




LLaVA: Продвижение моделей "зрение-язык" через настройку визуальных инструкций
Современные современные большие языковые модели (LLM), такие как ChatGPT, LLAMA и Claude Sonnet, продемонстрировали, что инструкции на основе человеческого языка могут быть мощным инструментом для повышения качества ответов. Используя такие методы, как проектирование подсказок, мы можем направлять LLM на генерацию ответов, которые более точно соответствуют нашим конкретным ситуациям использования.
Изначально LLM были разработаны исключительно для работы с текстовыми данными. Когда им давались текстовые инструкции, они генерировали соответствующий ответ. Хотя этот подход оказался весьма успешным, расширение возможностей до визуальных данных является естественным шагом вперед. Модели на основе визуальных данных принимают на вход как текстовую инструкцию, так и изображение, что позволяет решать такие задачи, как обобщение содержания изображения, извлечение информации или перевод текста на изображении.
В этой статье мы рассмотрим LLaVA (Large Language and Vision Assistant), одну из первых попыток реализовать текстовые инструкции для визуальных моделей. Прежде чем перейти к подробному описанию его реализации, давайте сделаем шаг назад, чтобы понять эволюцию визуальных моделей и то, как они преобразуют эту область.
Развитие визуально-ориентированных моделей
На ранних этапах развития большинство моделей, основанных на визуальном восприятии, опирались на архитектуру convolutional neural network (CNN) для выполнения общих задач видения. В своей простейшей форме модель на основе зрения может быть построена с помощью пары слоев CNN для выполнения простой задачи классификации изображений, например, определения, является ли данное изображение собакой или кошкой.
Однако для классификации более сложных изображений с большим количеством классов необходимо строить более глубокие модели, состоящие из сотен слоев CNN. Чем глубже слои модели, тем выше риск столкнуться с проблемой исчезающего градиента. Под исчезающим градиентом понимается явление, когда во время обучения модели градиент становится настолько мал, что модель не может ничему научиться и обновить свои веса.
Для решения этой проблемы в архитектуру модели были внедрены сложные алгоритмы, такие как residual connections, позволяющие избежать проблемы исчезающего градиента, часто возникающей в моделях глубокого обучения. Этот метод оказался эффективным, что привело к появлению модели ResNet, которая впоследствии достигла передовых результатов во многих эталонных наборах данных для классификации изображений.
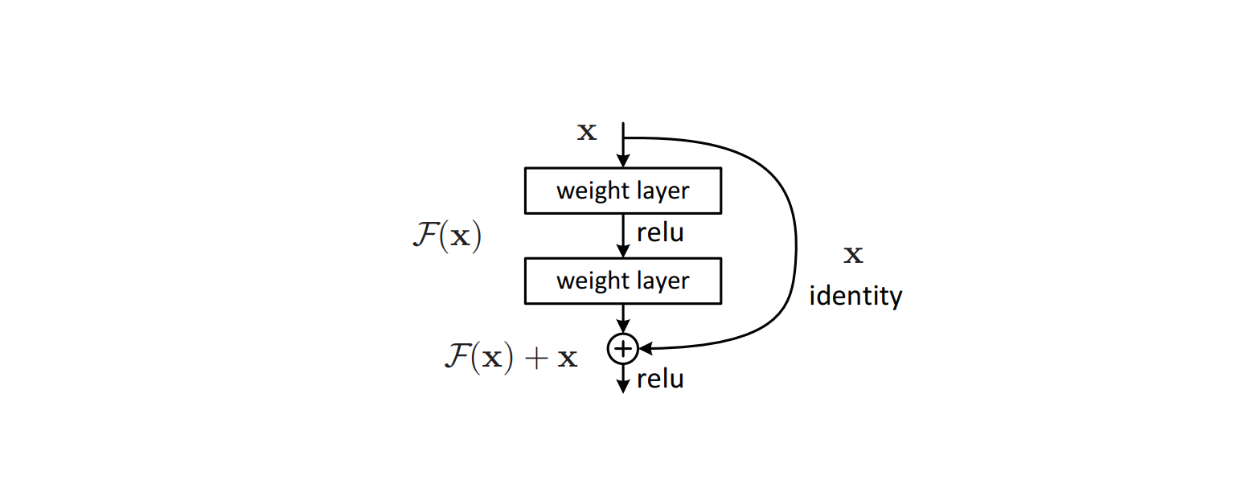
Фигура: Строительный блок остаточной связи в архитектуре модели. Источник.
