




DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
The AI monopoly is shifting. DeepSeek-VL2 offers GPT-4o-level vision-language intelligence at a fraction of the cost, showing that open models aren't just catching up. They are leading the way. Could this mark the end of expensive, closed AI?
Large Vision-Language Models (VLMs) have emerged as a transformative force in Artificial Intelligence. They extend the remarkable capabilities of large language models (LLMs) to process visual and textual information seamlessly. They tackle tasks like answering visual questions and document analysis. However, VLMs face the challenge of high computational costs. They also struggle with high-resolution images and varied aspect ratios, largely due to the quadratic computational scaling typically associated with increasing image resolutions.
DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models, addresses these issues. It introduces a dynamic, high-resolution vision encoding strategy and an optimized language model architecture that enhances visual understanding and significantly improves the training and inference efficiency. Another key advancement is the refined vision language data construction pipeline that boosts the overall performance and extends the model's capability in new areas, such as precise visual grounding.
DeepSeek-VL2 demonstrates superior capabilities across various tasks, including but not limited to visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. Evaluated on commonly used multimodal benchmarks,
DeepSeek-VL2 achieves similar or better performance than the state-of-the-art model, with fewer activated parameters. Notably, on OCRBench, it scores 834, outperforming GPT-4o 736. It also achieves 93.3% on DocVQA for visual question-answering tasks. Qualitative evaluation highlights its ability to reason across multiple images and generate coherent visual narratives.
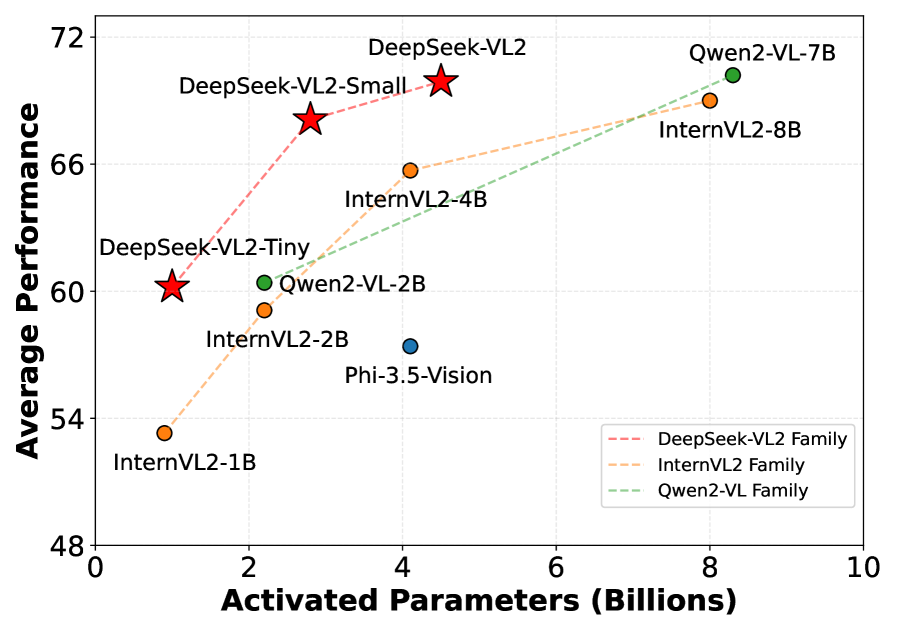
Average performance vs. activated parameters among different open-source models | Source
This blog discusses DeepSeek-VL2’s technical advances in vision and language. We analyze its benchmark results and efficiency improvements in detail and go over its role in democratizing high-performance multimodal AI.
DeepSeek-VL2: Core Model Architecture
At the core of DeepSeek-VL2 is a well-structured architecture built to enhance multimodal understanding. By combining a Mixture-of-Experts (MoE) framework with an advanced Vision-Language (VL) processing pipeline, DeepSeek-VL2 efficiently integrates visual and textual information.
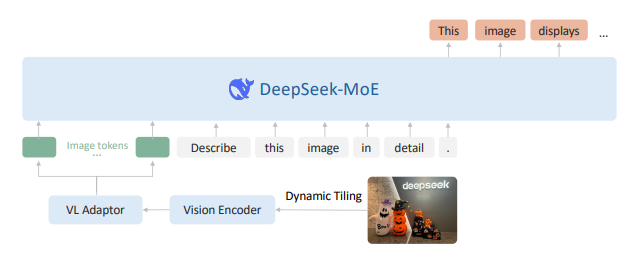
Architecture overview of DeepSeek-VL2 | Source
Below is the explanation of the core modules of DeepSeek-VL2:
Vision Encoder
The vision encoder is designed to extract high-resolution visual features efficiently. The vision encoder in DeepSeek-VL2 uses a dynamic tiling strategy designed for high-resolution image processing. The approach is to split a high-resolution into tiles to enable efficient processing of different high-resolution images with varying aspect ratios.
DeepSeek-VL2 uses SigLIP-SO400M-384 vision encoder. The vision encoder operates at a base resolution of 384x384. To accommodate high-resolution images of various aspect ratios, the image is first resized and split into tiles of 384x384 pixels. We define a set of candidate resolutions CR:
CR = {(m .384, n .384) | mN, n N, 1m,n,mn9}
where m:n represents the aspect ratio.
