




DeepSearcherの紹介:ローカルオープンソースディープリサーチ
 ディープ・リサーチャー.gif
ディープ・リサーチャー.gif
前回の記事、"I Built a Deep Research with Open Source-and So Can You!" では、リサーチエージェントの基礎となる原則のいくつかを説明し、与えられたトピックや質問に関する詳細なレポートを生成するシンプルなプロトタイプを構築しました。この記事と対応するノートブックは、「ツールの使用」、「クエリの分解」、「推論」、「リフレクション」の基本的な概念を示しています。前回の記事の例は、OpenAIのDeep Researchとは対照的に、MilvusやLangChainのようなオープンソースのモデルとツールだけを使い、ローカルで実行された。(続ける前に上記記事を読むことをお勧めする)
その後の数週間で、OpenAIのディープ・リサーチを理解し再現することへの関心が爆発的に高まった。例えば、Perplexity Deep ResearchやHugging Face's Open DeepResearchをご覧ください。これらのツールは、ウェブや社内文書をサーフすることによってトピックや質問を反復的に調査し、詳細で、情報に基づいた、よく構造化されたレポートを出力するという目的を共有しているものの、アーキテクチャや方法論が異なっている。重要なのは、基礎となるエージェントが、各中間ステップでどのようなアクションを取るべきかについての推論を自動化することである。
この投稿では、前回の投稿を基に、ZillizのDeepSearcherオープンソースプロジェクトを紹介します。私たちのエージェントは、追加の概念を示しています:クエリルーティング、条件付き実行フロー、ツールとしてのウェブクローリングです。これは、Jupyterノートブックではなく、Pythonライブラリとコマンドラインツールとして提供され、前回の投稿よりも機能が充実しています。例えば、複数のソース・ドキュメントを入力することができ、コンフィギュレーション・ファイルを使って、エンベッディング・モデルやベクター・データベースを設定することができる。まだ比較的シンプルではあるが、DeepSearcherはエージェント型RAGの素晴らしいショーケースであり、最先端のAIアプリケーションへのさらなる一歩である。