Успех ResNet вдохновил другие архитектуры моделей, способные выполнять более сложные задачи, связанные с изображениями. Визуальные модели, такие как YOLO, реализовали остаточные связи в своей архитектуре для выполнения задач обнаружения объектов. В то же время U-Net использовала комбинацию U-образной архитектуры и остаточных связей для выполнения задач сегментации изображений.
Хотя эти визуальные модели могут выполнять задачи, основанные на визуальном восприятии, каждая из них может выполнять только одну конкретную задачу. Если модель была обучена классификации изображений, она может быть использована только для этой цели. Кроме того, если мы попросим модель классифицировать изображение, значительно отличающееся от тех, что были в обучающих данных, мы можем наблюдать некоторую случайность в предсказаниях модели.
Появление в 2017 году знаменитой модели Transformers вызвало бурное развитие моделей глубокого обучения в целом. Модели, использующие в своей архитектуре Transformers, значительно превзошли более традиционные модели. Изначально предназначенная только для текстовых моделей, архитектура Transformers оказалась достаточно универсальной, чтобы использоваться и в моделях, основанных на зрении.
Модели зрения на основе трансформеров, такие как Vision Transformers (ViT), продемонстрировали высокие возможности при выполнении задач классификации изображений. В результате ViT сегодня используется многими популярными моделями текстового зрения, такими как CLIP, в качестве базовой архитектуры.
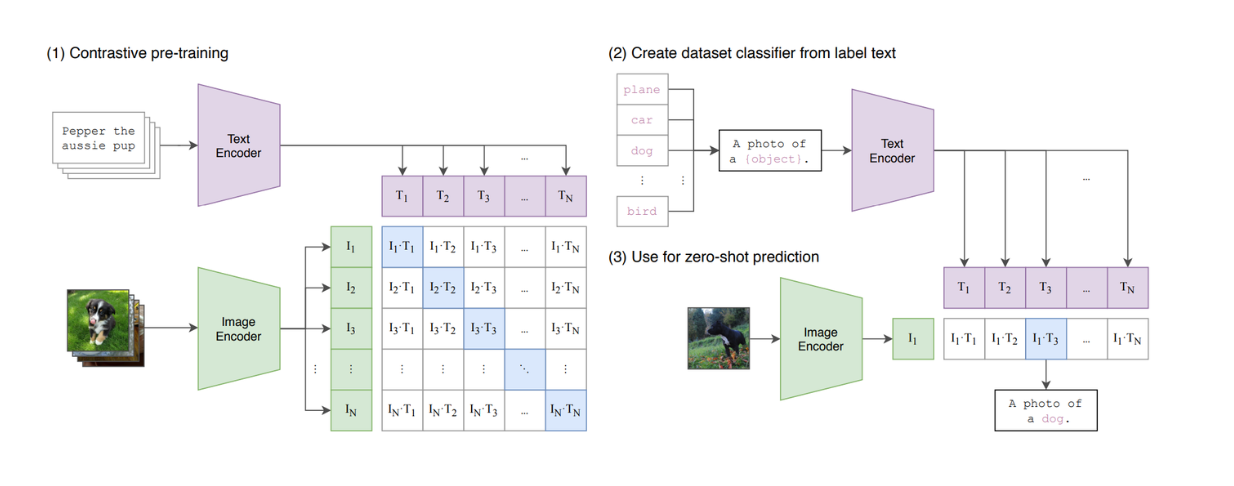
Рисунок: Краткое описание модели CLIP. Источник.
CLIP - это модель, объединяющая в своей архитектуре ViT и BERT-подобную модель. ViT обрабатывает изображения, а BERT-подобная модель - текстовые данные. CLIP был обучен с помощью контрастирующего обучения, в результате которого, когда на вход подаются текст и изображение, CLIP вычисляет сходство между текстом и изображением. Однако мы видим, что CLIP все еще ограничен в своей способности имитировать текстовые LLM, поскольку он не является генеративной моделью.
LLaVA - одна из самых ранних визуально-ориентированных LLM, способная принимать на вход текстовые инструкции и изображения и генерировать соответствующий ответ. Мы обсудим детали LLaVA в следующем разделе.
