




クラウドからエッジへの非構造化データ処理
非構造化データは現在、私たちが扱うデータの約80%を占めており、テキストや画像からビデオ、オーディオ、さらに複雑なフォーマットまで多岐にわたる。その量が増えるにつれて、それを処理・分析するためのより良い方法が必要とされている。
最近のウェビナーで、Zillizのプリンシパル・デベロッパー・アドボケイトであるTim Spann は、特にクラウド環境からエッジ・デバイスまでの非構造化データの管理に関する彼の洞察を共有した。彼はまた、Milvusのようなベクトル・データベースが、このデータの意味を理解する上でいかに重要であるかを強調した。
この投稿では、ティムの主なポイントを要約し、非構造化データの取り扱いにおける課題と、ベクトル・データベースがどのようにその方法をリードしているかについて議論する。また、これらのデータベースを搭載したエッジ・デバイスが、AIの新たな進歩をどのように促進するかについても見ていく。より詳細にご興味のある方は、YouTubeでのティムの講演の完全リプレイをご覧になることをお勧めします。
非構造化データを理解する非構造化データとは、あらかじめ定義されたフォーマットやスキーマを持たない情報のことです。構造化データとは、特定のフィールドやフォーマットを持つデータベースできちんと整理されたデータのことで、構造化されていないデータは未加工で整理されていません。多くの場合、以下のようなものが含まれる:
テキスト:**電子メール、ワード文書、ソーシャルメディアへの投稿
画像:**写真、スクリーンショット、図表
ビデオ:**会議記録、監視カメラ映像、マルチメディアコンテンツ
音声:**音声録音、音楽ファイル、ポッドキャスト
デジタルコンテンツの急増に伴い、非構造化データは指数関数的に増加し、組織にチャンスと課題の両方を提供している。この豊富な情報を活用するために、企業は以下のことができる:
顧客とのやり取りやフィードバックを分析することで、カスタマー・エクスペリエンスを向上させる。
センサーデータやシステムログからの洞察による業務効率の向上
製品開発にマルチメディアコンテンツを活用することで、イノベーションを推進する
従来のデータベースは、構造化されたデータを扱うように設計されていますが、非構造化データの不規則性に苦戦し、検索、クエリ、意味のある洞察の抽出が困難になっています。そこでベクトル・データベースが不可欠となり、非構造化情報を効率的に管理・検索するソリューションを提供します。
なぜ非構造化データ処理にベクトルデータベースを使うのか?
ベクトルデータベース**](https://zilliz.com/learn/what-is-vector-database)は、データのベクトル表現(ベクトル埋め込みとしても知られる)を保存、索引付け、照会するために設計された特殊なデータベースで、テキスト、画像、音声などの非構造化データから派生することが多い。これらのデータベースは、高次元空間での効率的な類似検索を可能にし、意味検索、自然言語処理(NLP)、推薦システム、画像検索、検索拡張生成(RAG)に最適である。
Milvus](https://zilliz.com/what-is-milvus)やZilliz Cloudなどのベクターデータベースは、高性能な検索機能以外にも様々な機能を提供しており、非構造化データの管理には欠かせない。
高性能検索を超えて
ベクトル・データベースは、しばしば高速な類似検索機能を連想させるが、その有用性はさらに広範囲に及ぶ。ベクトルデータベースは、非構造化データの効果的な管理と利用を保証する、その他の重要な機能を提供します:
CRUDオペレーション**である:ベクターデータベースは、従来のデータベースと同様に、データの作成、読み取り、更新、削除(CRUD)が可能です。これにより、複雑なデータ型を扱うにもかかわらず、基本的な操作は直感的でアクセスしやすいままです。
データの鮮度ベクターデータベースの強みの一つは、データを常に最新の状態に保つことです。レコメンデーションシステムのようなユースケースでは、データを最新に保つことが正確なインサイトを生成するために不可欠です。
永続性**:インメモリデータ構造とは異なり、ベクターデータベースは永続的なストレージを提供します。
可用性**](https://zilliz.com/learn/ensuring-high-availability-of-vector-databases):ベクターデータベースは、リアルタイムのクエリや検索が可能です。これにより、データが増大しても、高速で効率的な検索が可能になり、AI主導の意思決定を滞りなく行うことができます。
スケーラビリティ**](https://zilliz.com/learn/scaling-vector-databases-to-meet-enterprise-demands):データ量が増大しても、ベクトル・データベースはパフォーマンスを低下させることなく、効率的に拡張してデータの増大に対応します。これは、何十億もの非構造化データを管理する際に不可欠です。
完全なデータ管理
ベクターデータベースは、上記の機能以外にも、データの取り込み、インデックス作成、クエリなど、非構造化データを管理するための堅牢なツールを提供しており、最大規模のデータセットでも効率的に検索・分析することができます。また、バックアップとマイグレーションなどの機能により、データの安全性と復元性を確保し、ベクターデータベースは重要な情報を管理するための信頼できる選択肢となります。
運用のしやすさ
ベクターデータベースは、導入と管理を簡素化するように設計されています:
クラウドまたはオンプレミスの展開**:多くの目的別ベクターデータベースは汎用性が高く、パブリッククラウドやオンプレミスインフラに簡単に導入できるため、組織のニーズに応じた柔軟性を確保できます。
監視性**:多くのベクターデータベースは、データベースの健全性とパフォーマンスを追跡するための監視ツールを提供しており、ユーザーはシステムをプロアクティブに最適化することができます。
マルチテナント**](https://docs.zilliz.com/docs/use-pipeline-in-llamaindex?_highlight=multi&_highlight=tenancy#multi-tenancy):Zilliz Cloudのようなベクターデータベースは、複数のユーザーやアプリケーションをサポートし、各テナントの安全なアクセスと分離されたデータ処理を保証します。そのため、複数のチームが独立したデータ環境を必要とする大規模な導入に最適です。
