




Milvus Introduced MMap for Redefined Data Management and Increased Storage Capability
Milvus is the fastest solution in open-source vector databases, catering to users with intensive performance requirements. However, the diversity of user needs mirrors the data they work with. Some prioritize budget-friendly solutions and expansive storage over sheer speed. Understanding this spectrum of demands, Milvus introduces the MMap feature, redefining how we handle large data volumes while promising cost efficiency without sacrificing functionality.
What is MMap?
MMap, short for memory-mapped files, bridges the gap between files and memory within operating systems. This technology allows Milvus to map large files directly into the system's memory space, transforming files into contiguous memory blocks. This integration eliminates the need for explicit read or write operations, fundamentally changing how Milvus manages data. It ensures seamless access and efficient storage for large files or situations where users need to access files randomly.
Who benefits from MMap?
Vector databases demand substantial memory capacity due to the storage requirements of vector data. With the MMap feature, processing more data within limited memory becomes a reality. However, this increased capability comes at a performance cost. The system intelligently manages memory, evicting some data based on load and usage. This eviction allows Milvus to process more data within the same memory capacity.
During our tests, we observed that with ample memory, all data resides in memory after a warm-up period, preserving system performance. However, as data volume grows, performance gradually decreases. Therefore, we recommend the MMap feature for users less sensitive to performance fluctuations.
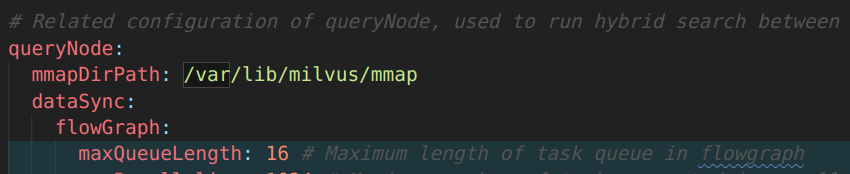
Enabling MMap in Milvus: a simple configuration
Enabling MMap in Milvus is remarkably straightforward. All you need to do is modify the milvus.yaml file: add the mmapDirPath item under the queryNode configuration and set a valid path as its value.
Striking the balance: performance, storage, and system limits
Data access patterns significantly impact performance. Milvus's MMap feature optimizes data access based on locality. MMap enables Milvus to write scalar data directly to the disk for sequentially accessed data segments. Variable-length data such as strings undergoes flattening and is indexed using an offsets array in memory. This approach ensures data access locality and eliminates the overhead of storing each variable-length data separately. Optimizations for vector indexes are meticulous. MMap is selectively employed for vector data while retaining adjacency lists in memory, conserving significant memory without compromising performance.
In addition, MMap maximizes data processing by minimizing memory usage. Unlike previous Milvus versions where QueryNode copied entire datasets, MMap adopts a streamlined, copy-free streaming process during development. This optimization drastically reduces memory overhead.
Our internal testing results show that Milvus can efficiently handle double the data volume when enabling MMap.
The road ahead: continuous innovation and user-centric enhancements
While the MMap feature is in its beta phase, Milvus's team is committed to continuous improvement. Future updates will refine the system's memory usage, enabling Milvus to support even more extensive data volumes on a single node. Users can anticipate more granular control over the MMap feature, enabling dynamic changes to collections and advanced field loading modes. These enhancements provide unprecedented flexibility, allowing users to tailor their data processing strategies to specific requirements.
Conclusion: redefining data processing excellence with Milvus MMap
Milvus 2.3's MMap feature marks a significant leap in data processing technology. By striking a delicate balance between performance, cost, and system limits, Milvus empowers users to handle vast amounts of data efficiently and cost-effectively. As Milvus continues to evolve, it remains at the forefront of innovative solutions, redefining the boundaries of what's achievable in data management.
Stay tuned for more groundbreaking developments as Milvus continues its journey toward unparalleled data processing excellence.

Keep Reading

How Zilliz Saw the Future of Vector Databases—and Built for Production
An inside look at how Zilliz built vector databases for real-world use, focusing on scalability, stability, and running them reliably at scale.

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.