




LLMにおける知識注入:微調整とRAG
大規模言語モデル(LLMs)は、膨大な知識を保存し生成する能力において印象的である。事前学習時に膨大なデータセットを利用し、様々なトピックのエキスパートになる。しかし、LLMにも限界がある。ひとつは、時間が経過しても更新されないため、知識が静的であることだ。さらに、一般的な知識には長けているが、医療、金融、法律などの専門分野で必要とされる深い専門知識を提供するには不十分なことが多い。
これらの限界に対処するために、Fine-TuningやRetrieval-Augmented Generation (RAG)といった知識注入法が利用される。Fine-tuningはタスクに特化したデータでモデルの重みを調整するものであり、RAGは推論中に外部の知識を取り込み、必要なときにモデルが関連する情報を取り込めるようにするものである。本研究では、この2つのアプローチを様々な知識集約型タスクで比較し、LLMの事実知識を拡張・洗練する際の有効性を評価する。
RAGは知識集約型タスクにおいて常にfine-tuningを上回り、外部情報を統合する優れた能力を実証した。ファインチューニングはベースモデルよりもパフォーマンスを向上させたが、RAGほどの競争力はなかった。さらに、学習中に同じ事実の複数のバリエーションにモデルをさらすことで、知識の保持が強化されるため、データの増強は微調整に有益であることが証明された。
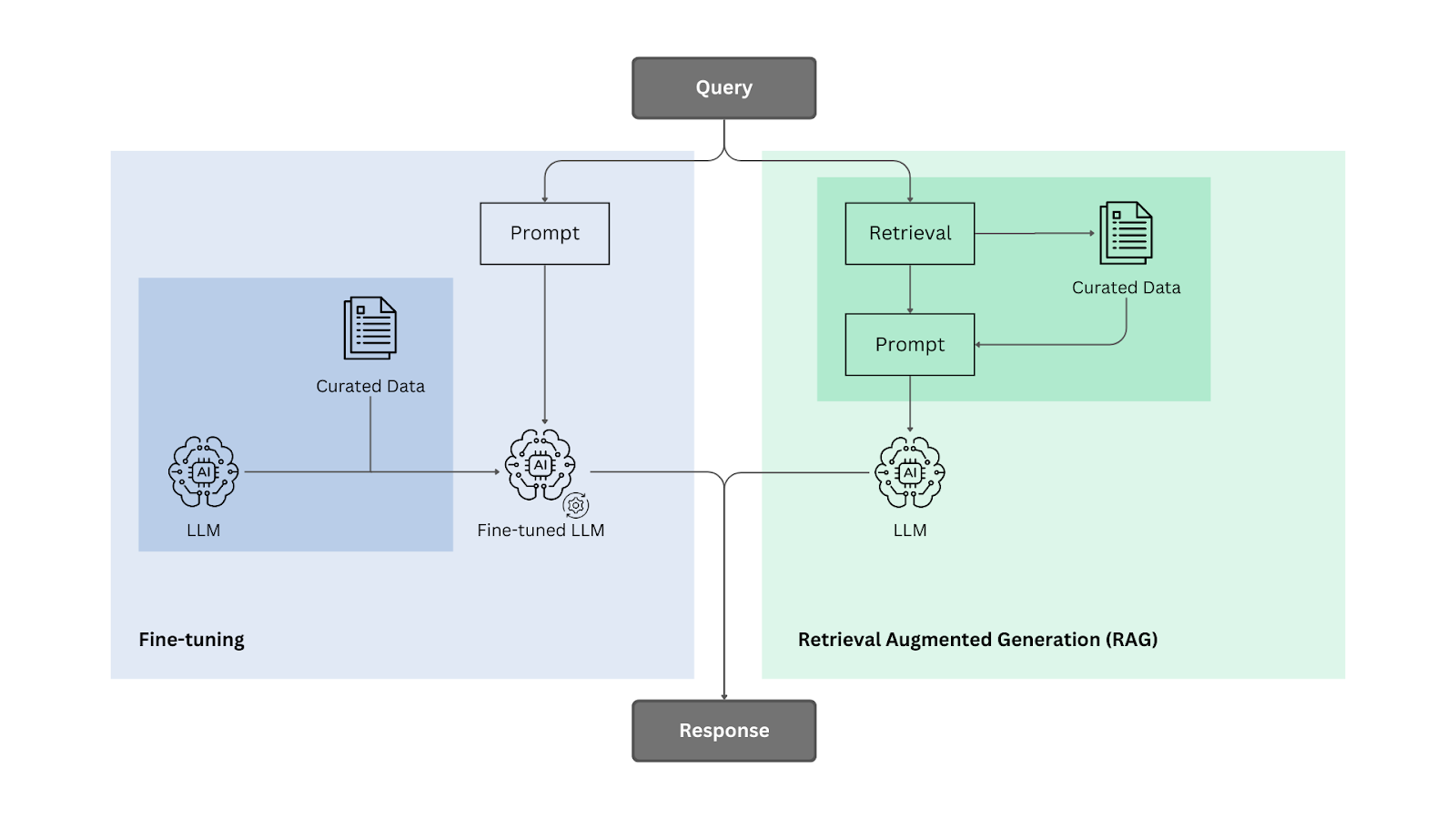
ファインチューニングとRAGの方法論パイプライン
LLMの知識を向上させるために、この2つの方法を詳しく見て、お互いにどのような違いがあるのかを探ってみよう。物事を整理するために、3人の学生が勉強していないトピックのテストを受けたとする。1人はテスト中だけ教科書を読み、もう1人はテスト前に勉強し、3人目はテストが始まると教材にアクセスできなくなる。誰が一番成績が良いと思いますか?