The padding required to resize each input image to each candidate is calculated, and the candidate with the minimum padding is selected. Minimizing padding reduces computational overhead and ensures more image content is retained, improving processing efficiency. The resized image is divided into mini local tiles measuring 384 × 384 and one global thumbnail tile. The SigLIP-SO400M-384 vision encoder processes all ( 1+mini ) tiles, producing 729 visual embeddings of 1152 dimensions per tile.
Vision-Language (VL) Adaptor
After visual feature extraction, the vision-language adaptor restructures and compresses tokens to bridge the gap between visual and textual representations. This step enables seamless visual and textual data integration by introducing special tokens to encode spatial relationships.
First, a 2×2 pixel shuffle operation reduces the spatial dimensions of each tile’s tokens from 27×27 to 14×14=196 tokens. The adaptor then inserts special tokens to encode spatial relationships between tiles.
Global Thumbnail: For the global thumbnail tile, 14
<tile_newline>tokens are added at the end of each row, resulting in a total number of 14 rows × 15 tokens = 210 tokens.Local Tiles: For the mn local tiles arranged in a grid (mi .14, ni .14), the system appends mi .14
<tile_newline>tokens to mark the end of each row of all the local tiles.Separator: A
<view_separator>token is added between global and local tiles.
This structured output ensures the model understands the spatial layout of the tiled image. The final visual token sequence 210+1+ mi⋅14 × (ni⋅14 +1) is projected into the LLM’s embedding space via a two-layer MLP.

Illustration of dynamic tiling strategy in DeepSeek-VL2 | Source
DeepSeekMoE Large Language Model
DeepSeek-VL2's language backbone is built on a Mixture-of-Experts (MoE) model augmented with Multi-head Latent Attention (MLA). MLA boosts inference efficiency by compressing the Key-Value cache into a latent vector, reducing memory overhead and increasing throughput capacity. This allows DeepSeek-VL2 to handle long-context sequences more effectively while maintaining computational efficiency.
The MoE architecture enables efficient inference through sparse computation, where only the top six experts are selected during inference. This significantly reduces computational costs while preserving performance. During training, a global bias term is introduced for each expert to improve load balancing and optimize learning efficiency.
DeepSeek-VL2 comes in three model variants, each with a different number of activated parameters and experts:
DeepSeek-VL2-Tiny: 1.0B parameters, 64 experts
DeepSeek-VL2-Small: 2.8B parameters, 64 experts
DeepSeek-VL2: 4.5B parameters, 72 experts
Training Methodology
DeepSeek-VL2 uses a three-stage training pipeline that balances multimodal understanding with computational efficiency. The overall process is divided into three phases:
Vision-Language Alignment
Vision-Language Pre-training
Supervised Fine-Tuning

High-level phases in the training pipeline
Before discussing the training pipeline, we will learn about the data construction and datasets used in different training phases.
Data Construction
A comprehensive Vision-Language dataset from diverse sources was built for DeepSeek-VL2. In this section, we will describe the data used in different stages of the training pipeline.
Vision-Language Alignment Data
In the VL Alignment stage, the focus is on bridging visual features with textual embeddings. The ShareGPT4V dataset is used for this initial phase. This dataset comprises approximately 1.2 million caption and conversation samples.
Vision-Language Pre-training Data
Pre-training data combines vision-language (VL) and text-only data to balance VL capabilities and test-only performance. In this stage, about 70% of the data comes from vision-language sources, and the remaining 30% is text-only data sourced from the LLM pre training corpus.
The categories of VL data used are described here:
Interleaved Image-Text Data: Open-source datasets like WIT, WikiHow, and samples from OBELICS provide varied image-text pairs for general real-world knowledge.
Image Captioning Data: Initial experiments with open-source datasets showed inconsistent quality (e.g., mismatched text, hallucinations). A comprehensive image captioning pipeline was used that considers OCR hints, metadata, and original captions as prompts to recaption the images with an in-house model. This curated recaptioned data was used in training.
Optical Character Recognition (OCR) Data: Public datasets such as LaTeX OCR and 12M RenderedText were combined with extensive in-house OCR data covering diverse document types.
Visual Question-Answering (QA) Data: Visual QA data consist of four categories: general VQA (from DeepSeek-VL), document understanding (PubTabNet, FinTabNet, Docmatix), web-to-code/plot-to-Python generation (Websight and Jupyter notebooks, refined with DeepSeek V2.5), and QA with visual prompts (overlaying indicators like arrows/boxes on images to create focused QA pairs).
- Visual Grounding Data: A dataset was constructed for visual grounding. For each image’s object detection annotations, the data was structured as follows using special tokens <|ref|>, <|/ref|>, <|det|>, <|/det|>:
Prompt: Locate <|ref|>
<|/ref|> in the given image. Response: <|ref|>
<|/ref|><|det|>[[x1, y1, x2, y2],...]<|/det|>
- Grounded Conversation Data: Conversational dataset where prompts and responses include special grounding tokens to associate dialogue with specific image regions.
Supervised Fine-Tuning Data
The Supervised Fine-Tuning stage refines the model’s instruction-following and conversational performance. The aspects covered include:
General Visual Question-Answering: Public visual QA datasets often suffer from short responses, poor OCR, and hallucinations. A new dataset was generated by regenerating answers using original questions, images, and OCR data.
