




機械学習におけるK-meansクラスタリングアルゴリズムを理解する
K-meansクラスタリング、K-meansアルゴリズム、あるいはK-meansクラスタリング・アルゴリズム-さて、クラスタリング・アルゴリズムがどのようなものであるかを説明する前に、現代の企業にとって、データ(製品に関するデータ、顧客に関するデータ、取引に関するデータなど)を理解することがいかに不可欠であるかを理解する必要がある。
テクノロジーがビジネスを再定義する世界において、企業は数百万ドルを費やしてデータを分析し、より効率的で利益向上に役立つパターンを開発している。属性に基づいてオブジェクトをグループ化することは、このようなパターンを考え出すプロセスに関わる最初のタスクの1つである。
オブジェクトをグループ化することで、企業はさまざまな状況に応じた戦略を設計することができる。顧客、製品、取引は、このようなプロセスで中心的な関心を集める対象である。行動に基づいて顧客をグループ化することは、企業がパーソナライズされたサービスを設計するのに役立つ。商品をグループ化することで、顧客に別の選択肢を提供することができる。また、トランザクションをグループ化することは、綿密な注意を必要とする異常なパターンを特定するのに役立つ。
ここでクラスタリングが登場する。クラスタリングは、属性に基づいてオブジェクトをグループ化する教師なし機械学習(ML)アルゴリズムである。
この包括的な記事は、生産可能なAIのための主要なベクトル・データベース企業であるZillizからのもので、機械学習におけるK平均クラスタリング・アルゴリズムがどのようなものなのか、そしてPythonを使ってどのように実装することができるのかについて深く掘り下げます。また、K-meansクラスタリング・アルゴリズムをどのような場合に使用するかを探り、実際のK-meansクラスタリングの例を示します。
クラスタリングとは何か?
クラスタリングとは、特定のグループの各要素が、他のグループの要素よりもそのグループの要素に類似するように、データ点をグループ化するプロセスです。クラスタリングは特定のアルゴリズムを指すものではありません。多くのアルゴリズムを使用することで解決できる一般的なタスクです。クラスタリング・アルゴリズムは一般に、類似性を体系的に定量化するためのメトリックを定義する。クラスタリングは画像処理、情報検索、推薦エンジン、データ圧縮など多くの分野で使われている。
クラスタリングは、クラスタリングする対象の属性に基づいて類似性を確立する。属性はドメインによって異なる。例えば画像の場合、属性はピクセル値である。ユーザープロファイルの場合、属性は年齢、性別、購入履歴などの詳細である。商品の場合、属性はカテゴリー、色、価格などである。クラスタリングが教師なしタスクと呼ばれるのは、ラベル付けされたデータを準備するユーザー監視の学習プロセスがないからである。
クラスタリングアルゴリズムはどのように機能するか?
ほとんどのクラスタリングアルゴリズムは、すべてのサンプルのペア間の類似度を計算することで動作します。各データポイントは距離計算に基づいて最も近い重心に割り当てられます。これはクラスタリングプロセスの基本ステップです。
問題に対するクラスタリング・アルゴリズムを決定する際に考慮すべき重要な要素として、データセットの量に対する拡張性があります。実行時間は要素のペア数に応じて増加します。極端な場合には、データ量の2乗に比例して変化します。
クラスタリングへの4つのアプローチ
クラスタリングには、重心ベース、密度ベース、階層ベース、分布ベースの4つの一般的なアプローチがあります。1つずつ見ていきましょう。
1.セントロイドベースのクラスタリング
この方法は、クラスタ内のすべてのデータ点の重心に基づいて、データ点を階層化せずに個々のクラスタに編成します。セントロイドとは物体の幾何学的中心である。簡単に言えば、n次元空間におけるそのオブジェクトを構成するすべての点の算術平均である。ここでクラスタとは、セントロイドの周囲に位置する点の集まりである。セントロイドベースのクラスタリングは、初期割り当てと外れ値に関連する問題に悩まされる。
2.密度ベースのクラスタリング
その名前が示すように、これはある領域内の点の密度を計算し、高い密度が見つかったところでデータ点をクラスタに割り当てます。この場合、クラスターはどのような形でもよい。密度に基づくクラスタリングは、データが本質的に密度の分散が大きい場合に問題に直面する。データの次元が高い場合は、クラスタと隣接するクラスタを区別するのに苦労するため、うまく機能しません。
3.階層的クラスタリング
この方法は、より大きなクラスタの内部にクラスタが位置する可能性を持つクラスタの木を提供する。この方法は、データが固有の階層性を示す場合によく適合する。階層的クラスタリングは、分析者が必要なポイントでツリーを壊して、そのポイント以降のクラスタだけを考慮することができるので、実行後に任意の数の異なるクラスタを選択することができます。
4.分布ベースのクラスタリング
この方法は、クラスタを見つけるために確率分布の概念を使用する。クラスタ中心からの距離が大きくなると、ある点がクラスタに含まれる確率が減少すると仮定します。この方法を効果的に使用するために、開発者はデータの分布を知る必要があります。
K-means クラスタリングとは?
