




AIアプリケーションのためのマルチモーダルなパイプライン
人工知能(AI)アプリケーションの成功には、効率的なデータ準備と管理が必要である。よりロバストなデータパイプラインは、より正確で信頼性が高く、コンテキストを考慮したアウトプットにつながります。AIワークフローがますます複雑になるにつれ、それをサポートするスケーラブルでインテリジェントなパイプラインの必要性が急務となっている。
最新のAIシステムは、レポート、画像、PDFなどの非構造化データと格闘している。検索拡張世代(RAG)を採用するシステムには、結果の精度を維持しながらコストを抑え、複雑なデータを処理するための正確な戦略が必要です。
このようなシステムの構築は、異なるフォーマットのデータを解析し、予測不可能なAIの出力に対処し、効率的に拡張できるパイプラインを構築することを意味する。最近、Zillizが主催したUnstructured Data Meetupで、データエンジニアリングとAIで18年以上の経験を持つDatavoloのCTOであるSamが、これらの課題に取り組んだ。
Apache NiFi上に構築されたプラットフォーム、DataVoloは、これらの問題に対処するために強調された。非構造化データ処理を簡素化し、スケーラブルでクラウドネイティブなパイプラインの作成を可能にする。DataVoloはまた、メタデータ、パーミッションの変更に対するリアルタイム応答性、非決定論的AIモデルに対応する強力な評価フレームワークをサポートしている。
この記事では、マルチモーダルパイプラインのベストプラクティスに関するセッションの主なポイントを解説します。非構造化データの管理とMilvusのようなベクトルデータベースによる効率的な検索、AIワークフローを強化するための実行可能な戦略について探ります。
ミートアップのフルビデオはこちらでご覧いただけます。
.AIにとってマルチモーダルなパイプラインが重要な理由
企業がAIを大規模に導入する際に直面する可能性のある主な課題は、大量の複雑なデータを扱うことです。従来の抽出-変換-ロード(ETL)ツールでは、テキスト、画像、動画、音声のような異なるフォーマットを扱うタスクを処理できません。その理由は以下の通りだ:
非構造化データが主流:** 企業のデータの80%以上は、文書、画像、動画を含む非構造化データです。これは従来のツールでは対処できない課題です。マルチモーダルパイプラインは、非構造化データを実用的なインテリジェンスに変換する高度なAIアルゴリズムを備えた統合ワークフローを提供します。これらのパイプラインは、生データとAIモデルのギャップを埋め、組織がより良い意思決定のためにデータを使用できるようにします。
AIの精度向上:** GPTのような大規模言語モデル(LLM)は堅牢ですが、無関係な出力や不正確な出力を生成するなどのエラーが発生しがちです。AIモデルの精度が向上するのは、マルチモーダルなパイプラインの機能により、さまざまな種類のデータをメタデータで強化された統一フレームワークに処理できるためです。このメタデータは、AIシステムが与えられたクエリに関連する最も関連性の高い情報を検索するためのガイドとして機能する。
Improving Retrieval-Augmented Generation: RAG は、データ検索と生成AIを組み合わせ、より革新的で文脈に関連した出力を生成する。マルチモーダルなパイプラインは、シームレスなワークフロー最適化のための埋め込みとメタデータを提供する。検索時に関連するデータを常に引き出すことで、生成モデルが適切な回答を与えることを保証する。
AIワークフローの拡張:** 現代企業は増加するデータ量に対応しています。マルチモーダルパイプラインは、チャンキング、埋め込み、メタデータ管理などのタスクを自動化します。これにより、ワークフローが拡張してもパフォーマンスを維持しやすくなります。これらのパイプラインは、効率性を犠牲にすることなく、増大する需要に対応するために必要なスケーラビリティを提供します。
