




セマンティック検索 vs. レキシカル検索 vs. フルテキスト検索
今日のデジタル世界では、検索エンジンは私たちの生活に欠かせないものとなり、情報への迅速かつ容易なアクセスを助けている。これらの検索エンジンの中心にあるのは情報検索アルゴリズムであり、情報がどのように検索されるかを決定する。
情報検索アルゴリズムには、全文検索や字句検索のような伝統的な手法から、意味検索のような高度な手法まで、いくつかのものがある。これらのアルゴリズムにはそれぞれ長所と短所があるため、ユースケースに合った最適な情報検索アルゴリズムを選択することが重要である。
この記事では、これらの情報検索アルゴリズムについて、特に語彙検索、全文検索、意味検索に焦点を当てて説明する。まず、最もシンプルな語彙検索から始めよう。
語彙検索
語彙検索はキーワード検索とも呼ばれ、テキストの単語レベルの分析に基づく検索アルゴリズムを指す(これが名前の由来である)。この情報検索アルゴリズムは、クエリ用語がテキストに現れたとおりにマッチする。例えば、検索クエリが "run "である場合、このアルゴリズムは文書内の "run "という用語のすべてのインスタンスを返します。
レキシカル検索は、最も基本的な情報検索アルゴリズムであり、クエリと完全に一致する用語を含む文書のみを返します。このため、特定の文字列や単語を含む文書やレコードを検索するなど、精度と特異性が求められる場合には、レキシカル検索が特に有用となる。

図:単純な語彙検索の図解。
しかし、字句検索の単純さは、いくつかの欠点にもつながる。まず、クエリーのタイプミスが許されない。たとえば、「run」ではなく「ron」と間違って入力した場合、探している結果は得られない。第二に、語彙検索は同義語、ステミング、レマタイゼーションを考慮しません。その結果、"run "を検索しても、"ran "や "running "といった異なる形の類似語にはマッチしない。
さらに、クエリに基づいて最も関連性の高いレコードを探す場合、字句検索は最良の選択肢ではないかもしれない。クエリ用語を含む文書やレコードには順序や順位の概念がないため、語彙検索で返された結果の関連性を評価することが難しくなります。
このように、ほとんどの情報検索ユースケースの要求を考慮すると、辞書的検索には大きな限界がある。さらに、ユーザーは結果に含まれる用語に関してより柔軟性を求めることが多いが、これも語彙検索には欠けている。そこで、全文検索の出番となる。
