




検索拡張世代(RAG)はロングコンテクストLLMに殺されるのか?
AIにおける革新と覇権の追求は衰える気配がない。最近Googleは、Geminiのデビューからわずか2ヶ月後にGemini 1.5,を公開した。最新の大規模言語モデル(LLM)は、最大1,000万トークンに及ぶコンテキストを扱うことができる。同時に、OpenAIはSoraのステージに立った。Soraは、その魅惑的な視覚効果で有名なロバストなテキストからビデオへのモデルである。この2つの最先端技術の対決は、AIの未来、特に検索拡張世代(RAG)の役割と終焉の可能性についての議論を呼び起こした。
このブログでは、Geminiのロングコンテクスト機能の複雑さ、限界、そしてRAG(Retrieval Augmented Generation)技術の進化への影響を探る。最も重要なことは、RAGが終焉の危機に瀕しているかどうか、そして、RAGシステムを最適化する方法について議論することである。
ジェミニのロングコンテクスト機能を理解する
そらの視覚効果の魅力の方が注目を集めるが、私はジェミニとそれに付随する技術報告書の方に興味がある。この報告書は50ページ以上に及び、ジェミニのロングコンテクストとマルチモーダル能力のテストを探求している。このレポートによると、Gemini 1.5 Proは、最大1,000万トークンの超ロングコンテクストとマルチモーダルデータ処理をサポートしており、Geminiは、書籍全体や膨大なドキュメントコレクションから、広範なコードライブラリや1時間の映画まで、多様なデータとシームレスに対話することができる。
