




Улучшение RAG с помощью графиков знаний с помощью KnowHow
Retrieval Augmented Generation (RAG) - это популярная техника, которая предоставляет LLM дополнительные знания и долгосрочную память через векторную базу данных, такую как Milvus и Zilliz Cloud (полностью управляемый Milvus). Базовый RAG может решить многие головные боли LLM, но его недостаточно, если у вас есть более сложные требования, такие как настройка или больший контроль над полученными результатами.
На нашем недавнем Unstructured Data Meetup Крис Рек, соучредитель WhyHow, рассказал о том, как он включает графы знаний (Knowledge Graphs, KG) в конвейер RAG для повышения производительности и точности. В этом блоге будут рассмотрены ключевые моменты его выступления, включая обзор графов знаний, RAG и способов интеграции графов знаний в системы RAG для повышения производительности.
Если вы хотите узнать больше об этой теме, мы рекомендуем вам посмотреть весь доклад на YouTube.
.Обзор RAG и его проблем
RAG - это метод, который использует сильные стороны как поисковых систем, так и генеративных систем искусственного интеллекта. Ванильный RAG обычно включает в себя векторную базу данных, например Milvus, модель embedding model и большую языковую модель (LLM.
Система RAG сначала использует модель встраивания для преобразования документов в векторные вкрапления и хранения их в векторной базе данных. Затем она извлекает релевантную информацию для запроса из этой векторной базы данных и предоставляет полученные результаты LLM. Наконец, LLM использует полученную информацию в качестве контекста для создания более точных результатов.
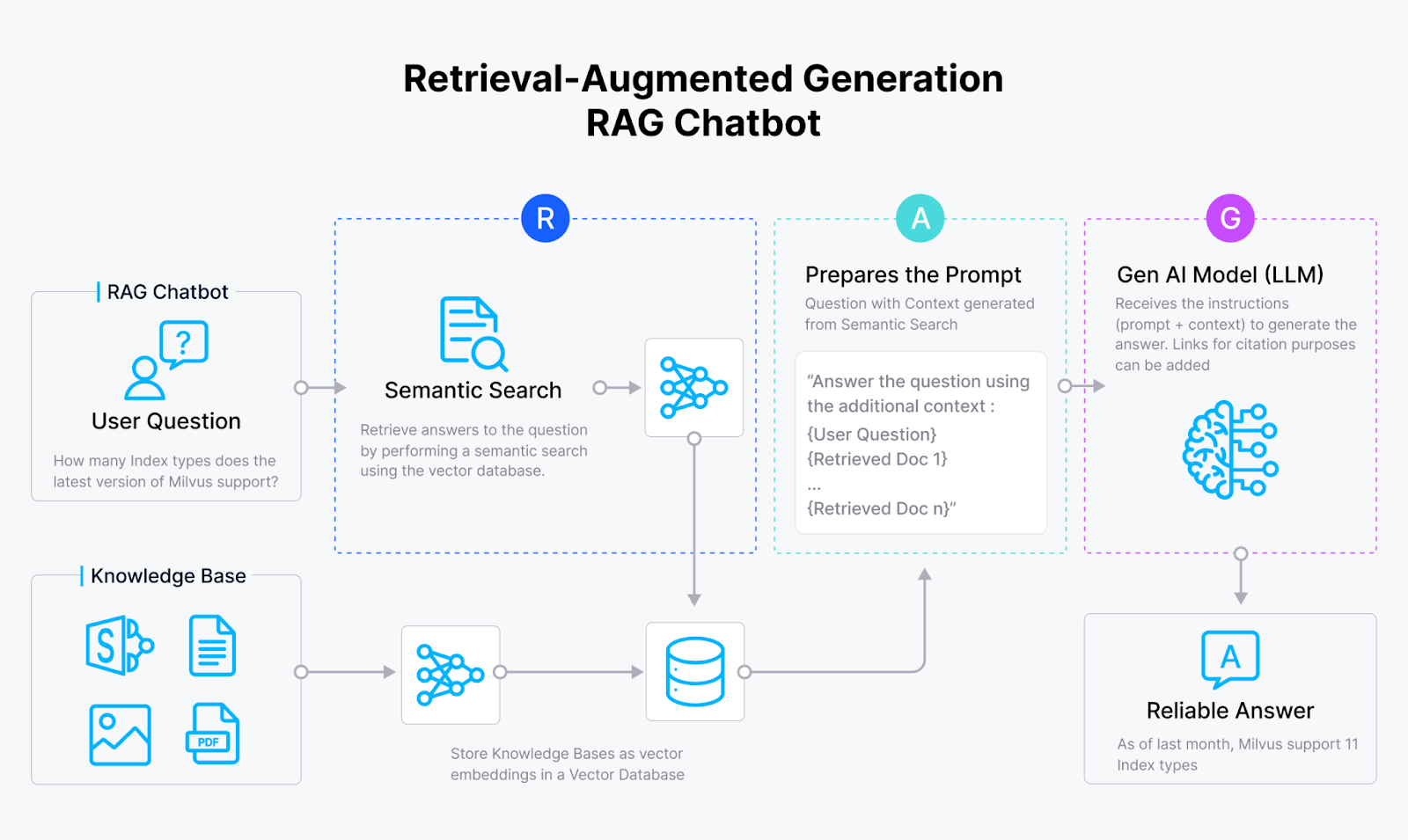 Рабочий процесс RAG
Рабочий процесс RAG
Рис. 1: Как работает RAG
Хотя ванильный RAG прекрасно подходит для получения более актуальных и точных результатов, у него все же есть несколько ограничений.