全文検索
全文検索は字句検索と同様に動作し、クエリに含まれる用語を含むレコードを検索します。しかし、フルテキスト検索はレキシカル検索よりも広範で高度な機能を提供し、レキシカル検索に関連する問題に対処します。
全文検索の実装には、多くの場合、ステミングやレマタイゼーションといった一般的な自然言語処理(NLP)テクニックが組み込まれている。つまり、"run "という語を検索すると、"ran "や "running "といった異なる形の類似語を持つ文書やレコードもすべて検索結果に含まれることになる。
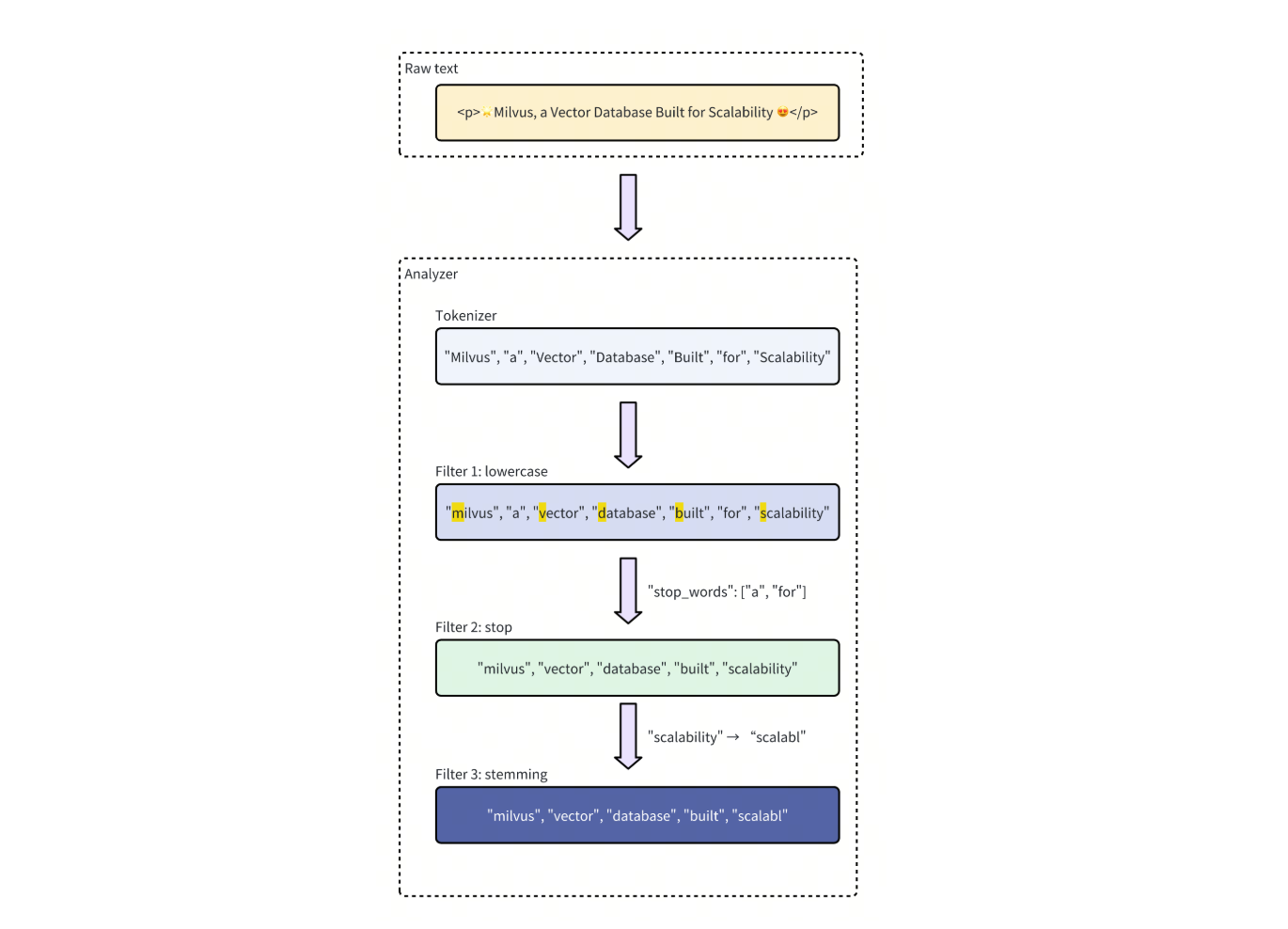
図:従来の語彙検索と比較した全文検索の進歩の図解_。
検索結果を関連性に基づいて並べ替えるために、TF-IDFやBM25のようなアルゴリズムを実装することもできる。この2つのアルゴリズムについてさらに説明しよう。
TF-IDFとBM25の基礎
用語頻度-逆文書頻度(TF-IDF)*は、与えられた用語やクエリに対する文書やレコードの関連性を決定するための簡単な統計的方法を使用します。TF-IDFは2つの要素から構成される:
用語頻度(TF):Term Frequency (TF):文書中のクエリー用語の出現回数を計算する。したがって、クエリ用語が文書に出現する頻度が高いほど、その文書のTFスコアは高くなる。
逆文書出現頻度(IDF)**:これは、クエリ用語を含む文書がコレクション全体に占める割合を計算する。

IDFコンポーネントの主な目的は、"a"、"an"、"the"、"and "のような一般的であまり意味のない用語をペナルティー化することである。例えば、クエリータームが "mix and match "の場合、最も関連性の高い文書には、"and "が多数出現するよりも、"mix "や "match "が多数出現することを望む。最後に、文書の最終的なTF-IDFスコアは、TFスコアとIDFスコアを掛け合わせることで得られる。
TF-IDFの主な欠点は、関連性を計算する際に文書の長さを考慮しないことである。現実には、長い文書ほどクエリー用語が頻繁に含まれている可能性が高い。例えば、クエリー用語が1,000語の文書(文書A)に10回出現する一方、50語の文書(文書B)には5回しか出現しない場合、出現回数が少ないにもかかわらず、文書Bの方が関連性が高いと主張できるかもしれない。
