




RAGベースのソリューションの総コストの計算方法
Retrieval-Augmented Generation (RAG)は、顧客サービス、コンテンツ作成、研究などの業界におけるAIアプリケーションを変革している。2023年、世界のRAG市場は10億4,270万ドルと評価され、2030年まで年平均成長率(CAGR)44.7%で成長すると予想されている。この成長は、正確で文脈を認識した応答を提供するAIシステムに対する需要の高まりを反映している。しかし、RAGベースのソリューションの採用を検討する際には、効果的な計画を立て、投資を最大限に活用するために必要なコストを理解することが重要です。
RAGの核心は、外部ソースから関連情報を取得し、生成的AIを使用して特定のクエリに合わせた応答を作成するという2つのプロセスを組み合わせることです。例えば、AIを搭載したカスタマー・サポート・システムは、データベースから最新の製品情報を取得し、顧客の質問に直接対応する回答を生成することができます。これにより、システムは信頼できるデータに基づいた結果を確実に提供し、複雑で特殊なタスクに適している。しかし、RAGシステムの構築、運用、拡張にはコストがかかり、これらのコストを明確に理解しなければ、必要なリソースを使いすぎたり、過小評価したりする危険性があります。徹底的なコスト分析は、予算を計画し、システムを効果的に拡張し、より良い投資収益率(ROI)を達成するのに役立ちます。
このガイドでは、RAGコストの主な構成要素を分解し、 Zilliz RAG Cost Calculator を使用してこれらの費用を計算する方法を紹介し、支出を効率的に管理するための戦略を探ります。
RAGコストの構成要素を分解する
RAGベースのソリューションの総コストを計算するには、全体的な費用に貢献する個々のコンポーネントを理解することが重要です。RAG パイプラインの各段階は、データの処理から回答の生成まで、コストを決定する役割を果たします。これらのコンポーネントを詳しく見てみましょう:
埋め込みコスト: 埋め込みでは、ドキュメントをセマンティック検索に不可欠な数値ベクトルに加工します。このステップでは、コンテンツを管理しやすい小さな塊に分割し、高次元の数値表現に変換する必要があります。コストは、データセットのサイズ、チャンクサイズ、そして選択する埋め込みモデルに依存する。例えば、OpenAIのtext-embedding-ada-002のような高性能なモデルを使用すると、より良い結果が得られるかもしれませんが、複雑なためコストが増加します。
データの保存と検索のコスト:一度データが埋め込まれると、クエリ中に検索するためにベクトルデータベースに保存されなければなりません。保存コストは、保存されるベクトルの数とその次元数に影響されます。検索コストはクエリの頻度と複雑さによって決まり、効率的な処理には計算リソースが必要です。クエリ量が多いアプリケーションでは、規模が大きくなるにつれてこれらのコストが急上昇します。
LLM推論コスト: 大規模言語モデル(LLM)を使用してレスポンスを生成することは、総コストに大きく貢献します。OpenAI GPTのような事前に訓練されたAPIに依存する場合、各クエリ中に処理されたトークンの数に基づいて支払います。あるいは、LLMを社内でホスティングする場合、GPUやTPUを含むハードウェアやメンテナンスの費用、モデルの微調整やアップデートの費用が発生します。
