




LangchainコミュニティAPIを探る:MilvusとZillizによるシームレスなベクターデータベース統合
この記事では、LangChain Community APIと、MilvusとZillizを統合して効率的なベクターデータベースのやり取りを実現する方法を紹介します。
#はじめに
大規模言語モデル](https://zilliz.com/glossary/large-language-models-(llms))の潜在能力をフルに引き出すために、開発者は関連情報を効率的に管理・検索する方法が必要である。そこで登場するのがベクトル・データベースである。ベクターデータベースは類似したデータポイントの扱いに優れており、LLMを利用したアプリケーションに最適である。
LangChain Community APIはLangChainのコア機能を拡張し、ベクトルデータベースのサポートを含む追加ツールや統合機能を提供します。この統合により、開発者はLangChainアプリケーションでMilvusやZillizのような強力なベクトルデータベースをシームレスに活用することができます。この記事ではLangChain Community APIと、MilvusとZillizの統合による効率的なベクタデータベースのインタラクションについて紹介します。
ベクターデータベースの概要と重要性
ベクトルデータベースは、高次元のベクトルを効率的に保存・検索するために設計された特殊なデータベースです。これらのベクトルは、テキスト埋め込み、画像、音声、その他数値ベクトル表現に変換可能なあらゆるデータなど、様々な種類のデータを表現することができる。
LangChain](https://python.langchain.com/docs/get_started/introduction/)や自然言語処理(NLP)アプリケーションでは、ベクトルデータベースは特にテキスト埋め込みを保存・検索するのに便利です。テキスト埋め込みは、テキストのsemantic意味と文脈を捉えるテキストの数値表現であり、効率的な類似性比較と検索を可能にします。下の埋め込み表現を見てください:
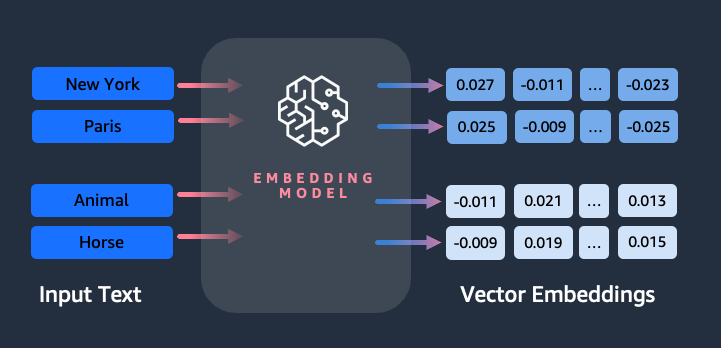
上の図は、埋め込みモデルがどのように単語を受け取り、それぞれのベクトル表現に変換するかを示しています。これにより、対応するベクトル間の距離を計算することで、データ点間の意味的類似度を測定することができます。似たような意味を持つ単語は、ベクトル空間において互いに近い埋め込みを持つことになります。
特に、MilvusやZillizクラウドのようなベクトルデータベースは、以下のようにベクトル埋め込みを使った関連情報の格納と検索に優れています:
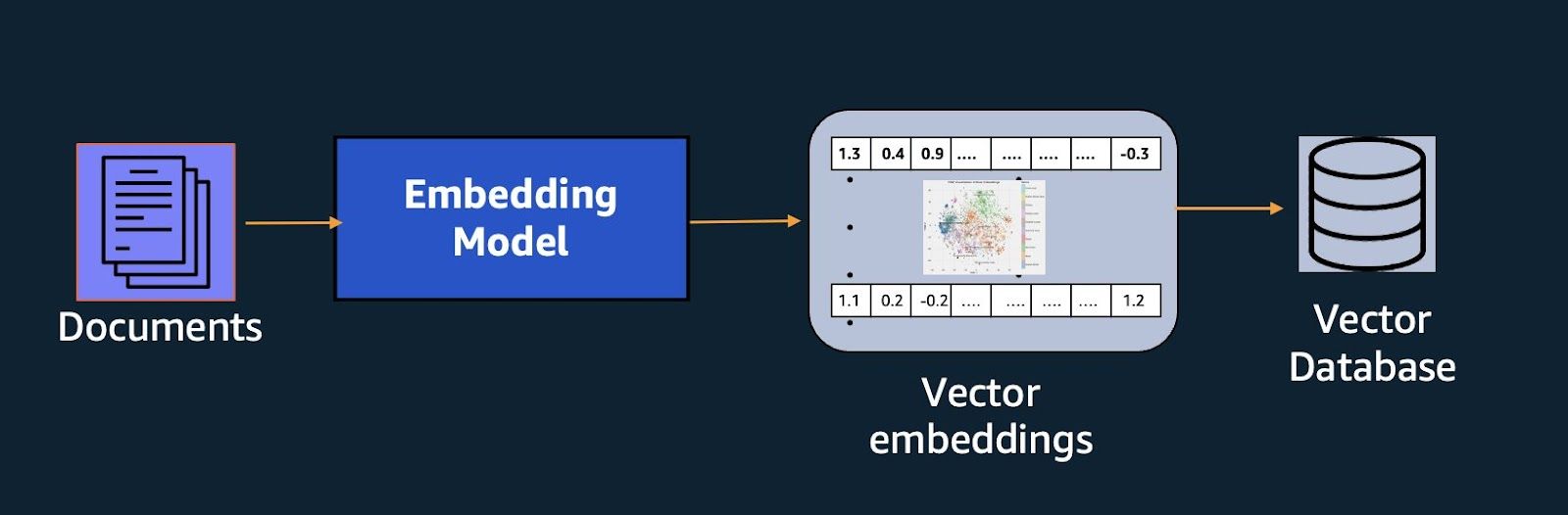
上の図は、文書がベクトル埋め込みとして表現され、埋め込みがベクトルDBに格納されていることを示しています。そして、このベクトルDBを使って、ユーザからのクエリに対して関連する文書を取り出すことができる。
ベクトルデータベースを活用することで、LangChainアプリケーションは、意味の類似性に基づいて大規模なテキストコーパスから関連情報を迅速かつ正確に検索することができ、質問応答、情報検索、知識抽出などの強力な機能を実現します。
なぜMilvusとZillizを使うのか?
Milvusベクトルデータベースは、大量のベクトルデータの保存とクエリのための非常にスケーラブルで高性能なソリューションを提供し、効率的なベクトル類似検索機能を必要とするアプリケーションにとって理想的な選択肢となります。
Milvusの主な特徴は以下の通り:
スケーラビリティ**:Milvusは数十億のベクトルを扱うことができ、分散配置による水平スケーリングをサポートします。
高性能**:Milvusは高度なインデックス作成技術と並列化技術により、高速なベクトル類似検索を実現します。
