




LLMワークフローを合理化するIBMデータ準備キットのご紹介
大規模言語モデル(LLM)は、ヘルスケア、小売、eコマース業界で広く採用され、全体で数十億ドルの収益を上げている。これらのLLMの成功を支える重要な要素は、LLMが学習するデータである。これらのモデルの一般的な知性は、使用されるデータの量、質、多様性に依存するため、効率的な前処理を確保することが重要になる。
最近Zillizが主催したNYC Unstructured Data Meetupでは、IBM ResearchのシニアエンジニアであるSantosh Borseが、LLMワークフローのデータ準備プロセスを合理化するために彼らが作成したオープンソースのDPK(Data Prep Kit)について語った。彼は、データ品質に関して直面した課題と、それにどのように取り組んだか、そしてオープンソースのDPKを実装するためのパイプラインについて議論した。
このブログでは、DPKがどのようにMilvusと統合され、セマンティック検索やRAG(Retrieval Augmented Generation)のようなアプリケーションに活用できるのか、そのポイントを紹介する。
Data Is the New Oil!「データは新しい石油である」-この言葉は、LLMの成長にも当てはめることができます。石油が経済を動かすように、データはLLMの成功の源である。
ここでは、OpenAIのGPTモデルなど、多くのLLMがLLMトレーニングのためのデータを抽出するために活用しているデータソースのリストを紹介します。
コモン・クロール**:ペタバイトのデータを含む巨大なデータソースで、約2500億のウェブページに相当します。また、他の多くのデータセットのスーパーセットでもある。このデータは、汎用言語モデルの基礎ソースとして機能する。
処理済みデータセット**:C4、The Pile、Red Pajama、Wikipediaは、特定のタスクに合わせた高品質なキュレーションデータを提供しています。
ドメイン固有データ**:ドメイン固有のデータは、より的を絞ったユースケースに対応するために利用することができる。例えば、文学分析のためのBookCorpus、数学的問題解決のためのMathQA、コーディング関連のタスクのためのStarCoderなどがあります。
HuggingFace**:210K以上のデータセットがあり、タスクを微調整するためのカスタマイズが可能です。
あなた自身のデータLLMは通常、自社データとオープンソースデータの組み合わせでトレーニングされる。
データ品質が鍵!
データの質を確保することは、LLMの最適なパフォーマンスを得るための最も重要なステップです。トレーニングデータを処理する際に考慮すべき重要な点は以下の通りです:
モデルの汎化のために学習するのに十分な情報があることを保証するために、データは様々な情報を含み、様々なソースから得られるべきである。
言語パターン**-LLMを言語やドメインにまたがってより一般化できるように、データには多様な言語パターンが存在すべきである。