BM25は、TF-IDFのこの限界に対処するため、追加の用語を導入し、TF-IDF式を文書の長さを考慮するように拡張している。
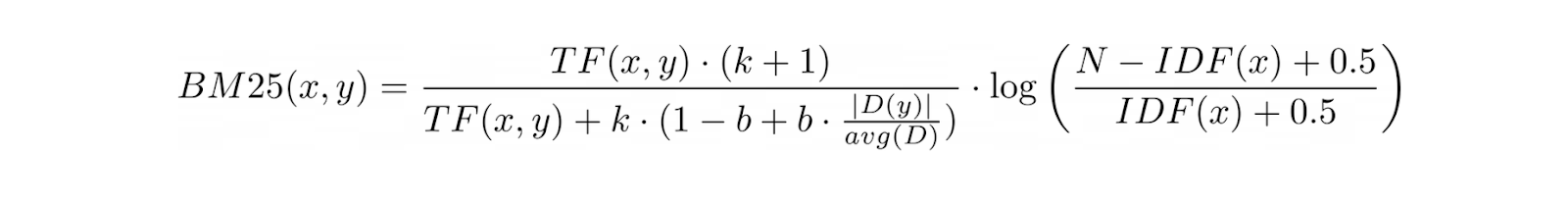
こうすることで、BM25は任意のクエリに対する文書の関連性を測定する際に、長い文書へのバイアスを排除する。
スパース埋め込みという概念
TF-IDFもBM25もスパース埋め込みとして表現することができます。スパース埋め込みはn次元の ベクトルであり、その次元数はコーパスや文書のコレクションに含まれるユニークな用語の数に依存します。
例えば、10,000のユニークな単語を含む10個の文書があるとします。各文書は10,000次元のベクトルに変換され、各次元はその文書内の特定の用語の重要度を表す。
![]()
図:文書からスパース埋め込みへの変換の説明図_。
ベクトルの次元はコーパスに含まれるユニークな用語の数によって決定されるため、しばしば巨大な次元のベクトルになってしまう。さらに、文書には通常、利用可能な用語のごく一部しか含まれていないため、上の画像でわかるように、これらのベクトルの要素の大部分はゼロになります。このようなベクトルが一般的にスパース埋め込みと呼ばれるのはこのためです。
すべての文書が埋め込みとして表現された今、 余弦類似度 や ユークリッド距離 のような一般的なアルゴリズムを使って、任意の2つの埋め込み間の類似度を計算することができます。直感的には、重要度の高い似たような用語を持つ2つの文書は、高い類似性を持つことになります。
全文検索におけるスパース埋込みの利点にもかかわらず、1つ重大な欠点がある。例えば、クエリが "Apple device "の場合、"apple"(果物)のインスタンスを多く含む文書は、クエリとの関連性は高いが "Apple"(企業)という用語を含まないテクノロジー文書よりも上位にランクされる可能性がある。
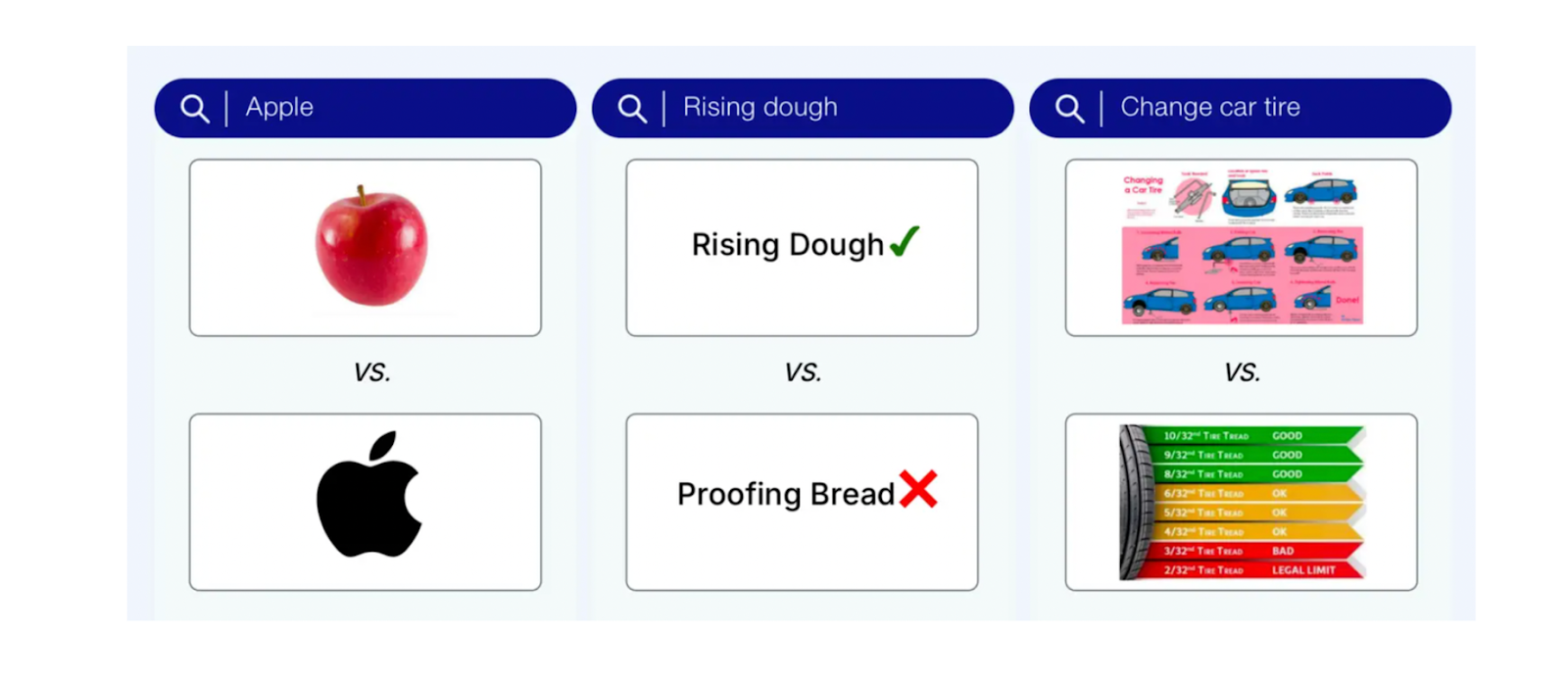
図:意味理解と文脈を必要とするクエリの例_。
類似した意味での検索結果を含むことがユースケースの要件である場合、全文検索は最適な情報検索アルゴリズムではないかもしれない。そこでセマンティック検索の出番となる。
セマンティック検索
