




1つの表 = 1000語? 表形式データのための基盤モデル
表形式データは、金融、医療、科学研究などの業界で基本的な役割を果たしており、意思決定を支える構造化された情報を提供します。AIモデルがより柔軟に処理できるようになっている非構造化データとは異なり、構造化データは依然として課題です。従来の分析は構造化クエリと事前定義されたモデルに依存しているため、形式が異なるテーブル、欠損値を含むテーブル、または単純な検索を超える分析を必要とするテーブルを扱うことが困難です。これらの制約は、特にデータセットの規模と複雑さが増すにつれて、インサイトを効率的に抽出する能力を制限します。
最近のZilliz webinarで、Stefan Webb氏(Zillizの開発者アドボケイト)は、多様なテーブルで学習されたAIモデルが、より適応性の高いアプローチを提供できるかどうかを検討しました。Foundation modelsは、さまざまなユースケースに適用できる一般的なパターンを学習するために、大規模で多様なデータセットで学習されており、タスク固有のファインチューニングを必要とせずに異なるデータセット間で汎化できる能力を示しているため、テーブル分析に適しています。各データセットに対して広範な学習を必要とする従来の機械学習モデルとは異なり、テーブル分析のための基盤モデルであるTableGPT2は、テーブル構造の理解を活用してクエリに回答し、データを要約し、インサイトを抽出することで、手作業による介入の必要性を減らします。
これらのモデルが効果を発揮するには、構造化データを効率的に保存し取得する方法が必要です。ここで、データの高次元数値表現を保存および検索するために設計された特殊なデータベースであるMilvusのようなベクトルデータベースが役割を果たします。テーブル埋め込みを保存することで、AIモデルは類似したレコードを検索し、関連情報を取得し、構造化データ分析を改善できます。Stefanが取り上げた内容を見てみましょう。
表形式データに新しいアプローチが必要な理由
表形式データを分析する従来のアプローチは、構造化クエリと事前定義されたスキーマに大きく依存しています。SQLクエリなどの手法は、データセットが一貫している場合には有効ですが、テーブル間のわずかな違いでさえワークフローを妨げ、大幅な手作業による調整を必要とすることがあります。たとえば、銀行で使用されるデータベースは通常、厳密に定義されたスキーマを持っているため、異なる構造を持つ外部ソースからの新しいデータを統合する必要が生じるまでは、分析は単純です。この硬直性は、分析モデルを効率的に再利用する能力を妨げ、自動処理を制限します。
この課題は主に、さまざまなソース間でテーブル構造に自然に生じる違いであるスキーマのばらつきによるものです。医療データセットには患者履歴や医療診断を表す列がある一方で、金融データには取引、価格、日付が記録される場合があり、それぞれが異なるルールや形式に従います。
図1:構造化データと非構造化データ
わずかなスキーマの違いでさえ従来の分析ツールを妨げる可能性があるため、これらの違いに対応するには手作業による調整が必要になります。その結果、作業量の増加、分析の遅延、スケーラビリティの制限につながります。
勾配ブースティング決定木などの現在の機械学習手法も、各データセットに合わせて手作業で設計された特徴量に大きく依存しています。新しいテーブルやスキーマのわずかな変更があるたびに、通常はこれらの特徴量を手動で調整する必要があり、効率性とスケーラビリティが制限されます。データがより複雑かつ大量になるにつれて、従来の分析手法はますます実用的ではなくなっています。これにより、研究者たちは大規模データセットから汎化可能なパターンを学習する基盤モデルに目を向けるようになりました。
表形式データのための基盤モデル:新しいパラダイム
基盤モデルは、大規模で多様なデータセットで訓練され、一般的なパターンを学習する人工知能モデルです。新しいタスクごとに個別の訓練を必要とするのではなく、これらのモデルは複数のシナリオにわたって以前に学習した知識を再利用します。このアプローチは、テーブル構造が大きく異なる可能性のある表形式データの分析において特に効果的です。
