




The Practical Guide to Self-Hosting Compound LLM Systems
Hosted during SF #TechWeek, Zilliz’s monthly “Unstructured Data Meetup” pulled in over 800 builders, founders, and VCs to discuss the latest developments in the AI ecosystem. The second talk, given by Chaoyu Yang (Founder/CEO of BentoML), gave actionable advice for those who prefer the control and customization of self-hosting large language models (LLMs) while trying to achieve the performance of just calling a managed API. BentoML shares its research insights in AI orchestration, demonstrating solutions it developed for optimizing common performance issues when self-hosting models.
In this post, we’ll recap the key points of Chaoyu’s talk and discuss key challenges, considerations, and practices for self-hosting your LLMs. We’ll also explore how to integrate BentoML and Milvus to build more powerful GenAI applications.
The LLM Doom Stack
As someone fairly new to AI, I found it easiest to understand BentoML and Milvus within the context of the modern LLM stack. In no particular order—just because it sounds cool—let's explore what I call the 'LLM DOOM Stack.'
Data: Preparing, storing, and processing large-scale data sets for high-quality training and inference. Such technologies include data pipelines, embedding models, and vector databases (like Zilliz/Milvus, woo!)
Operations: Monitoring, scaling, and maintaining the health and performance of deployed models. Real-time observability for active debugging to maintain reliability.
Orchestration: Deploying and scaling models across infrastructure, managing the flow between LLMs, external systems, and users. (This is where BentoML plays a key role.)
AI Models: The heart of LLM apps—training, fine-tuning, and optimizing models for specific tasks, whether using APIs, open-source, or pre-trained models.
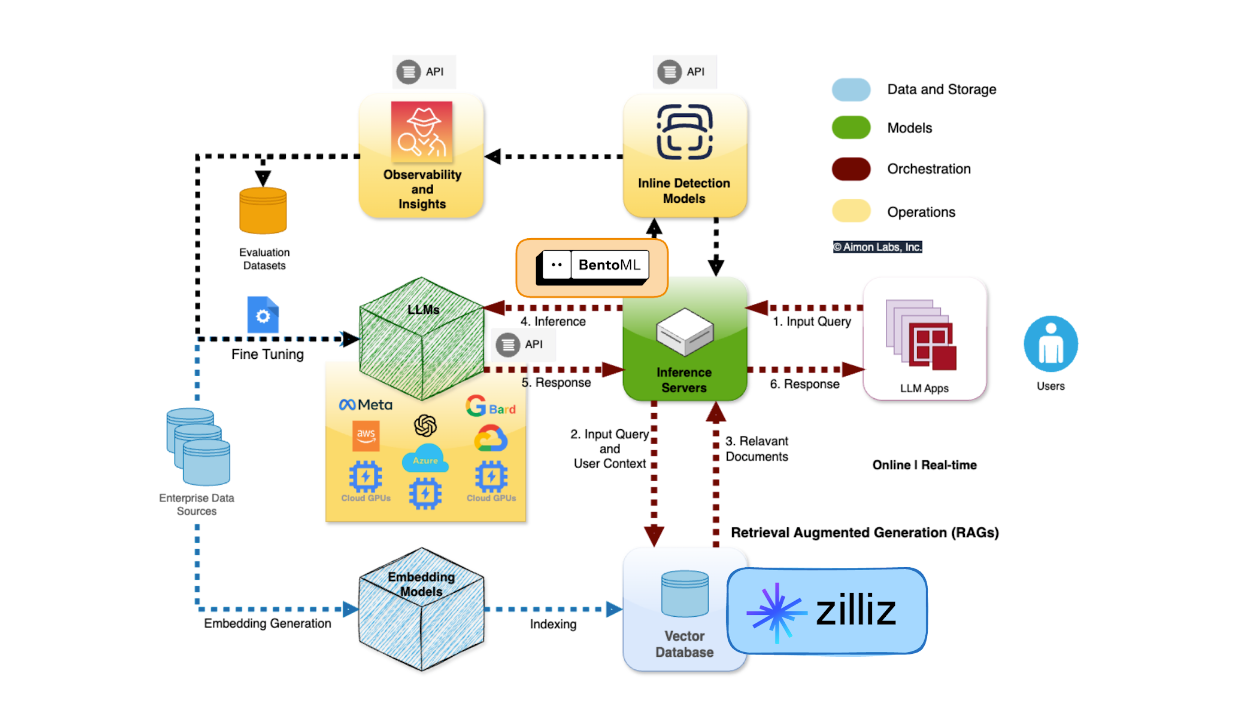 Figure- The LLM Doom Stack.png
Figure- The LLM Doom Stack.png
Figure: The LLM Doom Stack (adapted from this image.)
