




拡張SBERT:ペアワイズ文スコアリングのためのバイエンコーダを強化するデータ拡張法
#はじめに
対文スコアリングは、意味類似性、言い換え検出、および情報検索を含む、様々な自然言語処理([NLP])(https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing)タスクの基本である。これらのタスクは、検索エンジン、推薦システム、チャットボットなどの重要なアプリケーションの原動力となっており、これらのアプリケーションは、ユーザーのクエリを理解し、それに応答するために正確な文の比較を使用している。しかし、クロスエンコーダやバイエンコーダのような既存の手法は、大きな課題に直面している。
BERT](https://zilliz.com/learn/what-is-bert) (Bidirectional Encoder Representations from Transformers)のようなクロスエンコーダは、最適な結果を得るために文を直接比較しますが、大規模な使用には時間がかかり、コストがかかります。対照的に、SBERT(Sentence-BERT)のようなバイエンコーダは、限られたデータ表現に苦戦するものの、独立した文処理により高速でスケーラブルである。
STSb(英語)データセットにおけるクロスエンコーダとバイエンコーダのスピアマン順位相関(ρ)の比較、様々な学習サイズ(単位:千)に対する性能を示す](https://assets.zilliz.com/Comparison_of_Spearman_rank_correlation_r_between_Cross_Encoders_and_Bi_Encoders_on_the_ST_Sb_English_dataset_showcasing_performance_across_varying_training_sizes_in_thousands_dcede00044.png)
図:STSb(英語)データセットにおけるクロスエンコーダとバイエンコーダのスピアマン順位相関(ρ)の比較。
Augmented SBERT (AugSBERT)はSBERTの拡張であり、データ増強によってバイエンコーダの制限に対処し、余分な訓練データを生成する。このアプローチは、データ不足のシナリオにおいて高い性能を維持する。AugSBERTはシード最適化を採用しており、様々なシードで複数のモデルを訓練し、最適なモデルを特定する。文のペアの選択が重要であり、関連するペアを効率的に選択するためにBM25サンプリングを使用し、パフォーマンスを向上させる。
AugSBERTは、ドメイン内精度で1~6%の向上を達成し、ドメイン適応シナリオでは最大37ポイントの向上を実現する。正確でスケーラブルな文スコアリングタスクのための実用的なソリューションを提供する。
このブログでは、クロスエンコーダやバイエンコーダのような従来の手法が直面する課題と、拡張SBERTがこれらの問題にどのように対処するかについて説明します。また、AugSBERTがどのように機能するのか、その革新的なデータ補強の使用、バイエンコーダの性能を強化する能力についても説明します。詳細な理解については、以下の論文を参照されたい。
論文](https://assets.zilliz.com/unnamed_11cbda3c49.png)
図:クロスエンコーダ(右)は、1回のBERT推論ステップで両方の文を1つの入力として受け取り、類似度スコアを出力する。一方、バイエンコーダ(左)は、各文を独立して処理し、文ベクトルを出力する|出典
なぜデータ拡張はAugSBERTにとって重要なのか?
