




벡터 데이터베이스에서 벡터 레이크베이스로
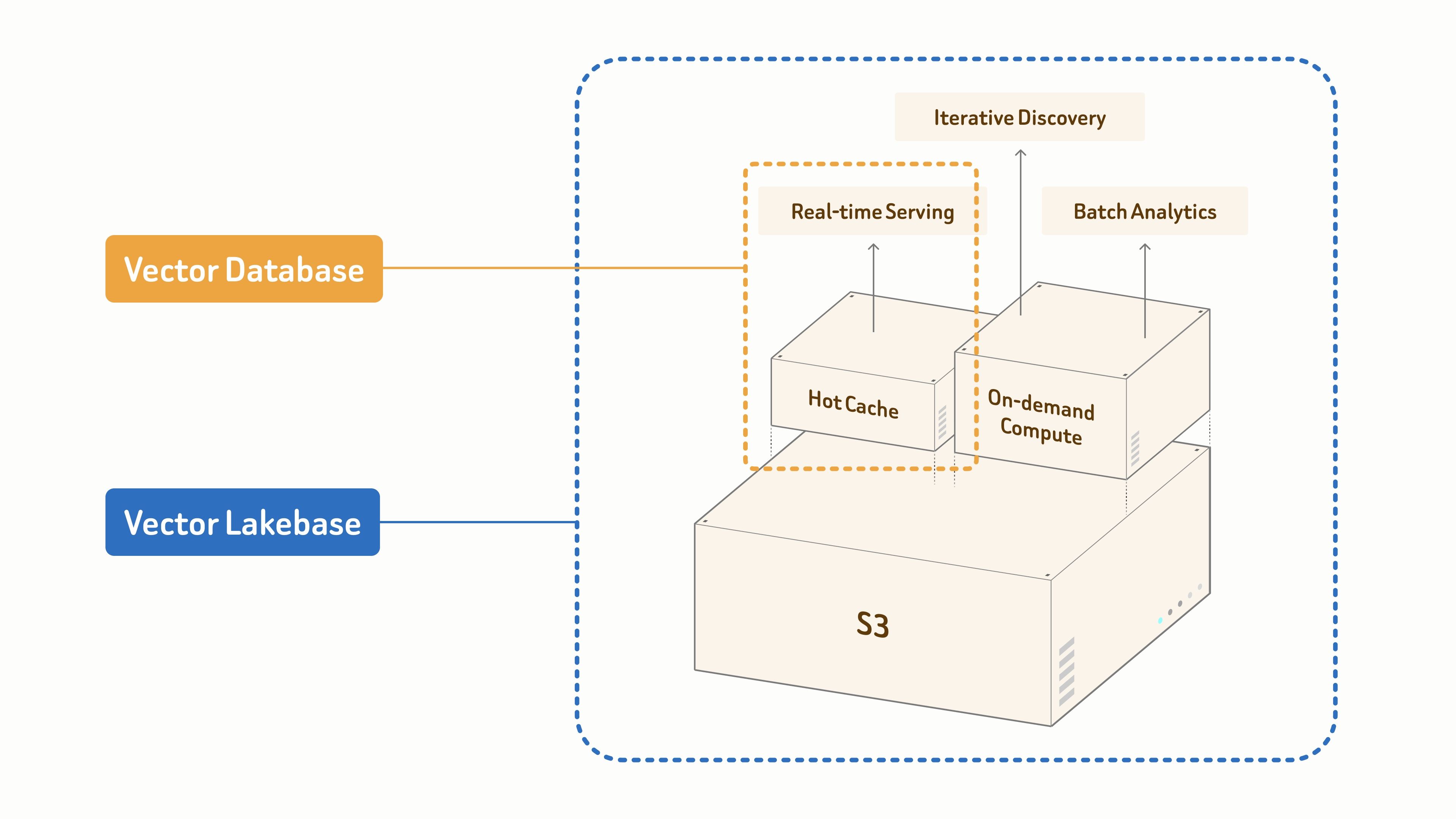
오늘, Zilliz Cloud의 다음 장인 Zilliz Vector Lakebase의 공개 프리뷰를 출시합니다. Vector Lakebase는 벡터 데이터베이스를 넘어서는 다음 단계입니다. 이는 개방형 스토리지와 탄력적 컴퓨팅이 AI 워크로드를 위해 결합되는 의미 중심 데이터 플랫폼입니다.
- 벡터 데이터베이스는 실시간 서빙을 위해 목적에 맞게 구축되었습니다.
- Vector Lakebase는 S3 기반 통합 데이터 기반 위에 구축되어 세 가지 워크로드 모드 전반에서 AI와 에이전트를 지원합니다:
- 지연 시간이 중요한 프로덕션 서빙을 위한 실시간 검색,
- 인터랙티브하고 다단계 탐색을 위한 반복적 발견,
- 오프라인 마이닝과 데이터셋 최적화를 위한 배치 분석.
기가바이트에서 페타바이트까지 모든 규모 확장을 지원합니다.
통합 데이터 기반과 세 가지 워크로드 모드가 정말 중요한 이유는 무엇인가요?
간단히 말해: AI 시스템은 더 이상 단일 쿼리 검색 문제에 그치지 않기 때문입니다. AI 시스템은 서빙, 학습, 개선의 지속적인 루프로 작동합니다.
