




Full RAG: A Modern Architecture for Hyperpersonalization
Personalization is the key to long-term customer retention for many user-centric products. For example, Netflix or Disney can ensure user satisfaction through personalized movie recommendations; food delivery apps can suggest restaurants and dishes based on past orders, etc. Artificial Intelligence provides different techniques to leverage the customer's historical data and provide personalization in products.
Mike Del Balso, CEO and Co-founder of Tecton, recently delivered a talk on using the RAG architecture to improve the personalization of AI Recommendation engines at the Unstructured Data Meetup hosted by Zilliz.
Mike shared an interesting fact he had read in a consulting report: “There’s going to be 5 trillion dollars of value added to global GDP deriving from AI-powered personalization.” He also presented an architecture based on Retrieval Augmented Generation(RAG) to achieve hyper-personalization.
This post will recap his key insights into AI-powered personalizations and how companies can power their products with artificial intelligence.
Watch the replay of Mike’s Talk
Personalization with Generative AI Models
Mike begins with a use case example: building a product similar to Booking.com or MakeMyTrip but with hyper-personalized travel recommendations.
Large Language Models (LLMs) like GPT are trained on vast text corpora and can generate travel recommendations. For example, if we query an LLM, “Where should I go this summer ?” we will get responses based on the most popular summer destinations, like Paris or Tokyo. But, we need a way to tailor these recommendations to individual customers.
Two techniques are available to improve your recommendation model: fine-tuning and prompt engineering.

While these techniques can make the model’s response more relevant based on the available training data, they do not provide a way to give the customer’s input data. Full-RAG is a method that can solve this problem. Before we understand what Full-RAG is and how it works, let’s recap how traditional RAG works.
Introduction to RAG
Retrieval Augmented Generation (RAG) is a technique that improves the response of large language models regarding quality and relevance. A RAG Engine usually consists of two key components: a Retriever and a Generator. A retriever combines an embedding model and a vector database like Milvus or Zilliz Cloud, and a generator is the LLM.
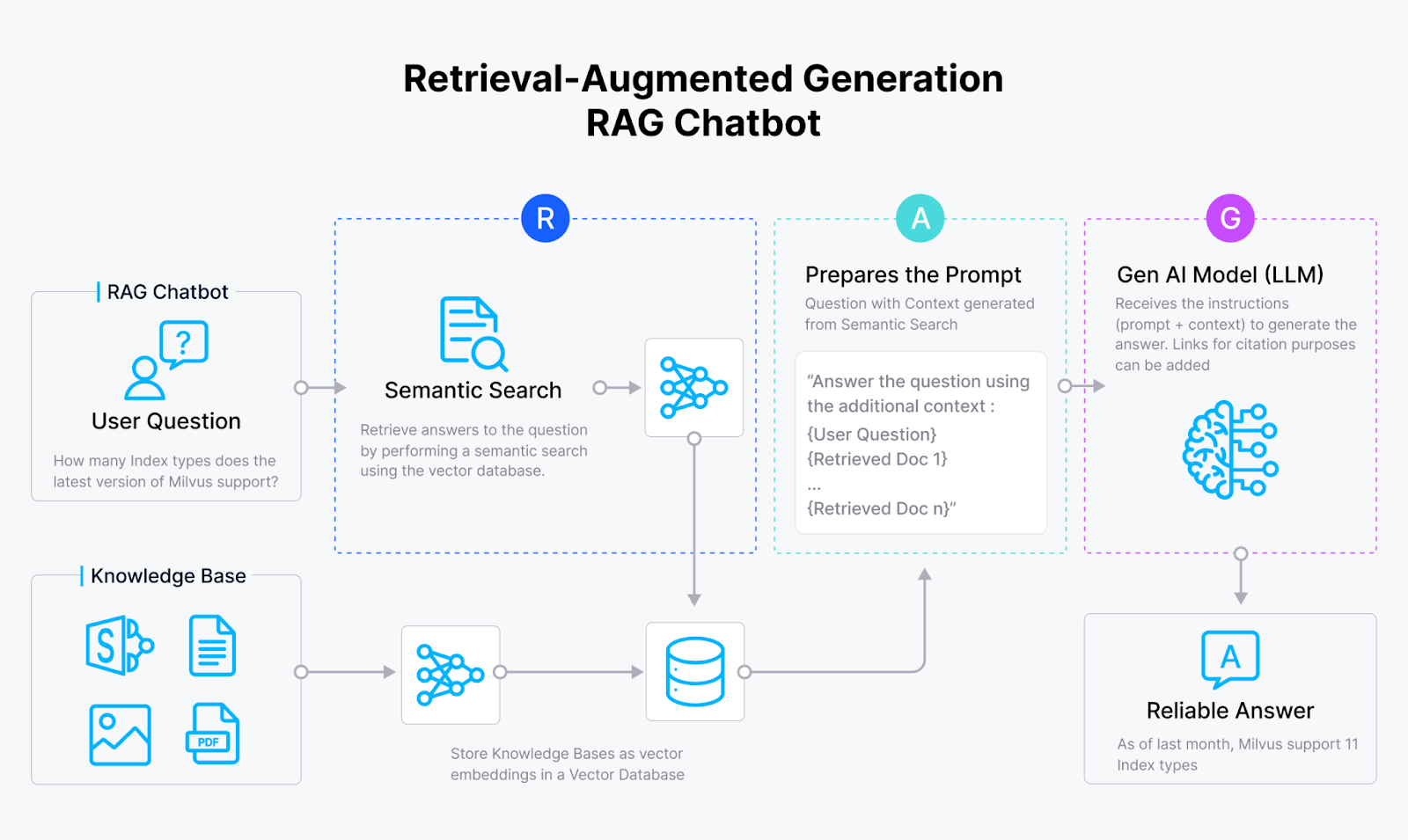