リアルタイム更新:*** 企業データは、コンテンツの更新からアクセス許可まで、常に変化しています。マルチモーダルなパイプラインはリアルタイムの同期を保証します。これにより、AIシステムは最新かつ最も関連性の高い情報で運用され続けます。また、正確なAI出力のためにリアルタイムのデータが重要な動的なユースケースもサポートします。
これらのパイプラインは、効率的で革新的なAIシステムの基礎を築きます。多様なデータソースの統合を合理化し、実世界におけるAIモデルのパフォーマンスを向上させます。
AIデータの課題
AIシステムには、トレーニング用の高品質なデータが必要だ。しかし、さまざまな種類のデータを管理するには課題が伴う。膨大な量の非構造化データを扱うビジネスでは、複雑さが増す。それでは、AIデータ環境における課題をいくつか見てみよう:
データ・タイプの複雑さ:*** データ・フォーマットには、意味のある情報を抽出するための特定のツールやワークフローが必要です。例えば、PDFは、表、テキスト、画像を含む混合データを含んでいる。そのため、必要なデータを取り出すには解析が必要です。レイアウト検出のようなモデルは、すべての重要な情報を保持するために、このようなデータを正確に処理し、配置することができます。
バックボーンとしてのメタデータ:**メタデータはAIワークフローの生産性を高めるために不可欠である。ユーザーが必要なデータに素早くアクセスできるように、高度な検索、取得、アクセス制御を提供する。メタデータは、検索された情報のフィルタリング、ランク付け、アクセスの確保に不可欠であり、したがって成功するAIシステムの重要な要素である。データをメタデータで豊かにすることで、ハイブリッド検索アプローチが強化され、セマンティック埋め込みがメタデータフィルターに結合される。これにより、AIシステムの精度と関連性が向上する。
データ管理:*** 大企業では、更新、修正、追加によってデータが変わることがある。そのようなダイナミックなフローをリアルタイムで効果的にサポートできるシステムが必要である。例えば、アクティブ・インジェスト・システムは、AIワークフローシステムへのソースファイルの同期を中断することなく保証する。
評価第一のアプローチ:** AIシステムの結果を継続的に監視・評価することは、一貫した信頼性の高いアウトプットを達成するために不可欠である。システムを本番稼動させる前に、企業は評価セットと評価指標を作成すべきである。これは、ビジネス目標を達成するためにシステムが複雑なデータをどのように処理するかを測定するのに役立つ。合成データセットは、チャンキングやエンベッディングを含む戦略のテストと改良に使用できる。
スケーラビリティと統合:*** データ量が徐々に増加するにつれて、スケーラビリティが非常に重要になる。AIシステムは、パフォーマンスの低下や作業負荷の増加なしに、既存のエンタープライズ・ツールと統合する必要があります。スケーラブルなソリューションは、データのサイズや複雑さが増すにつれてワークフローの効率を向上させる。ベクトルデータベースなどの高度なシステムを統合することで、ベクトル検索などの機能が強化され、実世界のシナリオでのスムーズな運用が保証される。
これらに対処することで、企業はデータのパワーをフルに引き出し、AIシステムがダイナミックな環境で強力に機能するための強固な基盤を作ることができる。最新のパイプラインは、AIにおける生データと運用ワークフローのギャップを埋めることで、変革的な結果をもたらす。
AIスタックにおけるDataVoloの位置づけ
DataVoloは、マルチモーダルデータパイプラインを構築するための画期的なプラットフォームです。Apache NiFi](https://nifi.apache.org/)を搭載したDataVoloは、最新のAIシステムのための強力な基盤を持っています。主な機能は以下の通りです:
継続的で自動化されたデータパイプライン: ** Datavoloは、継続的でイベントドリブンな取り込みのために構築されています。データ量の変動に応じて動的にスケールアップし、高スループット時でも予測可能なパフォーマンスを実現します。このプラットフォームは、音声、ビデオ、画像、センサー信号、構造化されたJSONやXML、テキストベースのログなど、様々な形式のデータをサポートします。
