




LangGraphとLlama 3.2によるローカル・エージェント型RAG
2024年9月25日、ラマ3.2にアップデート。
この投稿では、LangGraphとLlama 3を使って、特定のタスクを実行するためにインテリジェントにツールを呼び出すことができるエージェントを構築する方法を示します。また、効率的なデータストレージのためにMilvus Liteも活用します。これらのエージェントは、計画、記憶、ツール呼び出しを含むいくつかの重要な機能を統合し、検索拡張世代(RAG)システムの性能を向上させる。
LangGraphとLlama 3**の紹介。
LangGraphはLangChainを拡張したもので、large language models (LLMs)を使ってロバストでステートフルなマルチアクター・アプリケーションを構築するように設計されている。LangChainは、LLMを様々なワークフローに統合するためのフレームワークを提供しますが、LangGraphは、タスクをグラフ構造のノードとエッジとしてモデル化することで、これを進化させます。これにより、より複雑な制御フローが可能になり、LLMが計画を立て、学習し、目の前のタスクに適応できるようになります。LangGraphは、エージェントが多段階の推論を行い、各段階に適したツールを動的に選択するシステムを実装する柔軟性を提供します。さらに、LangGraphは、ユーザが定義した制御フローに毎回従う信頼性の高いRAGエージェントを構築し、その応答の一貫性と予測可能性を保証します。
LangGraphはまた、ワークフローにサイクルを組み込むことで、より複雑なエージェントのような動作を可能にします。このサイクルにより、エージェントは必要に応じて前のステップに戻ることができ、新しい情報や反省に基づいた行動をダイナミックに調整することができる。この結果、時間の経過とともに推論を洗練させることができる、よりインテリジェントなエージェントが誕生し、より堅牢で適応性の高いRAGシステムが構築される。
オープンソースの大規模言語モデルであるLlama 3は、エージェントメモリのコア推論エンジンとして機能します。LangGraphと組み合わせることで、Llama 3は入力を分析し、取るべき行動を決定し、必要なツールを呼び出すことができます。LangGraphを搭載したLlama 3は、単にテキストを生成するだけでなく、エージェントが行動を計画し、実行し、振り返ることを可能にし、エージェントをより知的で有能なものにします。
この投稿では、Llama 3とMilvus Liteを使って、LangGraph agentic ragシステムを作る方法を紹介します。このセットアップにより、外部サーバを必要とせず、全てをローカルで実行することができ、プライバシーを重視するユーザやオフライン環境に最適です。
LangGraphを使ったツール呼び出しエージェントの構築*
LangGraphのワークフローはノードの概念に基づいて構築されており、各ノードは特定のタスクやツールを表します。これらのタスクには、LLMの呼び出し、情報の取得、カスタムツールの呼び出しなどがあります。ツール呼び出しエージェントでは、2つの重要なコンポーネントが使用されます:
1.1.LLMノード:このノードは、ユーザーの入力に基づいて、どのツールを使うかを決定する。クエリを分析し、ツール名と関連する引数を出力する。
2.**LLM ノードからツール名と引数を受け取り、適切なツールを起動し、結果を LLM に返す。
ウェブ検索のような)タスクをノードとエッジとして構造化することで、LangGraphはインテリジェントなマルチステップワークフローの作成を可能にし、LLMはユーザの質問に対して、どのアクションを取るべきか、どのツールを使うべきか、どの回答が適切か、どのように回答を洗練させるかを推論することができます。Milvus Liteは、ベクトル化されたデータの効率的な保存と検索をローカルに提供することで、ここで重要な役割を果たしています。
ローカルなツール呼び出しエージェントをMilvus Liteがどのように強化するか**。