柔軟なデータモデル**:Milvusはフラット、階層型、ハイブリッドなど様々なデータモデルをサポートし、構造化データおよび非構造化データの効率的な保存と検索を可能にします。
複数のインデックスタイプMilvusは、HNSW、FLAT、IVF_FLAT、IVF_PQなどの複数のインデックスタイプを提供しており、ユーザは特定のユースケースとパフォーマンス要件に基づいて最適なインデックスタイプを選択することができます。
一方、ZillizはMilvusのクラウド管理版である。Milvusを中核とするベクトルDBに、データ取り込み、ETL(抽出、変換、ロード)パイプライン、データ可視化ツールなどの機能を追加している。
Zillizの主な特徴は以下の通り:
- マネージドMilvusデプロイメント**:Zillizは、最適なパフォーマンス、スケーラビリティ、使いやすさを保証するフルマネージドMilvusデプロイメントを提供します。
Data Ingestion Pipelines](https://zilliz.com/zilliz-cloud-pipelines):Zillizは様々なソースからデータを取り込み、前処理するためのツールとAPIを提供し、ベクトルデータベースのデータ準備プロセスを合理化します。
ETLワークフロー**:Zillizは、Milvusに格納する前にデータを変換・強化するための複雑なETLワークフローの構築をサポートします。
データ可視化**](https://zilliz.com/blog/Visualize-Your-Approximate-Nearest-Neighbor-Search-with-Feder):Zillizは、ユーザーがベクトルデータを探索し、分析し、より良い理解と解釈を可能にするデータ可視化ツールを備えています。
クラウドネイティブアーキテクチャ**:Zillizはクラウドネイティブなプラットフォームとして設計されており、最新のクラウドコンピューティング環境とのシームレスな統合を保証し、容易なスケーリングとデプロイメントを可能にします。
ローカルでベクトルDBを使用したい場合は、Milvusがそれをカバーします。一方、Milvusのフルマネージドクラウドバージョンをご希望の場合は、Zillizをお選びください。
MilvusとZillizのLangChainコミュニティAPIとの統合
Langchain Community API](https://api.python.langchain.com/en/latest/community_api_reference.html#)には、MilvusとZillizの両方専用のベクターストアコネクターが含まれています。これにより、LangChainアプリケーション内でのシームレスなベクター検索とデータベースサポートが可能になります。これらの統合により、LangChainアプリケーション内で効率的な検索や類似検索機能のためにベクトルデータベースの力を活用することができます。
環境の設定
Python環境](https://docs.python.org/3/library/venv.html)でMilvusやZillizと対話するためのPython SDKであるPyMilvusをインストールする必要があります。以下のコマンドを実行して、PyMilvus を PiP でインストールします:
bash
pip install pymilvus
次に以下のコマンドでLangChain、LangChain OpenAI、python-dotenv、Langchain Community APIをインストールする:
bash
pip install langchain langchain-community langchain-openai python-dotenv