構文解析とチャンキング: ** DataVoloは、非構造化データを簡単に扱うことができます。複雑なドキュメントを管理しやすいセクションに分割する、高度なドキュメント解析のための専用プロセッサーを備えています。例えば、ChunkDocumentプロセッサーは、構造情報を使用して、首尾一貫したチャンクを形成します。一方、ChunkTextプロセッサーは、意味的な意味に基づいて、さらに小さなチャンクに洗練します。
クラウドネイティブなデプロイメント: ** DataVoloは、本質的にクラウドネイティブであり、そのアーキテクチャは、AWS、GCP、Azureのような主要なプロバイダーへの柔軟なデプロイメントを可能にします。組織は、既存のクラウドインフラを利用することができます。ハイブリッドクラウド環境でのシームレスな運用を可能にし、パフォーマンスと管理性を保証します。
監視性: ** DataVoloは、標準化されたデータ収集のためにOpenTelemetryと統合されており、様々な監視・分析ツールとの相互運用が可能です。さらに、自然言語をNiFiフローに変換するGenAI-based Flow Generatorとも統合されています。これにより、データパイプラインの作成や管理が容易になる。
Datavoloは、データエンジニアをターゲットとしており、パイプラインの設計、計画、保守のためのビジュアルでローコードなインターフェースを提供しています。Datavoloのプラットフォームは、様々なプロセッサーとコネクターがあらかじめ用意されており、様々なソースとデスティネーションを効果的にサポートします。AIテクノロジーやデータ要件の変化に迅速に対応できる柔軟性を備えている。このため、データエンジニアは、インフラを複雑にすることなく、インパクトのあるAIソリューションを提供することができる。
ベクターデータベースとの統合: ** DataVoloは、効率的なベクターデータベース管理のために、ZillizとMilvusの両方と非常によく統合されています。この2つは相乗効果を発揮し、スケールとパフォーマンスに優れたAIワークフローの全社的な開発を支援します。
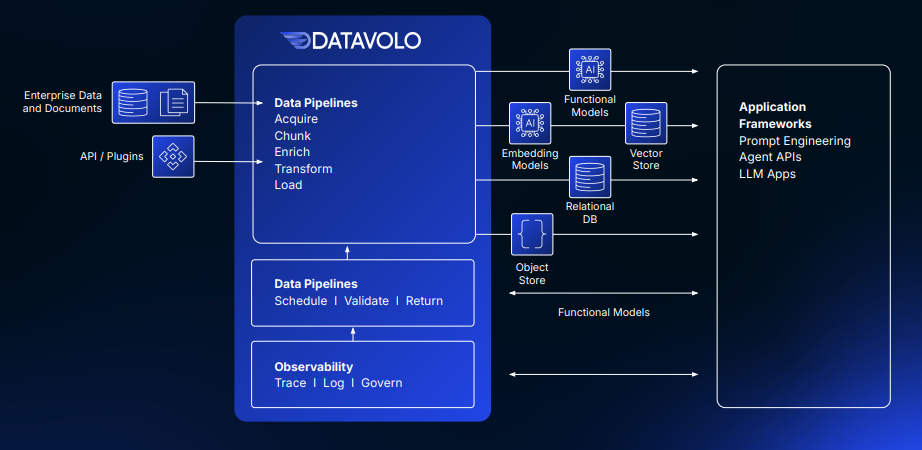
DATAVOLOの動作: ソース
ケーススタディ金融データ分析チャットボット
財務レポートのような非構造化ドキュメントの処理には、本質的な複雑さを扱うための革新的なアプローチが必要です。ほとんどの企業は、このような文書から意味のある洞察を抽出する際に深刻な課題に直面しています。このような文書を処理し、スケーラブルなソリューションを作成する方法を明らかにしましょう。
課題
10-Kレポートのような財務文書の処理は、企業にとって複雑です。これらのレポートは通常数百ページにも及び、表、グラフ、テキストデータを含んでいます。手作業で処理すると、非常に時間がかかり、エラーが発生しやすく、非効率的です。
解決策
スケーラブルで自動化されたパイプラインは、データ処理のための高度な技術とベクターデータベースを統合する必要がある。ソリューションには以下のプロセスが含まれる:
**S3バケット](https://docs.zilliz.com/docs/integrate-with-aws-s3)を含む様々なソースからデータを抽出する。各文書の関連性を高め、意思決定に役立てるために、文書のタイプやソースなどの重要な詳細を追加します。動的なデータフローを持つ非構造化データを扱う際には、CDC(Change Data Capture)が実装されている。これは、ソースファイルのすべての更新、修正、追加がキャプチャされ、リアルタイムでターゲットシステムと同期されることを保証します。
CDCは、無関係な情報の使用を回避し、ワークフロー全体でデータの整合性を維持します。古いデータの再処理を避けるために、これらのリストアップ戦略により、取り込みはさらに最適化されます:
