




CLIPからJinaCLIPへ:検索とマルチモーダルRAGのための一般的なテキスト画像表現学習
最近、マルチモーダル埋め込みモデルの急増が様々な業界で注目を集めており、機械がテキストや画像を解釈する方法を変えている。しかし、大きな進歩にもかかわらず、これらのモデルは核となる課題に直面しており、その一つがモダリティギャップです。このギャップは、画像とテキストの埋め込みが、同じオブジェクトを記述している場合でも、潜在空間において空間的に離れていることに現れます。
最近Zillizが主催したUnstructured Data Meetupでは、Jina AIのエンジニアリング・マネージャーであるBo Wangが、モダリティ・ギャップの複雑さとOpenAIのCLIPモデルからJinaCLIPへの移行について説明してくれた。
このブログでは、彼の要点を再確認するとともに、マルチモーダル類似検索システムを実装する。このシステムでは、JinaCLIPを使ってマルチモーダル埋め込みを生成し、Milvusのベクトルデータベースを使って、あるクエリが与えられたときの類似埋め込みを保存・検索します。詳しくは、Bo's full take on YouTube をご覧ください。
良い埋め込みモデルとは?埋め込みモデルの主な機能は、テキストや画像のようなものをvector、データ内の意味的な関係を捉える数値表現にマッピングすることです。例えば、2つのベクトル間の距離は、それが2つの画像、2つのテキスト、またはそれぞれの1つであるように、それらが表す2つのアイテムの類似性を反映する必要があります。
埋め込みモデルは、意味検索や画像検索など、最新のAIタスクの中核をなしている。しかし、埋め込みモデルの何が優れているのでしょうか?
領域を超えた汎用性
優れた埋め込みモデルは、微調整を必要とせず、幅広いドメインでうまく機能するはずです。この適応性により、入力がテキスト、画像、または他のデータタイプであろうと、埋め込みが普遍的に有用であることが保証されます。例えば、ある画像がベクトル空間に埋め込まれ、関連するテキストが同じ空間に埋め込まれた場合、2つの埋め込みは意味的な類似性を示すように近接するはずです。この広範な適用可能性は、類似検索、画像検索、クロスドメインアプリケーションなどのAIタスクに不可欠である。
正確な意味的類似性
優れた埋め込みモデルの主要な特徴は、意味的に関連する項目に対して高い類似度スコアを持つ埋め込みを生成することによって、左右を結びつける能力です。これは単なるテキストデータにとどまらず、あらゆるマルチモーダル入力に適用されます。テキストとテキスト、画像と画像、テキストと画像の比較のいずれにおいても、モデルはベクトル空間における埋込みの近さを通して正しい関係を反映する必要があります。
しかし、テキストと画像のモダリティを接続する古いモデルは、この目標を達成するのが困難でした。これらのモデルは、画像にタグを付けたり、周囲のテキストを用いたりする手作業に頼っていた。これらの方法は、特に配信外のシナリオでは、汎化が不十分でした。
マルチモーダル課題への挑戦
CLIP](https://zilliz.com/learn/exploring-openai-clip-the-future-of-multimodal-ai-learning)のようなモデルが導入される以前は、モダリティ(テキストと画像)の接続は、高度に手作業かつ仮説駆動型のタスクだった。Flickrのタグであろうと、ユーザーが追加したテキストの説明であろうと、そのプロセスはシームレスとは程遠いものでした。教師ありのアプローチは、多くの場合、分類器のラベルを使用し、不安定になりやすく、その領域外のパフォーマンスは満足のいくものではありませんでした。つまり、画像とテキストを結びつけることはできても、特に入力が複雑な場合、結果は必ずしも一貫していなかったのだ。
この問題を解決するために、画像とテキストのペアで訓練することでマルチモーダルモデルの性能を向上させる、対照的言語-画像事前訓練モデルCLIPが開発された。CLIPの、2つのモダリティを共有埋め込み空間で整列させる能力は革新的であった。しかし、このモデルにも限界がある。
CLIPモデル:制限のあるブレークスルー
CLIPは、テキスト用と画像用の2つのエンコーダを別々に学習させることで、新しい標準を打ち立てた。その核となるアイデアは、テキストと画像のベクトルが共存できる共有埋め込み空間を学習し、意味的に類似したテキストと画像をより近くに配置することであった。その結果は印象的だった:CLIPは、単純な余弦類似度関数を用いてマルチモーダルなタスクを可能にした。
