




From Words to Vectors: Understanding Word2Vec in Natural Language Processing (NLP)
From Words to Vectors: Understanding Word2Vec in Natural Language Processing (NLP)
What is Word2Vec?
Word2Vec is a machine learning model that converts words into numerical vector representations to capture their meanings based on the context in which they appear. Developed by Tomas Mikolov and his team at Google, it uses large text datasets to understand relationships between words to represent semantic and syntactic similarities. Unlike traditional approaches like one-hot encoding, Word2Vec creates dense, meaningful embeddings where similar words are positioned closer in a continuous vector space. Word2Vec is widely used in Natural Language Processing applications like sentiment analysis and recommendation systems.
Why Do We Need Word2Vec?
Understanding the relationships and meanings of words is a core challenge in Natural Language Processing (NLP). Traditional methods, like one-hot encoding, represent words as sparse, high-dimensional vectors where each word is independent of others. This approach fails to capture the semantic or syntactic relationships between words. For instance, in one-hot encoding, the vectors for “king” and “queen” would appear completely unrelated, even though their meanings are closely connected.
Additionally, these sparse representations are computationally inefficient, especially for large vocabularies, and don’t generalize well to unseen words or contexts. This limitation has made it difficult for machines to truly understand language, hampering progress in tasks like machine translation, sentiment analysis, and search ranking.
Word2Vec solves these challenges by creating compact, dense word embeddings that represent relationships between words based on how they appear in the text. By capturing both the meaning of words and their context, Word2Vec has transformed how machines interpret and process human language, making it more efficient and meaningful.
How Word2Vec Works?
At the heart of Word2Vec are word embeddings, which are low dimensional dense vectors that capture the semantic and syntactic properties of words. Word2Vec operates by analyzing large volumes of text to learn the relationships between words. At its core, it is a shallow neural network that generates vector representations for words, capturing their semantic and syntactic meanings. The model identifies patterns in the way words co-occur in sentences and uses this information to position related words closer together in a continuous vector space.
The main concept is that similar vectors represent words with similar meanings or contexts of use. For instance, the words “king” and “queen” will have closely related vectors, with differences that encode specific semantic distinctions, like gender.
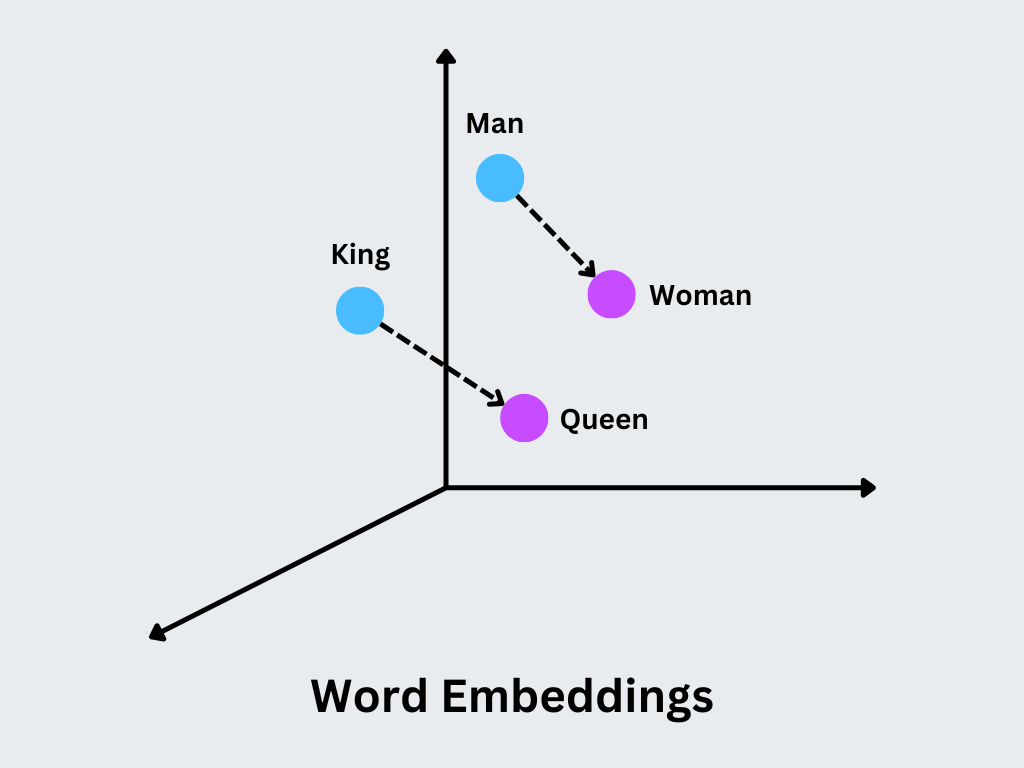 Figure- Word Embeddings.png
Figure- Word Embeddings.png
Figure: Word Embeddings
Word2Vec offers two approaches to generate embeddings, depending on how the context is handled:
Continuous Bag of Words (CBOW)
Continuous bag of words focuses on predicting a target word based on its surrounding words. For example, in the sentence “Apples are sweet and juicy,” CBOW uses the context words (“Apples,” “are,” “and,” and “juicy”) to predict the target word, such as “sweet.”
