




Migliori pratiche per l'implementazione di applicazioni RAG (Retrieval-Augmented Generation)
La Retrieval-Augmented Generation (RAG) è un metodo che si è dimostrato molto efficace nel migliorare le risposte dei LLM e nell'affrontare le allucinazioni dei LLM. In poche parole, la RAG fornisce alle LLM un contesto che può aiutarle a generare risposte più accurate e contestualizzate. I contesti possono provenire da qualsiasi luogo: da documenti interni, database vettoriali, file CSV, file JSON, ecc.
RAG è un approccio innovativo che consiste in molti componenti che lavorano insieme. Questi componenti includono l'elaborazione delle query, context chunking, il recupero del contesto, context reranking e lo stesso LLM per generare la risposta. Ogni componente influenza la qualità della risposta finale generata da un'applicazione RAG. Il problema è che è difficile trovare la migliore combinazione di metodi in ogni componente che porti alle prestazioni ottimali della RAG.
In questo articolo, discuteremo diverse tecniche comunemente utilizzate in tutti i componenti del RAG, valuteremo l'approccio migliore per ciascun componente e troveremo quindi la migliore combinazione che porta alla risposta ottimale generata dal RAG, secondo questo documento. Quindi, senza ulteriori indugi, iniziamo con un'introduzione ai componenti RAG.
Componenti RAG
Come già detto, la RAG è un metodo potente per alleviare i problemi di allucinazione dei LLM, che si verificano comunemente quando si pongono domande che vanno oltre i loro dati di addestramento o quando richiedono conoscenze specialistiche. Ad esempio, se poniamo a un LLM una domanda sui nostri dati interni, probabilmente otterremo una risposta imprecisa. RAG risolve questo problema fornendo al nostro LLM un contesto che può aiutarlo a rispondere alla nostra domanda.
RAG consiste in una catena di componenti che formano un flusso di lavoro. I componenti tipici di RAG includono:
Classificazione della query: per determinare se la nostra query necessita di un recupero di contesti o può essere elaborata direttamente dal LLM.
Recupero dei contesti: per recuperare i primi k candidati nei contesti più rilevanti per la nostra query.
Context reranking: per ordinare i primi k candidati recuperati dal componente di recupero, a partire da quello più simile.
Context repacking: per organizzare i contesti più rilevanti in un formato più strutturato per una migliore generazione di risposte.
Riassunto dei contesti:** per estrarre le informazioni chiave dai contesti rilevanti e migliorare la generazione delle risposte.
Generazione della risposta: per generare una risposta basata sulla query e sui contesti rilevanti.
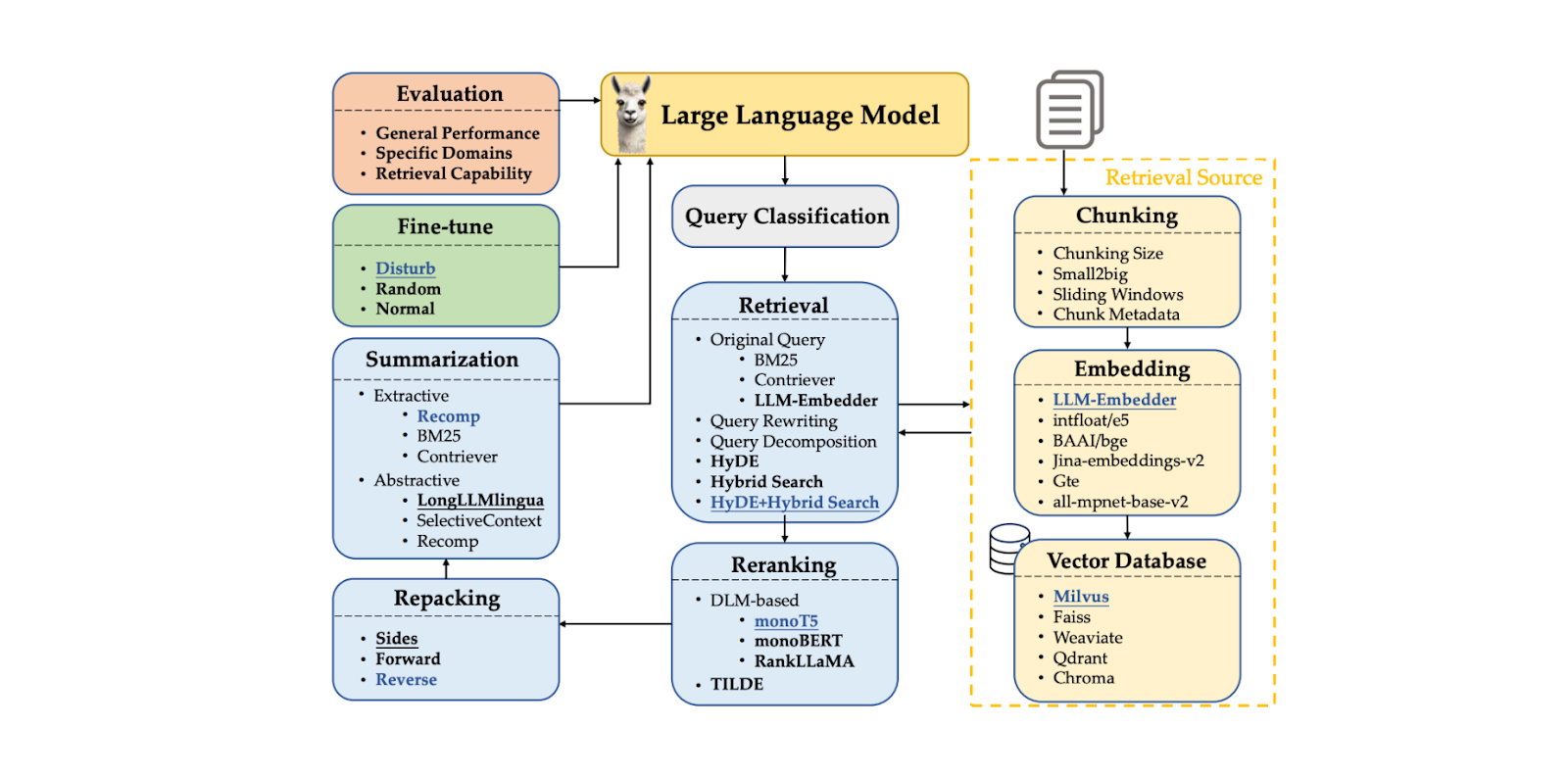 Figura- Componenti RAG..png
Figura- Componenti RAG..png
Figura: Componenti RAG._ Fonte
Sebbene questi componenti RAG siano utili durante il processo di generazione della risposta (cioè quando abbiamo già memorizzato tutti i contesti e sono pronti per essere recuperati), prima di implementare un metodo RAG occorre considerare diversi altri fattori.
Per rendere utili i documenti di contesto in un approccio RAG, è necessario trasformarli in embeddings vettoriali. Pertanto, è fondamentale scegliere il modello di embedding più appropriato e la strategia per rappresentare i nostri documenti di input come embeddings.