タイムスタンプに基づくリスト:** 特定のタイムスタンプ以降に追加または変更されたファイルのみをリストすることができます。これにより、新規または更新されたデータの取り込みが冗長性なく行われることが確認されます。
ハッシュ技術:*** ファイル名が同じままであっても、コンテンツを比較して、以前に処理されたファイルを識別し、スキップします。
これらの機能により、変化に適応した堅牢で効率的なデータ取り込みパイプラインが保証され、AIシステムは正確で最新の情報によって動的に作動し続けます。
**ドキュメントの前処理には、以下のステップが含まれます:
レイアウト検出:** レイアウト検出は、PDFや財務報告書などの複雑な文書を処理する際に重要な役割を果たします。これは、微調整されたYOLO-Xモデルを適用して、表、画像、セクションなどのコンポーネントを識別し、バウンディングボックスを使用してラベル付けします。表は構造を保持し、説明テキストや説明の文脈リンクがあります。ドキュメントグラフは、ナビゲーションと検索を向上させるために、これらの要素を階層化します。OCRは、テキストレイヤーが存在せず、すべての文書要素をキャプチャする必要がある場合に使用されます。これにより、正確で信頼性の高いデータ抽出のために、構造とコンテキストが維持されます。
チャンキング:*** 文書は効率的な処理のために管理しやすい塊に分割される。最も素朴なアプローチは、400のような固定文字数によるチャンキングです。しかし、これは意味的につながりのある情報を分割してしまう可能性があり、効果的とはいえない。より洗練された方法はセクションベースのチャンキングで、レイアウト検出によって検出されたセクションが境界となる。したがって、各チャンクは、見出しやその中に登場する物語テキストなど、セクションの文脈を保持する。チャンキングのもう一つの戦略は、連続する文の余弦類似度を適用することにより、テキストの意味を利用するものである。それが与えられたしきい値より小さいとき、チャンクを実行する。この検索戦略は、ユーザのクエリの精度を高めることで、それぞれの文章を意味的に支離滅裂なものにする。
メタデータの抽出:*** 文書タイプやソースURLなど、いくつかのメタデータは、パイプラインの設定によって静的に設定される。 その他のメタデータは、レイアウト検出や外部データソースによるエンリッチメントによって抽出された詳細など、処理の流れから自動的に導き出される。例えば、財務ドキュメントに存在するシンボルは、PostgreSQLテーブルの同じシンボルを照会し、適切な企業レベルのメタデータを付加する。これにより、ハイブリッド検索、ランク付けされた結果、強化されたメタデータに基づくセキュアなアクセス制御など、より高度なユースケースが可能になる。
エンベッディング:***テキストチャンクは、最先端のエンベッディングによってダイナミックな高次元ベクトルに変換されます。これらのベクトルはデータの本質を捉え、意味のあるつながりを明らかにします。ユーザーのクエリに答えながら、情報検索を直感的な体験にします。
**これらの埋め込みとメタデータは、Milvusのような高性能ベクトルデータベースに保存されます。これにより、インデックス化された何百万ものベクトルが保存されていても、迅速に検索することができます。メタデータフィルタリングは、クエリに日付範囲や文書セクションのような更なるコンテキストを考慮することを可能にすることにより、精度をもたらします。
リアルタイム更新: 継続的な取り込みパイプラインは、システムの正確性と関連性を維持するためにデータを自動的に更新します。ユーザーが最新のデータにアクセスできるようにします。
成果
これは、特に金融アナリストのためのチャットボットを作成するのに役立ちます。ボットは、"2023年のX社の純利益はいくらですか?"や "リスク評価セクションで特定された主なリスクは何ですか?"といったロングテールのクエリを受け取るかもしれません。ボットは、元の文書からの適切な引用とともに、数秒で正しい、文脈に関連した回答を提供する。