CBOW is computationally efficient because it averages the context words to predict the target. However, it performs better with frequent words and may struggle with rare terms.
Use Case: CBOW is commonly used in applications like autocomplete and spell check, where predicting a missing or next word is required.
Skip-Gram Model
Skip-Gram reverses the prediction process. Instead of predicting a target word from its context, it predicts the context words based on a target word. For instance, if the target word is “sweet,” Skip-Gram predicts the context words “Apples,” “are,” “and,” and “juicy.”
Skip-Gram is better at handling rare words and is especially effective at capturing more nuanced relationships when working with large datasets.
Use Case: Skip-Gram is valuable in tasks like building recommendation systems or clustering similar terms in specialized fields.
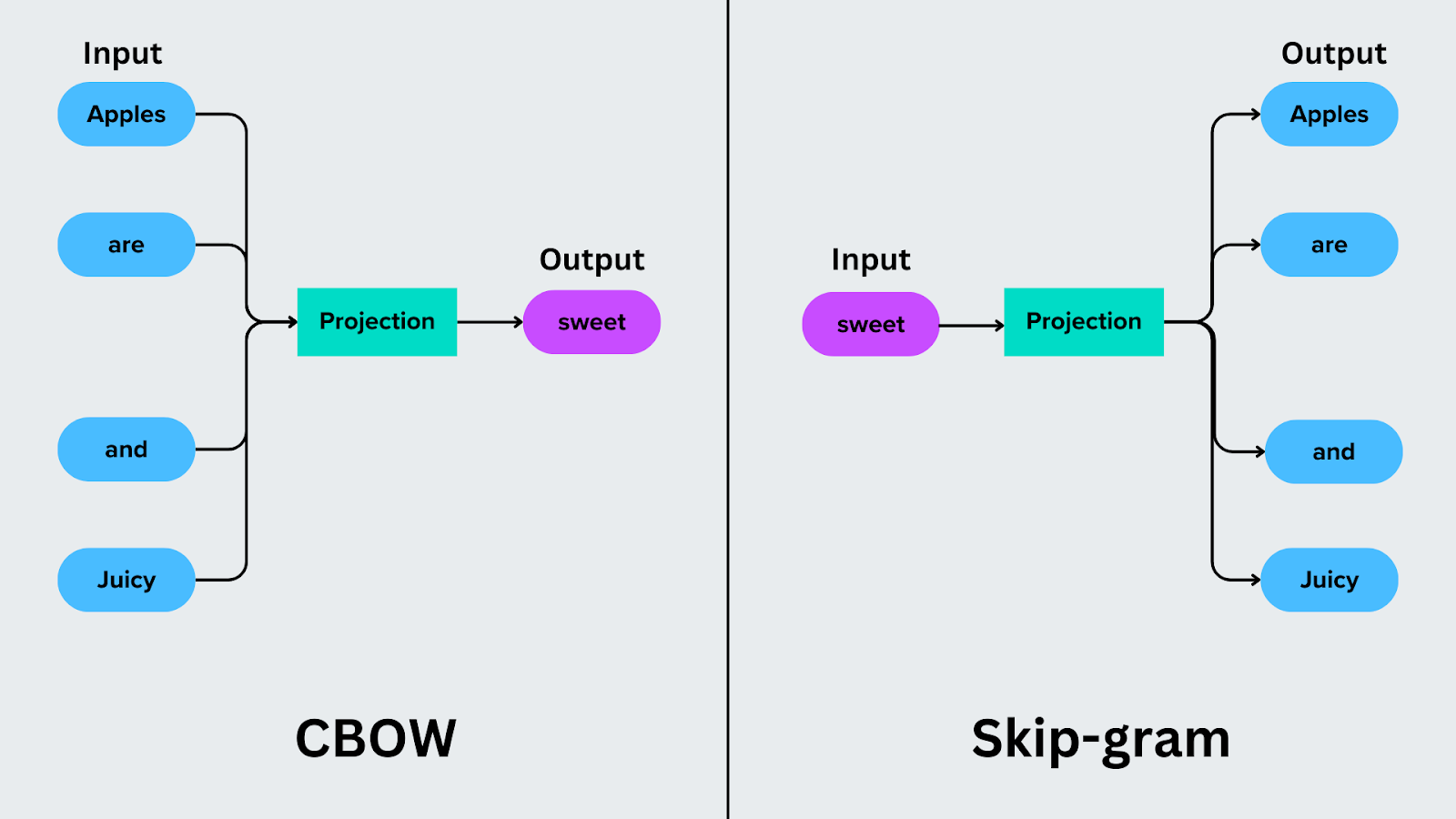 Figure- CBOW vs Skip-gram.png
Figure- CBOW vs Skip-gram.png
Figure: CBOW vs Skip-gram
Difference Between CBOW and Skip-Gram Model
While both CBOW and Skip-Gram aim to represent words in a meaningful way, they differ in how they process and predict words based on context. Below is a comparison to highlight the key differences between these two approaches:
| Feature | Continuous Bag of Words (CBOW) | Skip-Gram |
|---|---|---|
| Objective | Determines the target word using the surrounding context. | Predicts context words based on the target word. |
| Efficiency | Faster to train. | Slower to train. |
| Focus | Works well with frequent words. | Handles rare words effectively. |
| Complexity | Simpler and computationally efficient. | More complex and computationally intensive. |
| Use Case | Suitable for tasks like word prediction and autocorrect. | Ideal for specialized tasks like recommendation systems. |
| Context Window | Consider the average of all context words. | Evaluate individual context words separately. |
| Dataset Size Requirement | Performs well on smaller datasets. | Performs better with large datasets. |
| Example | Predicts "barking" from "The dog is ___". | Predicts "The," "dog," and "is" from "barking." |
Table: CBOW vs Skip-Gram
Word2Vec Implementation in Python