データ補強はAugmented SBERT(AugSBERT)の核心である。これは、既存の文のペアをサンプリングすることによって、新しい文のペアを生成するのに役立ちます。データ補強は、小さなデータセットと限られた文ペアによるSBERTの課題を解決することができます。これが不可欠な理由は以下の通りである:
多様な文ペアの生成:** AugSBERTは、多様な文ペアを生成するためにデータ補強を使用します。既存のラベル付き文ペア(金訓練セット)から個々の文を再利用し、それらを再結合して新しい文ペアを作成します。
低リソース学習**をブーストする:オーグメンテーションは、SBERT の微調整のための訓練データを増やすために、合成文ペアを生成する。これにより、AugSBERTは、これまで制限となっていた小さなデータセットでも、高性能な文変換器に微調整できるようになります。
従来の文スコアリング手法の問題点
伝統的な文スコアリング手法は、現代のテクニックの基礎を築いた。しかし、これらには顕著な限界がある。これらの欠点は、Augmented SBERTのような、より優れたアプローチの必要性を強調している。以下は、従来の手法の主な問題点である:
独立した文の表現がない**:BERT のようなクロス・エンコーダは、両方の文を一緒にエンコードすることで、文スコアリング・タスクでうまく機能します。しかし、これは各文に対して独立した埋め込みを作成しない。これは、1つのペアワイズ類似度を得るために完全な推論ステップを必要とし、ほとんどのユースケースでは使用できません。
大規模検索における非効率性:クロスエンコーダは精度は高いが、固定サイズの文埋め込みを生成することができない。そのため、大規模な検索タスクでは使いにくい。また、ポリエンコーダはインデックス作成に課題があり、あまり適していない。
大規模なデータ要件バイ・エンコーダは学習に大量の文対データを必要とする。このラベル付きデータの収集には時間とリソースがかかる。十分なデータがないと、性能が低下する可能性がある。
非対称スコアリング:** ポリエンコーダは、バイエンコーダやクロスエンコーダの問題点に対処している。しかし、スコア関数は非対称であるため、対称的な類似性を必要とするタスクでの使用は制限される。
拡張SBERTはこれらの問題を解決する。これはデータの拡張とサンプリングを用いて、高品質の文埋め込みを作成する。これは効率的で、異なるタスク間でうまく機能する。
拡張SBERT
Augmented SBERTは、文対タスクのバイエンコーダの性能を向上させる最先端の手法である。データ増強と半教師付き学習を使用することで、既存モデルの重大な制限に対処し、ドメイン内およびドメイン適応シナリオのための堅牢なソリューションを実現する。本手法は、意味的テキスト類似性、質問と回答のマッチング、情報検索などの文対タスクに焦点を当てている。パフォーマンスを向上させるために、これらのタスクに合わせた拡張技術が使用される。
拡張 SBERT はどのように違うのか?
Augmented SBERT(AugSBERT)は、データ処理、訓練、および性能における主要な変更によって、SBERT を改良する。両者の違いは以下の通りである:
データ要件の削減:** SBERT は、大量の高品質ラベル付きデータを必要とする。AugSBERT は、自動的にラベル付けされたデータとよりスマートなテクニックを使用することで、この必要性を低減します。
データ補強:** SBERT は、ラベル付けされた文のペアの固定セットを使用するため、特に小さなデータセットではパフォーマンスが制限される可能性がある。AugSBERT は、新しい文のペアを生成するためにデータ拡張を適用し、トレーニングデータを拡張します。
文ペアのラベリングのためのクロスエンコーダ:** AugSBERTは、新しい文ペアのラベリングにクロスエンコーダを使用し、微調整のためのデータを追加します。モデルのパフォーマンスを向上させるために、ゴールド(高品質)データセットとシルバー(自動生成)データセットを組み合わせます。
文ペアのサンプリング:** AugSBERTは、トレーニングの質を高める文ペアを選択するために、スマートなサンプリング技術を採用しています。
異なるドメインにおけるパフォーマンス:** AugSBERTは、ドメイン内およびドメイン外のシナリオによりよく適応します。その多様で拡張されたデータセットは、モデルが新しいタスクやドメインに対してより効果的に一般化するのに役立ちます。
Augmented SBERT はどのように機能するのか?