**主な利点
効率性:***取り込み、前処理、埋め込みが自動化され、財務チームがより高次のタスクに費やす時間を節約。
スケーラビリティ:*** 高度なベクトル・データベースにおける何百万ものベクトルの保存と検索をスケーラブルにサポートすることで、データ量の増加に伴う分析を簡素化します。
リアルタイムの洞察**:継続的な更新により、アナリストは一刻を争う意思決定に必要な最新情報を確実に入手できます。
このユースケースは、複雑なワークフローを簡素化するマルチモーダルパイプラインの威力を浮き彫りにしています。高度なデータ処理をベクトルデータベースソリューションと統合することで、いかに大きな価値を提供できるかを示しています。
Milvus: ベクトル検索の高速化
MilvusはマルチモーダルAIパイプラインのサポートを強化し、テキスト、画像、動画などのさまざまなデータを簡単に統合して処理するための機能を多数導入しています。主な強化点は以下の通りです:
ハイブリッド・ベクトル・キーワード検索:** Milvus は、ベクトル類似検索と全文キーワード検索を単一のプラットフォームに統合している。これにより、異なるデータモダリティにわたる効率的な検索が可能になる。これにより、意味理解と高精度のキーワードマッチングを必要とする高度なAIアプリケーションが可能になる。
Sparse-BM25テクノロジー:** Milvusは、BM25アルゴリズムのスパースベクトルバージョンを可能にするSparse-BM25テクノロジーを導入した。これは、全文検索システムで使用される最も一般的なアルゴリズムの1つです。この技術は、キーワード検索の速度と精度を著しく向上させ、ベクトルベースの意味検索を補完する。これにより、マルチモーダルAIパイプラインの性能が向上する。
AI開発ツールキットの統合:** Milvusは、LangChain、LlamaIndex、OpenAI、およびHuggingFaceを含むAI開発ツールキットの全スイートとネイティブに統合します。これらのツールキットにより、Milvusは様々なデータモダリティのRAGをサポートし、マルチモーダルAI開発の摩擦を軽減するジェネレーティブAIアプリケーションに最適なベクターストアとなります。
これらの機能強化により、MilvusはマルチモーダルAIパイプラインの構築と展開において堅牢かつ効率的になります。これにより、企業はさまざまな種類の非構造化データを一箇所で処理・分析できるようになる。
継続的で自動化されたデータパイプライン
企業のデータはダイナミックで常に変化しているため、AIシステムに供給するデータセットには、自動化されたワークフローが必要です。DataVoloは、次のような点でこれに対応します:
リアルタイムの取り込み: ** DataVoloは、S3バケット、Google Drive、SharePointなどのデータソースに接続することで、リアルタイムの取り込みを可能にします。イベント駆動型のメカニズムでインジェストを自動化し、人的介入を減らします。また、インジェストを効率的に処理するために、設定可能なインジェスト戦略も提供します。これらの戦略には、タイムスタンプベースのリストが含まれ、冗長性を発生させることなく、新規または更新されたファイルのみを識別して処理するため、リソースを最適化することができます。
イベント駆動型アーキテクチャ: ** DataVoloのパイプラインはイベント駆動型で、上流システムの変更に自動的に対応します。ファイルの変更、メタデータの更新、ユーザーパーミッションなどのイベントが、パイプラインの自動更新のトリガーとなります。ACLのような機密性の高いメタデータも、このプロセスを通して安全に管理されます。
スケーラブルでフォールトトレラントな設計:*** スケーラビリティとフォールトトレラントが特徴で、高スループットのインジェスト時のパフォーマンス低下を大幅に低減します。水平スケーリングは、Kubernetesを利用したオーケストレーションによって処理されます。リトライロジック、バックフィルプロセス、アップストリームダウンタイム管理機能を内蔵しており、データパイプラインの管理中に信頼性と回復力を提供します。
