




Decoding LLM Hallucinations: A Deep Dive into Language Model Errors
Introduction
As companies and big tech firms create better products using large language models (LLMs), it's important to understand their responsibility in delivering reliable solutions. A significant issue is that these models sometimes produce confident but incorrect information, leading users to mistakenly believe the output is accurate. This issue is known as a hallucination.
Morena, a Data Scientist, delivered an insightful presentation on LLM hallucinations at a recent Unstructured Data Meetup hosted by Zilliz, explaining in depth the concept of hallucinations, types of hallucinations, how they can be harmful, why they occur, and, most importantly, how we can detect these hallucinations.
Watch the replay of Morena’s talk
What are Hallucinations?
Hallucinations are false or contradicting outputs generated by any form of language model. Simply put, content that is factually incorrect, nonsensical, or unfaithful to the input context.
For example, let’s ask Llama3 an intricate question: What other name did Cofounders at State Software discuss for JSON?
Llama3’s answer is as shown below:
 Llama3’s answer to the example question
Llama3’s answer to the example question
Whereas the actual discussion is somewhat different:
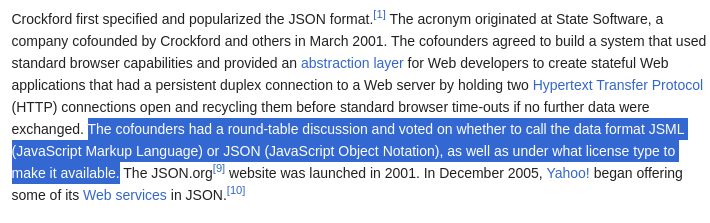 The answer on the Wikipedia page about JSON
The answer on the Wikipedia page about JSON
Llama 3-8B showcases a classic example of hallucination. Let's examine the different types of hallucinations a Language Model can give.
Different Types of Hallucinations
There are two major categories of hallucinations: intrinsic hallucinations and extrinsic hallucinations.
Intrinsic Hallucinations
Intrinsic hallucinations tend to contrast the source information given to them. Imagine yourself in a hurry trying to solve questions for a huge and complex comprehension test. You might get the information wrong and answer some questions incorrectly. Similarly, LLMs tend to hallucinate frequently when the data is highly unstructured, like an extensive text corpus.
Extrinsic Hallucinations
Extrinsic hallucinations occur when LLMs generate information that cannot be verified against the provided source data, often resulting in fabricated details. To effectively manage extrinsic hallucinations, prompt the LLM to use the given information only for completing tasks. This approach is especially beneficial in Retrieval-Augmented Generation (RAG) pipelines. Laurie Voss emphasized this practice during a Zilliz Unstructured Data Meetup, highlighting its importance in maintaining accuracy.
Below is a prompt example for addressing extrinsic hallucinations.
prompt = f"""Only using the Context Provided to you and not any outside knowledge, Answer the user query.
Context: {Wikipedia_Page_Content}
Query: Summarize me this Page"""
# Rather than just
prompt = f"""Summarize me this Page
{Wikipedia_Page_Content}"""
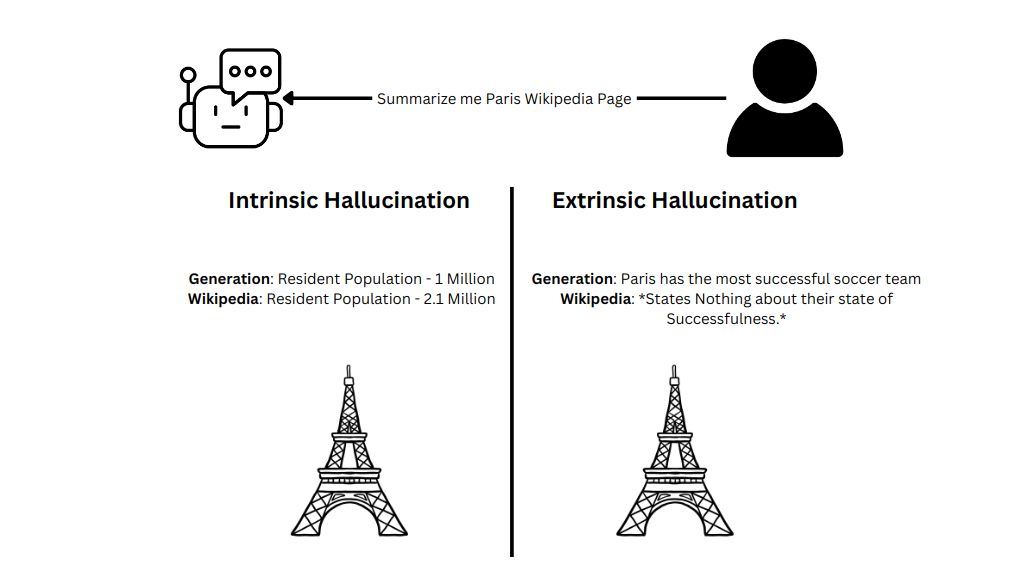 An Example of Intrinsic vs. Extrinsic Hallucination
An Example of Intrinsic vs. Extrinsic Hallucination
Problems with LLM Hallucinations
Hallucinations, which may initially seem harmless or even humorous, pose significant challenges when deploying LLMs in industries like law and healthcare. In these sectors, the accuracy of information generated by Generative AI models is critical for ensuring positive outcomes. When these models produce inaccurate outputs, it can lead to serious consequences such as incorrect legal decisions or compromised patient care, potentially endangering lives.