非構造化データ管理におけるMilvusの役割
Milvusはオープンソースのベクトルデータベースで、高次元のベクトルを10億単位で効率的に保存、インデックス付け、検索できるように設計されており、推薦システム、画像認識、retrieval-augmented generation (RAG)などのAIや機械学習を含むユースケースに最適である。
Milvusは、多様化する顧客ニーズに対応するため、複数の導入オプションを提供している。
オープンソースのMilvus**:オープンソースであり、自己管理型であり、コミュニティのサポートがあればどのマシン上でもホスト可能である。また、Milvusは、Milvus Lite、Milvus Standalone、Milvus Distributedなど、様々なニーズや環境に対応した複数の導入オプションを提供しています。詳細はMilvus documentationを参照してください。
クラウド向けに再設計されたMilvusのフルマネージド版であり、AWS、GCP、Azureのような主要なパブリッククラウド上で利用可能です。
Zilliz BYOC: エンタープライズ対応のプライベートVPC向けMilvusで、お客様の仮想プライベートクラウドに導入することができます。
図1- Milvusの導入方法.png](https://assets.zilliz.com/Fig_1_Ways_of_deploying_Milvus_fd36c0f3c1.png)
図1:ミルバスの配備方法
Milvusの主な特徴
Milvusは高いパフォーマンスとスケーラビリティを実現するために設計されており、以下のような機能を提供しています:
図- Milvusの主な特徴.png](https://assets.zilliz.com/Figure_Milvus_key_features_de57519bcb.png)
図:Milvusの主な特徴
マルチテナント**:Milvusは、複数のユーザまたはアプリケーションが互いに干渉することなく同じシステム上で作業することを可能にし、分離されたデータへの安全なアクセスを提供します。
ハードウェア・アクセラレーテッド・コンピュート**:GPUのようなハードウェアを活用するように最適化されており、AIモデル推論のようなリソース集約的なタスクをより高速かつ効率的に実行できます。
言語とAPIのサポート**:Milvusは汎用性が高く、Python、Java、Golang、NodeJSなどをサポートしており、幅広い開発者が利用できます。
スケーラブルで弾力的なアーキテクチャ**:Milvusは、増大するデータニーズに対応できるように設計されています。需要に応じて自動的に拡張され、データが増大しても最適なパフォーマンスを維持します。
多様なインデックスのサポートHNSW、PQ、Binary、DiskANNを含む複数のタイプのインデックスをサポートしており、データの保存方法や検索方法を柔軟に変更することができます。
調整可能な一貫性**:Milvusではデータの一貫性レベルを調整することができ、アプリケーションのニーズに応じてパフォーマンスとデータ精度のバランスをとることができます。
より詳細な情報については、Milvus ドキュメント をご参照ください。
様々なユースケースでMilvusを支えるテクノロジー
Milvusは、様々なアプリケーションに対応し、様々な環境においてパフォーマンス、柔軟性、スケーラビリティを確保するためのテクノロジー群によって支えられています:
図- 様々なユースケースに対応するMilvusのテクノロジー.png](https://assets.zilliz.com/Figure_Milvus_technologies_for_various_use_cases_e33edc8ced.png)
図: 様々なユースケースにおけるMilvusの技術
1.**コンピュート・タイプMilvusは、AVX512(高速コンピューティング用CPU命令セット)、SIMD(Single Instruction, Multiple Data)用Neon、GPUアクセラレーションなど、さまざまなハードウェア環境に最適化されています。これにより、Milvusは高性能ハードウェアを使用して、高速処理とコスト効率の高いスケーラビリティを実現します。
2.**検索タイプMilvusは、最も類似したデータポイントを見つけるためのtop-K ANN (Approximate Nearest Neighbors)、範囲ANN、スパース&密集検索、フィルタリング検索など、幅広い検索方法をサポートしています。これらの機能により、類似した画像、動画、テキストを特定するなど、アプリケーションの特定のニーズに合わせて検索機能を調整することができる。
3.マルチテナント:Milvusはコレクションとパーティション管理をサポートし、マルチテナンシーを可能にします。この機能により、異なるチームやアプリケーションがお互いのデータに干渉することなく同じデータベースを共有することができ、安全で分離されたデータの取り扱いが保証されます。
4.**インデックスタイプMilvusは、高速検索のためのHNSW (Hierarchical Navigable Small Worlds) 、コンパクトなストレージのためのPQ (Product Quantization) 、膨大なデータセットを扱うためのDiskANN など、15種類のインデックスタイプを幅広く提供しています。ユースケースに応じて、パフォーマンス、精度、コストのバランスが最も良いインデックスタイプを選択することができる。
これらの技術により、Milvusは大規模なクラウドの展開からリソースに制約のあるエッジデバイスまで、幅広い用途に適しています。
エッジコンピューティングへのシフト
非構造化データからのリアルタイムの洞察に対する需要が高まるにつれ、多くの企業はクラウド環境だけに頼っていては不十分であることに気づく。エッジ・コンピューティングでは、データが生成された場所で処理が行われるため、タイムセンシティブなAIアプリケーションに明確なメリットをもたらす。
エッジ・コンピューティングとは、データが生成された場所の近くでデータを処理することを指し、多くの場合、センサー、カメラ、IoTデバイスなどのエッジ・デバイス上で行われる。エッジコンピューティングでは、未加工のデータを中央のデータセンターに送って処理する代わりに、デバイス自体や近くの場所で計算を行うことができます。
