




Zilliz Cloudでのコレクション作成がさらに簡単になりました
適切なデータスキーマの構築は、あらゆるデータベースアプリケーションにとって極めて重要です。そしてプロジェクトの複雑性が増すにつれて、より強力な設定オプションが必要になります。Zilliz Cloud ではこれまでも SDK を通じて高度な機能を提供してきましたが、これらの機能を UI から直接利用したいという皆さまのフィードバックを受け止めました。
本日、まさにそれを実現します。コレクション作成体験全体を強化し、高度な機能をインターフェースに直接組み込むことで、ツールを切り替えることなく、本番環境対応のスキーマをより迅速かつ簡単に構築できるようにしました。
全文検索とキーワードマッチングが UI で利用可能に
全文検索は、用語の関連性に基づいてドキュメントをランク付けするもので、RAG(Retrieval-Augmented Generation)やキーワード重視のアプリケーションに不可欠です。生のテキストに直接作用し、スパースベクトルを自動生成します。手動での埋め込みは不要です。一方、キーワードマッチングは、完全一致フレーズのフィルタリングや精密な検索に最適です。
以前は、どちらの機能も SDK 経由でのみ利用可能でした。設定には、input text field、function、output sparse field がどのように連携するかを理解する必要があり、設定ミスが起こりやすく、デバッグも困難でした。
今回のアップデートにより、全文検索は完全に UI 主導で利用できるようになりました。VARCHAR 列を選択し、関数(Standard または Custom Analyzer)を選び、スパースフィールドを割り当てます。必要に応じてコードワークフローへスムーズに移行できるよう、SDK コードサンプルもインラインで表示します。
キーワードマッチングは、ワンクリックのトグルで有効化できるようになりました。特定のフィールドに対して直接有効化できるため、設定がより迅速で直感的になります。