Un embedding contiene una rappresentazione semanticamente ricca del nostro documento di input. Tuttavia, se il documento usato come contesto è troppo lungo, può confondere il LLM nel generare una risposta appropriata. Un approccio comune per risolvere questo problema è l'applicazione di un metodo di chunking, che prevede la suddivisione del documento di input in diversi chunk e la successiva trasformazione di ciascun chunk in un embedding. È fondamentale scegliere il metodo di chunking e la dimensione migliore, poiché i chunks troppo corti probabilmente conterranno informazioni insufficienti.
 Figura- Flusso di lavoro RAG.png
Figura- Flusso di lavoro RAG.png
Figura: Flusso di lavoro RAG_
Una volta trasformato ogni chunk in un embedding, è necessario considerare l'archiviazione appropriata per questi embeddings. Se non si ha a che fare con molti embedding, è possibile memorizzarli direttamente nella memoria locale del dispositivo. Tuttavia, nella pratica si ha a che fare con centinaia o addirittura milioni di embedding. In questo caso, per memorizzarli è necessario un database vettoriale come Milvus o il suo servizio gestito, Zilliz Cloud, e la scelta del giusto database vettoriale è fondamentale per il successo della nostra applicazione RAG.
L'ultima considerazione riguarda il LLM stesso. Se possibile, possiamo mettere a punto l'LLM per rispondere con maggiore precisione alle nostre esigenze specifiche. Tuttavia, la messa a punto è costosa e non necessaria nella maggior parte dei casi, soprattutto se si utilizza un LLM performante con molti parametri.
Nelle sezioni seguenti, discuteremo gli approcci migliori per ciascun componente della RAG. Quindi, esploreremo le combinazioni di questi approcci migliori e suggeriremo diverse strategie per l'implementazione di RAG che bilanciano prestazioni ed efficienza.
Classificazione delle query
Come accennato nella sezione precedente, RAG è utile per garantire che il LLM generi risposte accurate e contestualizzate, soprattutto quando è richiesta una conoscenza specialistica dei nostri dati interni. Tuttavia, la RAG aumenta anche il tempo di esecuzione del processo di generazione delle risposte. Il fatto è che non tutte le query richiedono il processo di recupero e molte di esse possono essere elaborate direttamente dal LLM. Pertanto, saltare il processo di recupero del contesto sarebbe più vantaggioso se una query non ne ha bisogno.
Possiamo implementare un modello di classificazione delle query per determinare se una query ha bisogno del recupero del contesto prima del processo di generazione della risposta. Un modello di classificazione di questo tipo consiste solitamente in un modello supervisionato, come BERT, con l'obiettivo principale di prevedere se una query necessita di essere recuperata o meno. Tuttavia, come altri modelli supervisionati, è necessario addestrarlo prima di utilizzarlo per l'inferenza. Per addestrare il modello, dobbiamo generare un set di dati di esempi di richieste e le corrispondenti etichette binarie, tra cui se la richiesta deve essere recuperata o meno.
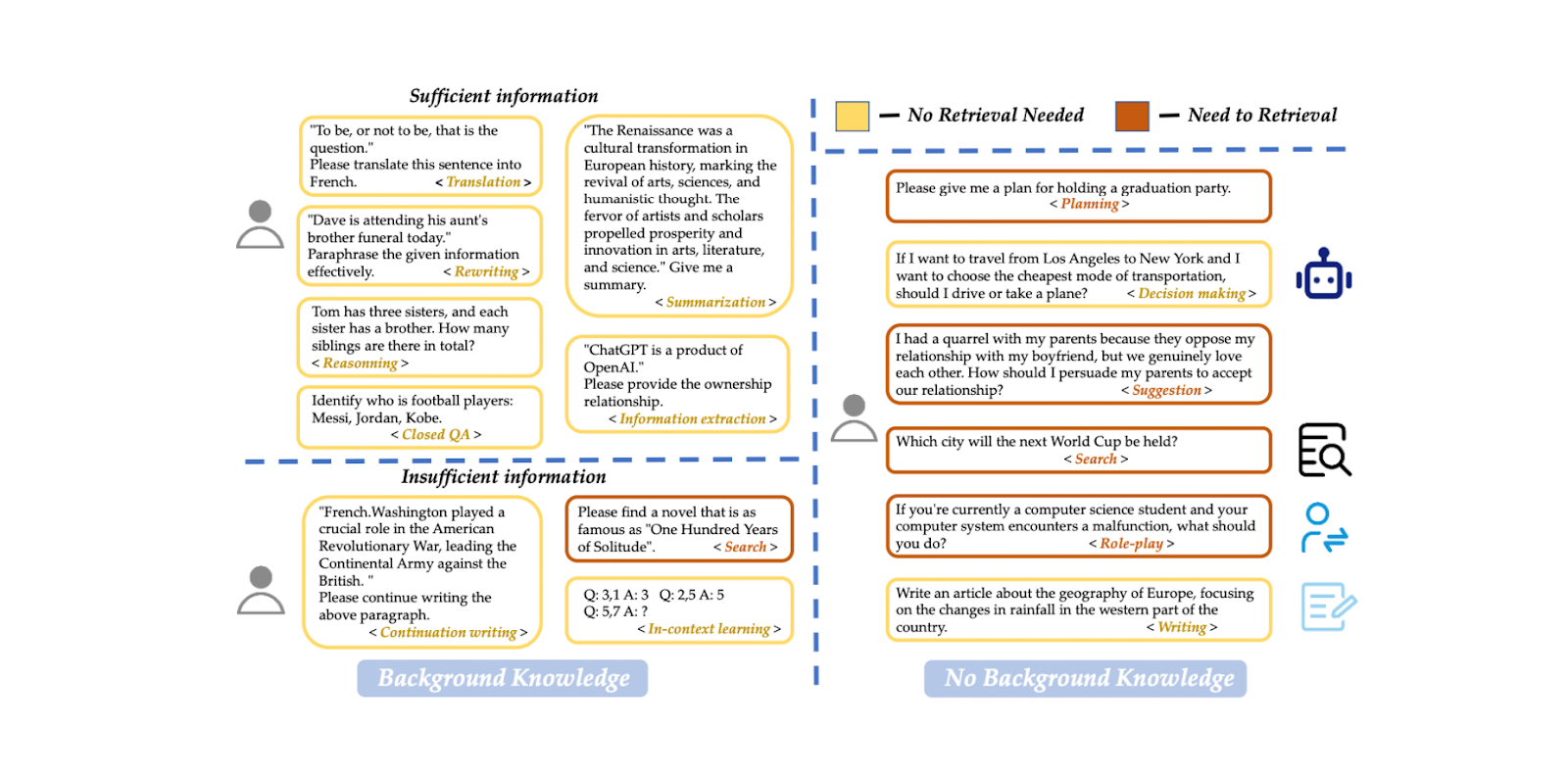 Figura- Esempio di dataset di classificazione delle query..png
Figura- Esempio di dataset di classificazione delle query..png
Figura: Query classification dataset example._ Source
Nel paper, per la classificazione delle query viene utilizzato un modello BERT-base-multilingue. I dati di addestramento comprendono 15 tipi di richieste in totale, come traduzione, riassunto, riscrittura, apprendimento nel contesto, ecc. Esistono due etichette distinte: "sufficiente" se il prompt è interamente basato sulle informazioni fornite dall'utente e non necessita di recupero, e "insufficiente" se le informazioni del prompt sono incomplete, necessitano di informazioni specializzate e richiedono un processo di recupero. Utilizzando questo approccio, il modello ha raggiunto il 95% sia in termini di accuratezza che di punteggio F1.