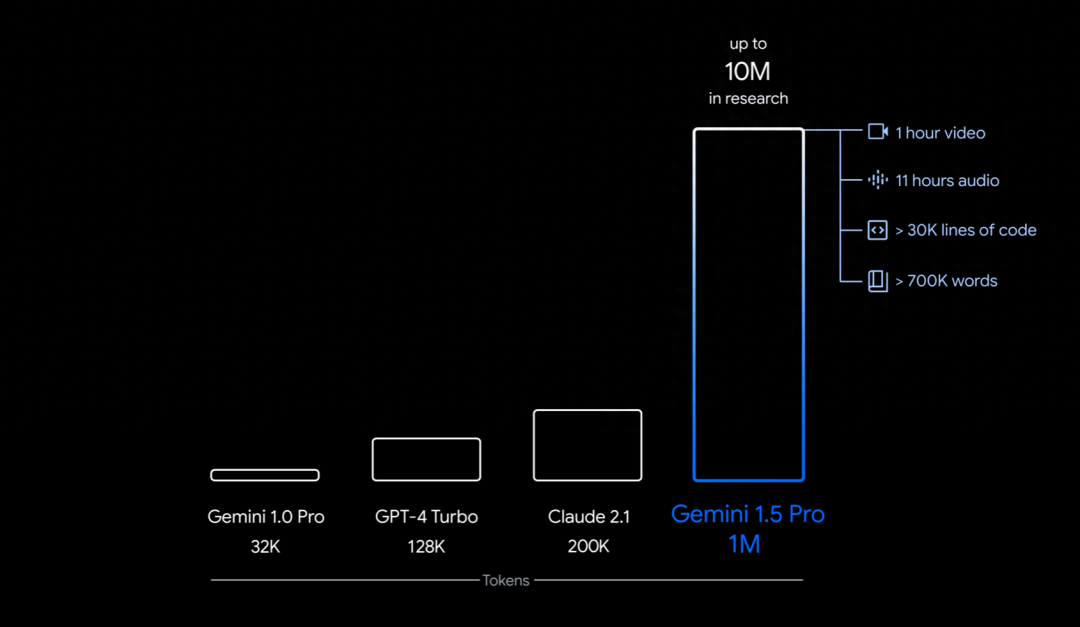
Gemini 1.5 Proは、最大10Mトークンの超ロングコンテキストをサポートしています。画像ソース:https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/
検索の安定性と精度
本レポートでは、Gemini 1.5 ProとGPT-4の検索能力をテストし比較するために、「干し草の山の中に針を刺す」評価方法を紹介する。このテストでは、Googleは長い文書(「干し草の山」)のさまざまな位置にテキストセグメント(「針」)を挿入し、GeminiとGPTは関連する文書を検索して名前を付ける必要がある。
テスト結果によると、Gemini 1.5 Proは、最大530,000個のトークンから100%のリコールを達成し、最大1M個のトークンから99.7%以上のリコールを維持した。10Mトークンという超長文のドキュメントでも、99.2%という驚異的な想起率を維持している。GPT-4は128,000未満のトークンを見事に処理する一方で、Geminiはより拡張されたコンテキストを処理することに長けている。これらの結果は、10Mトークンまでの非常に長いコンテキストにおけるGeminiの優れた情報検索、安定性、正確性を裏付けている。
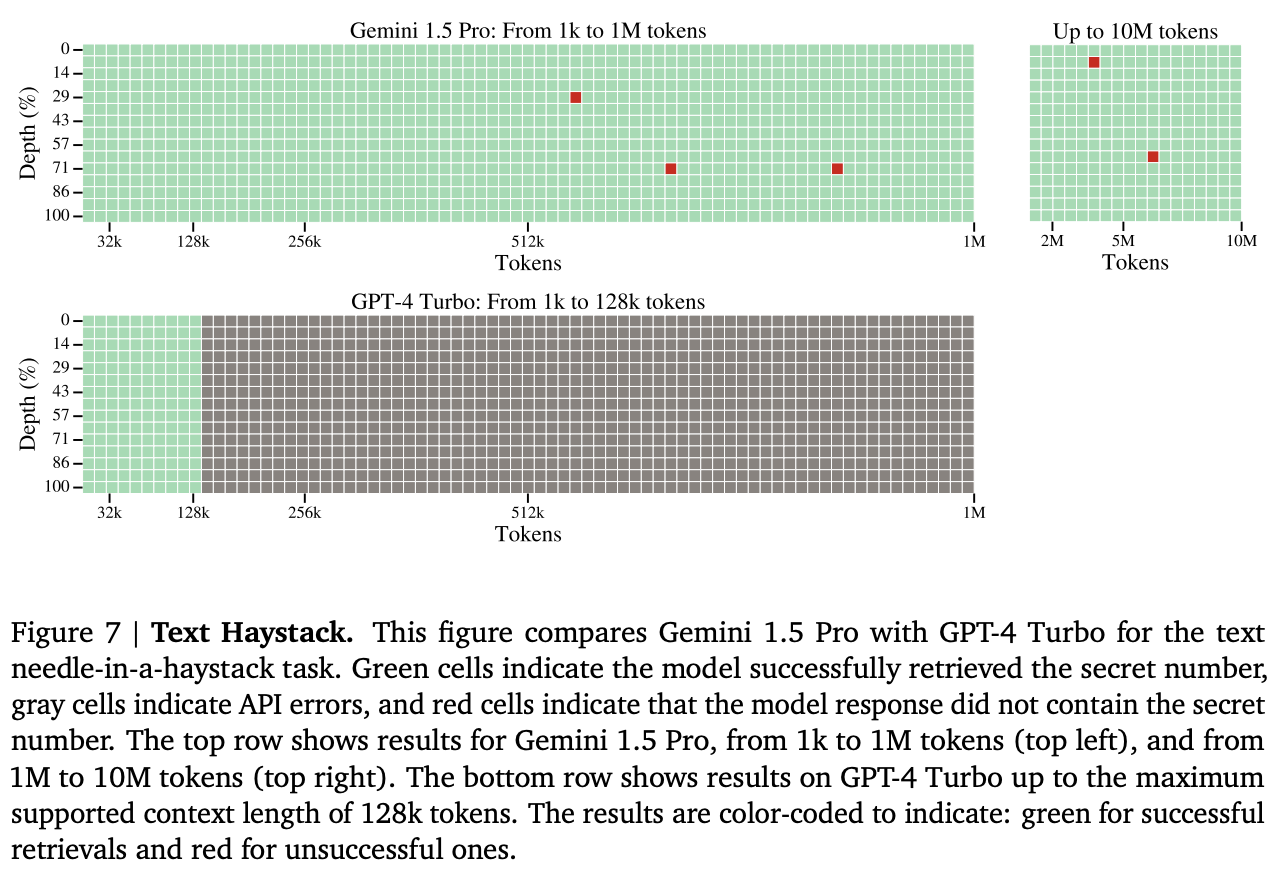
画像ソースhttps://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf_
質問回答