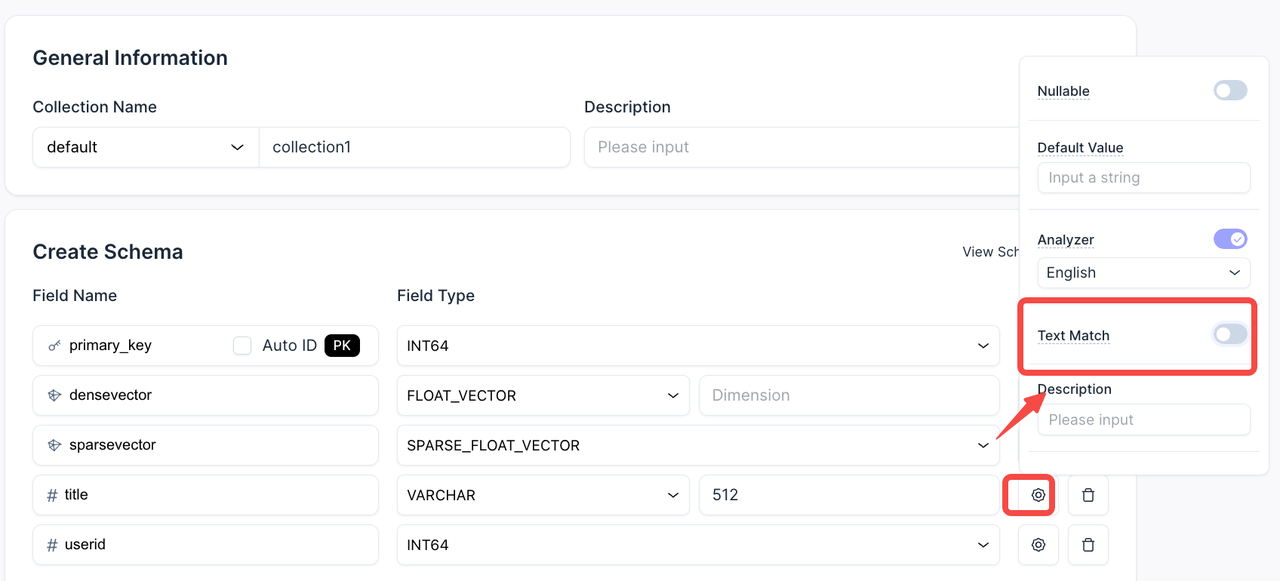 全文検索とキーワードマッチングが UI で利用可能に.png
全文検索とキーワードマッチングが UI で利用可能に.png
パーティショニングをシンプルに:適切な選択のための明確なガイダンス
パーティショニングは、特にマルチテナント環境や大規模環境におけるパフォーマンスチューニングに不可欠です。しかし、Partition と Partition Key の違いは必ずしも明確ではありませんでした。そしてその違いは重要です。
Zilliz Cloud では:
Partition は Collection の物理的なサブセットです。同じスキーマを共有しますが、データの一部のみを含みます。ワークロードの分離やクエリパフォーマンスの向上に最適です。
Partition Key を使うと、スカラー フィールドを使用してテナント間でデータを分割でき、スケールした論理的分離を実現できます。
以前は、パーティションの作成、定義、管理を SDK 経由で行う必要がありました。名称が似ていることや、相互に排他的な挙動により混乱が生じやすく、設定ミスはコストが高くつく可能性があり、場合によってはデータの完全な再ロードが必要になることもありました。
現在は、これをよりシンプルで安全にしました。コレクション作成時に、UI が Partition と Partition Key の違いを明確に説明し、ニーズに合った適切な設定を選べるよう支援します。新しいパーティション管理ページでは、パーティションの作成とプレビュー、そしてそれらへのデータの直接インポートが可能です。
Partition Key が有効な場合、パーティションは自動的に管理されます。UI は競合を防ぐため、手動パーティショニングを無効化します。
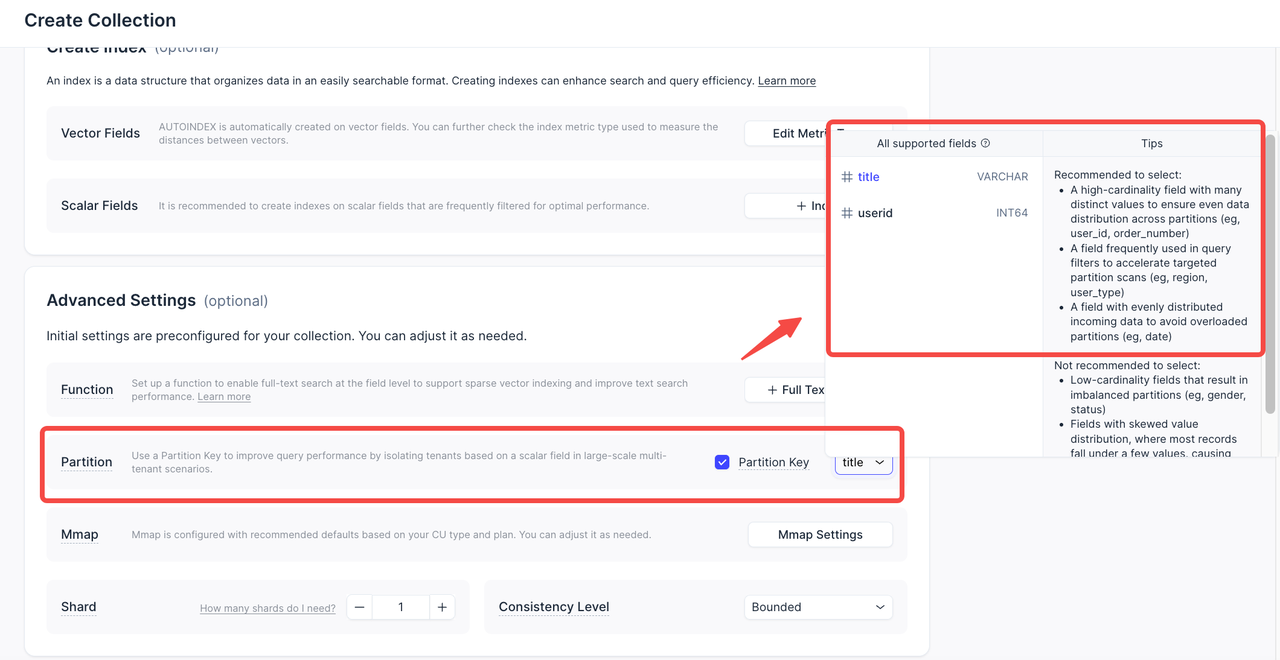 パーティショニングをシンプルに - 適切な選択のための明確なガイダンス