Questa fase di classificazione delle query può migliorare significativamente l'efficienza del processo di RAG, evitando recuperi inutili per le query che possono essere gestite direttamente dal LLM. Agisce come un filtro, assicurando che solo le query che richiedono un contesto aggiuntivo vengano inviate al processo di recupero, che richiede più tempo.
 Figura- Risultato del classificatore di query..png
Figura- Risultato del classificatore di query..png
Figura: Risultato del classificatore di query._ Fonte
Tecnica di raggruppamento
Chunking si riferisce al processo di suddivisione di lunghi documenti di input in segmenti più piccoli. Questo processo è molto utile per fornire al LLM un contesto più granulare. Esistono diversi metodi di chunking, tra cui approcci a livello di token e a livello di frase. Il chunking a livello di frase porta spesso a un buon equilibrio tra semplicità e conservazione semantica del contesto. Quando si sceglie un metodo di chunking, bisogna fare attenzione alla dimensione dei pezzi, perché pezzi troppo corti potrebbero non fornire un contesto utile al LLM.
 Figure- Splitting a long document into smaller chunks.png
Figure- Splitting a long document into smaller chunks.png
Figura: Suddivisione di un documento lungo in parti più piccole
Per trovare la dimensione ottimale dei pezzi, è stata condotta una valutazione sul documento Lyft 2021. Le prime 60 pagine del documento sono state scelte come corpus e suddivise in diverse dimensioni. È stato quindi utilizzato un LLM per generare 170 query basate su queste 60 pagine. Il modello text-embedding-ada-002 è stato utilizzato per le incorporazioni, mentre il modello Zephyr 7B è stato utilizzato come LLM per generare risposte basate sulle query scelte.
Per valutare le prestazioni del modello su chunk di diverse dimensioni, è stato utilizzato GPT-3.5 Turbo. Per valutare la qualità delle risposte sono state utilizzate due metriche: fedeltà e pertinenza. La fedeltà misura se la risposta è allucinata o corrisponde ai contesti recuperati, mentre la pertinenza misura se i contesti e le risposte recuperate corrispondono alle query.
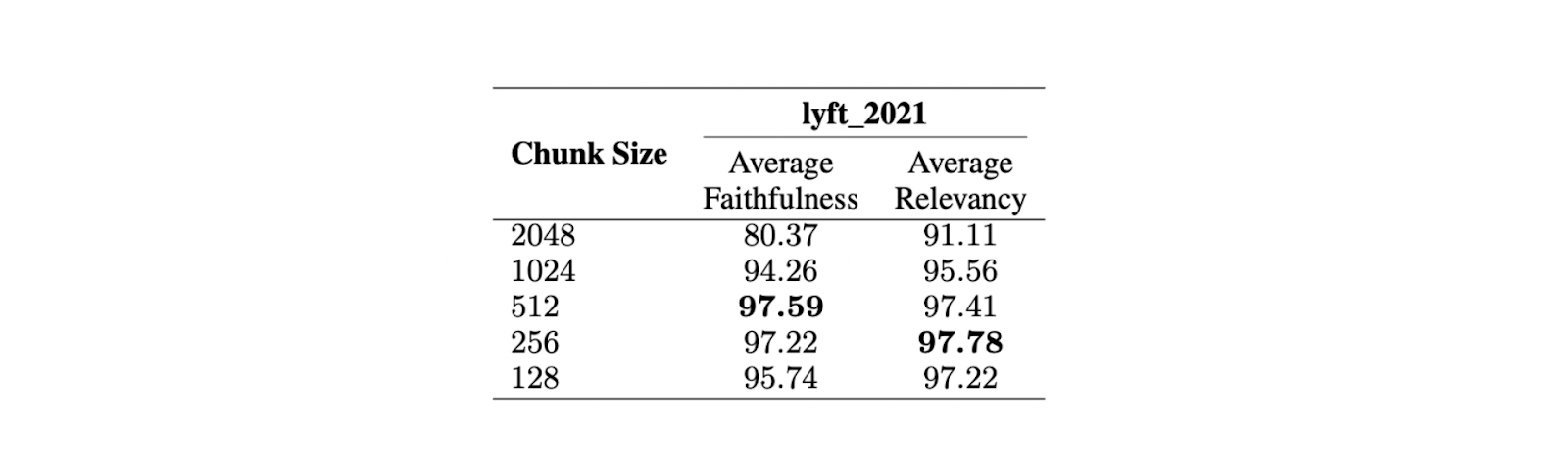 Figura- Confronto tra diverse dimensioni dei pezzi. .png
Figura- Confronto tra diverse dimensioni dei pezzi. .png
Figura: Confronto tra diverse dimensioni di chunk._ Fonte
I risultati mostrano che una dimensione massima di 512 token è preferibile per generare risposte altamente rilevanti dall'LLM. Anche dimensioni di chunk più brevi, come 256 token, hanno buone prestazioni e possono migliorare il tempo di esecuzione complessivo dell'applicazione RAG. Le tecniche avanzate di chunking, come small2big e sliding windows, possono essere utilizzate per combinare i vantaggi delle diverse dimensioni dei chunk.
Small2big è un approccio di chunking che organizza le relazioni tra i blocchi di chunk. I chunk di piccole dimensioni vengono usati per abbinare le query e i chunk più grandi, contenenti le informazioni di quelli più piccoli, vengono usati come contesto finale per l'LLM. La finestra scorrevole è un metodo di chunking che prevede sovrapposizioni di token tra i chunk per preservare le informazioni sul contesto.
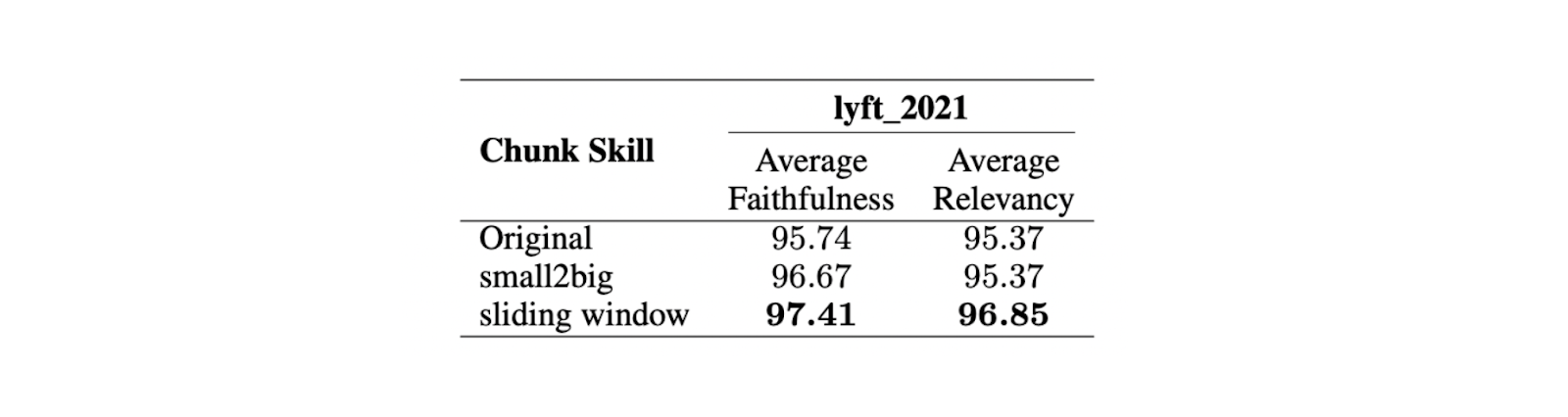 Figura - Confronto tra diverse tecniche di chunking..png
Figura - Confronto tra diverse tecniche di chunking..png
Figura: Confronto tra diverse tecniche di chunking._ Fonte
Gli esperimenti dimostrano che con una dimensione minore di 175 token, una maggiore di 512 token e una sovrapposizione di 20 token, entrambe le tecniche di chunking migliorano i punteggi di fedeltà e pertinenza delle risposte LLM.