Googleは、Geminiの検索能力のテストに加えて、文脈を提供する質問応答能力も評価している。このテストでは、Googleは「Les Misérables」(71万トークン)をコンテキストとして使用し、Gemini 1.5 Pro、Gemini 1.0 Pro、AnthropicのClaude 2.1に、この本に関する質問に答えるよう求めた。
Gemini 1.0 ProとClaude 2.1は、710,000トークンよりも小さいコンテキスト長をサポートしているため、Top-Kの最も関連性の高い文章(最大4,000トークン)にアクセスするために、検索拡張生成(RAG)技術をコンテキストとして利用する必要があります。Geminiはより大きなコンテキストウィンドウを持つため、本全体をコンテキストとして参照する。このテストでは、コンテキストとして何も提供されない0ショットのセットアップに対する3つのモデルのパフォーマンスも比較する。
テストの結果、Gemini 1.5 Proは、質問に対する回答において他のRAGを搭載したLLMよりも優れており、巨大なテキストコレクションの理解と処理における優位性を示している。また、このテストでは、検索拡張生成技術が、長距離の依存関係を持つデータソース間の参照表現や推論を解決するのに苦労することが多いことも明らかになった。
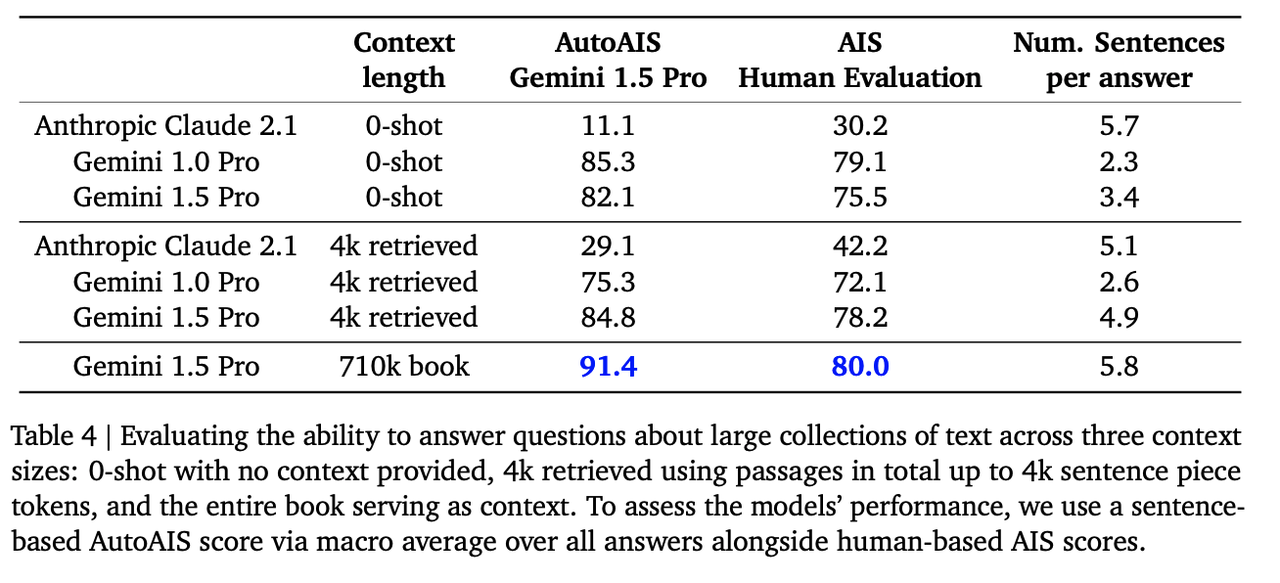
画像ソースhttps://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf_
ロングコンテクストLLMはRAGを殺すのか?