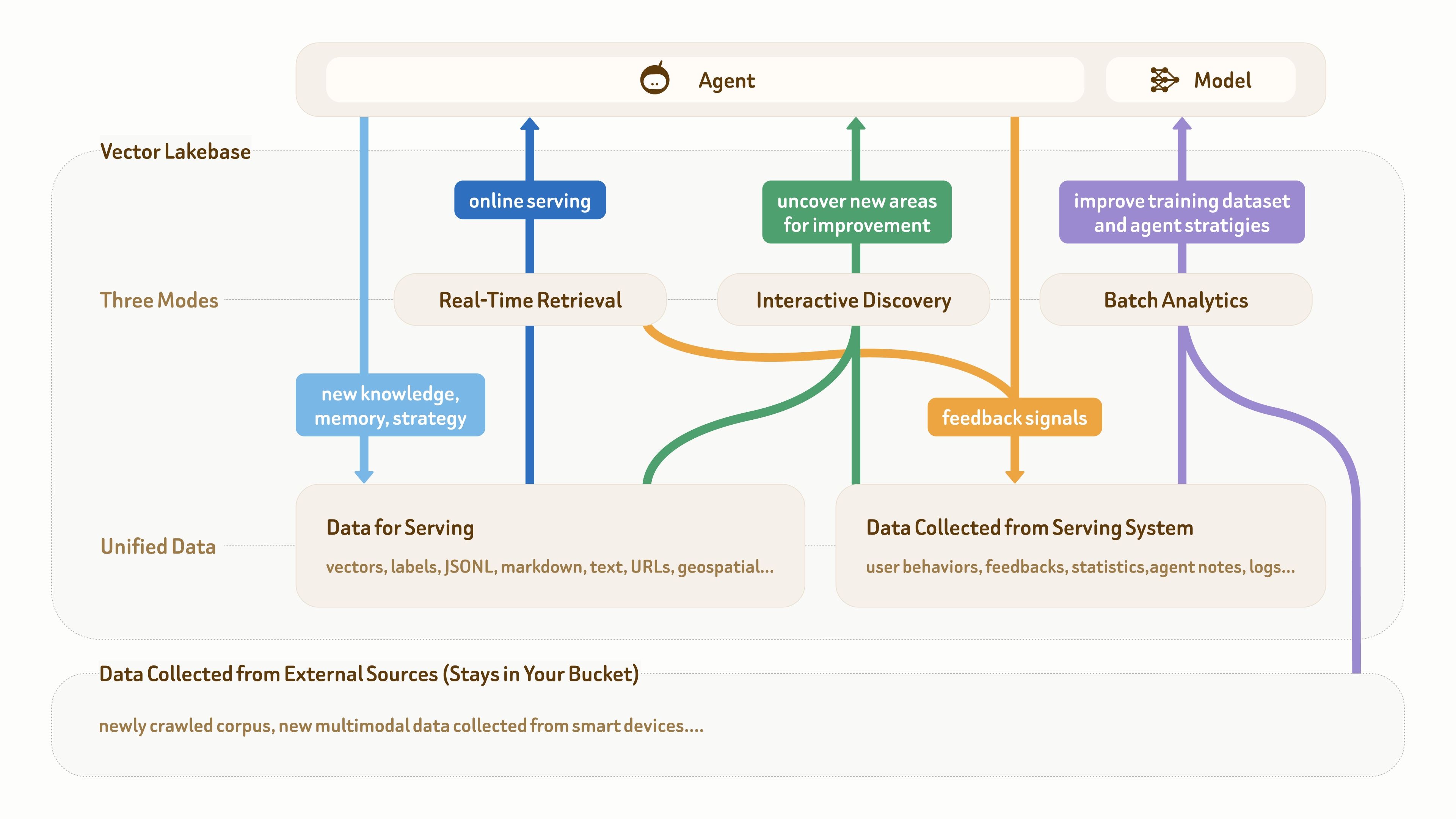
이 그림에서 보듯이, AI 및 에이전트 애플리케이션의 데이터 기반은 일반적으로 세 부분으로 구성됩니다: 하단의 원시 멀티모달 데이터, 온라인 서빙을 위한 의미 데이터(예: 텍스트, 벡터, 라벨), 그리고 프로덕션 시스템에서 수집된 피드백 데이터(예: 사용자 행동, 로그, 에이전트 노트, 통계).
많은 성숙한 에이전트 애플리케이션은 이미 이러한 종류의 데이터 기반을 갖추고 있습니다. 진짜 문제는 이러한 다양한 유형의 데이터가 여러 파이프라인과 시스템에 흩어져 있는 경우가 많고, 워크플로 루프를 지원할 통합되고 구조화된 데이터 플레인이 없다는 점입니다:
온라인 서빙(진한 파란색) → 지식 및 피드백 축적(연한 파란색 및 주황색) → 인사이트 발견(초록색) → 데이터셋 및 전략 개선(보라색) → 더 나은 온라인 서빙.
그림에서도 볼 수 있듯이, 벡터 데이터베이스만으로는 더 이상 충분하지 않습니다. 이는 주로 실시간 검색과 서빙 지향 데이터 쓰기(두 개의 파란색 경로)를 지원하기 때문입니다. 이 루프에서는 다른 두 가지 접근 모드인 인터랙티브 발견과 배치 분석도 그만큼 중요합니다.
예를 들어, AI 개발자들은(수동으로든 에이전트 시스템을 통해서든) 서빙 품질이 왜 낮은지 이해하기 위해 피드백 데이터와 기반 코퍼스를 탐색해야 하는 경우가 많습니다. 또한 새로 크롤링한 데이터에 대해 대규모 의미 중복 제거와 클러스터링을 실행한 뒤, 엣지 클러스터를 마이닝해 새로운 학습 데이터 후보를 발견할 수도 있습니다.
이러한 워크로드는 전통적인 빅데이터 처리와 매우 다릅니다. 핵심 연산은 수치적이라기보다 의미적입니다. 데이터는 주로 벡터, 텍스트, 라벨, 의미 메타데이터로 구성되며, 핵심 작업에는 벡터 검색, 전문 검색, 리랭킹, 의미 클러스터링 및 관련 의미 검색 작업이 포함됩니다.
이 때문에 인터랙티브 발견과 배치 분석은 데이터 계층과 컴퓨팅 계층 모두에서 벡터 데이터베이스와 자연스럽게 맞물립니다. 많은 경우 온라인 서빙과 오프라인 처리도 동일한 기반 데이터 토대를 공유합니다.
예를 들어, 팀은 오프라인에서 고가치 사용자 작업을 클러스터링하고 분석하는 동시에, 서빙 시스템의 지원 지식이나 전략에 희소성 또는 품질 문제가 있는지 확인할 수 있습니다.
전반적으로, 단편화된 데이터 아키텍처나 고립된 인프라 섬은 이러한 루프를 느리게 만듭니다. 이는 빠르게 진화하는 AI 역량 경쟁에서 치명적일 수 있습니다. Vector Lakebase는 간단하지만 효율적인 접근 방식으로 이 루프를 가속화합니다: 실시간 검색, 인터랙티브 발견, 배치 분석이라는 세 가지 워크로드 모드 모두에서 효율적으로 접근할 수 있는 제로카피 의미 데이터 플레인을 제공합니다.
