




InkeepとMilvusはいかにして、よりスマートな対話のためのRAG駆動型AIアシスタントを構築したか?
開発者として、様々なプラットフォームやサービスの技術文書を検索するのは退屈なものです。一般的な技術文書には、多くのセクションや階層があり、混乱したり、ナビゲートするのが難しいことがあります。その結果、必要な答えを探すのに多大な時間を費やしてしまうことがよくあります。技術文書にAIアシスタントを追加することで、多くの開発者にとって時間の節約になります。AIに問い合わせについて質問するだけで、AIが回答を提供したり、関連するページや記事にリダイレクトしてくれるからです。
最近のZilliz主催のUnstructured Data Meetupでは、Inkeepの共同創設者兼CTOであるRobert Tranが、InkeepとZillizがどのように彼らのドキュメントサイトにAIを搭載したアシスタントを構築したかについて議論した。このAIアシスタントは現在、 Zilliz と Milvus のドキュメント・サイトで実際に見ることができる。
この記事では、ロバート・トラン氏によって提示された技術的な詳細を探ります。それでは早速、技術文書ページにAIアシスタントを組み込む動機から始めましょう。技術文書にAIアシスタントを組み込む動機
技術文書は、すべてのプラットフォームがユーザーや開発者を支援するために提供しなければならない重要な情報源である。それは直感的で、包括的で、あらゆる経験レベルの開発者がプラットフォームで利用可能な特徴や機能を使えるように導くのに役立つものでなければならない。
しかし、プラットフォームが多数の新機能を導入するにつれて、その技術文書は過度に複雑になる可能性があります。この複雑さは、プラットフォームの技術文書をナビゲートする際に、多くの開発者を混乱させる可能性があります。開発者は多くの場合、迅速に結果を出さなければならないというプレッシャーにさらされており、技術文書で情報を探すのに時間を費やすと、実際のコーディングや開発作業から気が逸れてしまう可能性があります。
多くのプラットフォームは、開発者が必要なコンテンツを素早く見つけられるように、技術文書に基本的な検索機能を提供しています。これは、私たちがGoogleで検索する方法と似ています](https://zilliz.com/learn/evolution-of-search-from-traditional-keyword-matching-to-vector-search-and-genai)。ユーザーがキーワードを入力すると、プラットフォームは質問に答えるために関連しそうなページのリストを提供する。しかし、このような基本的な検索機能は、ユーザーのクエリの文脈を理解できないことが多く、無関係な検索結果や不完全な検索結果になってしまう。
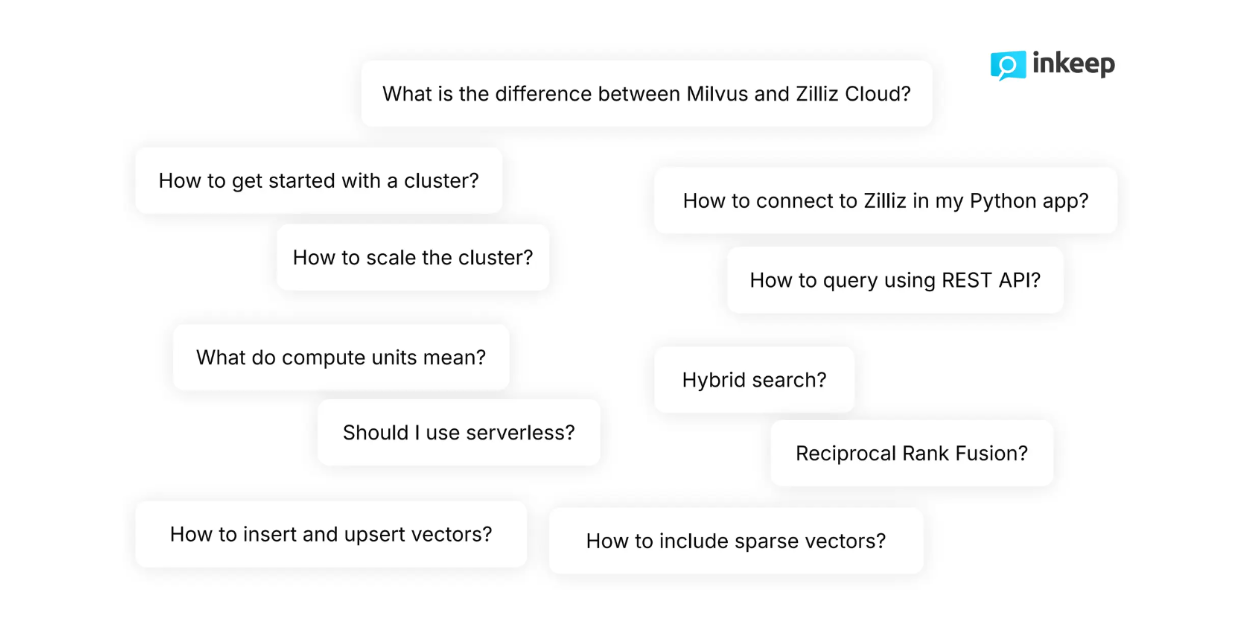 図- Milvusについて開発者に尋ねられた典型的な質問.png
図- Milvusについて開発者に尋ねられた典型的な質問.png
図:Milvusに関する開発者からの代表的な質問
開発者としての私たちの質問は、基本的な検索機能に対して、より微妙で複雑なものであることがよくあります。例えば、Zillizの技術ドキュメントを読み進める際、開発者は通常、"検索プロセス中に密なベクトルと共に疎なベクトルを含めるにはどうすればよいか?"や "クラスタを動的にスケールするにはどうすればよいか?"といった高度に技術的な質問をします。基本的な検索機能では、このような微妙で複雑な質問に満足に答えられないことが多い。
