




GLiNER: 双方向変換器を用いた名前付き固有表現認識のための汎化モデル
固有表現認識(NER)**は、自然言語処理(NLP)の重要なタスクであり、テキスト中の名前、場所、組織などのエンティティを識別し分類する。これにより、様々なアプリケーションのための構造化された情報抽出が可能になる。NERは、知識グラフの構築、情報の検索、コンテンツの分析などのタスクも扱うことができる。
従来のNERモデルは、あらかじめ定義されたエンティティを識別することに長けている。対照的に、大規模言語モデル(LLM)は、より複雑で多様なエンティティを扱うことができる。しかし、LLMはリソースを大量に消費することが多く、実用的な展開には課題がある。InstructUIE、UniNER、GoLLIEのような既存の名前付きエンティティ認識(NER)用の微調整されたオープンソースのLLMは効果的であるが、サイズが大きい、トークン生成に時間がかかる、エンティティの並列抽出に制限があるなどの課題がある。これらの問題に対処するため、研究者はGLiNERを開発した。これは、精度を維持しつつ、効率性、拡張性、多言語性能を向上させるように設計されたコンパクトで効率的なNERモデルである。
GLiNERは双方向の変換器エンコーダを使用したオープンソースのNERモデルである。並列エンティティ抽出を可能にし、従来のNERアプローチとLLMベースのNERアプローチの両方の限界に対処している。ゼロショット](https://zilliz.com/learn/what-is-zero-shot-learning)による多言語を含む様々なNERベンチマークの評価では、ChatGPTとUniNERのような微調整されたLLMの両方を凌駕している。GLiNERの最小バージョンでさえ、ゼロショット設定ではInstructUIEのような大規模モデルを上回る。
図:オープンNERのためのBiLM ](https://assets.zilliz.com/Figure_Bi_LM_for_open_NER_ec8f7b2e1d.png)
図:オープンNERのBiLM|出典
このブログではGLiNERとそのNERへのアプローチ、そしてNLPドメインへの影響について説明する。詳細は論文GLiNERをご覧ください。
##名前付き固有表現認識の概要
名前付き固有表現認識(NER)は自然言語処理(NLP)の基本的なタスクで、テキスト内の名前付きエンティティを識別・分類する。これらのエンティティは、人、組織、場所、日付などの実世界のオブジェクトを表す。
NER の主な構成要素
エンティティの検出:*** テキスト中の名前付きエンティティの境界を見つける(例えば、"Albert Einstein" を関心のあるスパンとして識別する)。
エンティティ分類:*** 検出された各エンティティに正しいラベルを割り当てる(例:"Albert Einstein" を Person とラベル付けする)。
GLiNER のアーキテクチャと機能の理解
GLiNERはBERTやDeBERTaのような双方向言語モデル(BiLM)を使用する。これらのモデルはテキストから豊かな文脈表現を捉えることで知られている。GLiNERのキーコンセプトは、NERタスクを、エンティティタイプの埋め込みを共有潜在空間におけるテキストスパン表現と比較するマッチング問題として捉えることである。これはNERを生成タスクとして扱う従来のアプローチとは対照的である。
GLiNERは3つの主要コンポーネントから構成される:
1.**GLiNERの基盤はDeBERTaのような事前に訓練されたBiLMであり、これがテキストエンコーダとして機能する。BiLMは入力シーケンスを処理し、単語間の文脈的関係を捕捉し、各トークンに対して文脈化された表現(埋め込み)を生成する。
2.スパン表現モジュール: このコンポーネントは、入力テキスト内の各スパンの表現を計算する。スパン表現は、各スパンの開始と終了のトークンに対するBiLMの出力を組み合わせることで得られる。これらのembeddingsは、関連するエンティティタイプの表現と密接に整合するように最適化されている。
