




♪言葉からベクトルへ:自然言語処理(NLP)におけるWord2Vecの理解
♪言葉からベクトルへ:自然言語処理(NLP)におけるWord2Vecの理解
Word2Vecとは?
Word2Vecは機械学習モデルで、単語を数値 ベクトル表現に変換し、単語が出現する文脈に基づいて意味を捉える。GoogleのTomas Mikolovと彼のチームによって開発されたこのモデルは、大規模なテキストデータセットを使って単語間の関係を理解し、意味的・構文的な類似性を表現する。ワンホットエンコーディングのような従来のアプローチとは異なり、Word2Vecは、連続ベクトル空間において類似した単語がより近くに配置される、高密度で意味のある埋め込みを作成する。Word2Vecは、感情分析や推薦システムのような自然言語処理アプリケーションで広く使用されている。
なぜWord2Vecが必要なのか?
自然言語処理(NLP)](https://zilliz.com/ai-faq/what-is-natural-language-processing-nlp)において、単語の関係や意味を理解することは重要な課題です。ワンホットエンコーディングのような従来の方法では、単語を疎な高次元ベクトルとして表現し、各単語は他の単語から独立している。このアプローチでは、単語間の意味的・統語的関係を捉えることができない。例えば、ワンホットエンコーディングでは、"king "と "queen "のベクトルは、意味が密接につながっているにもかかわらず、まったく無関係に見える。
さらに、このような疎な表現は、特に大規模な語彙の場合、計算効率が悪く、見たことのない単語や文脈にうまく一般化できない。この制限により、機械が言語を真に理解することが難しくなり、機械翻訳、感情分析、検索ランキングなどのタスクの進歩を妨げている。
Word2Vecは、コンパクトで高密度なword embeddingsを作成することで、このような課題を解決します。このword embeddingsは、単語がテキストにどのように現れるかを基に、単語間の関係を表現します。Word2Vecは、単語の意味とその文脈の両方を捉えることで、機械が人間の言語を解釈・処理する方法を変え、より効率的で意味のあるものにしています。
Word2Vecの仕組み
Word2Vecの核となるのは単語の埋め込みで、これは単語の意味と構文の特性を捕らえた低次元の高密度ベクトルです。Word2Vecは、単語間の関係を学習するために大量のテキストを分析することによって動作します。その核となるのは浅いニューラルネットワークで、単語のベクトル表現を生成し、意味と構文の意味を捉える。このモデルは、文中での単語の共起の仕方のパターンを特定し、この情報を使って、連続ベクトル空間において、関連する単語をより近くに配置する。
主な概念は、類似したベクトルは類似した意味や使用文脈を持つ単語を表すということである。例えば、"king "と "queen "という単語は、性別のような特定の意味的区別をエンコードする違いを持つ、密接に関連したベクトルを持つ。
図-単語の埋め込み.png](https://assets.zilliz.com/Figure_Word_Embeddings_b021a5a759.png)
図:単語の埋め込み
Word2Vecは、文脈の扱い方によって、2つの埋め込み生成アプローチを提供します:
連続単語袋(CBOW)