強力なエッジ・デバイスの利用可能性が高まるにつれ、機械学習やAIモデルをこれらのデバイス上に直接展開することが可能になった。このアプローチにより、自律走行車、スマートシティ、産業オートメーションなどのアプリケーションでリアルタイムの意思決定が可能になる。
なぜエッジでデータを処理するのか?
非構造化データをエッジで処理することには、いくつかの利点がある:
低遅延:低レイテンシー:データはソースの近くで処理されるため、結果を得るまでの遅延は最小限です。
帯域幅の削減**:データをローカルで処理することで、大量の生データをクラウドに送り返す必要性が減ります。
プライバシーとセキュリティ機密データをエッジ・デバイスに残すことができるため、送信中に漏洩するリスクを最小限に抑えることができます。
エッジAIとベクトル・データベース
エッジ・コンピューティングは、センサーやカメラ、Raspberry Piのような小型デバイスのデータ処理をよりソースに近いところで行うが、これらのデバイスが増え続ける非構造化データをリアルタイムで処理できるようにするのは、ベクター・データベースである。
例えば、産業環境では、エッジデバイスが機械の性能を監視し、センサーデータを使って潜在的な問題を検出する。Milvusのようなベクトルデータベースは、エッジデバイスが入力データを過去のパターンと迅速に比較し、メンテナンスの必要性を示す異常を特定することを可能にする。ベクトル・データベースがなければ、エッジ・デバイスはすべての生データをクラウド・サーバーに送って処理するか(遅延とコスト増を招く)、重要な洞察を見逃すリスクがある。
Milvus Lite:AI機能でエッジデバイスを強化
Milvus LiteはMilvusの軽量版で、エッジデバイスのようなリソースに制約のある環境向けに特別に設計されている。Milvusは、ベクターデータベースの基本的な機能をすべて備えていますが、より小型で性能の低いハードウェアでの展開に最適化されています。このため、リソースが限られた環境であっても、エッジデバイスに複雑なAIタスクを処理させるのに理想的なソリューションです。
エッジデバイス上でMilvus Liteを実行すると、デバイスはAIを搭載したデータプロセッサーに変わります。この組み合わせにより、エッジデバイスはローカライズされた画像認識、動画類似検索、あるいは自然言語処理を実行することができる。例えば小売店では、Milvus Liteを搭載したスマート・チェックアウト・システムが商品を即座に認識し、保存された商品のベクトル・データベースと照合することで、クラウドベースのシステムを必要とせずに取引をスピードアップすることができる。
Raspberry Pi上で動作するエッジ・デバイスにMilvusを搭載した実例を見てみよう。
Raspberry PiとMilvusによるリアルタイム姿勢推定システムの構築
Raspberry Pi は、Raspberry Pi Foundationによって開発された、小型で手頃な価格のシングルボードコンピュータのシリーズです。この例では、Raspberry Piをエッジデバイスとして、Milvus Liteを非構造化データの処理に使用します。
このポーズ推定システムは、ビデオストリームをキャプチャし、それらを処理して人間のポーズを推定し、抽出された特徴ベクトルをMilvusに保存して効率的な類似検索を行う。さらに、特定のポーズが検出されたときにアラートを出す通知用のSlackを統合します。
この例のソースコードはGitHubのTim's notebookで確認できます。
前提条件
Raspberry Pi (GStreamerとPythonがインストールされていること)
Milvusのセットアップ(ローカルまたはリモートサーバー)](https://milvus.io/blog/how-to-get-started-with-milvus.md)
通知用Slackアカウント
必要なライブラリのインポートと初期設定
まずは必要なライブラリのインポートと初期設定を行います:
インポート gi
gi.require_version('Gst', '1.0')
from gi.repository import Gst, GLib
インポート os
インポート argparse
インポートマルチプロセッシング
np として numpy をインポート
インポート setproctitle
インポート cv2
import time
from datetime import datetime
インポート uuid
インポート glob
インポートトーチ
from torchvision import transforms
from PIL import Image
import timm
from sklearn.preprocessing import normalize
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
from pymilvus import connections
from pymilvus import utility
from pymilvus import FieldSchema, CollectionSchema, DataType, Collection
from pymilvus import MilvusClient
from pymilvus import MilvusClient
インポート hailo
from hailo_rpi_common import (
get_default_parser、
QUEUE、
get_caps_from_pad、
get_numpy_from_buffer、
GStreamerApp、
app_callback_class、
)
ディメンション = 512
milvus_url = "https://in05-7bd87b945683c8d.serverless.gcp-us-west1.cloud.zilliz.com"
COLLECTION_NAME = "rpipose"
TOKEN = os.environ["ZILLIZ_TOKEN"]。
PATH = "/opt/demo/images"
time_list = [ 0, 5, 10, 20, 30, 40, 50, 59 ].