3.**このコンポーネントは、モデルが抽出しようとする各エンティティタイプの埋め込みを生成する。エンティティタイプを表す特別なトークンがBiLMに渡され、その出力がフィードフォワードネットワークを使って洗練される。これらのエンティティの埋め込みは、スパンの埋め込みと比較され、一致が判定される。
図:GLiNERアーキテクチャ](https://assets.zilliz.com/Figure_G_Li_NER_architecture_54582eaab7.png)
図:GLiNERアーキテクチャ|出典
GLiNERの仕組みはこうだ。
入力フォーマット
GLiNER は、エンティティを抽出するテキストと、潜在的なエンティティタイプのリストを入力として受 け取ります。これらの要素は単一の統一されたシーケンスに結合される。このシーケンスでは、[ENT] や [SEP] などの特殊トークンが重要な役割を果たす:
ENT]`トークンはリストの各エンティティタイプの前に置かれる。
ENT]
トークンはリストの各エンティティタイプの前に置かれ、[SEP]`トークンはエンティティタイプリストと入力テキストの間のセパレータとして機能する。ENT]
トークンも[SEP]` トークンも、学習処理の最初にランダムに初期化される。
図: 入力形式例 ](https://assets.zilliz.com/Figure_Example_input_format_e6f6b6015d.png)
図:入力フォーマット例|出典
BiLMによるトークン表現
次に事前に訓練されたBiLMが統一された入力シーケンスを処理する。BiLMはシーケンス全体を分析し、すべてのトークン間の関係を理解し、各トークンについて文脈に応じたベクトル表現を出力する。
- エンティティ型トークン(
[ENT]に関連付けられたトークン)の出力はp.
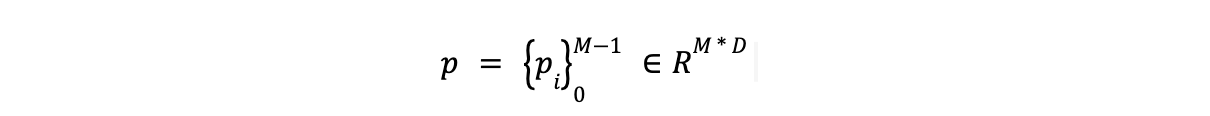
- 入力テキスト内の各単語の出力は h で表される。
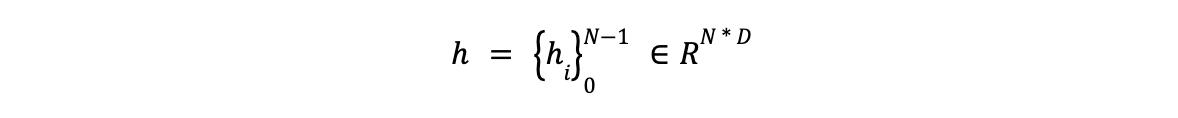
- トークン化でサブワードに分解された単語に対して、GLiNERはNERで一般的な最初のサブワードの表現を使用する。
エンティティとスパンの埋め込みを生成する
GLiNERはエンティティ・タイプとテキスト・スパンの両方を、効果的に比較できる統一された潜在空間にエンコードすることを目指している。これには以下が含まれる:
- エンティティ表現の精密化:** エンティティタイプ(p)の初期表現は、2層のフィードフォワードネットワーク(FFN)を用いて精密化される。この結果、エンティティタイプを潜在空間にマップする新しい表現(q と表記)が生成される。
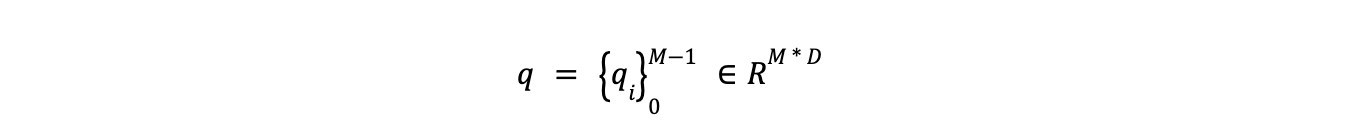
- スパン表現の計算:**スパンとは、入力テキスト内の連続した単語の並びのことである。GLiNERは別の2層FFNを用いて、各スパンの埋め込みを計算する。このFFNはスパンの開始と終了のトークンを連結した表現で動作する。この処理により、GLiNERはスパンの意味を全体として捉えることができる。
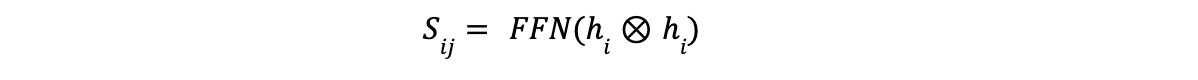
エンティティ・タイプとスパンのマッチング
GLiNERは、エンティティ・タイプとスパンの両方を同じ潜在空間に符号化し、対応する埋め込み間のマッチング・スコアを計算することで、スパンが特定のエンティティ・タイプに属する尤度を決定する。マッチング・スコアは、スパンの埋め込みSijとエンティティの埋め込みqtの内積を用い、シグモイド活性化関数を用いて計算される。結果のスコア(i, j, t)は、スパン(i, j)がタイプtである確率として解釈できる。
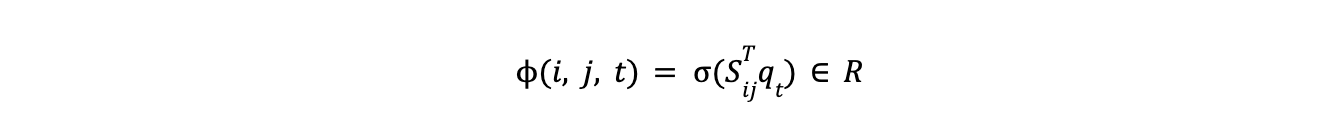
バイナリCross-Entropy Lossを使用した学習中、モデルは正しい(正)スパンとエンティティのペアのマッチングスコアを最大化し、正しくない(負)ペアのマッチングスコアを最小化する。
正のペアは、スパンが訓練データで実際にエンティティタイプでラベル付けされているものである。