OCR and Document Understanding: Used cleaned existing OCR datasets by removing samples with poor OCR quality.
Table and Chart Understanding: Enhanced table-based QA data by regenerating responses based on original questions to create high-quality data.
Reasoning, Logic, and Mathematics: To improve clarity, public reasoning datasets are enhanced with detailed processes and standardized response formats.
Textbook and Academic Questions: Internal college-level textbook collections focused on academic content across multiple disciplines.
Web-to-code and Plot-to-Python Generation: In-house datasets were expanded with open-source datasets after response generation to improve quality.
Visual Grounding: Data with object detection annotations guides the model to locate and describe objects precisely.
Grounded Conversation: Conversational datasets incorporate grounding tokens to link dialogue with image regions for improved interaction.
Text-Only Datasets: Text-only instruction-tuning datasets are also used to maintain the model's language capabilities.
Training Pipelines
Before starting training, the process is divided into defined stages. This structure ensures smooth transitions between alignment, pre-training, and fine-tuning. Initially, the vision encoder and vision-language adaptor MLP are trained while the language model remains fixed. Later, all model parameters are unfrozen for extensive pre-training, and finally, the model is fine-tuned using supervised data. The loss is computed solely on text tokens in each stage to prioritize learning visual context.
- Vision-Language Alignment: The VL Alignment phase connects visual features with textual embeddings. The training uses the ShareGPT4V dataset, which consists of approximately 1.2 million image-text pairs. During this phase, the language model remains frozen. Only the vision encoder and the adaptor are trained, using a lightweight MLP connector to merge visual and text features. This phase adjusts fixed-resolution encoders to handle dynamic high-resolution inputs.
- Vision-Language Pre-training: In the VL Pre-training phase, all parameters are unfrozen for optimization. The data mix comprises 70% vision-language data and 30% text-only data. The VL data includes interleaved image-text pairs that cover tasks such as OCR and document analysis. The text-only data comes from the LLM pretraining corpus. The training uses around 800 billion image-text tokens to build joint representations for visual and textual inputs.
- Supervised Fine-Tuning: During Supervised Fine-Tuning, the model’s instruction-following and conversational capabilities are refined. This phase uses curated question-answer pairs from public datasets and in-house data. Multimodal dialogue data is combined with text-only dialogues from DeepSeek-V2, and system/user prompts are masked so that supervision applies only to answers and special tokens.
Hyperparameters and Infrastructure
The hyperparameter configuration for DeepSeek-VL2 is detailed in the given table. During training, different stages use tailored settings. For instance, in Stage 1 for DeepSeek-VL2-Tiny, the learning rate is set to 5.4×10⁻⁴, while in Stage 3, it drops to 3.0×10⁻⁵. The Step LR Scheduler divides the learning rate by √10 at 50% and 75% of the total training steps. A fixed multiplier of 0.1 is applied to the vision encoder’s learning rate. Cosine learning rate schedulers are used in the early stages, with a constant schedule in the final stage. Additional settings include a weight decay of 0.1, gradient clipping at 1.0, and the AdamW optimizer configured with β₁ = 0.9 and β₂ = 0.95.

Hyperparameters for training DeepSeek-VL2 | Source
Training is carried out on the HAI-LLM platform, a lightweight system designed for large models. The pipeline employs fine-grained layer division for the vision encoder to ensure load balancing across GPUs, which helps prevent pipeline bubbles. Image tile load balancing is also performed across data parallel ranks to handle variability introduced by the dynamic resolution strategy.
Furthermore, tensor parallelism and expert parallelism techniques are incorporated to maximize efficiency. Combined with meticulous hyperparameter tuning, these infrastructure choices allow DeepSeek-VL2 to process billions of training tokens efficiently while maintaining robust multimodal performance.
DeepSeek-VL2 was trained in 7/10/14 days using a cluster of 16/33/42 nodes, each equipped with 8 NVIDIA A100 GPUs.
Evaluation
We now examine DeepSeek-VL2's performance using standard benchmarks and qualitative tests. The following sections outline the evaluation results and compare DeepSeek-VL2 with the state-of-the-art models.
Benchmarks
DeepSeek-VL2 is evaluated on a range of commonly used benchmarks. These include DocVQA, ChartQA, InfoVQA, TextVQA, RealWorldQA, OCRBench, AI2D, MMMU, MMStar, MathVista, MME, MMBench (and MMBench-V1.1), and MMT-Bench. In addition, the model’s grounding capability is tested on the RefCOCO, RefCOCO+, and RefCOCOg benchmarks. These tests span tasks from document understanding and chart interpretation to real-world problem solving, providing a comprehensive measure of the model’s performance.
Comparison with State-of-the-Art
DeepSeek-VL2 was compared with several state-of-the-art vision-language models such as LLaVA-OV, InternVL2, DeepSeek-VL, Qwen2-VL, Phi-3.5-Vision, Molmo, Pixtral, MM1.5, and Aria-MoE on the multimodal understanding benchmarks. In grounding tasks, DeepSeek-VL2 model outperforms others like Grounding DINO, UNINEXT, ONE-PEACE, mPLUG-2, Florence-2, InternVL2, Shikra, TextHawk2, Ferret-v2, and MM1.5.