Successivamente, è fondamentale trovare il miglior embedding model per rappresentare ogni chunk come un embedding vettoriale. A questo scopo è stato condotto un test su namespace-Pt/msmarco. I risultati mostrano che i modelli LLM Embedder e bge-large-en sono i migliori. Tuttavia, poiché LLM Embedder è tre volte più piccolo di bge-large-en, è stato scelto come embedding predefinito per l'esperimento.
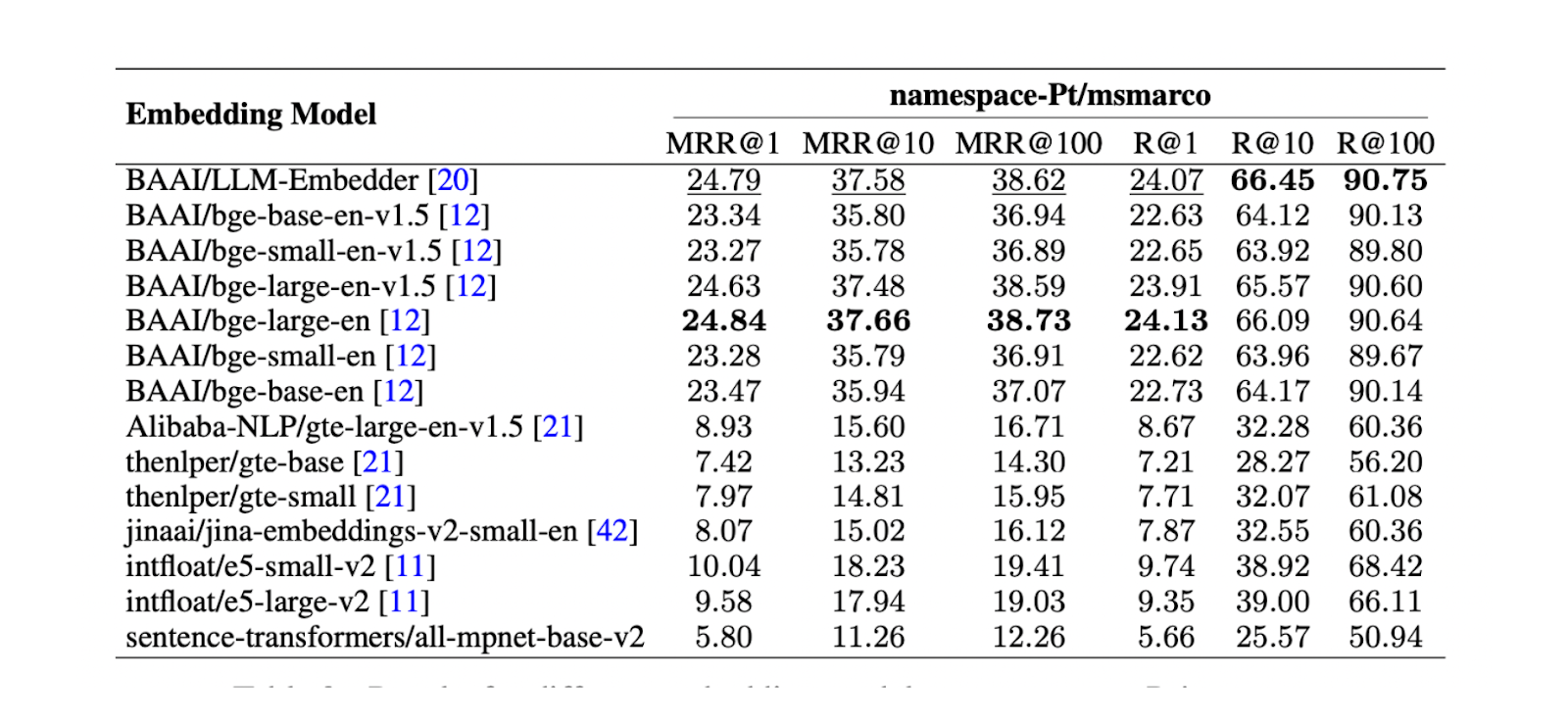 Figura - Risultati dei diversi modelli di incorporamento su namespace-Pt:msmarco. .png
Figura - Risultati dei diversi modelli di incorporamento su namespace-Pt:msmarco. .png
Figura: Risultati per diversi modelli di embedding su namespace-Pt:msmarco._ Source
Basi di dati vettoriali
I database vettoriali svolgono un ruolo cruciale nelle applicazioni RAG, in particolare per la memorizzazione e il recupero di contesti rilevanti. Nelle comuni applicazioni RAG del mondo reale, abbiamo a che fare con un'enorme quantità di documenti, il che porta a un vasto numero di incorporazioni di contesto che devono essere memorizzate. In questi casi, la memorizzazione di questi embeddings nella memoria locale è insufficiente e il recupero dei contesti rilevanti tra grandi collezioni di embeddings richiede molto tempo.
I database vettoriali sono stati progettati per risolvere questi problemi. Con un database vettoriale, possiamo memorizzare milioni o addirittura miliardi di embeddings vettoriali ed eseguire il recupero del contesto in una frazione di secondo. Nella scelta del miglior database vettoriale per il vostro caso d'uso, dobbiamo considerare diversi fattori, come il supporto del tipo di indice, il supporto di vettori su scala miliardaria, il supporto della ricerca ibrida e le capacità cloud-native.
Tra questi criteri, Milvus si distingue come il miglior database vettoriale open-source rispetto ai suoi concorrenti come Weaviate, Chroma, Faiss, Qdrant, ecc.
 Confronto tra vari database vettoriali..png
Confronto tra vari database vettoriali..png
Confronto tra vari database vettoriali. Fonte.
In termini di supporto del tipo di indice, Milvus offre diversi metodi di indicizzazione per soddisfare varie esigenze, come l'indice piatto ingenuo (FLAT) o altri tipi di indicizzazione progettati per accelerare il processo di recupero, come l'indice di file invertito (IVF-FLAT) e Hierarchical Navigable Small World (HNSW). Per comprimere la memoria necessaria a memorizzare i contesti, si può anche implementare product quantization (PQ) durante il processo di indicizzazione delle incorporazioni.
