




딥 강화 학습(DRL) 이해하기: 종합 가이드
짧은 답변: 딥 강화 학습(DRL)은 에이전트가 환경과 상호작용하고 피드백 또는 "보상"을 기반으로 시간이 지남에 따라 개선되면서 의사결정 방법을 학습하는 AI 분야입니다. DRL은 시행착오를 통한 학습 방법인 강화 학습(RL)과, 이미지나 센서 판독값 같은 복잡한 데이터를 에이전트가 처리할 수 있게 해주는 딥 러닝을 결합합니다. DRL은 딥 신경망을 사용하여 에이전트가 고차원 입력이 있는 복잡한 작업을 탐색하도록 가르칠 수 있습니다. 환경의 복잡성과 변동성 때문에 기존 학습 방법이 어려움을 겪는 로보틱스와 게임 플레이 같은 애플리케이션에서 널리 사용됩니다.
딥 강화 학습(DRL) 이해하기: 종합 가이드
2016년, AlphaGo가 우주의 원자 수보다 더 많은 가능한 수를 가진 게임인 바둑에서 세계 챔피언 이세돌을 이겼을 때, 이는 비즈니스 기술의 분수령이 되었습니다. 이 승리의 비결은 무엇이었을까요? 딥 강화 학습—테니스 선수가 코트에서 수년간 서브를 완성하듯, 컴퓨터가 연습을 통해 개선되도록 훈련하는 방법입니다. 기존 컴퓨터 프로그램이 예상치 못한 변화에 어려움을 겪는 반면, 이 기술은 바쁜 창고에서 로봇을 지휘하는 것부터 주식 거래에서 신속한 결정을 내리는 것까지 끊임없이 변화하는 상황에서 빛을 발합니다. 머신 러닝에 대한 이 새로운 접근 방식은 한때 일반 소프트웨어로 해결하기에는 너무 복잡했던 문제를 처리하며 기업에 새로운 가능성을 열어줍니다.
이 가이드는 딥 강화 학습에 대한 심층적인 탐구를 제공하며, 핵심 개념, 다양한 애플리케이션, 장점, 그리고 구현 과정에서 발생할 수 있는 과제를 강조합니다.
딥 강화 학습이란 무엇인가요?
딥 강화 학습(DRL)은 두 가지 효과적인 AI 기술인 강화 학습(RL)과 딥 러닝을 결합하여, AI 에이전트가 복잡한 환경에서 시행착오를 통해 최적의 행동을 학습할 수 있게 합니다. RL에서 에이전트는 환경과 상호작용하고 장기적 보상을 극대화하기 위해 보상과 학습 전략을 기반으로 행동을 조정합니다. 딥 러닝은 신경망을 사용해 상세한 상태 표현을 처리하는 능력을 추가합니다.
예를 들어, 미로를 탐색하는 로봇은 처음에는 무작위로 움직이지만, 시간이 지남에 따라 피드백을 통해 목표 지점에 효율적으로 도달하는 방법을 학습합니다. DRL은 에이전트가 동적인 환경에 적응하고 상세한 지시 없이 복잡한 문제를 해결하도록 돕습니다. 비디오 게임, 자율주행차, 개인화 추천에 유용합니다. 강화 학습과 딥 러닝을 결합함으로써 DRL 에이전트는 복잡한 실제 작업을 효과적으로 처리할 수 있습니다.
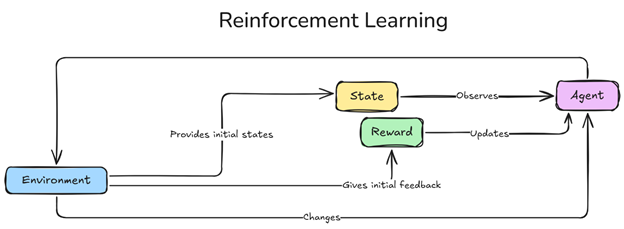 그림 1 강화 학습 프레임워크.png
그림 1 강화 학습 프레임워크.png
딥 강화 학습의 작동 방식
DRL이 어떻게 작동하는지 이해하려면 핵심 구성 요소를 아는 것이 중요합니다:
에이전트
환경
상태
행동과 보상
정책
에이전트
에이전트는 환경을 탐색하고 시간이 지남에 따라 누적 보상을 극대화하기 위한 선택을 하는 의사결정자입니다. 반복적인 상호작용(학습 에피소드)을 통해 에이전트는 피드백을 기반으로 전략을 개선하고, 장기적인 성공을 달성하기 위해 행동을 조정합니다. 게임 속 플레이어와 마찬가지로, 에이전트의 행동은 성능을 향상하고 최적의 결과에 도달하기 위해 시간이 지나며 학습된 규칙 집합인 정책에 의해 안내됩니다.