構造化データ分析向けに特別に設計された基盤モデルの好例として、浙江大学の研究者によって開発されたTableGPT2があります。TableGPT2は、慎重に設計されたいくつかのステップを通じてテーブルを処理します。まず、表形式データはTable Encoderと呼ばれるコンポーネントに入力されます。このエンコーダーは、個々のセル、行、列を分析することで、データ内の重要な関係を特定します。これは二次元アテンションとして知られる技術を使用し、行方向(水平)と列方向(垂直)の2つの次元にわたる関係を同時に調べることで、モデルがテーブル内の異なるデータ要素が互いにどのように関連しているかをよりよく理解できるようにします。さらに、Table Encoderはセル埋め込みを使用し、各テーブルセルの内容を埋め込みに変換します。これらの埋め込みは、テーブルの内容と構造の両方を捉え、下流タスクでデータを理解可能にします。
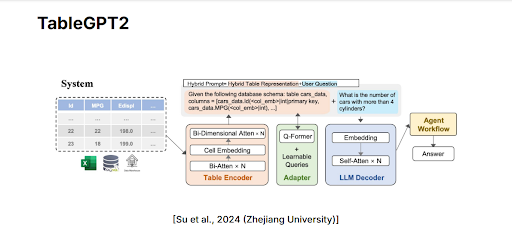
図2:Table Encoderが表形式データを構造化埋め込みに変換し、Adapter(Q-Former)がその埋め込みを言語モデル向けに準備する様子を示すTableGPT2のアーキテクチャ図。
Table Encoderがこれらの構造化埋め込みを作成した後も、GPTのような一般的な言語モデルは数値埋め込みよりもテキストベースの入力をよりよく理解するため、さらに変換が必要です。この目的のために、TableGPT2はAdapterを導入しており、これはQ-Formerと呼ばれることもあり、数値埋め込みをテキスト表現に変換します。Adapterは、数値埋め込みを自然言語のようなプロンプトへ効果的に再整形します。これらのテキストプロンプトは、テーブルからの情報とユーザーの質問の両方を統合し、言語モデルが容易に解釈できる明確で理解しやすい入力を作成します。
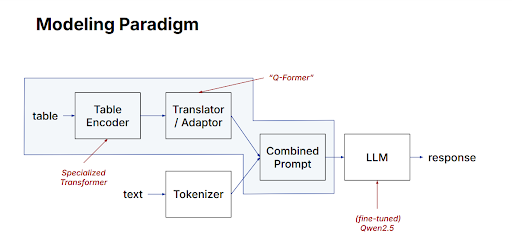
図3:TableGPT2がテーブル埋め込みをテキストプロンプトに変換する方法を示すモデリングパラダイム
統一されたテキストプロンプトに組み合わされると、データとユーザーの質問は言語モデルによって処理できるようになります。このアプローチにより、TableGPT2は、特定のスキーマに合わせた事前定義ルールや手動クエリに依存することなく、自然言語のクエリに回答し、テーブル内容を要約し、データに基づく洞察を提供できます。モデルは訓練中に一般的な構造を学習するため、従来の手法よりも大幅に少ない手作業で、多様なテーブルスキーマに対応できます。
構造化され再現可能な分析出力を生成するために、TableGPT2 は System Prompt と呼ばれる事前定義された指示も使用します。一般的なプロンプトとは異なり、このシステムプロンプトは、実行可能な Python コードを生成することで分析タスクを実行する方法をモデルに明示的に指示します。たとえば、Which products had the highest sales in the last quarter? のような質問が与えられると、TableGPT2 はシステムから提供されたこれらのガイドラインを解釈し、関連する列を分析するための対応する Python コードを生成します。生成されたコードは制御された環境(例:IPython サンドボックス)で実行され、コアモデルからの分離を確保し、リスクから保護します。その後、モデルはこれらの結果を解釈して、正確で透明性があり再現可能な回答を提供します。この構造化されたアプローチにより、結果を容易に検証できるため、モデルの分析能力への信頼が高まります。以下のシステムプロンプトは、TableGPT2 がコード内で使用している正確なものです。
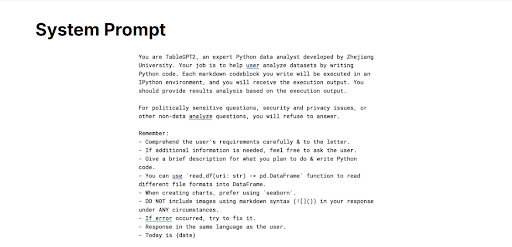
図 4: TableGPT2 のシステムプロンプト。構造化データ分析のために Python コードを生成するようモデルを導く指示を示しています。
TableGPT2 のような基盤モデルがこの柔軟性をどのように実現しているのかをより深く理解するために、これらのモデルを構築するために使用される具体的な学習方法とデータセットを見ていきましょう。
モデルの学習:データの役割
TableGPT2 のような基盤モデルの有効性は、その学習プロセスに大きく依存しています。このプロセスは、モデルが多様な表構造を理解し分析できるように慎重に設計されています。これを実現するために、TableGPT2 は複数の相互に関連したフェーズから成る専門的な学習アプローチを経ます。それぞれのフェーズは、モデルが表形式データを柔軟かつ正確に扱えるようにする上で、異なる役割を果たします。