K-meansクラスタリングアルゴリズムは、重心ベースのクラスタリングアルゴリズムです。ラベル付きデータに依存しないので、教師なし学習アルゴリズムである。K-meansクラスタリングアルゴリズムの「K」はクラスタ数を表します。
K-meansは反復アルゴリズムであり、収束する前に平均または重心を何度も計算する。収束するまでの時間は、使用する初期割り当てと最適なクラスタ数に依存する。一般に、K-meansの時間複雑度は
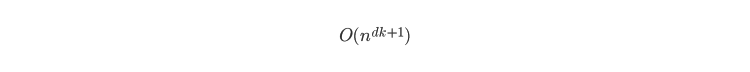
ここで d は次元数、 k はクラスタ数、 n はデータ要素のクラスタ数kである。
K-means クラスタリング・アルゴリズムは、クラスタの幾何学的中心からの各データ要素の距離を計算することで動作します。そして、特定のクラスタに属する点が他のクラスタの重心に近いと判断した場合、クラスタを再構成する。その後、クラスタ重心を再計算し、クラスタの再割り当てがなくなるまでこのプロセスを繰り返す。
このアルゴリズムがどのように機能するかを見てみよう。
K-means クラスタリングアルゴリズムはどのように機能するか?
K-meansクラスタリング・アルゴリズムは、4つの主要ステップを含む反復プロセスである。これらのステップを理解するために、2次元のクラスタリング問題を考えてみよう。点を(x1,y1)、(x2,y2)、...と仮定する。クラスタサイズは2から始める。
初期割り当て
このステップでは、各点を任意のクラスタに割り当てます。1つのオプションは、ランダムな点をクラスタのセントロイドとして割り当て、各データ点とセントロイド間の距離を計算することです。
点は、そのセントロイドが最も近いクラスターに割り当てられます。2つのクラスター間の距離は、ユークリッド距離の公式を用いて計算されます。例えば、x3,y3がランダムに割り当てられたセントロイドの1つである場合、x1,y1とx3,y3の間の距離はこの式を使って計算できる:
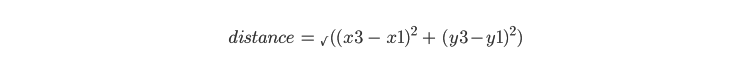
Y対X](https://assets.zilliz.com/image9_e716fe7063.png)
Y対X
赤と緑の点は初期ランダム重心割り当てを示します。これらの初期クラスタ重心のみに基づいて、初期クラスタ割り当てが以下のように表示されます:
Y vs. X](https://assets.zilliz.com/image7_021369b2ac.png)
Y vs. X
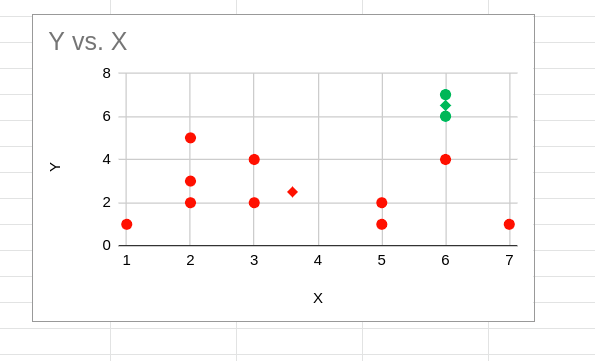
セントロイドの計算
このステップでは、各クラスタのセントロイドを再計算します。クラスタのセントロイドは、そのクラスタ内のすべての要素の算術平均を使用して計算されます。たとえば、x1,y1, x2,y2, x3,y3 がクラスタに属しているとします。そのクラスタのセントロイドは次のように計算されます:
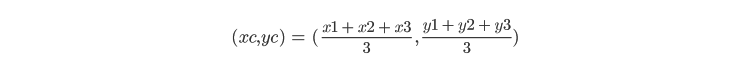
下図のような菱形の点が新しいセントロイドになる。
 Y対X
Y対X
Y対X
クラスターの再割り当て
3つすべてのクラスタの新しいセントロイドが見つかると、各ポイントと新しいセントロイド間の距離が再計算される。点のいずれかが、現在割り当てられているクラスターのセントロイドにより近い位置にある場合、その点は再割り当てされる。
Y対X](https://assets.zilliz.com/image5_113c51c9a6.png)
Y vs. X
収束
クラスタの再割り当ての後、セントロイドが再び計算され、プロセスが繰り返される。セントロイドの計算とクラスタの再割り当ては、新しい再割り当てがなくなるまで実行されます。この場合、収束したクラスタリングタスクは以下のように表示されます:
 Y対X
Y対X
Y vs. X
クラスター数の選択
理想的なクラスター数を選択するためによく使われる2つの方法は、エルボー法とシルエット法です。