上記のコードでは、動画処理(GStreamer)、画像処理(OpenCV)、ディープラーニング(PyTorch、timm)、データベース操作(pymilvus)、通信(Slack SDK)のための様々なライブラリをインポートしている。また、AIアクセラレーターと連携するためのHailoライブラリーもインポートしており、エッジデバイス上で深層学習アプリケーションを実現できるように設計されている。Milvusデータベース設定用のグローバル変数を設定し、定期的なアクションのための時間リストを定義する。MILVUSURLとTOKEN`はZillizクラウドとの認証を行う。
Milvusデータベースのセットアップ
次に、Milvusベクトルデータベースへの接続をセットアップする。Milvusはポーズ推定モデルから抽出された特徴量を保存するために使用します。
# Milvusに接続する。
# Milvus Lite
# milvus_client = MilvusClient(uri="pipose.db")
# クラウドサーバー
milvus_client = MilvusClient( uri=MILVUS_URL, token=TOKEN )
# 画像のid、ファイルパス、埋め込み画像を含むMilvusコレクションを作成します。
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True)、
FieldSchema(name='label', dtype=DataType.VARCHAR, max_length=200)、
FieldSchema(name='lefteye', dtype=DataType.VARCHAR, max_length=200)、
FieldSchema(name='righteye',dtype=DataType.VARCHAR,max_length=200)、
FieldSchema(name='confidence',dtype=DataType.FLOAT)、
FieldSchema(name='vector',dtype=DataType.FLOAT_VECTOR,dim=DIMENSION))。
]
schema = CollectionSchema(fields=fields)
milvus_client.create_collection(COLLECTION_NAME, DIMENSION, schema=schema, metric_type="COSINE", auto_id=True)
index_params = milvus_client.prepare_index_params()
index_params.add_index(field_name = "vector", metric_type="COSINE")
milvus_client.create_index(COLLECTION_NAME, index_params)
ここでは、Milvusデータベースをセットアップしています。クライアント接続を作成し、コレクションのスキーマを定義し(ID、ラベル、目の位置、確信度、特徴ベクトルのフィールドを含む)、コレクションを作成し、効率的な類似検索のためのインデックスを設定します。
通知用Slackのセットアップ
次に、通知を送信するためにSlackへの接続をセットアップする:
slack_token = os.environ["SLACK_BOT_TOKEN"]。
client = WebClient(token=slack_token)
このセットアップにより、環境変数に格納されたボットトークンを使ってSlackにメッセージやファイルを送信できるようになります。
フィーチャーエクストラクターの実装
ポーズ推定システムには、検出されたポーズをMilvusに保存するのに適したフォーマットに変換する特徴抽出器が必要です。そのためのクラスを定義します。
class FeatureExtractor:
def __init__(self, modelname):
# 学習済みモデルを読み込む
self.model = timm.create_model(
modelname, pretrained=True, num_classes=0, global_pool="avg" )
)
self.model.eval()
# モデルが必要とする入力サイズを取得
self.input_size = self.model.default_cfg["input_size"] # モデルが必要とする入力サイズを取得する。
config = resolve_data_config({}, model=modelname)
# モデルに対してTIMMが提供する前処理関数を取得する
self.preprocess = create_transform(**config)
def __call__(self, imagepath):
# 入力画像の前処理
input_image = Image.open(imagepath).convert("RGB") # 必要に応じてRGBに変換する。
input_image = self.preprocess(input_image)
# 画像をPyTorchテンソルに変換し、バッチ次元を追加する
input_tensor = input_image.unsqueeze(0)
# 推論を行う
torch.no_grad() を使う:
出力 = self.model(input_tensor)
# 特徴ベクトルを取り出す
feature_vector = output.squeeze().numpy()
return normalize(feature_vector.reshape(1, -1), norm="l2").flatten()
extractor = FeatureExtractor("resnet34")
この FeatureExtractor クラスは、画像を特徴ベクトルに変換します。このタスクでは、事前にトレーニングされた ResNet34 モデルを使用します。call__`メソッドは画像を開き、前処理を行い、モデルを通して実行し、正規化された特徴ベクトルを返します。
ユーザーコールバッククラスの定義
続けて、シンプルなユーザーコールバッククラスを定義します。
class user_app_callback_class(app_callback_class):
def __init__(self):
super().__init__()
このクラスは app_callback_class を継承しており、新しい機能は追加されていません。将来的にコールバックの動作をカスタマイズできるようにするためのプレースホルダです。
アプリケーションコールバック関数の作成
