




機械学習におけるK-最近傍(KNN)アルゴリズムとは?
***最新更新:7月31日
K-Nearest Neighbors (KNN)アルゴリズムは、分類と回帰の問題を解決できる教師あり機械学習アルゴリズムです。この包括的な記事では、生産可能なAIのためのベクターデータベースのリーディングカンパニーであるZillizが、KNNとは何か、KNNはどのように機能するのか、機械学習におけるKNNとは何か、なぜKNNが必要なのか、KNNを改善する方法にはどのようなものがあるのか、といった疑問にお答えします。また、Pythonを使ったKNNモデルの実装を実演します。
K-最近傍(KNN)とは?
前述の通り、K-最近傍 (KNN) アルゴリズムは、分類や回帰の問題を解決できる教師あり機械学習アルゴリズムです。KNNアルゴリズムは、あるデータ点が2つのグループのいずれかに属する可能性を、そのデータ点に最も近いデータ点に基づいて推定します。KNNアルゴリズムは、回帰問題だけでなく、分類や回帰タスクにも使用できる。KNNは遅延学習器(lazy learner)に分類され、学習段階を経ずに学習データセットのみを保存する。さらに、分類や予測が行われるときにすべての計算が行われることを意味する。学習データの保存にメモリを使用するため、メモリベース学習とも呼ばれる。
KNNには2つの重要な特徴がある。第一に、KNNはノンパラメトリック・アルゴリズムである。つまり、モデルを使用する際、データセットに関する仮定がなされない。その代わり、モデルは提供されたデータから完全に構築される。第二に、KNNを使用する場合、データセットはトレーニング・データセットとテスト・データセットに分けられない。これはKNNがトレーニング・セットとテスト・セットを区別しないためで、その代わりに予測を行うよう求められたときに、利用可能なすべてのデータを使用する。
K-最近傍(KNN)アルゴリズムの計算方法とアルゴリズムの仕組み
観察に基づいて未観測のデータポイントのクラスを決定するために、K-最近傍は基本的に投票メカニズムを使用します。これは、最も多くの票を獲得したクラスが、関連するデータポイントのクラスになることを示します。
Kが1に等しい場合、データポイントのクラスを決定するときに、そのデータポイントの最近傍のみを考慮します。Kが10に等しい場合は、10近傍が使われ、以下同様である。下図は、KNNが2つのクラスの学習点の間でどのように機能するかを説明しています。
KNNが2つのクラス間でどのように働くか.出典:https://www.ibm.com/in-en/topics/knn](https://assets.zilliz.com/KNN_working_between_two_classes_cadc78c78d.png)
2つのクラスを考えます:アルゴリズムでは、データ点がクラスAに属するかクラスBに属するかを判断するために、近傍のデータ点の状態を調べます。ほとんどのデータ点がグループAに属する場合、問題のデータ点がグループAに属することはほぼ確実です。
さて、あるデータ点が近傍であるかどうかを判断するための【距離メトリック】(https://docs.zilliz.com/docs/search-metrics-explained)はどのように計算されるのか、不思議に思われるのではないでしょうか?データ点とその最近傍との距離を計算する方法は数多くあります。ユークリッド距離](https://zilliz.com/blog/similarity-metrics-for-vector-search)、コサイン距離、ジャカード距離、ハミング距離などです。
ユークリッド距離は、ユークリッド空間における2点間の真の直線距離です。
コサイン距離](https://milvus.io/docs/metric.md)は主に2つのベクトルの類似度を計算するのに使われます。
ジャカード距離またはジャカード指数は、両方のデータセットを調べ、両方の値が1に等しい事件を見つけます。
ハミング距離(Hamming Distance)は、カテゴリデータを扱うときに、与えられたデータポイントの値が、距離を測定するデータポイントの値と等しいかどうかを調べるために使用されます。
このチャートは、これらの距離測定基準がどのようなものかを教えてくれる:
距離メトリクス](https://assets.zilliz.com/KNN_Chart_0e6b0d42fe.png)
距離メトリクス
K Nearest Neighbors 回帰のステップの大部分は、分類と同じです。最も多くの票を持つターゲット・データ・ポイントのクラスを割り当てる代わりに、未知のデータ・ポイントは、その近隣の値の平均を割り当てられます。
K-最近傍分類における'K'の値
Kの正しい値を選択することは、ハイパーパラメータのチューニングとして知られており、より良い結果を得るために必要です。Kの最適値を決定するための定義された方法はなく、問題の特定のタイプによって決定されます。
K 値は、特定のクエリ・ポイントの K Nearest Neighbor 分類器を決定するために、いくつの近傍をチェックするかを指定します。例えば、k=1 の場合、インスタンスはその1つの最近傍と同じクラスに割り当てられます。
Kの値が異なると、新しいデータのオーバーフィッティングやアンダーフィッティングにつながる可能性があるため、Kの定義はバランスを取る行為となります。K値が低いと分散は高いがバイアスは低く、K値が高いとバイアスは高いが分散は低くなります。
なぜKNNアルゴリズムが必要なのか?
