




LLM의 한계
도메인별 정보 부족
LLM은 공개된 데이터만으로 학습되므로, 비공개 또는 도메인별 정보를 다루지 못할 수 있습니다.
환각 현상 발생 가능성
LLM은 보유한 정보에만 의존해 답변합니다. 충분한 데이터가 없을 경우 잘못된 정보나 허구의 내용을 제공할 수 있습니다.
비용이 많이 들고 속도가 느림
LLM은 쿼리의 모든 토큰에 대해 요금을 부과하므로, 반복적인 질문에는 비용이 많이 들 수 있습니다. 또한, 피크 시간대에는 응답 지연으로 인해 사용자에게 불편을 초래할 수 있습니다.
최신 정보 접근 실패
LLM은 종종 오래된 데이터로 학습되며, 고비용으로 인해 정기적으로 업데이트되지 않습니다. 예를 들어 GPT-3 학습 비용은 최대 140만 달러에 달합니다.
토큰 제한
LLM은 쿼리 프롬프트에 추가할 수 있는 토큰 수에 제한을 둡니다. 예를 들어, ChatGPT-3는 4,096개, GPT-4(8K)는 8,192개의 토큰 제한이 있습니다.
변경 불가능한 사전 학습 데이터
LLM의 사전 학습 데이터에는 오래되거나 잘못된 정보가 포함될 수 있으며, 이러한 데이터는 수정, 교체 또는 제거할 수 없습니다.
Zilliz Cloud가 LLM 애플리케이션을 향상하는 방법
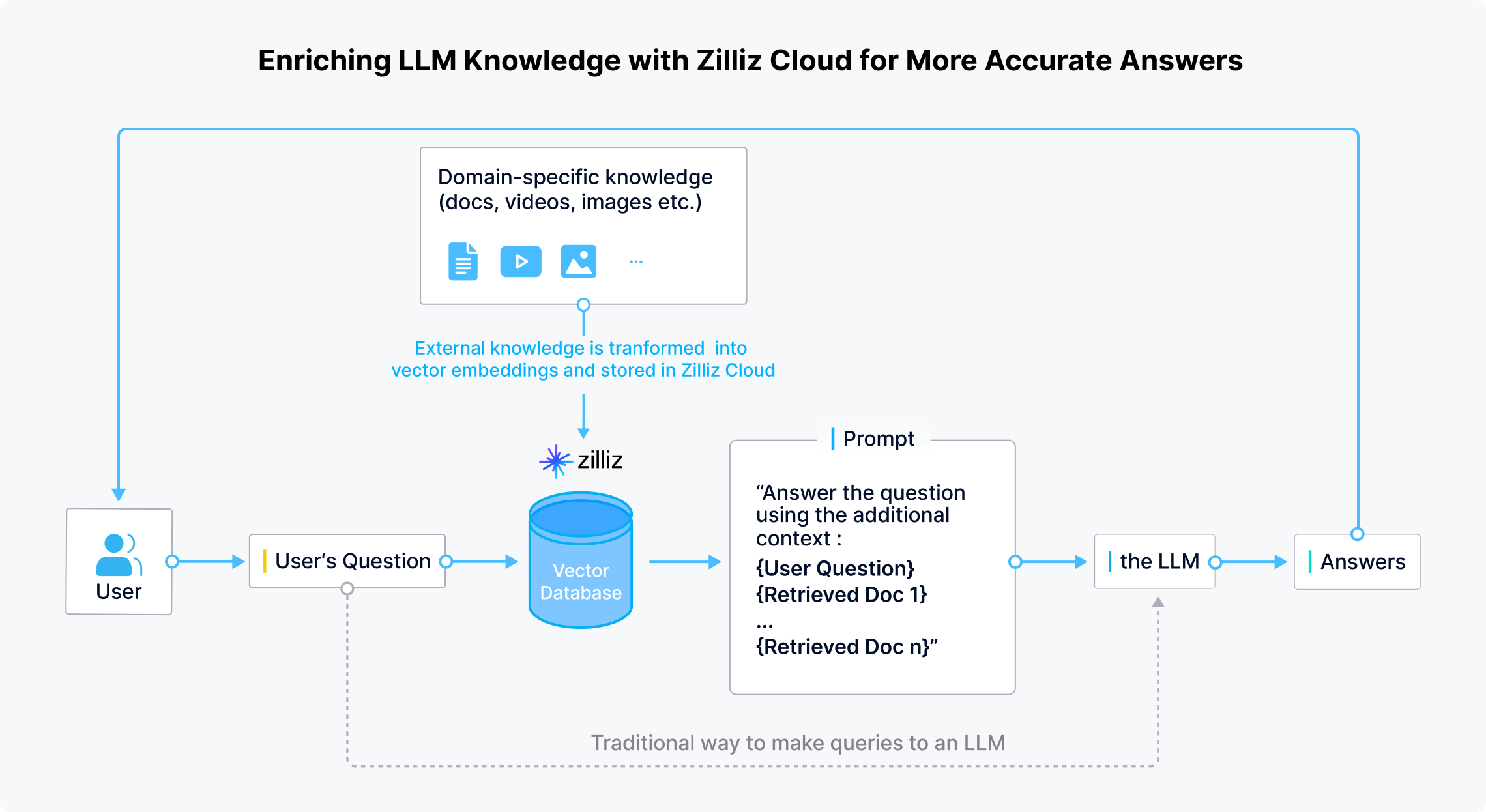
RAG로 LLM의 지식 기반 업데이트 및 확장
Zilliz Cloud는 도메인별 최신 비공개 데이터를 안전하게 저장할 수 있도록 합니다. 사용자가 질문하면 LLM 애플리케이션은 질문을 벡터로 변환하고, Zilliz Cloud는 유사성 검색을 수행하여 질문과 관련된 Top-K 결과를 제공합니다. 그런 다음 이 결과는 원래 질문과 결합되어 LLM이 보다 정확한 답변을 생성할 수 있도록 컨텍스트를 제공합니다.