Langchain Community APIはMilvusとZillizベクトルストア・コネクタを提供し、Langchainはtext splitterクラスを提供し、最後にLangChain OpenAIはOpenAIの埋め込みモデルを使ってテキストを埋め込むことを可能にします。
そして最後に、LangChain OpenAIによって、OpenAIの埋め込みモデルを使ってテキストを埋め込むことができるようになる:
バッシュ
from dotenv import load_dotenv
load_dotenv()
ライブラリのインストールが終了したら、統合ステップに進む前にMilvusインスタンスが起動していることを確認してください。Milvusをセットアップしていない場合は、[Milvus](https://milvus.io/docs/install_standalone-docker.md) project[ setup guide](https://milvus.io/docs/install_standalone-docker.md)を参照してください。
### MilvusとLangChainコミュニティAPIの統合<a id="integrating-milvus-with-langchain-community-api"></a>.
LangChainとMilvusを統合し、エンベッディングを保存してみましょう。まず、インストールしたライブラリから必要なクラスをインポートします。
``python
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Milvus
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
クラスをインポートした後、埋め込みモデルにアクセスする前に自分自身を認証する必要があるので、OpenAIのAPIキーを格納する変数を宣言する必要があります。APIキーを取得するには、この記事に従ってください。そして、APIキーを環境変数に格納し、このコードを使って取得します。OpenAIのエンベッディングモデルを使うことは必須ではなく、他のモデルを使うこともできます](https://python.langchain.com/docs/modules/data_connection/text_embedding/)。
パイソン
import os
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
ここで、Milvusベクターデータベースに格納するデータをロードし、小さなチャンクに分割する必要があります。こうすることで、効率的なインデックス作成が可能になります。データを分割した後、OpenAIのエンベッディングモデルを初期化します。
パイソン
loader = TextLoader("/content/vector-databases.txt")
ドキュメント = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
データと埋め込みモデルの準備ができたので、次はLanchain-Community API vector store connectorを使ってMilvusデータベースインスタンスに接続し、データと埋め込みモデルを保存します。
パイソン
milvus_db_integration = Milvus.from_documents(
docs、
embeddings、
connection_args={"host":「localhost", "port":"19530"},
)
上記のコードでMilvusのローカルホストに接続し、分割されたドキュメントをエンベッディングとともに保存します。
接続が成功したことを確認するために、クエリを渡してベクトルストアの類似性検索を行ってみましょう。
パイソン
query = "ベクトルストアとは?"