結果はいかに!
詳しい理解については、以下の論文を参照してください。
なぜLLMは事実誤認を生むのか?
LLMはその卓越した流暢さと多用途性にもかかわらず、本質的に事実誤認を起こしやすい。その原因は、領域知識の欠損、古い学習データ、推論の限界など、いくつかの重大な要因による。
- ドメイン知識不足:** LLMは、トレーニング中に十分に説明されなかった特定のドメインに関する深い専門知識が不足している可能性がある。例えば、一般的なニュースソースで主に訓練されたモデルは、ドメイン固有のデータで微調整されていない場合、医学や法律のような高度に専門化された分野で苦戦する可能性があります。
- LLMは訓練用データセットのカットオフ日付によって制限されます。カットオフ日以降に起こった出来事、科学の進歩、文化的変遷は取り込まれないため、時代遅れの回答になってしまいます。これは、COVID-19パンデミック以前にトレーニングされたモデルでは、パンデミックに関連した健康プロトコルやワクチン開発に関する情報が欠如しているような、ヘルスケアのようなダイナミックな分野では特に問題となります。
- 特に、学習データにおいて稀な事実やあまり頻繁に見られないパターンが含まれる場合、学習中にモデルによって学習された知識が保持されないことがある。この問題は、異なるタスクや入力にまたがって、あまり一般的でない情報を一貫して想起するモデルの能力を妨げる可能性がある。
- 忘却:** 微調整中に、モデルが以前に学習した情報、特に元のトレーニングからあまり強調されていない事実を忘れると、壊滅的な忘却が起こります。これはLLMによくある問題で、長期的な知識保持に影響を与える可能性がある。
- 推論の失敗:** LLMは、特に複雑で多段階の推論タスクにおいて、知識を正しく適用できないことがある。例えば、LLMは高度な数学の問題や多段階の論理的推論を解かせると、不正確な答えや不完全な答えを出すことがある。このような失敗は、思考が長く続くと論理的な一貫性が保てなくなることと関連していることが多い。
このような問題は、主にモデルの訓練段階に起因しており、訓練後の微調整中に生じる壊滅的な忘却は特筆すべき例外である。
言語モデルへの知識注入
大規模言語モデル(LLM)における事実誤認は、モデルの知識ベースにおけるギャップの結果であることが多い。これに対処するために、知識注入は、正確な答えを提供するモデルの能力を洗練し、拡張するのに役立つ重要なテクニックです。
ナレッジ・インジェクションとは、言語モデルを追加情報で修正または補強するプロセスを指します。全く新しい事実を学習するのではなく、モデルの予測を特定の知識ドメインに偏らせることで、知識集約的なタスクでのパフォーマンスを向上させます。
数学的定式化
それでは、知識注入の背後にある数学的定式化と、それがどのようにモデルの精度向上につながるかを探ってみよう。
問題
この研究では事実知識に焦点を当てている。もしモデルが何かを知っていれば、関連する質問に一貫して正しく答えることができ、真偽を区別することができる。
数学的にはこうなる:
Q = {qn}n=1N はN個の事実に関する質問の集合である。
各質問qnにはL個の可能な答えがあり、C = {cn}n=1Nはこれらの質問に対する正解の集合である。
Mはモデルを表し,各問題の答えを予測する.質問qnに対するモデルの予測答えは、M(qn) ∈ {an1 , . .anL }とします。そして、それは可能な答えの集合に属します。
我々は、モデルの知識スコア(正確さ)を計算することで、モデルの知識を評価することができます:
LM,Q := #{qn| M(qn) = cn} .N .
この式では
LM,Q はモデルの知識スコアである。
分子は、モデルの答えM(qn)が各問題qnの正解cnにマッチした回数を数えます。
分母は問題の総数Nです。
知識注入
多くの知識集約型タスクでは、一般的な事前トレーニングだけでは不十分である。パフォーマンスを向上させるには、知識注入が必要です。
これは次のように数学的に表現することができる。 事前訓練されたモデルM、質問セットQ、補助知識ベースBQが与えられたとき、我々は次のような知識注入のための関数Fを見つけることを目的とする:
M′ := F(M, BQ) s.t. LM',Q > LM,Q.
