




Elasticsearch Was Great, But Vector Databases Are the Future
This post was originally published on The New Stack and is reposted here with permission.
For decades, keyword matching also known as full-text search, exemplified by Elasticsearch, has been the default choice for information retrieval systems like enterprise search and recommendation engines.
As AI-powered search technologies advance, there is a shift toward semantic search, enabling systems to understand both the meaning and intent behind user queries. Embedding models and vector databases have become central to this shift.
Semantic search surpasses keyword matching by representing data as vector embeddings, providing a more nuanced understanding of search intent and transforming applications ranging from retrieval-augmented generation (RAG) to multimodal search.
In practice, effective information retrieval systems need both semantic understanding and exact keyword matching. For example, users expect search results to show concepts related to their search queries while also respecting the literal text used in the query, such as special terms and names and return the exact matching results.
A semantic search powered by dense vectors helps to understand the meaning (like knowing that ‘car’ and “automobile” are the same) and traditional full-text search provides the precise results users expect (like finding exact matches for “Python 3.9”). As a result, many organizations are adopting a hybrid search approach, combining the strengths of both methods to balance flexible semantic relevance with predictable exact keyword matching.
The Hybrid Search Challenge
A common way to implement hybrid search is to use a purpose-built vector database like open source Milvus for efficient and scalable semantic search, alongside traditional search engines like Elasticsearch or OpenSearch for full-text search.
While this approach can yield good results, it also introduces a new layer of complexity. Managing two distinct search systems means dealing with separate infrastructures, configurations and maintenance tasks, creating a heavier operational burden and increasing the chance of potential integration issues.
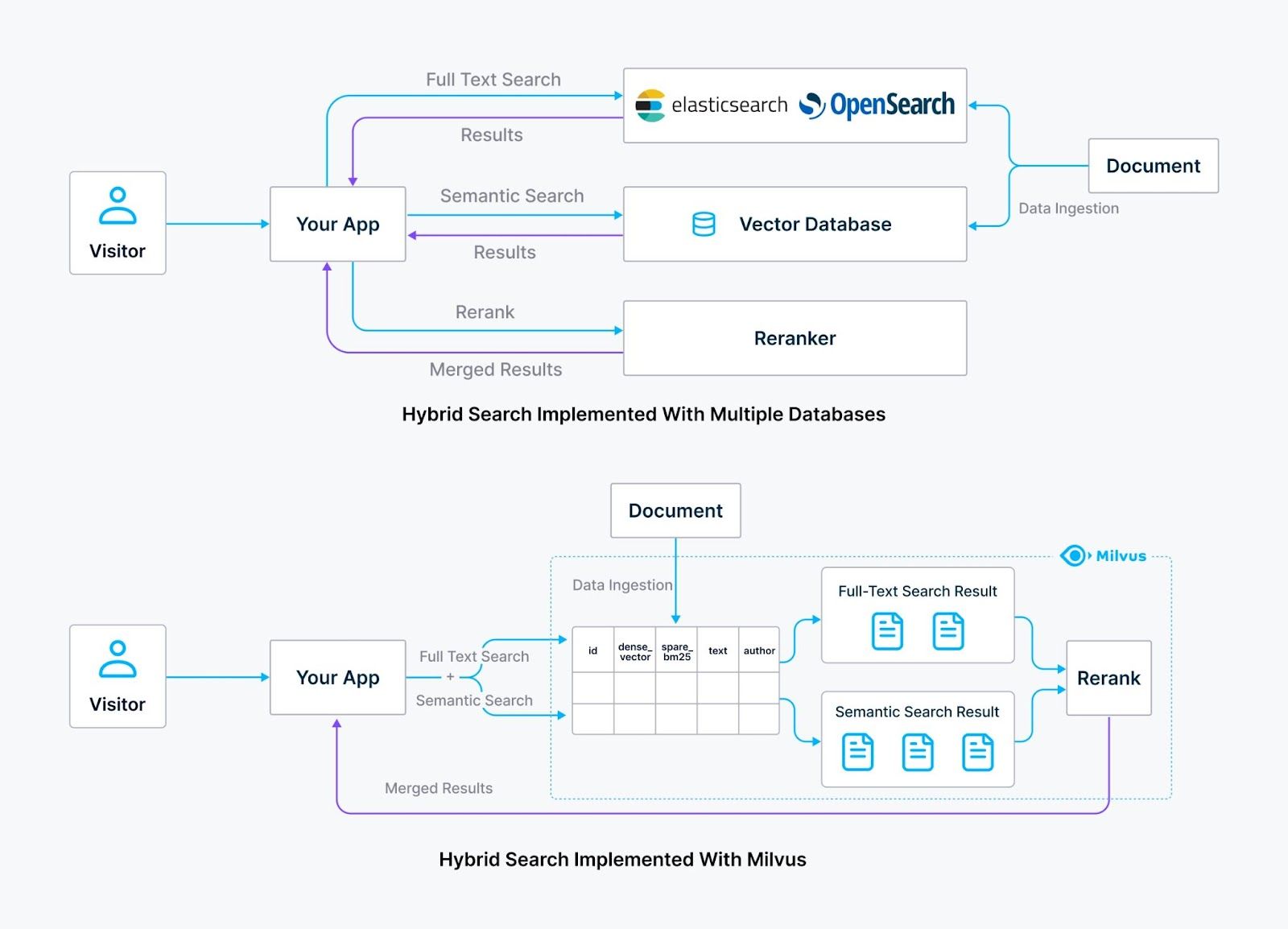 Elasticsearch vs Milvus on Hybrid search
Elasticsearch vs Milvus on Hybrid search
Figure: Elasticsearch vs Milvus on Hybrid search
A unified solution for hybrid search would provide many benefits:
Reduced infrastructure maintenance: Managing one system rather than two, drastically reduces operational complexity, saving both time and resources. This also means less context switching and mental overhead to master two different sets of APIs.
