: Tanh活性化関数
双曲線正接関数はシグモイド関数に似ていますが、-1から1の間の値を出力します。Tanh関数の式は次のとおりです。
tanh(x)= f(x)= 2 / (1+exp (−2x ))−1
または
tanh(x)= f(x)=2sigmoid(2x)-1
同じもののPythonコードは次のとおりです。
def tanh_function(x):
z = (2/(1 + np.exp(-2*x))) -1
return z
双曲線正接は、ニューラルネットワークの隠れ層、特に自然言語処理(NLP)タスクで使用されます。シグモイド関数といくつかの類似点を共有していますが、ゼロ中心であるという利点があり、特定のネットワークでは学習を高速化できます。ただし、シグモイド関数と同様に、tanhも勾配消失問題の影響を受けます。
Leaky ReLU活性化
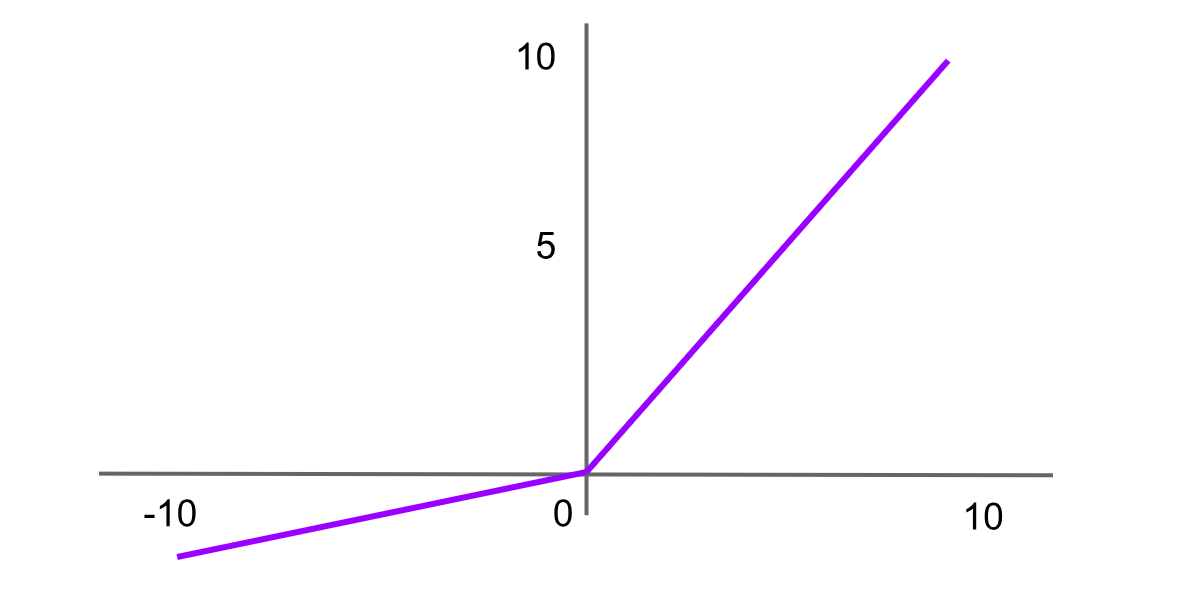 Figure- Leaky ReLU activation function .png
Figure- Leaky ReLU activation function .png
図: Leaky ReLU活性化関数
Leaky Rectified Linear Unit、またはLeaky ReLUは、負の値に対して平坦な勾配ではなく小さな勾配を導入することで「dying ReLU」問題を解決するよう設計されたReLUの変種です。これにより、ニューロンが恒久的に不活性になるのではなく、学習を継続できるようになります。Leaky ReLU関数の式は次のとおりです。
Leaky ReLU = f(x)=max(αx,x)
ここで、𝛼 α は小さな正の定数(例: 0.01)であり、負の入力に対してニューロンがゼロではなく小さな負の値を出力するようにします。Leaky ReLUはReLUの変種であるため、Pythonコードはわずかな変更で実装できます。
def leaky_relu_function(x):
if x<0:
return 0.01*x
else:
return x
比較
活性化関数をよりよく理解するには、ニューラルネットワークの他の主要コンポーネントと比較すると役立ちます。
活性化関数 vs. 損失関数
活性化関数は、ネットワーク内のニューロンが入力信号にどのように応答するかを定義します。ニューロン(または層)の出力に適用され、非線形性を導入することで、ネットワークがデータ内のパターンや関係を理解できるようにします。
一方、損失関数は、ニューラルネットワークの予測が実際の目標値(正解データ)とどの程度一致しているかを判断するために使用されます。予測出力と実際の結果との誤差を計算します。さらに、最適化アルゴリズムは、この誤差を最小化するために、学習中にネットワークの重みを調整します。損失関数には次のものがあります。
平均二乗誤差(MSE)は、回帰タスクで一般的に使用されます。
クロスエントロピー損失は、分類タスクで使用されます。
活性化関数 vs. 正規化
活性化関数は、データがある層から別の層へどのように移動するか、および入力に基づいてニューロンがどのように「発火」するかを制御します。
しかし、バッチ正規化などの正規化は、学習をより効果的にするのに役立ちます。これは、層への入力の分布を変更することで、ネットワークの学習を高速化し、勾配消失や勾配爆発を防ぎます。バッチ正規化は、各層への入力を一貫した平均と分散になるように正規化し、ネットワークの収束を容易にします。その他の正規化手法には次のものがあります。
Layer normalization: 各層全体で正規化します。
Instance normalization: 通常は画像処理で使用され、各インスタンスを個別に正規化します。
活性化関数の利点と課題
活性化関数はニューラルネットワークにいくつかの利点をもたらしますが、対処すべき課題もあります。まず、活性化関数の利点について説明しましょう。