インフラコスト: RAGシステムは、埋め込み、ストレージ、検索、推論プロセスをサポートするスケーラブルなインフラを必要とする。これらのタスクを効率的に処理するためには、クラウドサーバーなどの計算リソースが必要である。また、データがパイプラインの異なるコンポーネント間を移動する際には、ネットワーク転送料が発生する。リアルタイムまたは大規模なアプリケーションでは、応答性と信頼性を確保するために追加のインフラが必要となり、さらにコストを押し上げる。
これらのコスト・コンポーネントを理解することは、RAGベースのソリューションの現実的な見積もりを作成するための基礎となります。この知識は、RAG Cost Calculatorがどのように機能し、これらの費用を計算するプロセスを簡素化するかを理解するのに役立ちます。
##RAGコスト計算機:数秒でコストを計算する無料ツール
RAGシステムのコストを見積もるための実用的なツール、ZillizRAGコスト計算機を試してみましょう。この計算ツールは、2つの異なる見積もり方法を提供し、それぞれが計画プロセスの異なる段階用に設計されています。それぞれの方法がどのように機能し、潜在的なコストを理解するのに役立つかを説明しましょう。
ドキュメントベースの見積もり方法
**入力方法の選択
ドキュメント・ベースの方法は、実際のコンテンツを調査することで、最も詳細なコスト分析を提供します。その使い方を順を追って説明する:
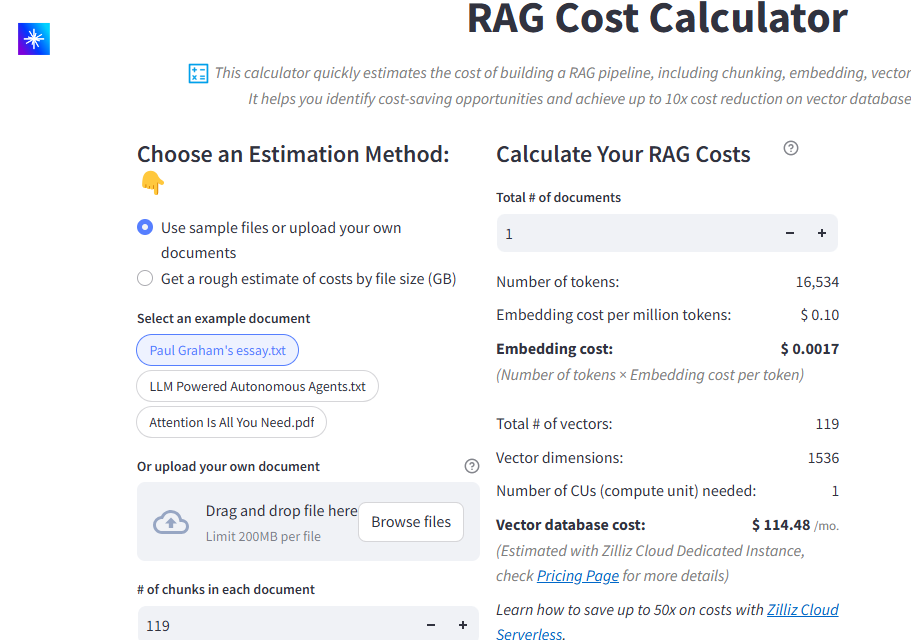
図:文書ベース推定法のユーザー・インターフェース
まず、コンテンツを提供する必要があります。あなた自身の文書(それぞれ200MBまで)をアップロードするか、Paul Graham's essay.txtのような提供されたサンプルを使用して、計算機がどのように機能するかを調べることができます。
**チャンキングサイズの指定
次に、各文書をいくつのチャンクに分割するかを指定します。チャンキングは、埋め込みコストとベクターデータベースの効率の両方に影響するため、これは非常に重要です。理想的なチャンクサイズは、特定のニーズによって異なります。チャンクが小さいと、より正確な検索結果が得られますが、保存するベクターと検索するベクターが増えるため、コストが増加します。チャンクが大きいと、コストは下がりますが、特定の情報を見つけるのが難しくなります。
**埋め込みモデルの選択
チャンキングの好みを設定したら、埋め込みモデルを選択します。
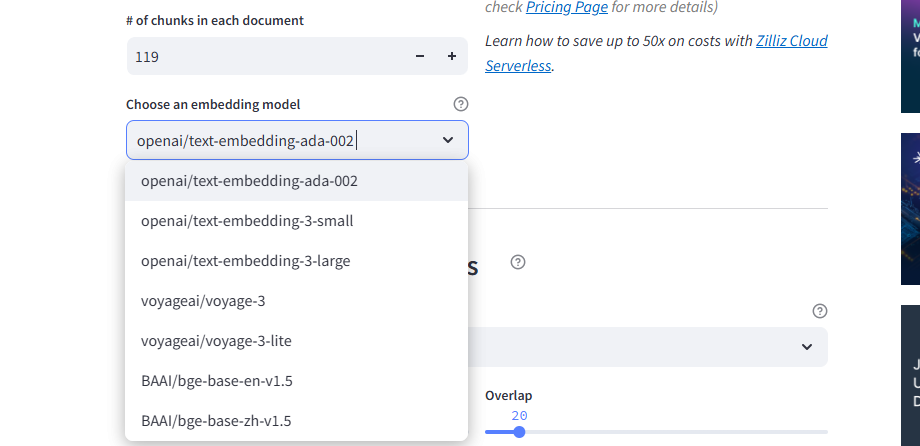
図:Zilliz RAGコスト計算機が提供するモデル選択オプション_。
この計算機は、OpenAIのtext-embedding-ada-002や、Voyage AIやBAAIのようなプロバイダーの代替品を含む、様々なオプションをサポートしている。各モデルは、コストとパフォーマンスのトレードオフを提供しています。次に、処理する予定のドキュメントの総数を指定します。これは、計算機がプロジェクト規模に合わせて適切に見積もりをスケーリングするのに役立ちます。最初の画像で、ドキュメントの総数フィールドを見ることができます。
コストの内訳を計算する*。