AIアシスタントの追加は、こうした問題を解決する。AIアシスタントは、クエリの背後にある開発者の意図や意味的な意味を理解することができ、開発者は数秒で必要な情報を得ることができる。開発者はクエリを入力するだけで、AIアシスタントが答えを提供したり、面倒で時間のかかる多くのコンテンツを選別する代わりに、正確な関連ページにリダイレクトしたりすることができる。
さらに、AIアシスタントは、通常、大規模言語モデル(LLMs )、ベクトル検索(vector search )、検索拡張生成(RAG )などの自然言語処理(NLP )における最新の進歩を搭載している。実際、RAGアプローチはこのAIアシスタントの核心であり、ユーザーの質問の背後にあるニュアンスを理解し、正確で適切な回答を数秒で返すことを可能にしている。
次のセクションでは、AIアシスタントの背後にある方法について説明する。
検索拡張世代(RAG)のコンセプト
Retrieval Augmented Generation (RAG)は、ベクトル検索やLLMなどの高度なNLP技術を組み合わせて、ユーザーのクエリに対する正確な回答を生成する手法です。
図- RAGワークフロー.png](https://assets.zilliz.com/Figure_RAG_workflow_5bfbcccddf.png)
図- RAGワークフロー.png]()RAGワークフロー.png
一言で言えば、RAGメソッドのワークフローは非常にシンプルである。まず、私たちユーザーはクエリを尋ねる。次に、RAGメソッドは、我々のクエリに対する答えを含む可能性のある関連文書をフェッチする。次に、我々のクエリと関連文書が一つのまとまったプロンプトにまとめられ、LLMに送られる。最後に、LLMは提供された関連文書を用いてクエリの答えを生成する。
見てわかるように、RAGの主なコンセプトは、LLMに我々のクエリに答えるための関連するコンテキストを提供することである。このアプローチには少なくとも2つの利点がある:第一に、LLM hallucination、つまり不正確で真実でない回答を生成するリスクを減らすことができる。第二に、LLMによって生成される応答は、より文脈化され、私たちのクエリに合わせて調整されます。これは、LLMに内部文書の内容に関する質問をする場合に特に有効である。
RAGを実装する際に考慮しなければならないRAGのステップは4つある:インジェスト、インデックス作成、検索、生成。
取り込み:データの収集と前処理を行う。各レコードの関連情報とメタデータも収集されるかもしれない。
索引付け:迅速な検索のために最適化された索引付け方法でデータを保存する。このステップでは、前処理されたデータは埋め込みモデルを使用してベクトル埋め込みに変換され、Milvusのようなベクトルデータベースに、FLAT、FAISS、またはHNSWのような高度な索引付けアルゴリズムとともに格納される。
検索:ベクトル検索操作により、ユーザーのクエリと蓄積されたデータを照合する。このプロセスでは、まず、蓄積データの変換に使用されたのと同じ埋め込みモデルを使用して、ユーザーのクエリをベクトル埋め込みに変換する。次に、ベクトルデータベースから最も関連性の高い情報を探し出すために、ユーザーのクエリと蓄積データとの間で類似性検索が実行される。
生成:最終的な応答を生成するためにLLMを利用する。まず、ユーザーのクエリと、検索ステップで得られた最も関連性の高いコンテキストが、プロンプトに結合される。次に、LLMはプロンプトで提供されたコンテキストに基づいて、ユーザーのクエリに対する応答を生成する。