簡単に言うと、知識ベースBQを元のモデルMに組み込むFを適用することで、新しいモデルM′を作ることを目指す。
精度ゲイン
(微調整やRAGのような)知識注入がどれだけモデルを改善したかを見るために、追加知識を加える前と後の精度を比較します。精度の向上は以下の式で計算されます:
(LM`,Q-LM,Q) / LM,Q ;
ここで
LM,Qは、新しい知識を追加する前のモデルの精度である。
LM`,Qは新しい知識を追加した後のモデルの精度。
この式は、相対的な精度の向上、つまり新しい情報を取り入れた後にモデルがどれだけ良くなったかを示しています。
知識注入のフレームワーク
知識注入のための2つの一般的なフレームワークは、ファインチューニング(FT)と検索補強生成(RAG)である。ファインチューニングは、ドメイン固有のデータでモデルを訓練することにより、モデルを適応させる。一方、RAGは、推論中に外部の知識ベースから関連する情報を検索することにより、モデルを拡張する。
ファインチューニング
ファインチューニングは知識注入のために広く使われている手法である。この技法では、事前に訓練されたLLMを特殊なデータセットでさらに訓練し、特定の知識を内在化させたり、特定のタスクのパフォーマンスを向上させたりする。このプロセスにより、モデルは以前に学習した知識を「適応」させ、新しい事実、ドメイン固有の用語、推論パターンを取り込むことができる。
ファインチューニングの種類
- 教師あり微調整:*** 教師あり微調整(SFT)は、ラベル付けされた入出力ペアのセットを必要とする。一般的な SFT 手法の 1 つは命令チューニングで、入力は自然言語タスク記述、出力は希望する動作の例です。最先端のLLMの多くは、事前学習フェーズの後にインストラクションチューニングを行っている。インストラクションチューニングは、モデルの全体的な品質を向上させ、特にゼロショットと推論能力に重点を置く。しかし、命令チューニングはモデルに新しい知識を教えるものではなく、それだけでは知識注入には不十分である。
強化学習による微調整:強化学習(RL)に基づく微調整技術は、正しい反応に報酬を与え、正しくない反応にペナルティを与えることで、モデルを最適化します。例えば、人間のフィードバックからの強化学習(RLHF)、直接選好最適化(DPO)、近接政策最適化(PPO)などがある。これらの方法は、回答や行動の全体的な質を向上させるのに有効である。しかし、命令チューニングのように、RLのファインチューニングは、知識注入に必要な知識の広さには必ずしも対応していない。
教師なし微調整:**教師なし微調整はラベル付きデータを必要としない。一般的な方法は、継続的な事前訓練または非構造化微調整であり、このプロセスは事前訓練の継続と見なされる。モデルは因果自己回帰的に学習され、次のトークンを予測する。壊滅的な忘却を防ぐため、一般的に低い学習率が使用される。このアプローチは、事前学習フェーズで蓄積された知識を基礎とするため、モデルに新しい知識を注入するのに有効である。この研究では、新しい情報を学習するモデルの能力を向上させるために、教師なし微調整を用いている。
検索拡張生成(RAG)