Below is the Python implementation of Word2Vec using the CBOW and Skip-Gram methods. This code trains on a small custom dataset to learn word embeddings, demonstrating how both methods work to capture relationships between words based on their context. Both sections of the code are designed to compare how CBOW and Skip-Gram learn relationships between words differently, but they share the same parameters for fair comparison. You can find the implementation below in this Kaggle notebook.
Code
from gensim.models import Word2Vec
# Small, focused corpus
corpus = [
["cat", "dog", "barked"],
["dog", "chased", "cat"],
["cat", "sat", "mat"],
["dog", "ran", "fast"],
["cat", "ran", "fast"],
["dog", "sat", "mat"]
]
# Train a CBOW model
cbow_model = Word2Vec(
sentences=corpus,
vector_size=10, # Smaller vector size for simplicity
window=2, # Context window size
min_count=1, # Include all words
sg=0 # Set sg=0 for CBOW
)
# Train a Skip-Gram model
skipgram_model = Word2Vec(
sentences=corpus,
vector_size=10, # Smaller vector size for simplicity
window=2, # Context window size
min_count=1, # Include all words
sg=1 # Set sg=1 for Skip-Gram
)
# Function to display word vectors and similar words
def display_model_results(model, model_name):
print(f"\n--- {model_name} ---")
for word in ["cat", "dog"]:
print(f"Word Vector for '{word}': {model.wv[word][:5]}...") # Display first 5 values of the vector
similar_words = model.wv.most_similar(word, topn=3)
print(f"Most similar to '{word}': {[(w, round(sim, 2)) for w, sim in similar_words]}")
# Display CBOW model results
display_model_results(cbow_model, "CBOW Model")
# Display Skip-Gram model results
display_model_results(skipgram_model, "Skip-Gram Model")
Output:
--- CBOW Model ---
Word Vector for 'cat': [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... Most similar to 'cat': [('dog', 0.54), ('fast', 0.33), ('barked', 0.23)] Word Vector for 'dog': [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... Most similar to 'dog': [('cat', 0.54), ('fast', 0.3), ('ran', 0.1)]
--- Skip-Gram Model ---
Word Vector for 'cat': [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... Most similar to 'cat': [('dog', 0.54), ('fast', 0.33), ('barked', 0.23)] Word Vector for 'dog': [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... Most similar to 'dog': [('cat', 0.54), ('fast', 0.3), ('ran', 0.1)]
In the CBOW part of the code:
The model is trained using the parameter sg=0, which tells Word2Vec to use the Continuous Bag of Words method.
