




ベクトル・データベースはRAG検索のベースである
LLMの躍進にもかかわらず、なぜRAGは残るのか?
Retrieval Augmented Generation(RAG)テクノロジーを活用したチャットボットの導入は、カスタマーサポートの強化を目指す企業にとって画期的なことだ。このアプローチは、大規模言語モデルの会話能力と、法律相談、カスタマーサポートボット、教育支援、ヘルスケアなど、様々な分野からラグ・データベースに蓄積された知識を組み合わせたものである。
標準的なRetrieval Augmented Generationフレームワークは、RetrieverとGeneratorの2つのコアシステムで構成される。Retrieverは、データ(ドキュメントのような)をセグメント化し、データをベクトル埋め込みにエンコードし、インデックス(Chunks Vectors)を作成し、ベクトル埋め込みでセマンティック検索を行うことで、セマンティックに関連する結果を検索する。一方、ジェネレータは、検索プロセスから得られたコンテキストを利用して大規模言語モデル(LLM)を促し、的確な応答を生成する。
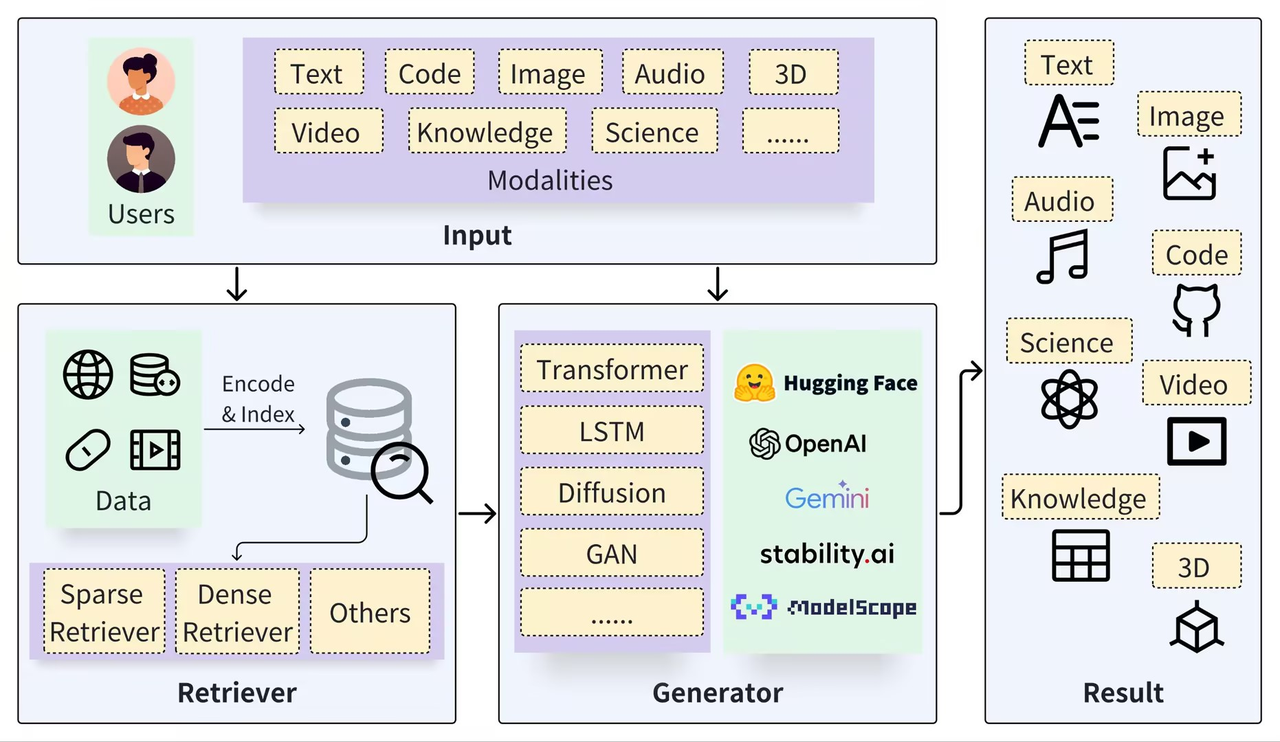
一般的なRAGアーキテクチャ。異なるモダリティにまたがるユーザークエリは、リトリーバとジェネレータの両方への入力となる。リトリーバはデータソースから関連情報を抽出する。ジェネレーターは検索結果と対話し、最終的にさまざまなモダリティの結果を生成する。出典https://arxiv.org/pdf/2402.19473_
検索拡張生成システムの有効性は、検索システムと生成モデルの相乗的な組み合わせに由来する。検索システムは、正確で関連性の高い情報、事実、データを提供し、一方、生成モデルは、柔軟で文脈に富んだ応答を作成する。この二重のアプローチにより、RAGは複雑な問い合わせを処理し、豊かで有益な回答を効率的に生成することができ、ニュアンスに富んだ自然言語処理、理解、生成を必要とするシステムにおいて非常に貴重なものとなっています。
Retrieval Augmented Generationテクノロジーは、以下のような従来の大規模言語モデルよりも優れています:
幻覚」問題の削減**:Retrieval Augmented Generationは、外部の関連データを活用して、LLMがより正確な回答を生成できるように支援し、出力の信頼性と追跡可能性を高めます。
データのプライバシーとセキュリティの強化**:RAGは外部知識ベース拡張機能として個人データを安全に管理することができ、モデル学習後の潜在的なデータ漏洩を防ぎます。
リアルタイム情報検索**:RAGは、最新のドメイン固有の関連情報をリアルタイムで取得することを容易にし、古い情報の課題に対処します。
現在進行中のLLMの進歩も、プライベートデータセットでの微調整や、より長いテキストウィンドウのトレーニングデータの提供などの戦略を通じて、これらの問題に対処していますが、RAGはそのため、より広範なGenAIアプリケーションにおいて、堅牢で信頼性が高く、費用対効果の高いソリューションであり続けています:
透明性と操作性**:ファインチューニングとロングテキスト管理の不透明なプロセスとは異なり、RAGはより明確で相互接続されたモジュール関係を提供し、チューナビリティと解釈可能性を向上させます。