Vector Lakebase의 핵심 기능
Zilliz Vector Lakebase는 다섯 가지 핵심 기능을 통해 이 워크플로 루프를 지원합니다:
- 계층형 서빙 솔루션
다양한 실시간 워크로드에 최적화된 유연한 서빙 계층 — 초고성능, 균형 잡힌 효율성, 대규모 데이터셋 전반의 비용 효율적인 확장을 제공합니다. - 온디맨드 검색
지연 시간이 덜 중요하고 컴퓨트가 대부분의 시간 동안 유휴 상태로 유지되는 대규모 워크로드를 위해 설계 — 비정기적 검색, 데이터 탐색, 배치 분석을 포함합니다. - 외부 데이터 레이크 검색
최첨단 인덱싱과 대규모 검색 기능을 기존 레이크 데이터에 직접 추가합니다. - 풀스펙트럼 검색 벡터와 텍스트부터 JSON 및 지리공간까지—하이브리드 검색, 필터링, 재랭킹과 결합하여 표현력 있는 멀티모달 쿼리를 지원합니다.
- 통합 레이크 네이티브 스토리지
서빙과 분석 모두를 위한 통합 스토리지로, Vortex 기반으로 구축되었습니다 — Lance 및 Parquet보다 더 빠르고 저렴한 랜덤 읽기를 제공하는 개방형 차세대 포맷이며, 컬럼별 포맷 유연성과 더 폭넓은 데이터 모델링 기능을 제공합니다.
계층형 실시간 서빙 솔루션
Zilliz Cloud의 계층형 서빙 솔루션은 Performance-Optimized, Capacity-Optimized, Tiered-Storage의 세 가지 서빙 계층을 제공합니다. 각 계층은 스토리지 계층 구조 전반에 걸친 전용 인덱싱 알고리즘과 데이터 배치 전략으로 구축되어, 다양한 성능–비용 절충안을 제공합니다.
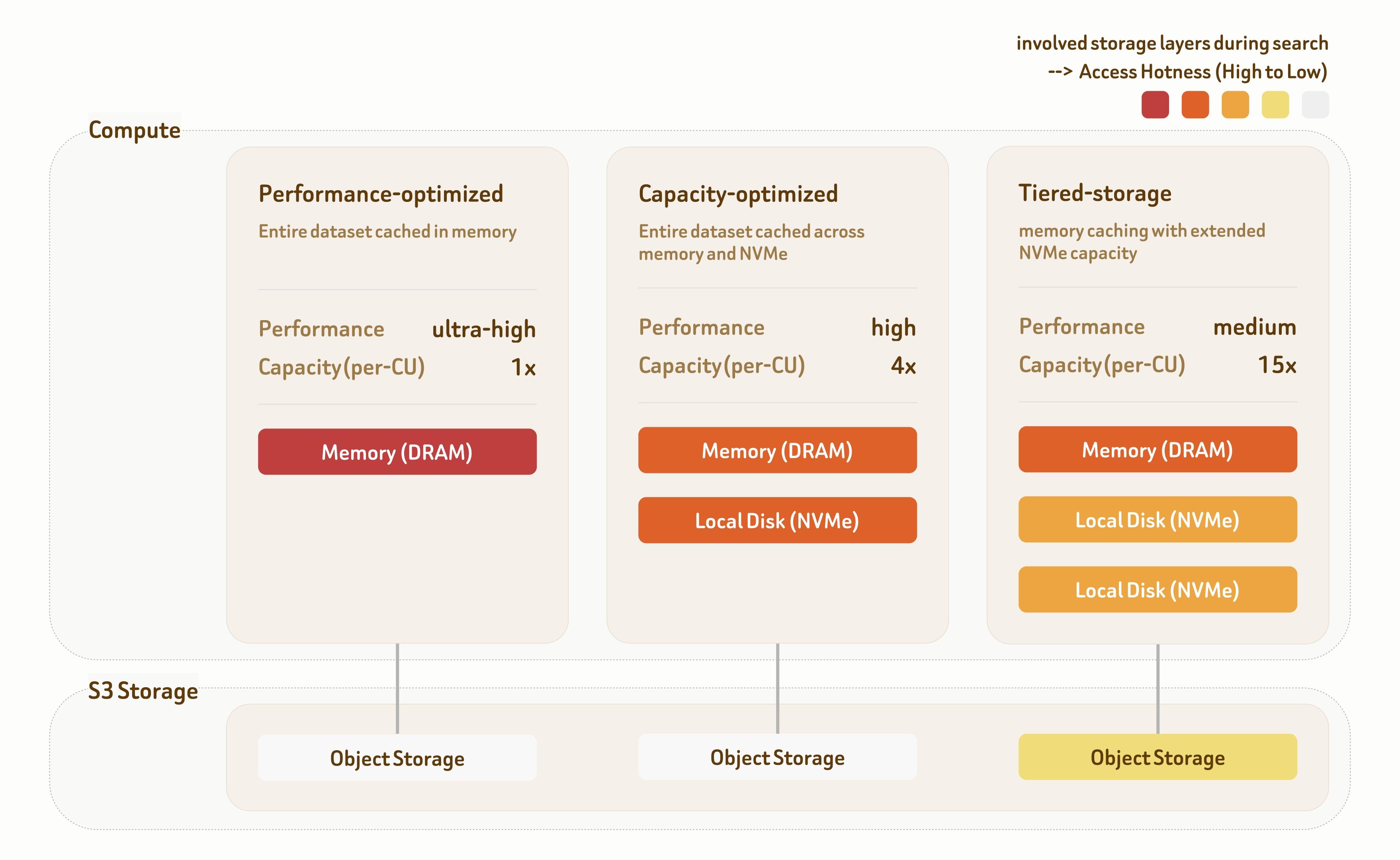
Performance-Optimized 계층은 초고성능 시나리오를 대상으로 합니다. 모든 데이터가 메모리에서 직접 제공되어, 한 자릿수 밀리초 지연 시간으로 1000+ QPS를 제공합니다. 처리량은 멀티 리플리카 배포를 통해 추가로 선형 확장됩니다.