ベクトルデータベース](https://zilliz.com/learn/what-is-vector-database)、LLM、[prompt-as-code](https://zilliz.com/glossary/prompt-as-code-(prompt-engineering appendix))を組み込んだretrieval augmented generation frameworkは、外部の知識ソースをシームレスに統合して、LLMの知識ベースを充実させ、的確で関連性の高い文書や回答を得るための最先端技術である。これは、幻覚やドメイン固有の知識の欠如といったLLMの基本的な課題に効果的に対処する実証済みのソリューションである。
長い文脈を処理するGeminiの素晴らしいパフォーマンスを目の当たりにして、RAGの終焉を予想する声もある。例えば、Twitter上のGemini 1.5 Proのレビューで、ヤオ・フー博士は、"10MのコンテキストはRAGを殺す "と大胆に述べている。

**この主張は本当だろうか?私の見解では、答えは "NO "だ。RAGテクノロジーの開発は始まったばかりであり、今後も進化し続けるだろう。Geminiは拡張コンテキストの管理に優れていますが、4Vとしてカプセル化された永続的な課題に取り組んでいます:Velocity(速度)、Value(価値)、Volume(量)、Variety(多様性)である。
LLMの4Vsの課題
Velocity(速度):** Geminiは、広範なコンテキストに対する秒以下の応答時間を達成するハードルに直面しており、これは360,000のコンテキストに応答するのに30秒の遅れがあることからも明らかである。LLMの計算の進歩については楽観的な見方をしているが、長いコンテクストを検索するときに秒以下のレベルで迅速に応答することは、大規模な変換器ベースのモデルにとって依然として困難である。
LLMの価値:** LLMの価値提案は、長いコンテキストで高品質の回答を生成することに関連するかなりの推論コストによって損なわれている。例えば、1000トークンあたり0.0015ドルのレートで100万トークンのデータセットを検索すると、1回のリクエストで1.5ドルに達する可能性がある。このコスト要因は、このような高額な出費を日常的に利用するのは非現実的であり、普及の大きな障壁となる。