환경
환경은 에이전트가 작동하는 구조화된 공간으로, 가능한 상태, 행동, 보상을 정의합니다. 환경은 각 에이전트의 행동에 반응하여 에이전트의 향후 결정에 영향을 미치고 학습 과정을 형성하는 피드백을 제공합니다.
상태
상태는 특정 순간의 환경 스냅샷을 나타내며, 에이전트의 의사결정에 중요한 정보를 포함합니다. 예를 들어, 상태에는 미로에서 에이전트의 위치와 장애물, 또는 차량의 속도와 다른 자동차와의 근접성이 포함될 수 있습니다. 각 상태는 에이전트가 자신의 상황을 평가하고 가장 유리한 행동을 선택하는 데 도움을 줍니다.
행동과 보상
행동은 각 상태에서 에이전트의 선택을 나타내며, 환경을 통과하는 경로를 지시합니다. 행동은 다음과 같을 수 있습니다:
이산 행동: 그리드 환경에서 위, 아래, 왼쪽 또는 오른쪽으로 이동하는 것과 같은 제한된 옵션은 에이전트가 탐색하고 정책을 개발하기 쉽게 만듭니다.
연속 행동: 여기에는 속도나 각도를 조정하는 것과 같은 값의 범위가 포함되며, 증가된 복잡성을 처리하기 위해 고급 모델이 필요합니다.
에이전트는 시간이 지남에 따라 최적의 행동을 하고 보상을 최대화하는 것을 목표로 합니다.
보상은 에이전트의 학습을 안내하기 위한 피드백을 제공합니다. 긍정적 보상은 성공적인 행동을 나타내는 반면, 부정적 보상은 실수를 처벌합니다. 보상에는 다음이 포함될 수 있습니다:
즉각적 보상: 체스에서 상대의 말을 잡아 점수를 얻는 것처럼, 행동 직후에 직접 주어집니다.
지연 보상: 미로를 탐색하는 것처럼, 일련의 행동을 완료한 후 획득됩니다.
보상 형성이라고 알려진 보상 구조를 설계하는 것이 중요합니다. 예를 들어, 복잡한 경로를 따라 제공되는 중간 보상은 학습을 가속화하여 에이전트가 최종 목표를 향한 특정 단계를 밟도록 동기를 부여할 수 있습니다.
 Figure- Reinforcement Learning architecture.png
Figure- Reinforcement Learning architecture.png
그림: 강화 학습 아키텍처
학습 과정
심층 강화 학습의 학습 또는 훈련 과정은 다음을 포함하는 상호작용, 피드백 및 개선의 반복적인 주기입니다:
탐색
활용
심층 신경망
역전파
탐색
처음에 에이전트는 환경을 알지 못합니다. 무작위로 탐색하며, 다양한 행동을 시도하고 그 결과를 관찰하는 것으로 시작합니다. 이 탐색 단계는 환경 정보를 수집하고 보상이 있는 행동을 발견하는 데 중요합니다.
활용
에이전트가 탐색하고 경험을 수집함에 따라, 긍정적인 보상으로 이어지는 행동을 식별하기 시작합니다. 그런 다음 이 지식을 활용하여 보상을 최대화하기 위해 그러한 행동을 더 자주 선택합니다.
심층 신경망
에이전트는 에이전트의 정책과 가치 함수를 근사하기 위해 심층 신경망을 사용합니다.
정책 네트워크: 이 네트워크는 현재 상태를 입력으로 받아 다양한 행동을 취할 확률을 출력합니다.
가치 네트워크: 이 네트워크는 특정 상태에 있는 것의 장기적 가치를 추정하여, 에이전트가 더 높은 누적 보상으로 이어지는 결정을 내리도록 돕습니다. 이러한 신경망은 에이전트가 복잡한 환경 패턴과 관계를 학습할 수 있게 하여, 더 지능적인 결정을 내리는 데 도움을 줍니다.