At the retrieval stage, we search through the vector database that stores all the documents and select the most relevant ones. The Top-K documents or candidates are selected and then provided as input to the Generative AI model. The model generates a coherent response using the query and Top-K candidates.
The RAG pipeline below explains how traditional RAG works.
All the documents are transformed into vector embeddings and stored in a vector database.
The user query is also converted into a vector embedding.
We use this vector to retrieve the most similar candidates from the vector database.
These top candidates, like Paris and Tokyo, are sent to an LLM, which generates the response.
However, the top candidates retrieved here do not have context on the particular user's likes and dislikes, so they are “Uncontextualized Candidates.”
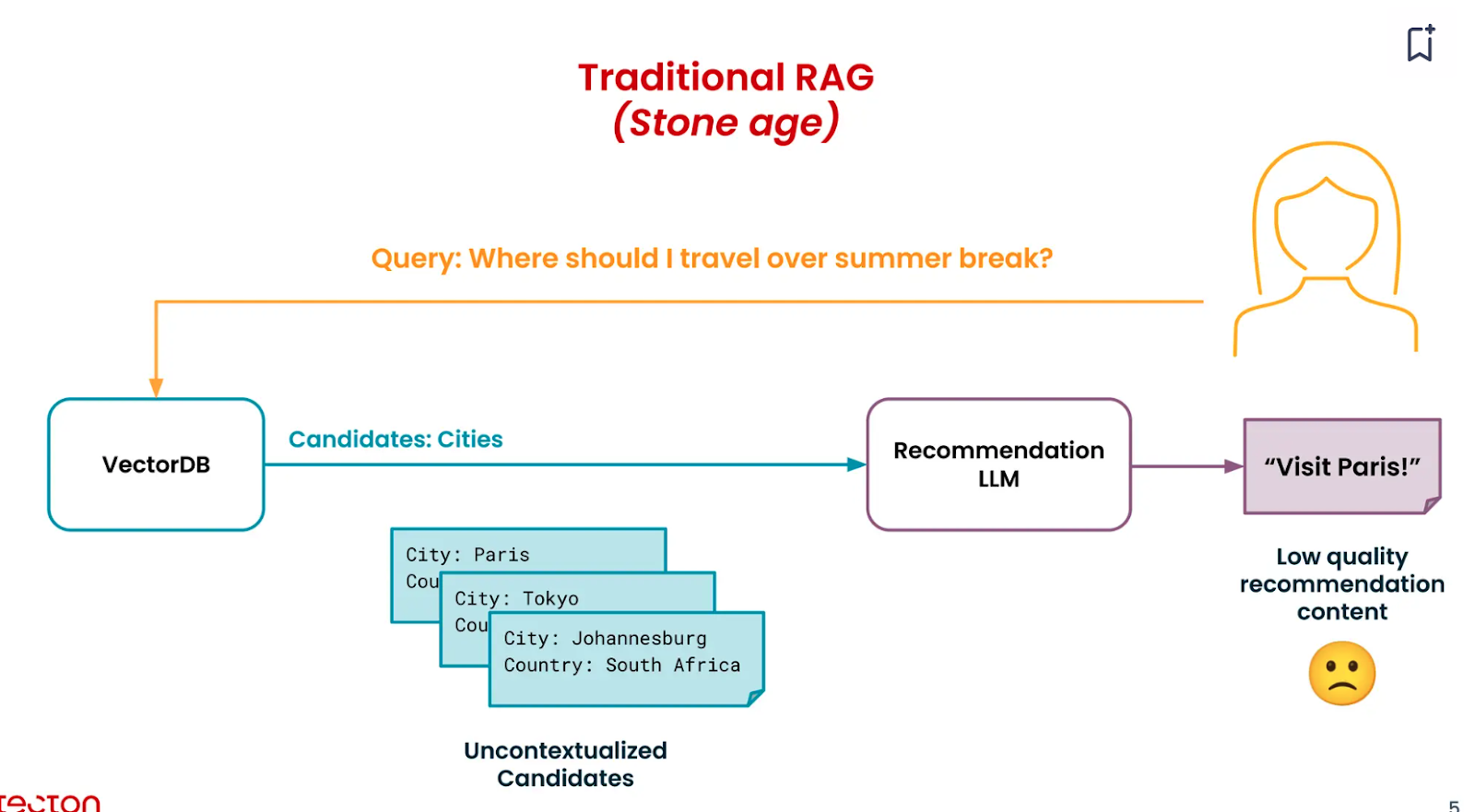
Full-RAG: Adding Context in the Retrieval Pipeline
Since the retrieved candidates in a basic RAG pipeline are uncontextualized, we need to add that context for better answers. The aim is to build an engine with high context and expertise.
Mike emphasizes how providing context can enrich retrieved information: “_Context is the relevant information that AI Models use to understand a situation and make decisions.”