Moreover, beyond their impact on specific industries, hallucinations generated by LLMs can have far-reaching societal implications. They undermine trust in reliable information sources and contribute to widespread confusion and mistrust among the public. This erosion of trust can be particularly damaging during critical events like elections.
For instance, during election periods, misinformation spread by LLMs about candidates, voting procedures, or election results can significantly influence democratic processes. False information may mislead voters about where and when to vote, potentially suppressing voter turnout and affecting election outcomes. Furthermore, misinformation can escalate tensions, leading to social unrest and even violence, as seen in situations where unfounded claims of election fraud have sparked protests and confrontations.
Why do LLMs Hallucinate?
LLMs lack a concept of ground truth; their outputs are determined by complex mathematical operations like matrix multiplications and softmax functions, which calculate probabilities for each token in a sequence based on preceding tokens. These probabilities dictate the sequence generated by the LLM, but what influences these probabilities?
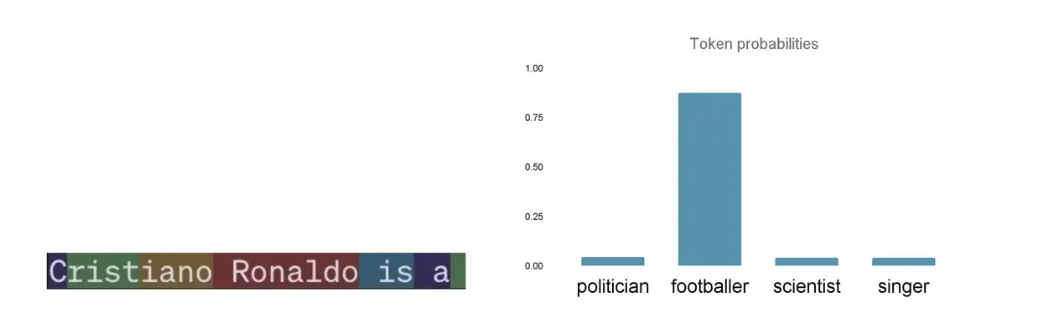 Token probabilities for a given string
Token probabilities for a given string
Contradicting or False Information in Training Data
Foundation models are trained on vast amounts of unstructured data, including Wikipedia pages, subreddits, tweets, Stack Overflow and MathOverflow threads, GitHub repositories, and numerous other internet sources. This training doesn't aim to ensure the model produces meaningful outputs from the start; instead, it builds foundational knowledge stored as tensors and generates coherent outputs.
However, not all data found on the internet is accurate. Misinformation and misleading content, such as from specific subreddits or tweets, can influence the model during training. This problem can lead to inconsistencies in the model's weights and result in distorted probability distributions, ultimately causing hallucinations in its outputs.
Complexity of Tasks
The nature of tasks also influences whether an LLM is prone to producing false or nonsensical outputs. Simple tasks like answering straightforward questions are less likely to result in hallucinations. However, LLMs can struggle and produce highly nonsensical outputs when faced with more complex tasks, such as summarizing extensive text passages or analyzing tabular data provided in markdown format.