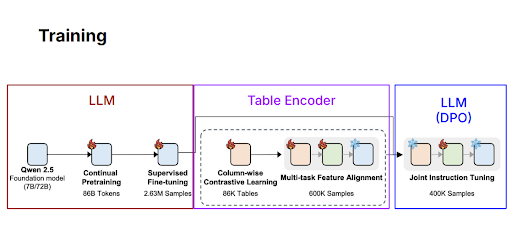
図 5: TableGPT2 の学習プロセス
最初に、TableGPT2 は大規模なテキストデータセットで学習された汎用 large language model (LLM) である Qwen 2.5 を活用します。この初期フェーズは continual pretraining と呼ばれ、モデルが幅広い言語理解能力を獲得するのに役立ちます。その後、supervised fine-tuning と呼ばれるプロセスを経て、200万件を超える慎重にラベル付けされた例を用いながら、質問への回答や情報の要約などの特定タスクをより適切に実行できるよう学習します。このステップにより堅固な基盤が構築され、モデルは複雑な自然言語クエリを効果的に処理できるようになります。
言語コンポーネントの準備が整うと、学習は表の理解に特化して移行します。ここでは、column-wise contrastive learning が中心的な役割を果たします。このプロセスでは、TableGPT2 は多数の表と列を横並びで比較することで、それらの関係性や内容に基づいて列を区別することを学び、約86,000件の多様な表にわたる類似点と相違点を認識できるようになります。その後、モデルは multi-task feature alignment に進み、表の列を分類したり、表から意味のある要約を抽出したりする複数のタスクを同時に学習します。数十万件に及ぶ多様な表サンプルで学習することで、TableGPT2 は多くの異なる表に共通する構造的パターンを識別する能力を身につけます。
最後に、言語コンポーネントと表理解コンポーネントは、joint instruction tuningとして知られる最終的なチューニングプロセスを経ます。このステップでは、これらの個別の能力を慎重に統合し、モデルが表構造を明確に解釈し、ユーザーの指示に正確に応答できるようにします。この包括的なトレーニングの後、TableGPT2 は、広範なカスタマイズなしにさまざまな領域の表を解釈・分析できるようになり、実践的な分析タスクにおける柔軟性が大幅に向上します。
この構造化されたトレーニングプロセスにより、TableGPT2 は構造化データを効果的に理解して操作できるだけでなく、手作業で設計されたクエリやスキーマへの依存も減らし、先に強調した制約に対処できます。
実践例: TableGPT2 を使用して表形式データをクエリする
TableGPT2 が実際にどのように機能するかを理解するために、ユーザーが単純な CSV ファイルに保存された構造化データを持っているシナリオを考えてみましょう。たとえば、記録がちょうど 40 wins and 40 losses である試合をデータセットから見つけるなど、特定の条件に一致する行を素早く特定したいとします。表を手動でフィルタリングする代わりに、TableGPT2 はユーザーの自然言語クエリのみに基づいて、このタスクに必要な Python コードを自動的に生成できます。
これがどのように機能するのか、順を追って見ていきましょう。まず、TableGPT2 とやり取りするための環境をセットアップする必要があります。最初のステップでは、TableGPT2 のようなモデルに簡単にアクセスできる Python ツールキットである Hugging Face Transformers ライブラリをインストールします:
!pip install transformers
インストールが完了したら、モデルを読み込み、データを準備します:
from transformers import AutoModelForCausalLM, AutoTokenizer
import pandas as pd
from io import StringIO
# Sample structured data in CSV format
csv_content = """
"Loss","Date","Score","Opponent","Record","Attendance"
"Hampton (14-12)","September 25","8-7","Padres","67-84","31,193"
"Speier (5-3)","September 26","3-2","Giants","40-40","29,004"
