




Building Advanced Retrieval Augmented Generation (RAG) Apps with LlamaIndex
Introduction
In a recent Unstructured Data Meetup hosted by Zilliz (San Francisco), Laurie Voss, VP of Developer Relations at LlamaIndex, delivered a talk on "Building Advanced RAG Apps with LlamaIndex. He shared his knowledge on how to make Retrieval Augmented Generation (RAG) Frameworks simpler and production-ready with LlamaIndex.
Let's dig into the concepts of RAG and see how LlamaIndex 🦙 assists with developing RAG apps. To give a quick background on LlamaIndex (formerly known as GPTIndex), much of their earlier works have been done with robust closed-source technologies like OpenAI. However, as open-source models started to catch up, they started integrating with open-source alternatives. Whether it’s LLMs, embedding models, or re-ranking technologies, they now cover a number of options for a user to use their own data to build a RAG Application.
What is Retrieval Augmented Generation (RAG)?
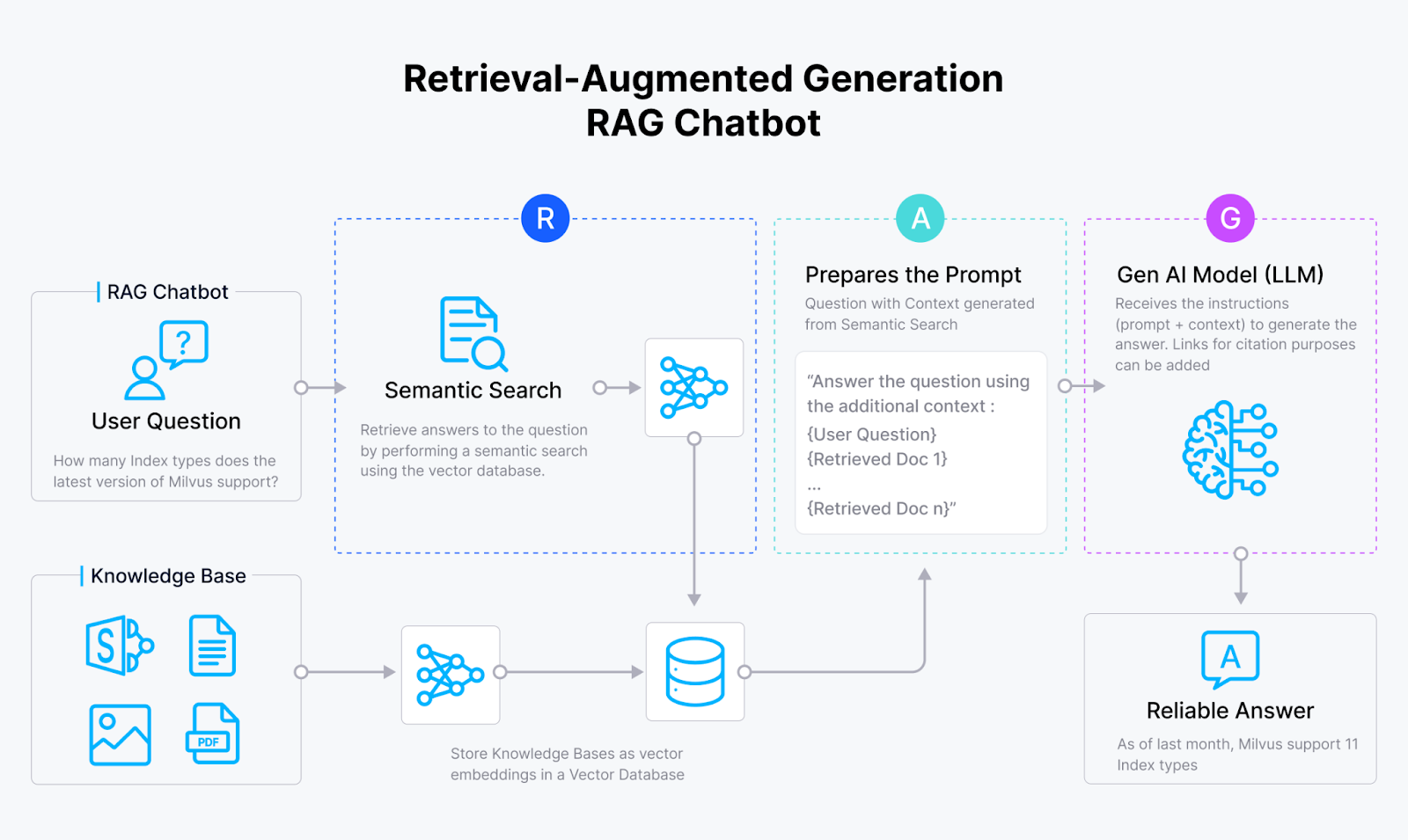
Systematic RAG Workflow
RAG is a framework designed to overcome the limitations of LLMs by assisting them with retrieval capabilities. The main drawback of LLMs is that they have limited context windows and can only handle part of an organization's data simultaneously (Not more than a million tokens at a time). RAG addresses this problem by selectively retrieving only the most relevant text/data to provide the most accurate responses.