CBOW determines a word using the context of the words around it. For example, in the sentence ["dog", "chased", "cat"], the model might use "dog" and "cat" to predict "chased."
The vector_size=10 defines the size of the word embeddings (how many numbers represent each word).
The window=2 specifies the context window, meaning it considers up to 2 words before and after the target word.
In the Skip-Gram part of the code:
The model is trained using the parameter sg=1, which switches Word2Vec to the Skip-Gram method.
Skip-Gram identifies surrounding words using a given target word. For example, if the target word is "chased," the model predicts "dog" and "cat" as its neighbors.
Similar to CBOW:
vector_size=10 defines the size of the word embeddings.
window=2 sets the range of context words to consider.
Benefits of Word2Vec
Below are some key benefits that make Word2Vec a foundational technique in NLP:
Captures Semantic Relationships: Word2Vec creates embeddings where semantically similar words (e.g., “king” and “queen”) are positioned close to each other in the vector space to analyze and use these relationships in NLP tasks.
Contextual Understanding: By analyzing the co-occurrence of words in large corpora, Word2Vec captures context-dependent relationships, allowing models to better understand the meaning of words in specific contexts.
Efficient Representation: Word embeddings are dense and low-dimensional compared to sparse representations like one-hot encoding, making them an efficient technique in terms of memory and computational costs.
Handles Large Vocabularies: Unlike older techniques, Word2Vec scales effectively to large datasets and vocabularies, making it practical for real-world applications.
Supports Transfer Learning: Pre-trained Word2Vec embeddings can be reused across multiple tasks, saving time and computational resources while improving results.
Arithmetic on Words: Word2Vec supports meaningful vector arithmetic for analogies like “king - man + woman = queen” to be computed directly using embeddings.
Use Cases of Word2Vec
Word2Vec has a wide range of applications for NLP tasks. Below are some of its practical and impactful use cases:
Machine Translation: Improves the mapping of words between languages by using embeddings to align words with similar meanings to enhance translation accuracy.
Sentiment Analysis: Identifies the tone of text by analyzing word relationships and context to classify positive, negative, or neutral sentiments.
Search Ranking: Enhances search engines by understanding the similarity between search queries and indexed content, leading to more relevant results.
Product Recommendations: Matches user preferences with products or services by analyzing textual descriptions and finding similar items.
Topic Modeling: Organizes and analyzes large text datasets by Grouping documents into clusters based on the similarity of word embeddings.
Text Autocompletion: Suggests relevant words or phrases by predicting contextually similar words, improving the user experience in typing or coding tools.
Chatbots: Enables a better understanding of user input and context, helping chatbots generate accurate and relevant responses.
Limitations of Word2Vec
Despite its benefits, Word2Vec comes up with its limitations:
Lack of Context Awareness: Word2Vec generates a single embedding for each word, regardless of its context. For example, the word “bank” will have the same vector representation, whether it refers to a riverbank or a financial institution.
Data Dependency: Effective training requires large, high-quality text datasets. Poorly curated or small datasets can lead to suboptimal embeddings.
Handling Rare Words: Struggles with infrequent words or out-of-vocabulary terms, as these may not appear enough in the training data to generate meaningful embeddings.
No Sentence-Level Representation: Word2Vec focuses on word-level embeddings and does not provide representations for entire sentences or documents, limiting its scope to specific NLP tasks.
Ignores Word Order: The model considers words within a context window but does not consider their sequence, which can affect understanding of grammar or sentence structure.
Outdated Compared to Modern Models: Word2Vec has mainly been superseded by advanced models like BERT, GLoVE, and GPT, which provide contextual and more robust embeddings.
Bridging the Gap: From Word2Vec to GloVe, BERT, and GPT
Predictive models like Word2Vec create word embeddings by focusing on local context through neural networks. However, their reliance on nearby word pairs introduces a limitation: They fail to capture broader, global relationships across an entire text corpus. For instance, while Word2Vec excels at identifying word associations nearby, it often misses more extensive semantic connections.