図:CLIPモデルの仕組み](https://assets.zilliz.com/Figure_How_the_CLIP_model_works_2c4fdd3295.png)
しかし、CLIPには欠点もある。重要な問題の1つは、テキストのみのタスクを効果的に処理できないことである。CLIPは主に短いキャプション(多くの場合、77文字未満)用に最適化されているため、長いテキストは難題となる。さらに、CLIPは学習過程でハードネガ例を欠いていた。ハードネガとは、近いけれども正しくない例であり、特にテキスト検索のようなタスクにおいて、モデルを改良するために極めて重要である。これがないと、CLIPの性能は、詳細なテキスト理解を必要とするタスクで頭打ちになる。
JinaCLIPへの移行:クリップの欠点への対処
JinaCLIPは、オリジナルのCLIPアーキテクチャをベースに、その限界に対処している。テキスト入力を拡張し、テキストエンコーディングに適合した BERT v2 アーキテクチャを使用している。画像処理のために、JinaCLIPはEVA-02モデルを組み込んでいる。JinaCLIPの学習プロセスは、画像キャプションの短いテキスト入力がもたらす課題を克服し、ハードネガを導入することに焦点を当てている。このプロセスは、以下の3段階で行われる:
図:JinaCLIPの学習プロセス](https://assets.zilliz.com/Figure_Training_Process_of_Jina_CLIP_94d30d22b2.png)
アライメント学習、長文統合、微調整である:
短いテキストとキャプションによるアライメント学習**:このステージでは、キャプション付き画像データと類似した意味を持つテキストペアの両方を用いてモデルを学習する。この目的は、テキスト-画像、テキスト-テキストの類似性を共同で最適化することで、画像とテキストの埋め込みを整合させることである。この共同学習プロセスにより、モデルは画像とテキストの関連付けを学習する一方で、テキストのみの能力も維持する。テキストのみの性能は、テキストペアのみで学習する場合に比べて若干低下するが、このフェーズではバランスの取れたアプローチが維持される。
長いテキスト記述の統合**:第2段階では、モデルを訓練するために合成データが導入される。このデータは、AIモデルによって生成された長いテキストと画像を整列させ、コンテンツをより詳細に説明します。同時に、テキストのみのペアが引き続きトレーニングに使用される。モデルは、画像との整列を維持しながら、より広範なテキスト説明を扱うことを学習し、短いテキストと長いテキストの両方の画像関係を理解する能力を強化する。
テキストのトリプルとハードネガによる微調整**:最後の段階は、ハードネガティ ブ(2つは意味的に似ているが、1つは意図的に異なる)を含むテキストのペアを使用することです。これは、特にテキストのみのシナリオにおいて、モデルがより細かい意味的区別を行うのに役立ちます。同時に、モデルは合成画像と長文テキストのペアで学習を続ける。この段階により、モデルのテキストのみの性能が大幅に向上し、同時に、以前の段階で学習された画像とテキストのアライメントがロバストであることが保証される。
このアプローチにより、マルチモーダルなタスクにおける強力なパフォーマンスを維持しながら、テキストのみのシナリオにおける能力を向上させることができる。 この新しいアプローチとオリジナルのClipとの比較を見てみよう。
パフォーマンス・メトリクスは、オリジナルのCLIPモデルと比較して、検索パフォーマンスの変化を示しています。下の画像に示すように、テキストからテキストへの検索では165%、画像から画像への検索では12%、画像からテキストへの検索では6%、テキストから画像への検索では2%の変化が見られます。
図:jina-clip、openai-clip-vit-b-16、jina-embeddings-v2-base-enのモデル性能比較](https://assets.zilliz.com/Figure_Model_performance_comparison_between_jina_clip_openai_clip_vit_b_16_and_jina_embeddings_v2_base_en_b60051c8b1.png)
この新しい学習プロセスは、タスク間の汎化を強化し、モダリティギャップを減らすのに役立つ。マルチモーダルAIモデルにおける大きな障害であるモダリティギャップについて、なぜこの問題が起こるのかを説明しよう。
モダリティ・ギャップ:なぜ起こるのか?