In the previous use-case example of building an AI Travel Agent, we can add context to the model in two ways:
1: Add Context of Candidates (Locations): While recommending a city, the model should be aware of the details of the dynamics. For example, the current weather, type of activities, famous local cuisines, an approximate budget, historical or heritage sites to visit, etc. This information helps users plan their vacations.
- User Personalized Context: It refers to providing information on who the user is and what their preferences and constraints are. This information enriches the top candidates retrieved with user-level information. For example, providing context on questions like:
Is the user interested in history?
What climate would the user prefer?
Will the user be interested in adventure sports activities?
What type of accommodation do they prefer?
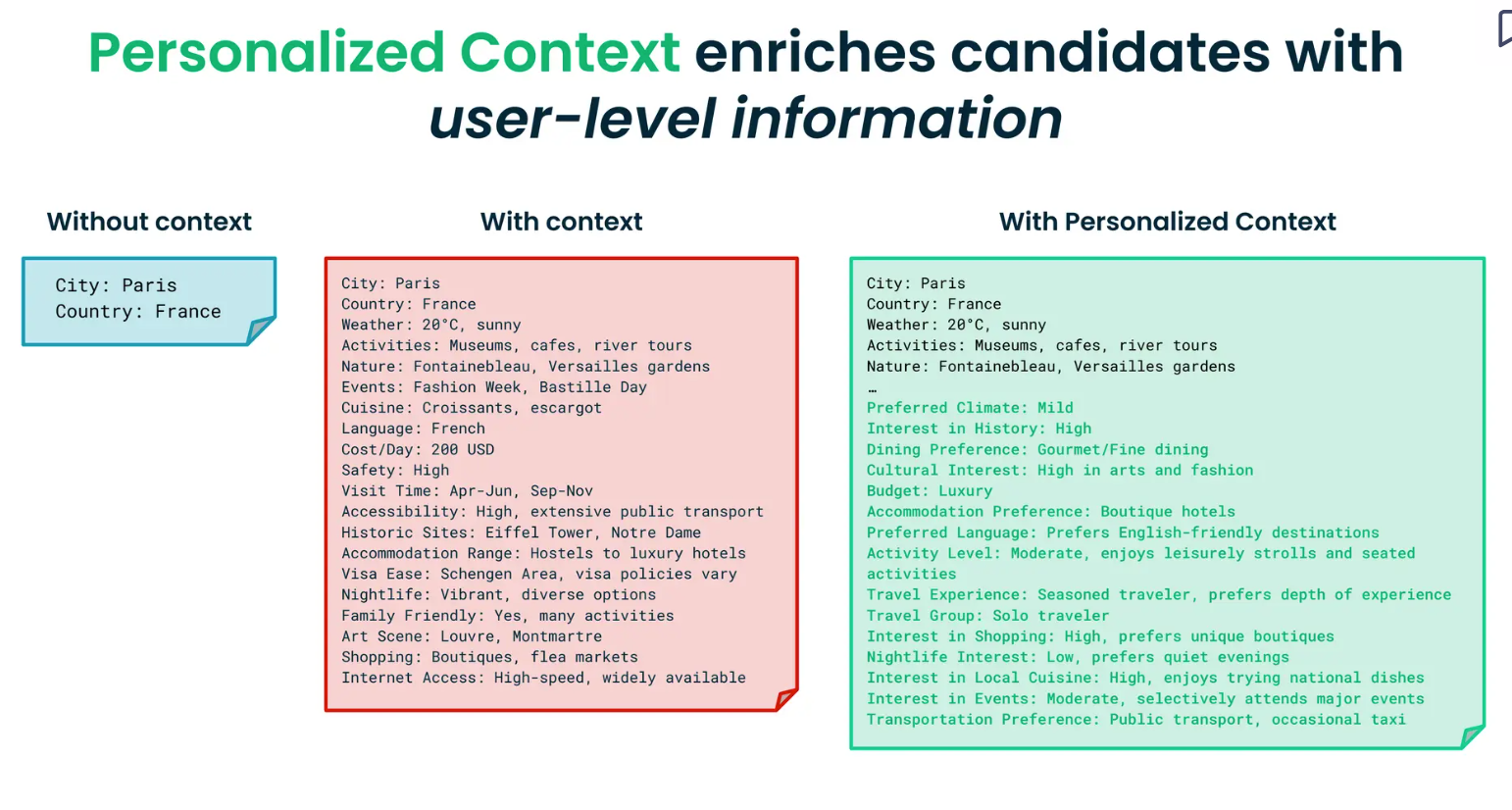
With context on what a city offers and what the user wants, the AI model can better match the suitable destination. Further, it can suggest activities, events, and accommodation options tailored to their preferences.
How Can We Build Amazing Personalized Contexts with Tecton?