負のペアは、同じバッチ内の他の例からエンティティをランダムにサンプリングして生成される。これは、モデルが真と偽のエンティティ割り当てを効果的に識別するのに役立ちます。
個々の例の訓練損失は、次のように定義されます:
個々の例に対する学習損失](https://assets.zilliz.com/The_training_loss_for_an_individual_example_is_defined_as_6a1cb2bea2.png)
欲張りスパン選択によるデコーディング
GLiNERは、デコーディング段階で入力テキストから最も可能性の高いエンティティを抽出するために、貪欲なスパン選択アルゴリズムを使用する。このアルゴリズムは、最も高いマッチングスコアを持つ非重複スパンを優先する。NERの2つのモードをサポートする:
フラットNER:**このモードでは、重複しないスパンのみを選択し、最も高いスコアを持つものを優先する。
このモードでは、部分的な重複を避けながら、入れ子になったスパン(他のエンティティに完全に含まれるスパン)を選択することができます。
この貪欲なアプローチにより、GLiNERはタスク固有の制約を守りながら、関連するエンティティを効率的に抽出する。
GLiNERの実験とハイパーパラメータの設定
GLiNERの有効性を評価するために、慎重に設計された実験セットアップとロバストなハイパーパラメータ設定が実装された。モデルはPile-NERデータセットで学習される。このデータセットは44,889のパッセージからなり、240,000のエンティティスパンと13,000のユニークなエンティティタイプを持つ。このデータセットはPileコーパスから派生したもので、50,000のテキストがサンプリングされ、ChatGPTを使ってアノテーションされている。アノテーションは事前に定義されたタイプ制約なしで生成され、データセットが多様なエンティティを捕捉できるようにした。
ChatGPTによるエンティティ抽出のプロンプト](https://assets.zilliz.com/Prompting_Chat_GPT_for_entity_extraction_19942e1c0d.png)
図:エンティティ抽出のためのChatGPTのプロンプト|出典
GLiNERは、経験的な強さが証明されているdeBERTa-v3モデルをバックボーンとして採用しています。このモデルは768の次元幅を持つ非プレットレイヤーを組み込み、オーバーフィッティングを緩和するために0.4のドロップアウト率を適用します。
学習プロセスは最大30,000ステップまで継続され、10%のウォームアップフェーズと、コサインスケジューラによって制御される減衰フェーズが続く。負のエンティティタイプは、特定のエンティティタイプが存在しない場合のモデルの処理能力を向上させるため、訓練中に同じバッチ内の他の例からランダムにサンプリングされる。
正則化](https://zilliz.com/learn/understanding-regularization-in-nueral-networks) いくつかの正則化戦略が、モデルの頑健性を向上させ、オーバーフィッ ティングを防止するために実装されています。これらの戦略には以下が含まれます:
エンティティの順序をシャッフルする: **これは、入力内の位置に関係なく、モデルがエンティティを識別するのに役立ちます。
エンティティのランダムな削除:** これは、情報が欠落していたり不完全であったりする場合に、モデルに強制的に処理させます。
学習時の計算の複雑さを管理するために、文ごとに処理されるエンティティタイプの数に制約が課せられます。この制限は 25 に設定されている。
GLiNER の性能分析
学習後、GLiNERの性能を様々なNERベンチマークでテストし、その有効性の要因を分析した。
英語データセットにおけるゼロショット性能
GLiNERはゼロショット設定で評価された。つまり、Pile-NERデータセットで学習され、さらに微調整することなく未見のデータセットで直接テストされた。
OOD NERベンチマーク