KNNは非常に正確な予測を行う。最も正確なSOTAモデル(最先端モデル)と競合できる。その結果、K Nearest Neighborアルゴリズムは、高い精度を必要とするが、人間が読めるモデルを必要としないアプリケーションに使用することができます。
予測の精度は、測定された距離によって決定されます。したがって、KNNアルゴリズムは、十分なドメイン知識があるアプリケーションに適しています。この理解は、適切な尺度の選択に役立ちます。
K-Nearest Neighborsの改善:その方法
より良い結果を得るためには、トレーニングデータ点を同じスケールで正規化することが推奨されます。また、Kと距離メトリックのハイパーパラメータのチューニングも重要です。
Kの値を変えてK Nearest Neighborアルゴリズムをクロスバリデーション手法でテストすることができます。最も精度の高いモデルを最良の選択肢とみなすことができます。
K-Nearest Neighborの例:KNNアルゴリズムのPython実装
それでは、PythonによるKNNモデルの実装に入りましょう。Jupyter notebook](https://colab.research.google.com/drive/1NbL9xVoVR2BTH6ORPTf2DXfn8AaVcdrM?usp=sharing)では、Python 3.8.5を使用しています。コードを分解するための手順を説明する。
それではどうぞ:
モジュールのインポート
np として numpy をインポート
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
データセット
Scikit-learnは、合成データセットを作成するトレーニングサンプルに使用できます。
X, y = make_blobs(n_samples = 4000, n_features = 3, centers = 3 ,cluster_std = 2, random_state = 80)
X
array([ 7.60190561, 4.86336321, 6.97616573]、
[ 5.97809745, 7.69910922, 2.77419701],