あなたの設定を構成したら、電卓はあなたの入力を処理し、コストの包括的な内訳を提示します。計算機は、最初にあなたの埋め込みコストを分析します。それはあなたの文書内のすべてのトークンをカウントし、私たちの例では16,534トークンです。現在の埋め込みコストは100万トークンあたり0.10ドルなので、トークン数×トークンあたりの埋め込みコストを計算します:16,534/1,000,000 × $0.10 = $0.0017.これが、これらの文書を処理するための1回限りの埋め込みコストです。
ベクターデータベースのコストについては、トークンから作成されたベクターの数を計算します。この例では、16,534個のトークンが119個のベクトルに分割され、それぞれが1,536次元(ada-002の標準)になっています。この量と次元数に基づいて、計算機はこれらのベクトルを効率的に処理するために1つの計算ユニットが必要であると自動的に判断します。Zilliz Cloudの専用インスタンス価格では、このコンピュート・ユニットのコストは月額114.48ドルです。
1回限りのエンベッディングコストと毎月のベクターデータベースコストを分離することで、初期設定費用とRAGシステムに必要な定期的コストの両方を理解することができます。
Fine-Tuning Your Chunks
ドキュメントベース方式の強力な特徴の一つは、ドキュメントの分割方法をプレビューして調整できることです。3つの分割方法からお選びいただけます:
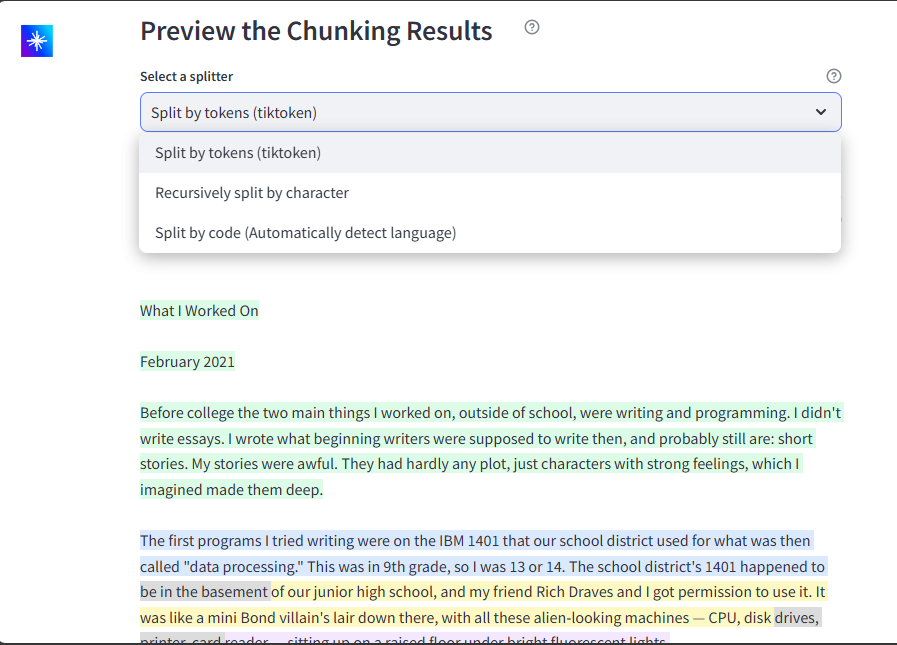
イメージ:Zilliz RAGコスト計算機でサポートされているチャンキングオプション_。
トークンによる分割(tiktoken)は、言語モデルのトークンに基づいてテキストを分割します。文字による再帰的分割は、自然な境界でテキストを分割します。コードによる分割はプログラミング言語の構造を保持します。チャンクサイズとオーバーラップの両方を調整して、文脈の保持とコストの最適なバランスを見つけることができます。
ファイルサイズに基づく推定方法
大規模なデータセットを扱う場合、または計画初期の段階であれば、ファイル・サイズ・ベースの方法がよりシンプルなアプローチを提供します。手順は簡単で、まず総データサイズをギガバイト単位で入力し、次にご希望のエンベッディング・モデルを選択します。
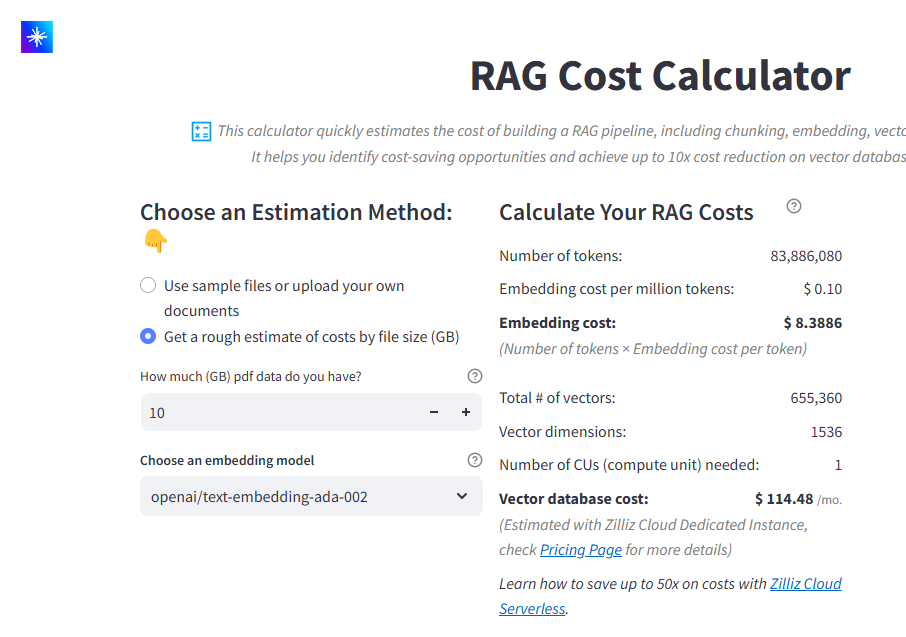
図:GBベースの推定インターフェース
計算機は次に、PDF文書内の典型的なトークン密度に基づいてコストを見積もります。例えば、10GBのPDFデータを処理する場合、計算機は83,886,080トークンを生成すると見積もり、その結果、埋め込みコストは8.3886ドルになります。生成された655,360個のベクターには1つの計算ユニットが必要で、ベクターデータベースの保管と処理にかかるコストは月々114.48ドルになります。
RAGコスト計算機の利点と限界
Zilliz RAG Cost Calculatorは、RAGパイプラインの構築と運用にかかる費用の見積もりプロセスを簡素化します。コスト計画のための貴重な洞察と柔軟性を提供する一方で、考慮すべき重要な制約もあります。その主な利点と制約を探ってみましょう。
RAGコスト計算機の利点
明確なコスト内訳**:この計算機では、1回限りの埋め込み費用と、繰り返し発生するベクターデータベースの費用を区別しているため、ユーザーは初期費用と継続費用の両方を計画することができます。
