




8 Latest RAG Advancements Every Developer Should Know
Large Language Models (LLMs) are powerful but only as good as their training data. When you ask a complex question, you want the AI to combine its built-in knowledge with fresh, relevant information from external sources. That's exactly what Retrieval-Augmented Generation does - it bridges the gap between static training data and dynamic, up-to-date information.
Traditional RAG has been significant, but developers have been pushing the boundaries of what is possible. In this article, we'll explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.
Why These New RAG Types Matter
Traditional RAG systems combined two steps: retrieving relevant data as context from a knowledge base powered by a vector database, such as Milvus, and generating answers using a language model.
While effective, early implementations of RAG faced efficiency, scalability, and data flow management challenges. They often relied on simple similarity measures that could miss crucial nuances, resulting in generic responses for complex queries. To overcome these limitations, researchers have introduced new strategies that allow models to:
Dynamically decide retrieval steps: Instead of always retrieving data in one go, newer methods determine the optimal moments to retrieve external information.
Incorporate multimodal data: Beyond text, some systems can retrieve images and videos to enrich generated content.
Optimize resource use: Advanced RAG frameworks adjust compute allocation based on the query’s complexity.
This is where the exciting advancements in RAG come into play. These enhancements have led to more accurate, context-aware outputs that better serve the needs of both developers and businesses.
Quick Reference: Which RAG Should You Use?
Here's a developer-friendly overview of what we'll cover:
| RAG Type | Key Innovation | Best For |
| DeepRAG | Step-by-step retrieval decision process | Legal or medical analysis |
| RealRAG | Real-time data processing | Social media monitoring, news app |
| CoRAG | Sequential, adaptive multi-step retrieval | Technical troubleshooting |
| VideoRAG | Video-to-text understanding | Lecture summarization |
| CFT-RAG | Tree-based (text + image) retrieval | Fraud detection |
| CG-RAG | Graph-based contextual reasoning | Academic research with citations |
| GFM-RAG | Graph neural networks knowledge connections | Patent analysis |
| URAG | Unified (text + image + audio) support | Educational chatbots |
DeepRAG
DeepRAG replaces traditional retrieval pipelines with a single neural network trained end-to-end. It models retrieval-augmented reasoning as a decision process. Instead of treating retrieval and generation as separate tasks, it dynamically decides when to rely on external data versus internal reasoning. This step-by-step approach targets specific knowledge gaps effectively.
It enhances depth and accuracy by improving reasoning-intensive tasks by around 8-15% and reduces unnecessary data retrieval, saving compute resources. While it may increase system design complexity and require fine-tuning to balance retrieval frequency. It is ideal for fact verification, multi-step reasoning tasks, research-intensive domains, and generating detailed reports (e.g., legal document analysis or medical diagnosis support).
Key Features:
Dynamic Retrieval: Evaluates each step to decide if retrieval is needed.
Strategic Decision-Making: Uses a decision process similar to a Markov Decision Process.
GitHub: https://github.com/microsoft/deepRAG
Paper: https://arxiv.org/html/2502.01142v1
RealRAG
RealRAG enhances text-to-image generative models (e.g., Flux and Stable Diffusion V3) by retrieving real-world images. By comparing generated images with retrieved examples, the system fills knowledge gaps to improve realism.
It produces more realistic image outputs and improves visual content quality. However, it has high infrastructure costs for 24/7 multimodal processing. It may also struggle in domains with limited quality image datasets. It is particularly useful for product design and medical imaging, where accurate visual representations are essential.