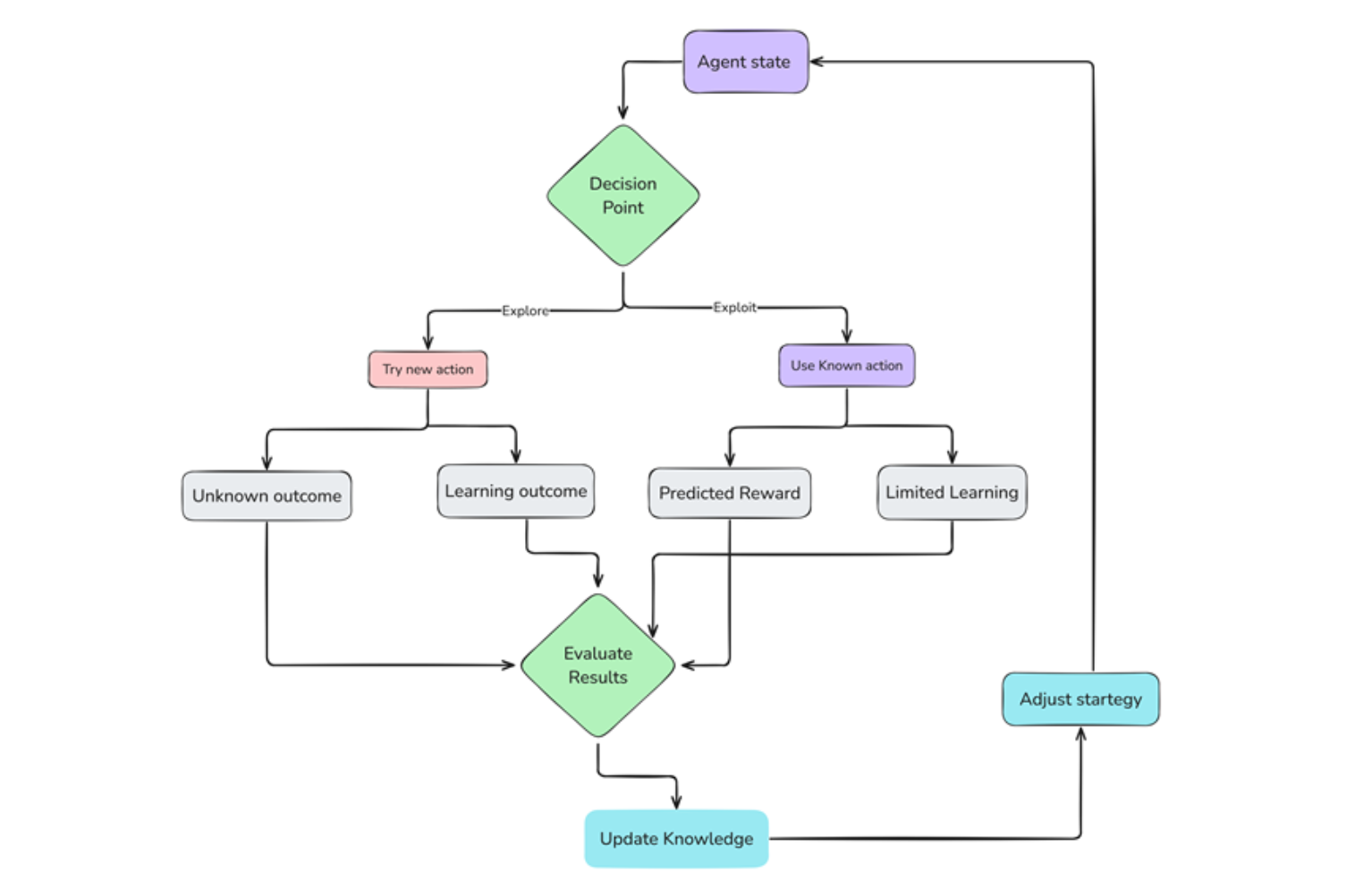 Exploration vs Exploitation Process .png
Exploration vs Exploitation Process .png
그림 3 탐색 vs 활용 과정
역전파
"오류의 역방향 전파"의 약자인 역전파는 신경망 훈련의 핵심 알고리즘입니다. 이는 예측의 오류를 최소화하기 위해 신경망의 가중치를 조정합니다.