Milvus Liteは、DockerやKubernetesを必要としない軽量なローカル版Milvusです。そのため、ラップトップやJupyterノートブック、あるいはGoogle Colabでも簡単にMilvusを実行することができます。Milvus Liteをローカルにデプロイすることで、外部のデータベースに依存することなく、様々なウェブソースやドキュメントから生成されたベクトルを保存することができます。LangGraphとシームレスに統合され、ベクトル検索を扱うことができるため、ローカルのRAGシステムにとって理想的なソリューションです。
例えば、Milvus Liteは、エージェントがウェブ検索中に取得したインデックス付きドキュメントを格納するために使用することができます。エージェントが情報を検索する際、ベクトルデータベースは関連文書を高速かつ正確に検索することができます。
LangGraphとLlama 3によるローカルRAGシステムの構築
LangGraphを使って、異なるアプローチを用いたカスタムローカルLlama 3.2搭載RAGエージェントを構築します:
各アプローチをLangGraphの制御フローとして実装する:
ルーティング(Adaptive RAG)** - エージェントがユーザのクエリを、質問に基づいて最も適した検索方法にインテリジェントにルーティングすることを可能にします。 LLMノードはクエリを分析し、キーワードや質問構造に基づいて、特定の検索ノードにクエリをルーティングすることができる。
例1:事実に基づいた回答を必要とする質問は、事前にインデックス付けされた知識ベース(Milvusによって提供される)を検索する文書検索ノードにルーティングされるかもしれない。
例2:オープンエンドで創造的なプロンプトは、生成タスクのためにLLMに指示されるかもしれない。
フォールバック(修正RAG)** - 最初の検索方法が関連する結果を提供できなかった場合、エージェントにバックアッププランがあることを保証する。 最初の検索ノード(例えば、知識ベースからの文書検索)が(関連性スコアや信頼度のしきい値に基づいて)満足のいく回答を返さなかったとする。その場合、エージェントはウェブ検索ノードにフォールバックする。
- ウェブ検索ノードは外部の検索APIを利用することができる。
自己修正(Self-RAG)** - エージェントが自身のエラーや誤解を招く出力を特定し、修正することを可能にする。 LLMノードは答えを生成し、評価のために別のノードにルーティングされる。この評価ノードは様々な技術を使うことができる:
Reflection:Reflection_:エージェントは、その答えがすべての側面に対処しているかどうかを確認するために、元のクエリと照らし合わせることができる。
信頼度スコア分析LLMは回答に信頼スコアを割り当てることができます。スコアがある閾値を下回る場合、その回答は修正のためにLLMに送り返されます。
エージェントの一般的なアイデア
リフレクション-*** 自己修正機構はリフレクションの一形態で、LangGraphエージェントがその検索と生成を振り返ります。評価のために情報をループバックし、エージェントが初歩的なリフレクションを行うことで、時間の経過とともに出力品質を向上させます。
エージェントは単にクエリに反応するだけでなく、最適な答えを検索・生成するためのステップ・バイ・ステップのプロセスを作成します。
ツールの使用-** LangGraphエージェントのコントロールフローは、様々なツールのための特定のノードを組み込んでいます。これには知識ベース(例えばMilvus)の検索ノードや外部情報のウェブ検索ノードが含まれ、膨大な情報プールを利用する能力を発揮します。
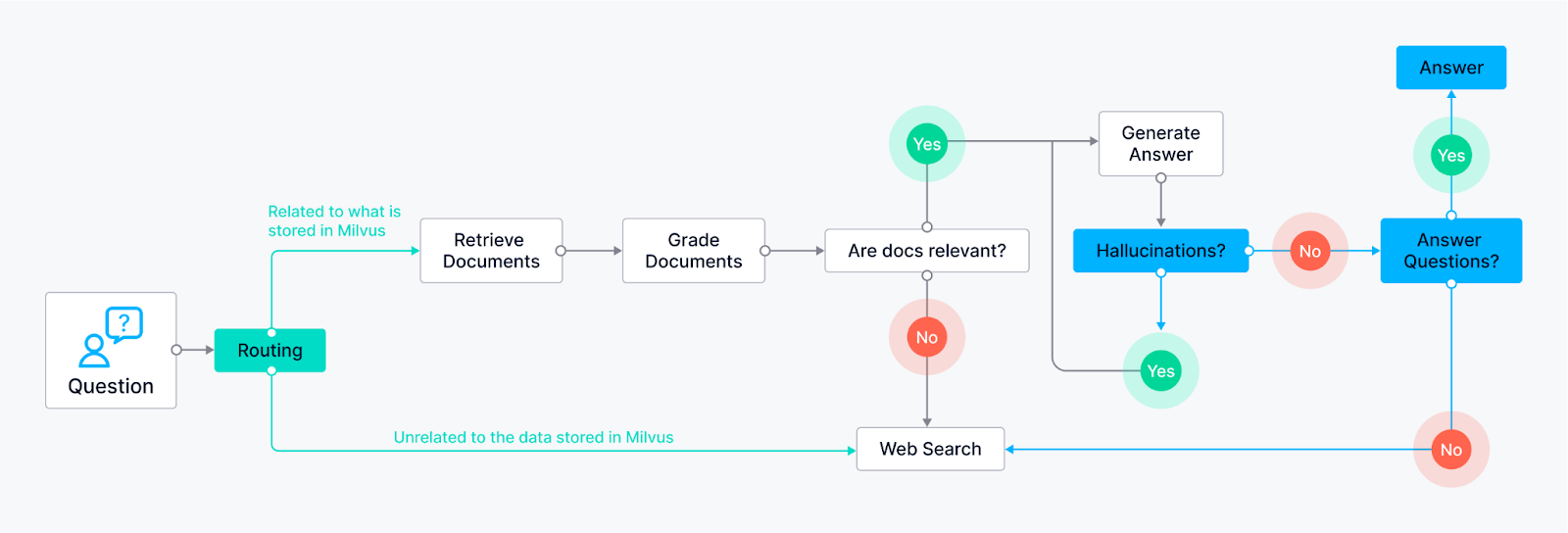
エージェントの例
LLMエージェントの機能を紹介するために、2つの重要なコンポーネントを見てみましょう: Hallucination Grader と Answer Grader です。完全なコードはこの投稿の一番下にありますが、これらのスニペットはこれらのエージェントがLangChainフレームワークの中でどのように動作するかをより良く理解するのに役立つでしょう。
幻覚グレーダー
Hallucination GraderはLLMの一般的な課題である、モデルがもっともらしく聞こえるが事実に基づかない答えを生成する幻覚を修正しようとします。このエージェントはファクトチェッカーとして機能し、LLMの答えがMilvusから検索された提供されたドキュメントのセットと一致しているかどうかを評価する。