[-4.36024844, -2.23247572, -5.29113293],
...,
[-8.22252297, -6.88609334, -6.52102135],
[-3.96254707, -5.27559922, -2.70880022],
[-4.25865881, -1.67791521, -3.70523373]])
y
array([1, 1, 2, ..., 2, 2, 2])
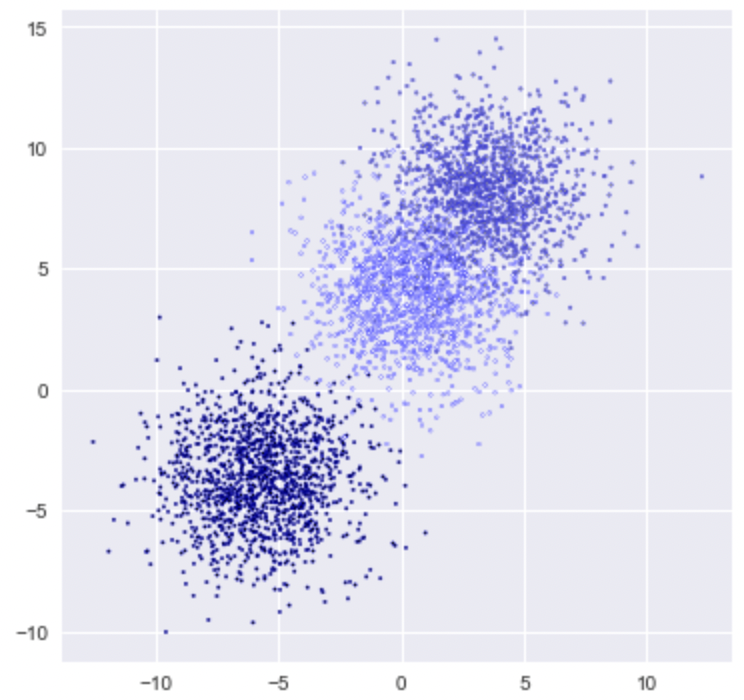
プロット
plt.figure(figsize = (6,6))
plt.scatter(X[:,0], X[:,1], c=y, marker= '.', s=10, edgecolors='blue')
plt.show()
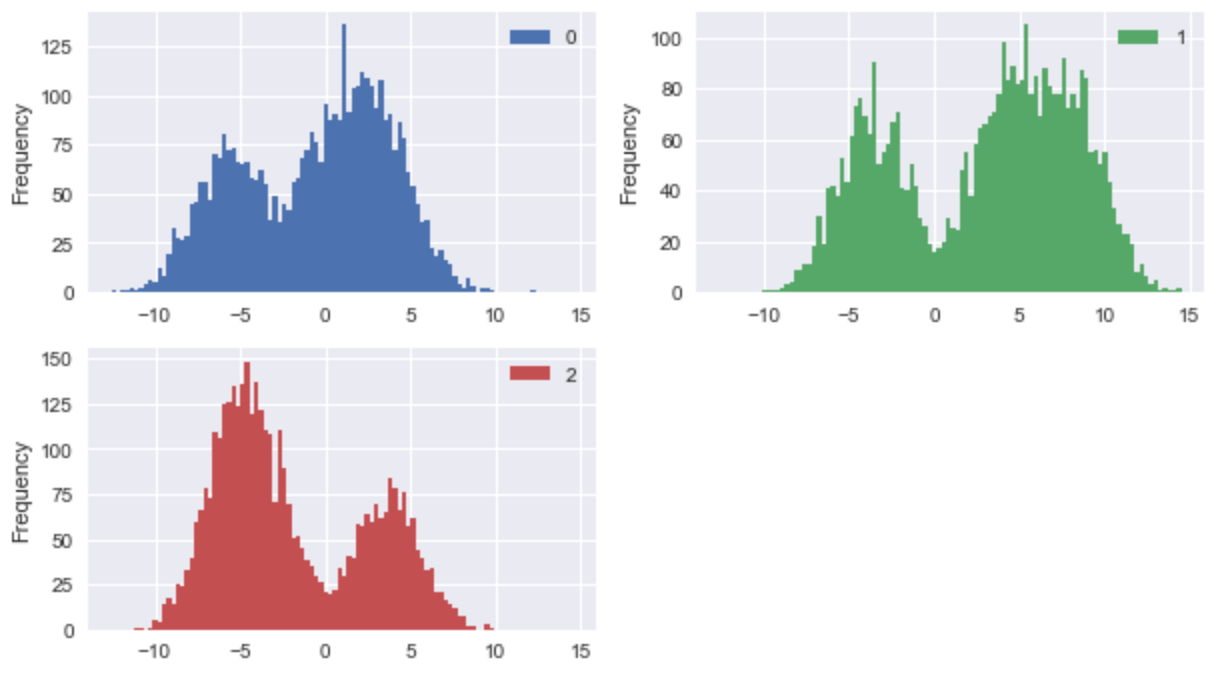
df = pd.DataFrame(X)
df.head()
plt.rcParams['figure.figsize']=(10,15)
df.plot(kind='hist', bins=100, subplots=True, layout=(5,2), sharex=False, sharey=False)
plt.show()
K-最近傍分類器の実装
K値の計算は状況によって大きく異なる。Scikit-Learn ライブラリを使用する場合の K のデフォルト値は 5 で、デフォルトの 距離メトリック はユークリッドです。
高い K 近傍精度を得るためのモデルのチューニング
from sklearn.model_selection import GridSearchCV
param_grid = {'n_neighbors':np.arange(1,4)}.
knn = KNeighborsClassifier()
knn_cv= GridSearchCV(knn,param_grid,cv=5)
knn_cv.fit(X,y)
print(knn_cv.best_params_)
print(knn_cv.best_score_)
{'n_neighbors': 3}.