역전파는 에이전트가 피드백으로부터 학습함으로써 의사결정 모델을 개선하는 데 도움을 줍니다. 에이전트가 행동을 취하면, 그 행동이 얼마나 좋았는지 또는 나빴는지에 대한 피드백을 받습니다(보상의 형태로). 그런 다음 역전파는 신경망의 가중치를 조정하여 예측된 결과와 실제 보상 사이의 오차를 줄입니다. 역전파를 반복적으로 적용함으로써 신경망은 가치 함수 또는 정책 함수를 더 잘 근사하는 방법을 학습하여 더 정확한 의사결정으로 이어집니다. 이 과정은 에이전트가 환경에 대한 이해를 점진적으로 개선하고 시간이 지남에 따라 점점 더 최적의 결정을 내릴 수 있게 해주며, 이는 동적이고 고차원적인 환경에서 복잡한 과제를 숙달하는 데 필수적입니다.
심층 강화 학습에서 널리 사용되는 알고리즘
DRL은 학습 과정에서 다양한 과제를 해결하도록 설계된 여러 알고리즘을 사용합니다. 다음은 가장 널리 사용되는 방법들입니다:
Q-Learning: Q-Learning은 기초적인 강화 학습 알고리즘 중 하나입니다. 이는 Q-values라고 하는 상태-행동 쌍의 가치를 추정하여, 에이전트가 특정 상태에서 어떤 행동이 더 바람직한지 판단하는 데 도움을 줍니다. 이 알고리즘은 즉각적인 보상과 예상되는 미래 보상을 기반으로 이러한 Q-values를 업데이트하며, 장기적 가치가 더 높은 행동을 선호하도록 에이전트의 선택을 점진적으로 개선합니다.
Deep Q-Networks (DQN): DQN은 신경망을 활용해 Q-values를 근사함으로써 Q-learning을 향상시킵니다. 이 접근 방식은 DQN을 게임 AI, 로봇 내비게이션, 자율 주행과 같은 복잡한 환경에서 효과적으로 만듭니다.
Policy Gradients: 가치 기반 방법과 달리, policy gradient 알고리즘은 받은 보상을 기반으로 신경망의 가중치를 조정하여 에이전트의 정책을 직접 최적화합니다. 이 접근 방식은 성공적인 행동의 가능성을 높임으로써 에이전트가 성능을 향상할 수 있게 하며, 로봇 팔 조작과 같이 정밀한 조정이 필요한 제어 과제에서 특히 중요합니다.
Actor-Critic Methods: 하이브리드 접근 방식은 주어진 상태에서 각 행동의 가치를 추정하는 것을 목표로 하는 정책 기반 방법과, 최적 정책을 직접 학습하는 데 초점을 맞춘 가치 기반 방법의 장점을 결합합니다. 이 프레임워크에서 actor는 행동 선택을 담당하고, critic은 이러한 행동을 평가하고 피드백을 제공합니다. 이 피드백은 정책의 지속적인 개선을 가능하게 합니다.
심층 강화 학습과 다른 개념의 비교
심층 강화 학습(Deep Reinforcement Learning, DRL)은 종종 다른 AI 접근 방식과 비교됩니다. 차이점과 유사점을 명확히 하기 위해 핵심 측면을 살펴보겠습니다:
| 측면 | 심층 강화 학습(DRL) | 일반 강화 학습(RL) | 지도 학습 | 비지도 학습 | |
| 핵심 개념 및 데이터 처리 | RL과 심층 신경망을 결합하며, 고차원의 복잡한 데이터를 처리함 | 더 단순한 모델을 사용하는 RL에 중점을 두며, 저차원 환경에서 잘 작동함 | 사전 정의된 출력이 있는 레이블이 지정된 데이터로부터 학습하며, 레이블이 지정된 데이터셋에 의존함 | 레이블이 없는 데이터에서 패턴을 찾으며, 레이블이 없는 데이터셋을 사용함 | |
| 학습 과정 | 환경과의 상호작용을 통한 시행착오. | 환경으로부터의 피드백을 통한 시행착오. | 레이블이 지정된 입력-출력 쌍에서 패턴을 학습함. | 데이터의 클러스터 또는 구조를 식별함. | |
| 목표 | 시간에 따른 누적 보상을 극대화함. | 시간에 따른 누적 보상을 극대화함. | 입력 데이터를 기반으로 출력을 예측함. | 데이터에서 숨겨진 패턴이나 그룹화를 발견함. | |
| 응용 분야 | 복잡한 작업: 게임 AI, 로보틱스, 자율주행차. | 기본 제어 시스템 및 간단한 의사결정 작업. | 분류, 회귀, 예측 모델링. | 클러스터링, 차원 축소, 이상 탐지. |
심층 강화 학습의 이점과 과제
심층 강화 학습에는 많은 가능성이 있지만, 무엇을 잘하고 어디에서 한계가 있을 수 있는지 아는 것이 중요합니다. DRL의 주요 이점과 과제 몇 가지를 살펴보겠습니다.