To address this, GloVe (Global Vectors for Word Representation) uses global co-occurrence statistics to create word embeddings. It analyzes how often words appear together across the entire corpus to capture both local context and broader semantic relationships for a more complete representation of language.
More recently, models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) have gone beyond static embeddings. BERT introduced contextual embeddings, representing words differently based on their usage in a sentence, while GPT focused on generating coherent text by understanding sequential context. These models further transformed NLP by incorporating dynamic, context-aware representations, addressing the limitations of earlier methods like Word2Vec and GloVe.
Word2Vec with Milvus: Efficient Vector Search for NLP Applications
Word2Vec provides a way to create word embeddings that are essential for tasks like semantic search, document similarity, and recommendation systems, where understanding word relationships is critical. However, managing and querying extensive collections of embeddings efficiently can be a challenge.
This is where Milvus, the open-source vector database developed by Zilliz, comes in. Milvus provides a robust solution for storing, indexing, and querying Word2Vec embeddings or any other type of embeddings at scale for seamless integration into NLP workflows. Here’s how Word2Vec and Milvus work together:
Efficient Management of Word Embeddings: Word2Vec generates high-dimensional embeddings for vocabulary words, which can grow significantly in size with larger datasets. Milvus efficiently handles these embeddings by:
Scalable Storage: Storing millions of word embeddings without performance degradation.
Fast Retrieval: Optimized algorithms ensure rapid search for similar embeddings, which are crucial for real-time NLP applications like recommendation systems or chatbots.
Enhanced Semantic Search: Word2Vec embeddings excel at capturing word relationships. When combined with Milvus, these embeddings can power advanced semantic search. For instance:
Searching for synonyms or related terms (e.g., querying for "king" retrieves embeddings like "queen" or "prince").
Implementing robust search systems like Retrieval Augmented Generation (RAG) that rely on word similarity for better results.
Streamlined NLP Workflows: Milvus simplifies NLP workflows involving Word2Vec by:
Allowing pre-trained Word2Vec embeddings to be stored and queried efficiently.
Supporting integration with machine learning frameworks for clustering, document similarity, and real-time search.
Conclusion
Word2Vec transformed how we work with language data by introducing word embeddings that capture the meanings and relationships of words. It solved many challenges of traditional methods, such as the inability to capture semantic and syntactic similarities. It is used in applications like sentiment analysis, translation, and recommendation systems. Despite its limitations, Word2Vec has laid the foundation for many advancements in the field and influenced the development of more sophisticated models like GLoVE, BERT, and GPT.
FAQs on Word2Vec
- What is Word2Vec, and why is it important?
Word2Vec is a machine learning model that creates dense vector representations of words, called word embeddings, based on their context. It’s important because it captures the relationships and meanings of words for NLP tasks like sentiment analysis, translation, and search.
- How does Word2Vec differ from traditional word representation methods?
Unlike traditional methods like one-hot encoding, which represent words as sparse vectors with no inherent relationships, Word2Vec creates dense embeddings that capture semantic and syntactic similarities between words, making it much more efficient and meaningful.
- What are the main architectures used in Word2Vec?
Word2Vec has two main architectures: Continuous Bag of Words (CBOW) and Skip-Gram. CBOW determines a target word from its surrounding context, while Skip-Gram identifies context words using a given target word. Each has its strengths depending on the use case and dataset.
- What are the primary use cases for Word2Vec?
Word2Vec is used in applications like sentiment analysis, machine translation, recommendation systems, search ranking, topic modeling, and chatbot development. Its ability to understand word relationships makes it versatile across various NLP tasks.
- What are the limitations of Word2Vec?
Word2Vec has several limitations, including its lack of context awareness (e.g., it doesn’t differentiate between different meanings of the same word), reliance on large datasets for training, and inability to capture word order or sentence-level meaning. These drawbacks have led to the development of more advanced models like GloVe, BERT, and GPT.
Related Resources
- What is Word2Vec?
- Why Do We Need Word2Vec?
- How Word2Vec Works?
- Word2Vec Implementation in Python
- Benefits of Word2Vec
- Use Cases of Word2Vec
- Limitations of Word2Vec
- Bridging the Gap: From Word2Vec to GloVe, BERT, and GPT
- Word2Vec with Milvus: Efficient Vector Search for NLP Applications
- Conclusion
- FAQs on Word2Vec
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free