**Например, термин "вместимость автомобиля" может означать как количество пассажиров, которое может вместить автомобиль, так и количество автомобилей, которые могут поместиться на дороге, что создает двусмысленность.
**Например, ответы на запросы, связанные с местоположением, такие как "Я хочу поехать в Лондон", значительно отличаются от ответов на более абстрактные запросы, связанные с состоянием здоровья, такие как "У меня стресс на работе, и я хочу взять отпуск".
В-третьих, нелегко провести различие между сходством и релевантностью. Например, бывает трудно провести различие между "пляжным домиком" в миле от берега и "домиком на берегу" прямо на песке.
В-четвертых, полнота ответов также вызывает озабоченность. Извлечение всей релевантной информации для комплексных вопросов может быть сложной задачей, особенно для сложных запросов, таких как список всех ограниченных партнеров (LP) в фонде, которые инвестировали не менее 10 миллионов долларов и имеют специальные права доступа к данным.
Наконец, многоцелевые запросы добавляют еще один уровень сложности, поскольку требуют точного объединения нескольких частей информации. Такой подход требует разбиения запроса на несколько подзапросов, каждый из которых имеет определенные условия, что обеспечивает точность и полноту конечного ответа.
Хотя такие решения, как улучшение оперативности, усовершенствованные стратегии разбиения на части, лучшие модели встраивания и повторное ранжирование, могут решить многие проблемы, связанные с RAG, WhyHow использует другой подход, включив графы знаний в конвейер RAG.
Что такое графы знаний (ГЗ)?
Граф знаний (ГЗ) - это тип структуры данных, которая не только хранит данные, но и связывает похожие или непохожие данные на основе их взаимосвязи. Такой подход позволяет получить коллекцию вещей (это могут быть данные любого типа), связанных между собой таким образом, что можно получить связанную или релевантную информацию.
Граф знаний состоит из узлов, ребер и свойств.