Что такое LLaVa?
LLaVA (Large Language and Vision Assistant) - это мультимодальная модель, которая сочетает в себе текстовые модели большого языка (LLM) с возможностями визуальной обработки, что позволяет ей работать с текстовыми и графическими данными. Она предназначена для выполнения таких задач, как обобщение визуального контента, извлечение информации из изображений и ответы на вопросы о визуальных данных.
LLaVA опирается на успех LLM, поскольку включает в себя визуальное понимание и согласовывает текстовые инструкции с анализом изображений. Такая интеграция позволяет модели обрабатывать парные данные - текстовые подсказки и изображения - и выдавать последовательные и контекстуально релевантные ответы.
Архитектура LLaVA
Архитектура LLaVA относительно проста. Она использует предварительно обученный LLM для обработки текстовых инструкций и визуальный кодер из предварительно обученного CLIP, модель ViT, для обработки информации об изображении.
Среди нескольких общедоступных предварительно обученных LLM авторы LLaVA выбрали Vicuna в качестве основы для обработки текстовой информации и генерирования окончательного ответа, если на вход подается пара текст-изображение.
Поскольку большинство текстовых LLM основаны на архитектуре Transformer, процесс преобразования текста до генерации ответа довольно прост. Каждая лексема во входном тексте преобразуется во вставку, затем она проходит через несколько стопок слоев внимания и плотных слоев, после чего на выходе получается конечный признак с фиксированной размерностью.
Для обработки входных изображений LLaVA использует предварительно обученную модель ViT в CLIP для преобразования входного изображения в представление признаков с фиксированной размерностью. Однако размерность признака изображения из CLIP отличается от размера признака текста из Vicuna. Поэтому LLaVA реализует простой плотный слой, чтобы спроецировать изображение на тот же размер, что и текстовый признак из Vicuna.
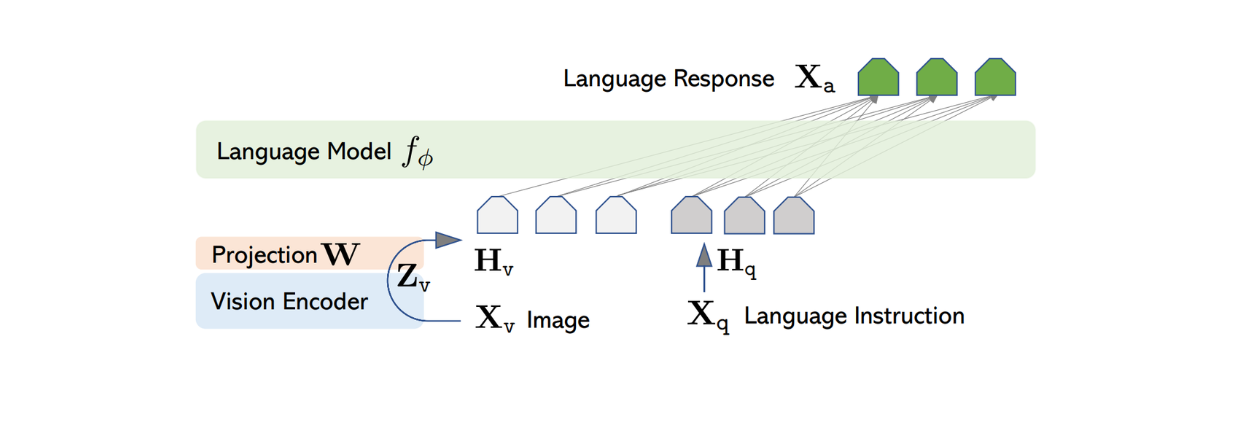
Рисунок: Архитектура LLaVA. Источник.
Теперь, когда изобразительные и текстовые признаки имеют одинаковый размер, необходимо найти подход для объединения этих двух признаков в один. Для этого обычно используется несколько подходов, например простое добавление признака изображения перед признаком лексемы ([признак изображения] + [признак текста]) или использование более сложных алгоритмов, таких как gated cross-attention и Q-former. Затем объединенные изображения и текстовые признаки поступают в Vicuna, что позволяет ей генерировать соответствующий ответ.