パーティショニングをシンプルに - 適切な選択のための明確なガイダンス
メモリマッピング制御:作成時だけでなく、いつでも設定可能
Mmap(メモリマッピング)は、特に大規模なフィールドやアクセス頻度の低いフィールドにおいて、メモリ使用量を削減し、スループットを向上させる強力な機能です。しかし、これまでは管理が難しいものでした。
以前は、Mmap はコレクション作成時に有効化する必要があり、変更は SDK 経由でしか行えませんでした。また、変更を行うためにコレクションをいつ解放する必要があるのか、あるいは Mmap をデータに適用するさまざまな方法について、インターフェース上で説明されていませんでした。
これらすべてに対応しました。
Mmap 設定は、より細かく明示的になりました。フィールドレベル、コレクションレベル、クラスターレベルの優先順位が明確に定義されています。
コレクションレベルまたはカラムレベルで、必要に応じて Mmap を設定できるようになりました。また、raw data と index data を別々に設定できます。
Mmap のステータスは、スキーマビューで直接確認・編集できます。コレクションを解放するだけで、UI から設定を更新できます。
Nullable とデフォルト値のサポート:より堅牢な書き込み、よりすっきりした UI
すべてのフィールドにデフォルト値や null 許容設定が必要なわけではないことは承知しています。しかし、特に不完全なデータや柔軟なスキーマを扱う場合など、必要な場面では不可欠です。
以前は、これらのオプションが未使用の場合でも、コレクション作成インターフェースを煩雑にしていました。現在は、操作体験を効率化しました。Nullable とデフォルト値の設定は、デフォルトでは折りたたまれています。必要なときには引き続き利用できますが、頻繁に行う操作の妨げにはなりません。
これにより、よりすっきりしたインターフェースを利用しながら、必要なときには完全なフォールトトレランス制御を保持できます。