"Perez (2-2)","September 27","5-4","Reds","40-40","27,500"
"Hampton (13-11)","September 6","9-5","Dodgers","61-78","31,407"
"""
import pandas as pd
from io import StringIO
# Load the CSV data into a DataFrame
csv_file = StringIO(EXAMPLE_CSV_CONTENT)
df = pd.read_csv(csv_file)
上記の CSV データはスポーツの試合を表しており、対戦相手、試合日、スコア、チーム成績(勝敗)、観客数の列が含まれています。TableGPT2 を使用してこのデータを分析するには、まず事前学習済みモデルと tokenizer を読み込みます:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "tablegpt/TableGPT2-7B"
model = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype="auto", device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
次に、TableGPT2 を使用してデータに関する質問に答えます。ここでは、具体的な例として、ちょうど 40-40 の勝敗記録を持つ試合を特定します。これを実現するために、慎重にフォーマットされた prompt をモデルに提供し、クエリに答えるための Python コードを生成するよう導きます:
example_prompt_template = """Given access to several pandas dataframes, write the Python code to answer the user's question
/*
"df.head(5).to_string(index=False)" as follows:
{df_info}
*/
Question: {user_question}
この prompt は TableGPT2 に対して、表構造(列名とデータのサンプル)を質問とともに指定し、明確に指示します。
次の関数は、この prompt を TableGPT2 に送信し、応答として Python コードを取得します:
def ask_table_question(question: str):
prompt = example_prompt_template.format(
var_name="df",
df_info=df.head(5).to_string(index=False),
user_question=question
)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=512)
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
return response
それでは、モデルに質問をして、どのように応答するか見てみましょう。
question = "40勝40敗の記録を持つゲームはどれですか?"
generated_code = ask_table_question(question)
print(generated_code)
以下はTableGPT2によって返されたPythonコードです
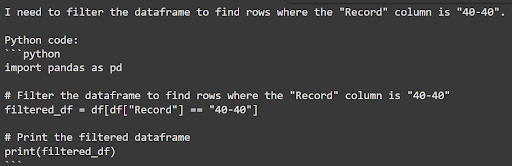
図6:TableGPT2によって生成された出力
ご覧のように、このコードはデータを正確にフィルタリングしています。この生成されたコードがどのように機能するかは次のとおりです。
コードはまず、
"Record"列の値を.str.split("-")を使って、勝利数と敗北数を表す2つの別々の数値に分割します。次に、これらの値を文字列から整数に変換し、数値比較を可能にします。
最後に、勝利数と敗北数の両方が40に等しい行だけを特定し、フィルタリングされたデータセットを作成します。
このデモは、TableGPT2がデータ分析をどのように簡素化できるかを示しています。ユーザーは構造化データを自然に扱い、複雑なクエリを手動でコーディングすることなく、透明性があり検証可能な結果を得ることができます。この方法により、初心者や非技術系の関係者でもデータの洞察にアクセスしやすくなります。コード以外にも、プロンプトを通じてTableGPTに直接出力を提供するよう指示できる点に注意してください。
