




Elasticsearchは素晴らしかったが、ベクターデータベースが未来だ
この記事はThe New Stackに掲載されたもので、許可を得てここに再掲載している。
何十年もの間、Elasticsearchに代表される全文検索として知られるキーワードマッチは、エンタープライズサーチやレコメンデーションエンジンのような情報検索システムのデフォルトの選択肢であった。
AIを活用した検索技術が進歩するにつれ、システムがユーザーのクエリの背後にある意味と意図の両方を理解できるようにする、セマンティック検索へのシフトが進んでいる。埋め込みモデルとベクトルデータベースは、このシフトの中心となっている。
セマンティック検索は、ベクトル埋め込みとしてデータを表現することで、キーワードマッチングを凌駕し、検索意図のより微妙な理解を提供し、retrieval-augmented generation (RAG)からmultimodal search までのアプリケーションを変革する。
実際には、効果的な情報検索システムには、意味的な理解と正確なキーワードマッチングの両方が必要である。例えば、ユーザーは、検索結果が検索クエリに関連する概念を示すと同時に、特別な用語や名前など、クエリで使用されたリテラルテキストを尊重し、完全に一致する結果を返すことを期待している。
密なベクトルによるセマンティック検索は意味を理解するのに役立ち(「car」と「automobile」が同じであることを知るように)、従来の全文検索はユーザーが期待する正確な結果を提供する(「Python 3.9」の完全一致を見つけるように)。その結果、多くの組織がハイブリッド検索アプローチを採用し、両者の長所を組み合わせることで、柔軟な意味的関連性と予測可能な完全一致キーワードのバランスを取っている。
ハイブリッド検索の課題
ハイブリッド検索を実装する一般的な方法は、効率的でスケーラブルなセマンティック検索のためにオープンソースMilvusのような専用に構築されたベクトルデータベースを、フルテキスト検索のためにElasticsearchやOpenSearchのような従来の検索エンジンと並行して使用することである。
このアプローチは良い結果をもたらすが、同時に新たな複雑さをもたらす。2つの異なる検索システムを管理することは、別々のインフラ、設定、メンテナンスタスクに対処することを意味し、運用の負担が重くなり、潜在的な統合の問題が発生する可能性が高まります。
ハイブリッド検索におけるElasticsearchとMilvusの比較](https://assets.zilliz.com/Elasticsearch_vs_Milvus_on_Hybrid_search_7981aca132.jpg)
図:ハイブリッド検索におけるElasticsearchとMilvusの比較
ハイブリッド検索の統一ソリューションは多くの利点をもたらすだろう:
インフラメンテナンスの軽減:** 2つのシステムではなく1つのシステムを管理することで、運用の複雑さを劇的に軽減し、時間とリソースの両方を節約できる。また、2つの異なるAPIを使いこなすためのコンテキスト切り替えや精神的なオーバーヘッドも少なくなる。
統一されたテーブル構造により、dense(ベクトルベース)とsparse(キーワードベース)の両方のデータを、共有されたメタデータ・ラベルと一緒に保存することができます。2つの別々のシステムを使用すると、双方がメタデータのフィルタリングを行うために、メタデータ・ラベルを2回保存する必要があります。