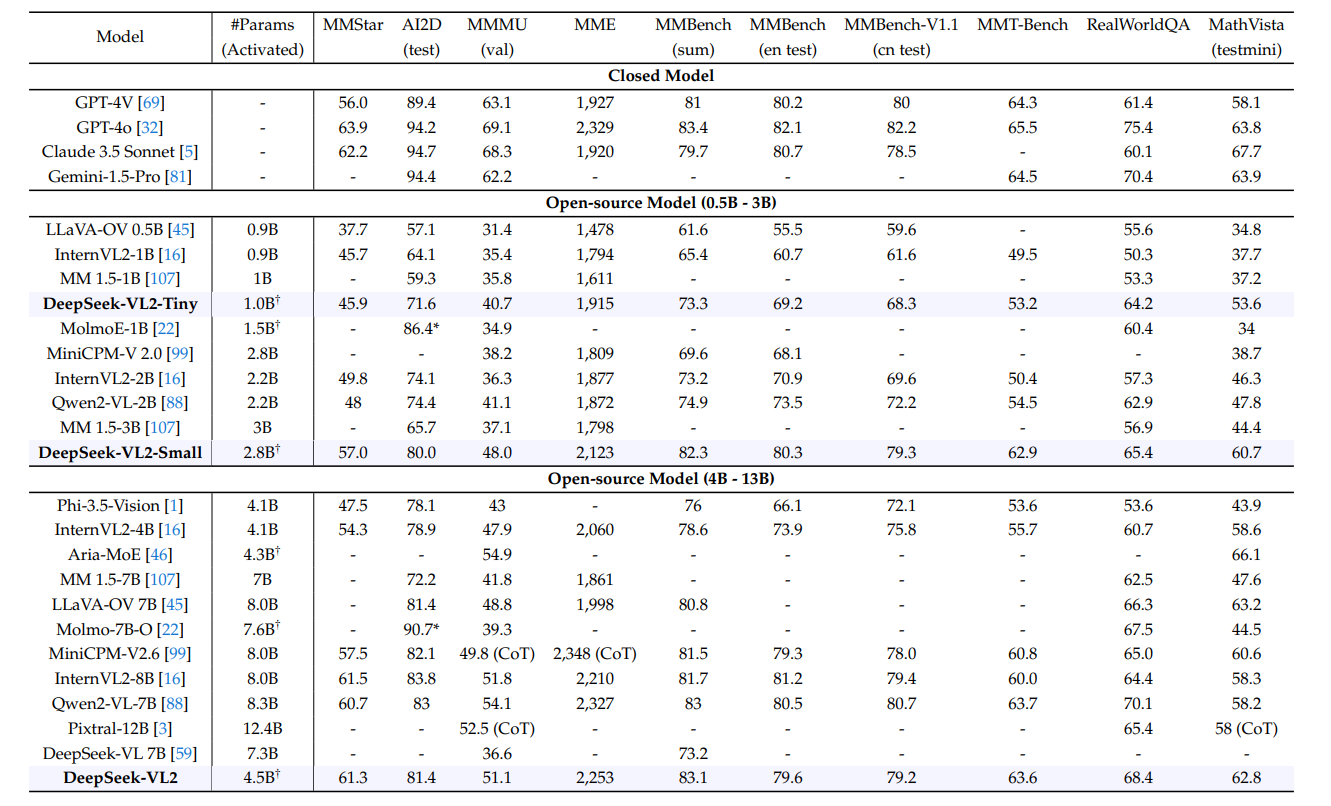
Comparison with state-of-the-art models on general QA and math-related multimodal benchmarks | Source
DeepSeek-VL2 achieves similar or better performance with fewer activated parameters. It demonstrates competitive performance across diverse multimodal benchmarks, matching or exceeding larger models like Qwen2-VL-7B (8.3B) and InternVL2-8B (8.0B) in tasks such as MMBench (83.1 vs. 85.0) and MME (2,253 vs. 2,327).
Despite its smaller activated parameter count, it approaches GPT-4o’s performance on MMStar (61.3 vs. 63.9) and outperforms most open-source models in OCR-heavy tasks like AIDD (81.4). The model’s efficiency, enabled by its MoE architecture, balances capability and computational cost effectively.