Tecton has developed a feature platform to integrate different business data sources. You can easily create and manage the personalized context we need to provide the recommendation algorithm. The feature platform takes the candidate and relevant user data and retrieves contextualized candidates from a vector database like Milvus.
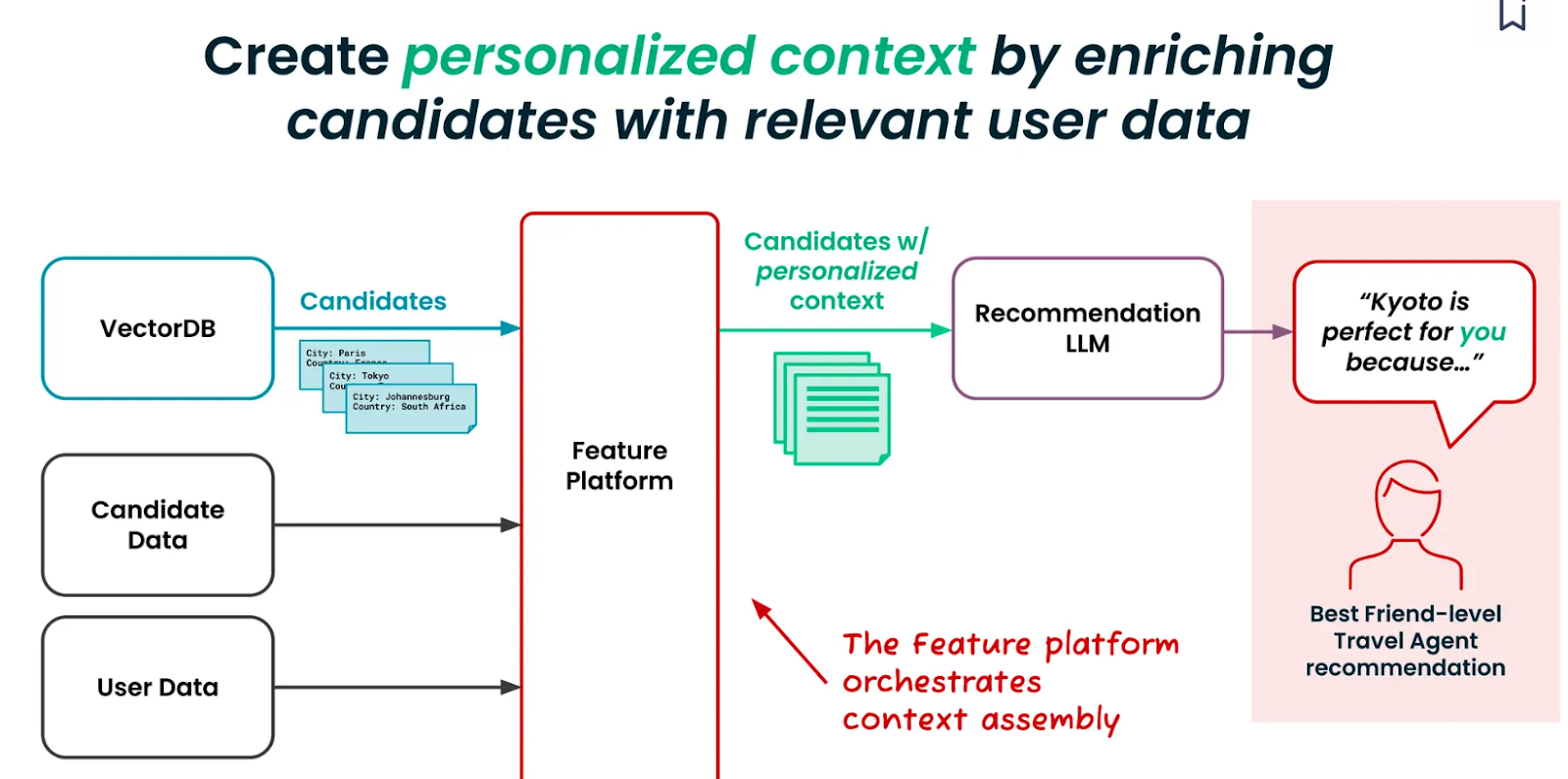
The personalized contexts can be built and managed at four broad levels.
Level 0: Base
This is the base layer or the starting point, with no additional information. The diagram below shows how a RAG works with zero contextual information.

Level 1: Batch Context
The next level provides historical data, such as trip history, favorite activities, etc. Implementing this level is challenging as you must build pipelines to retrieve and join data from different warehouses or data lakes. You would also need to create historical evaluation datasets for benchmarking and development.
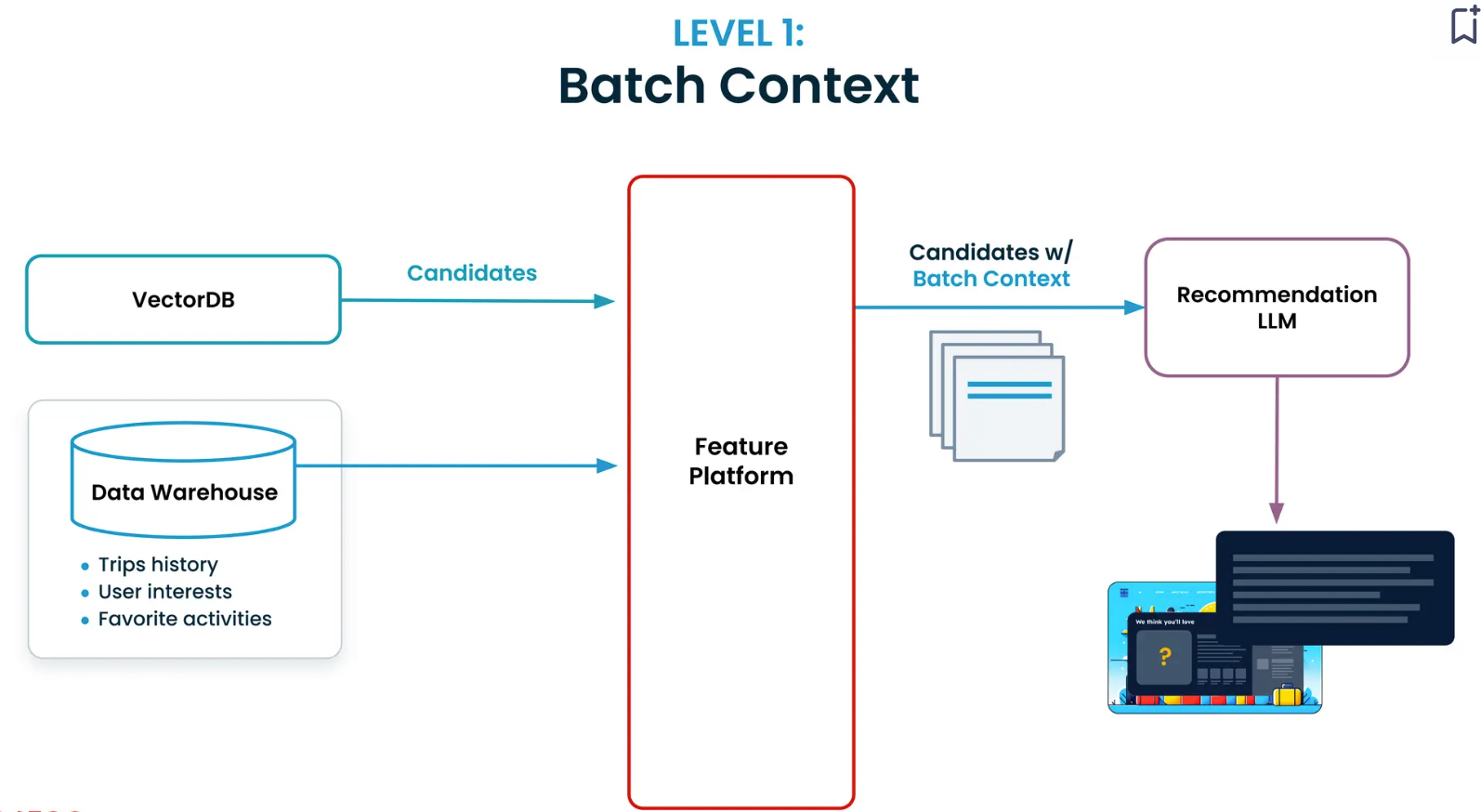
Tecton’s feature platform simplifies the process of building batch context. You can start with a simple context definition like “What are the last five places this user has visited?”. The platform also provides a Python SDK to code your definition and supports reading and evaluating the data in real time.