オーバーフィッティング vs. アンダーフィッティング**-インターネット上の100ページ以上にニュースが掲載されている場合、モデルはそれらのページすべてで学習されるため、その特定のデータではオーバーフィッティングを引き起こす。対照的に、他のニュースではアンダーフィットとなる。したがって、両者のバランスを保つ必要がある。
バイアス**-ジェンダーや文化的ステレオタイプなど、学習データのバイアスは、LLMに有害な出力を伝播する可能性がある。したがって、バイアスの軽減は重要な前処理ステップである。
個人情報**-個人情報は、個人のプライバシーとセキュリティを保護するために、符号化または削除されるべきである。
有害データ**-有害な内容(罵倒、冒涜、ヘイトスピーチ)を含むデータは、モデルの出力の倫理的・専門的水準を維持するために削除されるべきである。
| 悪いデータ | **良いデータ |
|---|---|
| 重複しているデータ | |
| 誤字・スペルミス|正確で間違いがない|一貫性がない|一貫性がある | |
| 一貫性がない |
| 毒性|安全・安心|... | ... | ... |
表良いデータと悪いデータ
データの質が悪いままだと、LLMを効果的に訓練するのに必要な計算コストと時間が増大する。
データのクリーニング
データクリーニングはLLMデータの前処理に欠かせないもう一つのステップである。これは、学習データに矛盾や不正確さ、無関係な情報がないことを保証する。以下はデータクリーニングの主なステップである。
図-データクリーニングの例.png](https://assets.zilliz.com/Figure_Data_Cleaning_Examples_fb202571ed.png)
図データクリーニングの例
重複排除**-データセットのエントリーが重複していると、トレーニング結果が歪み、非効率的なリソース利用やオーバーフィッティングにつながる可能性がある。
品質フィルター**-一貫性のないデータ(例えば、同じ文の中に2つの言語がある)を削除し、欠損値をインプットし、フォーマットを正規化し、不要なパターンやテキストを削除し、データをさらに純化するフィルター。
コンテンツフィルター***-有害または偏ったデータは、特定の有害な単語を、誰にとってもより包括的な節度ある倫理的な単語に置き換えることによってフィルターされます。
プライバシーの削減***-個人を特定できる情報(PII)は、個人または組織のデータのプライバシーを保護するために、特定のキーワードでエンコードされます。
ルールに基づくクレンジング***-タイプミス、不要な句読点、書式の問題などに関するエラーを除去するために、特定のルールが設定されます。
##データ準備キットとIBM Graniteモデルのためのデータ・ジャーニー