ボリューム:** 最大1,000万トークンの大きなコンテキストウィンドウを処理する能力があるにもかかわらず、Geminiのボリューム容量は、非構造化データの広大さと比較すると矮小である。例えば、Geminiを含むどのLLMも、Googleの検索インデックスに見られるような巨大なスケールのデータに適切に対応することはできない。さらに、非公開の企業データは、その所有者の範囲内に留まらなければならない。所有者は、RAGを使うか、独自のモデルを訓練するか、非公開のLLMを使うかを選ぶかもしれない。
多様性:*** 実際のユースケースには、長いテキスト、画像、動画などの非構造化データだけでなく、時系列データ、グラフデータ、コード変更など、学習目的のLLMでは容易に捕捉できない多様な構造化データも含まれる。このような多様なデータを効率的に処理するためには、合理化されたデータ構造と検索アルゴリズムが不可欠である。これらの課題はすべて、AIアプリケーションの開発におけるバランスの取れたアプローチの重要性を浮き彫りにし、人工知能の進化する状況においてRAGをますます重要なものにしている。
RAGの効果を最適化するための戦略
検索拡張生成はLLM幻覚を減らすのに有益であることが証明されているが、それには限界がある。このセクションでは、RAGシステムをより幅広い用途に適応できるようにするために、精度と性能のバランスを取るために、検索拡張生成の効果を最適化する戦略を探る。
長い文脈理解の強化
従来の検索拡張生成技術は、主に埋め込みモデルとそのコンテキストウィンドウのサイズ制限のために、非構造化データをベクトル化するためのチャンキングに頼ることが多い。しかし、このチャンキングアプローチには2つの顕著な欠点がある。
- 第一に、入力シーケンスが孤立したチャンクに分解され、コンテキストの連続性が失われ、埋め込み品質に悪影響を与えます。
- 第二に、連続する情報が異なるチャンクに分離される危険性があり、その結果、重要な情報が不完全に検索される可能性がある。