検索拡張生成(RAG:Retrieval Augmented Generation)は、文脈内学習 の一形態であり、応答を生成する前にモデルが外部ソースから関連情報を検索できるようにすることで、LLMに埋め込まれた静的な知識を超える。モデルの内部重みを修正する従来の微調整とは異なり、RAGは、リアルタイムのデータでモデルの出力を基礎づけるために外部の知識ベースに依存する。このアプローチには、最新の、ドメイン固有の、権威ある情報へのアクセスを提供するという利点があり、生成されるテキストが正確で適切なままであることを保証する。
RAGモデルは2つの主要コンポーネントから構成される:
- 検索コンポーネント:***モデルのこの部分は、ユーザーのクエリに基づいて、外部のデータベース、文書リポジトリ、あるいはウェブから関連情報を検索する役割を担う。検索の前に、ドキュメントは埋め込みモデルを用いてベクトル埋め込みに変換され、ベクトルデータベースに格納される。検索時には、クエリは埋め込みに変換され、最も関連性の高い情報を検索するために、ベクトルデータベースに格納された埋め込みと照合される。Milvus](https://milvus.io/)のような一般的なベクトルデータベースは、大規模なデータセットにわたる効率的な検索を可能にする。
- 関連する文書や知識が検索されると、生成コンポーネントは、検索された情報を首尾一貫した、文脈的に適切な応答に合成する。これにより、モデルはリアルタイムの情報を統合し、特に最新の知識を必要とするトピックについて、より高い精度で質問に答えることができる。
実験セットアップ
このセクションでは、知識ベース、モデルの選択、トレーニングセットアップ、モデルのパフォーマンスを評価するために使用された評価方法について説明します。
知識ベース
MMLU ベンチマーク、時事問題タスク、言い換え生成タスク。
MMLU ベンチマーク
大規模多言語言語理解(MMLU)ベンチマークから4つのタスクが、知識集約型タスクにおけるLLMの能力を評価するために選ばれた。これらのタスクは、解剖学、天文学、生物学、化学、先史学などの科目にわたっている。これらのタスクは、推論への依存を最小限に抑え、事実に基づいた知識に重点を置いていることに基づいて選択された。
MMLUがベンチマークとして選ばれたのは、さまざまな領域にわたる事実の多肢選択問題を幅広くカバーしており、モデルの事実理解を多様かつ客観的にテストできるためである。先史時代の課題は、モデルが近代史以外の事実情報を処理する能力を評価するために含まれた。このアプローチは、推論プロセスと切り離された知識を理解し、操作するモデルの熟練度をテストするものである。
時事問題タスク
新しいデータセットは、モデルのトレーニングデータのカットオフ後に発生した出来事に関する多肢選択問題に焦点を当てて作成された。具体的には、2023年8月から11月までのアメリカの「時事問題」を中心に、関連するウィキペディアの索引から抽出した。
このアプローチは、モデルがトレーニング中にこれらの事実に触れていないことを保証し、知識注入能力と最新の事実情報を扱う能力を直接テストすることを可能にする。
言い換えの生成
GPT-4は、データセットを作成した後、入力データの言い換えバージョンを提供することによって、補強を生成するために使用された。モデルには、文章を言い換えながら元の意味を保持するように指示した。各言い換えの反復では、生成されるバージョンの多様性を確保するために異なるシードが使用された。