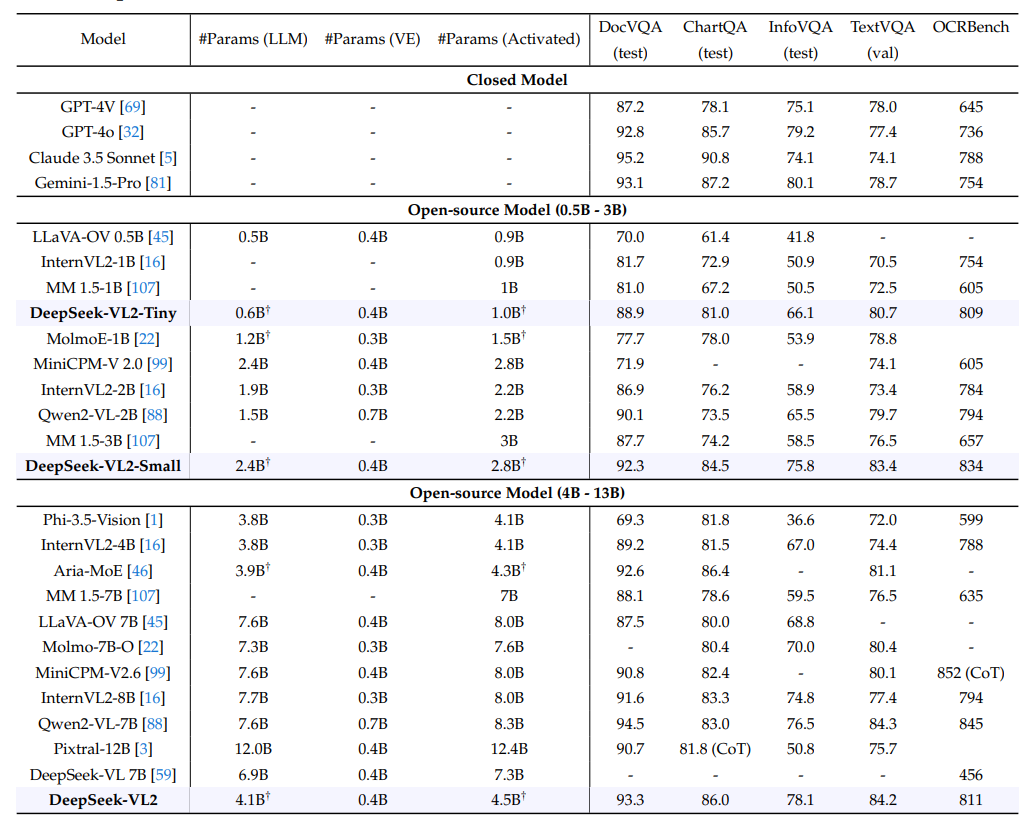
Comparison with state-of-the-art models on OCR-related multimodal benchmarks | Source
DeepSeek-VL2 achieves competitive performance in OCR tasks, matching or surpassing larger models like Qwen2-VL-7B in TextVQA (84.2 vs. 84.3) and outperforming GPT-4o in DocVQA (93.3 vs. 92.8). Its ChartQA (86.0) and InfoVQA (78.1) scores exceed most open-source peers, while its efficiency bridges the gap with closed models like Claude 3.5 Sonnet (OCRBench: 811 vs. 788). This demonstrates robust OCR capabilities despite its compact architecture.
Qualitative Study
The qualitative study demonstrates DeepSeek-VL2’s capabilities across various tasks. Key areas include:
- General Visual Question Answering: The model provides detailed responses, accurately describes dense image content, and recognizes landmarks in both English and Chinese. It has multifaceted capabilities, including