Capacity-Optimized 계층은 메모리와 로컬 NVMe 스토리지를 결합하여 성능과 용량의 균형을 맞춥니다. 100~500 QPS를 100 ms 미만의 지연 시간으로 제공하여, 대부분의 검색 워크로드에 적합합니다.
Tiered-Storage 계층은 메모리, 로컬 NVMe, 객체 스토리지에 걸쳐 있습니다. 고도로 최적화된 프리페칭 및 캐싱 전략을 통해 데이터 액세스의 95% 이상이 여전히 메모리 또는 로컬 디스크에서 처리되며, 훨씬 낮은 인프라 비용으로 약 100 ms 지연 시간에서 10~50 QPS를 제공합니다.
세 계층 모두 기본적으로 95%–98% 재현율을 제공하며, 인덱싱과 검색 전반에서 유연한 튜닝을 통해 워크로드 요구사항에 따라 90%부터 99%+ 재현율까지 지원합니다.
이러한 서빙 아키텍처는 다음을 포함하여, 세계에서 가장 까다로운 대규모 AI 및 인터넷 워크로드 일부에서 검증되었습니다:
- 인터넷 규모의 멀티테넌트 AI 플랫폼,
- 프리미엄 엔터프라이즈 사용자와 대규모 무료 사용자 풀 모두를 위한 차별화된 서비스 계층,
- 고성능 에이전트 지식 베이스,
- 초고처리량 추천 시스템,
- 웹 규모 AI 검색 엔진,
- 스토리지 계층 전반의 초 단위 동적 핫/콜드 데이터 스케줄링,
- 극단적인 비용 제약하에서 100B+ 규모의 자율주행 데이터 마이닝 파이프라인.
온라인 서빙의 경우, Zilliz Cloud는 교차 리전 고가용성 및 재해 복구를 위한 Global Cluster 기능도 제공하며, 99.99% 가동 시간 SLA로 뒷받침됩니다.
온디맨드 검색
인터랙티브 디스커버리와 배치 분석은 특히 피드백 데이터, 에이전트 생성 노트, 로그, 크롤링된 코퍼스를 포함할 때 온라인 서빙보다 한 자릿수에서 세 자릿수 더 큰 데이터 볼륨에서 작동하는 경우가 많습니다. 이러한 데이터셋은 쉽게 TB 또는 PB 규모에 도달할 수 있습니다. 그러나 이를 제공하기 위해 수백 또는 수천 개의 벡터 데이터베이스 노드를 사용하는 것은 비용–편익 관점에서 정당화하기 어려운 경우가 많습니다.

더 중요한 점은 이러한 워크로드가 일반적으로 작업 중심적이라는 것입니다. 에이전트 애플리케이션의 온라인 서빙 계층과 달리, 24/7 활성 인프라가 필요하지 않습니다. 컴퓨트 리소스는 활성 처리 작업 중에만 많이 사용되며, 대부분의 시간 동안 유휴 상태로 남아 있고, 유휴 시간이 97%를 넘는 경우도 많습니다.
서버리스 서빙 솔루션은 매력적으로 보일 수 있지만, 이러한 워크로드에서는 종종 훨씬 더 비싸집니다.
컴퓨트 계층에서 서버리스 시스템과 On-Demand Search는 모두 사용한 만큼 지불하는 모델을 따릅니다. 세부 가격 모델에는 차이가 있지만, 기본 컴퓨트 비용은 종종 유사합니다. 그러나 서버리스 아키텍처에서는 풀링 오버헤드, 인덱싱, 영구 데이터 비용이 기본 리소스의 실제 비용을 직접 반영하기보다는 추가적인 쓰기 및 스토리지 마크업에 포함됩니다.
반면, Zilliz On-Demand Search는 객체 스토리지와 온디맨드 컴퓨트에 대해 직접 과금합니다 — 이는 가격이 주로 할당된 리소스 크기와 실행 시간을 기반으로 하고, 스토리지 비용은 기본 S3 비용에 가깝게 유지되는 AWS Lambda와 유사합니다. 이를 통해 숨겨진 인프라 오버헤드와 블랙박스 가격 모델을 피할 수 있습니다.
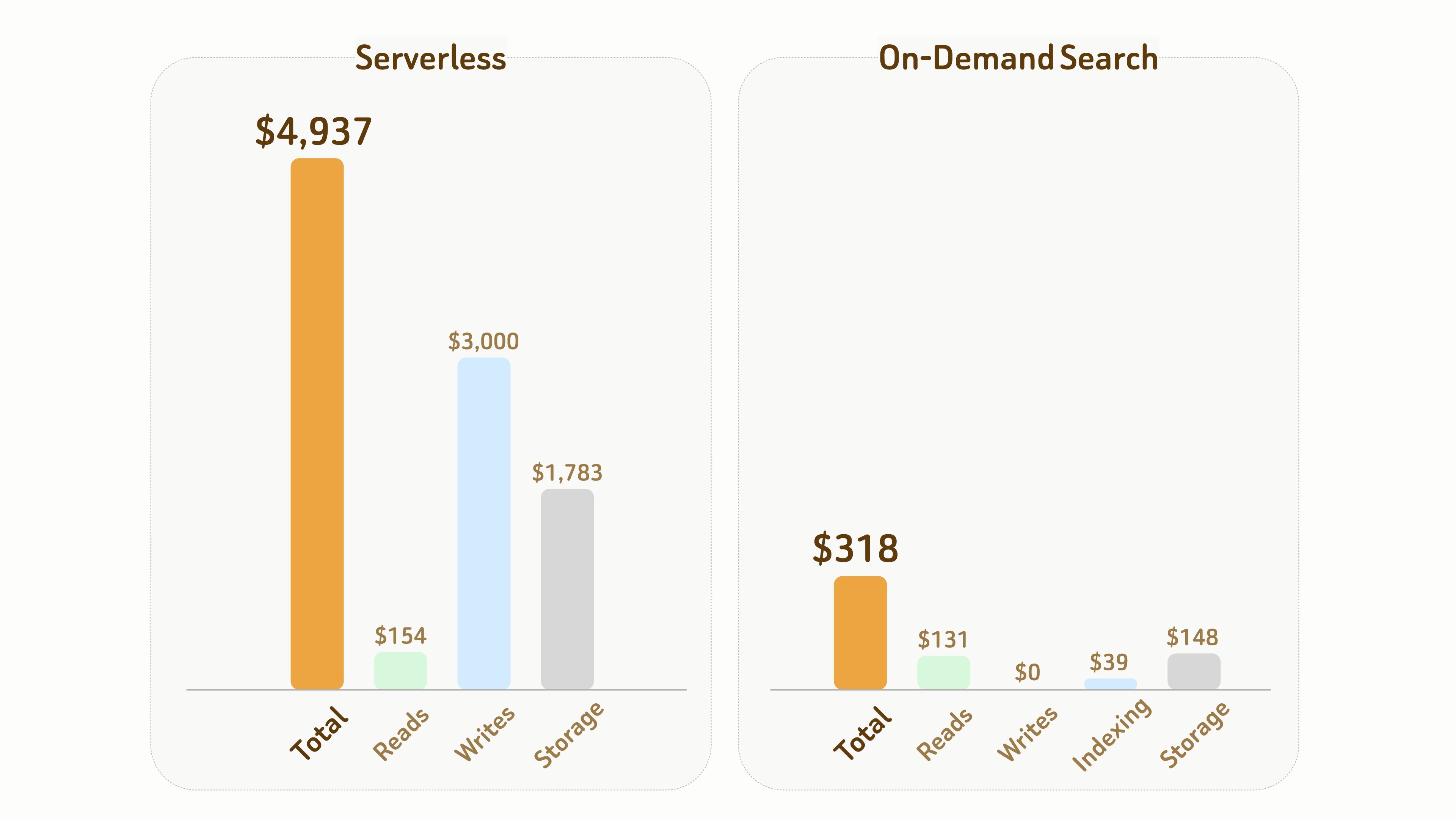
다음 비교는 Serverless와 On-Demand Search 간의 비용 차이를 보여줍니다.