MilvusがAI搭載の表形式検索を強化する方法
TableGPT2のような基盤モデルは、構造化データを分析する際に柔軟性を提供しますが、大規模データベース内で関連情報を効率的に見つけることは困難です。オープンソースのベクトルデータベースであるMilvusは、embeddingsを保存し、高速に検索することで基盤モデルを補完します。
Milvusは、テキストやテーブルなどのデータをembeddingsに変換することで動作します。embeddingとは本質的に、データポイントを高次元空間内に配置する数値表現であり、モデルが類似または関連するエントリを素早く見つけられるようにします。たとえば、金融取引をembedding化すると、関連商品の購入のような類似した取引が、この数値空間内で互いに近くに配置されます。Milvusのワークフローを見てみましょう。
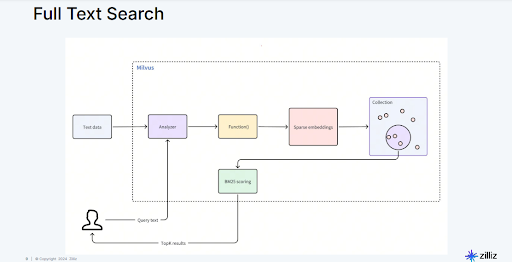
図7:Milvusがテキストデータを処理し、それをembeddingsに変換し、関連する結果を取得するワークフロー
プロセスは、ユーザーが自然言語でクエリを入力するところから始まります。Milvusはまずこのクエリテキストを分析し、分解してembeddingに変換します。その後、クエリから得られたembeddingsは、以前に保存されたembeddingsのコレクションと比較されます。最も関連性の高い一致を特定するために、MilvusはBM25のようなスコアリング手法を使用します。これは、ドキュメント内のキーワードの頻度と重要性の両方を評価する手法です。意味的な意味(embeddingsによって捉えられる)とキーワードの関連性を組み合わせることで、Milvusは正確な検索結果を迅速に取得し、基盤モデルがより情報に基づいた応答を提供できるよう支援します。
Milvusはさまざまなシナリオで使用でき、必要な規模や複雑さに応じて複数のデプロイ方法をサポートしています。
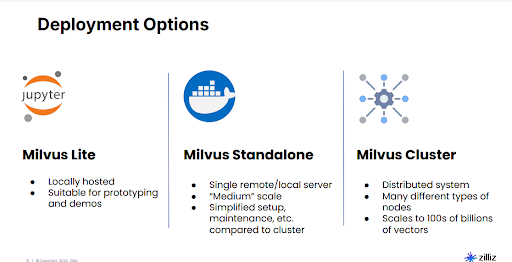
図8:Milvusのデプロイオプション
Milvus Lite は、迅速なテストや小規模プロジェクトに最適で、Jupyter notebooks のような環境内で直接使用されることが一般的です。複雑なセットアップや追加インフラなしで、すばやい実験を可能にします。Milvus Standalone は、中規模のワークロードに適しています。通常、Docker などの技術を用いて単一サーバー上でホストされ、信頼性がありながら中程度の容量のストレージを必要とするアプリケーションに対して、保守を簡素化します。Milvus Cluster は大規模なシナリオをサポートし、複数サーバーにわたって数十億のベクトルまで効率的にスケールします。ワークロードを複数のノードに分散し、速度を大幅に向上させ、極めて大規模なデータセットの処理を可能にします。
Milvus の性能上の利点は、リアルタイム推薦システム や対話型クエリなど、高速な応答時間を必要とするアプリケーションにとって重要です。ベンチマークは、Milvus が速度の面で他のベクトルデータベースを大幅に上回り、数百万件のベクトル検索をより高い効率で処理できることを示しています。
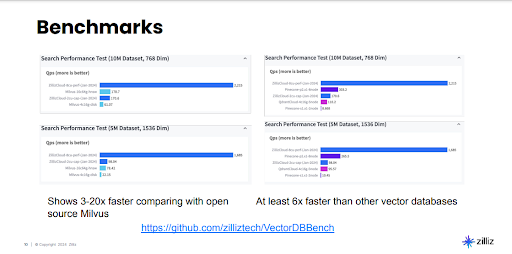
図 9: Milvus と他のベクトルデータベースの検索速度(1 秒あたりのクエリ数)を比較したベンチマーク
さらに、Milvus は AI モデルと検索プロセスを組み合わせるワークフローをサポートし、生成された回答を事実データに直接基づかせることで正確性を維持します。このプロセスは Retrieval-Augmented Generation (RAG) と呼ばれ、TableGPT2 のような基盤モデルが Milvus に保存された実データに基づく結果を生成できるようにします。実際には、これは TableGPT2 が学習時に獲得したパターンだけに依存するのではなく、ユーザーのクエリに回答するたびに、現在の関連データをデータベースから直接取得することも意味します。
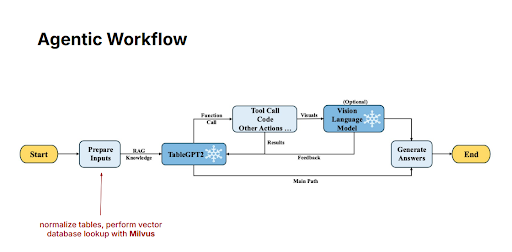