OOD (Out-of-Domain) NER Benchmarkは7つの多様なNERデータセットから構成され、 GLiNERの異なるドメインへの汎化能力を評価するために使用された。GLiNERはその全てのサイズバリエーション(小、中、大)において、ChatGPT、Vicuna、そしてさらに大規模なInstructUIEのようなモデルを凌駕する印象的なパフォーマンスを示した。
特筆すべきは、中型のGLiNERは140倍も小さいにもかかわらず、13BのUniNERモデルに匹敵する結果を達成したことである。最大のGLiNERモデルは、GoLLIE(最も優れたパフォーマンスを示したLLM)やUSMを含む競合モデルを常に上回っていた。
図:Out-of-Domain NERベンチマークのゼロショット・スコア](https://assets.zilliz.com/Figure_Zero_Shot_scores_on_Out_of_Domain_NER_benchmark_d1facdeab2.png)
図:アウトオブドメインNERベンチマークのゼロショットスコア|出典
20 NERベンチマーク
GLiNERはさらに、様々なドメインにまたがる20のNERデータセットのベンチマークで評価された。GLiNERはほとんどのデータセットでChatGPTとUniNERを上回り、その頑健性と異なるドメインへの適応性を実証した。しかし、ツイートベースのNERデータセットではUniNERに劣り、非公式でノイズの多いテキストの処理に改善の余地があることが明らかになった。
20のNERデータセットにおけるゼロショット性能](https://assets.zilliz.com/Zero_shot_performance_on_20_NER_datasets_f2b0fe91c1.png)
20のNERデータセットにおけるゼロショット性能|出典
ゼロショット多言語評価
未知の言語に対するGLiNERの汎用性を評価するため、11言語のデータを含むMulticonerデータセットで評価した。GLiNERの2つのバージョンを使用した:
一つは英語のDeBERTaバックボーンを持つもの(GLiNER-En)である。
1つは多言語DeBERTaバックボーン(GLiNER-Multi)である。
GLiNER-Multiは、ほとんどの言語でChatGPTを凌駕し、目覚しい性能を発揮した。それは
は、その言語で訓練されていないにもかかわらず、クロスリンガル・トランスファー能力を実証した。スペイン語では、英語よりもわずかに優れた結果を示した。
異なる言語でのゼロショットのスコア ](https://assets.zilliz.com/Zero_Shot_scores_on_different_languages_58c94ec8b1.png)
異なる言語でのゼロショットのスコア|出典
領域内教師付き微調整
GLiNERは教師あり設定でLLMと性能を比較するため、20のNERデータセットで微調整も行った。1つはゼロショット・モデル(Pile-NERで事前学習済み)の重みで初期化したもの、もう1つはゼロから学習したものである。事前訓練された変種は、事前訓練されていない変種を常に上回り、多様なデータセットでの事前訓練の利点を示している。
異なるデータセットサイズにおける教師ありのパフォーマンス](https://assets.zilliz.com/Supervised_performance_across_different_dataset_sizes_fd9a7f77a0.png)
異なるデータセットサイズにおける教師ありの性能|出典
事前訓練されたGLiNERはまた、はるかに大規模なInstructUIEを上回り、GLiNERのアーキテクチャの効率性を浮き彫りにした。UniNERには及ばなかったものの、GLiNERは20データセットのうち7データセットで最高スコアを達成した。
図:ドメイン内教師ありファインチューニング](https://assets.zilliz.com/Figure_In_domain_supervised_finetuning_0158f7670c.png)
図:ドメイン内教師ありファインチューニング|出典