docs = milvus_db_integration.similarity_search(query)
docs[0].page_content
上記のコードの出力は以下のようになる:

最初に検索された関連文書が、ベクトルストアに関するクエリと類似していることがわかる。
ZillizとLangChainコミュニティAPIの統合
前節の例では、あなたのコンピュータ上でローカルにホストされているMilvusインスタンスを統合に使用しました。このセクションでは、クラウド上にホストされたフルマネージド版MilvusであるZillizとLangChain Community APIとの統合について説明します。
この統合にはZillizの接続認証情報が必要です。Zillizアカウントにサインアップ](https://cloud.zilliz.com/signup)することで取得できます。サインアップ後、30日間有効な$100分の無料クレジットを受け取ることができます。続けてcreate a clusterに進み、接続認証情報を取得します。

これで統合プロセスを開始する準備ができました。統合プロセスはMilvusの統合プロセスと非常に似ていますが、若干の変更があります。
まず、必要なモジュールをインポートしてください。
パイソン
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Zilliz
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
次に、必要なZillizとOpenAIの環境変数を設定します。Zilliz のログイン認証情報を `.env` ファイルに追加するのを忘れないでください。
python
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
ZILLIZ_CLOUD_URI = os.getenv("ZILLIZ_CLOUD_URI")
ZILLIZ_CLOUD_API_KEY = os.getenv("ZILLIZ_CLOUD_API_KEY")
OpenAIのエンベッディングを初期化し、ドキュメントを読み込み、Milvusで行ったようにコンテンツをチャンクに分割します。
python
embeddings = OpenAIEmbeddings()
loader = TextLoader('/content/vectot-databases.txt')
ドキュメント = loader.load()
ドキュメントをチャンクに分割する
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = text_splitter.split_documents(documents)
クラスタに接続し、チャンク、エンベッディング、接続認証情報を渡してZillizとLangchain Community APIを統合します。
パイソン
vectorstore = Zilliz.from_documents(
documents=docs、
embedding=embeddings、
connection_args={
"uri":zilliz_cloud_uri、
"token":zilliz_cloud_api_key、
"secure":token":zilliz_cloud_api_key、
},
auto_id=True、
drop_old=True、
)
クエリーを渡し、ベクターストアの類似性検索を行い、接続が成功したことを確認してみましょう。
python
query = "ベクトルストアとは?"