Key Benefits of RAG:
Accuracy: When relevant and concise data is retrieved by implemented retrieval methods and sent to an LLM, it ensures accurate responses.
Recency: Some may question why companies don't train LLMs using their data. The challenge with fine-tuning is that loading an LLM into any environment, especially high-quality ones, is already costly. On the other hand, retrieval-augmented Generation (RAG) allows for easy, real-time data updates. This makes RAG a practical solution for dynamic data environments, such as those found in large private law firms or industrial companies.
Provenance: RAG can trace the niche sources of information, which is crucial for applications requiring verifiable data.
To simplify, remember the Comprehension Tests you gave as a kid? RAG is highly similar to it. The retrieved chunks of text act as a comprehension, from which the Kid (LLM) has to answer queries. It’s that simple ;-)
Advanced RAG Techniques
Two techniques are widely used for information retrieval.
Keyword Search: Traditional keyword search methods are still effective for retrieving data based on specific terms.
Vector Search(Most Powerful), also known as vector similarity search: Think of a vector search as something that turns words into numerical lists called vectors. These vectors capture the essence of each word’s meaning. We can find similar words by comparing these vectors based on their numerical closeness (measured mainly by cosine similarity or dot product). Vector search helps us retrieve data much more effectively and reliably. Once we perform the vector search, the LLM can access the most relevant text to answer the query.
Search engines are used in RAG systems to retrieve documents from various sources, enhancing the retrieval of relevant information and improving the overall responsiveness of AI tools.
When you think of a vector search, think of your Oxford Dictionary. However, group the words by their letter sequences instead of grouping them by their meaning. The vector embedding models do the same thing dimensionally.
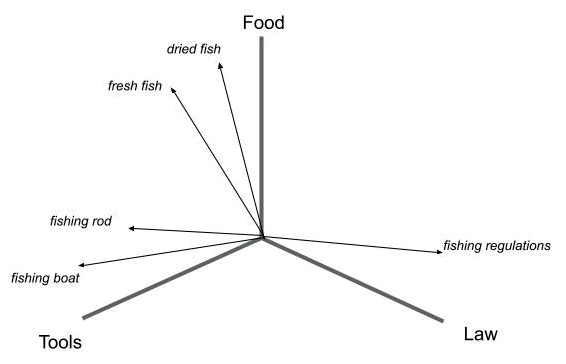
Dimensional and Semantic Grouping of Terms using Vector Search
Also, open-source Vector Databases like Milvus can be used to set up Vector Stores for free! Check it out here.
LlamaIndex: Simplifying RAG Implementation
LlamaIndex is an open-source framework that connects your data to LLMs, available in Python and TypeScript. It simplifies the creation of RAG applications, allowing developers to build functional RAG systems with minimal code. To implement a basic RAG functionality, you only need five lines of Python Code, thanks to LlamaIndex.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
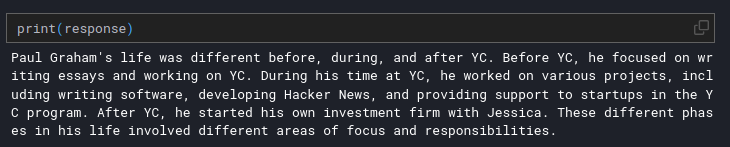
response = query_engine.query("What did the author do growing up?")