エルボー法
エルボー法は、WCSS (Within Cluster Sum of Squares)と呼ばれる指標を計算します。WCSSは,上記の最も近いクラスタのセントロイドからの各点の距離の2乗和である.クラスタ数に対するWCSSのプロットは、最適なクラスタ数を選択するための指標として使用されます。
開発者はK-meansクラスタリングを1からnのクラスタ数で実行し、これらの実行のそれぞれについてWCSSを計算する。WCSSは単一クラスタ実行で最も高く、クラスタ数が増えると低くなる。WCSSが腕の肘のように鋭く曲がる点が、理想的な最適クラスタ数と考えられる。
エルボー法](https://assets.zilliz.com/image8_84e2645a1e.png)
エルボー法
シルエット法
この方法は、同じクラスターに属する他のメンバーとのオブジェクトの類似性の程度と、他のクラスターからのオブジェクトの分離の程度を理解しようとするものである。ある点のシルエット・スコアは、その点のクラスタ内の他の点からの平均距離(a)と、隣接するクラスタを含む他のクラスタに属するすべての点との平均距離(b)を組み合わせて計算される。一旦aとbが見つかると、点のシルエット・スコアは次のように計算される。
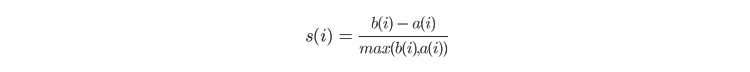
そして,各点のスコアが平均され,シルエット・スコアが求められる.スコアは最適カウントのすべての候補について計算され、k個のポイントを持ち、スコアが最も高いものが最適カウントとして選択される。
シルエット法](https://assets.zilliz.com/image12_3db3255a6e.png)
シルエット法
K-means クラスタリングアルゴリズムの実例 (Python による K-means クラスタリングの実装)
このチュートリアルでは、Pythonを使ってK-meansクラスタリングを実装し、最適なクラスタサイズを見つける方法を示します。これを行うために、eコマース領域で一般的な問題文を想定してみましょう。デモグラフィック属性と消費習慣に基づいて顧客をクラスタリングすることは、eコマース領域で一般的なタスクです。K-meansクラスタリングの例を単純化するために、ここでは2つの属性を使用します:顧客の年齢と1ヶ月あたりの平均消費額です。
1.そのために、scikit-learnと呼ばれるPython機械学習ライブラリと、matplotlibと呼ばれるプロット・ライブラリを使ってみよう。まず、以下に示すimport文を使ってライブラリを初期化する:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
1.次のステップは、入力データフレームを定義することである。ここで、最初の属性は年齢であり、2 番目の属性はインドルピー(INR)での月平均支出である。簡単にするために、コード内で配列を初期化します。ここには16個のデータポイントがあります:
raw\_features = np.array([[22,200],[24,200],[24,200],[20,800],[24,800],[24,800],[25,200],[54,200],[24,200],[54,200],[50,800],[53,800],[24,800],[55,800],[53,800],[50,800]])
1.そして、ある属性のばらつきが他の属性のばらつきを覆い隠さないように、データポイントを正規化する。
scaler = StandardScaler()
features = scaler.fit_transform(raw_features)
1.forループを実装して、クラスタ数を2から6まで変化させてK-meansクラスタリングを試す。次に、最適なクラスタ数を特定するために、平方和を計算し、それをクラスタ数に対してプロットする。
sse=[]
s_scores=[]
for i in range(2,6):