セマンティック検索**は、意味的な意味を考慮した検索結果が欲しい場合に有効なアプローチである。前のセクションで述べた例を使うと、「Apple device」のようなクエリを入力するとき、実際には「apple」という単語を含む文書やレコードを探しているわけではない。そうではなく、テクノロジー、できればアップル・デバイスについて論じた文書を探しているのである。この場合、全文検索は望ましくない結果をもたらすので、セマンティック検索がより良い選択肢となる。
密な埋め込みという概念
セマンティック検索は、洗練されたAIモデルを利用して、文書やクエリー用語を埋め込みに変換することで機能します。しかし、これらのモデルによって生成される埋め込みは、しばしばdense embeddngsと呼ばれ、前回説明した疎な埋め込みとは異なります。
密な埋め込みでは、各ベクトル次元の値が正確に0であることは稀であり、次元数自体も使用するモデルに依存します。しかし、密な埋込みの次元数は、疎な埋込みよりもはるかに小さいです。
![]()
図:文書から密な埋め込みへの変換の図解_。
密な埋め込みは、それらが表現するコンテンツに関する意味的に豊かな情報を含んでいます。したがって、2つの密な埋め込みが意味的にどの程度類似しているかを決定するには、単純に余弦類似度やユークリッド距離のような一般的な類似性アルゴリズムを使用することができます。
意味検索におけるベクトルデータベースの役割
実世界の情報検索アプリケーションでは、数百万から数十億の密な埋め込みを扱う可能性がある。そのため、これらの埋め込みデータをすべてコンピュータのメモリに格納することは現実的ではありません。
ベクトルデータベース](https://zilliz.com/learn/what-is-vector-database)は、近似最近傍(ANN)や階層的ナビゲーシブルスモールワールド(HNSW)のような高度な索引付け手法を用いることで、膨大な量の高密度埋め込みを効率的に格納することを可能にするシステムです。また、コサイン類似度やユークリッド距離のような一般的な類似性アルゴリズムを用いて、クエリに最も意味的に関連する文書を見つけるためのベクトル検索操作を実行する機能も提供する。
検索](https://assets.zilliz.com/Figure_Workflow_of_performing_a_vector_search_operation_4668651f81.png)
図:ベクトル検索操作のワークフロー_。
さらに、Milvusのような一般的なベクトルデータベースは、ハイブリッド検索のような高度な機能を提供しており、密埋め込みと疎埋め込みの両方の長所を組み合わせてベクトル検索を行うことができます。これについては後述する。