0.9887499999999999
#訓練とテストの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 80)
# モデルをインスタンス化する
knn = KNeighborsClassifier(n_neighbors=3)
# モデルをトレーニングセットにフィットさせる
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print('Model accuracy score: {0:0.4f}'. format(accuracy_score(y_test, y_pred)))
モデル精度スコア: 0.9890..
精度は98.90%であり、非常に良好である。近傍探索の数を1から4まで増やしたところ、k=3で最も良い結果が得られました。
KNN アルゴリズムの重要な利点
1.時間効率
Kニアレスト・ネイバー・モデルは、データそのものが将来の学習段階の予測の基準となるモデルであるため、学習期間を必要としません。その結果、時間効率が高く、利用可能なデータに対してランダムなモデリングを迅速に行うことができます。
2.チューニングが簡単
KNNはK値と距離メトリックの2つのハイパーパラメータしか必要としないため、他の機械学習アルゴリズムよりもチューニングが簡単である。
3.適応が容易
ほとんどの分類器アルゴリズムは、二値分類問題に対しては簡単に実装できるが、多クラス問題に対しては実装に余分な労力を必要とする。これに対して、KNNは余分な労力をかけずに多クラス問題に適応します。
KNN アルゴリズムの欠点
1.高次元データ
各データインスタンス間の距離を計算することは法外なコストがかかるため、KNNは大きなデータや高次元データではうまく機能しない。
2.欠損データ
KNNはノイズに敏感なデータや欠損データがある場合にはうまく機能しない。
3.アンバランスなデータ
データがアンバランスな場合も、K Nearest Neighborsはうまく機能しません。
4.次元の呪い
次元の呪い](https://en.wikipedia.org/wiki/Curse_of_dimensionality)のため、KNNはオーバーフィッティングを起こしやすい。これを防ぐために特徴選択と次元削減テクニックが使われるが、Kの値はモデルの動作に影響を与える可能性がある。
KNNをいつ使うか、そしてなぜ使うのか?
ここでMはデータの次元、Nはトレーニングデータセットのサイズまたはインスタンス数です。しかし、それでもなお、これに対処し、より効率的にするために、データを整理する複数の特殊な方法がある。
さらに、欠損データやノイズを除去し、データセットのバランスを確保するために、いくつかの前処理技術を使用することができる。このため、KNNは最も広く使われているアルゴリズムの1つである。
結論:ベクトル・データベース
コサイン関数と K Nearest Neighbor アルゴリズムを使用することで、2つのアイテムセットがどの程度似ているか、または異なっているかを判断し、その情報を使用して分類することができます。
高次元ベクトル空間では、コサイン関数はオブザベーション間の類似度 または距離を計算します。これらの高次元データは、従来のデータベースで使用すると計算処理が遅くなるため、ベクトル・データベースに格納することができる。
これは多くのベクトルデータベースの使用例の一つである。特に「ベクトル・データベースって何だろう」(https://zilliz.com/learn/what-is-vector-database)と疑問に思っている人、そしてそれを探求するかどうか迷っている人には、まさにZillizの出番である。
ベクトル・データベース](https://zilliz.com/blog/what-is-a-real-vector-database)がAIの現代における時代のニーズであることは否定できない。Zillizは、特にベクトル類似検索を活用するAI/MLアプリケーションを構築する企業に対して、その取り扱いに関する課題に対するワンストップ・ソリューションを提供します。
読み続けて

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

VidTok: Rethinking Video Processing with Compact Tokenization
VidTok tokenizes videos to reduce redundancy while preserving spatial and temporal details for efficient processing.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.