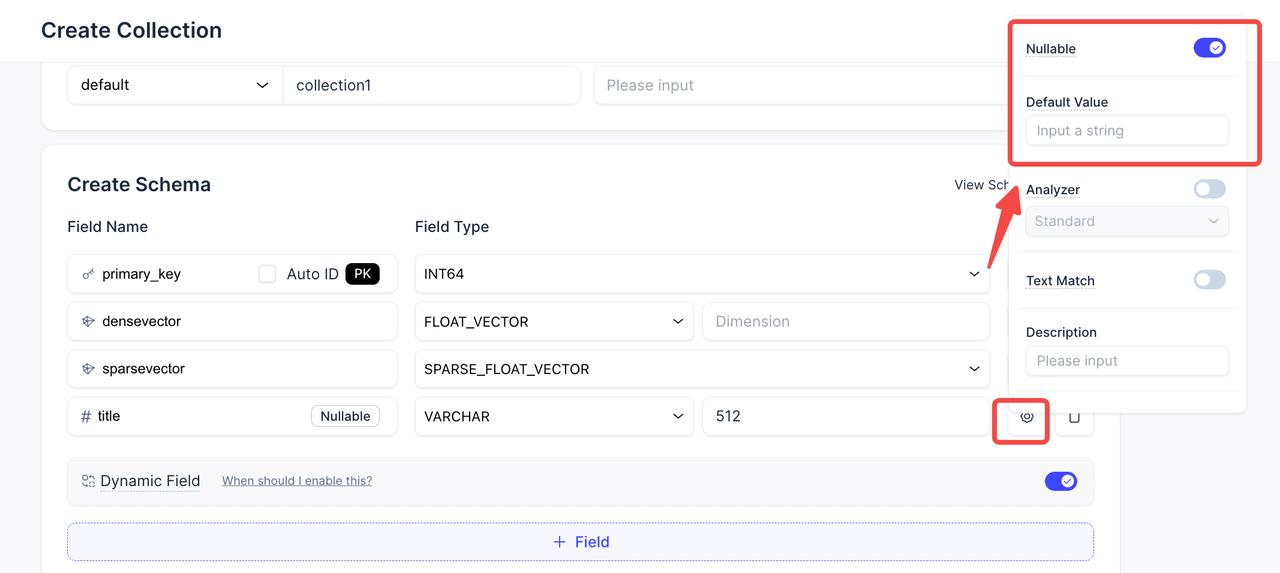 Nullable とデフォルト値のサポート - より堅牢な書き込み、よりすっきりした UI
Nullable とデフォルト値のサポート - より堅牢な書き込み、よりすっきりした UI
完全なインデックス管理:スカラーインデックスとベクトルインデックスを一か所で
インデックスは、高速な検索とフィルタリングに不可欠です。以前は、コレクションを作成するとベクトルインデックスは自動的に設定されていましたが、スカラーインデックスを作成したい場合は、SDK を使用して別途設定する必要がありました。また、UI ではスカラーインデックスがなぜ重要なのかも説明されていなかったため、ほとんどのユーザーはこの手順を省略していました。その結果、パフォーマンスのボトルネックが発生していました。ユーザーが適切なインデックスなしでスカラーフィールドを使用してデータをフィルタリングすると、クエリが本来よりも大幅に遅くなっていました。
今回のアップデートで、これらすべての問題に対応しました。
コレクション作成フローに完全なインデックス作成モジュールが含まれるようになり、インデックスが重要な理由を説明し、適切なインデックスの設定をガイドします。
専用のインデックス管理ページが追加され、すべてのインデックスタイプの作成、削除、プレビューをサポートし、ライフサイクル全体の管理を UI に統合しました。
JSON Path インデックスのサポートが利用可能になり、JSON および動的フィールドのクエリパフォーマンスを大幅に向上させます。
Shard と Consistency Level が UI で表示されるようになりました
Collection レベルで最も強力な設定の 2 つである Shard と Consistency Level は、これまで UI では非表示でした。そのため、デフォルト設定がワークロードに適しているかどうかを検証するのが困難でした。