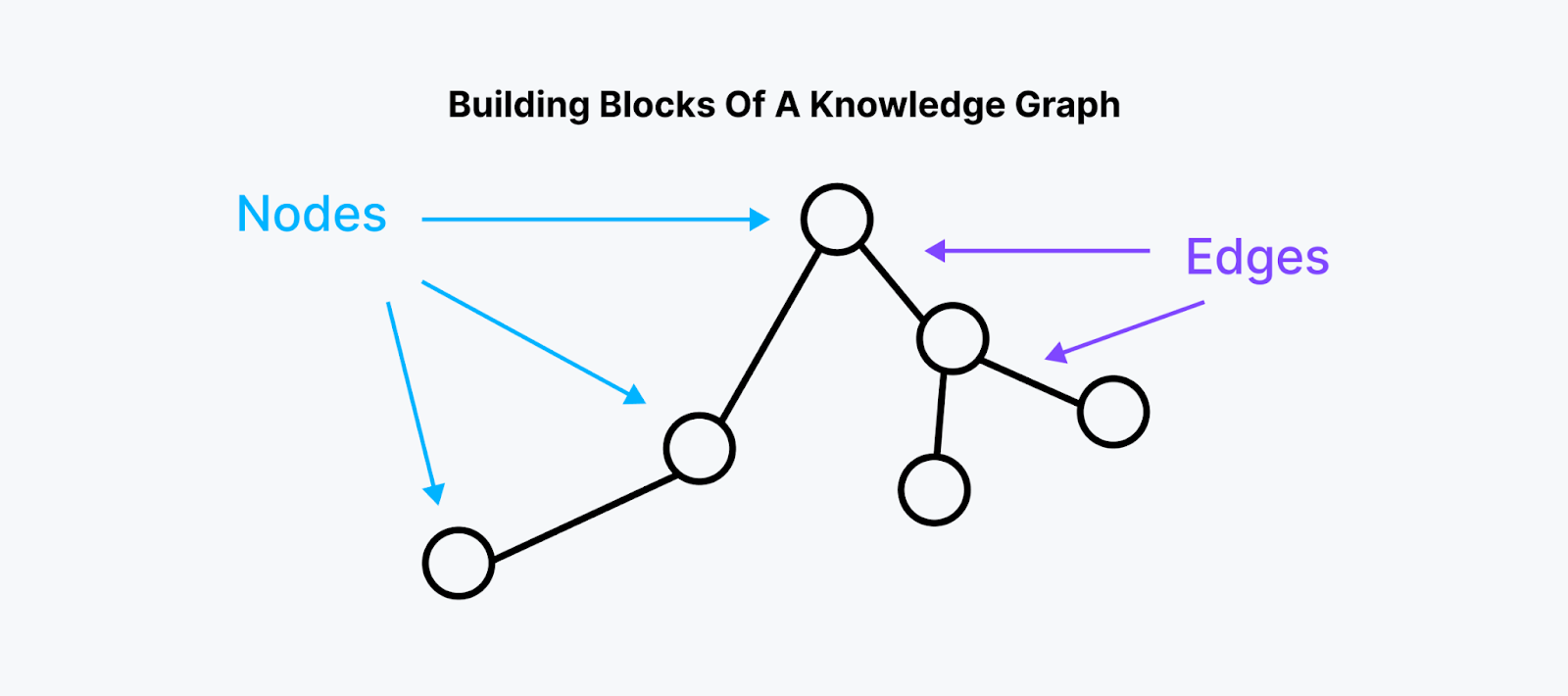 Рис. 2- Строительные блоки графа знаний
Рис. 2- Строительные блоки графа знаний
Рис. 2: Строительные блоки графа знаний
** Узлы:**
Представляют сущности или объекты в графе.
Хранимые значения этих сущностей могут быть любыми типами данных.
** Грани:**
Представляют собой отношения между сущностями.
Хранят информацию о характере отношений между связанными узлами.
Свойства: Характеристики или особенности, связанные с отдельными сущностями.
В отличие от традиционных табличных баз данных, графы знаний используют графовую структуру для гибкого представления связей и ориентированы на семантическое понимание. Такой подход позволяет выполнять сложные запросы и извлекать конкретную информацию.
Преимущества интеграции графов знаний в системы RAG
Включив графы знаний в систему RAG, мы можем значительно повысить поисковые возможности системы и качество ответов, что приведет к повышению производительности, точности, прослеживаемости и полноты. Вот основные преимущества системы RAG на основе графов знаний:
Улучшенное контекстное понимание
Графы знаний обеспечивают богатое, взаимосвязанное представление информации, позволяя системе RAG улавливать сложные взаимосвязи между объектами. Такое более глубокое понимание контекста приводит к более тонким и релевантным ответам.
Повышение точности и согласованности фактов
Структурированная природа графов знаний помогает поддерживать последовательность фактов в генерируемом контенте. Привязывая ответы к проверенной информации в графе, система может уменьшить количество ошибок и галлюцинаций, характерных для традиционных языковых моделей.