合理化されたクエリー:単一のリクエストで、セマンティック検索と全文検索の両方のタスクを実行できるため、別々のシステムに2回のAPIコールを行う必要がなくなる。
セキュリティとアクセス制御の強化**:統一されたアプローチにより、すべてのアクセス制御をベクトル・データベース内で一元管理できるため、よりわかりやすく堅牢なセキュリティ管理が可能になり、セキュリティ・コンプライアンスと一貫性が強化されます。
統一されたベクター・アプローチがハイブリッド検索を簡素化する ## How a Unified Vector Approach Simplifies Hybrid Search
セマンティック検索では、機械学習モデルはテキストをその意味に基づいて高次元空間に密なベクトルとして知られる点として「埋め込む」。似たような意味を持つテキストは、この空間において互いに近くなる。例えば、"apple "と "fruit "は、"apple "と "car "よりも近いかもしれない。これにより、近似最近傍(ANN)アルゴリズムを使って各ポイント間の距離を計算するだけで、意味的に関連するテキストを素早く見つけることができる。
この方法は、文書やクエリをスパースベクトルとして符号化することで、全文検索にも応用できる。スパースベクトルでは、各次元は用語を表し、その値は各用語が文書内でどの程度重要であるかを示す。
文書に存在しない用語の値はゼロである。通常、任意の文書で使用される用語は、語彙に含まれる可能性のあるすべての用語のごく一部であるため、ほとんどの用語は文書に登場しない。つまり、結果として得られるベクトルはスパースであり、その値のほとんどがゼロである。例えば、情報検索タスクの評価によく使われるMS-MARCOデータセットでは、約900万の文書と100万のユニークな用語があるが、検索システムは通常、この大規模なコレクションをより小さなセグメントに分割して管理を容易にする。
何十万もの用語が含まれるセグメントレベルであっても、各文書に含まれる用語は通常100未満であり、各ベクトルの値の99%以上はゼロである。この極端なスパース性は、これらのベクトルを効率的に保存・処理する方法にとって重要な意味を持つ。
このスパースパターンを利用することで、精度を維持しながら検索性能を最適化することができる。もともと密なベクトル用に設計されたベクトル・データベースは、このような疎なベクトルを効率的に扱えるように適応させることができる。例えば、オープンソースのベクトルデータベースMilvusは、Elasticsearchや他の全文検索システムで使用されているBM25アルゴリズムのスパースベクトル実装であるSparse-BM25を使用したネイティブの全文検索サポートをリリースしたばかりだ。Sparse-BM25は、全文検索のための近似ベースの最適化を可能にします:
データ刈り込みによる効率的な検索アルゴリズム:**セグメントインデックス内のスパースベクトル値が最も小さい文書を破棄するヒューリスティックベースの刈り込みを適用し、検索クエリ内の低バリュースパースベクトルを無視することで、ベクトルデータベースはインデックスサイズを大幅に削減し、最小限の品質損失でパフォーマンスを最適化することができます。
さらなる性能最適化のアンロック: ターム頻度を逆インデックスの代わりにスパースベクトルとして表現することで、ベクトルベースのさらなる最適化が可能になります。これには以下が含まれます:
ブルートフォーススキャンよりも効率的な検索にグラフインデックスを使用。