コスト効率と迅速な対応:RAGは、ファインチューニングされたモデルよりもトレーニング時間が短く、コストも低く抑えることができます。また、応答速度と運用コストにおいて、ロングコンテクスト処理のLLMを凌駕します。
プライベート・データ管理**:知識ベースをLLMから分離することで、RAGは実用的な実装基盤を確保し、既存および新たに獲得した企業知識を効果的に管理します。
LLMが進化し進歩し続ける中で、多くの人がRAGは終焉の危機に瀕していると予測していますが、それでも私はRAGの技術は残ると信じています。RAGは本質的にLLMを補完するものであり、複数のアプリケーションにおいて長期的な妥当性と成功を保証するものである。
ベクターデータベースはRAG検索のベースである
実際のプロダクションアプリケーションでは、RAG検索はしばしばベクトルデータベースと緊密に統合され、ChatGPT、Vベクトルデータベース、Prompt-as-codeテクノロジーで構成されるCVPスタックとして知られる一般的な検索拡張生成ソリューションの開発につながりました。この革新的なソリューションは、ベクトルデータベースの効率的な類似性検索機能を活用し、LLMのパフォーマンスを向上させます。RAGシステムは、ユーザクエリをベクトル埋め込みに変換することにより、ベクトルデータベース内の関連知識エントリを迅速に検索することができます。このアプローチにより、LLMはユーザーからの問い合わせに応答する際に、データベースに保存されている最新の情報にアクセスすることができ、知識の更新の遅れや、しばしば "幻覚 "と呼ばれる、生成されたコンテンツの不正確さといった問題に効果的に対処することができる。
検索エンジン、リレーショナル・データベース、ドキュメント・データベースなど、一般的なベクトル・データベースやデータベース以外にも多くの検索技術が市場に出回っている。しかし、ベクトルデータベースは、膨大な量のベクトル埋め込みを効率的に格納・検索できる優れた機能を持つため、RAGの実装において最も好まれる選択肢である。機械学習モデルによって生成されるこれらのベクトルは、テキスト、画像、動画、音声を含む様々なデータタイプを表現し、同時に複雑な意味的詳細を捕捉する。
以下は、情報検索における他の技術オプションに対するベクトルDBの比較分析であり、ベクトルDBがRAGアプリケーションの構築において好ましい選択肢となった理由を強調している。
| カテゴリ|サーチエンジン|リレーショナルデータベース|ドキュメントデータベース|ベクターデータベース | ||||
| 主な製品|Elasticsearch|MySQL|MongoDB|Milvus|など | ||||
| 実装原理|高速なテキスト検索のために転置インデックスを利用し、ベクトル検索の機能は限定的|最適なトランザクション処理のために標準化されたデータモデルとSQLを採用し、非構造化データの扱いに苦戦|JSON形式でデータを格納し、柔軟なデータモデルと基本的な全文検索を提供するが、意味検索の機能は限定的|高次元ベクトルのために特別に設計され、効果的な意味的類似性検索のために近似最近傍(ANN)アルゴリズムを利用|高次元ベクトルのために特別に設計され、効果的な意味的類似性検索のために近似最近傍(ANN)アルゴリズムを利用。 | ||||