Consolidated data management: A unified table structure allows you to store both dense (vector-based) and sparse (keyword-based) data alongside shared metadata labels. Using two separate systems would require storing metadata labels twice for both sides to be able to conduct metadata filtering.
Streamlined query: A single request can carry out both semantic and full-text search tasks, eliminating the need to conduct two API calls to separate systems.
Enhanced security and access control: A unified approach enables more straightforward and robust security management, as all access controls can be centrally administered within a vector database, enhancing security compliance and consistency.
How a Unified Vector Approach Simplifies Hybrid Search
In semantic search, machine learning models “embed” text as points, known as dense vectors, in a high-dimensional space based on its meaning. Texts with similar semantics are closer to each other in this space. For example, “apple” and “fruit” might be closer in this space than “apple” and “car.” This allows us to quickly find semantically related text by just calculating the distance between each point using approximate nearest neighbor (ANN) algorithms.
This method can also be applied to full-text search by encoding documents and queries as sparse vectors. In sparse vectors, each dimension represents a term and the value indicates how important each term is in the document.
Terms not present in the document have a value of zero. Since any given document typically uses only a small portion of all possible terms in the vocabulary, most terms will not appear in the document. This means the resulting vectors are sparse — most of their values are zero. For example, in the MS-MARCO data set commonly used for evaluating information retrieval tasks, while there are about 9 million documents and a million unique terms, a search system typically divides this large collection into smaller segments for easier management.
Even at the segment level, with hundreds of thousands of terms in its vocabulary, each document usually contains fewer than 100 terms, which means over 99% of each vector's values are zero. This extreme sparsity has important implications for the way we store and process these vectors efficiently.
This sparsity pattern can be exploited to optimize search performance while maintaining accuracy. Vector databases originally designed for dense vectors can be adapted to handle these sparse vectors efficiently. For example, the open source vector database Milvus has just released native full-text search support using Sparse-BM25, a sparse vector implementation of the BM25 algorithm used by Elasticsearch and other full-text search systems. Sparse-BM25 unlocks approximation-based optimization for full-text search with:
Efficient retrieval algorithm with data pruning: By applying heuristic-based pruning to discard documents with the lowest sparse vector values in the segment index and ignoring low-value sparse vectors in the search query, a vector database can significantly reduce index size and optimize performance with minimal quality loss.
Unlocking further performance optimizations: Representing term frequency as a sparse vector instead of a reversed index enables additional vector-based optimizations. These include:
Graph indexing is used for more efficient search than brute-force scans.
Product quantization (PQ) / scalar quantization (SQ) to further reduce memory footprint.
In addition to these optimizations, the Sparse-BM25 implementation also inherits several system-level advantages from the high-performance vector database Milvus:
Efficient low-level implementation and memory management: The core vector indexing engine in Milvus is implemented in C++, offering more efficient memory management than a Java-based system like Elasticsearch. This alone reduces memory footprint by saving gigabytes compared to JVM-based approach.
Support for MMap: Similar to Elasticsearch’s use of page-cache for index storage in both memory and disk, Milvus supports memory mapping (MMap) to extend memory capacity when the index exceeds available memory.
Why Traditional Search Stacks Fall Short on Vector Search
Elasticsearch was built for traditional inverted indexes, making optimizing the whole architecture for dense vector search fundamentally difficult. The impact is clear: Even with just 1 million vectors, Elasticsearch takes 200 milliseconds (as tested on fully-managed Elastic Cloud) to return the search result compared to 6ms on Milvus (as tested on fully-managed Zilliz Cloud) — that’s over 30x performance difference. The throughput measured by queries per second (QPS) also has a 3x difference, where the most performant instance on Zilliz Cloud runs at 6000 QPS while Elastic Cloud is 1900 QPS at most. Moreover, Zilliz Cloud is 15x faster in loading the vector data and building index than Elastic Cloud. This performance gap widens at scale, where Elasticsearch’s Java/JVM implementation struggles to match the scalability of C++/Go-based vector databases. Additionally, Elasticsearch lacks critical vector search features like disk-based indexes (DiskAnn, MMap), optimized metadata filtering, and range search.