Milvus supporta anche un approccio di ricerca ibrida. Questo approccio ci permette di combinare due metodi diversi durante il processo di recupero del contesto. Ad esempio, possiamo combinare l'embedding denso con l'embedding sparse per recuperare contesti rilevanti, migliorando la pertinenza del contesto recuperato rispetto alla query. Questo, a sua volta, migliora anche la risposta generata dal LLM. Inoltre, possiamo combinare l'embedding denso con il filtraggio dei metadati, se lo desideriamo.
Se si desidera utilizzare Milvus nel cloud, su GCP o AWS, per memorizzare miliardi di embedding, si può optare per il suo servizio gestito: Zilliz Cloud.
Con Zilliz Cloud, è possibile creare unità cluster (CU) ottimizzate sia per la capacità che per le prestazioni per archiviare embeddings su larga scala. Ad esempio, è possibile creare 256 CU ottimizzati per le prestazioni che servono 1,3 miliardi di vettori 128-dimensionali o 128 CU ottimizzati per la capacità che servono 3 miliardi di vettori 128-dimensionali.
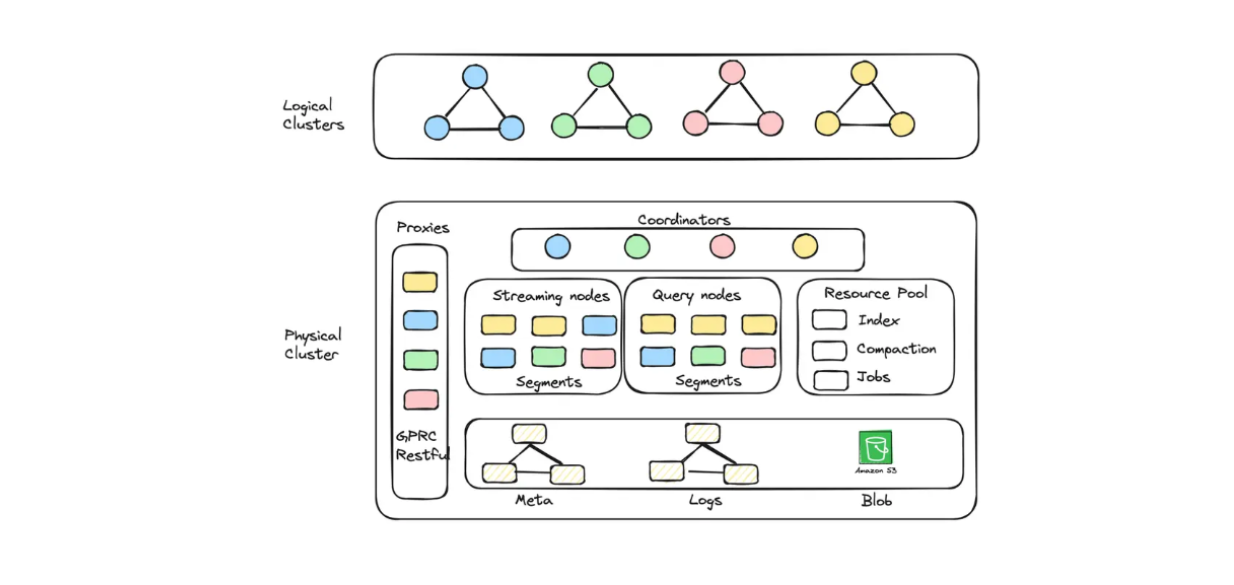 Diagramma del cluster logico e dell'autoscaling implementato in Zilliz Cloud Serverless..png
Diagramma del cluster logico e dell'autoscaling implementato in Zilliz Cloud Serverless..png
Diagramma del cluster logico e dell'autoscaling implementato in Zilliz Cloud Serverless.
Se desiderate costruire un'applicazione RAG con Milvus ma volete anche risparmiare sui costi operativi, potete optare per Zilliz Cloud Serverless. Questo servizio offre una funzione di autoscaling all'interno di Milvus, con costi che aumentano solo in base alla crescita dell'azienda. L'opzione serverless è perfetta anche per risparmiare sui costi, perché si paga solo quando si utilizza il servizio, non quando è inattivo.
Zilliz Cloud ha lanciato di recente numerosi ed entusiasmanti aggiornamenti, tra cui un nuovo servizio di migrazione, repliche multiple, una nuova integrazione con i connettori Fivetran, la funzionalità di auto-scaling e molte altre funzioni pronte per la produzione. Per maggiori dettagli, vedere di seguito:
Aggiornamento di Zilliz Cloud: servizi di migrazione, connettori Fivetran, repliche multiple e altro
I 5 motivi principali per migrare da Milvus Open Source a Zilliz Cloud
Tecniche di recupero
L'obiettivo principale della componente di recupero è recuperare i primi k contesti più rilevanti per una determinata query. Tuttavia, una sfida significativa in questa componente, che potrebbe influenzare la qualità complessiva del nostro RAG, deriva dalla query stessa. Le query originali sono spesso scritte o espresse male e mancano delle informazioni semantiche necessarie alle applicazioni RAG per recuperare i contesti rilevanti.
Diverse tecniche comunemente applicate per risolvere questo problema includono:
Riscrizione della query: Richiede al LLM di riscrivere la query originale per migliorarne la chiarezza e le informazioni semantiche.
Decomposizione della query**: decompone la query originale in sottoquery ed esegue il recupero in base a queste sottoquery.
Generazione di pseudo-documenti](https://zilliz.com/learn/improve-rag-and-information-retrieval-with-hyde-hypothetical-document-embeddings): Genera documenti ipotetici o sintetici basati sulla query originale e poi utilizza questi documenti ipotetici per recuperare documenti simili nel database. L'implementazione più nota di questo approccio è HyDE (Hypothetical Document Embeddings).
Gli esperimenti dimostrano che la combinazione di HyDE e della ricerca ibrida produce i migliori risultati nel TREC DL19/20 rispetto alla riscrittura delle query e alla decomposizione delle query. La ricerca ibrida menzionata nell'esperimento combina LLM Embedder per ottenere embeddings densi e BM25 per ottenere sparse embeddings.
Il flusso di lavoro di HyDe + ricerca ibrida è il seguente: per prima cosa, si genera un documento ipotetico che risponde alla query con HyDE. Successivamente, questo documento ipotetico viene concatenato con la query originale prima di essere trasformato in dense e sparse embeddings utilizzando rispettivamente LLM Embedder e BM25.