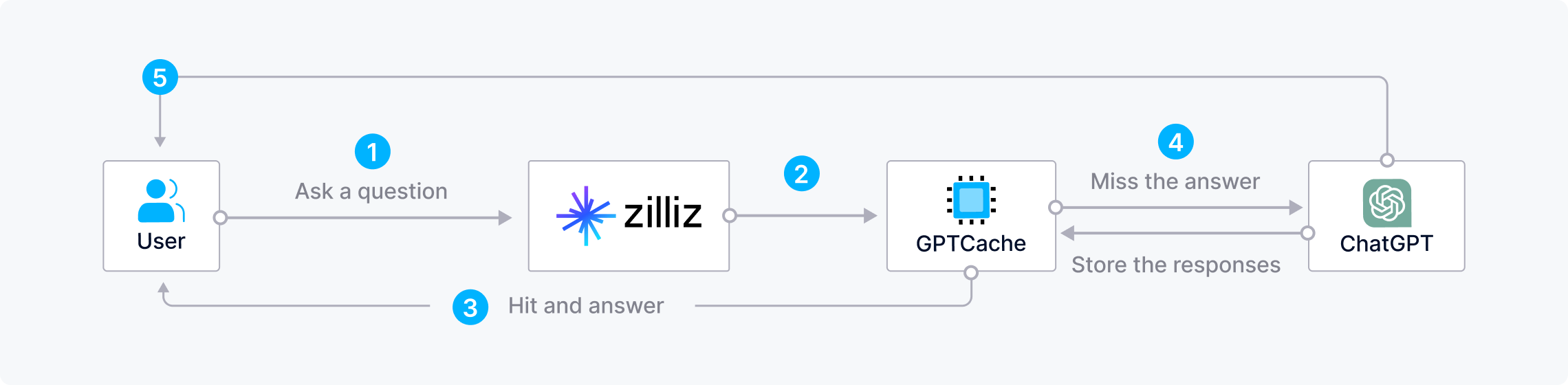
GPTCache와 함께 시간과 비용 절감
LLM에 반복적인 질문을 하면 비용과 시간이 많이 소요될 수 있습니다. Zilliz Cloud와 GPTCache를 함께 사용하면 비용 절감 및 응답 속도를 향상할 수 있습니다. 사용자가 질문을 하면 Zilliz는 먼저 GPTCache에서 답변을 찾고, 없으면 LLM에 쿼리를 보내고 결과를 GPTCache에 저장합니다.
CVP 스택
ChatGPT/LLM + 벡터 데이터베이스 + 코드 기반 프롬프트
CVP 스택(ChatGPT/LLM + 벡터 데이터베이스 + 코드 기반 프롬프트)은 AI의 성능을 극대화하는 인기 있는 기술 스택입니다. OSS Chat을 예로 들어 CVP 스택이 어떻게 작동하는지 설명합니다.