recognizing landmarks, image-based poetry composition, answering questions about general knowledge, understanding charts, recognizing text, and more.
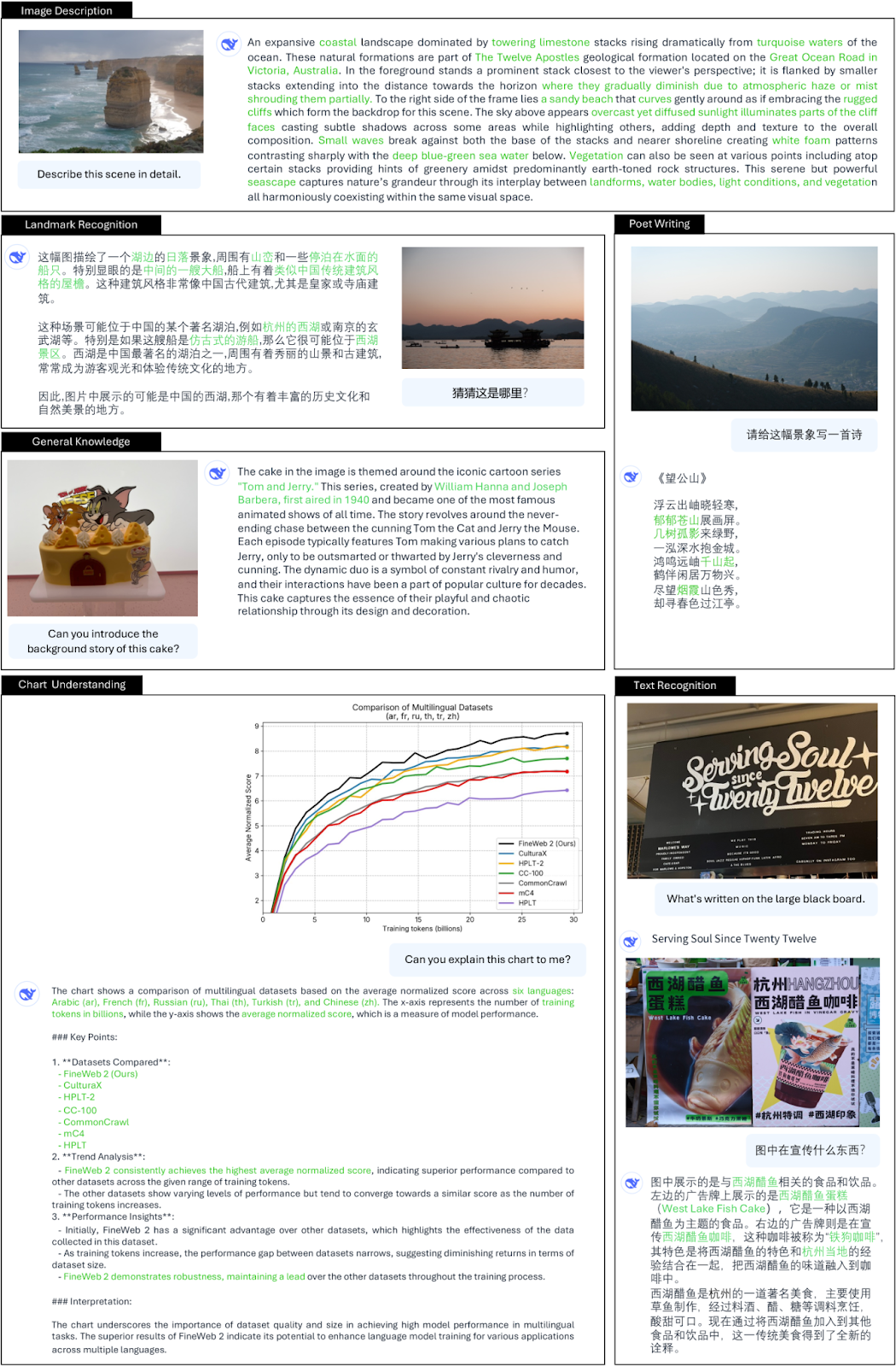
The general question-answering capability of DeepSeek-VL2 | Source
- Multi-Image Conversation: It effectively analyzes the associations and differences among multiple images while enabling simple reasoning by integrating the content of several images. For example, it can consider how to prepare a dish based on images of certain ingredients.
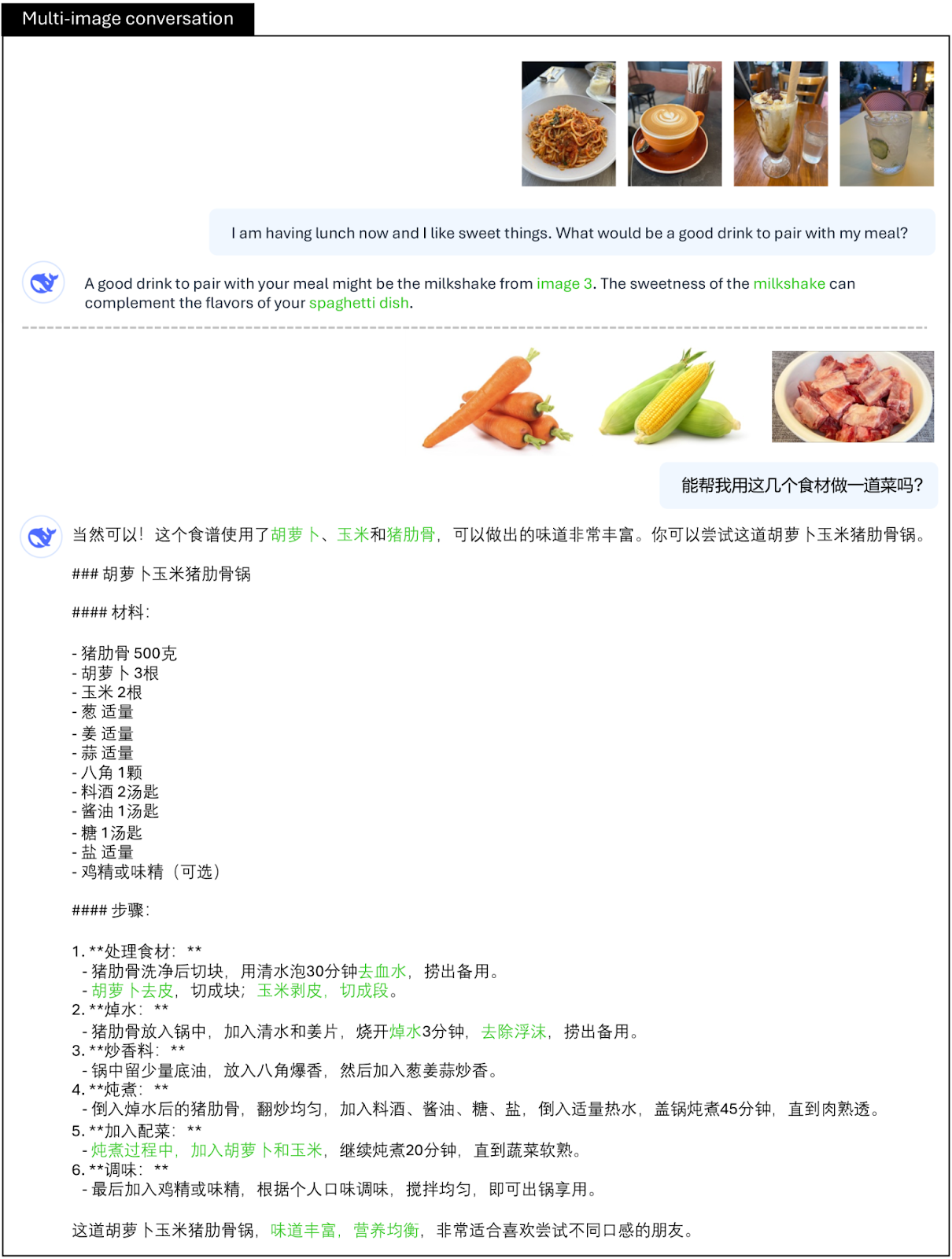
Multi-image conversation capability of DeepSeek-VL2 | Source
- Visual Storytelling: DeepSeek-VL2 can generate creative narratives based on a series of images while maintaining context and coherence. Its storytelling reflects an understanding of temporal progression and scene transitions, adding depth to the generated narratives.