Continuous Bag of Wordsは、周囲の単語から対象単語を予測する。例えば、"Apples are sweet and juicy "という文では、CBOWは文脈語("Apples", "are", "and", "juicy")を使って、"sweet "のような目的語を予測する。
CBOWは文脈単語を平均して対象を予測するため、計算効率が高い。しかし、CBOWは頻度の高い単語でより優れた性能を発揮し、稀な単語では苦戦する可能性がある。
使用例: CBOWは、オートコンプリートやスペルチェックのような、欠落している単語や次の単語を予測する必要があるアプリケーションで一般的に使用されている。
スキップグラムモデル
Skip-Gramは予測プロセスを逆転させます。文脈から目的語を予測する代わりに、目的語に基づいて文脈語を予測する。例えば、ターゲット単語が "sweet "の場合、Skip-Gramは文脈単語 "Apples," "are," "and," "juicy "を予測する。
Skip-Gramは珍しい単語を扱うのが得意で、大規模なデータセットを扱う場合、より微妙な関係を捉えるのに特に効果的です。
使用例: Skip-Gramは、推薦システムの構築や専門分野の類似語のクラスタリングのようなタスクで価値があります。
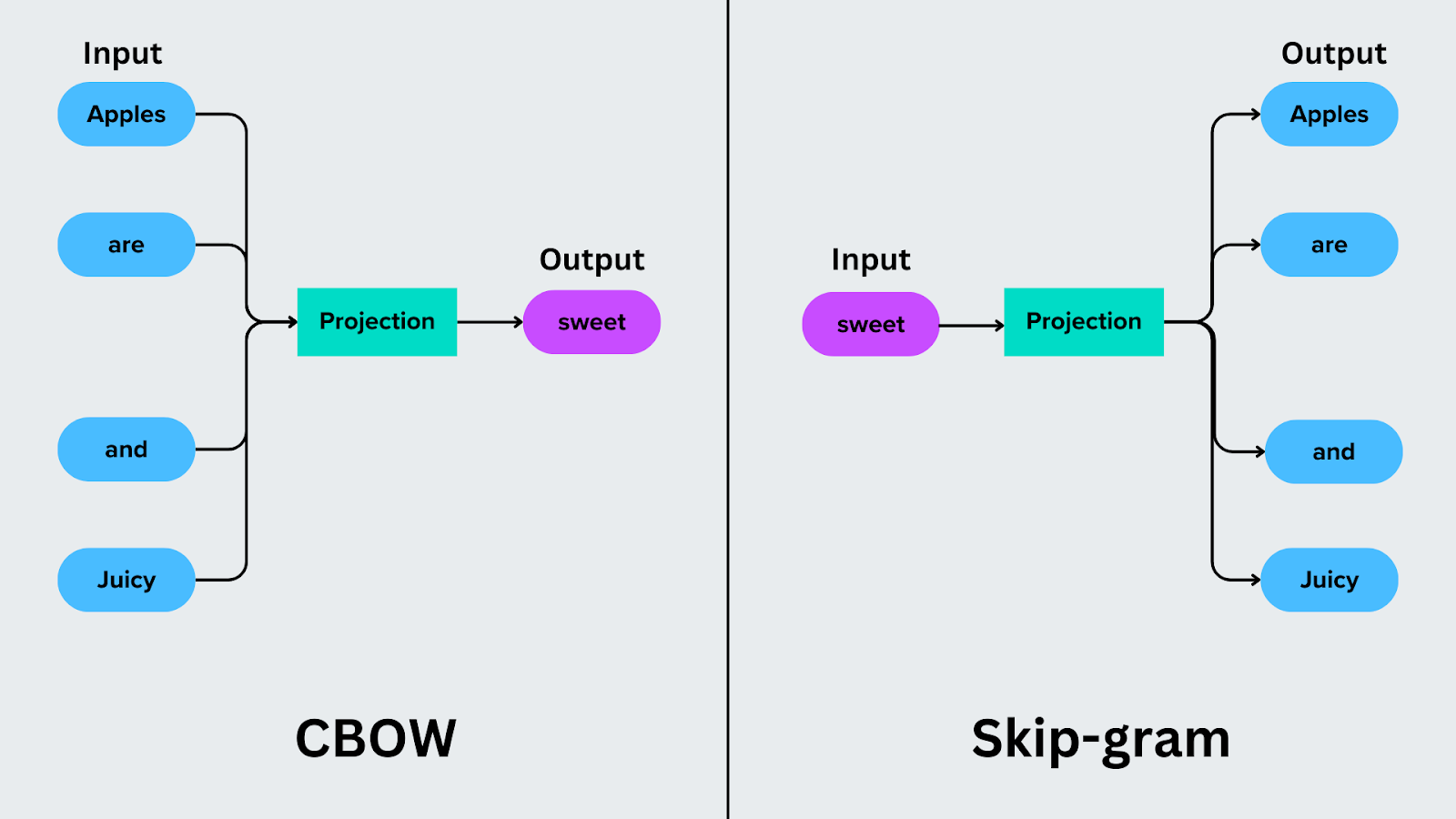 図- CBOW vs Skip-gram.png
図- CBOW vs Skip-gram.png
**図-CBOW対スキップグラム
CBOWとスキップグラムモデルの違い
CBOWとSkip-Gramはどちらも意味のある方法で単語を表現することを目的としていますが、文脈に基づいて単語を処理し予測する方法が異なります。以下は、これら2つのアプローチの主な違いを強調するための比較です:
| 特徴| Continuous Bag of Words (CBOW)| Skip-Gram | ---------------------------- | --------------------------------------------------------- | -------------------------------------------------------- | | 目的語|周囲の文脈から目的語を決定する。| 目的語から文脈を予測する。 | | 効率|学習が速い。 | 学習が遅い。 | | 頻出単語を効果的に扱う。 | 稀な単語を効果的に扱う。 | | 複雑さ|単純で計算効率が良い。 | 複雑で計算量が多い。 | | 単語予測やオートコレクトのようなタスクに適している。 | 推薦システムのような特殊なタスクに最適。| | すべての文脈語の平均を考慮する。 | 個々の文脈語を個別に評価する。 | | データセットのサイズ要件**|小さいデータセットでよく機能する。 | 大きなデータセットでより良い性能を発揮する。 | | 例: "The dog is ___" から "barking" を予測。 | "吠える "から "The"、"dog"、"is "を予測する。 |
表: CBOWとSkip-Gramの比較
Python による Word2Vec の実装