docs = vectorstore.similarity_search(query)
docs[0].page_content
類似検索が完了すると、次のような結果が出力される。
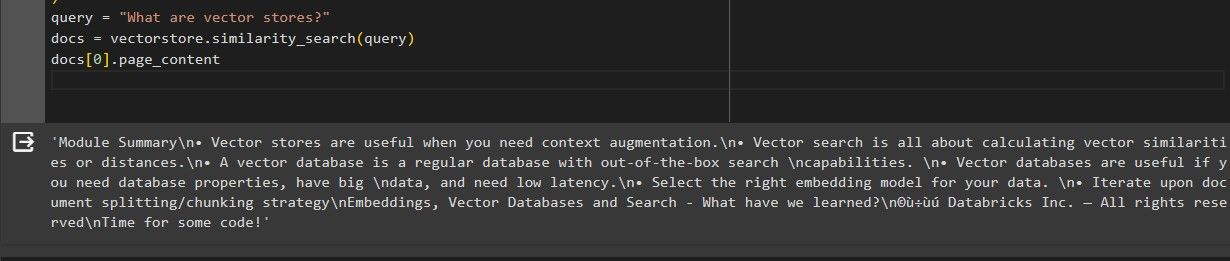
最初に検索された関連文書が、ベクトル・ストアに関するクエリと類似していることがわかる。
保存された情報は、Zillizアカウントのデータプレビューセクションからアクセスすることもできます。
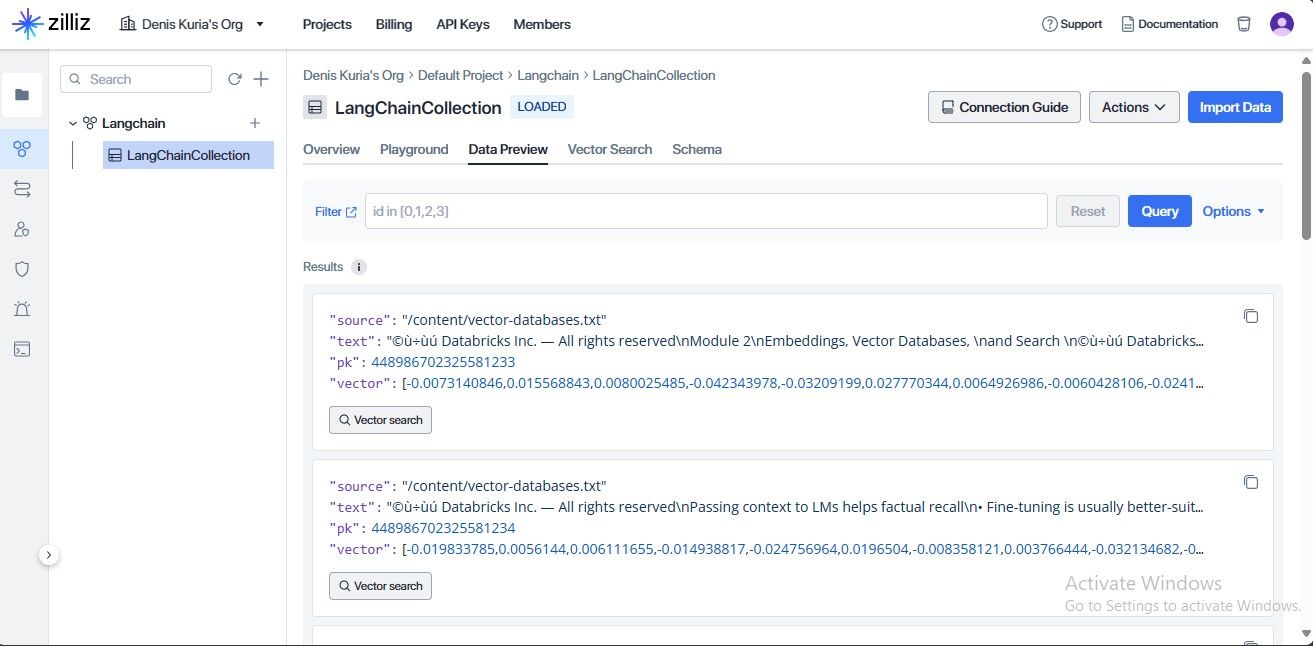
統合が成功し、データとその埋め込みが保存されたことがわかります。
## 実用例と使用例
MilvusとZillizをLangChain Community APIと統合することで、実用的なユースケースやアプリケーションの幅が広がります。以下はその一例です:
* 質問応答システム:LangChainの質問応答機能とMilvusやZillizが提供する効率的なベクトル検索を組み合わせることで、開発者は大規模なテキストコーパスから関連する情報を素早く見つけることができる強力な質問応答システムを構築することができます。
* ドキュメントの類似性とクラスタリング:LangChainアプリケーションはベクトルデータベースを活用し、効率的な文書類似性比較とクラスタリングを行うことができ、重複排除、トピックモデリング、文書整理などのタスクを実現します。
* 知識ベース構築:ベクターデータベースは、様々な概念、エンティティ、関係を表すテキスト埋め込みを保存・検索することで、リッチな知識ベースを構築するために使用することができ、LangChainアプリケーション内での高度な知識抽出と推論機能を可能にします。
* パーソナライズされたコンテンツ推薦:テキスト埋め込みとベクトルデータベースに保存されたユーザ嗜好ベクトルを組み合わせることで、LangChainアプリケーションは意味的類似性に基づいたパーソナライズされたコンテンツ推薦を提供することができます。
* 会話AI: ベクトルデータベースは、大規模な知識ベースから関連する文脈や情報を効率的に検索することができるため、LangChainで構築された会話AIシステムの機能を強化することができます。
知識ベース構築と質問応答ユースケースをカバーする単純な検索拡張世代(RAG)システムを実装してみよう。
## RAG システムの開発
ローカルにホストされたMilvusインスタンスと比較して、Zillizクラウドの方が検索速度が速いため、類似検索の実装にはZillizベクトルストアを使用する。
### 必要なモジュールのインポート
必要なモジュールのインポートから始める。また、LangChain Community API document retriever moduleから**PyPDF**をインポートします。
バッシュ
pip install pypdf
パイソン
インポート os
from langchain_openai import OpenAI
from langchain_community.vectorstores import Zilliz
from langchain_community.document_loaders import TextLoader, PyPDFLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.prompts import PromptTemplate