さらに、より高速で効率的な推論サービスの必要性を探る。推論モデルは、その出力を向上させるために「推論スケーリング」、つまり余分な計算を利用し、1つのレポートが数百または数千のLLMコールを必要とする場合があるという事実と組み合わせることで、推論帯域幅が主要なボトルネックとなる。私たちはSambaNovaの特注ハードウェア上のDeepSeek-R1推論モデルを使用しています。これは、出力トークン/秒において、最も近い競合他社よりも2倍高速です(下図参照)。
SambaNova Cloudは、Llama 3.x、Qwen2.5、QwQを含む他のオープンソースモデルの推論サービスも提供している。この推論サービスは、SambaNovaのリコンフィギュラブル・データフロー・ユニット(RDU)と呼ばれるカスタムチップ上で実行され、生成AIモデルの効率的な推論のために特別に設計されており、コストを削減し、推論速度を向上させる。詳細はウェブサイトを参照
出力速度- deepseek r1.png](https://assets.zilliz.com/Output_speed_deepseek_r1_d820329f0a.png)
ディープサーチャーのアーキテクチャ
DeepSearcher](https://github.com/zilliztech/deep-searcher)のアーキテクチャは、前回の投稿を踏襲し、問題を4つのステップ(質問の定義/絞り込み、リサーチ、分析、合成)に分割しています。DeepSearcher](https://github.com/zilliztech/deep-searcher)の改善点に焦点を当てながら、各ステップを見ていきます。
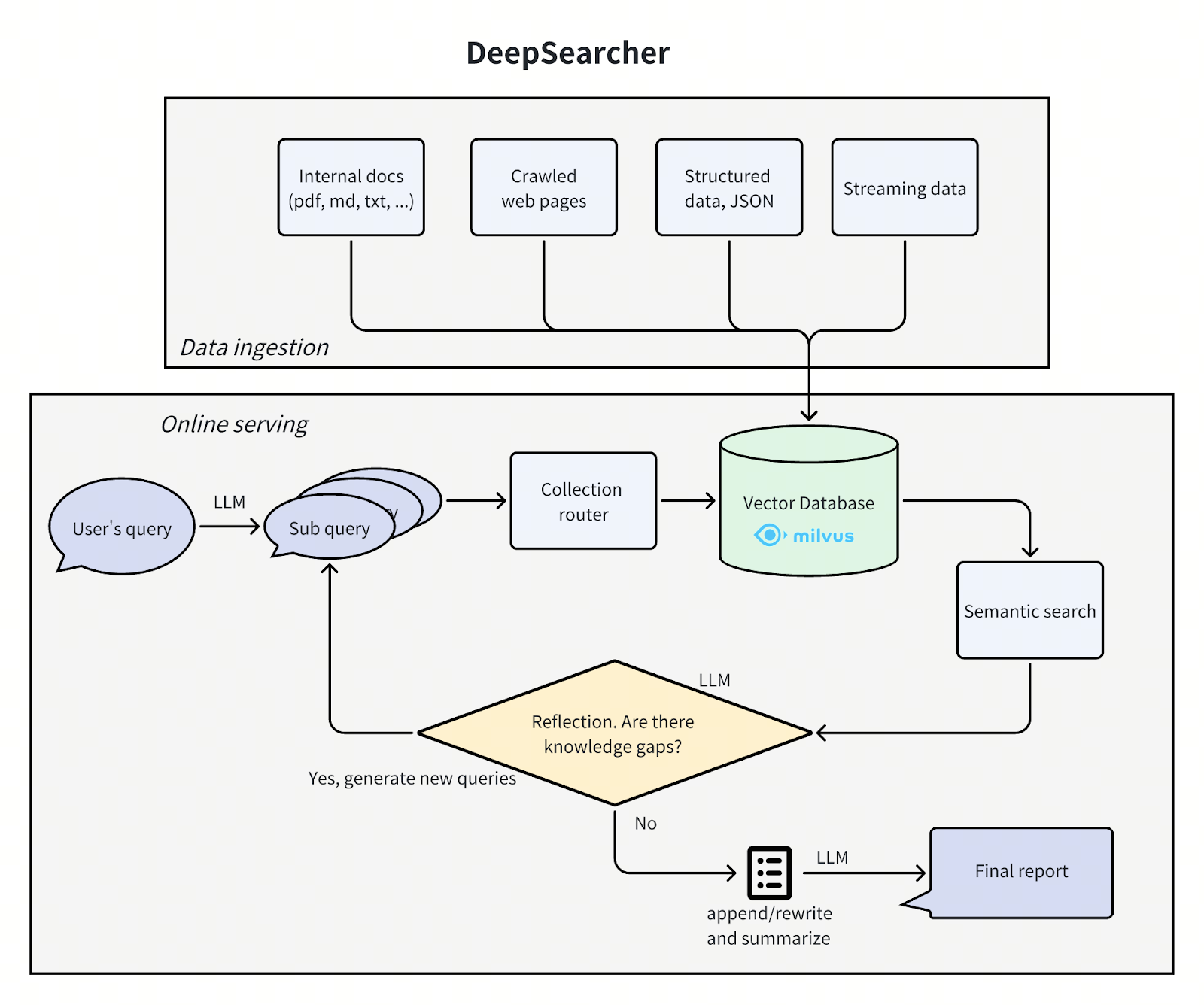 ディープサーチャーのアーキテクチャ.png
ディープサーチャーのアーキテクチャ.png
質問の定義と絞り込み
``txt 元のクエリを新しいサブクエリに分解する:[ ザ・シンプソンズの文化的影響と社会的妥当性は、デビューから現在までどのように進化してきたか? ザ・シンプソンズの異なるシーズン間で、キャラクター開発、ユーモア、ストーリーテリングのスタイルにどのような変化が起きたか? ザ・シンプソンズのアニメスタイルや制作技術は、時代とともにどのように変化してきたのか? ザ・シンプソンズの視聴者層、受け止められ方、視聴率は、放送期間を通してどのように変化してきたか?]