app_callback`関数はほとんどの処理を行う。この関数はビデオフレームを処理し、ポーズを推定し、結果をMilvusに保存します。
def app_callback(pad, info, user_data):
# プローブ情報からGstBufferを取得する。
左目 = ""
右目 = ""
buffer = info.get_buffer()
# バッファが有効かどうかをチェックする
buffer が None の場合
return Gst.PadProbeReturn.OK
# user_dataを使ってフレーム数をカウントする
user_data.increment()
string_to_print = f "フレーム数:user_data.get_count()}n "フレーム数:{user_data.get_count()}n"
# パッドからキャップを取得
フォーマット、幅、高さ = get_caps_from_pad(pad)
# user_data.use_frameがTrueに設定されている場合、バッファからビデオフレームを取得できます。
frame = None
if user_data.use_frame かつ format が None 以外かつ width が None 以外かつ height が None 以外:
# ビデオフレームを取得
frame = get_numpy_from_buffer(buffer, format, width, height)
# バッファから検出値を取得
roi = hailo.get_roi_from_buffer(buffer)
detections = roi.get_objects_typed(hailo.HAILO_DETECTION)
# 検出を解析する
for detection in detections:
label = detection.get_label()
bbox = detection.get_bbox()
confidence = detection.get_confidence()
if label == "person":
string_to_print += (f "Detection: {label} {confidence:.2f}n")
# 利用可能であれば)検出結果からポーズ推定ランドマーク
landmarks = detection.get_objects_typed(hailo.HAILO_LANDMARKS)
if len(landmarks) != 0:
points = landmarks[0].get_points()
left_eye = points[1] # 1を左目のインデックスとする
right_eye = points[2] # 2が右目のインデックスであると仮定する。
# ランドマークはバウンディングボックスに正規化されているため、フレームサイズに変換する必要があります。
left_eye_x = int((left_eye.x() * bbox.width() + bbox.xmin()) * width)
left_eye_y = int((left_eye.y() * bbox.height() + bbox.ymin()) * height)
right_eye_x = int((right_eye.x() * bbox.width() + bbox.xmin()) * width)
right_eye_y = int((right_eye.y() * bbox.height() + bbox.ymin()) * height)
string_to_print += (f" 左目: x:左目: x: {left_eye_x:.2f} y:左目:x:{left_eye_y:.2f} y:{left_eye_y:.2f}右目: x:右目: x: {right_eye_x:.2f} y:{right_eye_y:.2f}\n")
if user_data.use_frame:
# 目のランドマークを示すマーカーをフレームに追加します.
cv2.circle(frame, (left_eye_x, left_eye_y), 5, (0, 255, 0), -1).
cv2.circle(frame, (right_eye_x, right_eye_y), 5, (0, 255, 0), -1).
if user_data.use_frame:
# フレームを BGR に変換します.
framesave = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) .
user_data.set_frame(framesave)
time_now = datetime.now().
current_time = int(time_now.strftime("%S"))
if current_time in time_list and len(label) > 4:
# 画像を保存する
strfilename = PATH + "/personpose.jpg".
cv2.imwrite(strfilename, framesave)
左目 = (f "x: {left_eye_x:.2f} y: {left_eye_y:.2f}")
右目 = (f "x: {right_eye_x:.2f} y: {right_eye_y:.2f}")
# スラック
try:
response = client.chat_postMessage(
channel="C06NE1FU6SE",
text=(f "Detection: {label} {confidence:.2f}")
)
except SlackApiError as e:
# ok" が False の場合、SlackApiError が発生します。
assert e.response["error"]
try:
response = client.chat_postMessage(
channel="C06NE1FU6SE",
text=(f" 左目:x:{left_eye_x:.2f} y:左目: x: {left_eye_y:.2f}右目: x:右目: x: {right_eye_x:.2f} y:{right_eye_y:.2f}\n")
)
except SlackApiError as e:
# ok" が False の場合、SlackApiError が発生します。
assert e.response["error"]
try:
response = client.files_upload_v2(
channel="C06NE1FU6SE",
file=strfilename、
title=label、
initial_comment="ライブカメラ画像"、
)
except SlackApiError as e:
assert e.response["error"].