Однако при использовании вышеупомянутого подхода качество ответа, генерируемого Vicuna или другими подобными LLM, может быть неоптимальным. Это вполне ожидаемо, поскольку LLM обучаются исключительно на текстовых данных. Поэтому LLaVA нуждается в тонкой настройке, прежде чем она сможет генерировать согласованные ответы на основе пары "изображение-текст". Этот процесс тонкой настройки называется [настройка визуальных инструкций] (https://arxiv.org/abs/1512.03385), который мы рассмотрим в следующих разделах.
Процесс генерации данных для настройки визуальных инструкций
Настройка визуальных инструкций - это процесс обучения мультимодальных моделей ИИ пониманию и реагированию на текстовые инструкции в сочетании с визуальными данными, такими как изображения или видео. Эта техника позволяет совместить визуальное понимание с возможностями обработки естественного языка, что дает модели возможность выполнять такие задачи, как создание подписей к изображениям, визуальные ответы на вопросы, распознавание объектов и извлечение информации.
Одной из ключевых проблем настройки визуальных инструкций является отсутствие общедоступных данных о следовании мультимодальным инструкциям. Хотя существует несколько наборов данных, состоящих из пар изображение-текст, таких как CC и LAION, они не совсем соответствуют тому типу наборов данных, который мы хотели бы использовать для точной настройки визуальных LLM на выполнение инструкций пользователя.
Рисунок: Пример набора данных CC. Источник.
С другой стороны, ручное создание огромного количества мультимодальных данных о следовании инструкциям для настройки LLaVA потребует значительных усилий и времени. Поэтому мы можем использовать GPT-4 или ChatGPT для ускорения процесса создания мультимодальных данных следования инструкциям.
Как видно из приведенного выше примера с изображением CC, обычные мультимодальные наборы данных состоят из пары "изображение - текст подписи" в каждой записи данных. С помощью ChatGPT, получив изображение и подпись к нему, мы можем сгенерировать набор возможных вопросов, предназначенных для обучения LLM описанию содержания изображения. Формат данных мультимодальных инструкций будет выглядеть следующим образом: Человек: Xq Xv
Однако мы знаем, что предыдущие итерации ChatGPT принимали на вход только текст. Чтобы использовать его для составления списка вопросов по конкретному изображению, нам нужно предоставить информацию или метаданные об изображении. Авторы использовали два различных подхода, чтобы предоставить ChatGPT необходимую информацию о любом входном изображении: подписи и ограничительные рамки. Подписи обычно состоят из подробного описания изображения, а ограничительные рамки предоставляют ChatGPT полезную информацию о точном расположении объектов на изображении.

Рисунок: Пример надписей и ограничительных рамок для получения визуальной информации для текстового GPT-4. Источник.
Авторы создали три типа наборов данных мультимодальных инструкций:
Разговор: Состоит из разговора между LLM и пользователем. Ответы LLM задаются таким тоном, как будто он смотрит на изображение, а затем отвечает на вопросы пользователя. Типичные вопросы включают в себя визуальное содержание изображения, подсчет объектов на изображении, относительное положение объектов на изображении и т. д.
Подробные описания: состоят из списка вопросов, предназначенных для создания исчерпывающих описаний изображения.
Сложные рассуждения: состоят из вопросов, выходящих за рамки двух вышеперечисленных типов. Вместо того чтобы просто описать визуальное содержание изображения, эти вопросы заставляют LLM объяснить логику, лежащую в основе его ответов, требуя пошаговых рассуждений.

Рисунок: Пример трех типов наборов данных мультимодальных инструкций. Источник.