語彙検索 vs. 全文検索 vs. 意味検索
語彙検索、全文検索、セマンティック検索について詳しく理解したところで、それぞれのマッチングメカニズム、複雑さ、使用例、パフォーマンスを比較してみましょう。
| セマンティック検索
| メカニズム|文脈と意図|完全一致|キーワードと関連性 | 複雑さ|高さ|低さ|中 | パフォーマンス|遅い|速い|中程度 | ユースケース|NLPベースのシステム、検索拡張世代(RAG)、LLMを利用したアプリケーション、推薦システム|単純な検索|ドキュメントを多用するシステム|など。
表語彙検索 vs. 全文検索 vs. 意味検索
マッチングのメカニズムという点では、レキシカル検索は3つの中で最もシンプルであり、クエリ内の正確な用語にマッチする。全文検索は、クエリ用語の出現箇所を探すために文書全体をスキャンすることで語彙検索を改善し、クエリとの関連性に基づいて結果を並べ替えることができる。一方、セマンティック検索は、高度なディープラーニングモデルとNLP技術を活用し、意味的な意味と文脈に基づいて、クエリの用語を文書のコレクションにマッチさせる。
複雑さに関しては、辞書的検索が最もシンプルな選択肢である。全文検索は、テキストを疎な埋め込みに変換するTF-IDFやBM25のようなアルゴリズムの導入により、若干複雑になっている。意味検索は、テキストを高密度の埋め込みに変換する高度なディープラーニング・モデルを採用しているため、最も複雑である。
例えば、辞書的検索は、コード検索で変数名を探したり、文書内の製品IDを見つけたりするような、正確なマッチングが重要な場合に最適な選択だ。全文検索は、学術データベースや法的リポジトリの検索など、クエリに特殊な用語や概念を含む文書を検索する用途に適している。セマンティック検索は、カスタマーサポートのチャットボット、推薦システム、コンテンツ発見など、コンテキストを理解することが優先されるユースケースに最適です。
パフォーマンスに関しては、セマンティック検索と全文検索はその複雑さゆえに相対的に遅く、一方、語彙検索はその単純なアプローチゆえに速い。
ハイブリッド検索の概念
各情報検索アルゴリズムの多様性と長所・短所を考慮すると、最適なものを選ぶのは容易ではなく、すべての要件を満たすとは限りません。効果的な情報検索システムは、ユーザーに意味的な理解と正確なキーワードマッチングの両方を提供する必要があるため、実用的なユースケースでは、アプリケーション内の様々なニーズを満たすために、複数のアルゴリズムを採用する必要があることさえある。ハイブリッド検索は、この課題に対処するために考案されたコンセプトである。