拡張SBERTは、データ拡張によって新しい文のペアを生成する。次に、クロスエンコーダを使用してこれらのペアにラベル付けを行い、シルバーデータセットを作成する。シルバーデータセットはゴールドデータセットと組み合わされ、バイエンコーダ(SBERT)を微調整する。
図:拡張SBERTインドメインアプローチ】(https://assets.zilliz.com/Figure_Augmented_SBERT_In_domain_approach_eba9738f3b.png)
図:拡張SBERTインドメインアプローチ|出典
では、その具体的な手順を分解してみよう:
ステップ0:クロスエンコーダの微調整
クロスエンコーダ(BERT)はまず、高品質で人間が注釈を付けた文のペアのコレクションであるゴールドデータセット上で微調整される。このファインチューニングされたクロスエンコーダは、後に新しいラベル付けされていない文ペアの弱いラベルを生成するために使用される。クロスエンコーダから得られる弱いラベルは、後のプロセスでバイエンコーダの微調整をサポートする。
ステップ1:シルバーデータセットの作成
1.ラベリング(ステップ1.1)*:ラベル付けされていない文のペアが微調整されたクロスエンコーダに通される。モデルはラベルを割り当て、シルバーデータセットを作成する。このデータセットが「シルバー」と呼ばれるのは、ラベルが人間による注釈ではなく、機械によって生成されたものだからである。
2.サンプリング(ステップ1.2):可能性のあるすべての文のペアにラベルを付けることは、コストがかかりすぎ、非効率的である。これに対処するため、AugSBERT は、ラベリングのために最も関連性の高いペアを選択するサンプリング戦略を使用している。サンプリングは効率を改善し、ラベリングがより効果的に行われるようにする。これにより、不必要な組み合わせにリソースを浪費することなく、モデルのパフォーマンスを向上させることができる。サンプリング手法には、ランダム・サンプリング、カーネル密度推定(KDE)、BM25、セマンティック・サーチなどがある。これらの方法については、次のセクションで詳しく説明します。
ステップ2:学習と予測
1.バイエンコーダの微調整(ステップ2.1)*:シルバーデータセットはゴールドデータセットと組み合わされ、バイエンコーダ(SBERT)を微調整する。バイエンコーダはこの過程で、各文章を独立に密なベクトル空間にマッピングするように訓練される。
2.予測(ステップ2.2):微調整されたバイエンコーダは、類似度スコアリングのようなタスクのために比較可能な文埋め込みを生成する。
このパイプラインは、正確なクロスエンコーダラベリングとバイエンコーダの効率性を組み合わせ、文対タスク全体のパフォーマンスを向上させる。アーキテクチャ図は、ラベリングから最終予測までのこのプロセスをキャプチャしています。
実験セットアップ:データ、サンプリング、ベースライン、評価
ここでは、使用するデータセット、サンプリングアプローチ、ベースラインや評価方法などのその他の重要な要素を含む実験のセットアップを紹介する。
データセット
本研究では、シングルドメインのデータセット(例:Quora、AskUbuntu)とマルチドメインのデータセット(例:Quora、Sprint、SuperUser)の両方を使用する。これらのデータセットはセンテンスペアタスク用に設計されており、マルチドメインタスクは特化したコミュニティ間でのドメイン適応に焦点を当てている。
図:多様なドメイン内センテンスペアタスクに使用されている全データセットの概要](https://assets.zilliz.com/Figure_Summary_of_all_datasets_being_used_for_diverse_in_domain_sentence_pair_tasks_f621ef795d.png)
図:多様な領域内文対タスクに使われている全データセットの概要|出典
サンプリング
ペアのサンプリングはAugmented SBERTにおいて不可欠である。正しい文のペアを選択することは単純ではなく、AugSBERT の成功の鍵である。可能性のある文のペアをすべてラベル付けすることは、コストがかかりすぎ、非効率的である。この問題を解決するために、AugSBERT は、ラベリングのために最も関連性の高いペアに焦点を当てるサンプリング戦略を使用する。