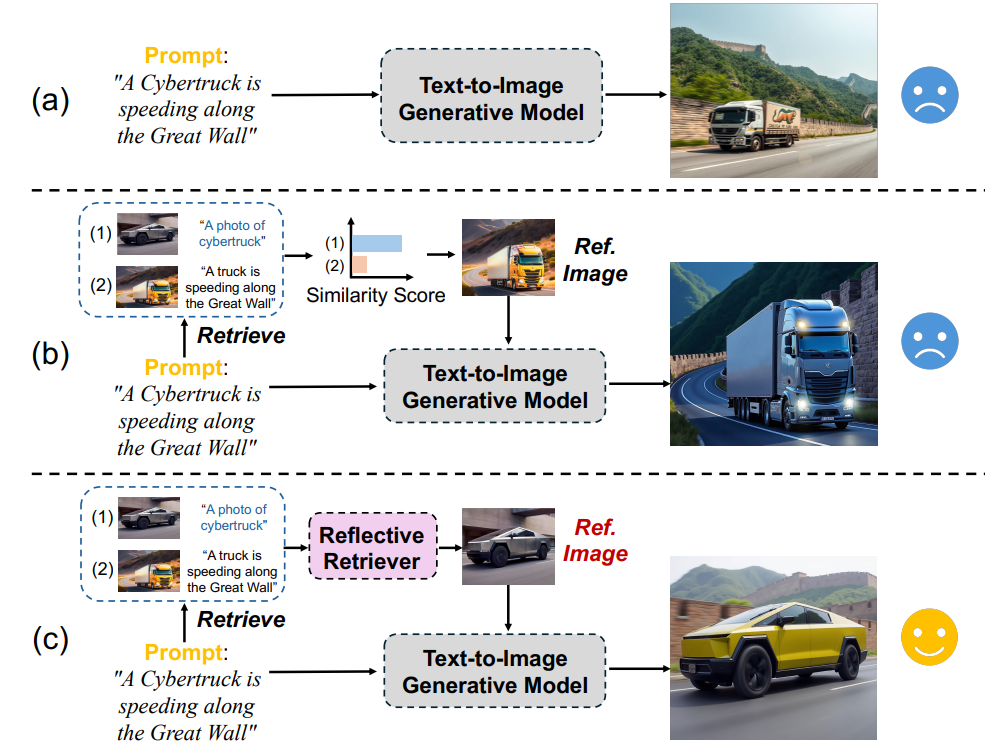 Figure- Overview of RealRAG
Figure- Overview of RealRAG
Figure: Overview of RealRAG (Source).
Key Features:
FID Score Increase: 16.18% on the Stanford Car benchmark
Image-Based Retrieval: Enhances generation with external visual data.
Self-Reflective Learning: Refines outputs via feedback from image comparisons.
Paper: https://arxiv.org/abs/2502.00848
CoRAG: Chain-of-Retrieval Augmented Generation
Inspired by chain-of-thought prompting, CoRAG breaks queries into sub-questions and retrieves information sequentially. It adjusts the depth and breadth of retrieval based on the query's complexity and reformulates queries as necessary.
It handles multi-faceted questions with up to 30% higher accuracy and prioritizes essential information through sequential retrieval. However, multiple retrieval rounds increase latency. It is ideal for technical troubleshooting or research where queries require multi-layered information.
Key Features:
Sequential Retrieval: Retrieves data in multiple steps to refine the answer.
Adaptive Compute Allocation: Balances resources based on data needs.
Paper: https://arxiv.org/abs/2501.14342
VideoRAG: Retrieval-Augmented Generation over Video Corpus
Video content is a rich source of information, but traditional RAG is primarily designed for text-based documents. VideoRAG extends RAG capabilities to video content by using vision-language models (VLMs) like CLIP, along with speech-to-text, frame analysis, and audio processing to extract information. This allows LLMs to understand, process, and respond to queries related to videos. It converts video frames into text embeddings to enable queries like “Find scenes with emotional conflict”.
VideoRAG can handle extremely long video content without compromising accuracy. Its dual-channel architecture provides detailed, context-rich summaries of video data. Unfortunately, it requires high GPU resources for 4K video processing and complexity in managing multimodal data streams. It is suitable for video content analysis, lecture summarization, and multimedia content generation.
Key Features:
Dual-Channel Architecture: Separately processes textual and visual data.
Unlimited-length Video Processing: Maintains context over long video sequences.
Below is a simple workflow of how it works:
Split the video into frames.
Generate embeddings using CLIP.
Store embeddings in a vector database (Milvus) for similarity search.
Retrieve relevant clips and generate summaries.