w/**は"with"_を表し、GLiNERモデルが20のNERデータセットでファインチューニングを行う前に、まずPile-NERデータセットで学習されたことを意味する。
w/o_は"without**"を表し,GLiNER モデルを Pile-NER データセットで事前学習していないことを示す.
様々なアーキテクチャの選択と学習戦略
GLiNERのパフォーマンスを最適化し、多様なシナリオへの適応性を確保するために、いくつかのアーキテクチャとトレーニング戦略が検討された。
異なるバックボーンの評価
GLiNERはさらに、異なるBiLMバックボーンを用いて、それらが性能にどのような影響を与えるかを調査した。BERT](https://zilliz.com/learn/what-is-bert)、RoBERTa、ALBERT、ELECTRA などのさまざまなモデルがテストされ、DeBERTa-v3 が一貫して最高の性能を示した。しかし、どのバックボーンも既存のモデルと比較し て強い結果を示した。このことから、GLiNERのアーキテクチャは異なるBiLM間で有効であることが示唆された。
図:異なるバックボーンにおけるゼロショット性能](https://assets.zilliz.com/Figure_Zero_shot_performance_for_different_backbones_3bd68282fa.png)
図:異なるバックボーンにおけるゼロショット性能|出典
ネガティブ・エンティティ・サンプリングの影響の評価
ネガティブエンティティサンプリングは、実世界のデータには特定のエンティティタイプが欠落して いることが多いことを認識するために、トレーニング中に導入されます。モデルの性能は、異なる負サンプリング比率(0%、50%、75%)を使用して評価され、50%の比率が精度と想起の最良のバ ランスを提供します。肯定的なエンティティのみで学習すると、誤検出が多くなり(精度が低下)、否定的なサンプリング比率が高いと、モデルが過度に慎重になり、エンティティの見落としが発生する(再現率が低下)。
図:負のエンティティタイプのサンプリングの効果 ](https://assets.zilliz.com/Figure_Effect_of_negative_entity_types_sampling_e0a9116c14.png)
図:負のエンティティタイプのサンプリングの効果|出典
ランダムなエンティティタイプ抽出の利点の評価
学習中にエンティティタイプのプロンプトをランダムに削除することで、モデルのロバスト性と、実世界のシナリオでエンティティの数が変化した場合の適応性が向上します。この手法により、領域外評価で平均 1.4 ポイントの改善が見られます。
図: エンティティタイプのランダムドロップ](https://assets.zilliz.com/Figure_Randomly_dropping_entity_types_9eb7ac7fd8.png)
図:エンティティタイプをランダムに削除する|ソース
GLiNER開発の意味合い
GLiNERの開発は、名前付き固有表現認識(NER)の分野にとって重要な意味を持つ:
NERのリソース効率:** GLiNERは大規模なLLMよりも小さなモデルサイズで強力な性能を達成することで、NERを進歩させる。この効率性はリソースが限られた環境において有益であり、様々なアプリケーションにおいてNERをより利用しやすくする。GLiNERはLLMの計算オーバヘッドなしにBiLMを効果的に使用し、NERを潜在空間におけるエンティティ型埋め込みとテキストスパン表現間のマッチングタスクとして構成する。
GLiNERはゼロショット設定において非常に優れた性能を発揮し、タスクに特化した微調整を行うことなく、NERベンチマークにおいて最先端の結果を達成している。GLiNERの様々なドメインや言語にわたる汎化能力は、ラベル付きデータが限られたシナリオにおいて有望なソリューションとなる。
プリトレーニングによる性能向上:**ドメイン内タスクのファインチューニングの前にPile-NERデータセットでプリトレーニングを行うことで、顕著な性能向上が見られる。これは特に教師データの量が限られている場合に当てはまる。この効果はデータセットが小さいほど顕著である。このことは、事前トレーニングが効果的な知識伝達を促進し、モデルの汎化能力を高め、新しいドメインやエンティティタイプに適応することを示唆している。