| 使用例|全文検索やわかりやすいデータ分析に最適|高い一貫性と複雑なトランザクション管理を必要とするアプリケーションに最適|迅速な開発とデータモデルが頻繁に変更される環境に最適|画像検索や意味的テキスト検索のような非構造化データに基づく検索に最適|大規模なベクトルデータセット検索に最適|大規模なベクトルデータセット検索に最適|大規模なベクトルデータセット検索に最適|大規模なベクトルデータセット検索に最適|大規模なベクトルデータセット検索に最適|大規模なベクトルデータセット検索に最適 | ||||
| 大規模ベクトルデータセット検索効率(高ければ高いほど良い)|中|低|高|低|高 | ||||
| マルチモーダル汎化能力(高ければ高いほど良い)|中|低|低|高 | ||||
| RAG検索への適合性(高ければ高いほど良い)|中|低|低|高|||。 | ||||
| 総コスト(低ければ低いほど良い) |
ベクトルデータベースを他の情報検索技術と比較する。
上表のように、ベクトル・データベースは以下の分野で有利である:
実装原理:ベクトルは意味的な意味を符号化し、ベクトルデータベースはディープラーニングモデルを用いてクエリの意味を解読し、単純なキーワード検索を超える。意味理解の精度はAIの進歩とともに向上し、ベクトル距離はNLPにおける意味類似性の標準的な尺度となり、埋め込みは多様なデータタイプを管理するための好ましいフォーマットとして位置づけられている。
検索効率:高次元ベクトルは、検索速度を大幅に向上させ、ストレージ需要を削減する高度なインデックス化と量子化技術を可能にします。ベクターDBは、膨大な関連データを持つ新しいデータを扱うRAGシステムに不可欠な迅速な応答時間を維持しながら、増大するデータ量を管理するために水平方向に拡張することができます。
汎化能力: 主にテキストを扱う従来のデータベースとは異なり、ベクトルDBは画像、ビデオ、オーディオを含む様々なタイプの非構造化データを保存・処理します。この汎用性は、RAGシステムの柔軟性と機能性を高めます。
総所有コスト: ベクターDBは、簡単なセットアップと包括的なAPIにより、既存の機械学習フレームワークへの導入や統合が容易です。このアクセシビリティは、全体的なコストの低さと相まって、RAGアプリケーションの開発者に好まれています。
より高性能なRAGアプリケーションのためのベクターデータベースの強化
ベクターデータベースはRAGシステムにおける基本的な検索技術である。しかし、開発者がますます複雑なRAGアプリケーションを構築し、実運用環境で使用するにつれて、ユーザクエリに対するより高品質でより正確な回答に対する要求は高まり、ベクトルデータベースに対する課題となっている。
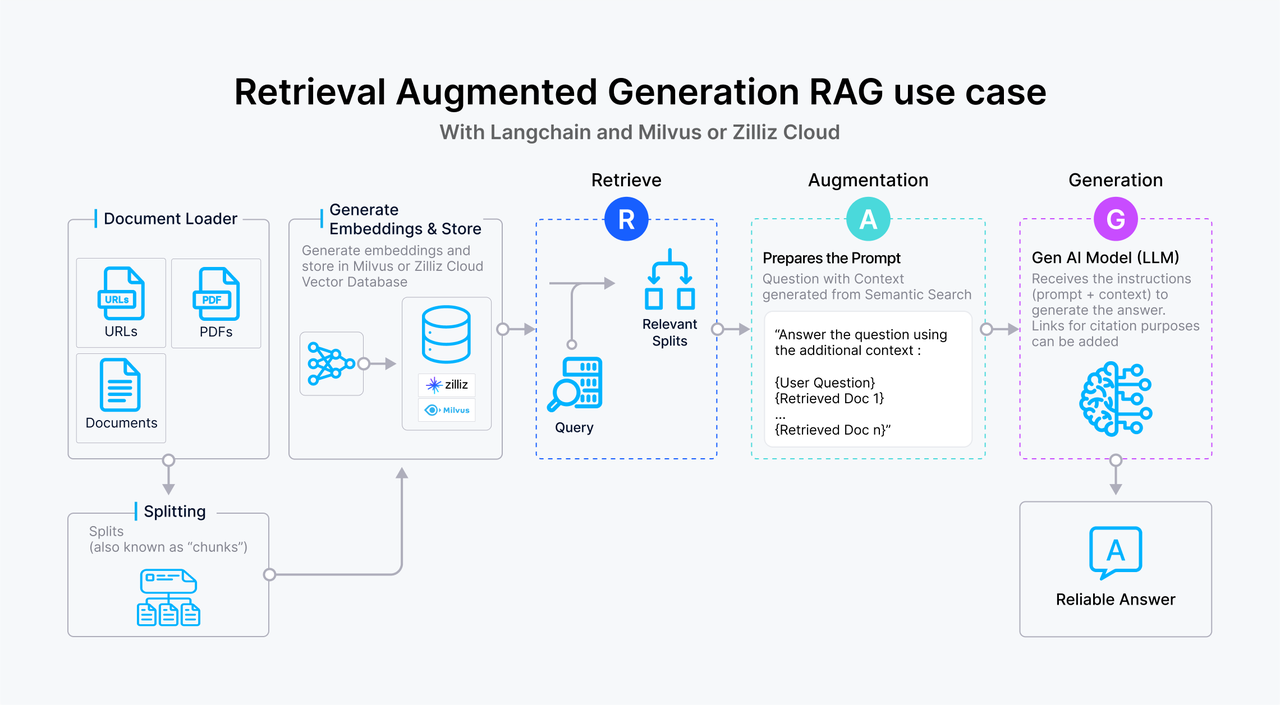 RAGユースケース.png
RAGユースケース.png
セグメンテーション、データクリーニング、エンベッディングによるデータの前処理、インデックスの構築と管理、プロンプト生成を改善するために類似セグメントを見つけるためのベクトル検索。ほとんどのベクトルDBは、インデックスの構築と管理、およびベクトルデータの検索を扱うが、Milvusのように、組み込みの埋め込み機能を提供するものはごく少数である。したがって、ベクトルデータ検索の質は、LLMが生成するコンテンツの関連性と有効性に直接影響する。