各MMLUタスクについて、240チャンクをランダムに選択し、各チャンクにつき2つの言い換えを生成しました。各チャンクに対して10個のパラフレーズが生成され、時事問題データセットのファインチューニングに使用された。
モデルの選択
Llama2-7B、Mistral-7B、Orca2-7Bを選択し、異なるモデリングアプローチにおける推論性能を評価した。このラインナップには、広く使用されているオープンソースのベースモデルと、インストラクションチューニングされたモデルが混在しており、比較のための十分な基盤を提供している。
さらに、RAGコンポーネントの埋め込みモデルとしてbge-large-enが選択された。このエンベッディング・モデルは、Hugging Face MTEBリーダーボードによると、オープンソースのオプションの中で最先端でした。
トレーニングセットアップ
トレーニングプロセスには以下の主要コンポーネントが含まれる:
- 手順:***すべてのモデルは教師なしトレーニング法を用いて微調整された。訓練データセットはチャンクに分割され、各チャンクが256トークンのサイズを超えないようにした。特別なトークン
と は各チャンクの開始と終了を示すために使用された。
- ハードウェア:***モデルは4つのNVIDIA A-100 GPUで学習され、大規模な微調整に必要な計算リソースが確保された。
ハイパーパラメーター:***。
学習率は以下の範囲でテストされた:1×10-6から5×10-5。
モデルは、ハイパーパラメータの最適化に基づいて選択された64のバッチサイズで、最大5エポック学習された。
評価
LLM の性能を評価するための一般的なツールである LM-Evaluation-Harness フレームワークを用いて評価を行った。このフレームワークはモデル評価の標準化されたアプローチを提供し、タスクや手法の一貫性を保証する。モデルは、事実問題に対する正解を予測する能力という観点から評価された。
実験では、これらの評価アプローチは
- ベースモデル:** 追加の知識注入を行わないモデルの生のパフォーマンス。
- ファインチューニング(FT):**モデルをタスクに特化したデータでファインチューニングし、事実知識ベースの質問に対するパフォーマンスを向上させる。
- この方法は、外部の知識ベースを使用し、モデルの応答を補強するために関連する情報を検索します。
- ファインチューニング+RAG(FT+RAG):**ファインチューニングと検索補強生成を組み合わせたハイブリッドアプローチ。
これら4つのアプローチの比較に加え、2つの異なる設定で性能を評価した:
- 0-shot:**モデルは事前の例なしでテストされ、事前学習と知識注入(fine-tuningまたはRAG)で学習した知識のみに依存する。
- 5-shot:** モデルには各タスクについて5つの例が与えられ、予測を行うためのコンテキストを提供する。この設定では、より実用的な実世界のシナリオにおいて、モデルが例から汎化する能力をテストする。
これら4つのアプローチでモデルの精度と性能を比較することで、知識注入、微調整、検索を利用した生成が、LLMの知識集約型タスクを処理する能力に与える影響が明らかになった。
実験結果
それでは、MMLUベンチマークや時事データなど、異なる知識ベースにおける実験結果に飛び込み、知識集約タスクにおける各アプローチのパフォーマンスを探ってみよう。