データ品質に関する主要な問題点とデータクリーニングによる対処について話した後、Santosh Borse氏は、以下に示すように、独自のIBM Graniteモデルのデータ処理の旅について話した。彼はまた、いくつかの前処理ステップを経た後のデータ量(最終的にはトレーニング用に2.5兆トークン)についての興味深い統計についても言及した。生データの70%以上は無駄であり、これはデータの前処理とクリーニングが重要なステップであることを意味する。
Data Prep Kit (DPK)](https://github.com/IBM/data-prep-kit)はIBM Researchによるオープンソースのツールキットで、LLM対応アプリケーションを構築する開発者のために非構造化データの準備を効率化するように設計されている。これは、ファインチューニング、命令チューニング、検索拡張生成(RAG)などのユースケースに合わせて調整されており、多様なデータ処理の課題を管理するためのモジュール式でスケーラブルなソリューションを提供する。DPKは、GraniteオープンソースLLMモデルの事前学習データセットを作成する上で有益かつ効果的であった。
DPK ワークフロー
データ準備キット(DPK)は、コードと言語データ用に設計された再利用可能な変換(モジュール)により、データ準備を簡素化する。また、画像、音声、マルチモーダルデータへのサポート拡大も構想されています。DPKは、開発者が基礎となるフレームワークやランタイムに関する深い知識を必要とせずに、データ処理を迅速に開始できる高レベルのAPIを提供します。
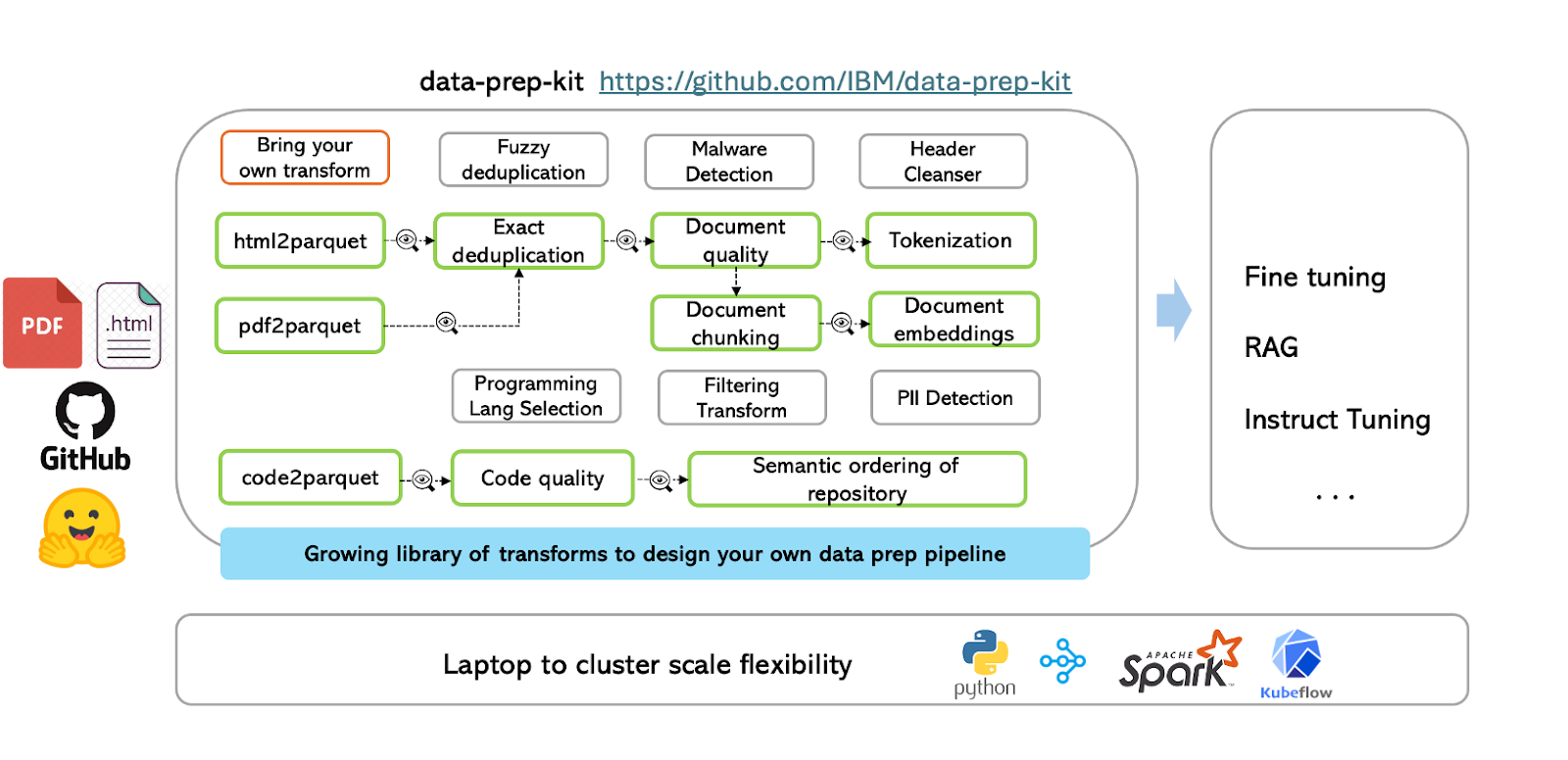 図- データ準備キットワークフロー.png
図- データ準備キットワークフロー.png
図データ準備キットのワークフロー
ワークフローは、まず入力ファイル(HTML、PDF、コードなど)を標準化されたParquet形式に変換し、一貫したデータスキーマを確保します。DPKの中核には堅牢なデータ処理ライブラリがあり、ユーザーは定義済みまたはカスタムの変換を適用し、複数の変換を連結して体系的にデータを処理できます。例えば、テキストデータは厳密な重複排除を経て、文書の品質分析やトークン化、文書のチャンキングや埋め込み生成などのステップに進むことができます。
その結果得られる文書埋め込みは、モデルの微調整、RAGパイプラインの実装、インストラクションチューニングなどの高度なアプリケーションに活用できる。データ準備プロセスを自動化・標準化することで、DPKは開発者がAIモデルの構築と改良に集中できるようにし、ラップトップからクラスタベースの環境まで容易に拡張できるようにします。
DPKはまた、特定のニーズに合わせてカスタム変換を作成・追加することもできます。DPKの使い方は以下の通りです:
新しいトランスフォームのテンプレート**](https://github.com/IBM/data-prep-kit/tree/dev/transforms/universal/noop)
独自のトランスフォームを追加するのに役立つStep-by-Step Tutorial.