Advanced RAG Features for Data Ingestion and Querying with LlamaIndex
LlamaIndex also provides a wide range of advanced data ingestion and querying features for your RAG applications.
Ingestion
Data Connectors: LlamaHub by LlamaIndex provides connectors for various data sources, including Google Drive, Notion, Slack, and databases like Postgres and MongoDB.
PDF Parsing: LlamaIndex offers advanced PDF parsing capabilities, converting complex PDFs into Markdown for better LLM understanding since LLMs are trained on a large chunk of Markdown Data.
Embedding Models: LlamaIndex supports various open-source and closed-source embedding models, allowing customization based on the domain.
Vector Stores: LlamaIndex integrates with multiple vector databases, again, both open and closed source, including Milvus and Zilliz Cloud, for efficient storage and retrieval.
Querying
- Sub-Question Query Engine
For complex questions that require multiple simple queries, the sub-question query engine breaks down the main query into smaller parts, retrieves answers from different sources, and combines them into a single response.
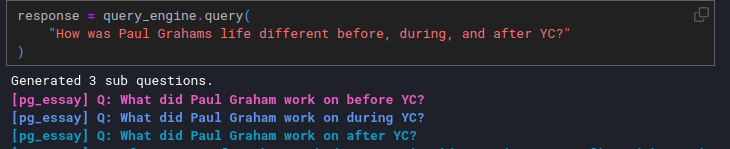 Query Breakdown for better retrieval
Query Breakdown for better retrieval
Query Breakdown for better retrieval
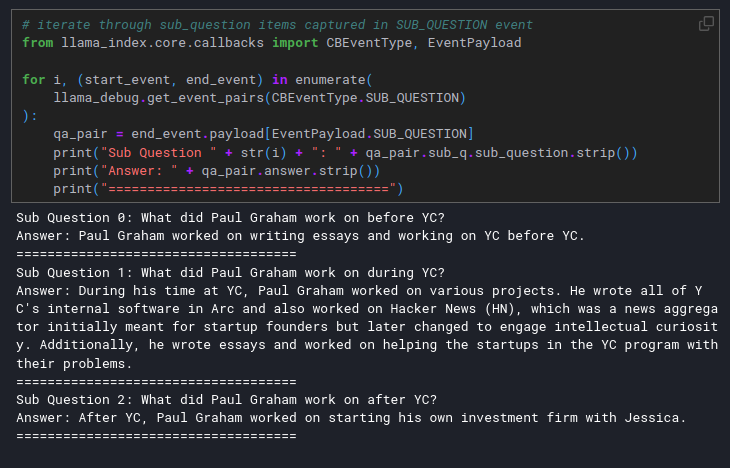 Separate Responses Collection
Separate Responses Collection
Separate Responses Collection
 Final Compiled Response
Final Compiled Response
Final Compiled Response
See the Code here.
- Small to Big Retrieval
This methodology involves embedding extremely small pieces of text (sentences that are highly and likely relevant to the user query) into vectors and retrieving the window of vectors around that sentence both up and Down.