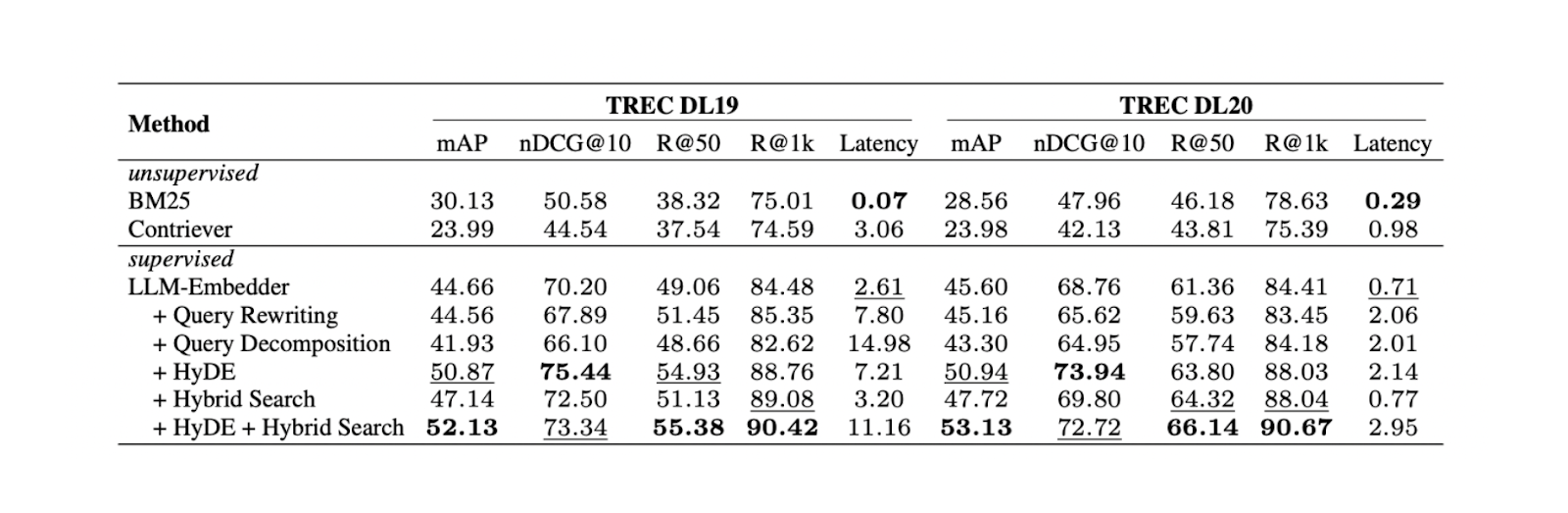 Risultati per diversi metodi di reperimento. .png
Risultati per diversi metodi di reperimento. .png
Risultati per diversi metodi di reperimento. Fonte
Sebbene la combinazione di HyDE e ricerca ibrida dia i migliori risultati, comporta anche costi computazionali più elevati. Sulla base di ulteriori test su diversi set di dati NLP, sia la ricerca ibrida che l'utilizzo di soli embeddings densi danno risultati comparabili a HyDE + ricerca ibrida, ma con una latenza quasi 10 volte inferiore. Pertanto, l'uso di una ricerca ibrida sarebbe più raccomandabile.
Poiché utilizziamo una ricerca ibrida, i contesti recuperati sono basati sulla ricerca vettoriale da embeddings densi e radi. Pertanto, è interessante esaminare anche l'impatto del valore di ponderazione tra embeddings densi e sparsi sul punteggio di rilevanza complessivo secondo questa equazione:
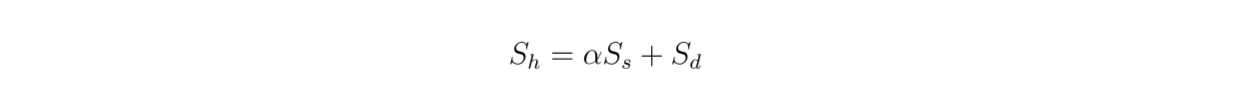 formula.png
formula.png
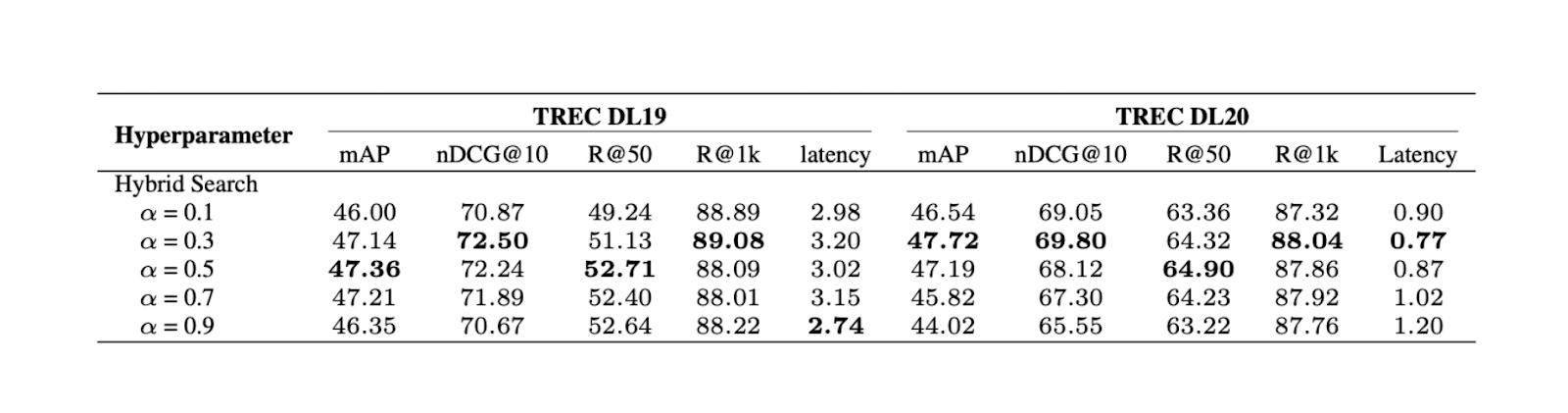 Figura - Risultati della ricerca ibrida con diversi valori alfa..png
Figura - Risultati della ricerca ibrida con diversi valori alfa..png
Figura: Risultati della ricerca ibrida con diversi valori alfa. Source._
L'esperimento mostra che un valore di ponderazione pari a 0,3 produce il miglior punteggio di rilevanza complessivo su TREC DL19/20.
Tecniche di reranking e repacking
L'obiettivo principale delle tecniche di reranking è quello di riordinare i primi k contesti più rilevanti recuperati dal metodo di reperimento per garantire che il contesto più simile venga restituito in cima alla lista. Esistono due approcci comuni per riordinare i contesti:
DLM Reranking: Questo metodo utilizza un modello di apprendimento profondo per il reranking. Il modello viene addestrato con una coppia composta dalla query originale e da un contesto come input e un'etichetta binaria "vero" (se la coppia è rilevante l'una per l'altra) o "falso" come output. I contesti vengono quindi ordinati in base alla probabilità che il modello restituisce quando predice una coppia di query e contesto come "vera".
TILDE Reranking: Questo approccio utilizza la probabilità di ogni termine della query originale per effettuare il reranking. Durante il tempo di inferenza, possiamo usare la componente di verosimiglianza della query (TILDE-QL) da sola per un reranking più veloce o la combinazione di TILDE-QL con la componente di verosimiglianza del documento (TILDE-DL) per migliorare il risultato del reranking a un costo computazionale più elevato.