# ミルバス挿入
try:
imageembedding = extractor(strfilename)
milvus_client.insert( COLLECTION_NAME, {"vector": imageembedding, "lefteye": lefteye, "righteye": righteye, "label": label, "confidence": confidence})
except Exception as e:
print("An error:", e)
print(string_to_print)
return Gst.PadProbeReturn.OK
このコールバック関数は、人物を検出するためにビデオフレームを処理し、バウンディングボックス、確信度、目のランドマークなどの詳細を抽出することに焦点を当てます。フレーム内の検出された目の位置をマークし、フレーム内に人がいる場合はフレーム画像を保存します。さらに、検出の詳細とマークされた画像をSlackに通知します。そして、保存された画像から埋め込みベクトルを抽出する。埋め込みベクトル(vector)、眼球座標(lefteyeとrighteye)、物体ラベル(label)、検出信頼度(confidence)を含むこのデータでMilvusを更新する。
COCOキーポイントの効用関数の作成
COCOキーポイントを取得するためのユーティリティ関数を作成します。これは、ポーズ推定に使用される人体上の特定のポイントです。
def get_keypoints():
"""COCOキーポイントとその左右反転対応マップを取得する。"""
キーポイント = {
'nose': 1、
'left_eye': 2、
'right_eye':3,
左耳4,
右耳5,
'left_shoulder': 6、
'right_shoulder':7,
'left_elbow':8,
'right_elbow':9,
左手首」:10
'right_wrist': 11、
左ヒップ12,
右ヒップ13,
'左膝': 14、
'right_knee': 15、
左足首16,
右足首17,
}
キーポイントを返す
この関数は、ボディパーツとそれに対応する COCO データセット形式のキーポイントインデックスを対応付けた辞書を返す。
GStreamerパイプラインの作成
GStreamer パイプラインをセットアップするメイン・アプリケーション・クラスを作成する。これは、マルチメディア・データを特定の順序で処理する一連の要素です。ライブ・ビデオ・ストリームを処理します。
# このクラスは hailo_rpi_common.GStreamerApp クラスを継承しています。
class GStreamerPoseEstimationApp(GStreamerApp):
def __init__(self, args, user_data):
# 親クラスのコンストラクタを呼び出す
super().__init__(args, user_data)
# ここに追加の初期化コードを追加できる
# Hailo パラメータを設定する これらのパラメータは、使用するモデルに基づいて設定する必要があります。
self.batch_size = 2
self.network_width = 640
self.network_height = 640
self.network_format = "RGB"
self.default_postprocess_so = os.path.join(self.postprocess_dir, 'libyolov8pose_post.so')
self.post_function_name = "filter"
self.hef_path = os.path.join(self.current_path, '../resources/yolov8s_pose_h8l_pi.hef')
self.app_callback = app_callback
# プロセスタイトルを設定する
setproctitle.setproctitle("Hailo Pose Estimation with Milvus")
self.create_pipeline()
def get_pipeline_string(self):
if (self.source_type == "rpi"):
source_element = f "libcamerasrc name=src_0 auto-focus-mode=2 !"
source_element += f "video/x-raw, format={self.network_format}, width=1536, height=864 !"
source_element += QUEUE("queue_src_scale")
source_element += f "videoscale !"
source_element += f "video/x-raw, format={self.network_format}, width={self.network_width}, height={self.network_height}, framerate=30/1 !"
elif (self.source_type == "usb"):
source_element = f "v4l2src device={self.video_source} name=src_0 !"
source_element += f "video/x-raw, width=640, height=480, framerate=30/1 !"
else:
source_element = f "filesrc location={self.video_source} name=src_0 !"
source_element += QUEUE("queue_dec264")
source_element += f" qtdemux ! h264parse ! avdec_h264 max-threads=2 !"
source_element += f" video/x-raw,format=I420 !"
source_element += QUEUE("queue_scale")
source_element += f "videoscale n-threads=2 !"
source_element += QUEUE("queue_src_convert")
source_element += f "videoconvert n-threads=3 name=src_convert qos=false !"
source_element += f "video/x-raw, format={self.network_format}, width={self.network_width}, height={self.network_height}, pixel-aspect-ratio=1/1 !"
pipeline_string = "hailomuxer name=hmux "
パイプライン文字列 += source_element
pipeline_string += "tee name=t !"
pipeline_string += QUEUE("bypass_queue", max_size_buffers=20) + "hmux.sink_0 "
pipeline_string += "t. !" + QUEUE("queue_hailonet")
pipeline_string += "videoconvert n-threads=3 !"
pipeline_string += f "hailonet hef-path={self.hef_path} batch-size={self.batch_size} force-writable=true !"
pipeline_string += QUEUE("queue_hailofilter")
pipeline_string += f "hailofilter function-name={self.post_function_name} so-path={self.default_postprocess_so} qos=false !"