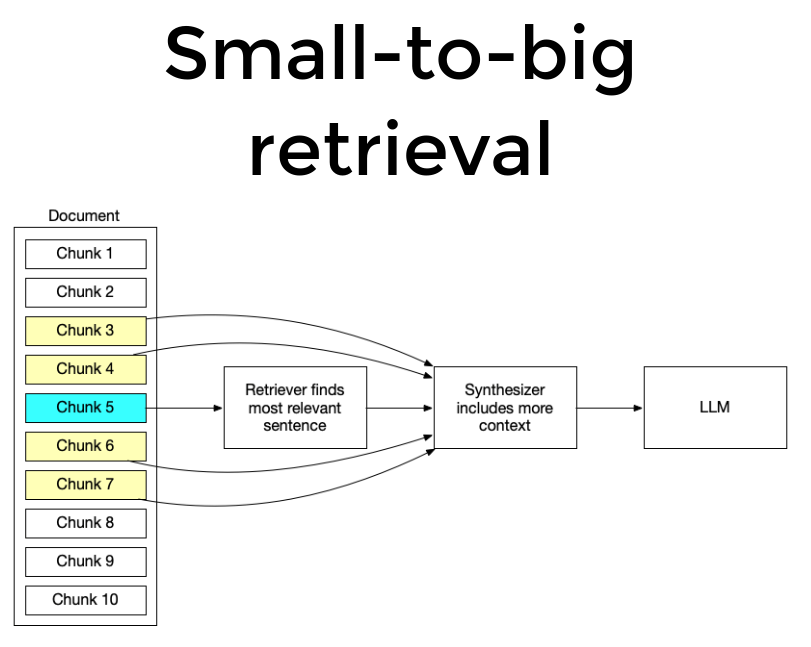 Small to Big Retrieval methodology visualization
Small to Big Retrieval methodology visualization
Small to Big Retrieval methodology visualization
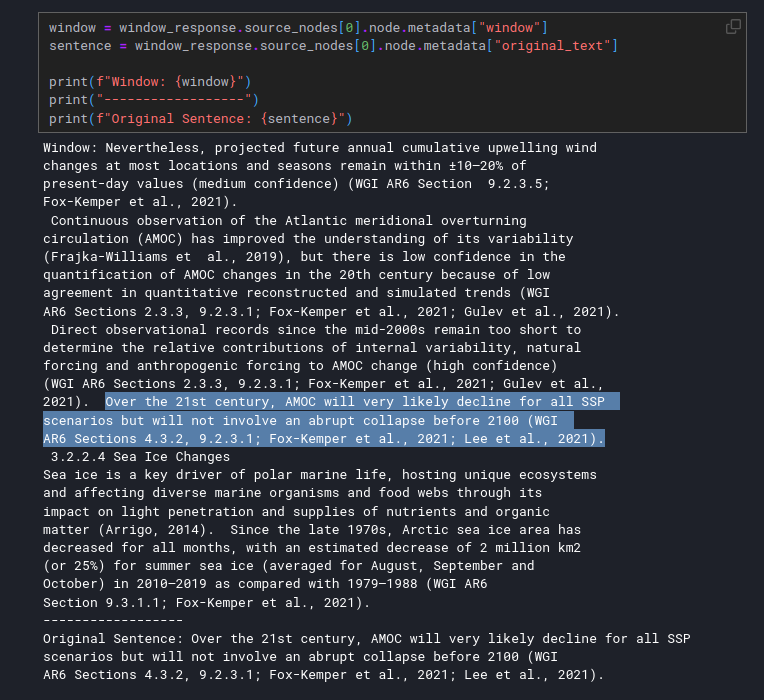 Real Implementation
Real Implementation
Real Implementation
See the Code here.
Pre-tagging documents with metadata (e.g., year, user, company, keywords), like the example below, allows for more precise filtering and retrieval, enhancing the accuracy of the LLM's responses. This feature can help with Keyword Search. Think of metadata like custom properties for text.
 A T-shirt ad
A T-shirt ad
A T-shirt ad
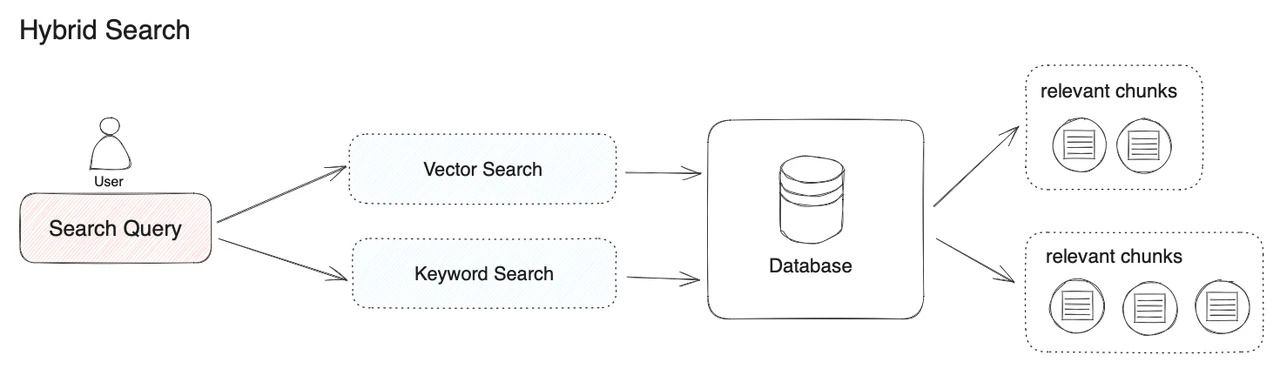
By combining keyword and vector search, the hybrid search runs queries through the specified methods. It merges the results based on confidence scores, ensuring the most relevant data is retrieved—a detailed example with Code here.