Возможности многоходовых рассуждений
Графы знаний позволяют системе RAG выполнять многоходовые рассуждения, соединяя разрозненные фрагменты информации логическими путями. Эта возможность позволяет выполнять более сложные запросы и генерировать выводы.
Эффективный поиск информации
Графовая структура способствует быстрому и точному поиску информации даже по сложным запросам. Такая эффективность приводит к ускорению времени отклика и созданию более релевантного контента. Кроме того, системы RAG на основе графов знаний позволяют использовать гибридный подход к поиску, сочетая обход графов с [векторным поиском и поиском по ключевым словам] (https://zilliz.com/blog/a-review-of-hybrid-search-in-milvus) - возможностями, предоставляемыми векторными базами данных, такими как Milvus и Zilliz Cloud.
Более конкретно, этот гибридный подход позволяет:
Точное сопоставление сущностей и отношений с помощью обхода графов
семантическое сходство сопоставление с помощью векторных вкраплений
Традиционный поиск по ключевым словам для контента с большим объемом текста
Эта многогранная стратегия поиска повышает способность системы находить наиболее релевантную информацию в различных типах и структурах данных, что приводит к более полным и точным ответам.
Прозрачные и отслеживаемые результаты
С помощью графов знаний система может обеспечить четкое подтверждение информации, используемой при создании ответов. Такая прослеживаемость повышает доверие пользователей и позволяет легче проверять факты.
Синтез междоменных знаний
Представляя различные области в рамках единой структуры графов, системы RAG на основе графов знаний могут легче синтезировать информацию из разных областей, что приводит к более полному и междисциплинарному пониманию.
Улучшенная обработка неоднозначности
Реляционная структура графов знаний помогает определить сущности и понятия, уменьшая путаницу в ситуациях, когда термины или названия могут иметь несколько значений или ссылок.
Используя эти преимущества, приложения RAG, дополненные графами знаний, могут предоставлять более точные, контекстуально релевантные и полные ответы на запросы пользователей.
Что такое WhyHow? Как она улучшает RAG с помощью графов знаний?
WhyHow - это платформа для построения и управления графами знаний для поддержки поиска сложных данных. Построение всеобъемлющих графов знаний - сложная и трудоемкая задача. WhyHow решает эту проблему путем создания небольших графов знаний и их многократной итерации до тех пор, пока не появится удовлетворительный граф знаний для конкретной области. Такой подход позволяет сделать его специфичным для конкретной области, упростить и облегчить работу с ним, поскольку КГ являются сложными.
WhyHow также предоставляет разработчикам строительные блоки для организации, контекстуализации и надежного получения неструктурированных данных для выполнения сложных RAG. Интегрировав WhyHow в существующие конвейеры RAG на основе векторной базы данных, вы сможете сделать свою систему RAG более структурированной, согласованной и контролируемой. На схеме ниже показано, как работает RAG с использованием Knowledge Graph.
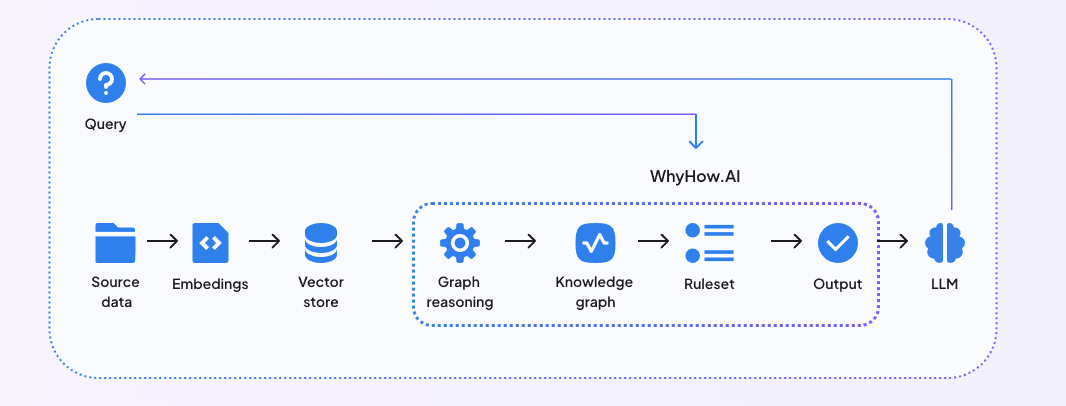 Рис. 3 Интеграция RAG с WhyHow
Рис. 3 Интеграция RAG с WhyHow
Рис. 3: Интеграция RAG с WhyHow
Включив WhyHow в рабочий процесс RAG, вы можете использовать гибридный графо-векторный подход, используя лучшие возможности графов знаний и векторного поиска, предоставляемые векторными базами данных.