이점:
적응성: DRL의 핵심 이점 중 하나는 적응성입니다. DRL 에이전트는 추가 프로그래밍 없이도 새롭고 예상치 못한 상황에 대처할 수 있습니다. 예를 들어, DRL 기반 자율주행 차량은 장애물이나 악천후와 같은 갑작스러운 도로 변화에 반응하여 안전하게 주행하도록 행동을 조정할 수 있습니다.
최적의 의사 결정: DRL은 또한 더 스마트하고, 종종 더 효과적인 의사 결정을 가능하게 합니다. 기존의 규칙 기반 시스템과 달리, DRL 모델은 인간 설계자조차 놓칠 수 있는 전략을 발견할 수 있습니다. 예를 들어 금융 분야에서는 DRL이 기존 시스템보다 더 수익성 있는 결정을 자주 내리는 트레이딩 봇을 만드는 데 성공적으로 적용되었습니다.
자동화 잠재력: DRL은 물류, 의료, 고객 지원과 같은 분야의 작업 자동화를 가능하게 합니다. 복잡한 경우가 많고 항상 변화하는 이러한 영역에서 DRL은 작업을 자동화함으로써 일을 더 쉽게 만들어 줍니다.
과제:
샘플 효율성: DRL의 가장 큰 과제 중 하나는 방대한 양의 학습 데이터가 필요하다는 점입니다. DRL 모델은 일반적으로 우수한 성능을 내기 위해 광범위한 데이터를 필요로 하며, 이를 수집하는 데 비용과 시간이 많이 들 수 있습니다. 경험 재현과 같은 기법은 모델이 과거 데이터로부터 학습할 수 있게 하여 도움이 되지만, DRL을 더 실용적으로 만들기 위해서는 데이터 효율성의 개선이 여전히 필요합니다.
보상 설계: 또 다른 과제는 효과적인 보상 함수를 설계하는 데 있습니다. 적절한 보상을 설정하는 것은 매우 중요합니다. 잘못 설계된 보상은 의도하지 않은, 때로는 문제가 되는 에이전트 행동으로 이어질 수 있기 때문입니다. 따라서 DRL에서의 보상 설계는 에이전트가 의도한 목표와 일치하는 방식으로 행동하도록 보장하기 위해 신중한 계획이 필요합니다.
안정성과 수렴: 마지막으로, DRL 학습은 불안정할 수 있습니다. 때때로 모델은 최적이 아닌 전략에 갇히거나 안정적인 해에 도달하지 못할 수 있습니다. 학습 안정성을 개선하는 것은 DRL 모델을 더 신뢰할 수 있게 만드는 데 필수적이며, 특히 일관성이 핵심인 고위험 애플리케이션에서 중요합니다.
심층 강화 학습의 실제 적용 사례
이제 심층 강화 학습(DRL)의 작동 방식을 살펴보았으니, 그 실제 적용 사례로 초점을 옮겨 보겠습니다. DRL은 다양한 영역에서 현실 세계의 문제를 해결하는 데 사용되고 있습니다. 예를 들면 다음과 같습니다:
게임 플레이: DRL은 Chess, Go, Dota 2와 같은 게임에서 뛰어난 고급 AI 에이전트의 생성을 가능하게 했습니다. 직접 탐구해 보고 싶은 사람들을 위해 Unity ML-Agents는 게임 기반 학습을 실험할 수 있는 접근성 높은 툴킷을 제공합니다.