Every AI infrastructure startup fits within this DOOM framework. Milvus and its managed cloud service, Zilliz Cloud, are vector databases built to store, index, and retrieve unstructured data in numerical representations called vector embeddings in a high-dimensional space. They are fundamental components of various LLM-powered systems, particularly retrieval augmented generation (RAG). BentoML provides operational optimizations for the current LLM workflows. By borrowing concepts that have proven to work with operating systems and combining them with data-backed research, BentoML has proven to provide superior performance for building and deploying LLMs—and its Founder, Chaoyu, has shared its secrets in this talk.
The LLM Dilemma: Self-Host or Just Call the API?
One of the most critical decisions when deploying LLMs is whether to self-host or rely on managed APIs. Both options come with their own trade-offs, making it essential to weigh convenience against control. Managed APIs are appealing for their ease of use, lower maintenance overhead, and fast scaling capability, while self-hosting offers full control and flexibility, allowing for deeper customization. Ultimately, the decision for most teams comes down to balancing short-term deployment speed with long-term scalability and performance goals.
 Figure- Benefits and Challenges of Self-Hosting LLMs.png
Figure- Benefits and Challenges of Self-Hosting LLMs.png
Figure: Benefits and Challenges of Self-Hosting LLMs
Who Should Self-Host LLMs?
Chaoyu began his talk with a quick survey on managed vs. self-hosted LLMs. Most attendees raised their hands for managed APIs, and understandably so—Building, scaling, and maintaining the infrastructure while simultaneously developing your application is no easy task.
Chaoyu highlighted that managed services, while convenient, often prioritize throughput over optimization for specific use cases. Self-hosting, on the other hand, allows for custom fine-tuning of models, advanced inference strategies, and predictable quality and latency.
However, self-hosting isn’t the right choice for everyone. So, who exactly should consider self-hosting LLMs? Here are the key reasons to explore this approach:
 Figure- Who Should Self-Host LLMs? .png
Figure- Who Should Self-Host LLMs? .png
Figure: Who Should Self-Host LLMs?
Control: Self-hosting allows you to run LLMs on your own terms, complying with data security, privacy regulations, and specific organizational needs. This is especially true for industries with stringent data protection requirements, where sensitive data cannot leave your infrastructure.
Customization: With self-hosting, you can fine-tune models and optimize inference strategies for your specific use case, achieving better performance, speed, and accuracy than what managed APIs can offer. You also gain the flexibility to experiment with advanced inference techniques like Chain of Thought (CoT) decoding or Equilibrium Search, which are only possible with full control over the inference layer.
Long-term Cost Benefits: While self-hosting can incur higher upfront costs in terms of infrastructure and maintenance, it can offer long-term cost savings. You can optimize costs over time and scale by leveraging open-source platforms like BentoML and OpenLLM without being locked into vendor pricing models.
Key Challenges and Optimizations for Self-Hosting LLMs
Self-hosting LLMs provide greater control but come with a set of technical challenges, particularly around scaling, inference optimization, and the cold start problem. BentoML offers a suite of solutions to address these issues, allowing teams to optimize their deployments efficiently. Chaoyu shared the key approaches they used to address such challenges.