積の量子化(PQ)/スカラの量子化(SQ)](https://zilliz.com/learn/scalar-quantization-and-product-quantization)により、メモリフットプリントをさらに削減。
これらの最適化に加え、Sparse-BM25の実装は、高性能ベクトルデータベースMilvusのシステムレベルの利点をいくつか継承している:
効率的な低レベルの実装とメモリ管理:** MilvusのコアとなるベクトルインデキシングエンジンはC++で実装されており、ElasticsearchのようなJavaベースのシステムよりも効率的なメモリ管理が可能です。これだけで、JVMベースのアプローチと比較して、メモリフットプリントをギガバイト単位で削減することができます。
MMapのサポート:** Elasticsearchがメモリとディスクの両方にインデックスを保存するためにページキャッシュを使用しているのと同様に、Milvusはインデックスが利用可能なメモリを超えた場合にメモリ容量を拡張するためのメモリマッピング(MMap)をサポートしています。
伝統的な検索スタックがベクトル検索に劣る理由
Elasticsearch は伝統的な転置インデックス用に構築されているため、高密度なベクトル検索のためにアーキテクチャ全体を最適化することは根本的に困難です。その影響は明らかで、たった100万ベクトルでも、Elasticsearchは検索結果を返すのに200ミリ秒(フルマネージドElastic Cloudでテスト)かかるのに対し、Milvusは6ミリ秒(フルマネージドZilliz Cloudでテスト)、これは30倍以上の性能差です。1秒あたりのクエリー数(QPS)で測定したスループットも3倍の差があり、Zilliz Cloudの最もパフォーマンスの高いインスタンスは6000 QPSで動作するのに対し、Elastic Cloudは最大でも1900 QPSです。さらに、Zilliz CloudはElastic Cloudよりもベクトルデータのロードとインデックスの構築で15倍高速です。ElasticsearchのJava/JVM実装はC++/Goベースのベクターデータベースのスケーラビリティに匹敵するのに苦労しています。さらに、Elasticsearchにはディスクベースのインデックス(DiskAnn、MMap)、最適化されたメタデータフィルタリング、範囲検索といった重要なベクトル検索機能が欠けています。
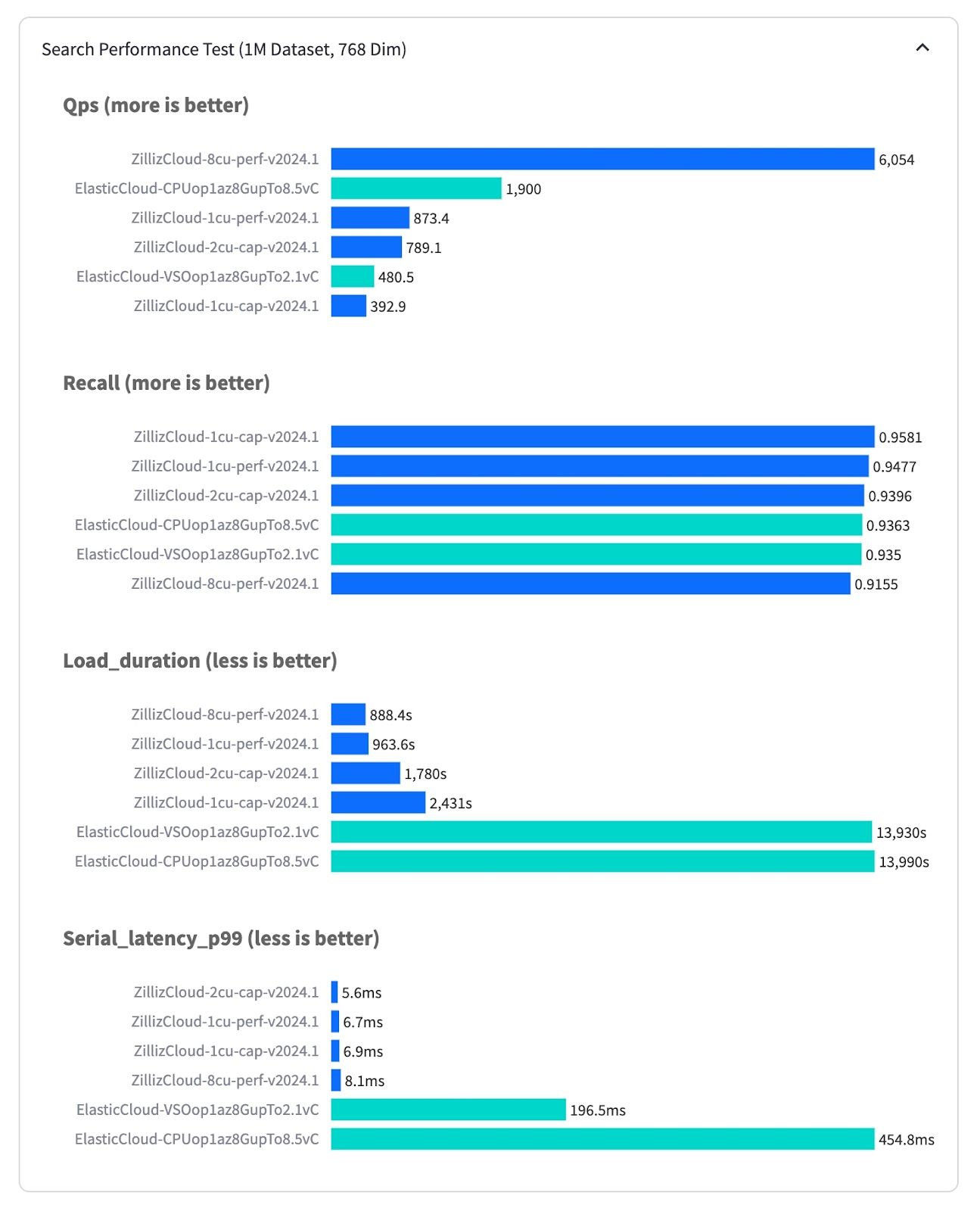 VectorDBBenchベンチマーク結果.jpg
VectorDBBenchベンチマーク結果.jpg
図:VectorDBBenchのベンチマーク結果(source)
結論
Milvusに代表されるベクターデータベースは、ハイブリッド検索の統合ソリューションとしてElasticsearchを凌ぐ勢いです。密なベクトル検索と最適化されたスパースベクトル技術を統合することで、ベクトルデータベースは優れたパフォーマンス、スケーラビリティ、効率を提供します。この統一されたアプローチにより、インフラストラクチャが簡素化され、メモリフットプリントが削減され、検索機能が強化され、高度な検索ニーズの未来が実現します。その結果、ベクターデータベースはセマンティック検索とフルテキスト検索をシームレスに組み合わせた包括的なソリューションを提供し、Elasticsearchのような従来の検索システムを凌駕します。

読み続けて

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.