설정:
- 768차원의 10억 개 벡터, 데이터 및 인덱스 파일을 포함해 약 6 TB의 스토리지 필요,
- 누적 활성 컴퓨트 시간 10시간을 포함한 1개월 기간.
전반적으로 이 실험에서 On-Demand Search의 총 비용은 Serverless의 약 1/15 ($318 vs $4,937)에 불과합니다.
외부 데이터 레이크 검색
Zilliz Vector Lakebase는 완전 관리형 스토리지와 쿼리 컴퓨트를 제공하여 사용자가 Zilliz Cloud에서 직접 데이터를 저장하고 운영할 수 있도록 합니다. 그러나 일부 고객은 이미 성숙한 데이터 레이크 인프라와 거버넌스 파이프라인을 갖추고 있습니다.
AI 애플리케이션의 경우, 핵심 과제 중 하나는 기존 레이크 데이터 위에서 직접 효율적인 검색과 의미론적 탐색을 가능하게 하는 것입니다. Spark 및 Ray와 같은 전통적인 빅데이터 시스템은 이러한 워크로드에 최적화되어 있지 않은데, 이는 근본적으로 인덱스 가속 쿼리와 의미론적 검색이 아니라 전체 데이터 스캔과 맵리듀스 계산을 중심으로 설계되었기 때문입니다.
이를 해결하기 위해 Zilliz는 External Collection 모드를 제공합니다. 이는 Zilliz 데이터 플레인에서 고객 소유의 레이크 테이블로 제로 카피 논리적 매핑을 생성하는 동시에, 해당 매핑 위에서 고성능 인덱스와 전체 스펙트럼 검색을 가능하게 합니다.
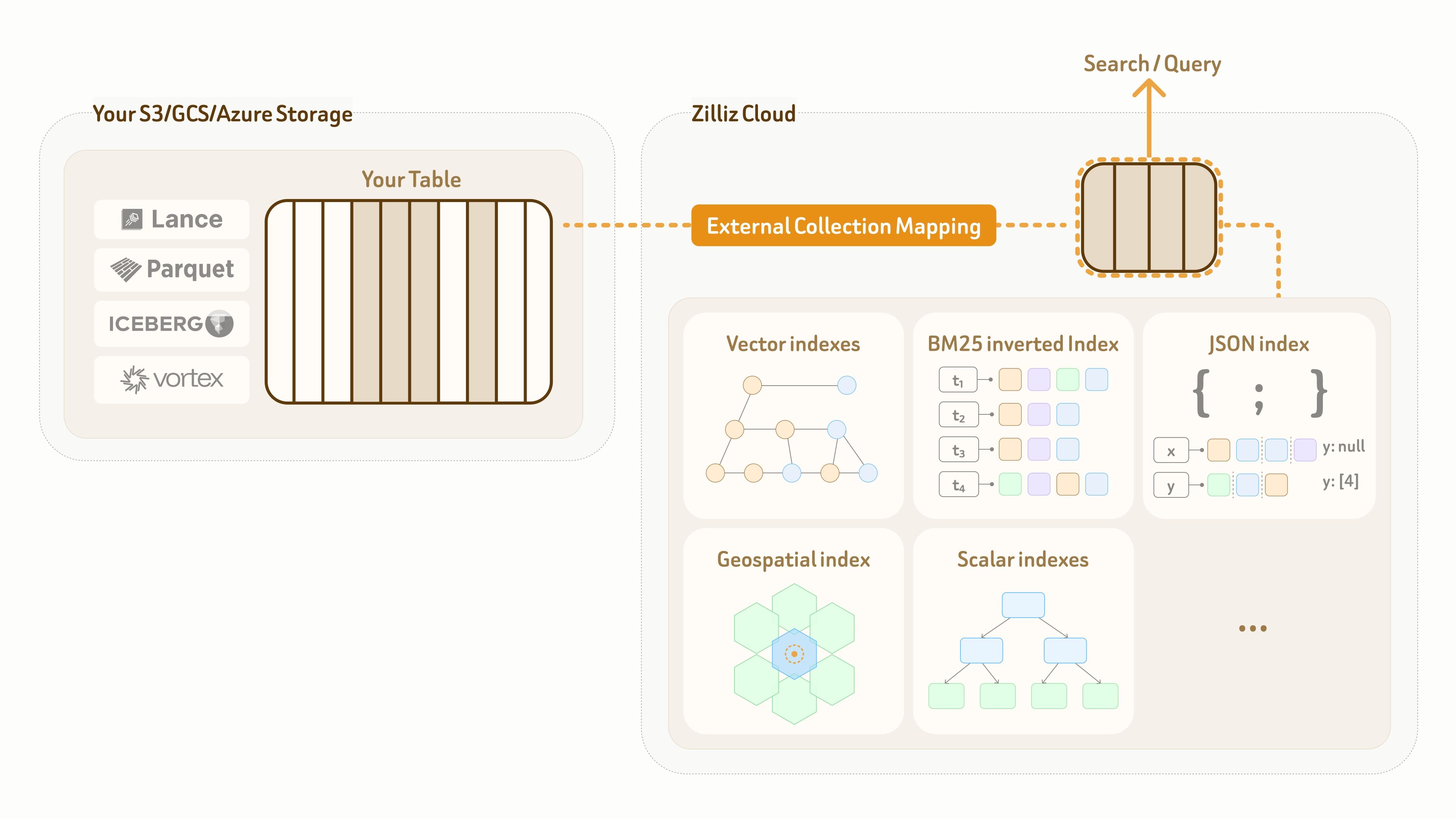
현재 External Collection은 두 가지 데이터 레이크 테이블 형식인 Lance와 Iceberg, 그리고 두 가지 오픈 데이터 형식인 Parquet와 Vortex를 지원합니다.