MMLUの結果
全てのタスクと設定において、RAGは対数尤度精度の点で一貫してベースモデルを上回った。
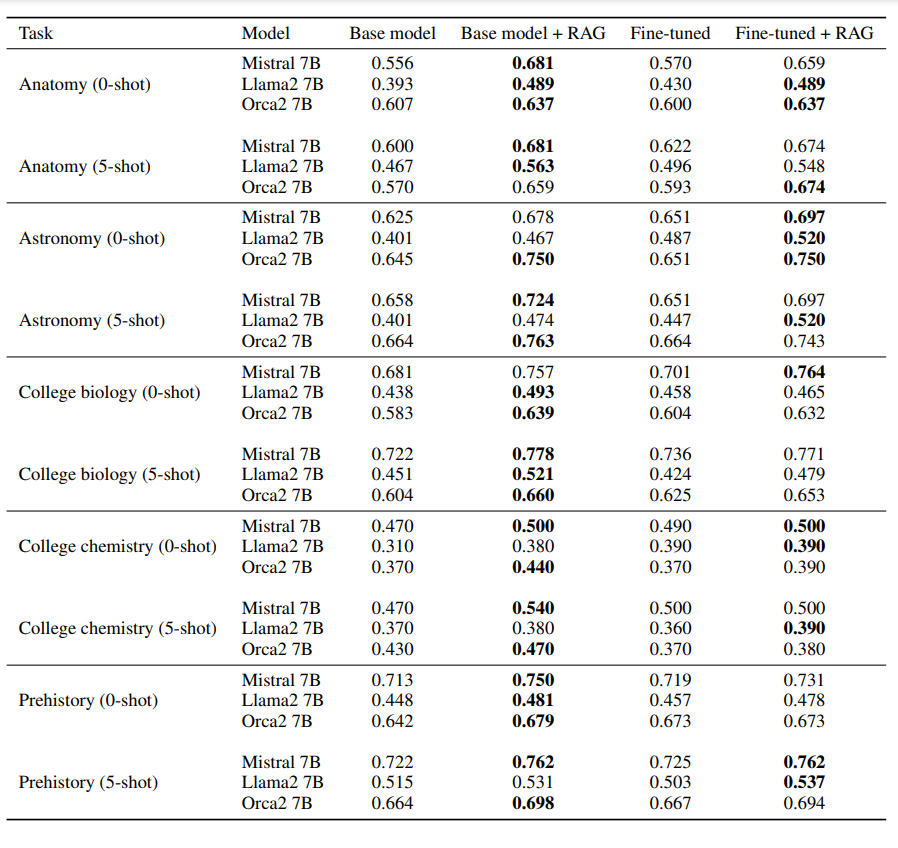
MMLUデータセットの対数尤度精度の結果|出典
ベースモデルを生成器としてRAGを使用することは、ファインチューニング単独よりも優れていることが証明された。場合によっては、RAGパイプラインでベースモデルをファインチューニングされたモデルで置き換えることで、さらに結果が改善されることもありました。しかし、その効果は一貫しておらず、ファインチューニング特有の不安定さが浮き彫りになった。さらに、5ショットのプロンプトは、すべてのメソッドにおいて、わずかではあるが一貫した向上をもたらした。
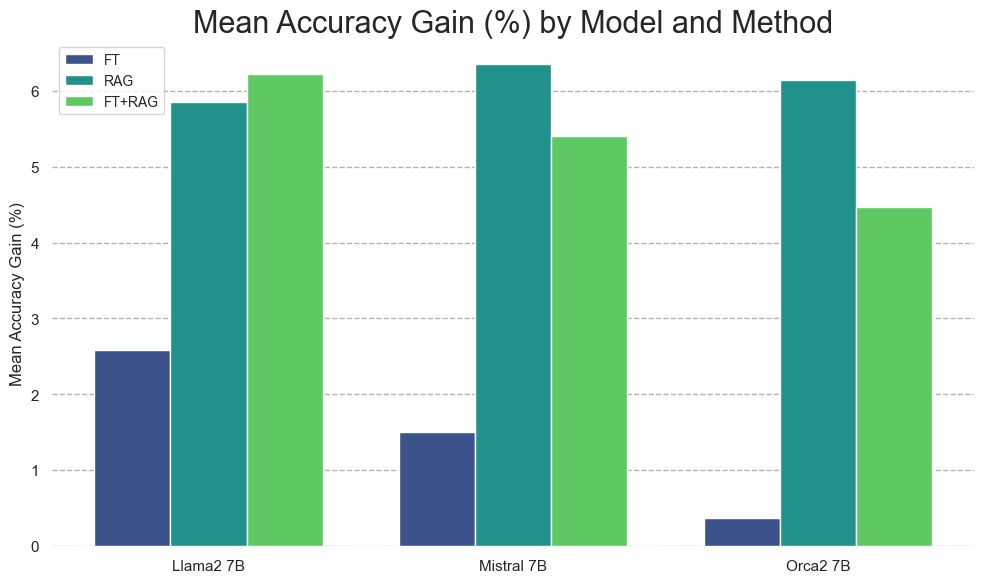
MMLUデータセットの全実験を平均した(列ごとの)各知識注入法の相対的精度向上|出典
時事問題の結果
RAGは、質問と補助データセットの間の正確なアライメントのおかげで、時事問題タスクにおいて卓越したパフォーマンスを提供した。ファインチューニングは有益であることが証明されたものの、RAGの有効性には及ばなかった。しかし、ファインチューニング(FT-par)を複数の言い換えで補強することで、ベースラインアプローチ(FT-reg)よりも結果が大幅に改善された。

時事問題の結果。元のデータセットでファインチューニングされたモデルはFT-regとラベル付けされ、複数の言い換えを含むデータセットで学習されたモデルはFT-parとラベル付けされている|出典
ファインチューニング対RAG
MMLUと時事問題の両タスクの結果から、RAGがfine-tuningよりも優れていることが確認された。ファインチューニングはベースモデルよりも精度を向上させたが、検索による性能向上には及ばなかった。
この傾向にはいくつかの要因がある:
- 文脈的知識アクセス**:ファインチューニングとは異なり、RAGは動的に関連情報を検索し、応答が文脈に基づくことを保証する。
- 壊滅的な忘却**:微調整は、以前に学習した知識を上書きするリスクがあり、モデルの一般的な能力を低下させる可能性がある。
- アライメントの問題**:ファインチューニングされたモデルは、最適なパフォーマンスを達成するために、さらに教師ありのファインチューニングや強化学習(RLHF)を必要とする可能性がある。
主な結果
- RAG (Retrieval Augmented Generation)は、外部データでモデルを補強することで、特に知識集約的なタスクの精度を大幅に向上させ、ベースモデルを一貫して上回った。
- RAG vs. Fine-Tuning (FT):** RAGはFine-Tuning (FT)を常に上回った。RAGとFTの組み合わせは、RAGパイプラインのジェネレーターとしてファインチューニングされたモデルを使用した場合に、若干の改善を示しました。しかし、結果は一貫しておらず、RAGと比較してファインチューニングが本質的に不安定であることを示しています。
- 5ショットブースト:**0ショットから5ショットに移行することで、RAGが追加されたコンテキストの恩恵を最も受け、パフォーマンスは小さいながらも一貫して改善されました。