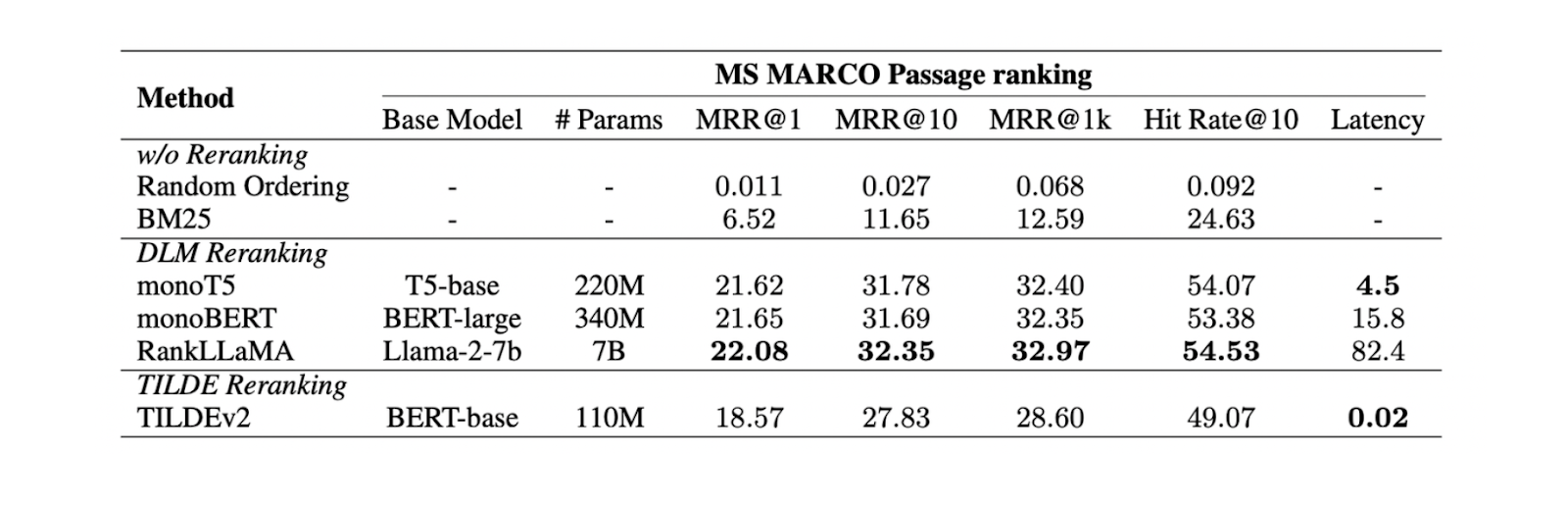 Figura- Risultati dei diversi metodi di reranking..png
Figura- Risultati dei diversi metodi di reranking..png
Figura: Risultati di diversi metodi di reranking._ Fonte
Gli esperimenti condotti sul dataset MS MARCO Passage ranking mostrano che il metodo di reranking DLM con il modello Llama 27B offre le migliori prestazioni di reranking. Tuttavia, trattandosi di un modello di grandi dimensioni, il suo utilizzo comporta un costo computazionale significativo. Pertanto, l'uso di mono T5 è più consigliato per il reranking DLM, in quanto fornisce un equilibrio tra prestazioni ed efficienza computazionale.
Dopo la fase di reranking, dobbiamo anche considerare come presentare i contesti reranked al nostro LLM: se in ordine discendente ("forward") o ascendente ("reverse"). Sulla base degli esperimenti condotti in questo lavoro, si può concludere che la migliore qualità di risposta viene generata utilizzando la configurazione "inversa". L'ipotesi è che il posizionamento di un contesto più rilevante vicino alla query porti a risultati ottimali.
Tecniche di riassunto
Nei casi in cui abbiamo contesti lunghi recuperati da componenti precedenti, potremmo volerli rendere più compatti e rimuovere le informazioni ridondanti. Per raggiungere questo obiettivo, in genere vengono implementati approcci di riassunto.
Esistono due diverse tecniche di riassunto dei contesti: estrattive e astraenti.
La sintesi estrattiva divide il documento di input in segmenti più piccoli, poi classificati in base all'importanza. Nel frattempo, il metodo astraente genera un nuovo riassunto del contesto che contiene solo le informazioni rilevanti.
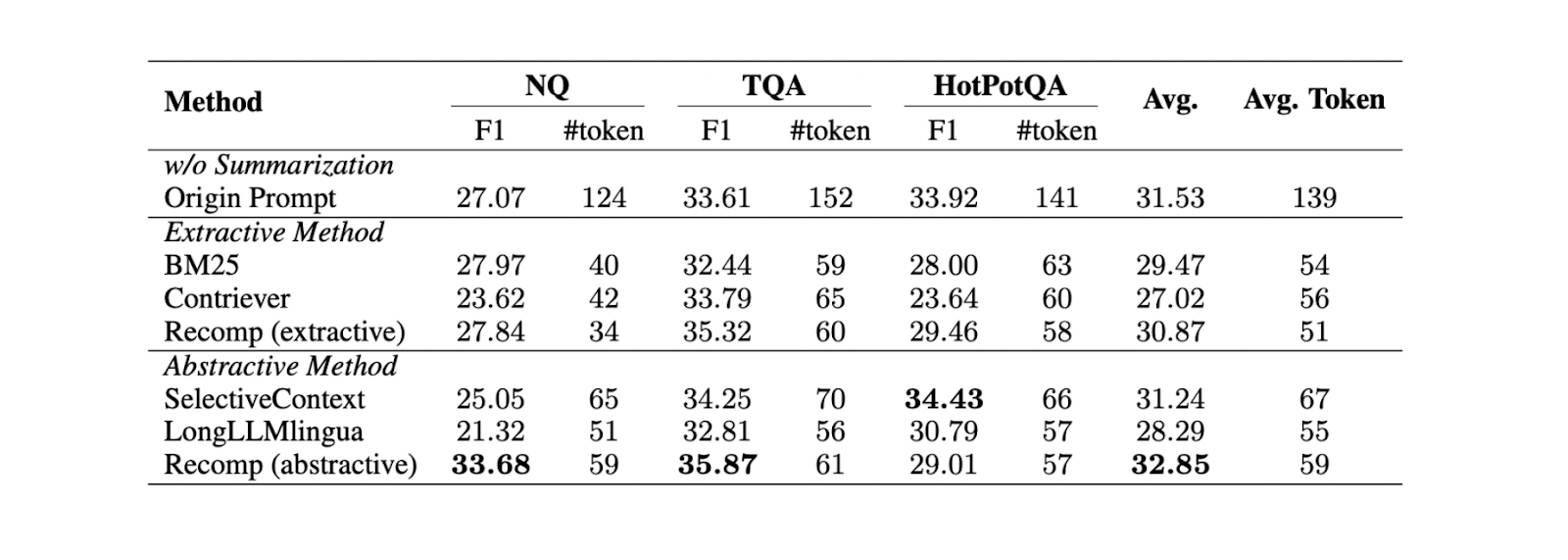 Figura- Confronto tra diversi metodi di riassunto..png
Figura- Confronto tra diversi metodi di riassunto..png
Figura: Confronto tra diversi metodi di sintesi._ Fonte
Sulla base di esperimenti condotti su tre diversi set di dati (NQ, TriviaQA e HotpotQA), la sintesi astraente con Recomp offre le migliori prestazioni rispetto ad altri metodi astraenti ed estrattivi.