LLM がレスポンスを生成する際のガイドとなる `Prompt Template` クラスもインポートする。RunnablePassthrough` クラスは RAG パイプラインを構築するためのもので、 `StrOutputParser` クラスは LLM からの出力を使用可能な形式にパースするためのものである。
### 環境変数のセットアップ
次に、**OpenAI** と **Zilliz** クラウドサービスにアクセスするために必要な環境変数を定義します。
パイソン
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
ZILLIZ_CLOUD_URI = os.getenv("ZILLIZ_CLOUD_URI")
ZILLIZ_CLOUD_API_KEY = os.getenv("ZILLIZ_CLOUD_API_KEY")
注意すべき点は、セキュリティ上の理由から、これらのAPIキーをコード内で公開しないことだ。
OpenAI LLMとエンベッディングの初期化
LLMは応答を生成するために使用されるAIモデルで、埋め込みモデルはテキストデータをZillizベクトルデータベースによる保存と検索に適した数値表現に変換するために使用されます。
パイソン
llm = OpenAI(temperature=0.1)
埋め込み = OpenAIEmbeddings()
temperature`パラメータはLLMが生成するテキストのランダム性を制御する(値が小さいほど、より保守的な出力になる)。
### ドキュメントの読み込みと分割
チャットを行いたいPDFまたはテキストファイルファイルをロードする。
パイソン
file_path = '/content/vector-databases.pdf,' # これをファイルパスに変更する。
if file_path.endswith('.txt'):
loader = TextLoader(file_path)
elif file_path.endswith('.pdf'):
loader = PyPDFLoader(file_path)
else:
raise ValueError("Unsupported file type. .txt または .pdf ファイルを指定してください。")
ドキュメント = loader.load()
これは、チャンクの境界で情報が欠落するのを防ぐために、指定されたオーバーラップで文字数に基づいてドキュメントを分割します。
パイソン
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
docs = text_splitter.split_documents(documents)
これが埋め込みを生成するためのチャンクです。
### プロンプトテンプレートの定義とプロンプトオブジェクトの作成
LLMに動作を指示するプロンプト・テンプレートを定義することから始めましょう。テンプレートは好みに応じて変更できます。
パイソン
prompt_template = """
人間:あなたは親切なアシスタントで、提供された文脈を使って質問に答えます。以下の情報を使って、<question>タグで囲まれた質問に簡潔に答えてください。答えがわからない場合は、わからないと答え、答えを作ろうとしないでください。
<context> {コンテキスト}。</context>
<question> {質問}。</question>
アシスタント:""
次に、プロンプトテンプレートのインスタンスを作成します。
``python
prompt = PromptTemplate(
テンプレート=PROMPT_TEMPLATE、
input_variables=["コンテキスト", "質問"].