### 幻覚グレーダー
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# プロンプト
prompt = PromptTemplate(
template="""あなたは採点者です。
を評価する採点者です。回答が一連の事実に基づいているか/裏付けされているかを示すために、「はい」または「いいえ」の二値得点を与えてください。
答えが一連の事実に基づいているか/事実によってサポートされているかどうかを示します。バイナリ・スコアを JSON として提供します。
として提供する。
ここに事実があります:
{ドキュメント}。
これが答えです:
{世代}です。
""",
input_variables=["generation", "documents"]、
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke({"documents": docs, "generation": generation})
回答グレーダー
幻覚グレーダーに続いて、別のエージェントが介入する。このエージェントは、LLMの答えがユーザの元の質問に直接対応しているかどうかという、もう一つの重要な点をチェックする。このエージェントは同じLLMを使用しますが、異なるプロンプトを使用し、特に質問に対する答えの関連性を評価するように設計されています。
def grade_generation_v_documents_and_question(state):
"""
生成の根拠が文書と質問への回答であるかどうかを決定します。
引数
state (dict):現在のグラフの状態
戻り値
str:次に呼び出すノードの決定
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
ドキュメント = state["documents"]
世代 = state["generation"]
score = hallucination_grader.invoke({"documents": documents, "generation": generation})
評点 = score['score']
# 幻覚をチェックする
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# 質問回答チェック
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
評点 = score['score']
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
"not useful "を返す
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "サポートされていません"
上のコードを見ると、分類器として使っているLLMによる予測をチェックしていることがわかる。
LangGraph グラフのコンパイル
これで、定義した全てのエージェントがコンパイルされ、RAGシステムに様々なツールを使うことができるようになります。
# コンパイル
app = workflow.compile()
# テスト
from pprint import pprint
inputs = {"質問":「プロンプトエンジニアリングとは何ですか?}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f "Finished running: {key}:")
pprint(value["generation"])
'実行終了:generate:'
('プロンプトエンジニアリングとは、大規模言語'
'モデル(LLM)とコミュニケーションするプロセスである。
'モデルの重みを更新する。それはアライメントとモデルの操縦性に焦点を当て、'
'モデル間で効果が異なるため、実験とヒューリスティックを必要とする'
'モデル間で効果が異なるため、実験とヒューリスティックスを必要とする。目標は、特定の用途のためにプロンプトを最適化することで、制御可能なテキスト生成を改善することである。