Paper: https://arxiv.org/abs/2501.05874
GitHub: https://github.com/starsuzi/VideoRAG
CFT-RAG: Cuckoo Filter Tree-based RAG
CFT-RAG uses a tree-based acceleration method using an improved Cuckoo Filter with structured data (e.g., CSV files, SQL tables). This speeds up entity localization during retrieval, ensuring faster access to relevant information. It supports both text and images. For example, asking “Show me healthy meal recipes” returns ingredient lists and cooking videos.
It accelerates the retrieval process significantly and improves precision by focusing on key entities. Although it requires clean, well-structured data, and maintaining the tree structure requires regular updates. It is best for real-time support systems, fraud detection, or high-frequency trading platforms.
Key Features:
Retrieval and Generation: Milvus for multi-modal embeddings, GPT-4 with vision capabilities.
Entity Tree Structure: Organizes information in a hierarchical tree.
Cuckoo Filter Optimization: Enhances retrieval speed and accuracy.
Paper: https://arxiv.org/abs/2501.15098
CG-RAG: Contextualized Graph RAG
CG-RAG enhances context using knowledge graphs to capture relationships between entities (such as people or events). It utilizes Lexical-Semantic Graph Retrieval (LeSeGR) to enhance answer quality by considering the interconnections among concepts. For instance, querying “Apple’s product launches” retrieves entities (e.g., iPhones, CEOs) and their relationships. Tools like Neo4j are used for graph storage, and Graph Neural Networks (GNNs) for traversal.
This RAG innovation excels in complex topics or research questions by mapping citation relationships. But it also requires upfront schema design, and graph queries can be resource-intensive. Overall, it is highly effective in academic research, technical documentation, and scenarios needing deep insights into interrelated data.
Key Features:
Graph-based Retrieval: Structures information as interconnected nodes.
Citation Relationships: Captures how different pieces of information relate.
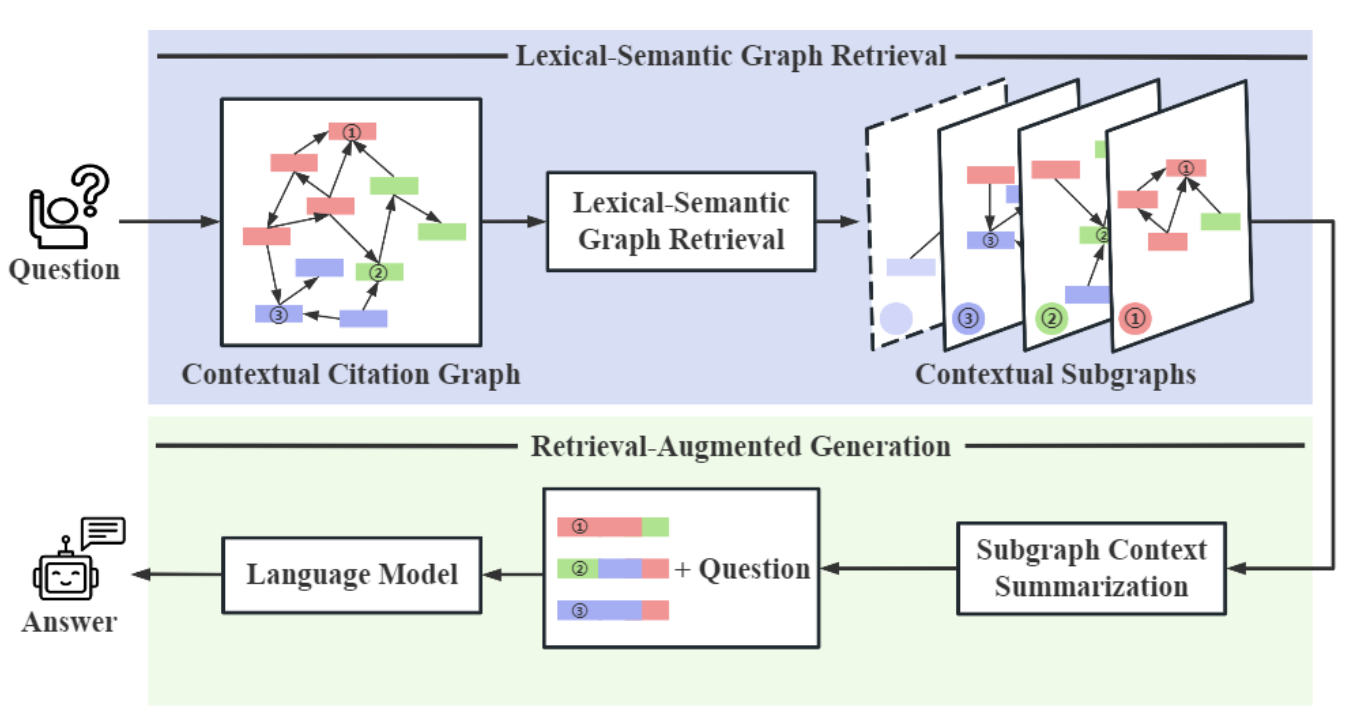 Figure- Overview of CG-RAG
Figure- Overview of CG-RAG
Figure: Overview of CG-RAG (Source).