- Agents
LlamaIndex Agents are semi-autonomous software pieces that use various tools to achieve a goal. They can combine multiple retrieval strategies and tools to answer complex queries effectively.
Think of it this way: a tool is a predefined user function on which a user can set a description of what it does, and the Agent is an Engineer who works with these tools. If the user prompts an LLM directly on what the multiplication of two huge numbers will result in, it will most likely give an answer nearing the actual ground truth answer but not the same. But if we give it a multiplication tool that it can call based on a set description, it will consistently achieve the correct answer no matter the size of the numbers.
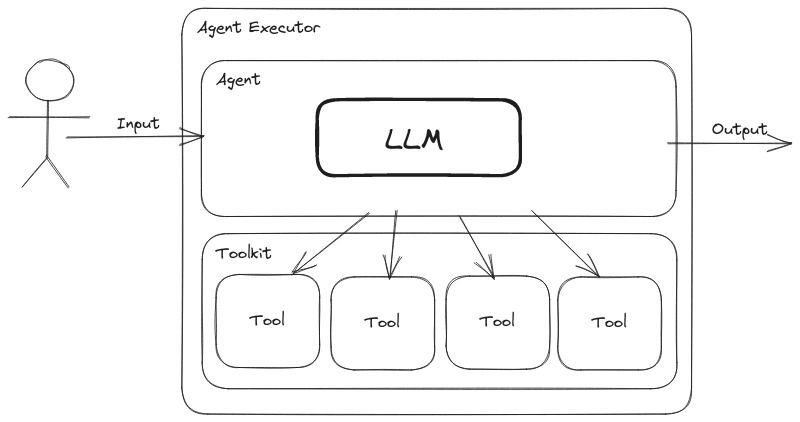 Simple Agentic Workflow
Simple Agentic Workflow
Simple Agentic Workflow
Similarly, a user can build an Agentic RAG Workflow by giving LLM the tools and their descriptions and letting it decide which to use for a specific RAG query.
Advanced RAG Summary
Laurie’s presentation showcases basic and advanced application frameworks for RAG, which we can build with minimal lines of code using LlamaIndex. LlamaIndex also provides us with LlamaParse, which can help us index our data into our favorite vector databases like Milvus locally or on the cloud. It’s ultimately up to the user to choose what best fits their use cases. This presentation also showcased various RAG strategies that one can opt for to optimize Retrieval and Generation.
Citations
Liu, Jerry. “Llamahub.” Llamahub, 2023, https://cloud.llamaindex.ai/parse.
Liu, Jerry. “Starter Tutorial (OpenAI).” LlamaIndex, 2023, https://docs.llamaindex.ai/en/stable/getting_started/starter_example/.
“Llama Hub.” Llama Hub, 2023, https://llamahub.ai/.
LlamaIndex. “Hybrid Search.” LlamaIndex, 2023, https://docs.llamaindex.ai/en/stable/examples/vector_stores/MilvusHybridIndexDemo/.
LlamaIndex. “LLM based Agents.” LlamaIndex, 2023, https://docs.llamaindex.ai/en/stable/use_cases/agents/.
LlamaIndex. “Metadata Replacement + Node Sentence Window.” LlamaIndex, 2023, https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/MetadataReplacementDemo/.
LlamaIndex. “Sub Question Query Engine.” LlamaIndex, 2023, https://docs.llamaindex.ai/en/stable/examples/query_engine/sub_question_query_engine/.
Milvus. “Milvus.” Milvus: Vector database, 2019, https://milvus.io/.
Milvus. “Milvus Vector Datbases.” Milvus: Vector database, 2023, https://milvus.io/.
Milvus. “Quickstart Milvus documentation.” Milvus, 5 May 2024, https://milvus.io/docs/quickstart.md.
Keep Reading

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.