モダリティ・ギャップとは、異なる入力タイプ、例えば意味的には似ているがベクトル空間ではかけ離れているテキストと画像の埋め込み間の空間的な隔たりのことです。このギャップは、埋め込みが関連する入力間の真の関係を完全に反映していないため、マルチモーダル検索システムの有効性を弱めます。下の画像でわかるように、この表現は円錐を切り詰めたような形をしており、一方の端には画像の埋め込みが、もう一方にはテキストの埋め込みがあり、モダリティのギャップがはっきりと表れています。
図:Jina CLIPにおける画像埋め込みとテキスト埋め込みの初期位置。重みは完全にランダム化され、事前の学習はない。
最新のモデルでもこのギャップが生じる理由はいくつかある:
初期化時のコーン効果
マルチモーダルモデル、特にテキストと画像の入力を扱うモデルは、それぞれのモダリティに対して別々のエンコーダを使うことが多い。これらのエンコーダは通常、ランダムまたは事前に訓練された重みで初期化されます。そのため、上の画像に見られるように、テキスト埋め込みはベクトル空間のある領域に、画像埋め込みは別の領域に集まってしまいます。コーン効果と呼ばれるこの初期分離は、異なるモダリティ(例えば、画像と関連するテキスト)からの埋め込みが適切に整列することを困難にします。例えば、もふもふの猫のテキスト埋め込みと、猫の画像埋め込みは、意味的に関連しているにもかかわらず、この初期化バイアスのために、離れて開始する可能性があります。
温度スケーリング
学習中、AIモデルは埋め込みがどの程度密接に整列するかを調整するために、対比的損失関数の中で温度スケーリングと呼ばれるテクニックを使用します。これは埋め込み間の距離を微調整するのに役立ちますが、温度スケーリングはモダリティ間の初期分離を不注意にも維持し、モダリティギャップを強化する可能性があります。例えば、温度スケーリングが注意深く調整されないと、遊び好きな子犬と犬の画像の埋め込みは、同じ概念を記述しているにもかかわらず、ベクトル空間では離れすぎてしまうかもしれません。
バッチ内偽陰性
大規模なデータセットで学習する場合、一致しないデータ点のペア(例えば、"a red apple "というテキストとペアになった犬の画像)は否定例として扱われます。しかし、これらの偽陰性は意味的に重複している可能性がある。例えば、両方の項目が動物という広いカテゴリに関連している場合(例えば、犬の画像と "遊び心のあるオオカミ "というテキスト)、モデルはこれらの埋め込みを必要以上に遠ざけ、完全に無関係なものとして誤って扱うことでモダリティギャップをさらに悪化させる可能性がある。
なぜモダリティ・ギャップが起こるのかを理解することは、最初の一歩に過ぎない。このギャップを埋めるために、異なるモダリティからの埋め込みをより近づけ、マルチモーダル課題においてより正確な検索を保証するための様々な学習戦略が開発されてきた。
モダリティギャップの解決:トレーニングテクニックとその先へ
モダリティギャップは構造的な問題であり、簡単には解決できないが、その影響を緩和する戦略はある。重要なのは、学習時に異なるモダリティからの埋め込み間の分離を減らし、一緒に属する画像とテキストがベクトル空間においてより近くにマッピングされるようにすることです。
高温スケーリング
実際には、トレーニング中の温度を上げることで、モデルの学習プロセスにランダム性を加えることで、異なるモダリティからの埋め込みをより近づけることができます。例えば、温度を上げることで、猫の画像とテキスト "a fluffy cat "の埋め込みをより近づけることができます。しかし、その代償として収束が遅くなり、より多くの計算リソースが必要になる。高温スケーリングで訓練されたモデルは、テキストと画像の埋め込み位置合わせを改善する傾向がありますが、トレードオフとして、訓練時間が長くなり、計算機への要求が大きくなることがよくあります。
ハードネガティブサンプリング
ハードネガティヴな例、つまり意味的に近い非マッチングペアを導入することは、モダリティギャップを減らすもう一つのテクニックです。これらのハードネガティヴなペアは、関連する概念間のより細かな区別を学習するようモデルを後押しし、検索精度を向上させる。例えば、ネコの画像と "a small tiger"というテキストをペアにすると、一見ミスマッチのように見えるかもしれないが、モデルはこの2つの入力が重複するセマンティクス(どちらもネコ科の動物である)を持っていることを学習し、それでも埋め込み空間ではある程度整列しているはずだと学習する。このプロセスにより、モデルは関連する概念間の類似点と相違点の両方を認識するようになり、ほぼ一致するものを区別する能力が向上する。