評価によるAIの成功
評価は効果的なAI導入に不可欠な柱である。精度、信頼性、満足度を高めるためのシステムの改良を測るものである。AIモデルの評価には、以下の指標が役立ちます:
検索メトリクス
精度:** 検索された関連データの全結果に対する比率で、システムは最も適切な情報のみを返します。
回収率:*** 検索された関連データの、関連データ全体に対する割合。
F1スコア:** この指標は、精度とリコールを1つのスコアにまとめたものです。この2つのトレードオフのバランスをとり、総合的な評価を行います。
言語モデルの指標
AIの応答が得られた文脈からのものであるかどうかを検証し、事実性を維持するために幻覚を減らす。
AIが生成した回答をテストデータと比較し、出力の正確さを測定します。
課題は非決定論的モデルの評価にあり、システムは確率的な性質のため、同じ入力に対して異なる出力を与える可能性がある。正しい」応答を決定し評価することは、本質的に複雑である。正確さや妥当性の認識は、ユーザーや特定の文脈によって異なることが多い。これを解決するには、動的なフィードバックループ、反復、様々なテストセット、コンテキストに敏感なメトリクスが必要である。
ハイパーパラメータのチューニングは、AIワークフロー、特に検索支援生成(RAG)システムを改良する上で極めて重要である。様々なチャンキング戦略には、チャンクサイズ、オーバーラップ、類似度のしきい値などのパラメータを注意深く設定する必要がある。このようなチャンキング戦略には、より広範なコンテキストのためのセクションベースのチャンキングや、より高精度のためのセマンティックチャンキングが含まれる。
検索メトリクスと組み合わせた反復テストは、精度とコンテキストの豊富さの最適なバランスを特定するのに役立ち、高品質の検索と生成を保証する。
評価優先のワークフローにより、AIシステムは刻々と変化するデータとユーザーニーズのランドスケープに対応することができます。反復的な改良と強固なメトリクスの重視により、アウトプットは信頼性、実用性、文脈性を維持する。そうすることで、実験から信頼できる実世界への展開へのギャップを埋め、AIアプリケーションの結果に対する信頼と満足を得ることができる。
結論
ロバストなマルチモーダルパイプラインは、AIシステムを実験段階から本格的な生産へと拡張するためのバックボーンである。これらのパイプラインは多様なデータタイプをシームレスに処理し、企業がより革新的なワークフローを構築することを可能にする。
ZillizやMilvusのような先進的なデータパイプラインプラットフォームとベクトルデータベースを統合することで、スケーラブルでセキュアで高性能なデータ管理を提供します。さらに、データの前処理、埋め込み、メタデータエンリッチメントなどのタスクを自動化することで、正確性と拡張性を損なうことなく、手作業を減らすことができる。
AIシステムの変換とリアルタイムの同期化によって、AIシステムは効果的になる。AIワークフローの作成が容易になり、継続的な評価と改善が可能になる。
これは、企業が継続的にアプリケーション・パフォーマンスを改善し、進化するデータ・ランドスケープに適応し、ダイナミックなビジネス・ニーズに対応するのに役立つ。このようなテクノロジーは、企業がどのようにデータを処理し、AI主導のアプリケーションを展開するかを支援することができる。
その他のリソース

読み続けて

How Zilliz Saw the Future of Vector Databases—and Built for Production
An inside look at how Zilliz built vector databases for real-world use, focusing on scalability, stability, and running them reliably at scale.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.