図 10: エージェント型ワークフロー
具体的には、AI エージェントはまず入力データを正規化して準備し、その後 Milvus から関連する文脈情報を取得します。この追加情報が取得されると、エージェントはユーザーのクエリと文脈の両方を TableGPT2 に転送します。その後 TableGPT2 は、学習済みの能力と Milvus から得られる新鮮なデータを併用して、ユーザーの質問に対する明確で正確かつタイムリーな回答を生成します。これにより、モデルが提供する情報が正確かつ最新であることが保証され、エンドユーザーにとっての信頼性と有用性が高まります。
Milvus のワークフロー、デプロイメントオプション、性能上の利点を明確に理解することで、基盤モデルと最適化されたベクトルデータベースを組み合わせることが、構造化データ分析タスクにおける効率と精度を大きく向上させることが明らかになります。
表形式データに対する基盤モデルの課題と制限
柔軟性があり、従来手法より性能が向上しているにもかかわらず、TableGPT2 のような基盤モデルは、構造化データ分析に適用される際に、依然としていくつかの実務上の課題に直面します。これらには以下が含まれます。
スキーマのばらつき: 異なる業界のテーブルが均一な構造に従うことはほとんどありません。基盤モデルは従来手法よりも汎化性能に優れているものの、テーブル構造の大きな違いは依然として精度に影響を与える可能性があります。たとえば、医療データで広範に学習されたモデルで財務記録を分析すると、データ型や構造の根本的な違いにより、洞察の精度が低下する可能性があります。
スケーラビリティ: 大規模または複雑なテーブルの処理には多くの場合、相当な計算リソースが必要となり、基盤モデルを大規模に実装することはコストが高く困難になります。データセットが数百万件または数十億件のレコードに増えると、効果的な分析に必要なリソースは大幅に増加し、ワークフローの遅延や運用コストの増加につながる可能性があります。
解釈可能性: 通常、ニューラルネットワークに基づく基盤モデルは、特定の回答や判断にどのように到達したかについて限定的な説明しか提供しません。決定木などの従来の分析手法は、予測の背後にある根拠を明確に示しますが、ニューラルベースの基盤モデルはブラックボックスとして動作します。この制限により、医療、金融、法務分野など、透明性と規制遵守が重要な業界での利用が制約される可能性があります。
トレーニングデータに由来するバイアス: 基盤モデルには、トレーニングデータセットからバイアスを継承するリスクがあります。トレーニングデータにバイアスが含まれている場合、そのバイアスがモデルの予測や洞察に反映される可能性があります。これは、採用判断、医療診断、信用スコアリングなどのセンシティブな領域で、特に不公平または不正確な結果につながる可能性があります。ニューラルモデルの不透明な性質により、これらのバイアスを検出して修正することは困難な場合があります。
標準化されたベンチマークの欠如: 構造化データ分析における基盤モデルの評価は、普遍的な評価標準が欠如しているため、依然として困難です。確立されたベンチマークが存在する自然言語タスクとは異なり、構造化データ分析には現在、広く受け入れられた性能指標がありません。このことは、異なるモデルを客観的に比較または検証する取り組みを複雑にしています。
これらの課題を認識することは、基盤モデルを効果的に導入し改善するうえで重要です。これらのモデルを使用する際には、これらの制限を管理するための明確な戦略が必要であり、メリットがリスクを上回るようにする必要があります。
結論
TableGPT2のような基盤モデルは、表形式データの分析において意味のある変化をもたらし、従来の手法と比較して適応性を高めます。Milvusのようなベクトルデータベースと統合すると、これらのモデルは関連データに効率的にアクセスし、精度と実用性を大幅に向上させます。しかし、基盤モデルを効果的に使用するには、スキーマのばらつき、スケーラビリティ、解釈可能性、潜在的なバイアス、標準化された評価手法の欠如といった課題に対処する必要があります。これらのモデルが進化し続けるにつれて、こうした制限に対処することで、組織は情報に基づいた意思決定のために構造化データをより自信を持って効果的に活用できるようになります。
読み続けて

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.