Milvus と JinaCLIP によるマルチモーダル検索:実例
さて、モダリティギャップの背後にある技術的な理由を探ったところで、オープンソースのベクトルデータベースであるMilvus,とJinaCLIPを使って、マルチモーダル検索システムを構築する方法の実践的な例に飛び込んでみよう。
Milvusは、高次元ベクトルを管理、検索、クエリするので、マルチモーダル検索タスクやRAG(Retrieval Augmented Generation)タスクに理想的なソリューションです。Milvusは、テキスト、画像、その他のデータタイプのいずれを扱っている場合でも、埋め込みを効率的に保存し、高度な類似検索技術を使用して関連する結果を取得することができます。
このセクションでは、Milvusを使用して、テキストと画像の埋め込みを扱うマルチモーダル検索システムを作成するプロセスを説明します。このシステムでは、ユーザがテキストまたは画像を入力し、混合データセットから最も意味的に関連性の高い結果を取得することができます。
ステップ1:環境の構築
まず、システムに必要なライブラリを環境にインストールする必要がある:
pip install pymilvus transformers torch timm
次に、必要なライブラリをインポートして、エンコーダー・クラスをセットアップする。
# 必要なライブラリのインポート
from transformers import AutoModel
from pymilvus import MilvusClient
インポートトーチ
# テキストと画像の埋め込み生成を処理するエンコーダクラスを定義する。
クラス Encoder:
def __init__(self, model_name: str):
# モデルの初期化 (SentenceTransformer の代わりに transformers から AutoModel)
self.model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
def encode_text(self, text: list[str]) -> list[float]:
# テキストのみの埋め込みを生成
torch.no_grad()を使う:
text_emb = self.model.encode_text(text)
return text_emb
def encode_image(self, image_urls: list[str]) -> list[list[float]]:
# 画像のみの埋め込みを生成
torch.no_grad()を使う:
image_emb = self.model.encode_image(image_urls)
return image_emb
# エンコーダをモデルjinaai/jina-clip-v1で初期化する。
モデル名 = "jinaai/jina-clip-v1"
エンコーダー = エンコーダー(model_name)
上記のコードでは、まず必要なライブラリをインポートする:エンコードモデルを変換するための AutoModel 、Milvus とやり取りするための MilvusClient 、テンソル演算のための torch である。
次に、トランスフォーマの AutoModel をラップする Encoder クラスを定義する。encode_textメソッドとencode_imageメソッドは、それぞれテキストと画像の埋め込みを生成するためにモデルを使用する。コンテキストマネージャtorch.no_grad()` は勾配の計算を無効にするために使用される。
最後に、エンコーダを jinaai/jina-clip-v1 モデルで初期化する。
ステップ2:データの準備
次に、Milvusに埋め込むためのサンプルデータを準備します。
# データを読み込む: 埋め込み用の画像とテキスト
sentences = ['青い猫', '赤い猫', 'AIによって生成された赤い猫', '棒にかじりつく犬']。
image_urls = [