適切なチャンクサイズの選択、重複セグメントの必要性の判断、適切な埋め込みモデルの選択、コンテンツタグの追加、hybridセマンティック検索アプローチのための語彙ベースの検索の統合、リランカーの選択など、ベクトルDBの検索品質を向上させるために数多くの工学的最適化が出現する。これらのタスクの多くをベクトルデータベース内に統合することができる。
具体的には、ベクトル・データベースは以下の分野を改善すべきである:
検索における高精度**:ベクトルデータベースは、ベクトル類似度検索を通じて、ユーザーのクエリに基づいて最も関連性の高い文書やデータスニペットを正確に検索することに優れていなければならない。これには、高次元ベクトル空間内の複雑な意味的関係を処理・解釈し、検索されたコンテンツがユーザーのクエリと正確に一致するようにする必要がある。
迅速な応答最適なユーザー・エクスペリエンスを保証するために、ベクトルDBはミリ秒以内の検索を提供する必要があります。そのためには、膨大なデータセットから迅速にアクセスし、情報を抽出する能力が求められます。データ量が増加し、クエリが複雑化するにつれて、これらのデータベースは、信頼性の高いリコール・パフォーマンスを一貫して維持しながら、より大きなデータセットやより高度なクエリを処理し、柔軟に拡張する必要があります。
マルチモーダルなデータ処理:ベクトル・データベースは、テキスト・データだけでなく、画像、ビデオ、その他のマルチモーダルなデータも扱わなければならない。そのためには、多様なデータタイプの埋め込みをサポートし、多様なモーダルクエリに基づいて効率的に情報を検索する能力が必要です。
- 解釈可能性とデバッグ可能性**:また、ベクトルデータベースには、結果が効果的に検索されない場合の問題に対処するための、堅牢な診断ツールや最適化ツールを提供することが不可欠です。
まとめ
RAG(Retrieval Augmented Generation:検索拡張世代)アプリケーションの需要が高まり続ける中、開発者は様々な目的でRAGテクノロジーを活用するようになってきている。このような採用の拡大は、情報検索と知識取得の効率と事実上の精度を劇的に向上させ、最終的に組織がデータにアクセスして使用する方法を再構築することによって、多くの業界を変える態勢を整えている。
ベクトルDBは、まだ比較的十分に活用されていないものの、RAGシステムの基盤インフラとして計り知れない可能性を秘めている。その中でも、Milvusベクトルデータベースは、RAGアプリケーションの開発と強化に関連する課題に積極的に取り組み、克服しており、際立っている。Milvusは、Generative AI開発者からの洞察を活用することで、人工知能業界のニーズによりよく応えるべく、その機能を継続的に改良している。
次回の投稿では、オープンソースのMilvusベクターデータベースに潜入し、その最新機能を紹介し、エンタープライズ対応のRAGアプリケーションの構築に理想的な選択肢である理由を説明します。さらなる洞察にご期待ください。

読み続けて

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.