以下は、CBOWメソッドとSkip-Gramメソッドを使用したWord2VecのPython実装です。このコードは単語の埋め込みを学習するために小さなカスタムデータセットで学習し、文脈に基づいて単語間の関係をキャプチャするために両方のメソッドがどのように動作するかを示します。コードの両セクションは、CBOWとSkip-Gramがどのように異なる単語間の関係を学習するかを比較するように設計されていますが、公平な比較のために同じパラメータを共有しています。下記のKaggle notebookに実装があります。
コード
from gensim.models import Word2Vec
# 小さなコーパス
コーパス = [
["cat", "dog", "barked"]、
["dog", "chased", "cat"]、
[猫", "座った", "マット"]、
[犬", "走った", "速い"]、
[猫", "走った", "速い"]、
[犬", "座った", "マット"]
]
# CBOWモデルを学習する
cbow_model = Word2Vec(
sentences=corpus、
vector_size=10, # 簡単のためベクトルサイズは小さめ
window=2, # コンテキストウィンドウサイズ
min_count=1, # 全ての単語を含める
sg=0 # CBOWではsg=0とする
)
# スキップグラムモデルの学習
skipgram_model = Word2Vec(
sentences=corpus、
vector_size=10, # シンプルにするためにベクトルサイズを小さくする。
window=2, # コンテキストウィンドウサイズ
min_count=1, # 全ての単語を含める
sg=1 # スキップグラムにはsg=1を設定する
)
# 単語ベクトルと類似単語を表示する関数
def display_model_results(model, model_name):
print(f"{model_name} ---")
for word in ["cat", "dog"]:
print(f "Word Vector for '{word}': {model.wv[word][:5]}...") # ベクトルの最初の5つの値を表示する
similar_words = model.wv.most_similar(word, topn=3)
print(f "Most similar to '{word}':{[(w, round(sim, 2)) for w, sim in similar_words]}")
# CBOWモデルの結果を表示する
display_model_results(cbow_model, "CBOW モデル")
# スキップグラムモデルの結果を表示
display_model_results(skipgram_model, "スキップグラムモデル")
出力:
--- CBOWモデル
cat」の単語ベクトル:[ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... cat' に最も似ている:('犬', 0.54), ('速い', 0.33), ('吠える', 0.23)]. dog' の単語ベクトル: [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... dog' に最も似ている単語: [('cat', 0.54), ('fast', 0.3), ('ran', 0.1)]...