Inference Optimization
When self-hosting LLMs, optimizing inference is crucial to improve performance and reduce costs. Chaoyu highlighted several key techniques:
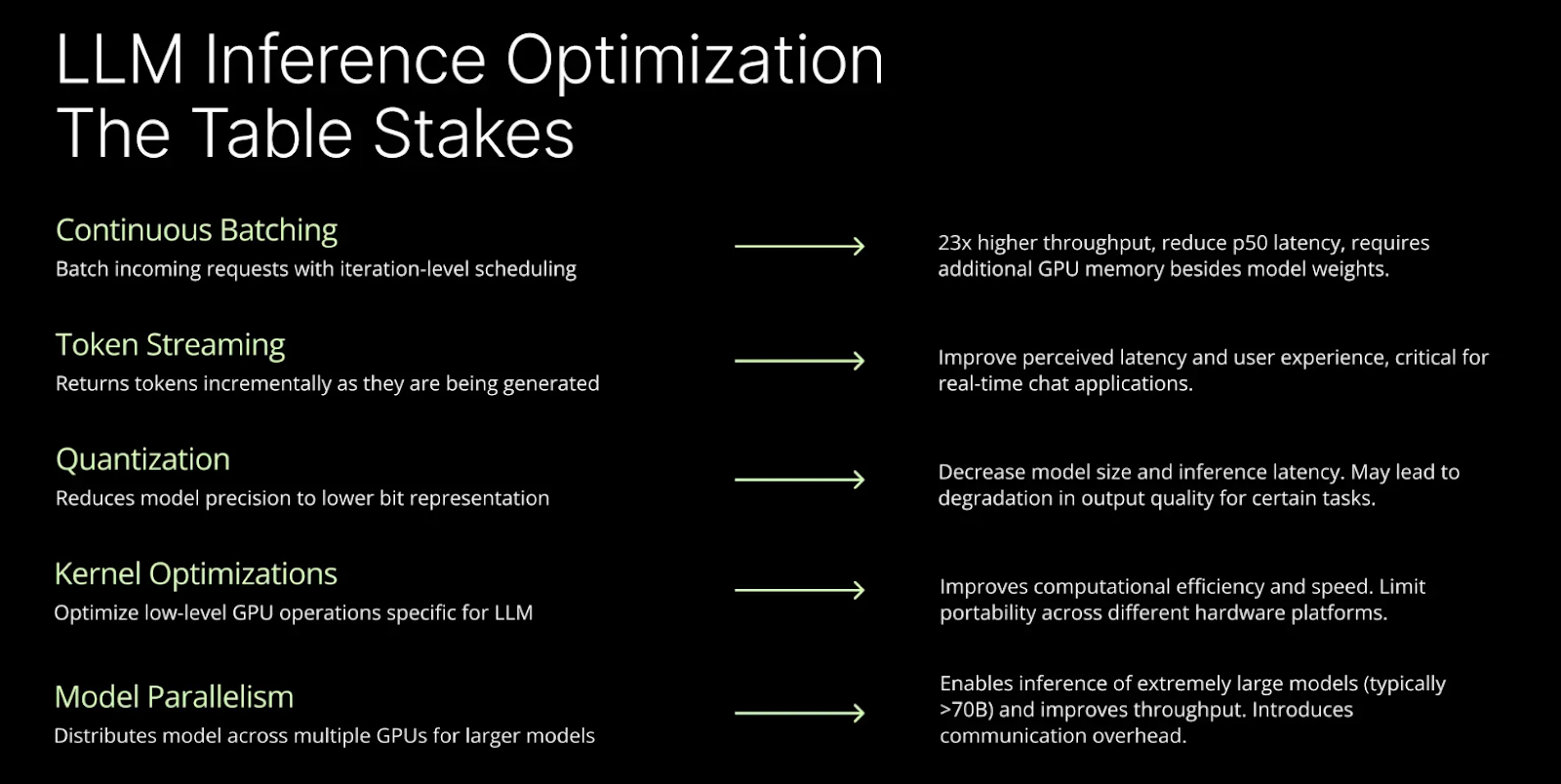 Figure- LLM Inference Optimization- The Table Stacks.png
Figure- LLM Inference Optimization- The Table Stacks.png
Figure: LLM Inference Optimization: The Table Stacks
Batching Requests
As one of the most impactful strategies, batching requests can increase throughput by up to 23x. By processing multiple requests in parallel rather than sequentially, you can maximize GPU resource utilization, reducing idle time and improving efficiency, especially for high-traffic applications.
Token Streaming
Another essential optimization is token streaming, which returns tokens incrementally as they are generated. This approach significantly improves perceived latency, particularly in real-time applications like chatbots, where faster response times enhance user experience.
Quantization
Additionally, quantization lowers memory usage and inference latency by reducing model precision (e.g., from 32-bit to 8-bit). While this approach may cause a slight reduction in output quality for certain tasks, the trade-off is worthwhile for performance gains.
Kernel Optimizations
Optimizing at the kernel level allows for low-level GPU optimizations tailored to LLM workloads, ensuring that computational tasks are handled as efficiently as possible. However, these optimizations may reduce portability across different hardware platforms.