Visual storytelling capability of DeepSeek-VL2 | Source
- Visual Grounding: The model successfully identifies and locates objects in images, generalizing them from natural scenes to varied scenarios such as memes and anime. It demonstrates robust performance even when objects are partially obscured or presented in challenging conditions.
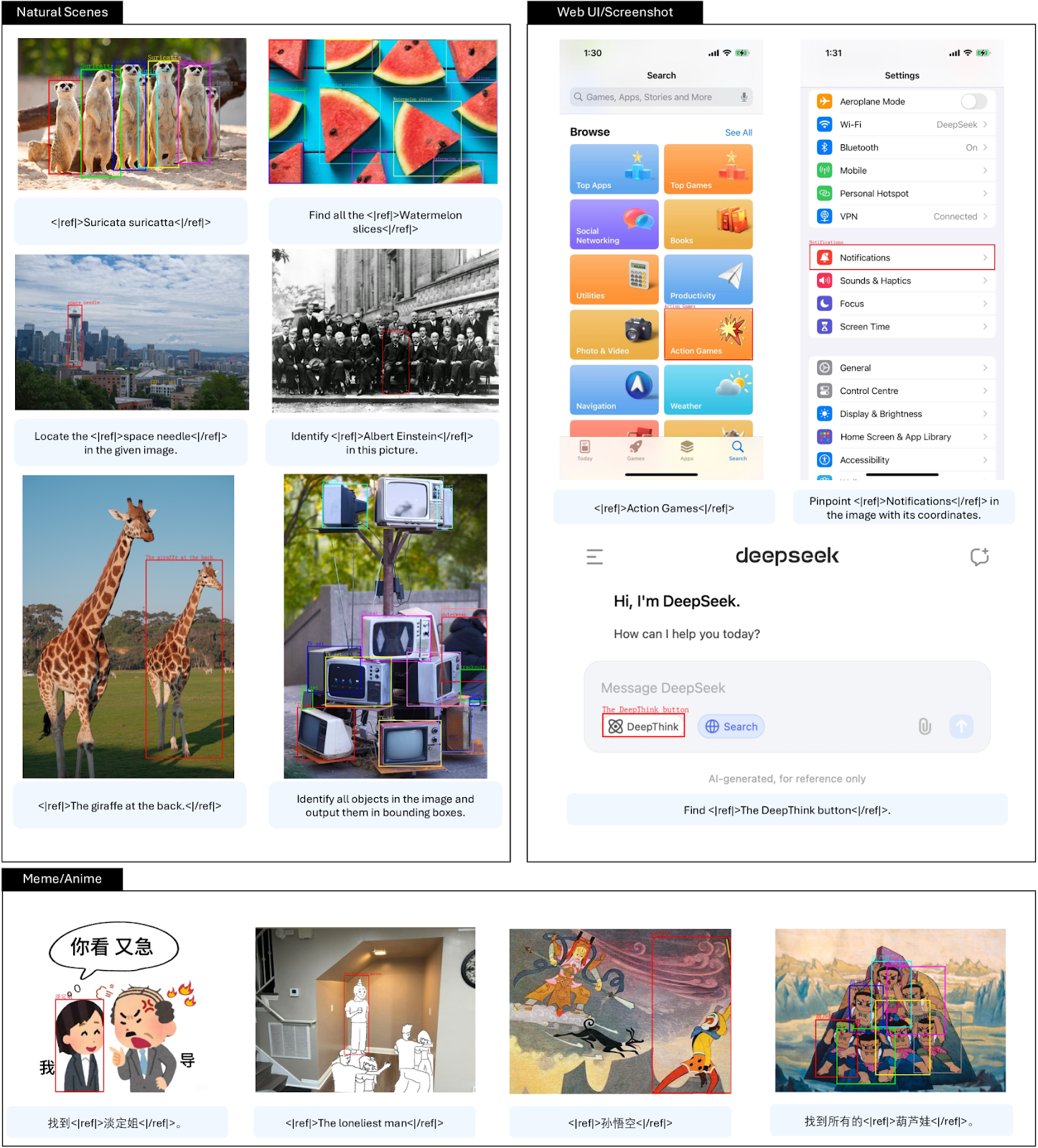
Visual grounding ability of DeepSeek-VL2 | Source
- Grounding Conversation: With the use of special grounding tokens <|grounding|>, the model refers to key objects with precise location details, enhancing its interactive capabilities. Its grounded responses facilitate practical applications in real-world interactive systems.