不適切なサンプリングは、無関係なペアを導入する可能性があり、モデルのパフォーマンスを低下させ、改善につながらない可能性が高い。
kの影響はAugSBERTでは最小であり、k = 3またはk = 5を使用することで最良の結果が得られる。
以下はAugSBERTで使用される一般的なサンプリング戦略です:
ランダム・サンプリング(RS):** この方法は、ラベリングのために文のペアをランダムに選択する。多くの場合、非類似(否定的)で肯定的なペアが少ない結果となる。これは、シルバーデータセットの不均衡を引き起こし、有用性を低下させる。
カーネル密度推定(KDE):** KDEはシルバーデータセットとゴールドデータセットのラベル分布のバランスをとることを目的とする。KDEは、文のペアの大規模なセットを弱くラベル付けし、正と負のラベルの分布に一致するようにペアを選択する。目標は分布の差を最小化することである。しかし、KDEは無作為に廃棄されたサンプルを多数ラベル付けする必要があるため、計算コストが高い。
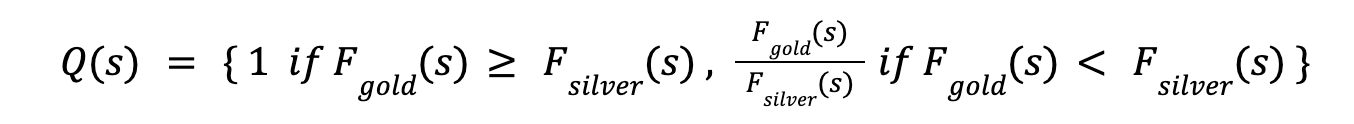
BM25:**BM25は語彙重複に基づく検索手法で、類似度の高い上位k個の文章を素早く特定する。強力な類似度分布を作成し、シルバーデータセットに有効である。
セマンティック検索(SS):**この方法は、たとえ共通語が多くなくても、意味的に類似した文章を探す。事前に訓練されたバイエンコーダ(SBERT)を使用し、コサイン類似度に基づいて上位k個の最も類似した文章を見つける。
BM25 + 意味検索:** これはBM25と意味検索の両方を組み合わせたものである。これは語彙的類似性と意味的類似性の両方を捉える。しかし、負のペアが多すぎるため、パフォーマンスが低下する可能性がある。
実験でのパフォーマンス
実験によると、BM25 と KDE が最高のパフォーマンスを発揮する。KDEの方が若干優れている場合もあるが、BM25の方が高速で効率的である。ランダム・サンプリングは、異種のペアを生成しすぎるため、うまく機能しない。BM25 + SSは、いくつかのデータセットではBM25単独よりも性能が悪い。全体として、BM25は性能と効率の両方において最良の選択である。
結果を改善するためのシードの最適化: BERTのような変換モデルは、訓練中に使用されるランダムシードによって異なる結果を出すことがある。このばらつきは、小さなトレーニングデータセットの場合に顕著になります。これに対処するため、AugSBERTは、異なるシードで複数のモデルをトレーニングし、開発セットで最も良いパフォーマンスを発揮するものを選択することで、シードの最適化を適用します。
時間を節約するために、最初は全てのシードに対してトレーニングステップの一部(20%)のみが完了する。その後、最も有望なモデルを完全に訓練する。このアプローチにより、より優れた汎化が保証され、最終的な性能が向上する。
ベースライン
AugSBERT は、いくつかのベースラインに対して評価された。回帰タスクでは、Jaccard 類似度が 2 つの入力文の単語の重なりを測定した。分類タスクには、多数決ラベルベースラインを使用した。最先端の事前学習済みモデルである Universal Sentence Encoder(USE)もテストされた。AugSBERT はさらに、NLPAug のデータ増強手法と比較された。その中で、BERT モデルによる同義語置換が最も良い結果を示した。
評価
実験は、様々なタスクと構成における AugSBERT のパフォーマンスを評価するために実施された。以下は、使用されたモデル、ハイパーパラメータ、および評価メトリクスの概要である。
- モデル:** 実験は PyTorch、Huggingface の Transformers、Sentence-Transformers フレームワークを使用して実装された。
英語データセット:** bert-base-uncasedモデルを使用。
スペイン語データセット:** bert-base-multilingual-cased モデルを使用。
すべてのAugSBERTモデルは、SBERTに匹敵する計算速度を示した。
- ハイパーパラメータ:**異なるハイパーパラメータが、クロスエンコーダの微調整、バイエンコーダの微調整、サンプリングのためにテストされた。以下は、実験中に使用された最適なハイパーパラメータである。