데이터 레이크 업데이트의 경우, Zilliz External Collection은 증분 동기화 기능을 제공합니다. 데이터 레이크 업데이트 패턴과 쿼리 가시성 요구사항에 따라 사용자는 refresh 호출로 언제든지 데이터를 동기화할 수 있습니다.
전체 스펙트럼 검색
AI 애플리케이션은 상호 보완적인 정보를 결합하고 더 나은 검색 및 분석 품질을 위해 동일한 원시 콘텐츠에서 여러 관점을 추출하기 위해, 서로 다른 소스와 모달리티 전반의 데이터를 검색하고 분석해야 할 필요성이 점점 커지고 있습니다.
Zilliz Vector Lakebase는 밀집 및 희소 벡터, 텍스트, JSON, 지리공간 데이터, 기본 타입을 포함한 풍부한 데이터 타입과 Struct 및 Array 같은 복잡한 구조를 갖춘 와이드 테이블 모델링을 지원하여, 통합된 테이블 레이아웃 내에서 직접 효율적인 중첩 의미론적 모델링을 가능하게 합니다.

이를 통해 각 애플리케이션 수준 엔터티를 단일 행에 직접 매핑함으로써 통합된 컨텍스트 모델링이 가능해집니다. 예를 들어 문서를 텍스트 청크, 이미지, 테이블을 위한 수백 개의 행으로 분할하는 대신, Zilliz Vector Lakebase는 전체 문서를 단일 행으로 모델링할 수 있습니다. 이는 JOIN과 집계의 성능 및 운영 오버헤드를 피하면서 멀티모달 검색과 분석을 개선합니다.
데이터 모델링을 넘어, Vector Lakebase는 지원되는 모든 데이터 유형 전반에서 최첨단 인덱싱 및 검색 기능도 제공합니다. 자세한 기능은 아래에 나열되어 있습니다:
| Vector Search | HNSW, IVF, RaBitQ를 능가하는 고급 인덱싱 알고리즘과 10단계의 recall-latency 튜닝. |
|---|---|
| Full-Text Search | BM25, 구문, 접두사, 퍼지 매칭, 다양한 분석기를 지원하는 전문 검색. |
| Grep | 대부분의 grep 스타일 매칭 패턴을 포괄하는 내장 정규식 지원. |
| Hybrid Search | 향상된 재현율과 관련성을 위한 하이브리드 dense 및 sparse 벡터 검색. |
| Query on JSON | 중첩 JSON 필드에 대한 빠른 필터링 및 쿼리를 위한 내장 JSON shredding 및 인덱싱. |
| Geospatial Search | 반경, 최근접 이웃, 영역 필터링을 지원하는 빠른 지리공간 검색. |
| Multi-Vector Search | 하나 이상의 모달리티에서 생성된 여러 임베딩에 대한 검색과 통합 reranking. |
| Vector Search with Filtering | 낮은 필터 선택도부터 높은 필터 선택도까지 최적화된 속성 필터링을 포함한 벡터 검색. |
| Range Search | 쿼리 벡터로부터 지정된 거리 임계값 내의 모든 벡터를 반환. |
| Iterative Search | 중간 결과를 기반으로 단계별 쿼리 개선을 수행하는 반복 검색. |
| Multi-Path Retrieval | 여러 전략을 사용하는 멀티패스 검색으로, 각 경로는 위의 검색 방법 중 하나를 사용할 수 있음. |
또한 멀티패스 검색과 함께 사용되는 reranking 기능도 제공합니다.
| Cohere Reranker | 높은 의미적 정밀도로 쿼리–문서 쌍에 점수를 매겨 검색 결과를 최대 관련성 순으로 재정렬하는 cross-encoder reranking 모델. |
|---|---|
| Voyage AI Reranker | 대규모 검색 파이프라인에서 빠르고 비용 효율적인 관련성 점수 산정을 위해 최적화된 경량 고처리량 reranking 모델. |
| Boost Reranker | 매칭된 결과에 조건부 필터를 적용하고 지정된 가중치로 점수를 조정하여 순위를 올리거나 내림. |
| Decay Reranker | 거리나 시간 같은 요인을 기반으로 decay 함수를 적용해 결과 점수를 조정하며, 값이 목표에서 멀어질수록 관련성을 점진적으로 낮춤. |
| RRF Reranker | 여러 결과 목록에서 각 항목의 순위 위치를 결합하여 단일 순위로 병합. |
| Weighted Reranker | 설정 가능한 가중치를 사용해 여러 결과 목록의 점수를 결합하여 통합 순위를 생성. |
통합 Lake-Native 스토리지
Zilliz Cloud는 완전히 분리된 스토리지–컴퓨트 아키텍처를 기반으로 구축되었으며, 모든 것이 클라우드 객체 스토리지에 영구 저장됩니다.