このような課題に対して、LLMに基づく新しい埋め込み戦略が、効率的なソリューションとして注目を集めています。これらは、より優れた埋め込み能力を誇り、コンテキストウィンドウの拡張をサポートしている。例えば、SRF-Embedding-MistralとGritLM7Bは、Huggingface MTEB LeaderBoardで最も優れた性能を持つ2つの埋め込み言語モデルであり、32k-token長のコンテキストをサポートし、埋め込み能力の大幅な向上を示しています。非構造化データの埋め込みにおけるこの強化は、長いコンテキストに対するRAGの理解も高めています。
上記の課題に取り組むもう一つの効果的なアプローチは、最近リリースされたBGELandmark Embedding戦略である。このアプローチはチャンキングのないアーキテクチャを採用しており、例えば文のような細かい入力単位に対する埋め込みは、首尾一貫した長い文脈に基づいて生成することができる。また、長い文脈の中で、連続する複数の文からなる有用な情報の完全な検索を容易にするために、位置認識機能を活用している。したがって、ランドマーク埋め込みは、長い文脈を理解し処理するRAGシステムの能力を高めるのに有益である。
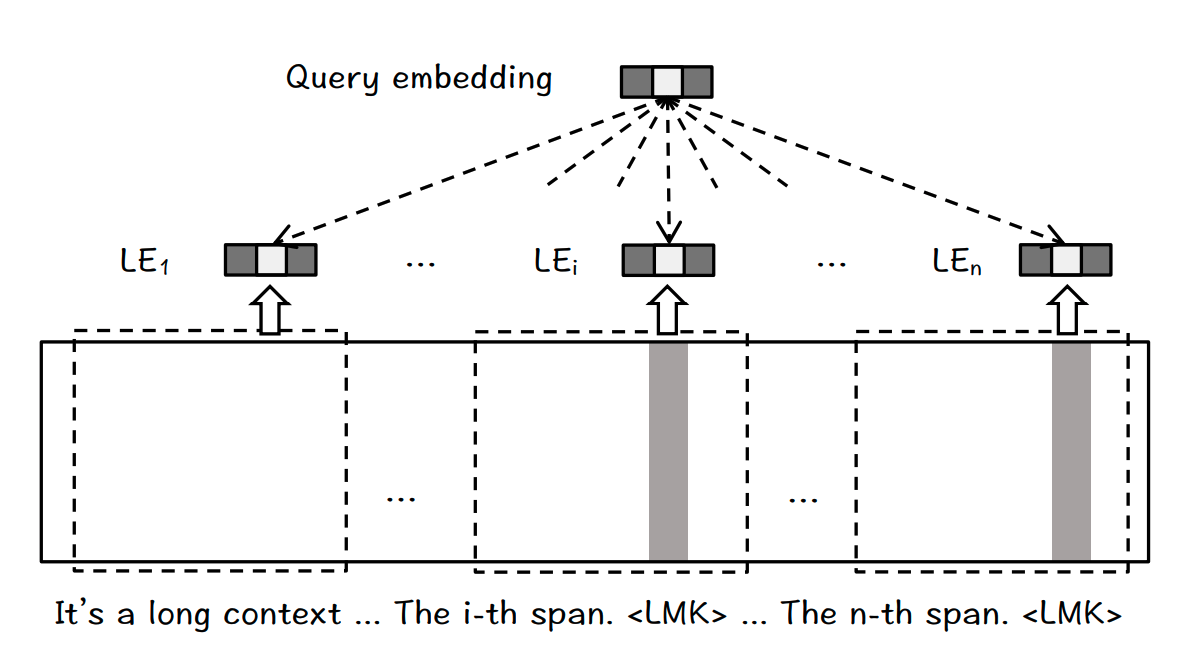
ランドマーク埋め込みのアーキテクチャは、ランドマーク(LMK)トークンを文末に付加する。LLMの文脈ウィンドウより長い入力テキストを扱うために、スライディングウィンドウが採用されている。画像ソースhttps://arxiv.org/pdf/2402.11573.pdf_
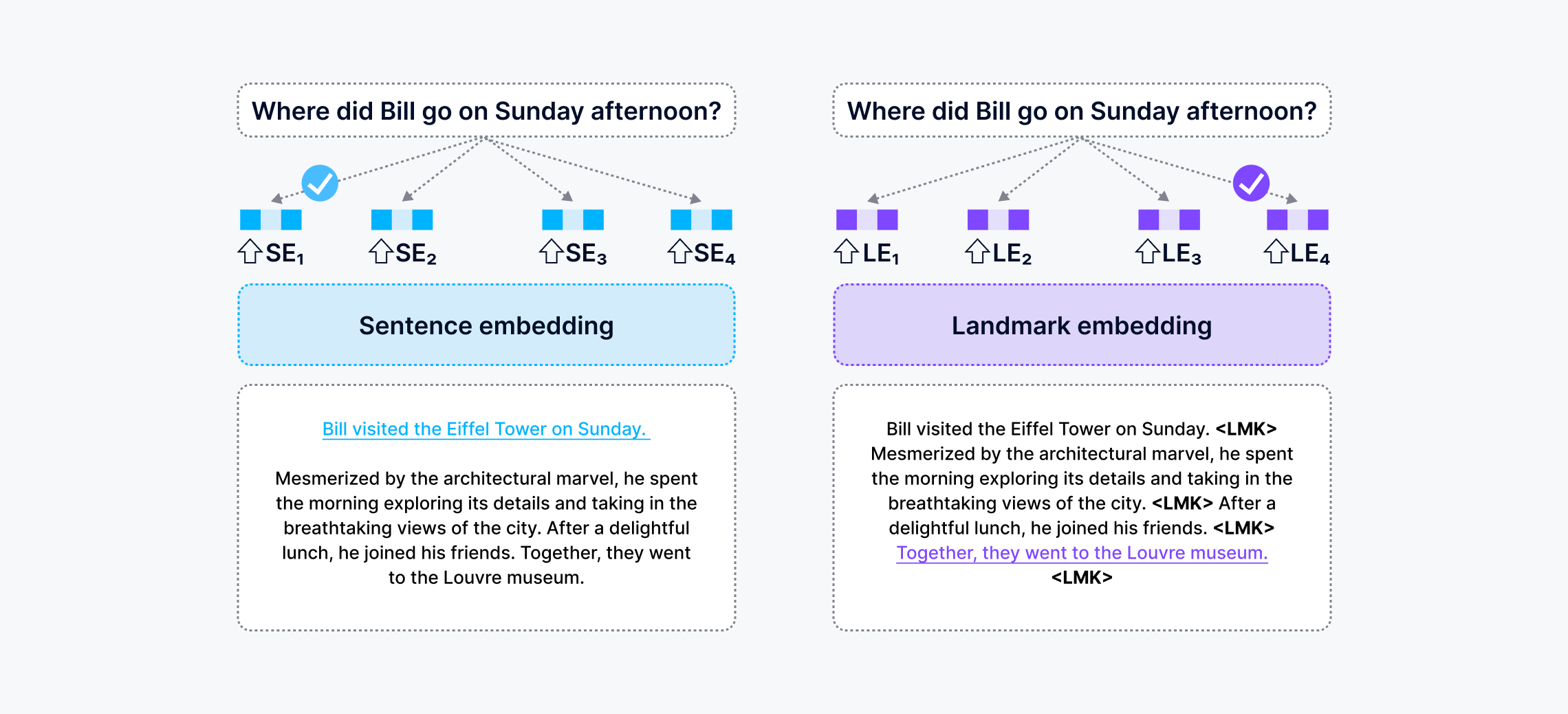
この図は、RAGアプリが質問に答えるのを助けるために、センテンスエンベッディングとランドマークエンベッディングの方法を比較したものです。前者はチャンク化されたコンテキストで動作し、顕著な文を選択する傾向がある。後者は首尾一貫した文脈を維持するため、正しい文を選択することができる。青と紫でハイライトされた文は、それぞれ2つの埋め込み方法によって検索された回答である。Sentence embeddingを利用したRAGシステムは誤った答えを与え、Landmark embeddingに基づくRAGは正しい答えを与えた。この画像はhttps://arxiv.org/abs/2402.11573からの引用です。