今後の研究の方向性
GLiNERの能力をさらに向上させるために、いくつかの研究手段を探ることができる:
代替アーキテクチャの探求**:GLiNERの現在のアーキテクチャーは効果的であるが、異なるBiLM(双方向言語モデル)のバリエーションを実験したり、新しいスパン表現技術を導入することで改善の余地がある。このような技術革新はさらなる性能向上につながり、GLiNERがより複雑なタスクに効率よく取り組むことを可能にします。
ノイズの多い非公式なテキストの処理:GLiNERは多くの文脈で優れた性能を発揮するが、ノイズの多い非公式なテキストを扱う能力には改善が必要である。ソーシャルメディアコンテンツには、スラング、略語、非標準的な文法が含まれることが多く、ユニークな課題があります。将来的には、GLiNERを改良して、これらのニュアンスをよりよく捉え、このような非構造化テキストを処理する際の頑健性を向上させることに重点を置くことができるだろう。
外部知識の統合**:知識グラフやドメイン固有ガゼッタのような外部知識ソースを統合することで、GLiNERの曖昧性解消の精度を向上させることができる。これらのリソースをモデルのアーキテクチャに組み込むことで、研究者はより正確で文脈を意識した名前付き実体の表現を開発し、パフォーマンスを向上させることができる。
ドメイン固有のユースケースのためのファインチューニング**:GLiNERのゼロショットの性能は印象的であるが、ドメイン固有の微調整によってさらに洗練される可能性がある。バイオメディカルテキストマイニングや法的文書解析のような分野は、このアプローチから恩恵を受ける可能性があります。これによりGLiNERは、エンティティ認識が複雑で専門的な言語パターンを捉える必要がある特殊な分野に適応しやすくなります。
結論
GLiNERはNERにおける重要な進歩である。コンパクトな双方向変換モデルにより、効率性、適応性、アクセシビリティを兼ね備えている。GLiNERは、ChatGPTやUniNERのような代替モデルを凌駕し、大きなモデルの計算コストなしに、強力なゼロショットと多言語性能を達成する。
今後の研究としては、代替アーキテクチャの探求、ノイズの多い非正規のテキストにおける頑健性の向上、より良い固有表現曖昧性解消のための外部知識の統合、ドメイン固有のデータセットに対する微調整、クロスリンガル転送による低リソース言語での性能向上などが考えられる。これらの方向性は、多様なNERタスクにおけるGLiNERの有効性をさらに向上させる大きな可能性を秘めている。
その他のリソース
DistilBERT: A Distilled Version of BERT](https://zilliz.com/learn/distilbert-distilled-version-of-bert)
BERT (Bidirectional Encoder Representations from Transformers)とは](https://zilliz.com/learn/what-is-bert)
大規模言語モデルとは](https://zilliz.com/glossary/large-language-models-(llms))
ベクトル埋め込みとは](https://zilliz.com/glossary/vector-embeddings)

読み続けて

Introducing Zilliz CLI and Agent Skills for Zilliz Cloud
Manage your vector database from your terminal or AI coding agent. Zilliz CLI and Agent Skills work with Claude Code, Cursor, Codex, and Copilot.

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.