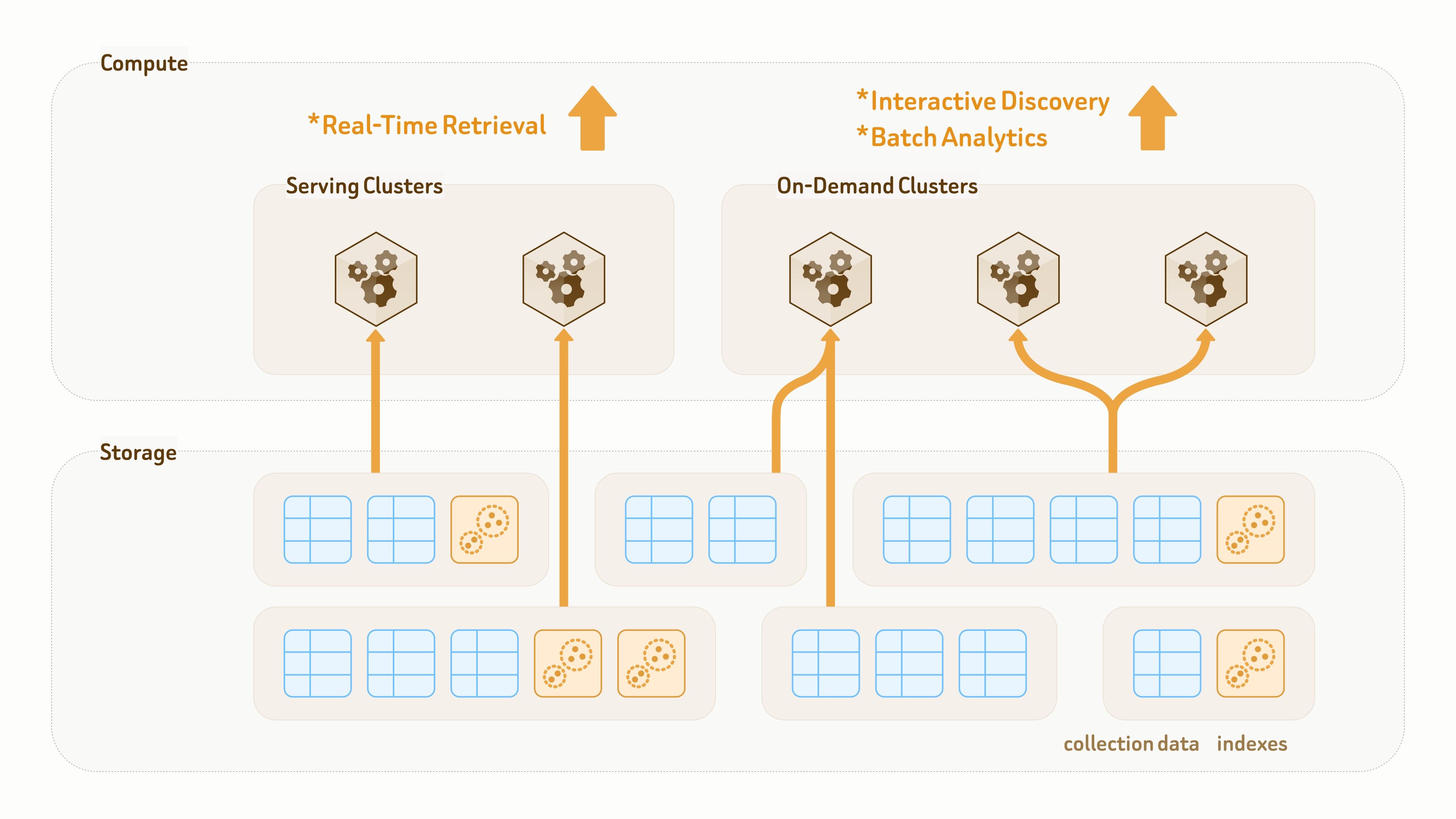
주로 저장을 위해 설계된 기존 데이터 레이크와 달리, Zilliz Vector Lakebase의 데이터 계층은 영속성과 쿼리 실행을 모두 위해 설계되었습니다. 컬렉션과 인덱스는 컴퓨트 클러스터에서 분리되어 있어, 동일한 데이터와 인덱스를 서로 다른 쿼리 및 분석 워크로드를 위해 서로 다른 클러스터에서 zero-copy 액세스로 마운트할 수 있습니다.
새 레이블과 기능을 자주 추가하거나 임베딩 모델을 전환하는 등 데이터 모델이 지속적으로 진화하는 AI 및 에이전트 애플리케이션을 위해, Zilliz는 매끄럽고 고속의 스키마 진화 및 데이터 백필 메커니즘을 제공합니다.
새 필드는 풀링된 플랫폼 컴퓨트 리소스에 의해 백필되고 정렬된 다음, 메타데이터 업데이트를 통해 쿼리 클러스터에 노출됩니다. 1억 행 백필은 일반적으로 한 자릿수 분 단위로 완료될 수 있습니다.
대부분의 작업이 플랫폼 측 컴퓨트 리소스에 의해 처리되기 때문에, 기존 사용자 클러스터는 영향을 받지 않으며 프로세스 전반에 걸쳐 읽기 및 쓰기 트래픽을 계속 처리할 수 있습니다.