- クロスエンコーダ微調整:** 以下の微調整パラメータがクロスエンコーダ(BERT)用に最適化されました:
学習率:** 1 × 10-⁵。
学習レート:** 1 × 10-⁵ 隠れ層のサイズ: {200, 400}
バッチサイズ:** 16
CLS]トークンの上にシグモイド活性化を持つ線形層が追加され、0から1の間の類似度スコアを出力する。
- SBERTバイ・エンコーダは、以下のハイパーパラメータで微調整された:
バッチサイズ:** 16
学習レート:** 2 × 10-⁵。
オプティマイザー:** AdamW
- サンプリング戦略:** BM25とSemantic Searchのサンプリングにおいて、{3, 18}の範囲で様々なトップk値が評価された。その結果、kの選択は性能に最小限の影響しか与えず、k = 3またはk = 5で最良の結果が得られることがわかった。
- 評価メトリクス:**異なるタスクに対して異なる評価メトリクスが使用されました。評価指標の詳細は以下を参照:
領域内回帰タスク(例:STS、BWS):*** 評価指標の詳細は以下を参照のこと。
- 性能評価には、予測類似度スコアと金類似度スコア間のスピアマンの順位相関(ρ×100)を用いた。
領域内分類タスク(例:Quora-QP、MRPC):***.
- 正ラベルのF1スコアが報告された。最適な閾値は開発セットに基づいて選択され、テストセットに適用された。
領域適応タスク:***.
- 評価指標としてAUC(0.05)を用いた。AUC(0.05)は、偽陽性率(FPR)の関数として、真陽性率(TPR)の曲線下面積を測定するもので、FPR = 0からFPR = 0.05まである。この指標は偽陰性に対してよりロバストである。
- シードの最適化:**ドメイン内実験は信頼性を確保するために10個のランダムなシードで繰り返された。各構成の平均スコアと標準偏差が報告された。さらに、シードの最適化を行い、各実験におけるばらつきを考慮した。
ドメイン内およびドメイン適応の結果
ドメイン内およびドメイン適応タスクの両方におけるAugSBERTの性能は、バイエンコーダの能力を向上させる有効性を実証しています。AugSBERTは、クロスエンコーダとバイエンコーダの長所を組み合わせることで、様々なNLPタスクに実用的なソリューションを提供します。ドメイン内適応とドメイン適応の両方の実験から得られた詳細な結果を評価しよう。
図:インドメインとクロスドメインの両実験のAUC(0.05)スコア](https://assets.zilliz.com/Figure_AUC_0_05_scores_for_both_In_Domain_and_Cross_Domain_experiments_0fb552dd12.png)
図:インドメイン実験とクロスドメイン実験のAUC(0.05)スコア|出典
インドメインの結果
バイエンコーダ(SBERT、SeedOptなし)の性能**:プレーンバイエンコーダ(SBERT without SeedOpt.)は、すべてのドメイン内タスクで一貫してクロスエン コーダの性能を下回っており、性能差は 4.5~9.1 ポイントに及ぶ。
AugSBERTの性能**:AugSBERTは、すべてのタスクで性能を1~6ポイント向上させ、バイエンコーダSBERTを大幅に上回り、クロスエンコーダBERTとの性能差を縮めました。
同義語置換(NLPAug)との比較:AugSBERTは、すべてのタスクで同義語置換データ増強技術(NLPAug)を上回っています。
Universal Sentence Encoder (USE)との比較:ほとんどのタスクにおいて、AugSBERT は、既製の USE モデルを大幅に上回る。例外は、スペイン語-STSで、USEはトレーニング中にテストセットに事前にさらされることで良い結果を出している。
Cross-Encoder**との比較:既知のトピック(in-topic)において、AugSBERT はクロスエンコーダを上回り、良好なパフォーマンスを示した。この性能の向上は、BERT クロスエンコーダに比べ、SBERT バイエンコーダの汎化能力が優れているためと思われる。
ペアワイズサンプリング戦略**:
ランダムサンプリングは、ラベル分布を歪ませる非類似のペアの数が多いため、性能が低下する。
BM25とカーネル密度推定(KDE)サンプリング法は、より多くの類似ペアを生成することでパフォーマンスを向上させる。