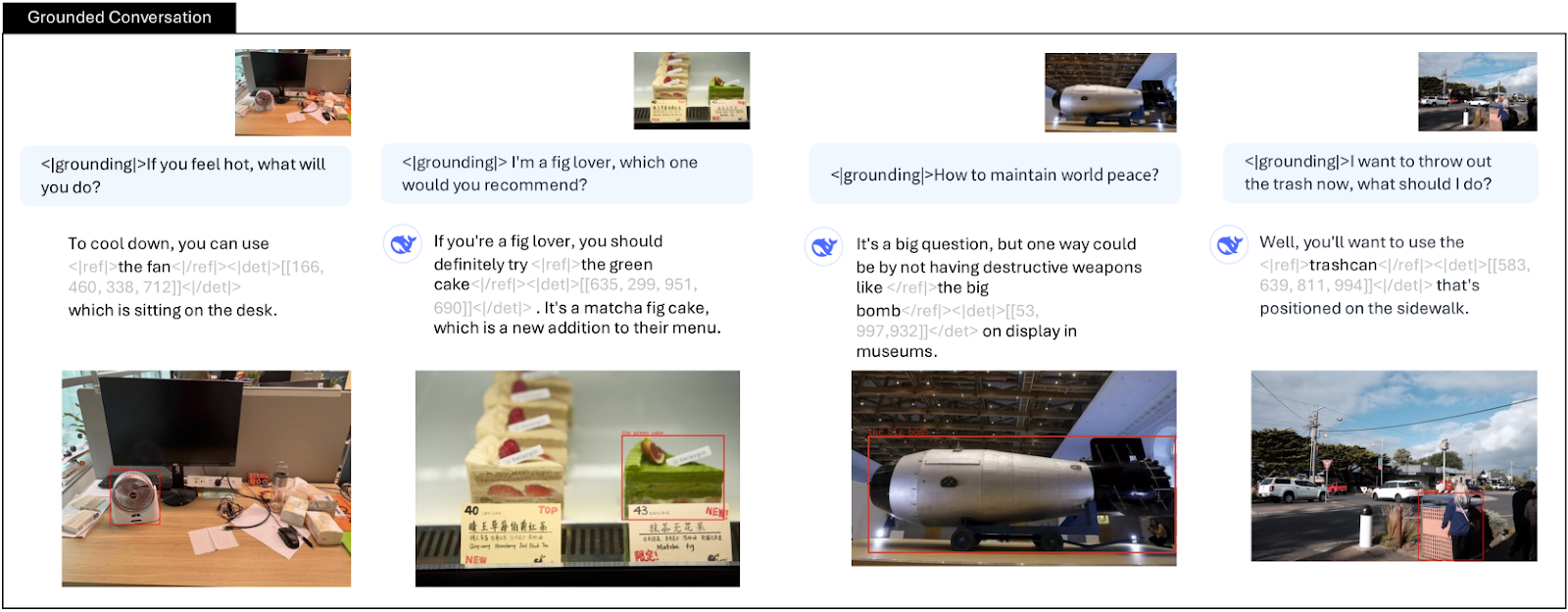
Grounded conversation with DeepSeek-VL2 | Source
Key Findings
- Efficiency and Scalability: DeepSeek-VL2 attains competitive results with fewer activated parameters thanks to its efficient MoE design and dynamic tiling approach. This balance between performance and resource usage enables deployment in environments with limited computational capacity.
- Robust Multimodal Understanding: The model excels in tasks spanning OCR, document analysis, and visual grounding. Its ability to integrate visual and textual information results in high accuracy across diverse applications.
- Enhanced Instruction-Following and Conversational Skills: The model shows marked improvements in generating coherent and context-aware responses through supervised fine-tuning. This refinement bolsters its performance in interactive and conversational settings.
- Real-World Applicability: The strong performance observed in both quantitative benchmarks and qualitative studies indicates that DeepSeek-VL2 is well-suited for practical applications, such as automated document processing, virtual assistants, and interactive systems in embodied AI.
Potential Future Research Directions
DeepSeek-VL2 is an enhanced version of MoE-based vision-language models available in three sizes: 3B, 16B, and 27B total parameters, with 1.0B, 2.8B, and 4.5B activated. This smart design makes both training and inference more efficient. It allows the smallest model to run on a single GPU with just 10 GB of memory, while larger variants require 40 GB and 80 GB.
One of the standout features is its dynamic tiling strategy, which adeptly processes high-resolution images across various aspect ratios. By releasing the code and pre-trained models publicly, DeepSeek-VL2 will inspire further research and innovative applications at the exciting crossroads of vision and language.
There are several areas where DeepSeek-VL2 could be improved.
- Context Window: Currently, the model supports only a few images per chat session. Future updates could extend the context window to allow richer multi-image interactions.
- Robustness to Image Quality: The model sometimes faces challenges with blurry images or unseen objects. Addressing these issues could improve its reliability in diverse scenarios.
- Reasoning Capabilities: While the model performs well in visual perception and recognition, its reasoning abilities can be enhanced. Strengthening this aspect may broaden its real-world application potential.
Further Resources
- Research Paper: DeepSeek-VL2: Mixture-of-Experts Vision-Language Models

Keep Reading

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.