検索品質向上のためのハイブリッド検索の活用
検索拡張生成応答の品質は、高品質な関連情報を検索する能力にかかっている。データクリーニング、構造化情報抽出、そしてハイブリッド検索はすべて、検索品質を高める効果的な方法である。最近の研究では、Spladeのようなスパースベクトルモデルが、領域外知識検索、キーワード知覚、意味検索、その他多くの分野において、密ベクトルモデルよりも優れていることが示唆されている。
最近オープンソース化されたBGE_M3 埋め込みモデルは、同じモデル内でスパース、密、コルベールのようなトークンベクトルを生成することができる。この技術革新は、異なるタイプのベクトル間でハイブリッド検索を行うことで、ベクトルデータベースの検索品質を大幅に向上させる。特筆すべきことに、このアプローチは、Zillizのようなベクトルデータベースベンダーの間で広く受け入れられているハイブリッド検索のコンセプトと一致している。例えば、近々リリースされるMilvus 2.4は、密なベクトルと疎なベクトルのより包括的なハイブリッド検索を約束しています。
RAGの性能を向上させるための先端技術の活用
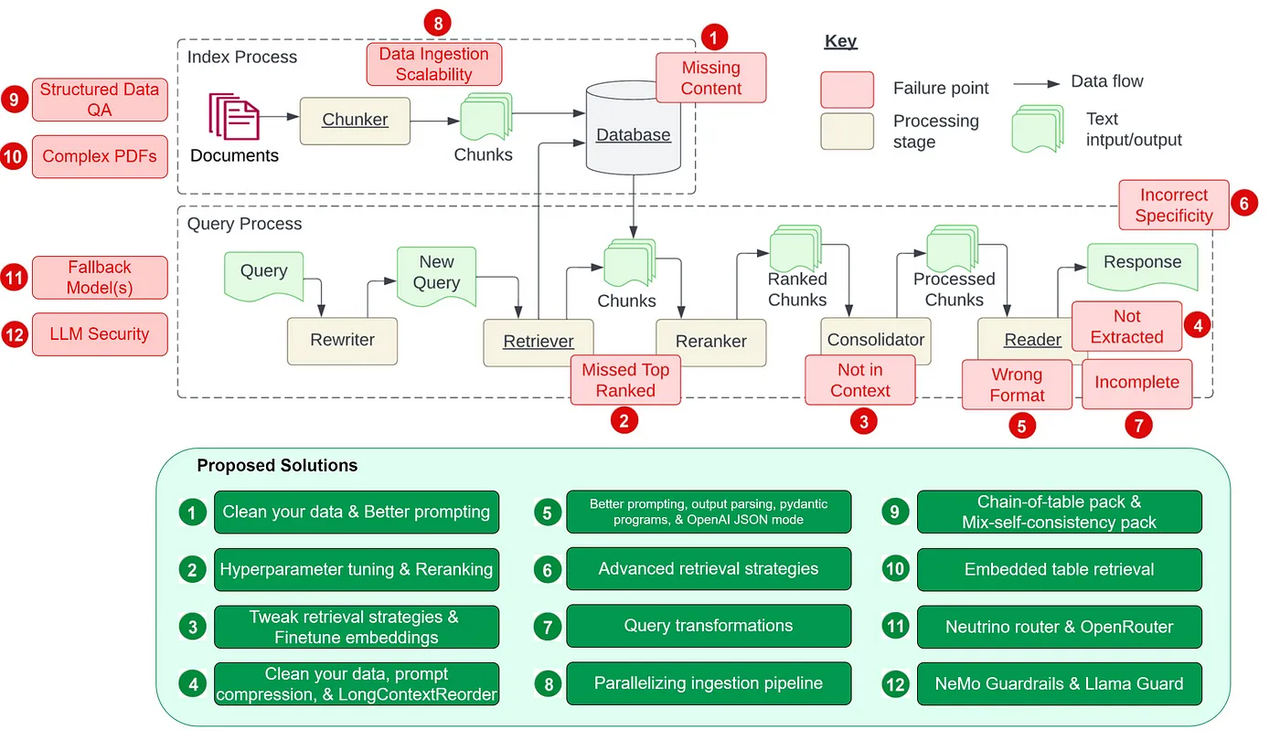
画像ソース:https://towardsdatascience.com/12-rag-pain-points-and-proposed-solutions-43709939a28c_
RAGの能力を最大化するには、アルゴリズムに関する数多くの課題に対処し、高度なエンジニアリング能力と技術を活用する必要があります。Wenqi Glantz氏が彼女のブログで強調しているように、RAGパイプラインの開発には、少なくとも12の複雑な工学的課題があります。これらの課題に対処するには、MLアルゴリズムを深く理解し、クエリの書き換え、意図認識のトレーニングデータ、エンティティ検出のような複雑なテクニックを活用する必要がある。