'https://i.pinimg.com/600x315/21/48/7e/21487e8e0970dd366dafaed6ab25d8d8.jpg',
'https://i.pinimg.com/736x/c9/f2/3e/c9f23e212529f13f19bad5602d84b78b.jpg',
'https://images.fineartamerica.com/images/artworkimages/mediumlarge/1/red-cat-art-3771-bb-james-ahn.jpg'、
'https://images.squarespace-cdn.com/content/v1/54822a56e4b0b30bd821480c/29708160-9b39-42d0-a5ed-4f8b9c85a267/labrador+retriever+dans+pet+care.jpeg?format=1500w'
]
# テキストと画像の埋め込みを生成する
text_embeddings = encoder.encode_text(sentences)
image_embeddings = encoder.encode_image(image_urls)
# 一貫した次元を確保する
dim = len(image_embeddings[0])
ここで、サンプル文と画像URLのリストを定義する。URLには赤猫、青猫、犬の画像が含まれている。次に、エンコーダを使ってテキストと画像の埋め込みを生成する。dim`変数には埋め込み値の次元が格納される。これはMilvusコレクションを作成するときに必要になる。
ステップ3:Milvusのセットアップ
次に、Milvusクライアントをセットアップして、マルチモーダルデータ用のコレクションを作成する。
# エンベッディングをMilvusに挿入する。
コレクション名 = "multimodal_rag_demo"
milvus_client = MilvusClient(uri="./milvus_demo.db")
# コレクションが存在するかチェックし、存在する場合は削除する
if milvus_client.has_collection(collection_name):
print(f "コレクション{コレクション名}は既に存在します。 削除します...")
milvus_client.drop_collection(collection_name)
# Milvus コレクションの作成
milvus_client.create_collection(
コレクション名=コレクション名、
auto_id=True、
dimension=dim、
enable_dynamic_field=True、
)
Milvusクライアントを初期化し、ローカルのデータベースファイルに接続する。希望する名前のコレクションが既に存在するかどうかをチェックし、存在する場合はそれを削除してまっさらな状態にします。
そして、指定した名前で新しいコレクションを作成します。auto_id=TrueパラメータはMilvusにエントリのIDを自動的に生成するように指示します。dimensionをエンベッディングに合うように設定し、ダイナミックフィールドを有効にする。
ステップ4:インデックスの作成
データを挿入する前に、検索パフォーマンスを最適化するためにインデックスを作成します:
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="vector", # インデックス対象のフィールド(埋め込みフィールド)
metric_type="COSINE", # L2、COSINEなどを指定可能。
index_type="FLAT", # FLATは正確な検索を保証します.
)
# コレクションのインデックスを作成する
milvus_client.create_index(collection_name, index_params)
print(f "Index created successfully for collection: {collection_name}")
上記のコードは、余弦類似度を距離指標としてFLATインデックスを作成している。
ステップ 5: Milvusへのデータ挿入
コレクションとインデックスがセットアップされたので、データをMilvusに挿入することができる。
data_to_insert = [].