At this stage, your recommendation LLM can draw insights from historical context and provide suggestions. For example, if the user has visited many historical sites in the past, it would suggest visiting the temples of the ancient city of Kyoto.

Level 2: Batch + Streaming Data Context
Adding streaming information about the user, such as the movies, videos, and blogs they watch and read, can help our model understand their current interests. This streaming information may include the user’s search data, purchase data, or session interactions on web pages.
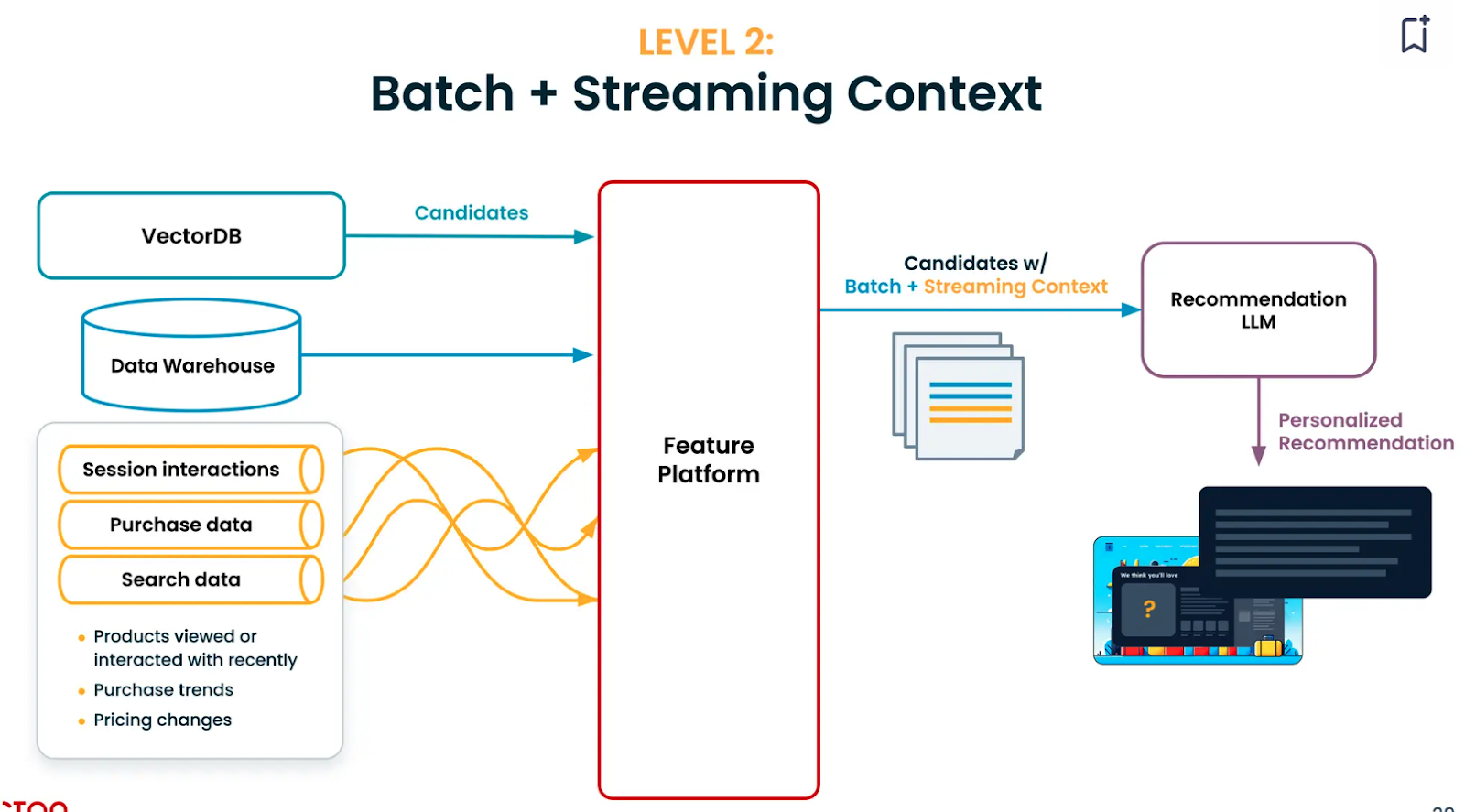
The challenge here is to incorporate streaming data pipelines and productionalize them. While implementing at scale, the cost for both model building and real-time inference may be higher.

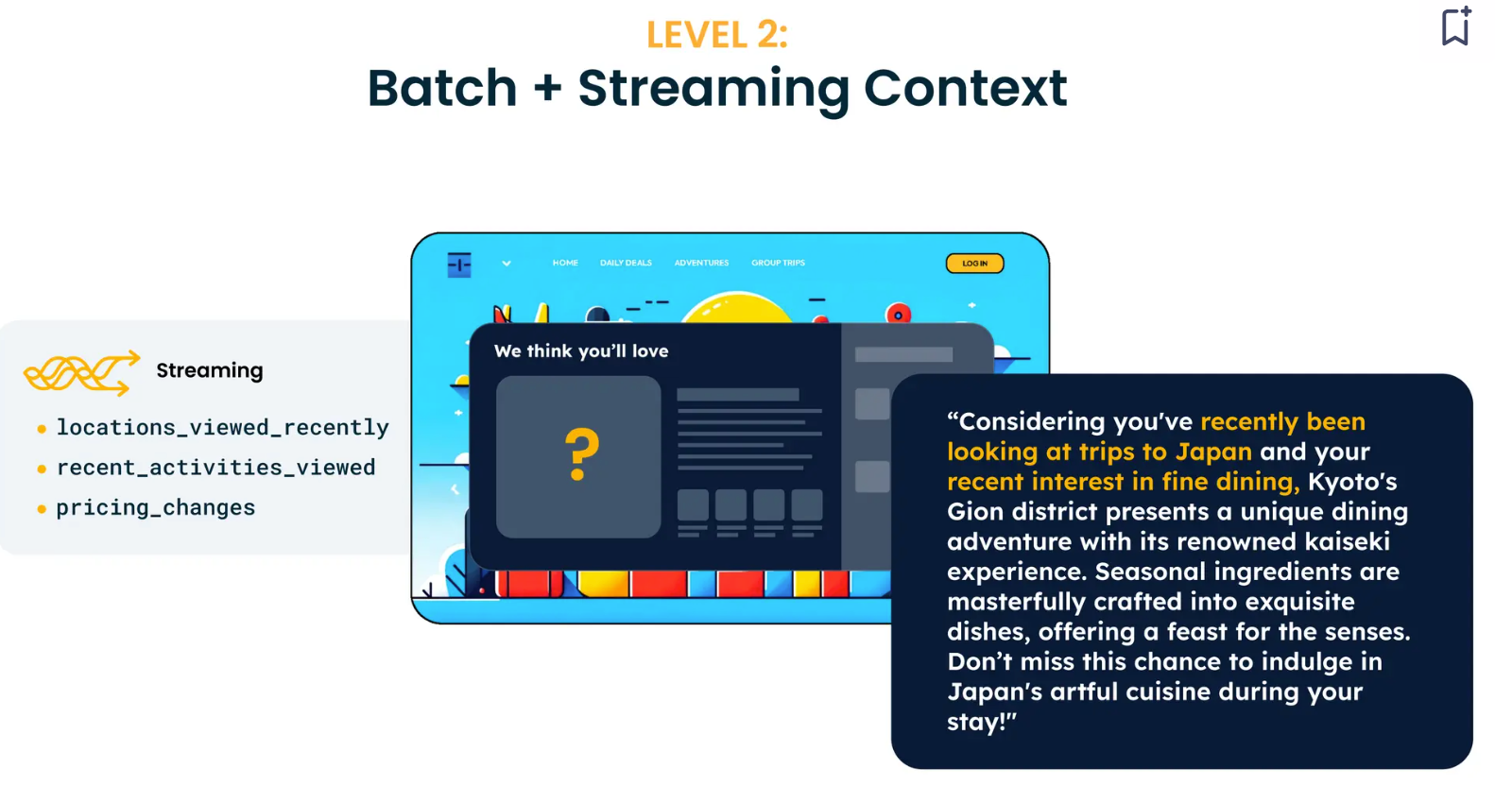
Tecton simplifies building streaming context. For example, it starts with a simple context definition: "In the past hour, what topics did the user watch a video about ?”. This can be coded into the platform's Python SDK. We can test it, deploy it to production, and use it in real time. The recommendation at this stage is significantly better than the previous one. For example, if the user has been searching for flights to Japan and loves fine dining, the LLM will curate a dining experience in Japan.