KDEは、正負のペアのより良い分布を作ることでパフォーマンスを向上させるが、計算効率が悪い。
BM25は、計算効率と性能のバランスが最もよく、より多くの類似ペアを生成する。
ドメイン適応結果
ドメイン適応における AugSBERT**:AugSBERT は、ほとんどのソースとターゲットのドメインの組み合わせにおいて、ドメイン外データ(クロスドメ イン)で訓練された SBERT を一貫して上回っている。例えば、Sprint データセット(ターゲット)において、AugSBERT は最大 87.5% AUC(ソース:Quora)を達成し、SBERT(50.5% AUC)に対して 37 ポイントの大幅な改善を示しています。
ソースとターゲットのドメイン**:AugSBERTは、ソースドメインが一般的(例:Quora)で、ターゲットドメインが特殊(例:Sprint)な場合に、特に優れたパフォーマンスを発揮する。これは、Quora が多様なトピックをカバーしているため、クロスエンコーダがより具体的なターゲットドメインに効果的に適応できるためと思われる。特定のドメイン(例:Sprint)からより一般的なターゲット(例:Quora)に移行した場合、AugSBERTはほとんど改善を示さない。例えば、Sprint をソース、Quora をターゲットとした場合、AugSBERT は、SBERT と同じ 49.5%の AUC を達成する。これは、特定のドメインから一般的なドメインへの適応が困難であることを示している。
Bi-LSTM**との比較:AugSBERTは、Sprintデータセット(ターゲット)を除く多くのケースで、最先端のBi-LSTMバイエンコーダーモデルを凌駕している。例えば、AskUbuntuをソースとするSprintデータセット(ターゲット)では、Bi-LSTM(敵対的)は92.2%のAUCを達成し、AugSBERTの85.2%のAUCを上回った。にもかかわらず、AugSBERTは、特に一般的なドメインから特定のドメインに適応する場合、他のほとんどのドメインペアにおいてより良いパフォーマンスを発揮する。
主要な結果
AugSBERTの改善**:AugSBERTは全タスクで1~6ポイント性能を向上。クロスエンコーダとの差を縮め、SBERTを上回る。
ドメイン適応**:AugSBERTは、特に一般的なドメインから特定のドメインに移行する場合、ドメイン外のデータでトレーニングされたSBERTを最大37ポイント上回る。
ペアワイズ・サンプリングBM25は、性能と効率の間で最も良いバランスを保っている。KDEはパフォーマンスを向上させるが、計算効率が悪い。
USEとの比較**:AugSBERT は、ほとんどのタスクで Universal Sentence Encoder(USE)を上回っている。
バイエンコーダとベクトルデータベース
AugSBERTのようなバイエンコーダーモデルは、文の密なベクトル表現を作成し、固定長の埋め込みで文の意味的な意味を捉える。これらのモデルは、各入力を独立してエンコードし、その内容を表すユニークなベクトルを生成する。テキストデータを高次元の埋め込みに変換することで、バイエンコーダは効率的な意味的類似性の比較を可能にする。この能力は、意味検索、文書ランキング、情報検索のような、テキストの背後にある意味を理解することが重要なアプリケーションに力を与える。
ベクターデータベースは、これらの埋め込みを大規模に扱うための特別なインフラを提供する。ベクトルデータベースは、余弦類似度やユークリッド距離のようなメトリックスを使った類似検索のようなタスクのために、これらの高次元埋め込みデータを格納し、インデックスを付け、検索します。クエリベクトルが送信されると、データベースは最も意味的に類似したベクトルを検索し、質問応答システム、推薦エンジン、クロスドメイン検索などのユースケースを可能にする。意味のある表現を生成するためのバイエンコーダと、効率的な検索のためのベクトルデータベースの組み合わせは、スケーラビリティとスピードの両方を提供し、最新のAI駆動型検索・推薦システムのバックボーンを形成する。
ベクトルデータの管理とクエリのための代表的なプラットフォームの一つは、Zillizによって開発されたオープンソースのベクトルデータベースであるMilvusである。Milvusは大規模な類似検索をサポートし、高次元データと高速なインデックス作成とクエリの両方に最適化されている。