Ниже приведен пример подсказки, использованной авторами для создания набора данных разговорного типа:
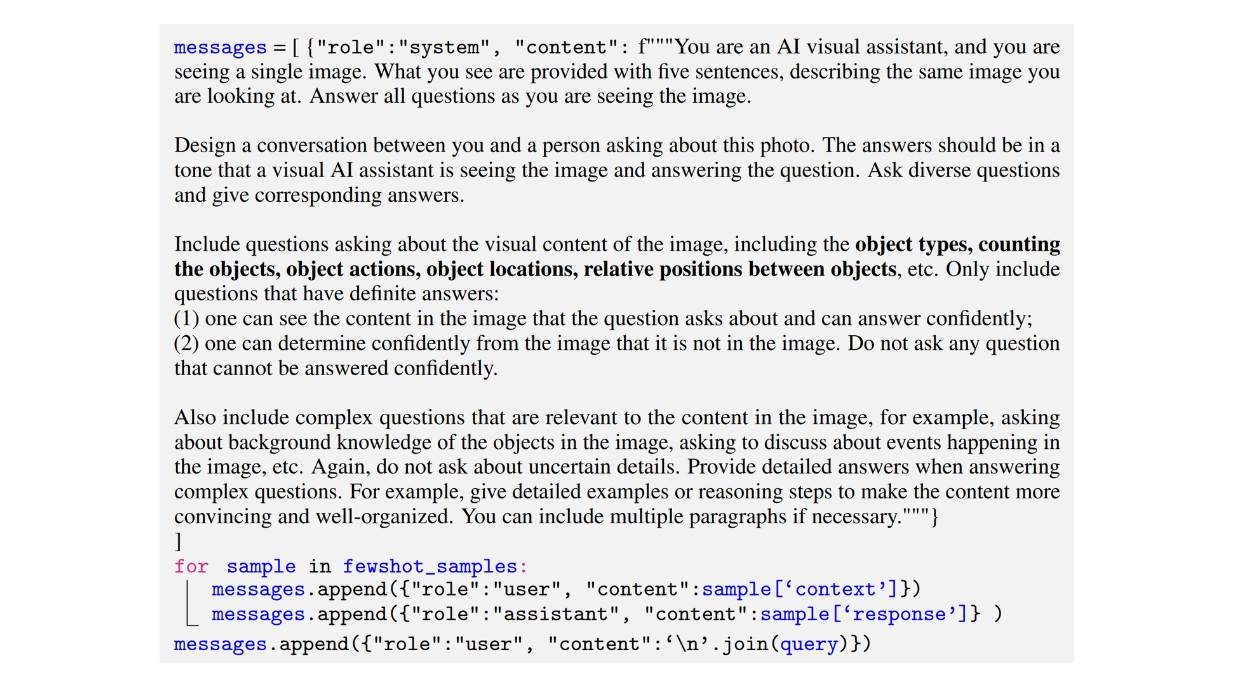
Рисунок: Пример подсказки, использованной для создания набора данных мультимодальных инструкций-следований разговорного типа. Источник.
Получить желаемый результат в правильном формате из сгенерированных LLM мультимодальных данных следования инструкциям довольно сложно. Поэтому, попросив ChatGPT сгенерировать все три типа наборов данных мультимодальных инструкций, авторы использовали несколько образцов, чтобы использовать возможности внутриконтекстного обучения.
В примере с несколькими снимками авторы предоставили несколько созданных вручную примеров разговоров между LLM и пользователем, сопровождающих подсказку. Эти примеры помогают ChatGPT лучше понять структуру ожидаемого вывода. Ниже приведен пример примера с несколькими снимками, реализованного авторами в подсказке для создания набора данных разговоров.

Рисунок: Пример примера из нескольких кадров, передаваемого вместе с подсказкой для внутриконтекстного обучения. Источник.
Процедура обучения LLaVA
Общее количество мультимодальных данных о следовании инструкциям, сгенерированных с помощью вышеупомянутого подхода, составило около 158K. Затем на основе этих мультимодальных данных была проведена тонкая настройка модели LLaVA.
В наборе данных, для каждого изображения Xv, есть многооборотные разговоры между ЛЛМ и пользователями (X1q, X1a, - - - , XTq, XTa), где T - общее количество оборотов. Для каждого оборота t ответ Xta рассматривается как ответ LLM, и, следовательно, инструкция на оборот t будет такой:
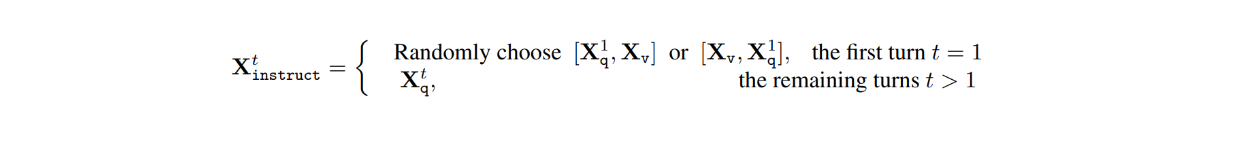
Далее, в процессе настройки визуальных инструкций, было проведено два этапа: предварительное обучение для выравнивания признаков и тонкая сквозная настройка.