カスタマイズ可能なパラメータ**:ユーザーは、チャンクサイズ、オーバーラップ、エンベッディングモデルなどの設定を調整し、特定の要件に合わせて見積もりを行うことができます。
シナリオ・シミュレーション**:このツールでは、データセットサイズやドキュメント数などの変数によってコストがどのように変化するかを調べることができ、予測や規模拡大の意思決定に役立ちます。
ユーザーフレンドリーなデザインサンプルファイルと直感的なインターフェイスにより、豊富な経験がなくても簡単にコストを見積もることができます。
複数の埋め込みモデルのサポート:OpenAI、Voyage AI、BAAIなどのプロバイダーが提供するエンベデッドモデルとの互換性により、オプション間でコストとパフォーマンスを比較することができます。
RAGコスト計算機の制限事項
テキストベースのデータ**へのフォーカス:この計算機は、主にテキストデータセットをサポートし、画像やマルチメディアなどの他のデータタイプへの使用を制限しています。
計算単位の柔軟性**:電卓は、必要な計算ユニット(CU)数を推定しますが、特定の性能要件のためにCUタイプをカスタマイズすることはできません。
限定された範囲**:このツールは、エンベッディングとベクトル・データベースのコストに重点を置いており、インフラ、LLM推論、システム・メンテナンスなどのその他の費用は含まれていません。
RAGパイプラインの主なコスト要因
RAG Cost Calculatorがどのように機能するかを検討した後、これらのコストを生み出す要因を詳しく見ていくことが重要である。この計算機は見積りを提供しますが、システムの各部分がなぜ総費用に貢献するのかを理解することで、最適化について十分な情報に基づいた決定を下すことができます。ここでは、RAGパイプラインの主なコスト要因と、予算とスケーラビリティへの影響について見ていきましょう。
クラウド・インフラストラクチャ
クラウドリソースはRAGパイプラインの中核であり、すべてのオペレーションをサポートするバックボーンとして機能します。コンピュートリソースは、エンベッディングエンジン、ベクトルデータベース、クエリ処理モジュールなどの主要コンポーネントを実行するために不可欠です。これらのリソースは、パイプラインの規模や実行されるタスクの複雑さによって異なります。例えば、リアルタイムのカスタマーサポートシステムでは、安定したパフォーマンスを実現するために専用のインスタンスが必要になるかもしれませんし、小規模なアプリケーションでは、コストを削減するためにサーバーレスオプションに頼ることができるかもしれません。
クラウド・インフラストラクチャでは、ストレージも重要な検討事項だ。大規模なデータセットを埋め込んだり、追加のベクトルに対応するためにスケーリングしたりすると、ストレージ要件が大幅に増加する。クラウド・プロバイダーは、選択したストレージ容量とパフォーマンス・ティアに基づき課金し、高速ストレージ・オプションの方が高くつくことが多い。さらに、埋め込みデータをベクターデータベースに保存したり、ベクターデータベースから取得したりする場合など、データがシステム間を移動するたびにネットワーク転送料が発生します。データフローを最適化し、不要な転送を最小限に抑えることで、これらの料金を削減することができます。
モデルの使用法