Paper: https://arxiv.org/abs/2501.15067
Other GraphRAG innovations:
GFM-RAG: Graph Foundation Model for RAG
GFM-RAG employs a graph foundation model using GNNs to refine connections between queries on niche datasets (e.g., academic papers, patent filings) for jargon-heavy domains. This approach enables multi-hop reasoning over a structured knowledge graph, significantly boosting accuracy in knowledge-intensive queries.
It improves accuracy in knowledge-intensive queries and is capable of handling complex relationships in large datasets. However, it requires well-defined feature sets, and complex queries may slow responses. It is effective in scientific research requiring precise data mapping.
Key Features:
Graph Neural Network (GNN): Enriches retrieved data semantically.
Multi-Hop Reasoning: Connects disparate information across documents.
Paper: https://arxiv.org/abs/2502.01113
URAG: Unified RAG
URAG combines text, images, audio, and video under one architecture. It uses rule-based methods with RAG techniques to support lightweight LLMs, providing precise answers in environments with limited computational resources.
It delivers accurate responses with reduced computational overhead. However, rule-based components may limit flexibility. Balancing between retrieval and rule-based logic can be challenging. It’s ideal for educational chatbots answering via text and diagrams.
Key Features:
Modular design: Swap retrieval/generation components.
Multi-format Support: Handles over 10+ data formats.
Hybrid System: Integrates rule-based logic with modern RAG techniques.
Lightweight Model Support: Optimizes performance for smaller models.
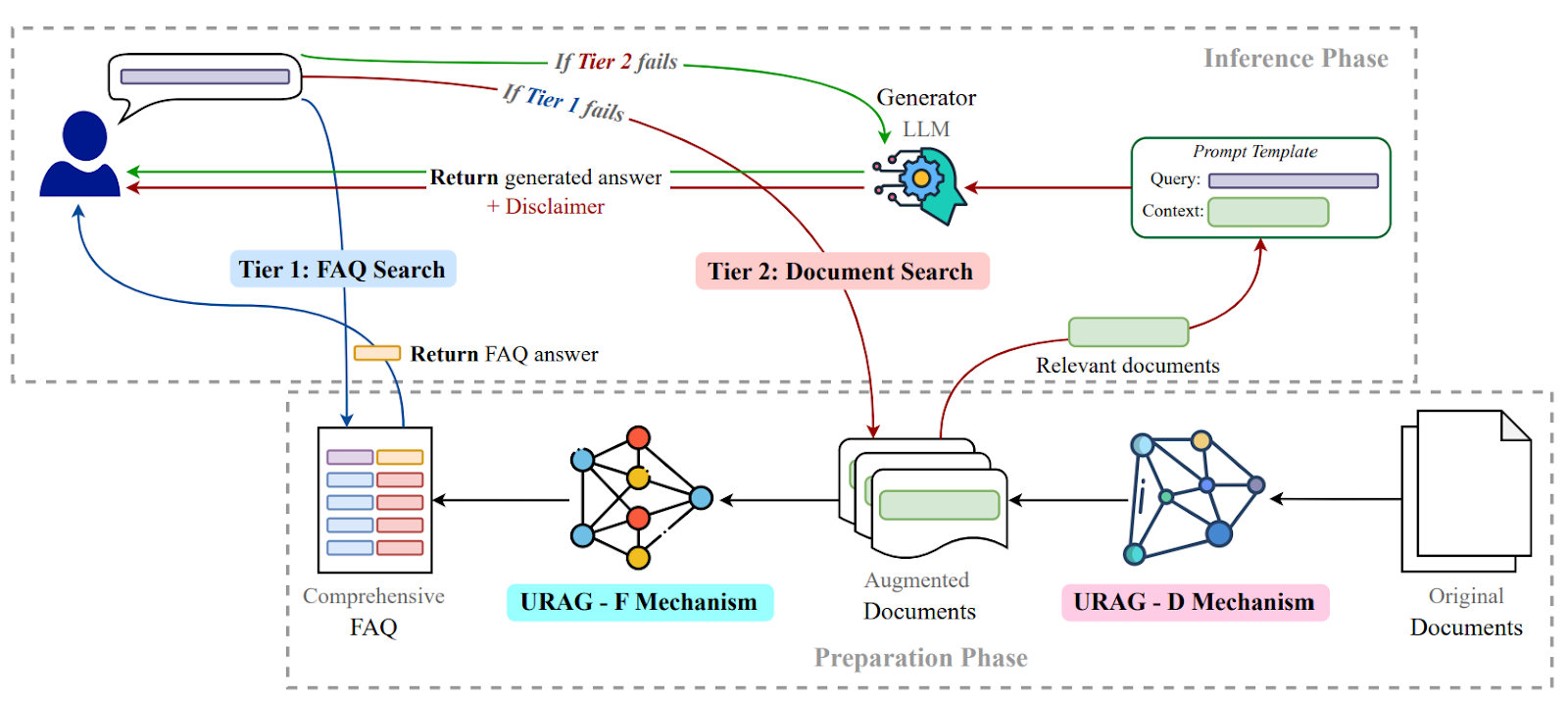 Figure- URAG Framework for Improving LLM Performance in University Chatbots
Figure- URAG Framework for Improving LLM Performance in University Chatbots
Figure: URAG Framework for Improving LLM Performance in University Chatbots (Source).
Paper: https://arxiv.org/abs/2501.16276
Resource Requirements Comparison
| RAG Type | GPU Memory | Latency | Setup Complexity | Best Performance |
|---|---|---|---|---|