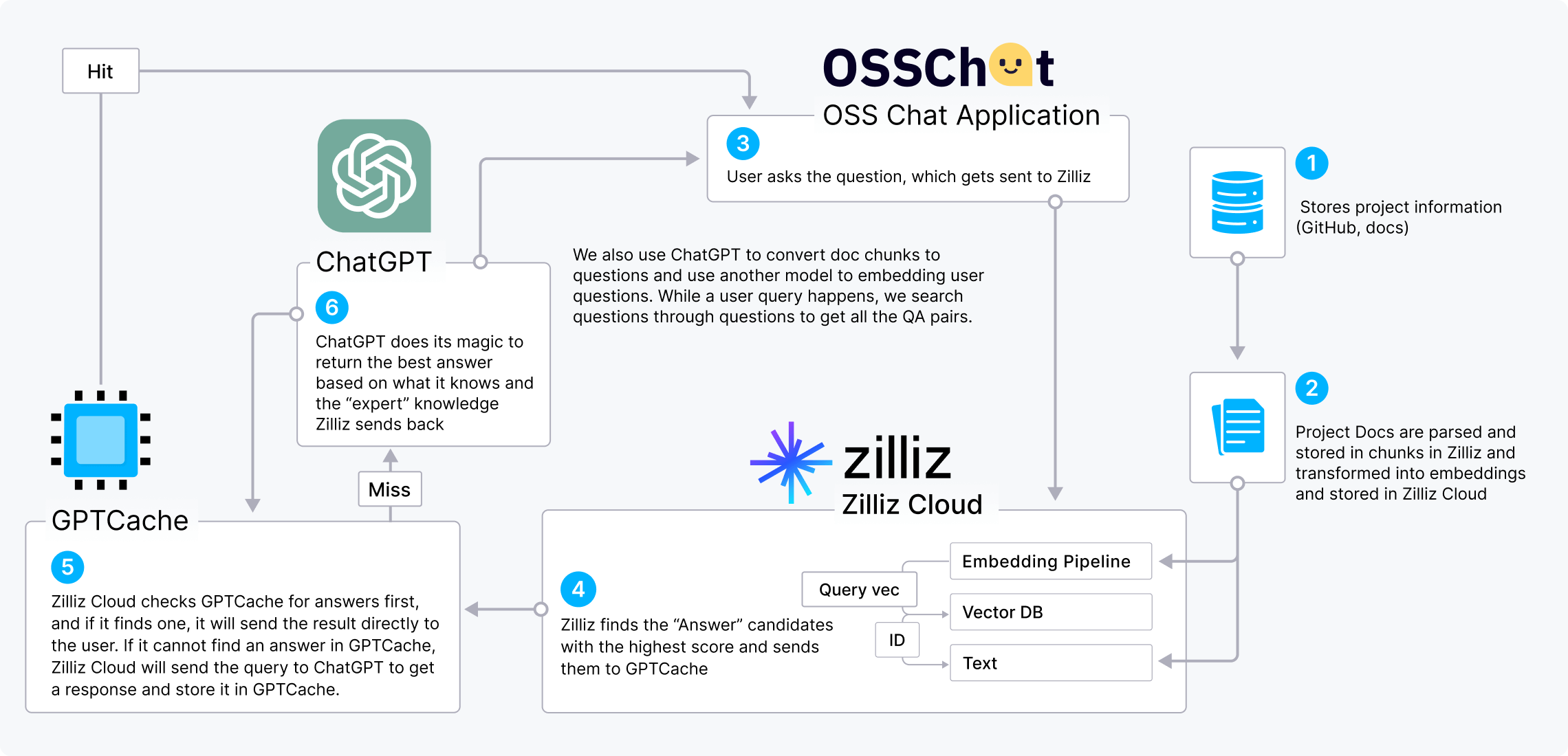
OSS Chat은 GitHub 프로젝트에 대한 질문에 답변하는 챗봇입니다. 다양한 GitHub 저장소와 문서에서 정보를 수집하고 이를 Zilliz Cloud에 벡터 임베딩 형태로 저장합니다. 사용자가 프로젝트에 대한 질문을 하면 Zilliz Cloud는 유사성 검색을 수행해 가장 관련성이 높은 결과를 반환하고, 이 결과는 질문과 결합되어 ChatGPT가 더 정확한 답변을 제공합니다.
CVP 스택에 GPTCache를 통합하여 비용 절감 및 응답 속도를 더욱 개선할 수 있습니다.
Milvus & Zilliz Cloud를 활용한 LLM 프로젝트
개발자들이 Milvus와 Zilliz Cloud를 통해 생성형 AI 애플리케이션을 어떻게 강화하고 있는지 알아보세요.
- OSS Chat
- PaperGPT
- NoticeAI
- Search.anything.io
- IkuStudies
- AssistLink AI
인기 있는 AI 프로젝트와의 Milvus 통합
OpenAI, LangChain, LlamaIndex 등 많은 AI 리더들이 Zilliz Cloud와 통합하여 검색 기능을 강화하고 있습니다.