--- スキップグラムモデル
cat' に対する単語ベクトル:[ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... cat' に最も似ている:('犬', 0.54), ('速い', 0.33), ('吠える', 0.23)]. dog' の単語ベクトル: [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... dog' に最も似ている単語: [('cat', 0.54), ('fast', 0.3), ('ran', 0.1)]...
CBOWの部分では
これはWord2VecにContinuous Bag of Wordsメソッドを使うように指示する。
CBOWは周りの単語の文脈を使って単語を決定する。例えば、["dog", "chased", "cat"]という文では、モデルは "dog "と "cat "を使って "chased "を予測するかもしれない。
vector_size=10は、単語の埋め込みサイズ(各単語を表す数字の数)を定義します。
window=2はcontext windowを指定します。つまり、ターゲット単語の前後2単語までを考慮します。
スキップグラムの部分で
モデルはパラメータsg=1を用いて学習され、Word2VecはSkip-Gramメソッドに切り替わります。
Skip-Gramは指定されたターゲット単語を使って周囲の単語を識別します。例えば、ターゲット単語が "chased "の場合、モデルは "dog "と "cat "を近傍単語として予測します。
CBOWに似ている:
vector_size=10は単語の埋め込みサイズを定義します。
window=2は考慮する文脈語の範囲を設定する。
Word2Vecの利点
以下は、Word2Vecを自然言語処理における基礎的なテクニックにしている主な利点です:
意味的関係を捉える**:Word2Vecは、意味的に類似した単語(例えば、"king "と "queen")がベクトル空間内で近接して配置される埋め込みを作成し、これらの関係を分析し、自然言語処理タスクで利用する。
文脈理解**:大規模なコーパスにおける単語の共起を分析することで、Word2Vecは文脈依存の関係を捉え、モデルが特定の文脈における単語の意味をより理解できるようにする。
効率的な表現**:単語埋め込みは、ワンホットエンコーディングのような疎な表現に比べ、高密度で低次元であるため、メモリや計算コストの点で効率的な手法である。
大規模な語彙に対応**:旧来の手法とは異なり、Word2Vecは大規模なデータセットや語彙に対して効果的にスケールするため、実世界のアプリケーションで実用的です。
転移学習をサポート**:事前に訓練されたWord2Vecの埋め込みは、複数のタスクで再利用することができ、結果を向上させながら、時間と計算リソースを節約することができます。
単語の演算**:Word2Vecは、「王 - 男 + 女 = 女王」のようなアナロジーを埋め込みを使用して直接計算するための意味のあるベクトル演算をサポートしています。
Word2Vecの使用例
Word2Vecは自然言語処理タスクに幅広く応用できます。以下はその実用的でインパクトのある使用例です:
機械翻訳機械翻訳**: 翻訳精度を向上させるために、意味の似ている単語を揃える埋め込みを使用することで、言語間の単語のマッピングを改善します。
感傷分析**:語句の関係や文脈を分析し、肯定的、否定的、中立的な感情を分類することで、テキストの語調を識別します。
検索ランキング検索クエリとインデックスされたコンテンツの類似性を理解することで、検索エンジンを強化し、より関連性の高い結果を導きます。
商品の推薦**:テキストの説明を分析し、類似のアイテムを見つけることによって、製品やサービスとユーザーの好みを一致させます。
トピック・モデリング単語の埋め込みの類似性に基づいて文書をクラスタにグループ化することにより、大規模なテキストデータセットを整理および分析する。
テキスト自動補完**:文脈的に類似した単語を予測することで、関連する単語やフレーズを提案し、タイピングやコーディングツールのユーザーエクスペリエンスを向上させます。
チャットボットチャットボットが正確で適切な応答を生成できるように、ユーザーの入力とコンテキストをよりよく理解できるようにします。