最初のカスタムトランスフォームを実装してみる**](https://github.com/IBM/data-prep-kit/blob/dev/examples/notebooks/Run_your_first_transform_colab.ipynb)
包括的なデモ では、1 つのワークフローでドキュメントの前処理ステップをすべて実装できます。
DPKとMilvus for RAGの統合
生データをDPKに通した後、結果はテキスト埋め込みとなり、これをさらにMilvusのようなベクトルデータベースと統合することで、興味深いLLMアプリケーションを作成することができる。DPKとMilvusを統合したRAGパイプラインの例を見てみよう。
Retrieval Augmented Generation (RAG)は、検索と生成の手法を組み合わせることで、LLM出力の精度、関連性、事実の根拠を高める高度な手法である。RAGは、外部データで満たされたMilvusのようなベクトルデータベースから関連する文脈情報を取得するリトリーバと、この文脈を利用して正確で意味のある応答を生成するジェネレータの2つの主要コンポーネントから構成される。
以下は、MilvusとDPKで構築されたRAGパイプラインである。Milvusはこのパイプラインのリトリーバーとして機能し、大規模な外部データを効率的に管理し、照会する。DPKはデータを前処理し、Milvusに格納する前にクリーンで一貫性があり、高品質であることを保証します。LLMはジェネレーターであり、ユーザーのニーズに合わせた正確でコンテキストを意識したレスポンスを生成する。
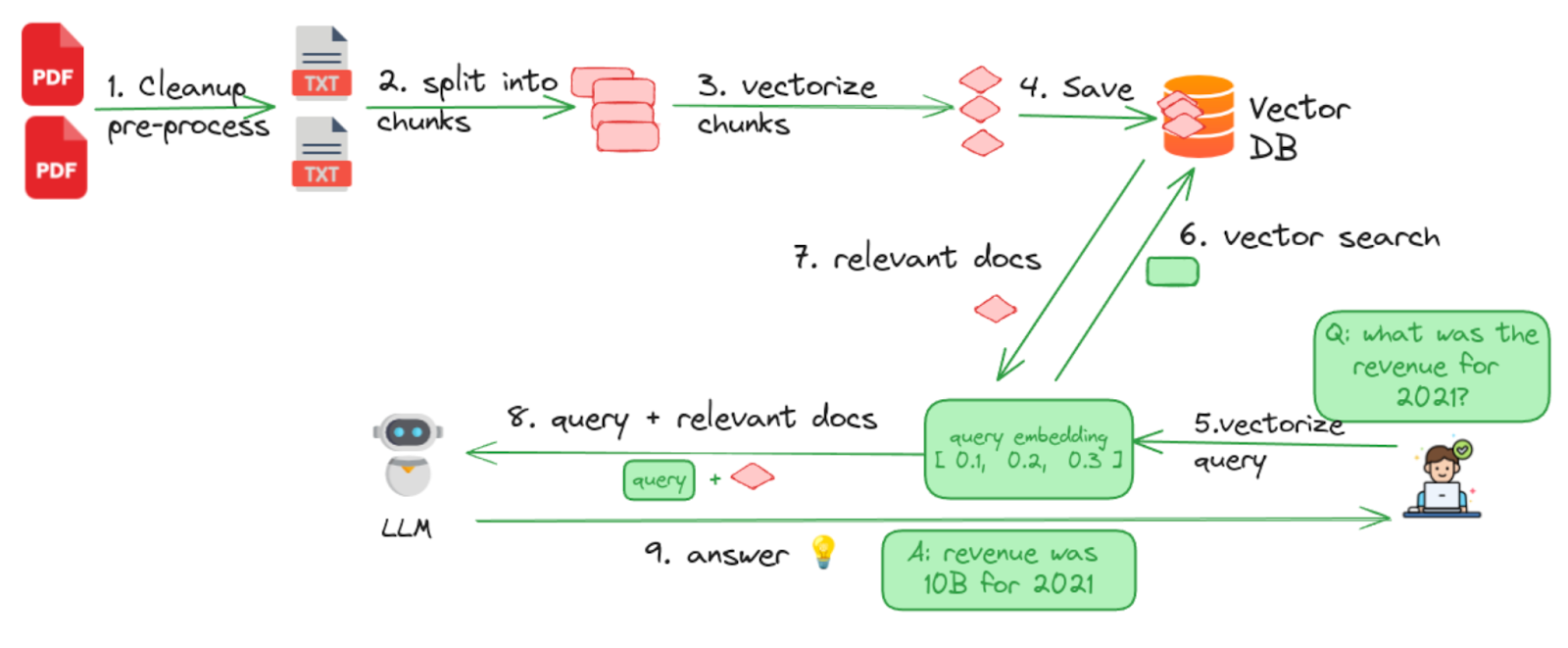 図- Milvus for RAGによるデータ準備キットの全体ワークフロー.png
図- Milvus for RAGによるデータ準備キットの全体ワークフロー.png
図:Milvus for RAGを用いたデータ準備キットの全体的なワークフロー (出典)
1.クリーンアップ文書 - このステップは、マークアップの削除、厳密な重複排除とファジー重複排除の実行など、すべてのデータ前処理機能を実行する。
2.チャンクへの分割 - 様々なチャンキング戦略を使って、ドキュメントを管理しやすいチャンクやセグメントに分割します。ドキュメントはページ、段落、セクションに分割できる。適切なチャンキング戦略は、処理されるドキュメントの種類によって異なります。
3.ベクトル化/生成 埋め込み - 得られたチャンクは、次に埋め込みモデルを使ってベクトル化される。このステップは、テキストを検索可能にするためのものである。
4.データを Milvus ベクトルデータベースに保存する - Milvusはエンコードされた埋め込みをすべて保存し、類似検索に備える。
5.質問をベクトル化する - ユーザが質問をすると、同じ埋め込みモデルを用いてベクトル化される。
6.ベクトル検索** - エンコードされたクエリはベクトル類似検索のためにMilvusに送られる。