'特定のアプリケーションのためのプロンプトを最適化することによって、制御可能なテキスト生成を向上させることである。')
結論
今回のブログポストでは、LangChain/ LangGraph、Llama 3.2、Milvusを使ったエージェントを使ったRAGシステムの構築方法を紹介しました。これらのエージェントを使うことで、LLMに計画、記憶、様々な道具を使う能力を持たせることができ、よりロバストで情報量の多い応答が可能になります。
改善のための次のステップ
現在のagentic RAGシステムの実装は、ローカルで単一エージェントのワークフローには効果的であるが、さらなる改善と革新のためのエキサイティングな方向性がいくつかある。
**現在、LangGraphはウェブ検索のような事前に定義された制御フローの中で動作するシングルエージェントシステムを設計するために使用されています。しかし、自然な流れとしては、このシステムを拡張して、複数のエージェントが並行して、あるいは協調して動作することをサポートすることでしょう。タスクが専門的な知識や複数の検索ソースを必要とするシナリオでは、エージェントはタスクの異なる部分を共同で処理することができる。例えば、あるエージェントは事実情報の検索に集中し、別のエージェントは創造的なタスクやユーザーとのインタラクションを処理し、3番目のエージェントは出力全体の品質を評価する。このようなマルチエージェントシステムは、より複雑なオペレーションを可能にし、多様なクエリをより高い効率と精度で処理することにつながる。
リアルタイムデータ更新:もう一つの潜在的な改良点は、エージェントがリアルタイムでデータソースを更新できるようにすることである。現在、Milvus Liteは静的な知識ベースとして機能しているが、動的なドメインでは、情報はすぐに古くなってしまう。エージェントは、ウェブや他のAPIからの新鮮なデータを継続的に監視し、ローカルベクタストアを更新するように設計することで、システムの出力が適切かつ最新の状態を維持できるようになる。例えば、エージェントが最新の株価やニュース速報について質問された場合、自動的に最新のデータを取得することで、システムの適応性を高め、ペースの速い環境でも役立つようにすることができる。
反省と自己改善の強化: 現在の反省メカニズムは便利ですが、自己修正という点では改善の余地があります。エージェントの将来のバージョンは、強化学習や継続的学習メカニズムのような、より高度な技術を取り入れることができ、エージェントは過去の経験や失敗から時間をかけて学ぶことができます。エージェントが反復的に回答品質を向上させるための記憶作業を可能にすることで、高品質の回答を検索・生成するだけでなく、フィードバックに基づいてプロセスを改良するシステムを実現できるだろう。
このような次のステップを取り入れることで、エージェント型RAGシステムの能力を大幅に向上させ、柔軟性、適応性、そして様々な業界における複雑なタスクの解決に効果的なシステムにすることができる。
Milvus Bootcampリポジトリ](https://github.com/milvus-io/bootcamp/tree/master/bootcamp/RAG/advanced_rag)で利用可能なコードを自由にチェックしてください。
langgraphエージェントRAGを構築する方法を紹介したこのブログポストを楽しんでいただけたなら、私たちに星を与え、私たちのコミュニティに参加してあなたの経験を共有することを検討してください。
これはMetaのGithubリポジトリに触発されたもので、Llama 3を使うためのレシピがあります。

読み続けて

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.

Zilliz Cloud BYOC Upgrades: Bring Enterprise-Grade Security, Networking Isolation, and More
Discover how Zilliz Cloud BYOC brings enterprise-grade security, networking isolation, and infrastructure automation to vector database deployments in AWS