DeepSearcherの設計では、質問の調査と絞り込みの境界が曖昧になっています。最初のユーザークエリは、前の投稿と同様に、サブクエリに分解されます。クエリ「How has The Simpsons changed over time?」から生成される最初のサブクエリについては、上記を参照してください。しかし、次の調査ステップでは、必要に応じて質問を絞り込み続けます。
### リサーチと分析
クエリをサブクエリに分解し、エージェントのリサーチ部分を開始する。大まかに言って4つのステップがある:ルーティング"、"サーチ"、"リフレクション"、"条件リピート "である。
#### ルーティング
私たちのデータベースには、異なるソースからの複数のテーブルやコレクションが含まれています。手元のクエリに関連するソースのみにセマンティック検索を制限できれば、より効率的である。クエリ・ルーターはLLMに、どのコレクションから情報を取得するかを決定させる。
以下はクエリ・ルーティング・プロンプトの作成方法である:
python
def get_vector_db_search_prompt(
question: str、
collection_names:リスト[str]、
collection_descriptions:List[str]、
context:List[str] = None、
):
セクション = [].
# 共通プロンプト
common_prompt = f"""あなたは高度なAI問題アナリストです。あなたの推論能力と、既存のすべてのデータセットに基づく過去の会話情報を使って、以下の質問に対する絶対的に正確な答えを導き出し、質問に関連すると思われるデータセットの説明に従って、各データセットに適した質問を生成してください。
質問{質問}
"""
sections.append(common_prompt)
# データセットプロンプト
data_set = [].
for i, collection_name in enumerate(collection_names):
data_set.append(f"{collection_name}: {collection_descriptions[i]}")
data_set_prompt = f"""以下はすべてのデータセット情報です。データセット情報の書式は、データセット名:データセットの説明。
データセットと説明:
"""
セクション.append(data_set_prompt + "\n".join(data_set))
# コンテキストプロンプト
if context:
context_prompt = f"""以下は過去の会話を凝縮したものです。この情報をこの分析で組み合わせて、答えに近い質問を生成する必要があります。同じデータセットに対して同じ質問や類似の質問を生成してはいけません。また、無関係と判断されたデータセットに対して質問を再生成することもできません。
過去の会話
"""
sections.append(context_prompt + "♪n".join(context))
# 応答プロンプト
response_prompt = f"""上記を踏まえて、以下のデータセットリストからいくつかのデータセットを選択するだけで、上記の問題を解くために、選択したデータセットに対して適切な関連質問を生成することができます。出力形式はjsonで、キーはデータセットの名前、値は対応する生成された質問です。
データセット
"""
sections.append(response_prompt + "\n".join(collection_names))
footer = """正確なJSONスキーマに一致する有効なJSONフォーマットのみで応答してください。
重要な要件
- アクションタイプは1つだけ含める
- サポートされていないキーを追加しない
- JSON以外のテキスト、マークダウン、説明をすべて除外すること
- 厳密なJSON構文を維持する"""
section.append(フッター)
return "\nn".join(sections)
LLMが構造化された出力をJSONとして返すようにするのは、その出力を次に何をすべきかの決定に簡単に変換するためである。
検索
前のステップで様々なデータベースコレクションを選択したので、検索ステップではMilvusを使って類似検索を行う。前の投稿と同様に、ソース・データは事前に指定され、チャンク化され、埋め込まれ、ベクター・データベースに格納されている。DeepSearcherの場合、ローカルとオンラインの両方のデータソースを手動で指定する必要がある。オンライン検索は今後の研究に譲る。
リフレクション
前の投稿とは異なり、DeepSearcherはエージェント的なリフレクションの真の形を示し、これまでの質問と関連する検索チャンクに情報ギャップが含まれているかどうかを「リフレクション」するプロンプトに、コンテキストとして事前の出力を入力する。これは分析ステップとして見ることができる。