# テキストを埋め込む
for idx, txt_emb in enumerate(text_embeddings):
data_to_insert.append({"text": sentences[idx], "vector": txt_emb})
# 画像の埋め込み
for idx, img_emb in enumerate(image_embeddings):
data_to_insert.append({"image_url": image_urls[idx], "vector": img_emb})
# データをMilvusに挿入する
insert_result = milvus_client.insert(
コレクション名=コレクション名、
data=data_to_insert、
)
print(f "挿入結果:{insert_result}")
milvus_client.load_collection(collection_name)
上記のコードでは、辞書のリストを作成し、各辞書にはテキストセンテンスまたは画像URLと、それに対応する埋め込みベクトルが含まれています。そして、Milvusクライアントの insert メソッドを使用して、このデータをコレクションに追加します。挿入後、コレクションをメモリにロードして検索に備える。
ステップ6:マルチモーダル検索の実行
最後に、画像とテキストの両方のクエリを使用して、マルチモーダル検索を実行します。
# 画像クエリとテキストクエリの組み合わせによるマルチモーダル検索
query_image_url = 'https://imgcdn.stablediffusionweb.com/2024/4/5/5e70d71c-a7f6-44e9-972d-8c5a27d45c3d.jpg'
query_text = "似たような赤い猫をください"
# クエリ埋め込み(画像+テキスト)を生成する
query_embedding_image = encoder.encode_image([query_image_url])[0]。
query_embedding_text = encoder.encode_text([query_text])[0]。
# 画像埋め込みを使用してMilvusで検索を実行する
search_results_image = milvus_client.search(
コレクション名=コレクション名、
data=[query_embedding_image]、
output_fields=["image_url", "text"], # 両方のフィールドが結果に含まれるようにする。
limit=5, # 結果を返す数
search_params={"metric_type":"COSINE", "params":{"nprobe":10}}
)
# テキストを埋め込んでMilvusで検索する
search_results_text = milvus_client.search(
コレクション名=コレクション名、
data=[query_embedding_text]、
output_fields=["image_url", "text"], # 両方のフィールドが結果に含まれるようにする。
limit=5, # 結果を返す数
search_params={"metric_type":"COSINE", "params":{"nprobe":10}}
)
# 画像クエリから結果を取得して表示する
print("画像クエリの結果:")
for result in search_results_image:
for hit in result:
image_url = hit['entity'].get('image_url')
text = hit['entity'].get('text')
if image_url:
print(f "Retrieved Image URL (from image query):{image_url}")
if text:
print(f "Retrieved Text (from image query):{テキスト}")
# テキストクエリの結果を取得し、表示する
print("テキストクエリの結果:")
for result in search_results_text:
for hit in result:
image_url = hit['entity'].get('image_url')
text = hit['entity'].get('text')
if image_url:
print(f "Retrieved Image URL (from text query):{image_url}")
if text:
print(f "Retrieved Text (from text query):{テキスト}")
上記のコードでは、マルチモーダル検索を実行するプロセスを示している。まず、クエリ画像のURLとクエリテキストを定義します。クエリー画像は以下のようになる:
図2:赤と白の猫のクエリ入力画像](https://assets.zilliz.com/Figure_2_Query_input_image_of_a_red_and_white_cat_99b47e63c6.png)