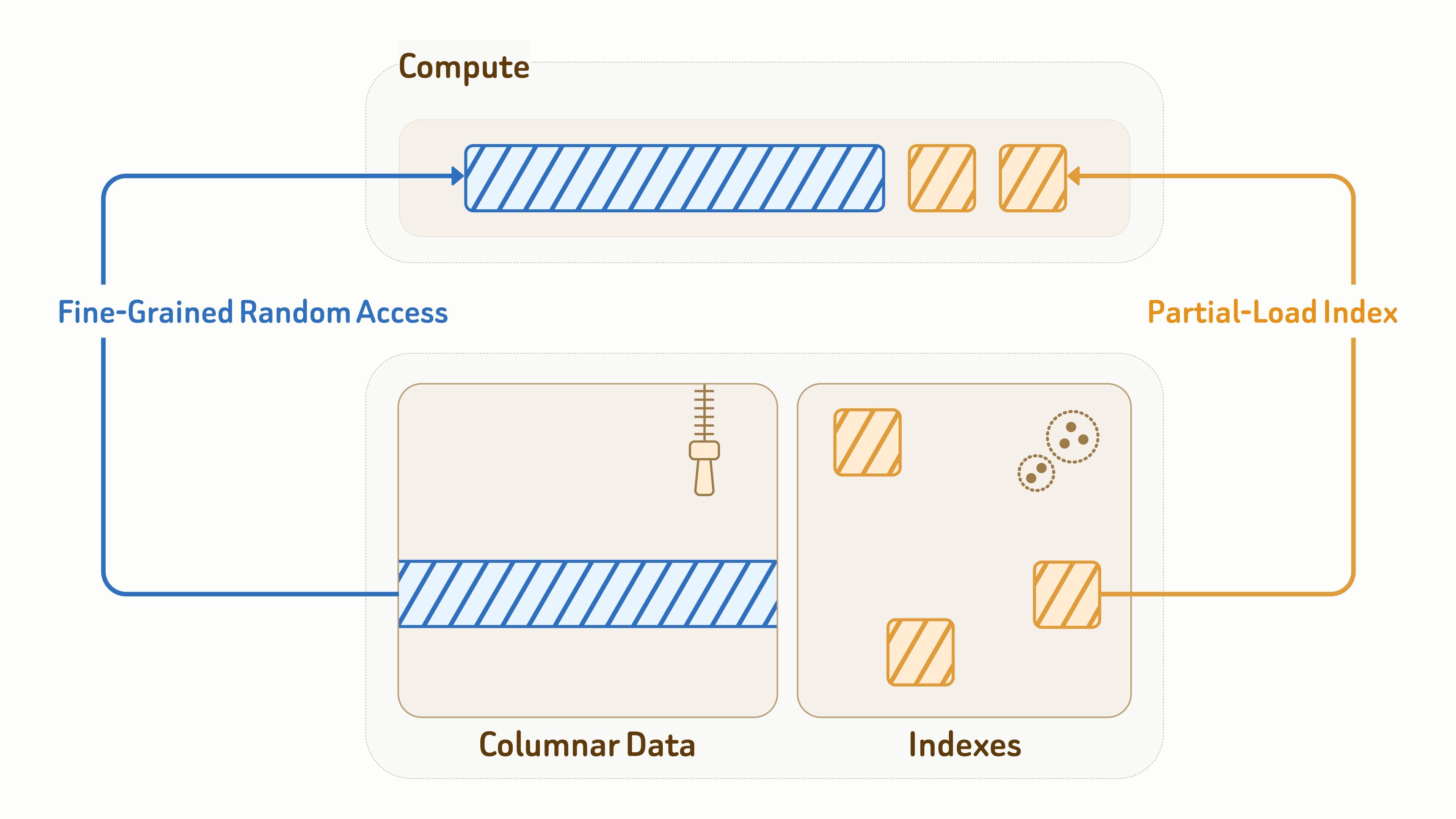
데이터 계층이 쿼리 워크로드도 직접 처리하기 때문에, 효율적인 I/O는 지연 시간과 처리량 모두에 매우 중요합니다.
컬렉션 데이터의 경우, Zilliz는 컬럼형 스토리지 레이아웃을 위해 Vortex 오픈 포맷을 사용하며, 효율적인 인코딩과 데이터 프래그먼트에 대한 세밀한 랜덤 액세스를 결합합니다 — 랜덤 읽기에서 Lance와 Parquet보다 훨씬 빠릅니다.
인덱스의 경우, Zilliz는 효율적인 I/O를 위해 깊이 최적화된 레이아웃과 액세스 패턴을 갖춘 오브젝트 스토리지 인식 인덱스 알고리즘 설계를 제공하며, 여기에는 벡터 인덱스, BM25 역색인, JSON 인덱스가 포함됩니다.
쿼리 실행 중에는 컴퓨트 노드가 쿼리가 접근한 인덱스 페이지와 데이터 엔티티만 부분적으로 로드합니다. 캐싱 및 데이터 프루닝과 결합하면, 이는 읽기 증폭을 90% 이상 크게 줄입니다.
Vector Lakebase의 주요 사용 사례
Vector Lakebase의 일반적인 애플리케이션 시나리오는 다음을 포함하지만 이에 국한되지 않습니다:
실시간 서빙 워크로드:
- 지연 시간에 민감한 에이전트 메모리 및 전략 검색.
- 법률, 헬스케어, 금융 및 기타 전문 산업을 위한 수직 도메인 지식 베이스.
- 웹 규모 AI 검색 엔진.
- 초고처리량 추천 시스템.
- 스토리지 계층 전반의 초 단위 동적 핫/콜드 데이터 스케줄링.
- 프리미엄 엔터프라이즈 사용자와 대규모 무료 사용자 풀 모두를 위한 차별화된 서비스 계층.
반복적 발견 워크로드:
- 피드백 데이터, 에이전트 생성 노트, 로그 및 기타 다중 소스 데이터 전반의 AI 서비스 품질 분석 및 문제 발견.
- 대규모 데이터셋의 효율적인 탐색.
- 다단계 반복형 심층 연구.
배치 분석 워크로드:
- 초대규모 코퍼스 중복 제거 및 클러스터링.
- 효율적인 필터링, 검색, 2단계 coarse-to-rerank 쿼리 파이프라인을 위해 Spark와 Ray에 전체 스펙트럼 검색 기능 추가.
- 학습 및 파인튜닝 데이터셋 준비.
하이브리드 사례:
- Lance 및 Iceberg와 같은 기존 데이터 레이크 테이블에서 가속화된 인덱싱 및 검색.
- 빈번한 대규모 백필을 수반하며 지속적으로 진화하는 데이터 모델.
- 벡터, 메타데이터, LLM 생성 요약 및 구조화된 필드를 일관된 버저닝과 계보 관리가 가능한 엔티티 중심 테이블로 통합하는 멀티모달 시맨틱 와이드 테이블 모델링.
Zilliz Vector Lakebase 사용해 보기
Vector Lakebase와 최신 업데이트에 대한 자세한 내용은 Zilliz 웹사이트를 방문하거나 Zilliz Cloud 문서를 살펴보세요. 이 글의 아키텍처나 사용 사례가 귀하의 업무와 관련이 있다면, 더 심도 있는 기술 논의를 위해 Zilliz 팀에 문의하세요.

계속 읽기

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.