エンベッディングと大規模言語モデル(LLM)の選択は、コストを決定する上で中心的な役割を果たします。OpenAIのGPTモデルのようなAPIを使用すると、トークンごとの料金が発生します。この料金は、返されるトークンの数と同様に、クエリの長さと複雑さに基づいて増加します。例えば、長いレスポンスや詳細なコンテキストを必要とするリクエストは、より高いコストが発生します。開発者は、クエリを短くしたり、よく使われる結果をキャッシュすることで、利用を最適化できます。
セルフホスティング・モデルは、API利用の代替手段を提示する。この場合、トークンごとの料金は不要になるが、GPUやTPUなどの基礎となるハードウェアや、システムのメンテナンスに関連する費用が発生する。特定のタスクのためにモデルを微調整することもコスト増につながりますが、モデルをドメインに合わせて調整することで、長期的にはパフォーマンスを向上させ、非効率を減らすことができます。
データ量とスケーリング
データセットのサイズが大きくなると、データの保存と処理に関連するコストも大きくなります。パイプラインの各ドキュメントはベクターを生成し、ベクターの総数はドキュメントの数、選択したチャンキング設定、オーバーラップによって増加します。ベクターが増えると、ベクターデータベースの保存領域が増え、保存コストが高くなります。
トラフィックの増加に対応するためのシステムのスケーリングは、さらに複雑なレイヤーを追加します。クエリ量が多いシステムでは、検索操作を効率的に管理するために追加の計算リソースが必要になります。データセットのサイズとシステム性能のバランスをとることで、スケーラビリティを維持しながらコストを抑えることができます。クエリーのバッチ処理や、処理前の結果のフィルタリングなどのテクニックは、データ量の増加による影響を軽減するのに役立ちます。
レイテンシー要件
リアルタイムのレコメンデーションやカスタマーサポートシステムなど、低レイテンシーが要求されるアプリケーションでは、運用コストが高くなることがよくあります。低レイテンシを実現するには、通常、クエリを迅速に処理するために、パフォーマンスに最適化されたコンピュートユニットや高スループットシステムが必要になります。例えば、10ミリ秒以下で結果を取得するためには、特別な設定やインフラが必要となり、追加費用が発生する場合があります。
レイテンシーとコストのトレードオフは、アプリケーションのニーズに基づいて慎重に検討する必要があります。オフライン分析ではレイテンシーの高いソリューションも許容できるかもしれませんが、リアルタイムシステムでは速度を優先する必要があるため、ハードウェアとソフトウェアの両方を最適化して応答性を高めることが重要になります。
運用コスト
RAGパイプラインの運用と保守には、初期設定以外にも継続的な運用コストがかかります。システムメンテナンスは、ベクターデータベースやエンベッディングシステムなどのコンポーネントが更新され、効率的に機能することを保証します。これには、ソフトウェアのパッチ適用、ハードウェアのアップグレード、潜在的な問題を検出するためのパフォーマンスメトリクスの監視などのタスクが含まれます。
モニタリング・ツールは、システムのパフォーマンスを追跡するために不可欠です。これらのツールは、ボトルネックを特定し、アップタイムを確保し、リソースが十分に活用されていないか、または過剰な負荷がかかっている場所についての洞察を提供するのに役立ちます。例えば、クエリーパターンを分析することで、検索プロセスを最適化したり、冗長なオペレーションを削減したりする機会を明らかにすることができます。スケーリング管理は、運用コストのもう一つの重要な側面です。トラフィックが変動する中、リソースを過剰にプロビジョニングすることなく需要を満たすためにインフラを調整するには、慎重な計画が必要です。クラウド・プロバイダーが提供するような自動スケーリング・ソリューションは、このプロセスを簡素化できるが、それなりのコストがかかる。