Milvusを使用すると、AugSBERTのようなモデルによって生成された数十億のベクトルを保存し、類似性に基づいて最も関連性の高いデータを見つけるためにリアルタイム検索を実行することができます。Milvusは、低レイテンシ検索を保証しながら、大規模なデータセットに拡張できる様々なインデックス作成アルゴリズムをサポートしています。
Zillizはまた、企業顧客向けにMilvusをベースとしたクラウドベースのソリューションであるZilliz Cloudを提供している。手間がかからず、Milvusの10倍高速です。この提供により、ベクター検索と管理をクラウドネイティブなアーキテクチャに統合することが容易になる。ユーザーはインフラ管理を心配することなく、大規模AIアプリケーション用のベクトルデータベースを導入することができる。
結論と今後の研究の方向性
AugSBERT アプローチは、ペアワイズ文スコアリングタスクのためのバイエンコーダを強力に強化する。AugSBERTは、クロスエンコーダによって生成されたソフトラベルによるデータ補強を用いて、バイエンコーダとクロスエンコーダの性能ギャップを埋める。モデルにとらわれない設計により、様々な文スコアリング・アプリケーションにシームレスに適応することができる。これにより、意味表現を改善するための汎用的なツールとなる。
AugSBERTは、ドメイン内タスクで最大6ポイント、ドメイン適応シナリオで最大37ポイントという大幅な性能向上を実現する。その有効性にもかかわらず、AugSBERTはKDEなどの計算集約的なサンプリング戦略に依存しており、大規模な実装ではスケーラビリティが制限される可能性がある。さらに、意味のある文のペアを識別する一方で、多言語や敵対的な設定における課題に直面している。
AugSBERT の今後の研究の方向性
Binoculars 法を改善し、その限界に対処するための将来の研究方向がいくつかある:
サンプリング戦略の効率性:** AugSBERT は BM25 や KDE のような戦略から恩恵を受けているが、より計算効率の良いサンプリング手法のさらなる探求が不可欠である。これらの方法は、特に大規模なデータセットに対して、性能向上とスケーラビリティのバランスを取るべきである。
多言語および低リソース設定:** AugSBERTの多言語タスクにおける性能は、より強力な多言語モデルを用いて改善することができる。今後の研究は、訓練データと事前に訓練されたモデルが限られている低リソース言語における有効性の改善に焦点を当てることができる。
関連リソース
拡張SBERT論文:https://arxiv.org/pdf/2010.08240
Zilliz Cloud Platform: https://www.zilliz.com
Milvusドキュメント: https://milvus.io/docs
Understanding Transformer Models Architecture and Core Concept](https://zilliz.com/learn/decoding-transformer-models-a-study-of-their-architecture-and-underlying-principles)
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
ジェネレーティブAIリソースハブ|Zilliz](https://zilliz.com/learn/generative-ai)
2025年に注目すべきAIエージェントトップ10 🚀](https://zilliz.com/blog/top-10-ai-agents-to-watch-in-2025)
2025年、開発者が無視できないオープンソースLLMフレームワーク10選 ](https://zilliz.com/blog/10-open-source-llm-frameworks-developers-cannot-ignore-in-2025)
 Haziqa Sajid
Haziqa SajidDigital Storytelling for Data, AI, B2B & SaaS
読み続けて

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.