kmeans = KMeans(init = **"random "** ,n_clusters = i,n_init = 10,max_iter = 300,random_state = 42)
kmeans.fit(features)
sse.append(kmeans.inertia_)
s_scores.append(silhouette_score(features, kmeans.labels_))
1.matplotlib ライブラリを使用して、クラスタ数に対する平方和をプロットする。
plt.style.use( **"fivethirtyeight "** )
plt.plot(range(1, 6), sse)
plt.xticks(range(1, 6))
plt.xlabel( **"クラスター数 "** )
plt.ylabel( **"SSE "** )
plt.show()
1.上記のコードを実行すると、最適なクラスタ数を特定するために使用できるプロットが得られます。
K-平均クラスタリング](https://assets.zilliz.com/image10_3c09715ab1.png)
K平均クラスタリングアルゴリズム
上の散布図は4で明確な「肘」を示している。つまり、ここでの最適なクラスタ数は4である。データサイエンティストは、ある程度の専門知識があれば、この数を4つの組み合わせとして説明することができる。しかし、このような説明は常に可能とは限らず、最適なクラスタ数は問題の仕様によって異なります。
PythonでK-meansクラスタリングを実行する方法は以上です。scikit-learnとmatplotlibフレームワークを使えば、Pythonでクラスタリングを使うのはとても簡単だ。
K-平均クラスタリングアルゴリズムを使うとき
これまで学んできたように、クラスタリングは教師なし機械学習アルゴリズムであり、類似性に基づいてオブジェクトをグループ化するのに役立ちます。探索的なデータ分析のために多くの産業領域で広く使われています。
顧客セグメンテーション、推薦エンジン、類似検索などの分野で有用である。とはいえ、K-meansクラスタリングアルゴリズムは、これらの問題を解決するために使用できる唯一の手法ではない。このような問題を解決するもう一つの方法は、各オブジェクトの属性に基づいてベクトル埋め込みを生成することである。
ディープラーニングベースの学習ネットワークは、多数の属性を持つオブジェクトに対して多次元の埋め込みを生成することができる。これらの埋め込みは、優れたベクトルデータベースと相まって、類似性に基づく問題をはるかに優れた制御で解決することができる。
もし、あなたがそのような問題に取り組んでいるのであれば、Zillizをチェックしてみてください。これは、非構造化データを扱う際の課題に対するワンストップ・ソリューションを提供するもので、特にベクトル類似性検索を活用するAI/MLアプリケーションを構築する企業向けのものだ。
Zillizはオープンソースのベクトルデータベースとして広く認知されているMilvusを開発し、世界中で1000を超える企業ユーザーに利用されています。同社はまた、フルマネージドベクトルデータベースサービスであるZilliz Cloudを提供しており、企業はインフラストラクチャの構築や管理に煩わされることなく、Milvusのフルパワーを体験することができます。
知りたい方はベクターデータベースとは - 詳細ガイドをご覧ください。関連するトピックについてさらに情報をお探しですか?近似最近傍探索(ANNS)](https://zilliz.com/glossary/anns)の説明をご覧ください。Zillizがどのようにお役に立てるか、もっと知りたいですか?ここをクリック](https://zilliz.com/contact)してお尋ねください!
読み続けて

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.