コスト最適化の戦略
RAGパイプラインのコストを押し上げる主な要因を見てきたところで、これらの費用をどのように最適化できるかを考えてみよう。コスト削減戦略は、パイプラインの特定の側面をターゲットとし、過剰な支出をすることなく効率性と拡張性を維持できるようにする必要がある。
ストレージの最適化
効率的なストレージ管理は、コスト削減の重要なステップです。効果的な方法の1つにベクトル量子化があり、これはほとんどのユースケースで十分な精度を保ちながら、ベクトルサイズを縮小して圧縮します。これは特に高次元ベクトルを扱う場合に有効で、ストレージ要件を大幅に削減します。
もう一つの方法は、ベクトルの次元を分析し最適化することです。例えば、1,536次元のベクトルは高い精度を提供するかもしれませんが、多くのアプリケーションは768次元で同等の結果を得ることができ、ストレージ要件を半分に減らすことができます。さらに、階層型ストレージ ソリューションを実装し、アクセス頻度の低いベク ターを安価で低速なストレージ階層に格納し、高速で高価なストレージを優先順位の高いデータ に使用することもできます。
最後に、冗長な埋め込みや古くなった埋め込みは定期的に削除してください。時間が経つにつれて、もはや関連性のない埋め込みデータは蓄積され、不必要にストレージコストを膨れ上がらせます。
推論コストの削減
エンベッディングとLLMの推論コストはすぐに膨れ上がりますが、いくつかの戦略によって最小化することができます。よく使われる埋め込みや出力をキャッシュすることから始めましょう。例えば、特定のクエリやデータポイントが繰り返しアクセスされる場合、それらの埋め込みは毎回再計算するのではなく、保存して再利用することができ、計算資源と金銭的資源の両方を節約することができます。
ユースケースに適したモデルを選択することも、コスト最適化において重要な役割を果たします。OpenAIのtext-embedding-ada-002のような大きなモデルは強力ですが、それほど複雑でないタスクでは、より小さくコスト効率の良いモデルで十分かもしれません。パフォーマンス目標を達成するために必要な最小限の複雑さを特定するために、モデルを試してみてください。さらに、データを1つ1つ処理するのではなく、埋め込みをバッチ処理することで、計算リソースをより有効に利用できるため、効率向上に役立ちます。
効率的なクエリー
システムがクエリを処理する方法を最適化することで、検索コストを大幅に下げることができます。可能であれば、クエリーのバッチ処理から始めてください。複数のクエリをまとめて処理することで、各クエリを個別に処理する際の計算オーバーヘッドを削減し、運用のコスト効率を高めることができます。
検索パターンを絞り込むこともコスト削減の強力な方法です。データセット全体を検索するのではなく、データの特定のサブセットやコレクションに検索範囲を絞り込む。例えば、カスタマー・サポート・システムを運用している場合、データベース全体ではなく、FAQや最近のクエリのコレクションから結果を取得することで、効率を向上させ、コンピュート使用量を削減することができます。また、クエリ最適化テクニック を実装することで、近接しきい値のような検索パラメータを調整するなど、検索中に取得されるベクトルの数を減らすこともできます。