Shards は Collection を水平方向に分割し、同時書き込みチャネルを可能にします。これにより、書き込みスループットが大幅に向上します。
Consistency Level は、検索およびクエリ操作中にデータがどの程度新鮮である必要があるかを制御します。デフォルトでは、鮮度とパフォーマンスのバランスを取る
Boundedを使用します。
今回のアップデートでは、コレクション作成フローの最初の段階で両方の設定を表示するようにしました。組み込みの説明と使用ガイダンスにより判断をサポートしながら、アプリケーションのニーズに基づいてすぐにカスタマイズできます。
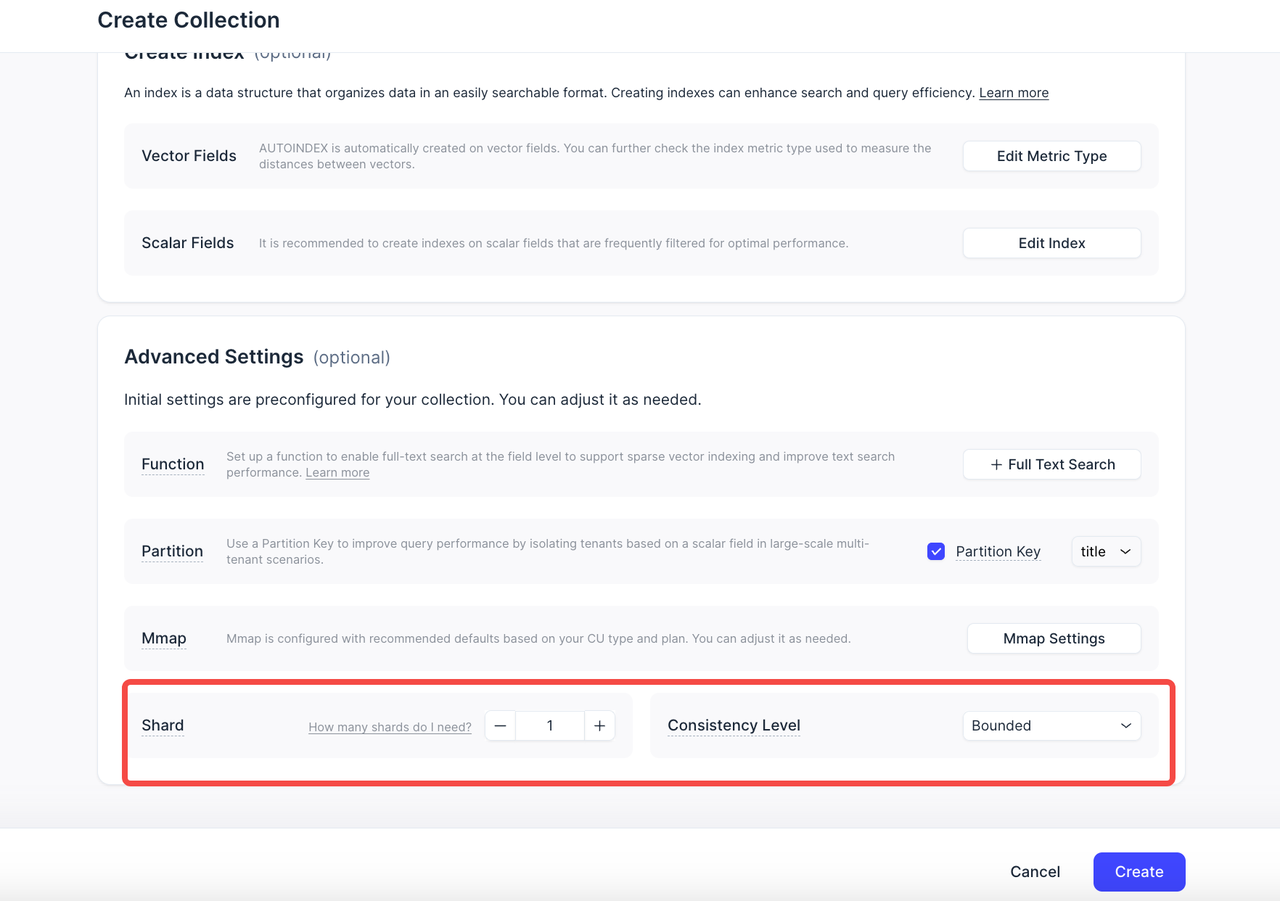 Shard と Consistency Level が UI で表示されるようになりました
Shard と Consistency Level が UI で表示されるようになりました
強化されたスキーマ設計:より優れた Dynamic Field の統合
Dynamic fields を使用すると、スキーマを変更せずに新しいフィールドを挿入できます。柔軟なデータ構造を持つアプリケーションに最適です。しかし、Zilliz Cloud UI ではこれが単なるトグルとして表示されていたため、dynamic fields が scalar 列や vector 列とどのように関連するのかが分かりにくくなっていました。
現在では、dynamic fields はスキーマ設計において scalar フィールドや vector フィールドと並んで表示されます。この強力な機能がスキーマにどのように適合するかを理解できるよう、説明ラベルも追加しました。
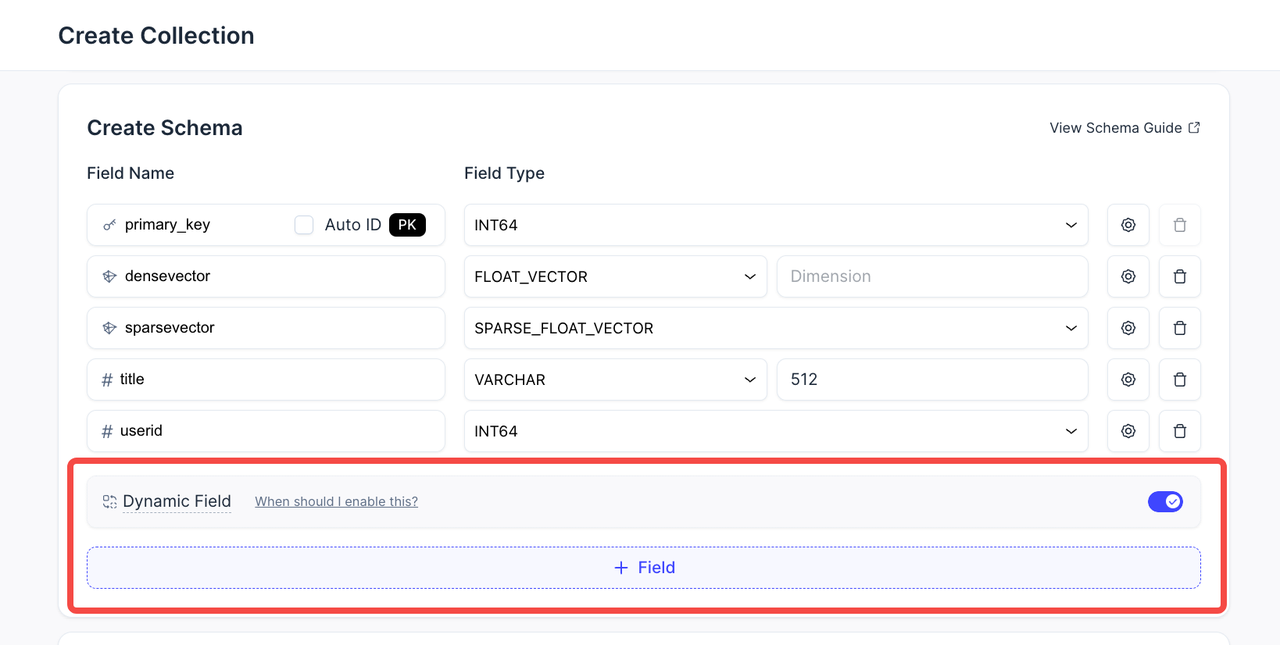 強化されたスキーマ設計- より優れた Dynamic Field の統合
強化されたスキーマ設計- より優れた Dynamic Field の統合
また、Data Import を Data Preview に統合し、ワークフローを簡素化してタブ切り替えを減らしました。