На этапе предварительного обучения для выравнивания признаков основной целью является обучение проекционного слоя, который отображает выход ViT-модели из предварительно обученного кодера CLIP в конечный визуальный признак, имеющий ту же размерность, что и текстовый признак. На данном этапе обучение проводилось на отфильтрованном наборе данных CC, содержащем 596 тыс. пар "изображение-текст". Для каждого изображения Xv случайным образом выбирается вопрос Xq из пула вопросов, а соответствующий Xc используется в качестве истинной метки. Таким образом, для обучения выбираются вопросы, которые просят LLM кратко описать изображение, как показано на изображении ниже:

Рисунок: Пример подсказок для краткого объяснения содержания изображения. Источник.
Поскольку мы обучаем только проекционный слой, веса ViT и LLM на этом этапе заморожены.
Тем временем на втором этапе, который является сквозной тонкой настройкой, модель LLaVA настраивается с помощью 158K сгенерированных данных мультимодального следования инструкциям. На этом этапе замораживаются только веса ViT, а веса проекционного слоя и LLM обновляются в процессе тонкой настройки.
Результаты LLaVA
Для оценки эффективности LLaVA было проведено сравнение с другими современными моделями, такими как GPT-4, и моделями на основе визуального восприятия, такими как BLIP-2 и OpenFlamingo. Для оценки результатов авторы использовали только текстовый GPT-4 в качестве судьи для оценки качества ответов на основе полезности, релевантности, точности и уровня детализации.
В качестве первой оценки были выбраны 30 случайных изображений из набора данных COCO-Val-2014, и с помощью процесса генерации данных, описанного в предыдущем разделе, были сгенерированы три типа наборов данных. В результате было получено в общей сложности 90 точек данных: 30 для разговоров, 30 для подробных описаний и 30 для сложных рассуждений. Затем ответы LLaVA были сравнены с результатами модели GPT-4, использующей только текстовое описание/капчу в качестве метки и ограничительные рамки в качестве визуального ввода. Результаты оказались следующими:
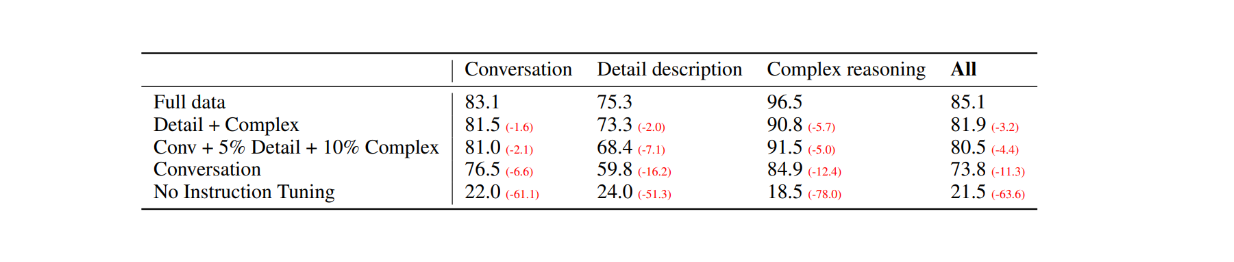
Рисунок: Сравнение производительности LLaVA и текстового GPT-4 на 30 случайных изображениях. Источник.
При настройке визуальных инструкций способность модели следовать инструкциям увеличилась по меньшей мере на 50 пунктов в каждом типе наборов данных. При этом относительный результат LLaVA был не намного ниже, чем у модели GPT-4, использующей в качестве визуального ввода подписи к изображениям, о чем свидетельствуют цифры в скобках в каждой категории.
Производительность LLaVA также сравнивалась с моделями на основе визуальных данных, такими как BLIP-2 и OpenFlamingo, для чего сначала было взято 24 случайных изображения с 60 вопросами в общей сложности. Как показано в таблице ниже, производительность LLaVA значительно превосходит две другие модели на основе визуальных инструкций. Это демонстрирует возможности настройки визуальных инструкций, так как BLIP-2 и OpenFlamingo не были специально настроены с помощью мультимодального набора данных по следованию инструкциям.

Рисунок: Сравнение производительности LLaVA и BLIP-2 и OpenFlamingo. Источник.