図- RAGのステップ.png](https://assets.zilliz.com/Figure_Steps_of_RAG_12c42b1f3d.png)
図:RAGのステップ
上記の各ステップを実施する際には、考慮しなければならない要素がいくつかある。例えば、取り込みの段階では、データのソース、データクリーニングのアプローチ、チャンキングの方法について考える必要があります。一方、インデクシングの段階では、使用したい埋め込みモデルやベクトルデータベース、そしてユースケースに適したインデクシングアルゴリズムを検討する必要があります。
次のセクションでは、ZillizとMilvusのドキュメントページのAIアシスタントを構築するためにInkeepとZillizが行った詳細なRAG実装について説明する。
AIアシスタントを構築するためにInkeepとZillizが用いた方法
AIアシスタントを構築するために、InkeepとZillizはRAGの実装に異なる技術を組み合わせて使用しています。Inkeepは取り込みと生成の部分を処理し、Zillizはインデックス作成と検索のステップでInkeepをサポートする。
前のセクションで述べたように、RAG実装の最初のステップは取り込みステップである。このステップでは、Inkeepは技術的なドキュメント、サポートやFAQ、GitHubリポジトリなど様々なソースからZillizとMilvus関連のテキストデータを収集する。このテキストデータは、各情報が広すぎず、細かすぎないようにクリーニングされ、チャンク化されます。
次のステップに進む前に、チャンクされた各レコードのメタデータも収集される。これらのメタデータには以下が含まれる:
ソースの種類:データがGitHubのレポ、技術文書、サポートやFAQページなどから取得されたものかどうか。
レコードの種類:データのバージョン、テキストかコードかなど。コードの場合はプログラミング言語も記載する。
階層参照:各データポイントの子、親、兄弟など。Zillizのウェブサイトから収集したデータであるため、これは重要である。
URL、タグ、パス:データの取得元URLなど。このメタデータは、LLMによって生成されたレスポンスに引用やソースへのリンクを提供するのに非常に有用である。
日付:各データの公開日など。
Inkeepがデータとそのメタデータを収集したら、次のステップはインデックス作成方法です。
インデックス作成法では、検索ステップで類似検索を可能にするために、前処理されたデータをベクトル埋め込みに変換する必要がある。各データポイントをベクトル埋め込みに変換するために、InkeepとZillizは3つの異なる埋め込み方法を使用している:1つは伝統的なスパース埋め込みモデル、1つはディープラーニングに基づくスパース埋め込みモデル、1つは密な埋め込みモデルである。
図- スパース埋め込みと密埋め込み.png](https://assets.zilliz.com/Figure_Sparse_and_dense_embeddings_42cddb000f.png)
図:疎な埋め込みと密な埋め込み
スパース埋め込みは、単純な、キーワードベースの、ブーリアンマッチング処理に特に有効です。したがって、スパース埋め込みから取得される関連文書には、通常、クエリのキーワードが含まれています。一方、密な埋め込みは、クエリのニュアンスや意味的な意味を捉えるのに便利です。密な埋め込みからフェッチされたドキュメントは、クエリのキーワードを含んでいるかもしれないし、含んでいないかもしれませんが、コンテンツはクエリとの関連性が高いでしょう。