非線形性: 活性化関数の最も重要な利点は、ネットワークに非線形性を導入することです。これにより、ネットワークはデータ内の非線形パターンを捉えられるようになり、画像認識や自然言語理解などのタスクに最適です。
出力範囲: sigmoid や softmax のような活性化関数は、出力を特定の範囲内に制限します(sigmoid は 0〜1、tanh は -1〜1 の間)。これにより、特に分類タスクにおいて、出力を理解することがはるかに容易になります。
効率的な計算: ReLU のようないくつかの関数は計算効率が高く、ネットワークをスケールアップして大規模データセットに適用できます。
次に、活性化関数の課題について説明しましょう。
勾配消失問題: これは深層ニューラルネットワークでよく見られ、主に sigmoid や tanh のような活性化関数を使用する場合に発生します。逆伝播中、勾配が複数のネットワーク層を伝播するにつれて非常に小さくなり、ネットワークの収束が遅くなって効果的に学習できなくなります。
勾配爆発: 勾配爆発は、大きな誤差勾配が蓄積し、トレーニングプロセス中にニューラルネットワークモデルの重みに対して非常に大きな更新が発生する問題です。これにより、モデルが不安定になり、トレーニングデータから学習できなくなります。
関数の選択: タスクやニューラルネットワークに最適な活性化関数を選択することは難しい場合があり、通常はいくつかの実験が必要です。これは、解決しようとしている問題の種類によって異なります。
活性化関数のユースケース
活性化関数は、さまざまなタスクを実行する各種ニューラルネットワークアーキテクチャの重要な構成要素です。主な応用例を以下に示します。
画像分類: Convolutional Neural Networks (CNNs) は、隠れ層で ReLU 活性化を使用してピクセルデータを処理し、出力層で softmax を使用して多クラス分類を行います。
自然言語処理 (NLP): Recurrent Neural Networks (RNNs)、Long Short-Term Memory (LSTM)、および Transformers は、隠れ層で tanh または ReLU 活性化を使用して系列データを処理します。
生成モデル: Generative Adversarial Networks (GANs) は通常、生成器ネットワークで ReLU または LeakyReLU を使用して非線形性を導入し、現実的な出力を生成し、識別器ネットワークで sigmoid を使用します。
TensorFlow や PyTorch を含むいくつかの深層学習フレームワークは、組み込みの活性化関数と実装を幅広く提供しており、独自の活性化関数を作成することもできます。
活性化関数に関する FAQs
- 活性化関数とは何ですか?
活性化関数は、ニューラルネットワークが入力データ内の複雑なパターンを学習できるようにする基本的な構成要素です。ノード(ニューロン)の入力信号を出力信号に変換し、それが次のニューラルネットワーク層に渡されます。
- なぜ ReLU 活性化関数が使用されるのですか?
ReLU 活性化関数はニューラルネットワークに非線形性を導入し、機械学習モデルのトレーニング中に勾配消失問題を軽減するのに役立ちます。
- 最も一般的に使用される活性化関数は何ですか?
ReLU、Leaky ReLU、Softmax、Swish は人気のある活性化関数です。
- 活性化関数は何に使用されますか?
活性化関数の主な目的は、ノードからの重み付き入力の合計を出力値に変換することであり、その出力値は次の隠れ層に渡されるか、最終出力として使用されます。
- 複数の活性化関数を使用できますか?
はい、ニューラルネットワークの異なる層で異なる活性化関数を使用することは一般的です。たとえば、標準的な構成では、多クラス分類問題において隠れ層にReLU活性化関数を使用し、出力層にsoftmaxを使用することがあります。