 Simple vs. Complex Task
Simple vs. Complex Task
Detecting Hallucinations
Several methodologies are used to detect LLM hallucinations: self-evaluation, reference-based detection, uncertainty-based detection, and consistency-based detection. Let's explore some of these methodologies in detail.
 Hallucination detection methods
Hallucination detection methods
Self-evaluation
Self-evaluation is a process where the LLM assesses its outputs, which may initially seem counterintuitive, given that hallucinations often originate internally within the model. However, this method remains valuable because evaluating the quality of a response is inherently easier than generating the response itself. Simpler tasks, like answer assessment, are less prone to hallucinations than more complex tasks, such as response generation to intricate queries. This is because LLM's ability to gauge the correctness and coherence of a response is less challenging than its capacity to generate entirely new information accurately.
Moreover, integrating self-evaluation with other detection methods, such as reference-based or consistency-based approaches, enhances the LLM's ability to assess its outputs comprehensively. This combined approach strengthens the model's capability to effectively identify and mitigate potential hallucinations, thereby improving the overall reliability and credibility of the generated content.
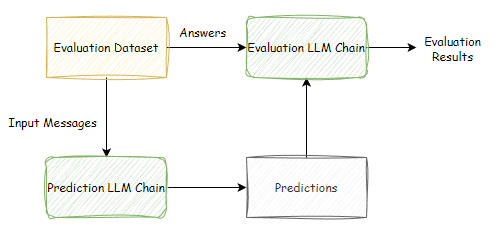 A basic Workflow for LLM’s Evaluating themselves
A basic Workflow for LLM’s Evaluating themselves
Reference-based Methods
Reference-based methodology evaluates the consistency of generated outputs against provided references, making it particularly useful in production environments utilizing Retrieval Augmented Generation (RAG) and tasks like summarization.
Providing source knowledge as references allows the LLM to generate outputs that align closely with the given references. Consider the task of summarizing a Wikipedia page about Paris. Using reference-based methods, the LLM can generate summaries evaluated against the original content to ensure accuracy and coherence.
Performance metrics such as BERTScore or ROUGEScore are commonly used to evaluate LLM performance on specific tasks. They provide quantitative measures of how well the generated outputs match the references. Additionally, incorporating self-evaluating layers further enhances the reliability and effectiveness of reference-based evaluation methods.
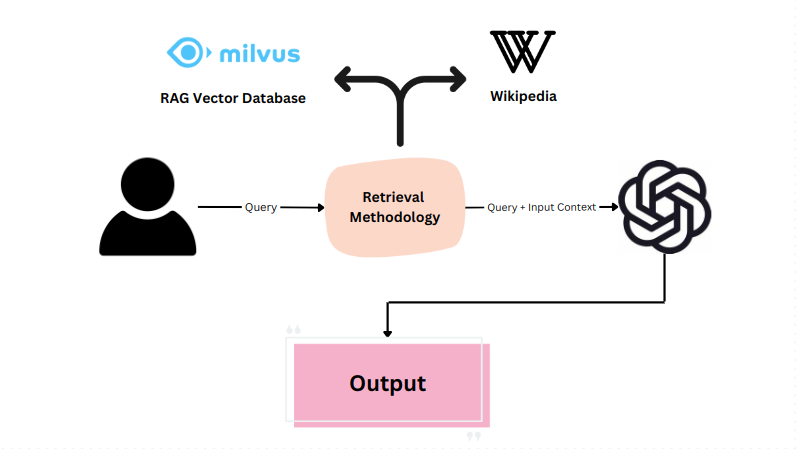 A Systematic Workflow for Context Based-Retrieval
A Systematic Workflow for Context Based-Retrieval
Uncertainty-based Methods
Remember how we previously observed LLMs confidently producing incorrect outputs? Well, under the surface, this isn't always the case when it comes to hallucinations. Hallucinations can occur due to uncertain probability distributions where a token is ranked slightly higher than the "best" ground truth token, leading to a faulty generation of outputs.