Level 3: Batch + Streaming data + Real-time Context
The next stage is bringing in real-time data for a high-quality signal. This context can help your model better understand the user intent. This data includes the user's search queries and looking up data from other applications in real-time. For example, we must look up real-time flight prices to suggest the cheapest option.

The biggest challenge is integrating the third-party real-time data sources and managing the trade-off between speed and costs. With real-time personalized recommendations, users will find it very valuable as it saves time for them instead of doing research alone.

You could also add a feedback-level context on top of this. The user’s feedback on the provided recommendation can help the model steer in the right direction.
Conclusion
Context can enhance AI personalization in numerous cases like tailored shopping experiences, building chatbots, providing personal finance advice, or recommending new movies. Higher levels of personalization improve the product experience, but the difficulty of building increases parallelly.
RAG is an important technique for providing LLMs with additional domain-specific information for better and more relevant information. It is also the key to long-term customer retention for many user-centric GenAI products.
A standard RAG comprises a vector database-powered retriever and an LLM generator. All the additional information is stored in a vector database like Milvus, and the LLM generates answers based on the information retrieved that is relevant to user queries.
Though effective in addressing hallucinations, a standard RAG system falls short in use cases like providing hyper-personalized recommendations. This is because the top-k candidates retrieved might not have more personalized context on the particular user's likes and dislikes.
Tecton provides a solution that assembles the personalized context for LLMs, streamlining the process for companies. However, significant challenges remain, such as version control, model governance, and debugging to find the root cause.
For more information about this topic, watch Mike’s meetup video recording.

Keep Reading

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

How Zilliz Saw the Future of Vector Databases—and Built for Production
An inside look at how Zilliz built vector databases for real-world use, focusing on scalability, stability, and running them reliably at scale.

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.