pipeline_string += QUEUE("queue_hmuc") + " hmux.sink_1 "
pipeline_string += "hmux.!" + QUEUE("queue_hailo_python")
pipeline_string += QUEUE("queue_user_callback")
pipeline_string += f "identity name=identity_callback !"
pipeline_string += QUEUE("queue_hailooverlay")
pipeline_string += f "hailooverlay !"
pipeline_string += QUEUE("queue_videoconvert")
pipeline_string += f "videoconvert n-threads=3 qos=false !"
pipeline_string += QUEUE("queue_hailo_display")
pipeline_string += f "fpsdisplaysink video-sink={self.video_sink} name=hailo_display sync={self.sync} text-overlay={self.options_menu.show_fps} signal-fps-measurements=true "
print(pipeline_string)
return pipeline_string
このクラスはGStreamerパイプラインをセットアップします。Hailo AIアクセラレータは、エッジデバイス上でディープラーニングやAI推論タスクを実行するために設計されたエッジAIプロセッサです。バッチサイズ、入力寸法、カラーフォーマット、ニューラルネットワークモデルと後処理のためのファイルパスなどのパラメータを初期化する。入力ソース(例:Raspberry Piカメラ、USBカメラ、ビデオファイル)に応じて、GStreamerパイプラインを構築し、ビデオをキャプチャし、Hailoモデルを通して処理し、後処理を適用し、出力を表示します。パイプラインの設定は get_pipeline_string メソッドで指定され、このタスクに必要な GStreamer 要素を組み立てる。
プログラムの実行
最後のステップはプログラムの実行である。
if __name__ == "__main__":
# ユーザーアプリのコールバッククラスのインスタンスを作成する。
user_data = user_app_callback_class()
parser = get_default_parser()
args = parser.parse_args()
app = GStreamerPoseEstimationApp(args, user_data)
app.run()
ここですべてを接続する。user_app_callback_classのインスタンスを作成し、コマンドライン引数を解析してGStreamerPoseEstimationApp` を作成し、それを実行します。
以下はプログラムを実行したときの結果のサンプルである。
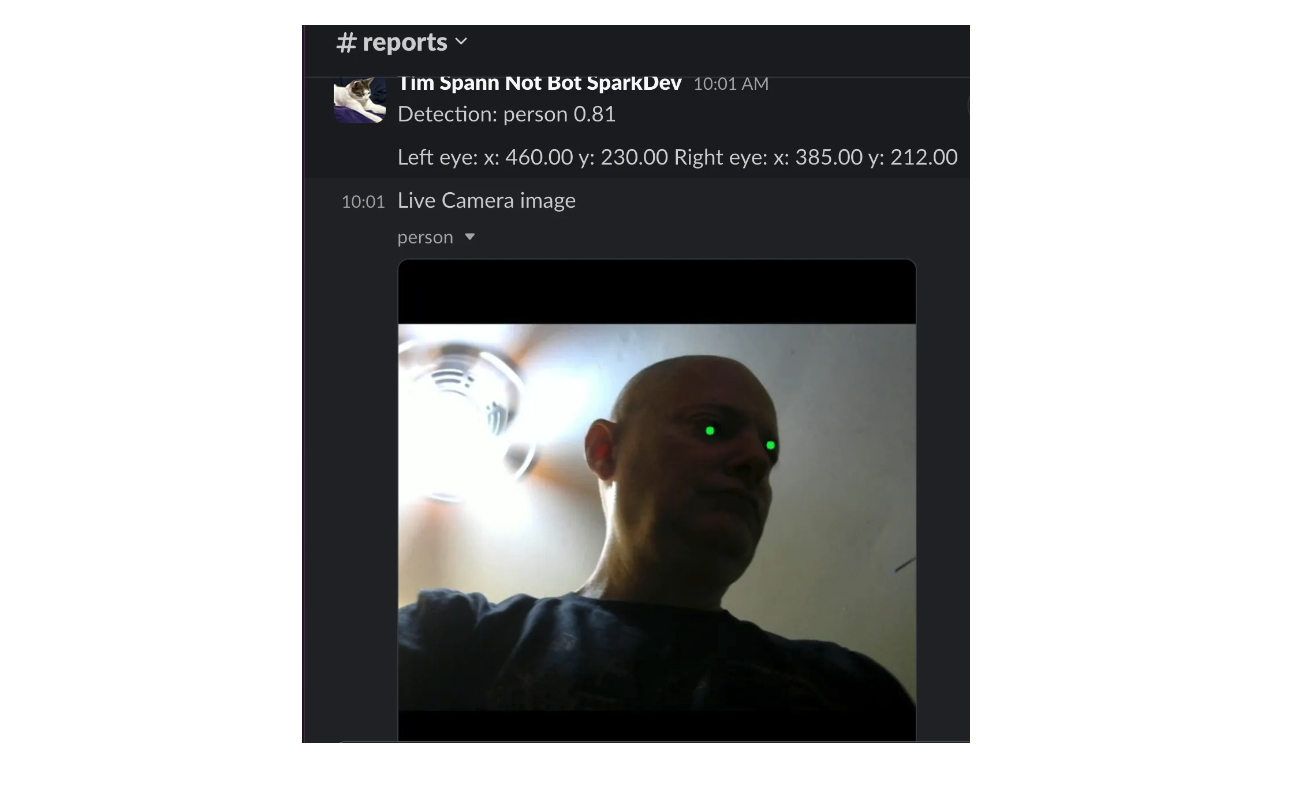 図2-Slackでのポーズ推定プログラムの出力(目のランドマークが緑の点で示されている).png
図2-Slackでのポーズ推定プログラムの出力(目のランドマークが緑の点で示されている).png
図2:Slackでのポーズ推定プログラムの出力。
これは人物が検出されたときのSlackへの更新です。信頼度81%、左右の目の座標、目のランドマーク(左右の目の位置に緑色の丸印)が表示された画像です。
AIとベクターデータベースを組み合わせた使用例
エッジAIとベクターデータベースを組み合わせることで、数多くのユースケースが生まれる。以下はその一例である。
ロボティクス
エッジAIとベクトル・データベースは、自律型ロボットの能力を強化し、センサー・データをローカルで処理し、即座に判断できるようにする。このテクノロジーは、ダイナミックな環境における効率性と適応性を大幅に向上させる。