Теперь давайте рассмотрим пример реакции моделей в действии. Рассмотрим изображение куриных котлеток, образующих карту мира, и спросим: "Можете ли вы подробно объяснить этот мем?" Ниже приведены примеры ответов от LLaVA, текстового GPT-4, BLIP-2 и OpenFlamingo.

Рисунок: Примеры ответов от LLaVA, GPT-4, BLIP-2 и OpenFlamingo. Источник.
Как видно, модели BLIP-2 и OpenFlamingo не смогли выполнить инструкцию, так как не были настроены с помощью визуальной настройки инструкции. Тем временем LLaVA продемонстрировала свои способности к визуальному мышлению в понимании юмора. Вместе с GPT-4 она смогла дать лаконичный ответ в соответствии с инструкцией.
При точной настройке на наборе данных ScienceQA в течение примерно 12 эпох LLaVA также достигла очень конкурентоспособных результатов по сравнению с моделью MM-CoT, которая в настоящее время является самой современной моделью (SOTA) на этом наборе данных. Как показано в таблице ниже, LLaVA достигла общей точности 90,92 % по нескольким различным предметам по сравнению с 91,68 % у модели MM-CoT. Однако, когда результаты LLaVA были объединены с GPT-4, производительность достигла нового уровня SOTA на наборе данных ScienceQA с точностью 92,53 %.
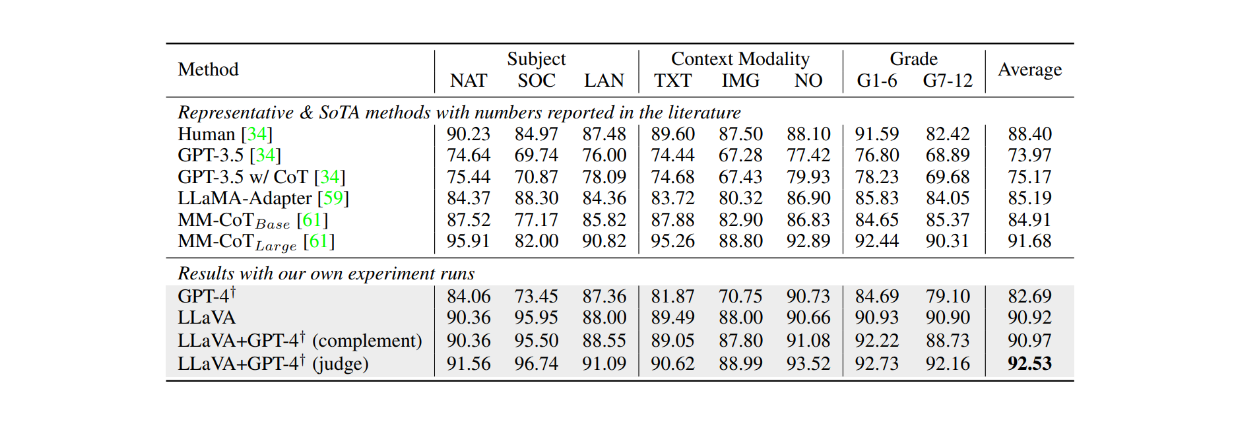
Рисунок: Точность LLM на наборе данных ScienceQA. Источник.
Заключение
LLaVA представляет собой раннее достижение в разработке визуальных моделей большого языка (LLM), способных следовать текстовым инструкциям. Модель сочетает в себе предварительно обученный трансформатор Vision Transformer (ViT) из CLIP для обработки изображений и Vicuna в качестве основы языковой модели, используя проекционный слой для выравнивания размеров признаков между двумя компонентами. Затем модель была отлажена на 158 тыс. образцов данных о следовании мультимодальным инструкциям.
Благодаря такому подходу к настройке визуальных инструкций LLaVA может описывать и выполнять сложные рассуждения на заданном изображении в соответствии с инструкциями в подсказке. Результаты оценки демонстрируют эффективность настройки визуальных инструкций, поскольку производительность LLaVA стабильно превосходит две другие модели, основанные на визуальном восприятии: BLIP-2 и OpenFlamingo.
Дальнейшее чтение
Читать далее

Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
Learn how vector-based code retrieval cuts Claude Code token consumption by 40%. Open-source solution with easy MCP integration. Try claude-context today.

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.