データをスパース埋め込みに変換するために使用できるモデルには、伝統的/統計的ベースのモデルと、ディープラーニングベースのモデルの2種類がある。AIアシスタントでは、InkeepとZillizは、伝統的ベースのモデルとしてBM25を、深層学習ベースのモデルとしてSPLADE/BGE-M3を使用している。
データを密な埋め込みに変換するために、OpenAI、Sentence-Transformers、VoyageAIなどの埋め込みモデルなど、多くのディープラーニングモデルから選択できる。AIアシスタントでは、InkeepとZillizは3つの異なるエンベッディングモデルを使用しています:MS-MARCO、MPNET、BGE-M3である。
すべてのデータがスパースとデンスの埋め込み表現に変換されると、埋め込みはベクトル・データベースに格納され、高速な検索が可能になる。AIアシスタントを構築するために、InkeepとZillizはベクトル・データベースとしてMilvusを使用している。ここで疑問なのは、どちらか一方を選べば十分かもしれないのに、なぜスパース埋め込みとデンス埋め込みを組み合わせて使う必要があるのか、ということだ。
図- ハイブリッド検索図.png](https://assets.zilliz.com/Figure_Hybrid_search_illustration_d231b60be2.png)
図:ハイブリッド検索イラスト._.
スパース埋め込みとデンス埋め込みの両方を使うことで、検索ステップに柔軟性が生まれます。例えば、クエリが短い場合(5語以下)、スパース埋め込みで十分かもしれません。一方、クエリが長い場合は、ほとんどの場合、密な埋め込みを使用した方が良い結果が得られます。また、ベクトルデータベースとしてMilvus を用いれば、hybrid search、すなわち、疎埋め込みと密埋め込みを組み合わせた類似検索を行うことができます。また、必要に応じてmetadata filteringを用いて、denseまたはsparse embeddingによる類似検索を行うこともできる。
クエリに対して最も関連性の高いコンテンツを見つけるためにハイブリッド検索を実装する場合、リランキング法も考慮する必要がある。なぜなら、2つの異なる方法から類似性の結果を得ることになり、これらの結果を組み合わせるアプローチが必要になるからだ。これを実現するために、InkeepとZillizは2つの異なるリランキング手法を実装した:重み付きスコアリングと相互ランク融合(RRF)である。
加重スコアリングのコンセプトは単純で、各手法に重みを割り当てる。例えば、密な埋め込みによる類似度の結果に60%の重み付けをし、疎な埋め込みによる類似度の結果に40%の重み付けをすることができる。一方、RRFでは、コンテキストのスコアは、2つの異なる手法の順位の逆数を合計することによって計算される。
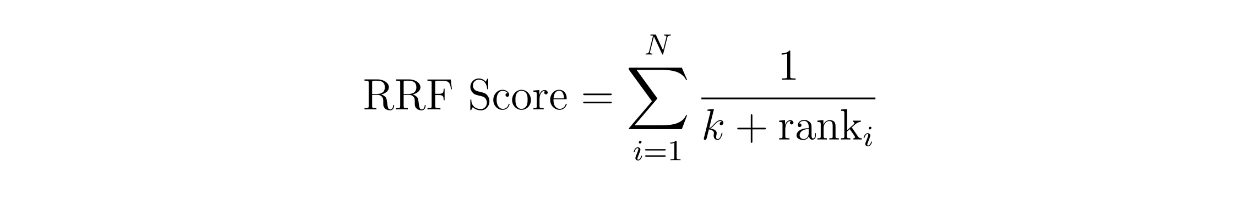 関数rrf score.png
関数rrf score.png
ここで、Nは手法の数で、疎な埋め込みと密な埋め込みのハイブリッド探索を実装しているので、2つであるべきです。変数'rank'はメソッドiにおけるコンテキストのランクであり、kは定数である。
上のRRF方程式を用いて、各コンテキストのRRFスコアを計算することができる。RRFスコアが最も高いコンテキストが、クエリに最も関連するコンテキストとして選択される。
関連するコンテキストがフェッチされると、元のクエリと最も関連するコンテキストが1つのまとまったプロンプトに結合される。このプロンプトはLLMに送られ、最終的なレスポンスを生成する。LLMには、OpenAIとAnthropicのモデルを使用しています。