| DeepRAG | Medium | Medium | Medium | Reasoning tasks |
| RealRAG | High | High | High | Live data streams |
| CoRAG | Medium | High | Medium | Multi-step queries |
| VideoRAG | Very High | Very High | High | Video content |
| CFT-RAG | Low | Low | Medium | Structured data |
| CG-RAG | Medium | Medium | High | Relationship queries |
| GFM-RAG | High | Medium | Very High | Complex reasoning |
| URAG | Medium | Medium | Medium | Mixed content |
The eight RAG variants we've explored represent exciting recent developments in the field, with most emerging from research papers and early-stage implementations. While these innovations show great promise and demonstrate interesting approaches to common RAG challenges, they're still evolving as the community experiments with them in different contexts.
As with any emerging technology, we'd recommend starting with small experiments to see how these approaches work with your specific data and use cases. The code examples and recommendations below are meant to help you get started with exploration rather than serve as production blueprints. Each variant may require some adaptation to fit your particular requirements and infrastructure.
Conclusion
The latest advancements in RAG are solving critical challenges in AI by enhancing accuracy, speed, and context awareness, so there is always a RAG variant tailored to your needs. These innovations enable smarter, more responsive systems that can unlock new possibilities and expand the applications of LLMs across industries.
By leveraging Zilliz Cloud’s managed Milvus service, developers can easily deploy these RAG variants with ease. As RAG continues to evolve, it will play a critical role in shaping the future of AI, ensuring that responses are fluent and deeply informed by the latest data and contextual cues.
Related Resources

Keep Reading

Migrating Self-Managed Milvus to Zilliz Cloud for >99% Latency Reduction
Step-by-step guide to migrating 50M vectors from self-managed Milvus to Zilliz Cloud using milvus-backup. Achieve >99% query latency reduction with zero data loss.

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.