結論:最初から正しく構築する
Zilliz では、コレクション作成が当て推量であってはならないと考えています。正しいスキーマは、クエリパフォーマンスからコスト効率、AI アプリケーションをどれだけ迅速にスケールできるかに至るまで、すべての基盤です。
このアップグレードは、単に設定を追加するためのものではありません。最初から自信を持ってデータモデルを設計できるよう、明確さと制御性を提供するためのものです。パーティションの設定、Mmap の切り替え、インデックスの定義、整合性設定の微調整など、すべてが UI から直接、より見やすく、理解しやすく、管理しやすくなりました。
これらの改善により、インフラストラクチャの複雑さを心配する必要がなくなり、ベクトル検索を活用した、より高速でスマート、よりインテリジェントなアプリケーションの構築に集中できます。
Zilliz Cloud を始める
強化されたワークフローを体験する準備はできましたか?新しいインターフェースは、すべての Zilliz Cloud ユーザーに向けてすでに利用可能です。
既存ユーザー: Zilliz Cloud コンソールにログインし、新しいコレクションを作成して更新された機能を試してみてください。既存のコレクションはこれまで通り変更なく動作し続けます。
Zilliz Cloud が初めてですか? 無料でサインアップ して、最大 $200 分のクレジットで始めましょう。シンプルになったスキーマ設計ツールで、マネージドベクトルデータベースの力を体験してください。
ヘルプが必要ですか? ベクトルデータベース設定の最適化に関するガイダンスについては、our ドキュメント を確認するか、our サポートチームにお問い合わせ ください。
いつものように、Zilliz Cloud をさらに改善し続けるため、皆さまからのフィードバックをお待ちしています。

読み続けて

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.