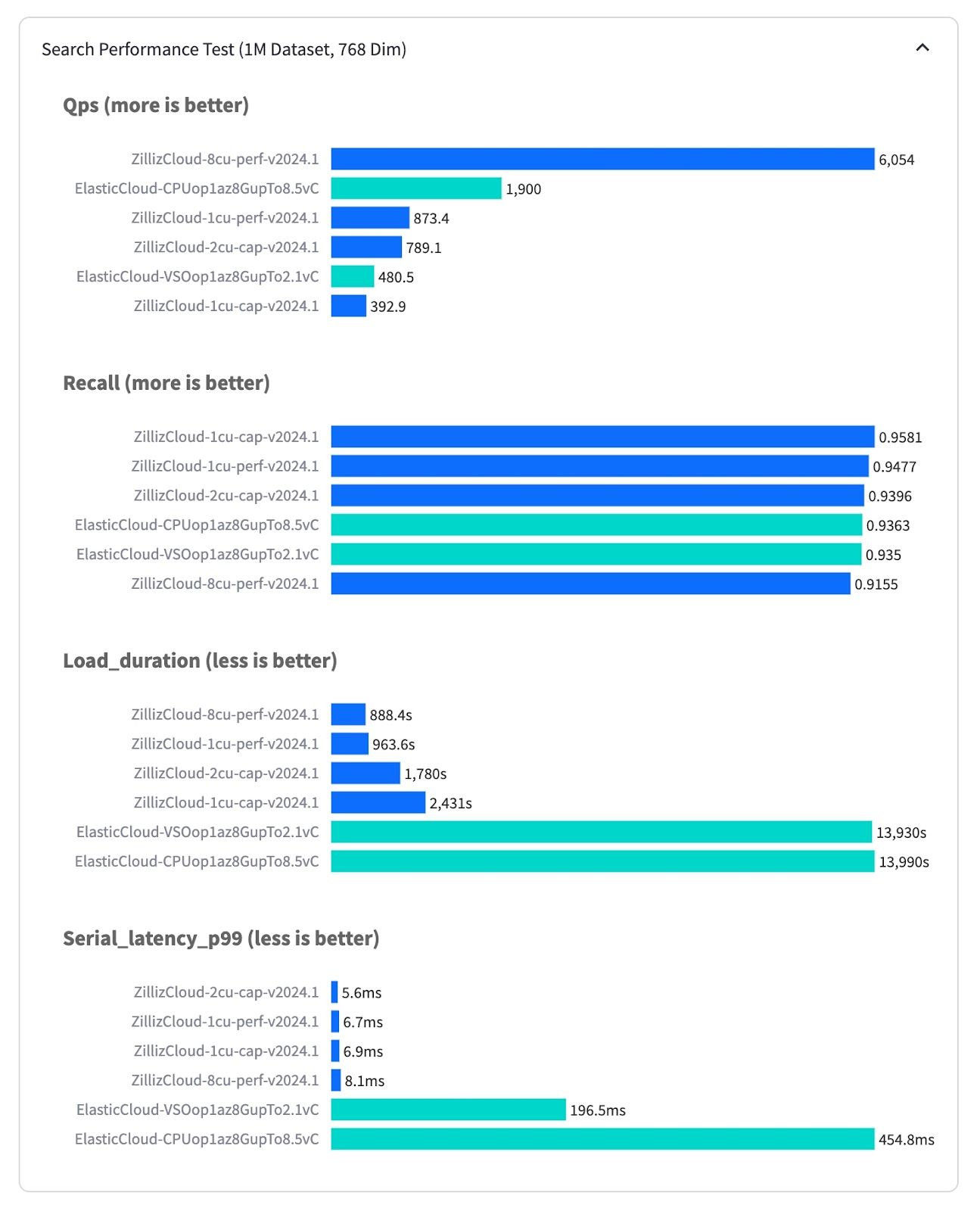 VectorDBBench Benchmarking Results.jpg
VectorDBBench Benchmarking Results.jpg
Figure: VectorDBBench Benchmarking Results (source)
Conclusion
Vector databases, exemplified by Milvus, are poised to surpass Elasticsearch as the unified solution for hybrid search. By integrating dense vector search with optimized sparse vector techniques, vector databases offer superior performance, scalability and efficiency. This unified approach simplifies infrastructure, reduces memory footprint and enhances search capabilities, making it the future of advanced search needs. As a result, vector databases provide a comprehensive solution that seamlessly combines semantic and full-text search, outperforming traditional search systems like Elasticsearch.

Keep Reading

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.