正しいインフラ
RAG パイプラインに最も適切なインフラを選択することは、最も影響力のあるコスト削減戦略の 1 つです。トラフィックパターンが変化するアプリケーションの場合、オートスケーリングソリューションは需要に基づいてリソースを動的に調整し、使用した分だけの支払いを保証します。例えば、トラフィックが少ない期間には、リソースを自動的にスケールダウンし、アイドルコストを削減します。
アプリケーションに安定したトラフィックがある場合は、専用インスタンスの方が長期的に費用対効果が高い場合があります。Zilliz Cloudのようなマネージド・サービスは、ベクターの保存と検索に最適化された構成を提供します。これらのサービスは、スケーリングとメンテナンスの複雑さを処理し、オーバーヘッドコストを削減しながら、アプリケーションのパフォーマンスに集中することができます。Zilliz Cloudは、ベクトル操作のためのカスタマイズされた最適化により、RAGコストを最大**50倍削減できる可能性があります。
ハイブリッド・アプローチ
ハイブリッド検索ストラテジーは、費用対効果の高い手法と目標とする精度を組み合わせたものです。例えば、キーワードマッチングやBM25のような軽量な検索メカニズムを使用して、大規模なデータセットを絞り込むことができます。関連する結果のサブセットが特定されたら、よりリソース集約的なRAGパイプラインを適用して、結果をさらに絞り込む。このアプローチは、埋め込みと検索操作を必要とする文書数を減らし、計算コストを大幅に削減する。
さらに、ハイブリッド・ストレージ・システムは、効率的なコスト管理に役立つ。例えば、頻繁にアクセスされるデータは高性能システムに保存し、重要度の低いデータは低コストのストレージ・ソリューションに保存することができる。このバランスにより、重要度の低いオペレーションに過剰なプロビジョニングを行うことなく、重要度の高いクエリに必要なリソースを確保することができる。
結論
RAGパイプラインを最適化することは、コスト要因を理解することと同様に、コスト要因を削減するための実行可能な方法を見つけることでもあります。リソース管理に戦略的なアプローチを取り、RAG Cost Calculatorのようなツールを活用することで、効率性、拡張性、パフォーマンスのバランスが取れたシステムを構築することができる。ストレージ方法からクエリ処理まで、あらゆる選択がシステムの持続可能性と有効性を形作ります。適切な調整を行うことで、RAGパイプラインは予算や長期的な目標に沿いながら、インパクトのある結果を提供することができます。
読み続けて

Introducing Zilliz CLI and Agent Skills for Zilliz Cloud
Manage your vector database from your terminal or AI coding agent. Zilliz CLI and Agent Skills work with Claude Code, Cursor, Codex, and Copilot.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.