Word2Vecの制限事項
その利点にもかかわらず、Word2Vecには限界があります:
文脈認識の欠如**:Word2Vecは、文脈に関係なく、各単語に対して単一の埋め込みを生成します。例えば、"bank "という単語は、それが川岸を指していても、金融機関を指していても、同じベクトル表現を持つことになります。
データ依存性効果的な学習には、大規模で高品質なテキストデータセットが必要である。データセットが不十分であったり、少なかったりすると、最適な埋め込みができない可能性がある。
希少語の扱い:頻度の低い単語や語彙の少ない用語は、意味のある埋め込みを生成するのに十分な学習データが得られない可能性があります。
文レベルの表現がない:Word2Vecは単語レベルの埋め込みに重点を置いており、文全体や文書全体の埋め込みを提供しないため、特定のNLPタスクに適用範囲が限定される。
単語の順序を無視**:このモデルは文脈ウィンドウ内の単語を考慮しますが、文法や文構造の理解に影響する可能性のある単語の順序は考慮しません。
最新のモデルと比べて古い**:Word2Vecは主にBERT、GLoVE、GPTのような先進的なモデルに取って代わられ、文脈に沿ったよりロバストな埋め込みを提供しています。
ギャップを埋める:Word2VecからGloVe、BERT、GPTへ
Word2Vecのような予測モデルは、ニューラルネットワークを通して局所的な文脈に注目することで、単語の埋め込みを作成します。しかし、近傍の単語ペアに依存することには限界があります:つまり、テキスト・コーパス全体にわたる、より広範でグローバルな関係を捉えることができないのです。例えば、Word2Vecは近傍の単語の関連性を識別することには優れていますが、より広範な意味的なつながりを見逃すことがよくあります。
この問題に対処するために、GloVe (Global Vectors for Word Representation) はグローバルな共起統計を使って単語の埋め込みを行う。GloVeは、コーパス全体で単語が一緒に出現する頻度を分析し、局所的な文脈とより広範な意味的関係の両方を捉えて、より完全な言語表現を実現する。
最近では、BERT (Bidirectional Encoder Representations from Transformers)やGPT (Generative Pre-trained Transformer)のようなモデルが、静的な埋め込みを超えている。BERTは文脈埋め込みを導入し、文中の用法に基づいて単語を異なる形で表現し、GPTは連続的な文脈を理解することで首尾一貫したテキストを生成することに焦点を当てた。これらのモデルは、Word2VecやGloVeのような以前の手法の限界に対処し、動的で文脈を意識した表現を取り入れることで、NLPをさらに変革した。
Word2Vec with Milvus: NLPアプリケーションのための効率的なベクトル探索
Word2Vecは、意味検索、文書類似度、推薦システムなど、単語の関係を理解することが重要なタスクに不可欠な単語埋め込みを作成する方法を提供します。しかし、埋め込みの膨大なコレクションを効率的に管理し、検索することは困難です。
そこで、Zillizによって開発されたオープンソースのベクトルデータベースであるMilvusの登場です。Milvusは、Word2Vecの埋め込み、またはその他の埋め込みをシームレスに自然言語処理ワークフローに統合するための大規模な保存、索引付け、クエリのための堅牢なソリューションを提供します。Word2VecとMilvusの連携は以下の通りです:
1.**Word2Vecは語彙の高次元埋め込みデータを生成します。Milvusはこれらの埋め込みを以下の方法で効率的に処理します:
スケーラブルなストレージ:スケーラブルなストレージ: パフォーマンスを低下させることなく、何百万もの単語の埋め込みを保存します。
高速検索**:最適化されたアルゴリズムにより、レコメンデーションシステムやチャットボットなどのリアルタイムNLPアプリケーションに不可欠な、類似埋め込みデータの高速検索を実現します。
2.セマンティック検索の強化: Word2Vec埋め込みは、単語の関係性を捉えることに優れています。Milvusと組み合わせることで、これらの埋め込みは高度なセマンティック検索を可能にします。例えば