- データ増強は知識保持を改善する:** 実験は、言い換えベースのデータ増強が知識注入タスクにおけるモデルの精度を単調増加させることを示しています。モデルは、情報を複数の方法で言い換えることで、新しい知識をよりよく理解し、一般化します。言い換えの数が増えるにつれて、モデルの精度は着実に向上し続けました。
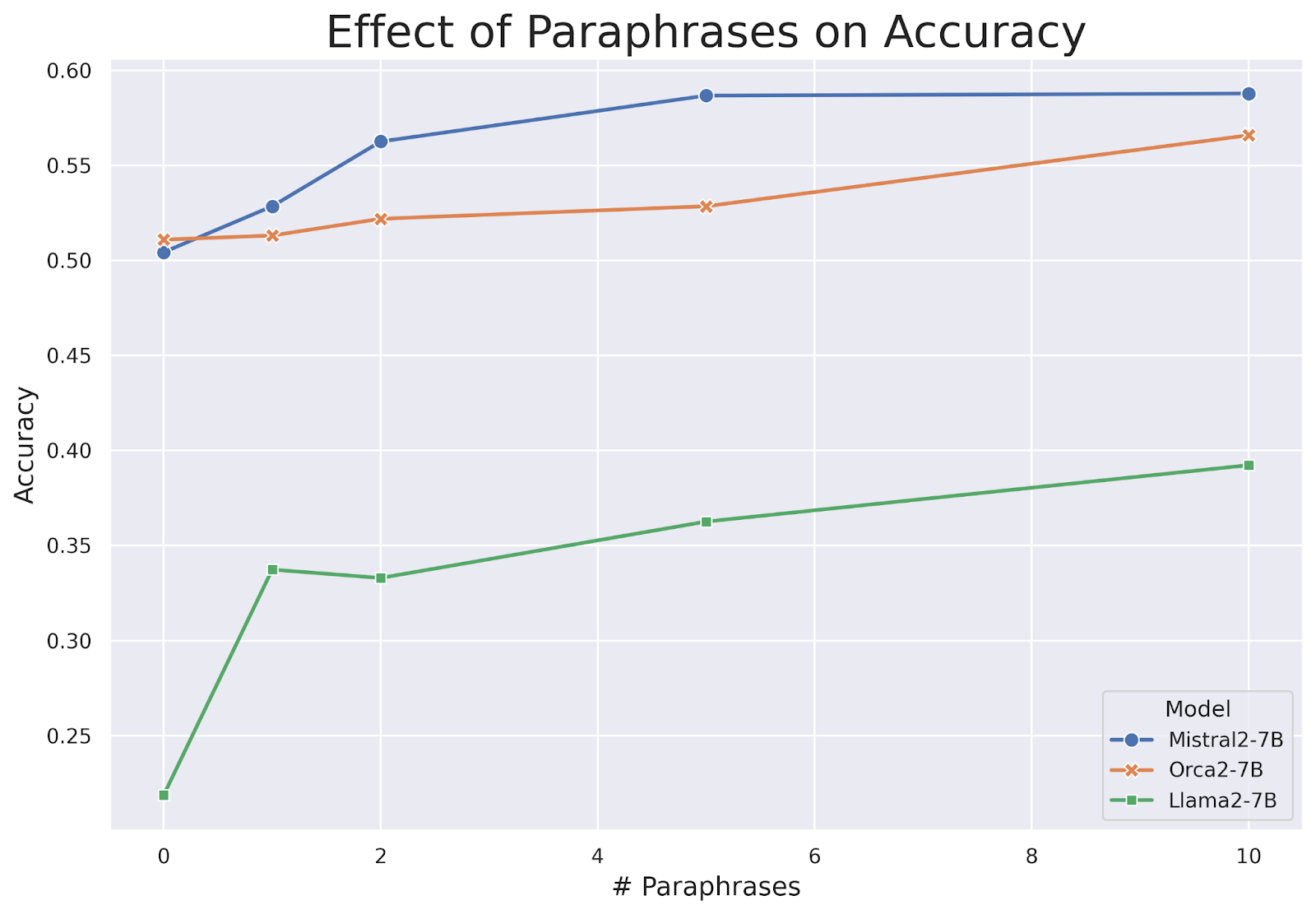
言い換えの数の関数としての時事問題タスクのモデル精度| 出典
RAG とベクトルデータベース
RAG(Retrieval Augmented Generation)は、検索されたデータを回答に統合することで、大規模言語モデルを強化し、事実の正確さと文脈の関連性を向上させる。
RAGにおけるベクトルデータベースの役割
ベクターデータベースは、高次元埋め込みデータの効率的な保存と検索を可能にすることで、RAG(Retrieval-Augmented Generation)において重要な役割を果たす。RAGシステムでは、検索段階は膨大な知識ベースから最も意味的に関連する情報を特定することに依存し、ベクトルデータベースが得意とするところである。
これらのデータベースは、テキストデータやマルチモーダルデータを高密度のベクトル埋め込みとしてインデックス化し、近似最近傍(ANN)検索のような手法を用いて、高速かつ正確な類似検索を可能にする。クエリが生成されると、ベクトルデータベースはコサイン類似度やその他の距離メトリクスに基づいて、最もマッチする埋め込みデータを検索します。これにより、最も文脈に関連した情報のみが生成モデルに渡され、事実精度が向上し、幻覚が減少する。
ベクトルデータベースは、質問応答システム、チャットボット、企業検索、推薦エンジンなどのアプリケーションのためのリアルタイムの知識検索において特に価値がある。
ベクターデータベース/クラウドプラットフォームとしてのMilvus/Zilliz
Zillizによって開発されたオープンソースのベクトルデータベースであるMilvusは、RAG(Retrieval-Augmented Generation)システムにおける高次元埋め込みデータの管理とクエリのための強力なソリューションである。RAGは応答を生成する前に関連知識を検索するために効率的な類似検索に依存しており、Milvusは大規模でリアルタイムの検索タスクのために最適化されている。
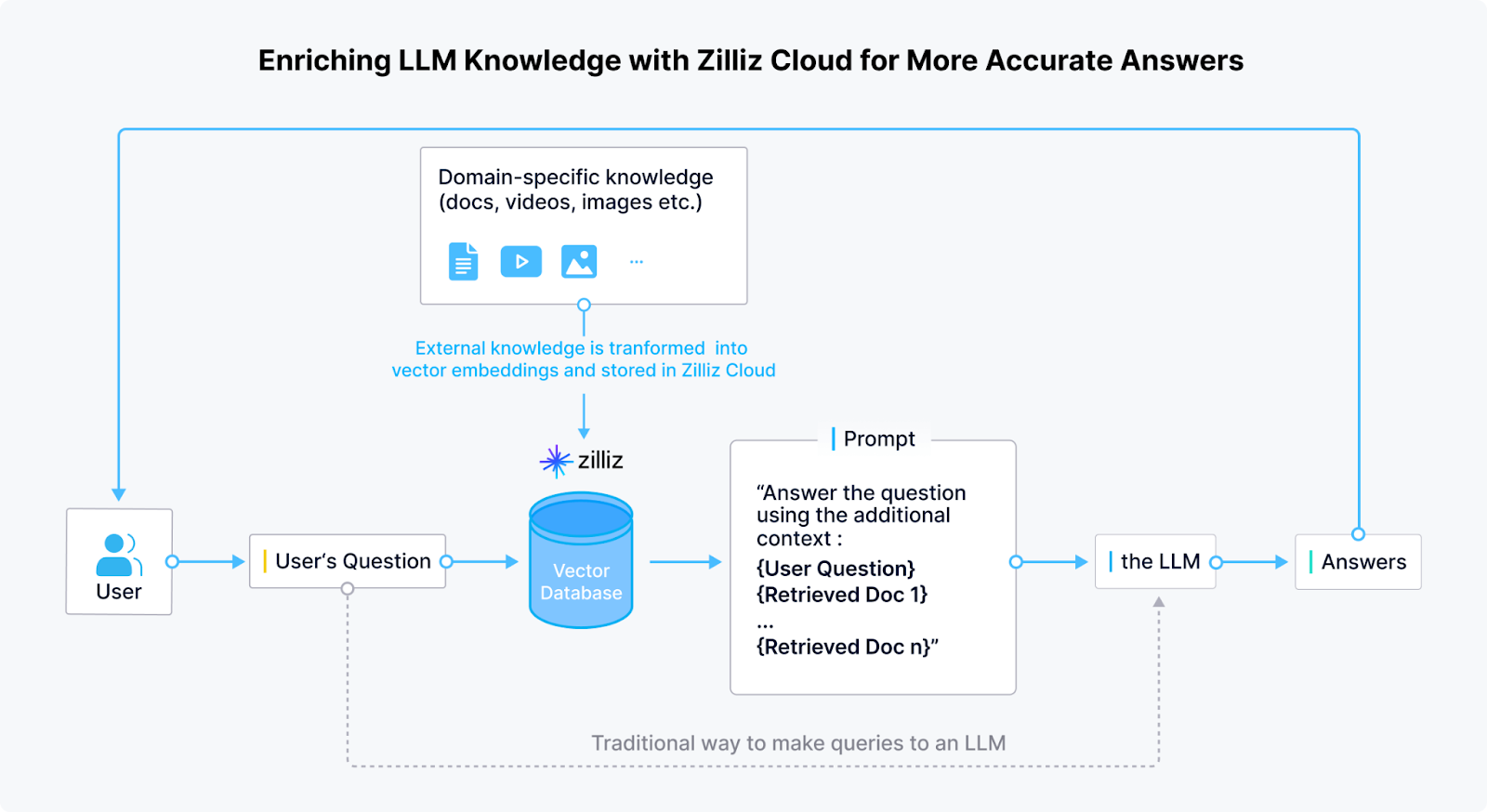
LLMの知識をZillizクラウドで充実させ、より正確な回答を実現|出典
Milvusは、数百万から数十億のベクトル埋め込みデータの保存とインデックス作成を可能にし、RAGモデルによる膨大な知識ベースの迅速な意味検索を可能にします。Milvusは、複数のインデックス作成アルゴリズムをサポートすることで、低レイテンシの検索を保証します。これは、チャットボット、検索エンジン、エンタープライズAIシステムなど、リアルタイムの情報が不可欠なアプリケーションにとって非常に重要です。
ZillizはクラウドベースのソリューションでMilvusを拡張し、企業がインフラを管理することなく、RAG向けベクトル検索の導入と拡張を容易にします。このクラウドネイティブなアプローチは、LLMとのシームレスな統合を保証します。これにより、企業はパフォーマンスとスケーラビリティを維持しながら、動的な知識検索によってモデルを強化することができます。