To analyze token probabilities, you can leverage Hugging Face class methods. These methods allow you to examine the probabilities associated with token generation, providing insights into how the model makes decisions and potentially identifying instances where hallucinations occur.
from transformers import GPT2Tokenizer, AutoModelForCausalLM
import numpy as np
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer.pad_token_id = tokenizer.eos_token_id
inputs = tokenizer(["Today is"], return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=5, return_dict_in_generate=True, output_scores=True)
transition_scores = model.compute_transition_scores(
outputs.sequences, outputs.scores, normalize_logits=True
)
input_length = inputs.input_ids.shape[1]
generated_tokens = outputs.sequences[:, input_length:]
for tok, score in zip(generated_tokens[0], transition_scores[0]):
# | token | token string | logits | probability
print(f"| {tok:5d} | {tokenizer.decode(tok):8s} | {score.numpy():.4f} | {np.exp(score.numpy()):.2%}")
# Expected output:
#| 262 | the | -1.4136 | 24.33%
#| 1110 | day | -2.6089 | 7.36%
#| 618 | when | -2.0096 | 13.40%
#| 356 | we | -1.8593 | 15.58%
#| 460 | can | -2.5083 | 8.14%
You can try this method with closed-source models like gpt-4 via logprobs.
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": "Hello!"}
],
logprobs=True,
top_logprobs=2
)
print(completion.choices[0].logprobs)
The output for logprobs is like the JSON below.
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1702685778,
"model": "gpt-4o",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello!"
},
"logprobs": {
"content": [
{
"token": "Hello",
"logprob": -0.31725305,
"bytes": [72, 101, 108, 108, 111],
"top_logprobs": [
{
"token": "Hello",
"logprob": -0.31725305,
"bytes": [72, 101, 108, 108, 111]
},
{
"token": "Hi",
"logprob": -1.3190403,
"bytes": [72, 105]
}
]
},
{
"token": "!",
"logprob": -0.02380986,
"bytes": [
33
],
"top_logprobs": [
{
"token": "!",
"logprob": -0.02380986,
"bytes": [33]
} ]
}, "finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 2,
"completion_tokens": 2,
"total_tokens": 4
},
"system_fingerprint": null
}
Consistency-based Detection
Consistency-based detection is a straightforward yet effective method for identifying LLM hallucinations. This approach involves querying the LLM with the same question multiple times and comparing its responses. Consistent outputs across repeated queries indicate a lower likelihood of hallucinations, whereas inconsistent responses suggest potential issues.
Below is an example Morena shared during his talk, where he repeatedly asked the LLM three questions.
ronaldo_prompt = "Give me three facts about Cristiano Ronaldo."
toaster_prompt = "Give me an absurd fact about toasters."
seinfeld_prompt = "In what episode of Seinfeld did Kramer buy a giant hat?"
Setting up the prompts:
ronaldo_passages = []
for i in range(3):
prompt = ronaldo_prompt
result = chat_gpt_prompt(prompt).choices[0]-message.content
ronaldo passages.append(result)
toaster_passages = []
for i in range(3):
prompt = toaster_prompt
result = chat_gpt_prompt(prompt).choices[0].message.content
toaster_passages.append(result)
seinfeld_passages = []
for i in range(3):
prompt = seinfeld_prompt
result = chat_gpt_prompt(prompt).choices[0].message.content
seinfeld_passages.append(result)
In this example, querying about Cristiano Ronaldo, whose information is ingrained in the LLM training data, tends to yield consistent outputs with minimal hallucination risks. This consistency demonstrates the model's reliability in generating accurate responses for well-established topics.
 The answer generated by the LLM about Cristiano Ronaldo
The answer generated by the LLM about Cristiano Ronaldo
However, the case differs for Seinfeld passages as Kramer never bought a “Giant Hat.”
 The answer generated by the LLM about Giant Hat
The answer generated by the LLM about Giant Hat
Conclusion
As more businesses use large language models (LLMs) for production applications, it's vital to consistently address their challenges. Hallucinations, if left unchecked, can become increasingly detrimental. We can minimize their effects by understanding their origins, triggers, and detection strategies.
This post has explored the concept of hallucinations and their potential triggers. Additionally, we introduced four practical methods for detecting hallucinations: self-evaluation, reference-based methods, uncertainty-based methods, and consistency-based detection. These methods cater to different use cases and can be combined to enhance the precision of hallucination detection.
 Comparing different hallucination detection methods
Comparing different hallucination detection methods
Implementing these approaches ensures the responsible deployment of LLMs and other generative AI technologies, maximizing their positive impact on society.
Keep Reading

Introducing Customer-Managed Encryption Keys (CMEK) on Zilliz Cloud
We're announcing the general availability of Customer-Managed Encryption Keys (CMEK) on Zilliz Cloud.

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.