ハイブリッド検索では、2つの異なる検索アルゴリズムを組み合わせることができ、最も一般的なのは、セマンティック検索とフルテキスト検索またはレキシカル検索の組み合わせである。しかし、ハイブリッド検索を実装するには、関係するシステムが異なるために課題がある。具体的には、密な埋め込みを保存して意味検索を行うにはMilvusのようなベクトルデータベースが必要であり、全文検索を行うにはElasticsearchのような検索エンジンが必要である。
しかし、異なる検索アルゴリズムに対応するために2つの別々のシステムを使用することは、新たな複雑さをもたらす。それは、別々の設定やメンテナンス作業に対処することを意味し、将来的に統合の問題につながる可能性がある。また、このアプローチでは、2つのインフラにデータを保存する必要があるため、コストが2倍になる可能性もある。
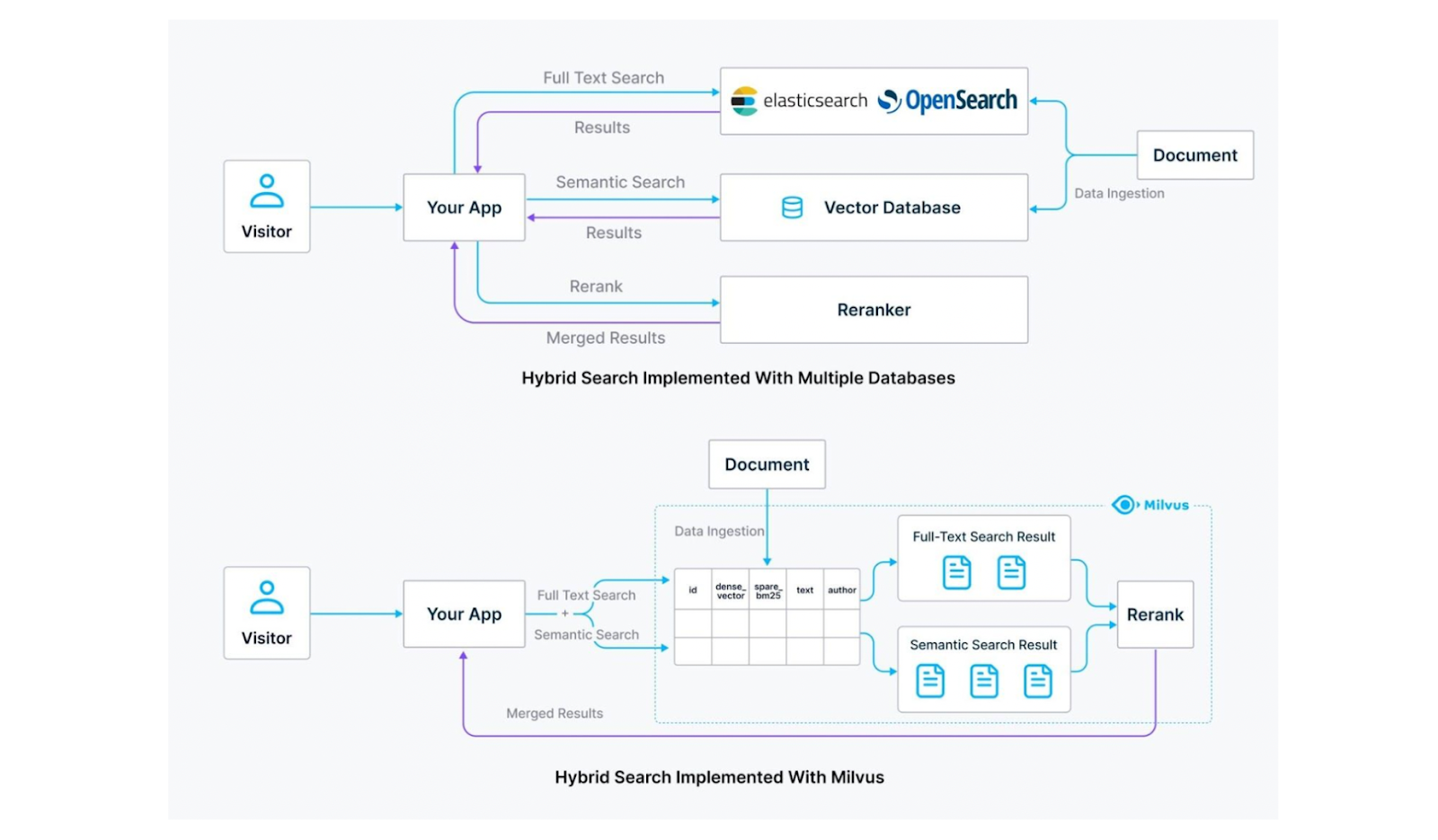
図:ハイブリッド検索におけるElasticsearchとMilvusの比較。
より良い解決策は、セマンティック検索と全文/レキシカル検索の両方を促進できる統一されたシステムを使うことである。Milvusは、ハイブリッド意味検索と全文検索の実装をサポートしているので、このケースに最適なオープンソースのベクトルデータベースである。さらに、Milvusはメタデータフィルタリング検索、範囲検索、リランキングにも対応しており、最も正確な検索結果を得ることができる。
Milvusでは、密な埋め込み、疎な埋め込み、メタデータなど、様々なタイプの検索に必要なデータをすべて保存することができる。これにより、セマンティック検索と全文検索や語彙検索のようなハイブリッド検索を行うことができる。Milvusは、その高度なインデックス作成手法のおかげで、ベクトル検索操作にも高度に最適化されており、Elasticsearchと比較して情報検索プロセスを大幅に高速化します。
結論