Milvus AIアシスタントのデモ
このセクションでは、InkeepとZillizによって構築されたAIアシスタントの使い方を簡単に紹介します。もしフォローしたい場合は、 Zilliz または Milvus ドキュメントページで確認することができます。このデモでは、MilvusのドキュメントページにあるAIアシスタントを使用します。
Milvusのドキュメントページを開くと、画面右下に "Ask AI "ボタンが表示されます。このボタンをクリックしてAIアシスタントにアクセスしてください。
スクリーンショット1.png](https://assets.zilliz.com/screenshot_1_f50e9eec4d.png)
次に、ポップアップ画面が表示され、Milvusのドキュメントで調べたいことを質問するよう促されます。オプションとして、ポップアップ画面の右上にある "Search "オプションをクリックすることで、基本的な検索を行うこともできます。
例えば、Milvus Python SDKとBGE-M3を使ってデータをベクトル埋め込みに変換する方法を知りたいとします。質問を入力するだけで、AIアシスタントが答えを教えてくれる。
スクリーンショット2.png](https://assets.zilliz.com/screenshot_2_b616933c40.png)
回答を提供するだけでなく、AIアシスタントは、生成された回答に関連するさらなる情報を見つけることができる引用や関連ページも教えてくれる。
スクリーンショット3.png](https://assets.zilliz.com/screenshot_3_fe76bf9a06.png)
結論
InkeepとZillizによって構築された技術文書へのAIアシスタントの統合は、高度なAIソリューションが開発者の生産性とユーザーエクスペリエンスをいかに向上させることができるかを示している。RAGは、このAIアシスタントを支える中核的なコンポーネントであり、この方法は、LLMがニュアンスの異なる複雑なクエリに対して、より正確で文脈に沿った回答を提供するのに役立ちます。
RAGは、取り込み、インデックス付け、検索、生成という4つの重要なステップで構成されている。MilvusのようなベクターデータベースはRAGパイプラインの重要な構成要素であり、索引付けと検索のステップを実行する。各ステップで使用される方法は、特定のユースケースに応じて慎重に検討する必要がある。この記事では、InkeepとZillizがRAGの各ステップで様々な戦略を実装し、洗練されたAIアシスタントを構築した例も見てきた。
MilvusとInkeepがどのようにしてこのAIアシスタントを構築したのか、詳しくはYouTubeでのロバートの講演のリプレイをご覧ください。
続きを読む
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
MilvusでAIアプリを作る:チュートリアル&ノートブック](https://zilliz.com/learn/milvus-notebooks)
AI開発者のMilvusコミュニティに参加する](https://zilliz.com/community)
RAGとは](https://zilliz.com/learn/Retrieval-Augmented-Generation)

読み続けて

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.