次に、これらのクエリを我々のエンコーダを使ってエンコードし、それぞれの埋め込みを生成する。次に、Milvusで2つの検索を行う。1つは画像埋め込みを使用し、もう1つはテキスト埋め込みを使用する。それぞれの検索において、image_urlフィールドとtextフィールドの両方を出力に要求することで、両方のタイプのデータを取得することができる。各検索の結果は5件に制限し、距離メトリックとして余弦類似度を採用している。検索パラメータの nprobe パラメータにより、検索するクラスタの数を微調整することができ、検索速度と精度のバランスをとることができる。最後に、検索結果を表示し、各クエリタイプでどの画像またはテキストが検索されたかを示すことで、テキストと画像ベースの両方のクエリを処理し、関連付けるシステムの能力を示す。
完全なコードはこちらでご覧いただけます。
以下にサンプル結果を示します:
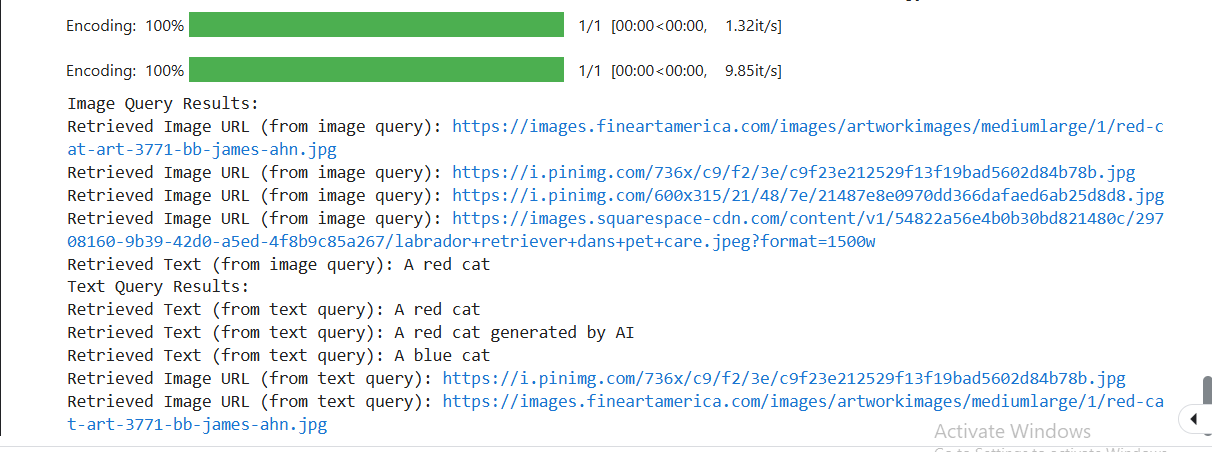
画像を使ってベクトル検索を行うと、画像のURLと画像に関連するテキストの両方が得られる。これがマルチモーダル検索の力である。以下は、両方のケースで類似画像として検索された画像の一つである。
図3:Milvusで類似検索を行った後の赤い猫の出力画像](https://assets.zilliz.com/Figure_3_Output_image_of_a_red_cat_after_conducting_a_similarity_search_in_Milvus_a3fa8c7280.png)
ご覧のように、この画像はクエリとしてシステムに与えた赤い猫の画像と類似しています。
このシステムにリランカーを追加することで、検索結果を関連性の高い順に並べ、関連性の高い結果が上位に来るようにすることができる。しかし、明らかなように、Milvusはベストマッチを最初に検索する良い仕事をしています。このシステムを進化させて、マルチモーダルRAGシステムを作ることもできる。
結論
Bo Wang氏は、マルチモーダルモデルにおけるモダリティギャップを埋めることの複雑さを説明し、CLIPからJinaCLIPへの移行を紹介した。彼は、テキストと画像のアライメントの主要な課題を分解し、JinaCLIPがこれらの課題にどのように対処しているかを示した。
本記事では、JinaCLIPを使って埋め込みを生成し、Milvusを使って効率的な検索を実現するマルチモーダル類似検索システムを構築することで、彼の洞察を拡張した。この知識があれば、マルチモーダル検索アプリケーションを実装し、テキストベースのクエリと画像ベースのクエリにまたがるシームレスなパフォーマンスを確保し、さらにはリランキングのような高度な検索テクニックを統合することで、さらに進化させることができます。
その他のリソース
マルチモーダルRAG: よりスマートなAIのためのテキストを超えた拡張](https://zilliz.com/blog/multimodal-rag-expanding-beyond-text-for-smarter-ai)
Trulensを使用したマルチモーダルRAGの評価](https://zilliz.com/blog/evaluating-multimodal-rags-in-practice-trulens)
2024年のマルチモーダルAIモデルトップ10 ](https://zilliz.com/learn/top-10-best-multimodal-ai-models-you-should-know)
Gemini、BGE-M3、Milvus、LangChainを使ったマルチモーダルRAGの構築](https://zilliz.com/learn/build-multimodal-rag-gemini-bge-m3-milvus-langchain)
CLIPとLlama3で局所的にマルチモーダルRAGを構築する ](https://zilliz.com/blog/multimodal-RAG-with-CLIP-Llama3-and-milvus)
Milvusにおけるハイブリッド探索のレビュー ](https://zilliz.com/blog/a-review-of-hybrid-search-in-milvus)
Milvusによるマルチモーダル検索システムの構築 ](https://zilliz.com/blog/how-vector-dbs-are-revolutionizing-unstructured-data-search-ai-applications)
clip-vit-base-patch32ガイド|OpenAI](https://zilliz.com/ai-models/clip-vit-base-patch32)

{kind=link}
読み続けて

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.

VidTok: Rethinking Video Processing with Compact Tokenization
VidTok tokenizes videos to reduce redundancy while preserving spatial and temporal details for efficient processing.