情報検索アルゴリズムの選択は、我々のアプリケーションにおける検索結果の効率性と関連性を決定する上で重要な役割を果たします。レキシカル検索は完全な用語マッチングを提供するため、完全な一致が不可欠なシナリオに最適である。全文検索は、ステミング、ファジィマッチング、関連性ランキングのような技術をTF-IDFやBM25のようなアルゴリズムに取り入れることで、語彙検索に進歩をもたらし、文書が多いアプリケーションに適している。一方、セマンティック検索は、文脈と意図を理解する機能を提供し、顧客チャットボットのような複雑なNLPベースのシステムにとって非常に有用です。
しかし、柔軟で効率的な検索システムに対する要求が高まるにつれ、ハイブリッド検索は複数の検索アルゴリズムの長所を適用する実用的なソリューションとなる。セマンティック検索と全文検索/レキシカル検索の両方を統合することで、Milvusは柔軟性とユーザーエクスペリエンスの向上を提供します。こちらのチュートリアルでMilvusのセマンティック検索と全文検索をお試しください。
関連リソース
Elasticsearch is Dead, Long Live Lexical Search](https://milvus.io/blog/elasticsearch-is-dead-long-live-lexical-search.md)
Milvus 2.5のご紹介:全文検索、より強力なメタデータフィルタリング、ユーザビリティの向上!](https://milvus.io/blog/introduce-milvus-2-5-full-text-search-powerful-metadata-filtering-and-more.md)
Milvus 2.5でハイブリッドセマンティック/フルテキスト検索を始める](https://milvus.io/blog/get-started-with-hybrid-semantic-full-text-search-with-milvus-2-5.md)
セマンティック検索 vs. 全文検索: Milvus 2.5でどちらを選ぶべきか](https://milvus.io/blog/semantic-search-vs-full-text-search-which-one-should-i-choose-with-milvus-2-5.md)
Milvusとは|Milvusドキュメント](https://milvus.io/docs/overview.md#Types-of-Searches-Supported-by-Milvus)
読み続けて

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.