Model Parallelism
For extremely large models (70B+ parameters), distributing the workload across multiple GPUs enables more efficient inference. While this improves throughput, it introduces some communication overhead between GPUs.
Scaling LLM Inference: Concurrency-Based Autoscaling
A common challenge in self-hosted environments is managing scale. Traditional scaling metrics like CPU/GPU utilization and queries per second (QPS) are insufficient for LLMs, which have variable resource demands depending on input complexity.
Chaoyu explained that concurrency-based scaling is a more effective approach. This method monitors the number of concurrent requests to determine system load and dynamically adjusts resources based on the batch size. This method ensures that the system scales precisely when needed, preventing over-provisioning and reducing costs while maintaining high performance during traffic spikes.
Prefix Caching for Cost Savings
One of the most effective ways to reduce costs and improve performance in self-hosting environments is through prefix caching, which can lead to 90%+ cost savings. This strategy works by caching the common parts of prompts, such as system instructions or static content, to avoid redundant computations.
By front-loading static information at the beginning of requests, you increase the likelihood of cache hits, reducing the computational load for subsequent requests with similar structures. This is especially useful for applications handling frequent, repeated queries where most of the prompt remains the same. Prefix caching lowers latency and decreases resource usage, significantly optimizing performance and costs for LLM inference.
The Cold Start Problem
Another major challenge in self-hosting is the cold start problem—the delay when new instances take time to become ready to handle traffic. Chaoyu discussed two key strategies for overcoming this issue.
One solution is to have pre-heated models on standby. This ensures that models are instantly ready to handle requests when a surge occurs, minimizing startup delays.
Another critical optimization is slimming down container images. By reducing unnecessary dependencies, you can dramatically decrease the time required to pull images when scaling up services dynamically. For example, a 154MB image will load much faster than a bulky 6.7GB image, reducing startup time significantly.
Additionally, streaming model weights progressively into GPU memory rather than loading them sequentially further reduces initialization time. This ensures that your system can handle sudden traffic spikes without long startup delays, improving the overall responsiveness of your self-hosted models.
Integrating BentoML and Milvus for More Powerful LLM Applications
BentoML optimizes online serving systems for AI applications and model inference. Its managed service, BentoCloud, offers a range of state-of-the-art open-source AI models, including Llama 3, Stable Diffusion, CLIP, and Sentence Transformers. These pre-built models can be deployed with a single click on the platform.
Milvus is an open-source vector database built for storing, indexing, and searching billion-scale unstructured data using high-dimensional vector embeddings. It is ideal for modern AI applications like RAG, semantic search, multimodal search, and recommendation systems.
BentoCloud integrates seamlessly with Milvus and its managed service, Zilliz Cloud, allowing for the easy development of powerful LLM-powered applications, particularly Retrieval Augmented Generation (RAG). RAG is a technique for enhancing LLM output by providing the model with external knowledge to which it had no access.
You can use BentoCloud to serve embedding models and convert unstructured data into vector embeddings, which can then be stored and retrieved in Milvus (or Zilliz Cloud). Milus then retrieves the most relevant results and provides them as context with the LLM to generate more accurate results.
 Figure- RAG workflow.png
Figure- RAG workflow.png
For more information on how to build RAG or other types of GenAI APPs, check out the tutorials and blogs below:
Tutorial: Retrieval-Augmented Generation (RAG) with Milvus and BentoML | Milvus Documentation
Blog | Infrastructure Challenges in Scaling RAG with Custom AI Models
Video | RAG as a service with BentoML
Summary
Deploying LLMs comes with critical decisions and challenges, from choosing between self-hosting and managed APIs to optimizing performance and scaling. While managed APIs offer convenience and simplicity, self-hosting provides greater control, flexibility, and long-term cost efficiency for teams needing custom solutions. BentoML’s platform addresses many of the complexities of self-hosting, offering powerful tools for optimizing inference, scaling efficiently, and overcoming technical hurdles like the cold start problem.
By leveraging BentoML, Milvus, or their managed services, teams can seamlessly integrate their LLM applications' Data and Operations layers, building high-performance systems that meet their specific needs.
If you're ready to dive into self-hosting LLMs and build LLM applications, tools like BentoML, OpenLLM, and Milvus make it easier to get started and optimize for your unique use case.
Team up with people dedicated to optimizing their layer of the DOOM stack. Stand on the shoulders of giants, leverage the world like Archimedes, and keep the momentum going.

Keep Reading

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.