)
このコードでは、定義されたテンプレート文字列 (`PROMPT_TEMPLATE`) を使用して `PromptTemplate` オブジェクトを作成し、テンプレート内のプレースホルダを埋めるために使用される入力変数 (`context` と `question`) を指定します。
### Zilliz ベクトルストアの初期化
埋め込みデータを保存し、意味的類似度に基づいた効率的な検索を可能にするZillizベクトルストアを初期化する。これは知識ベースとして機能する。
パイソン
vectorstore = Zilliz.from_documents(
documents=docs、
embedding=embeddings、
connection_args={
"uri":zilliz_cloud_uri、
"token":zilliz_cloud_api_key、
"secure":token":zilliz_cloud_api_key、
},
auto_id=True、
drop_old=True、
)
このコードでは、ベクターストアに新しいドキュメントを入れる前に、既存のデータをすべて削除しています。
レトリバーの作成と取得したドキュメントのフォーマット
Zillizベクトルストアからretrieverオブジェクトを作成します。リトリーバーは、指定されたクエリに基づいて関連ドキュメントを検索するために使用されます。
``python
retriever = vectorstore.as_retriever()
次に、ヘルパー関数 `format_docs` を定義する。この関数は、検索されたドキュメントのリストを受け取り、それらのページの内容を結合する (`page_content` 属性を持っていると仮定する)。
python
def format_docs(docs):
return "nn".join(doc.page_content for doc in docs)
この関数は、読みやすくするために改行を2倍にします。
RAG チェーンの構築と呼び出し
核となるRAG(Retrieval-Augmented Generation)チェーンを構築する。RAGシステムは、応答品質を向上させるために、文書検索とLLM生成を組み合わせる。
パイソン
rag_chain = (
{"context": retriever | format_docs, "question":RunnablePassthrough()}.
| プロンプト
| プロンプト
| StrOutputParser()
)
チェーンの仕組みはこうだ:
- context": retriever | format_docs`:retrieverを使ってZillizストアから関連ドキュメントを取得し、取得したドキュメントをフォーマットする。
- 質問RunnablePassthrough()`:このパートでは、ユーザーが提供した質問を変更することなくチェーンに渡すことができます。
- `| prompt`:定義されたプロンプトテンプレート (`prompt`) をコンテキストと質問に適用します。
- `| llm`:プロンプトテキストを OpenAI LLM に送信し、レスポンスを生成します。
- StrOutputParser()`:LLM の出力を文字列形式に解析します。
最後に、RAG チェインを呼び出して、ドキュメントとチャットします。
``python
question = "vecoreストアとは何ですか?"
response = rag_chain.invoke(question)
print(response)
以下は、RAGチェーンを呼び出した結果である。

この結果から、得られた回答が質問に対する直接的な回答であることがわかる。これは、私たちのシステムがZillizベクトルストアの知識ベースを持つ質問応答システムとして構築されているからです。
結論
コミュニティAPIを通じてMilvusとZillizをLangChainと統合することで、開発者はNLPアプリケーションの情報検索に効率的なLangChain類似検索を活用することができます。これにより、質問応答型知識ベース構築などの革新的なユースケースへの道が開かれます。
どうぞ、より実用的な類似検索のユースケースを実装してみてください!
その他のリソース
このノート](https://colab.research.google.com/drive/1AzMx54yvTyZ8GPfEQxUD8rU0dgyPF90K?usp=sharing)からソースコードを入手できます。
https://python.langchain.com/docs/integrations/vectorstores/milvus/
https://api.python.langchain.com/en/latest/community_api_reference.html#
https://python.langchain.com/docs/integrations/vectorstores/zilliz/
https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.



{kind=link}
{kind=link}