例えば、同義語や関連語を検索する(例えば、"king "を検索すると、"queen "や "prince "のようなエンベッディングが検索されます)。
Retrieval Augmented Generation (RAG)](https://zilliz.com/learn/Retrieval-Augmented-Generation)のような、より良い結果を得るために単語の類似性に依存するロバストな検索システムの実装。
3.合理化された NLP ワークフロー: Milvus は Word2Vec を含む NLP ワークフローを以下のように簡素化します:
事前に訓練されたWord2Vecの埋め込みを効率的に保存し、照会することができます。
クラスタリング、文書の類似性、リアルタイム検索のための機械学習フレームワークとの統合をサポートします。
結論
Word2Vecは、単語の意味と関係を捉える単語埋め込みを導入することで、言語データの扱い方を一変させた。意味的・構文的な類似性を捉えることができないなど、従来の手法の多くの課題を解決した。センチメント分析、翻訳、推薦システムなどのアプリケーションで使用されている。その限界にもかかわらず、Word2Vecはこの分野における多くの進歩の基礎を築き、GLoVE、BERT、GPTなどのより洗練されたモデルの開発に影響を与えた。
Word2Vecに関するFAQ
1.**Word2Vecとは何ですか?
Word2Vecは機械学習モデルであり、文脈に基づいて単語の埋め込みと呼ばれる密なベクトル表現を作成します。センチメント分析、翻訳、検索のようなNLPタスクのために、単語の関係と意味を捉えるので重要である。
2.**Word2Vecは従来の単語表現手法とどう違うのか?
ワン・ホット・エンコーディングのように、単語を疎なベクトルとして表現し、固有の関係性を持たない従来の手法とは異なり、Word2Vecは単語間の意味的・構文的な類似性を捉える密な埋め込みを作成するため、より効率的で意味のある表現が可能になります。
3.**Word2Vecで使われている主なアーキテクチャは?
Word2Vecには2つの主要なアーキテクチャがある:CBOW(Continuous Bag of Words)とSkip-Gramです。CBOWは周囲の文脈から目的語を決定し、Skip-Gramは与えられた目的語を用いて文脈の単語を特定する。それぞれユースケースやデータセットによって強みがあります。
4.**Word2Vecの主なユースケースは?
Word2Vecは、感情分析、機械翻訳、推薦システム、検索ランキング、トピックモデリング、チャットボット開発などのアプリケーションで使用されている。単語の関係を理解する能力により、様々なNLPタスクに汎用的に使用できる。
5.**Word2Vecの限界は?
Word2Vecには、文脈認識の欠如(例えば、同じ単語の異なる意味を区別しない)、訓練用の大規模データセットへの依存、単語の順序や文レベルの意味を捕捉できないなど、いくつかの限界がある。これらの欠点は、GloVe、BERT、GPTのような、より高度なモデルの開発につながった。
関連リソース
データサイエンティストが知っておくべきNLPテクニックトップ10](https://zilliz.com/learn/top-10-nlp-techniques-every-data-scientist-should-know)
トップ10の自然言語処理ツールとプラットフォーム](https://zilliz.com/learn/top-10-natural-language-processing-tools-and-platforms)
独自のテキスト埋め込みモデルのトレーニング](https://zilliz.com/learn/training-your-own-text-embedding-model)
自然言語処理のための20の人気のあるオープンデータセット](https://zilliz.com/learn/popular-datasets-for-natural-language-processing)
自然言語処理のパワーを解き明かす:トップ10の実世界アプリケーション](https://zilliz.com/learn/top-5-nlp-applications)
GloVe: 単語のつながりを解読する機械学習アルゴリズム](https://zilliz.com/glossary/glove)