La sintesi delle migliori tecniche di RAG
Ora che conosciamo l'approccio migliore per ogni componente RAG per specifici set di dati di riferimento, possiamo testare ulteriormente tutti gli approcci menzionati nelle sezioni precedenti su altri set di dati. I risultati mostrano che ogni componente contribuisce alle prestazioni complessive della nostra applicazione RAG. Di seguito è riportato un riepilogo dei risultati di ciascun approccio per ogni componente, basato su cinque diversi set di dati:
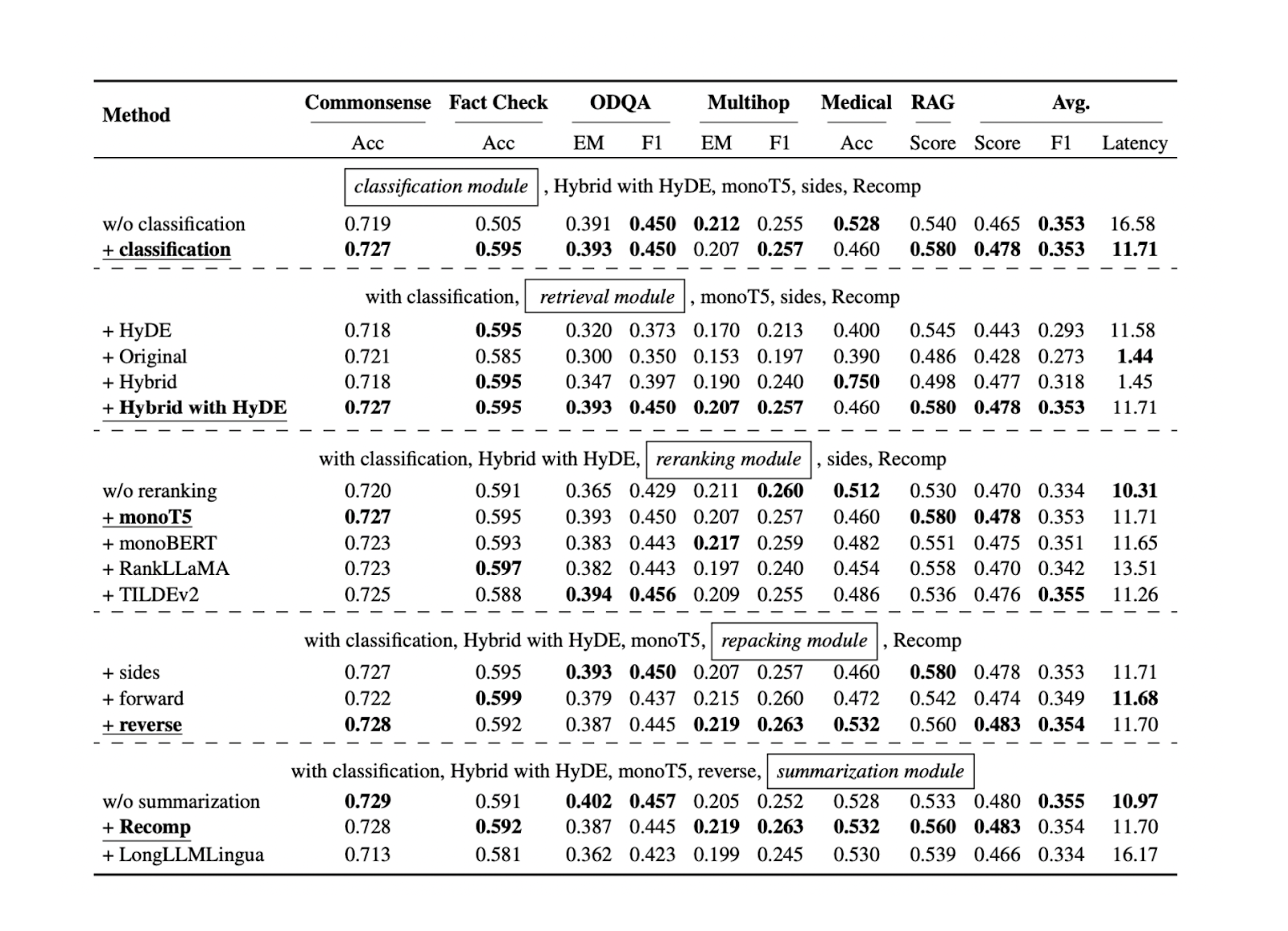 Figura- Risultati della ricerca di pratiche ottimali di RAG..png
Figura- Risultati della ricerca di pratiche ottimali di RAG..png
Figura: Risultati della ricerca di pratiche RAG ottimali._ Fonte
La componente di classificazione delle query si rivela utile per migliorare l'accuratezza delle risposte e ridurre la latenza complessiva del runtime. Questa fase iniziale aiuta a determinare se una query richiede il recupero del contesto o può essere elaborata direttamente dal LLM, ottimizzando così l'efficienza del sistema.
La componente di recupero è fondamentale per garantire l'ottenimento di candidati contestuali rilevanti rispetto alla query. Per questa componente, si raccomanda un database vettoriale scalabile e performante come Milvus o il suo servizio gestito, Zilliz Cloud. Inoltre, si raccomanda una ricerca ibrida o una ricerca densa di incorporazioni. Questi metodi raggiungono un equilibrio tra una corrispondenza completa del contesto e l'efficienza computazionale.
La componente di reranking garantisce l'ottenimento dei contesti più rilevanti riordinando i primi k contesti recuperati dalla componente di retrieval. Il modello monoT5 è consigliato per il reranking grazie al suo equilibrio tra prestazioni e costi computazionali. Questa fase affina la selezione dei contesti, dando priorità a quelli più rilevanti per l'interrogazione.
Per il repacking dei contesti si consiglia il metodo inverso. Questo approccio posiziona il contesto più rilevante più vicino alla query, portando potenzialmente a risposte più accurate e coerenti da parte del LLM.
Infine, il metodo astraente con Recomp ha mostrato le migliori prestazioni per la sintesi del contesto. Questa tecnica aiuta a condensare i contesti lunghi preservando le informazioni chiave, facilitando l'elaborazione e la generazione di risposte pertinenti da parte del LLM.
Messa a punto del LLM
Nella maggior parte dei casi, la regolazione fine dell'LLM non è necessaria, soprattutto se si utilizza un LLM performante con molti parametri. Tuttavia, se si hanno vincoli hardware e si possono usare solo LLM più piccoli, potrebbe essere necessario metterli a punto per renderli più robusti quando si generano risposte relative al caso d'uso. Prima di mettere a punto un LLM, è necessario considerare i dati da usare come dati di addestramento.
Durante la preparazione dei dati, è possibile raccogliere i dati di addestramento in prompt e contesto come coppia di input, con un esempio di testo generato come output. Gli esperimenti dimostrano che, durante l'addestramento, l'aumento dei dati con un mix di contesti pertinenti e selezionati a caso garantisce le migliori prestazioni. L'intuizione alla base di questa scelta è che mescolare contesti pertinenti e casuali durante la messa a punto può migliorare la robustezza del nostro LLM.
Conclusione
In questo articolo abbiamo esplorato vari componenti della RAG, dalla classificazione delle query alla sintesi dei contesti. Abbiamo discusso ed evidenziato gli approcci con prestazioni ottimali in ogni componente.
Questi componenti ottimizzati lavorano insieme per migliorare le prestazioni complessive del sistema RAG. Migliorano la qualità e la pertinenza delle risposte generate, mantenendo al contempo l'efficienza computazionale. Implementando queste best practice in ogni componente, possiamo creare un sistema RAG più robusto ed efficace, in grado di gestire un'ampia gamma di interrogazioni e compiti.
Ulteriori letture
Continua a leggere

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.