今後の研究の方向性
大規模言語モデル(LLM)は膨大な量の知識を持っているが、新しい情報、専門的な情報、見たことのない情報に適応する能力は依然として課題である。ファインチューニングと検索補強型生成(RAG)は、知識注入のための2つの著名なアプローチである。ファインチューニングは多くの用途に有用であるが、RAGは外部知識を統合するためのより信頼性の高い選択であることが証明されている。
LLMにおける知識注入の理解を深めるために、いくつかの重要な分野でさらなる調査が必要である:
- ハイブリッド知識統合:ハイブリッド知識統合:ファインチューニング、RAG、その他のテクニックを組み合わせて適応性を向上させる研究。これらのアプローチが互いにどのように補完し合っているかを理解することで、より効率的な知識注入につながる。
- ファインチューニング手法の組み合わせ:***今後の研究では、教師なしファインチューニングに、インストラクションチューニングや強化学習(RL)ベースのファインチューニングを統合することを探求すべきである。これにより、知識の適応と保持が改善される可能性がある。
- LLMにおける知識表現の評価**:LLMが注入された知識を内部的にどのように保存し、取り出すかを理論的観点から調査する。より明確な理解は、より解釈しやすく効率的なモデルにつながる可能性がある。
- LLMにおける知識の測定:LLMにおける知識の測定:知識保持をより良く評価するために、経験的なアプローチを超えた新しい評価フレームワークを開発する。標準化されたベンチマークを確立することで、異なるモデルの比較可能性を向上させることができる。
これらの分野でさらに研究を進めることで、知識注入戦略を洗練させ、新しい情報への適応におけるLLMの効率性と信頼性を向上させることができる。
参考資料
大規模言語モデルとは何か](https://zilliz.com/glossary/large-language-models-(llms))
Zillizクラウドプラットフォーム](https://www.zilliz.com)
Milvusドキュメント](https://milvus.io/docs)
ディープラーニングのファインチューニングを極める:テクニック&Tips](https://zilliz.com/glossary/fine-tuning)
検索拡張生成(RAG)](https://zilliz.com/vector-database-use-cases/llm-retrieval-augmented-generation)
LLMにおけるインコンテキスト学習](https://zilliz.com/learn/unlock-power-of-many-shot-in-context-learning-in-llms)
ベクトル・データベースとは何か、どのように機能するか](https://zilliz.com/learn/what-is-vector-database)

{kind=link}
読み続けて

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.