プロンプトを作成する方法を以下に示します:
以下はプロンプトを作成するメソッドである。 def get_reflect_prompt( question: str、 mini_questions:リスト[str]、 mini_chuncks:リスト[str]、 ): mini_chunk_str = "" for i, chunk in enumerate(mini_chuncks): mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n""" reflect_prompt = f"""元のクエリ、以前のサブクエリ、検索されたすべてのドキュメントチャンクに基づいて、追加の検索クエリが必要かどうかを判断する。さらなる調査が必要な場合は、3つまでの検索クエリのPythonリストを提供する。さらなる調査が必要ない場合は、空のリストを返します。
元のクエリがレポートを書くためのもので、それ以上のクエリを生成したい場合は、空のリストを返します。
元のクエリ質問
以前のサブクエリ{mini_questions}
関連チャンク
{mini_chunk_str}
"""
footer = """他のテキストを含まない、有効なstr形式のリストのみで応答する。"""
return reflect_prompt + フッター
もう一度、LLMが構造化された出力を、今度はPythonで解釈可能なデータとして返すようにします。
上記の最初のサブクエリに答えた後、リフレクションによって「発見された」新しいサブクエリの例を示します:
次の反復のための新しい検索クエリ:[ "ザ・シンプソンズの声優陣や制作チームの変化は、シーズンごとの番組の進化にどのような影響を与えたか? 「ザ・シンプソンズの風刺と社会的コメントは、数十年にわたる現代問題への適応においてどのような役割を果たしてきたか? ザ・シンプソンズは、ストリーミング・サービスなどメディア消費の変化にどのように対処し、配信やコンテンツ戦略に取り入れてきたか?]
#### 条件付きリピート
前回の投稿とは異なり、DeepSearcherは条件付きの実行フローを示しています。ここまでの質問と回答が完了したかどうかを反映した後、追加で質問することがあれば、エージェントは上記のステップを繰り返します。重要なのは、実行フロー(whileループ)がハードコードされているのではなく、LLM出力の関数であることです。この場合、二者択一しかありません:調査を繰り返す "か "レポートを生成する "かです。より複雑なエージェントでは、次のような選択肢があります:ハイパーリンクをたどる、チャンクを検索する、メモリに保存する、反映する、など。このようにして、エージェントがループを終了してレポートを生成することを決定するまで、質問はエージェントが適切と考えるように改良され続けます。Simpsonsの例では、DeepSearcherは追加のサブクエリでギャップを埋める処理をさらに2回実行します。
### 合成
最後に、完全に分解された質問と取得されたチャンクは、1つのプロンプトを含むレポートに合成されます。以下はプロンプトを作成するコードです:
``python
def get_final_answer_prompt(
question: str、
mini_questions:リスト[str]、
mini_chuncks:リスト[str]、
):
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
summary_prompt = f"""あなたはAIコンテンツ分析の専門家で、コンテンツの要約が得意です。前のクエリと検索されたドキュメントチャンクに基づいて、具体的で詳細な回答やレポートを要約してください。
元のクエリ質問
以前のサブクエリ{ミニクエリ}
関連チャンク
{mini_chunk_str}
"""
return summary_prompt
このアプローチには、各質問を個別に分析し、単純に出力を連結した私たちのプロトタイプよりも、すべてのセクションが互いに一貫している、つまり、繰り返されたり矛盾したりする情報を含まないレポートを作成するという利点がある。より複雑なシステムは、レポートの構造化、要約、書き換え、反映、ピボットなどの条件実行フローを使用して、両方の側面を組み合わせることができる。
結果
以下は、DeepSeek-R1がソースとしてThe SimpsonsのWikipediaページを渡して、"How has The Simpsons changed over time? "というクエリによって生成されたレポートのサンプルです:
テキスト レポートシンプソンズの進化(1989年~現在) 1.文化的影響と社会的妥当性 ザ・シンプソンズは、アメリカの中流階級の生活を破壊的に批判する番組としてデビューし、1990年代にはその大胆な風刺で有名になった。当初は反文化的現象であり、宗教、政治、消費主義に取り組むエピソードで規範に挑戦した。やがて、『サウスパーク』や『ファミリー・ガイ』のような競合番組が境界線をさらに押し広げるにつれ、文化的支配力は衰えていった。2010年代には、社会的な反響は少なくなったものの、気候変動やLGBTQ+の権利といった現代的な問題に取り組む試みとレガシー・アピールのバランスを取りながら、番組はトレンドセッターからノスタルジックな存在へと変遷した。 ... 結論 ザ・シンプソンズ』は、テクノロジー、政治、視聴者の期待の移り変わりをナビゲートしながら、過激な風刺劇からテレビ番組へと進化した。その黄金時代の輝きは今でも比類のないものだが、ストリーミング、最新のユーモア、世界的な広がりなど、その順応性は文化の試金石としての地位を確保している。この番組の長寿は、ノスタルジーと現実的な変化の受け入れの両方を反映している。
レポート全文はこちら](https://drive.google.com/file/d/1GE3rvxFFTKqro67ctTkknryUf-ojhduN/view?usp=sharing)、比較のために[DeepSearcherがGPT-4o miniで作成したレポート](https://drive.google.com/file/d/1EGd16sJDNFnssk9yTd5o9jzbizrY_NS_/view?usp=sharing)をご覧ください。
## 考察
我々は、[DeepSearcher](https://github.com/zilliztech/deep-searcher)を発表した。これは、調査およびレポート作成のためのエージェントである。我々のシステムは、前回の記事のアイデアをベースに、条件付き実行フロー、クエリルーティング、改良されたインターフェースなどの機能を追加したものである。小さな4ビット量子化推論モデルによる局所推論から、巨大なDeepSeek-R1モデルのオンライン推論サービスに切り替え、出力レポートを定性的に改善した。DeepSearcherは、OpenAI、Gemini、DeepSeek、Grok 3(近日公開予定!)など、ほとんどの推論サービスで動作します。
推論モデル、特に研究エージェントで使用される推論モデルは、推論を多用します。幸運なことに、SambaNova社のカスタムハードウェア上で動作するDeepSeek-R1の最速版を使用することができました。デモクエリでは、SambaNovaのDeepSeek-R1推論サービスを65回呼び出し、約25kトークンを入力し、22kトークンを出力しました。モデルには6710億のパラメータが含まれ、1テラバイトの3/4のサイズであることを考えると、推論のスピードには感心した。[詳細はこちら!](https://sambanova.ai/press/fastest-deepseek-r1-671b-with-highest-efficiency)
私たちは、今後の投稿でこの研究を繰り返し、さらなるエージェントの概念と研究エージェントのデザイン空間を検証していきます。その間、皆さんには[DeepSearcher](https://github.com/zilliztech/deep-searcher)を試していただき、[GitHubでスターを付けて](https://github.com/zilliztech/deep-searcher)、フィードバックを共有していただきたいと思います!
## リソース
- ZillizのDeepSearcher**](https://github.com/zilliztech/deep-searcher)
- 背景を読む:[**_"私はオープンソースでディープリサーチを構築しました、そしてあなたもできます!"_**](https://milvus.io/blog/i-built-a-deep-research-with-open-source-so-can-you.md)
- _"_[__SambaNovaが最高効率で最速のDeepSeek-R1 671Bをローンチ__](https://sambanova.ai/press/fastest-deepseek-r1-671b-with-highest-efficiency)_"_"_。
- DeepSearcher: [シンプソンズに関するDeepSeek-R1レポート](https://drive.google.com/file/d/1GE3rvxFFTKqro67ctTkknryUf-ojhduN/view?usp=sharing)
- DeepSearcher: [ザ・シンプソンズのGPT-4o miniレポート](https://drive.google.com/file/d/1EGd16sJDNFnssk9yTd5o9jzbizrY_NS_/view?usp=sharing)
- Milvusオープンソース・ベクター・データベース](https://milvus.io/docs)

読み続けて

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.