7.関連文書の取得 - Milvusはクエリに最も関連性の高いトップK文書を返します。
8.**検索された文書と元のクエリは、LLMの新しいプロンプトを形成するために結合されます。
9.**最後に、LLMはその知識とMilvusベクトルデータベースから取得した文脈情報を使って、より正確な答えを生成する。
上記のワークフローの完全な実装をチェックするには、このチュートリアルをご覧ください。
結論
IBMのオープンソースDPK(Data Prep Kit)は、データの毒性、オーバーフィット、バイアスなどの一般的な課題に取り組むことで、LLMワークフローのデータ前処理を簡素化します。DPKは、20以上のモジュール式変換により、重複排除、フィルタリング、プライバシー保護などの重要なタスクを効率化します。DPKパイプラインは、まずPDFやHTMLなどの生の入力を前処理し、Parquetのような構造化形式に変換します。品質チェック、データクリーニング、埋め込み生成がこのステップに続きます。これらの埋め込みはMilvusのようなベクトルデータベースに保存することができ、微調整やRAG(Retrieval-Augmented Generation)などのアプリケーションをサポートします。
このブログでは、MilvusとDPKを統合することで、文脈に関連した文書の検索が可能になり、LLMの出力が信頼性の高い事実に基づいた回答で強化されることも紹介しました。
関連リソース
DPK GitHub**:https://github.com/IBM/data-prep-kit
ベクトル・データベースに最適化されたデータ・モデリング技法 ](https://zilliz.com/learn/data-modeling-techniques-optimized-for-vector-databases)
VectorDBを用いたエージェントSQL生成における高基数カテゴリデータの飼いならし ](https://zilliz.com/blog/tame-high-cardinality-categorical-data-in-agentic-sql-generation-with-vectordbs)
PII MaskerとMilvusによる安全なRAGの構築](https://zilliz.com/blog/safe-rag-with-hydrox-ai-and-zilliz-pii-masking-for-responsible-genai)
RAGの評価:知っておくべきすべてのこと](https://zilliz.com/blog/evaluating-rag-everything-you-should-know)
MilvusによるマルチテナントRAGの設計: ベストプラクティス](https://zilliz.com/blog/build-multi-tenancy-rag-with-milvus-best-practices-part-one)
読み続けて

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.