Gemini 1.5のような高度なモデルでさえ、かなりのハードルに直面している。GoogleのMMLUベンチマークテストで90.0%の精度を達成するためには、32回の呼び出しを必要とする。このことは、RAGシステムにおいてパフォーマンスを最大化することの本質を浮き彫りにしている。
最先端のAI技術の一つであるベクターデータベースは、RAGパイプラインのコアコンポーネントである。Milvus](https://zilliz.com/what-is-milvus)のような、より成熟した先進的なベクトルデータベースを選択することで、RAGパイプラインの機能を、回答生成から、分類、構造化データ抽出、複雑なPDF文書の処理のようなタスクにまで拡張することができます。ベクターデータベースのこのような多面的な機能強化は、より幅広いアプリケーションのユースケースにおいてRAGシステムの適応性に貢献します。
結論RAGは、AIアプリケーションの持続的な成功のための要であり続ける。
大規模な言語モデルは世界を再構築しているが、我々の世界の基本原理を変えることはできない。計算、メモリ、外部データストレージの分離は、1945年にフォン・ノイマン・アーキテクチャが登場して以来存在している。しかし、シングル・マシンのメモリがテラバイト・レベルに達した今日でも、SATAとフラッシュ・ディスクは、さまざまなアプリケーションのユースケースで重要な役割を果たしています。これは、技術の進化に直面しても、確立されたパラダイムの回復力を示しています。
RAGフレームワークは、依然としてAIアプリケーションの持続的成功のための要である。大規模言語モデル用の長期メモリの提供は、クエリの品質と費用対効果の最適なバランスを求める開発者にとって不可欠である。大企業がジェネレーティブAIを導入する際、RAGは応答品質を損なうことなくコスト管理を行うための重要なツールである。
大容量メモリの開発がハードディスクドライブを追い出すことができないように、RAGの役割は、ベクトルデータベースのようなサポート技術と相まって、不可欠かつ適応的であり続ける。RAGは、AIアプリケーションと情報検索という進化し続ける新しいデータの中で耐え、共存する態勢を整えている。

読み続けて

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.