Для получения более подробного руководства по созданию RAG с использованием графа знаний и WhyHow мы рекомендуем вам посмотреть живую демонстрацию, которой Крис поделился во время встречи по неструктурированным данным, организованной Zilliz.
Больше контроля над рабочими процессами поиска в RAG с помощью WhyHow и Zilliz Cloud
Помимо повышения производительности и отслеживаемости приложений RAG, многие разработчики также надеются получить больший контроль над тем, что извлекает их RAG. Это связано с тем, что приложения RAG иногда не могут последовательно получить нужные фрагменты данных, когда пользователи отправляют плохо сформулированные запросы или когда им необходимо включить в ответы контекстно-значимые, но семантически несхожие данные.
Для решения этих проблем WhyHow создает Rule-based Retrieval Package путем интеграции с Zilliz Cloud. Этот пакет на языке Python позволяет разработчикам создавать более точные рабочие процессы поиска с расширенными возможностями фильтрации, обеспечивая им больший контроль над процессом поиска в рамках конвейеров RAG. Этот пакет интегрируется с OpenAI для генерации текста и Zilliz Cloud для хранения и эффективного векторного поиска по сходству с фильтрацией метаданных.
Решение для поиска на основе правил выполняет такие задачи:
** Создание векторного хранилища:** Создание коллекции Milvus для хранения вкраплений чанков.
Разделение, Chunking** и встраивание:** Автоматическое разделение, разбиение на куски и создание вкраплений для загруженных документов с помощью PyPDFLoader и RecursiveCharacterTextSplitter от LangChain, а также поддержка модели OpenAI text-embedding-3-small.
Вставка данных: Загрузка вкраплений и метаданных в Milvus или Zilliz Cloud.
Автофильтрация: Построение фильтра метаданных на основе заданных пользователем правил для уточнения запросов к хранилищу векторов.
Рабочий процесс выглядит следующим образом:
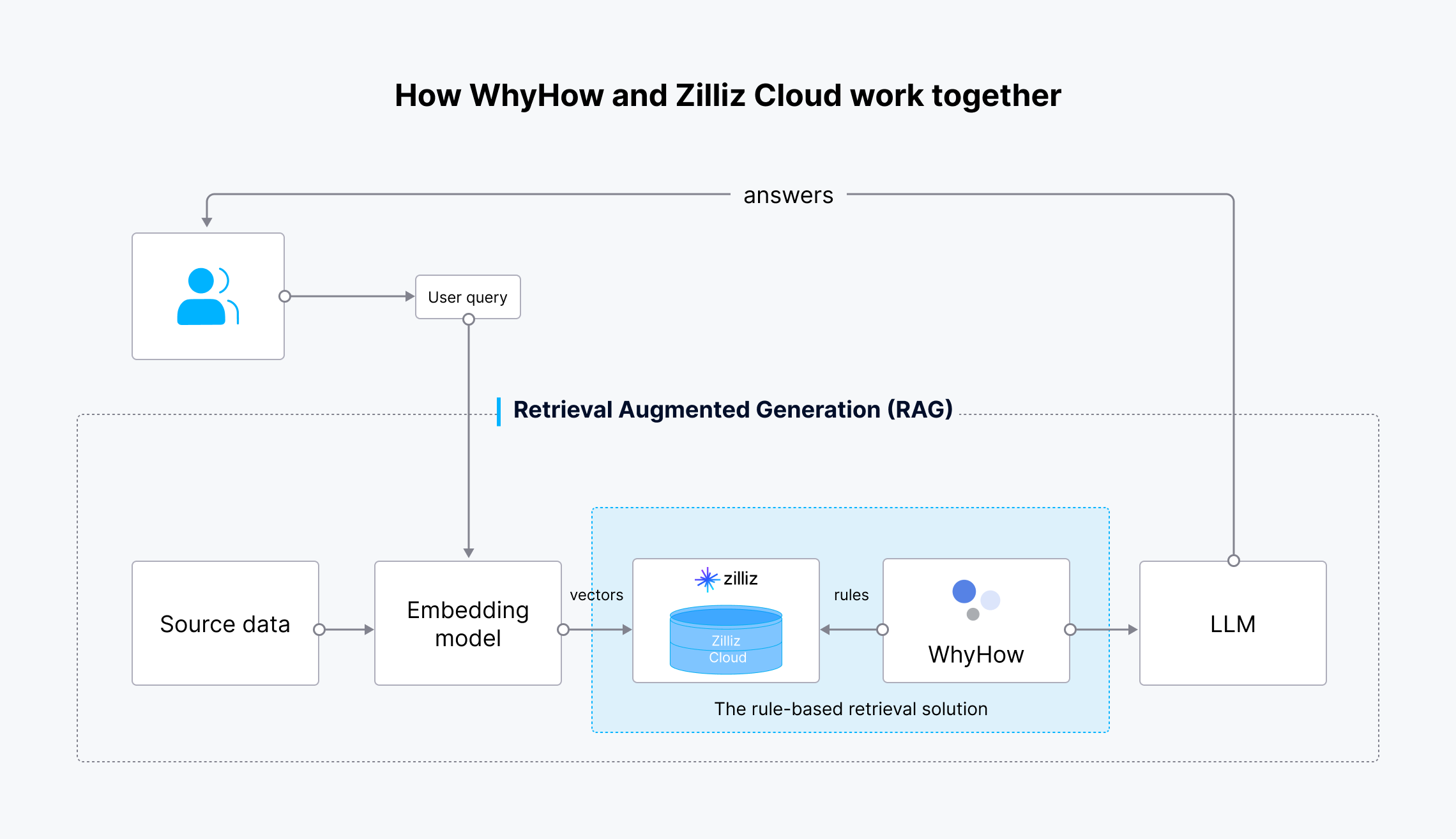 Как работают вместе WhyHow и Zilliz Cloud
Как работают вместе WhyHow и Zilliz Cloud
Рис. 4: Рабочий процесс решения для извлечения информации на основе правил
Исходные данные преобразуются в векторные вкрапления с помощью модели вкрапления OpenAI и поступают в Zilliz Cloud для хранения и поиска. Когда пользователь делает запрос, он также преобразуется в векторные вкрапления и отправляется в Zilliz Cloud для поиска наиболее релевантных результатов. WhyHow устанавливает правила и добавляет фильтры к векторному поиску. Полученные результаты, а также исходный запрос пользователя отправляются в LLM, который генерирует более точные результаты и отправляет их пользователю.
Заключение
LLM действительно облегчили наше бремя поиска ответов на различные проблемы. Они достаточно умны, чтобы понять запрос, но галлюцинируют, и их трудно поддерживать в актуальном состоянии из-за нехватки ресурсов. Поэтому техника расширенного поиска (retrieval augmented generation, RAG) расширяет их возможности, предоставляя контекст запросу; однако у систем RAG есть и ограничения, о которых мы уже говорили.
WhyHow выявил эти ограничения, подчеркнув, что решение заключается во включении графов знаний в конвейеры RAG. Дополнив RAG графами знаний, ваши системы RAG смогут получать более релевантную и контекстную информацию и генерировать более детерминированные ответы с меньшим количеством галлюцинаций и высокой точностью.
Если вы хотите глубже погрузиться в эту тему, посмотрите [презентацию Криса на YouTube] (https://www.youtube.com/watch?v=6pjObdJdyFs).
Дополнительные ресурсы

Читать далее

How Zilliz Saw the Future of Vector Databases—and Built for Production
An inside look at how Zilliz built vector databases for real-world use, focusing on scalability, stability, and running them reliably at scale.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.