例倉庫オートメーションでは、自律移動ロボット(AMR)がオンボードカメラとローカルのベクトルデータベースを使用してリアルタイムの物体認識を行っている。倉庫内を移動する際、これらのロボットは視覚データとローカルに保存されたベクトルを比較することで、瞬時に商品を識別し、分類します。これにより、クラウドインフラに依存することなく、変化する倉庫の状況に適応し、ルートを最適化することができる。
スマートシティ
エッジAIとベクトル・データベースは、交通管理から公共安全まで、都市運営の最適化において重要な役割を果たす。これらのテクノロジーは、エッジでの迅速なデータ処理と意思決定を可能にし、都市の効率と住民の生活の質を向上させる。
例インテリジェント交通管理システムは、エッジAIを活用して交差点カメラからのビデオフィードをローカルで処理する。システムは交通パターンをベクトル表現に変換し、ローカルのベクトル・データベースに保存されている過去のデータと比較する。これにより、渋滞緩和のための信号機調整をリアルタイムで行うことができ、中央サーバーへの常時データ送信を必要とせず、迅速な対応が可能となる。
産業オートメーション
エッジAIとベクトル・データベースは、製造業や産業環境における予知保全と設備監視を推進する。このアプローチにより、機械の健全性をリアルタイムで分析し、ダウンタイムを防ぎ、生産プロセスを最適化することができます。
例スマートな製造工場では、重要な機械にセンサーを配備し、振動データを継続的に収集する。エッジデバイスは、このデータをベクトル表現に変換し、ローカルのベクトルデータベースに保存されている既知の「健全な」振動パターンと「欠陥のある」振動パターンと比較します。このリアルタイム分析により、機器の潜在的な故障を即座に検出することができ、予防的なメンテナンスが容易になり、コストのかかる中断を最小限に抑えることができます。
ヘルスケア
エッジAIとベクトル・データベースは、プライバシーを損なうことなく継続的な健康監視を可能にすることで、患者ケアを変革する。これらのテクノロジーは、ウェアラブルデバイスやローカルシステム上で直接、健康データの高度な分析を可能にします。
例ウェアラブルECGモニターは、エッジAIを利用して心拍データをローカルで処理する。デバイスはECGパターンをベクトルに変換し、オンボードに保存された正常・異常リズムのデータベースと比較する。このアプローチにより、潜在的な心臓の問題を即座に検出することが可能になると同時に、機密性の高い健康データをデバイスに保持することができ、応答性と患者のプライバシーの両方が強化される。
結論
非構造化データの規模と重要性が増すにつれ、効率的な処理ソリューションがますます重要になっている。ティムは、Milvusのようなベクトル・データベースがクラウドとエッジの両方の展開に高度な機能を提供し、変革をもたらす可能性があることをうまく強調した。大規模なAIアプリケーションであれ、リソースに制約のあるエッジデバイスであれ、Milvusとその軽量版であるMilvus Liteは、組織がリアルタイムの意思決定、イノベーション、業務効率化のために非構造化データを活用することを可能にする。クラウドからエッジまで柔軟に拡張できるこれらのテクノロジーは、最新のAI主導型ソリューションの最前線にある。
その他のリソース
GitHubにあるティムのAIプロジェクト:
Raspberry Pi AIキットによる非構造化データ処理](https://medium.com/@tspann/unstructured-data-processing-with-a-raspberry-pi-kit-c959dd7fff47)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
読み続けて

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.

Top 5 AI Search Engines to Know in 2025
Discover the top AI-powered search engines of 2025, including OpenAI, Google AI, Bing, Perplexity, and Arc Search. Compare features, strengths, and limitations.