로보틱스: 로보틱스에서 DRL은 탐색과 물체 조작 같은 기계 기술을 가르칩니다. DRL은 창고에서 매우 효과적임을 입증하며, 로봇이 새로운 배치와 변화하는 작업에 적응하도록 하여 운영 효율성을 높입니다.
자율주행 차량: 자율주행 자동차에서 DRL은 차선 변경, 장애물 회피, 속도 조절을 위한 순간적인 결정을 내리는 데 중요한 역할을 합니다. 예를 들어 Waymo는 복잡한 교통 상황에서 차량이 안전한 선택을 하도록 돕기 위해 DRL을 사용합니다.
금융 트레이딩: DRL은 시장 변화에 대응하는 트레이딩 봇을 개발하기 위해 금융 분야에서도 널리 사용됩니다. Deep Q-Learning과 같은 접근 방식을 사용하여, DRL 기반 트레이딩 봇은 과거 추세와 실시간 데이터를 분석해 정보에 기반한 매수, 보유, 매도 결정을 내리며, 종종 수동 트레이딩 전략보다 더 나은 결과를 달성합니다.
개인화된 추천: DRL은 점점 더 발전된 추천 시스템을 구동합니다. 맞춤형 추천을 제공하기 위해 DRL 알고리즘은 스트리밍 서비스, 온라인 스토어, 소셜 미디어 플랫폼에서 사용자 행동과 선호도를 분석합니다. 사용자 행동을 관찰함으로써 DRL은 개인의 선호도에 더 가깝게 부합하는 콘텐츠나 제품을 추천할 수 있습니다.
심층 강화 학습에 대한 FAQ
- 심층 강화 학습에서 에이전트는 어떻게 학습하나요?
DRL에서 에이전트는 환경에서 행동을 취하고 보상의 형태로 피드백을 받음으로써 학습합니다. 에이전트는 효과적인 전략을 발견하기 위해 탐색(새로운 행동 시도)을 사용하고, 보상을 극대화하기 위해 활용(알려진 행동 사용)을 사용합니다. 심층 신경망은 에이전트가 경험으로부터 일반화하고 복잡한 시나리오에 적응하도록 돕습니다.
- 심층 강화 학습 모델은 탐색과 활용의 균형을 어떻게 맞추나요?
DRL 모델은 epsilon-greedy 또는 Thompson Sampling과 같은 알고리즘을 통해 탐색(더 나은 전략을 발견하기 위해 새로운 행동 시도)과 활용(보상을 극대화하기 위해 알려진 행동 사용)의 균형을 맞춥니다. 이러한 기법은 균형을 유지하는 데 도움을 주어, 에이전트가 알려진 보상을 극대화하면서 새로운 전략을 발견하도록 보장합니다.
- 심층 강화 학습에서 가치 함수는 어떻게 작동하나요?
가치 함수는 특정 상태에 있는 것(상태-가치 함수) 또는 주어진 상태에서 특정 행동을 취하는 것(행동-가치 함수)의 기대 보상을 추정합니다. 이는 에이전트가 더 높은 보상으로 이어지는 상태와 행동의 우선순위를 정하도록 도와 의사결정을 안내합니다.
- AI 애플리케이션에서 DRL을 Milvus와 함께 어떻게 사용할 수 있나요?
Milvus는 DRL 에이전트가 생성한 고차원 상태 표현을 저장하고 관리할 수 있습니다. 과거 경험을 위한 replay buffer로 사용되거나 상태 표현 저장을 지원하여 정책 최적화와 가치 추정의 효율성을 향상시킬 수 있습니다.
- 심층 강화 학습 사용의 윤리적 우려는 무엇인가요?
윤리적 우려에는 훈련 데이터의 잠재적 편향, 잘못 설계된 보상 함수에서 비롯되는 의도치 않은 행동, 민감한 애플리케이션에서의 공정성 문제가 포함됩니다. 이러한 위험을 완화하려면 견고한 테스트, 투명성, 설명 가능한 AI를 구현하는 것이 중요합니다.
관련 리소스
더 깊이 탐색하려면 다음 리소스를 고려해 보세요: