




Ein umfassender Leitfaden zu ANN-Benchmarks: Bewertung der Leistung der Approximate Nearest Neighbor Search (ANNS)

Ein umfassender Leitfaden zu ANN-Benchmarks: Bewertung der Leistung der Approximate Nearest Neighbor Search (ANNS)
Stellen Sie sich vor, Sie bauen eine Suchmaschine, die schnell die ähnlichsten Elemente aus einer Datenbank mit Milliarden von Bildern, Textdokumenten oder anderen unstrukturierten Daten finden muss. Wie stellen Sie sicher, dass Ihr Suchalgorithmus nicht nur genaue Ergebnisse liefert, sondern dies auch blitzschnell tut? Hier kommt die Approximate Nearest Neighbor (ANN)-Suche ins Spiel. Die ANN-Suche ist in vielen realen Anwendungen entscheidend, von Empfehlungssystemen bis hin zur groß angelegten Bildsuche.
Bei so vielen auf dem Markt verfügbaren ANN-Suchlösungen: Wie bewerten wir die Effektivität verschiedener ANN-Algorithmen, insbesondere im großen Maßstab? Hier kommen die ANN-Benchmarks ins Spiel, die zum Goldstandard für das Testen der Leistung von ANN-Suchmethoden auf großen Datensätzen geworden sind.
In diesem Blog befassen wir uns mit ANN-Benchmarks, warum sie wichtig sind und wie sie Entwicklern und Algorithmus-Ingenieuren helfen, die richtigen Vektorsuche-Lösungen für die jeweilige Aufgabe auszuwählen. Außerdem sehen wir uns einige der heute beliebtesten Benchmarks an und was sie in der Vektorsuche unverzichtbar macht.
Was ist ANN Search und wie funktioniert sie?
Bevor wir in Benchmarks eintauchen, ist es wichtig, die Approximate Nearest Neighbor (ANN) Search, oder ANNS, zu verstehen und wie sie funktioniert. ANN Search ist eine leistungsstarke Technik im Machine Learning (ML), die eine effiziente Suche nach semantischer Ähnlichkeit in großen Datensätzen ermöglicht, wie sie häufig in Vektordatenbanken wie Zilliz Cloud zu finden sind. Sie kann schnell die Elemente finden, die einem bestimmten Abfrageelement in einem Datensatz am nächsten liegen. Im Gegensatz zu exakten Suchmethoden, die 100 % Genauigkeit sicherstellen, tauscht ANNS einen kleinen Teil der Genauigkeit gegen erhebliche Verbesserungen bei Geschwindigkeit und Skalierbarkeit ein.
Wie ANN Search funktioniert:
Datenrepräsentation: Jedes Element im Datensatz wird als Vektor in einem multidimensionalen Raum dargestellt. Vektoren werden in der Regel von einem Embedding-Modell codiert, wie etwa OpenAI text embedding models, Cohere multilingual models und OpenAI multimodal models. Beispielsweise könnte ein Bild als Vektor von Merkmalen wie Farbe oder Form in einem 128-dimensionalen Raum dargestellt werden.
Abfrageverarbeitung: Wenn eine Abfrage gestellt wird, durchsucht der ANN-Search-Algorithmus den Datensatz nach Vektoren, die nahe am Abfragevektor liegen, und verwendet dabei Approximationen, um den Prozess zu beschleunigen.
Ergebnisranking: Der Algorithmus ordnet die nächsten Nachbarn basierend auf ihrer Entfernung zur Abfrage im hochdimensionalen Raum, häufig unter Verwendung von Metriken wie euklidischer Distanz oder Kosinusähnlichkeit. Je näher die Vektoren beieinander liegen, desto ähnlicher und relevanter sind sie.
Effizienz: Der entscheidende Vorteil von ANN Search ist ihre Fähigkeit, Ergebnisse in einem Bruchteil der Zeit zu liefern, die eine exakte Suche benötigen würde, wodurch sie ideal für groß angelegte Datensätze ist.
ANNS-Methoden verwenden verschiedene Strategien, um die nächsten Nachbarn schnell zu approximieren:
Baumbasierte Methoden: Techniken wie KD-Trees und Ball Trees organisieren Daten hierarchisch, um den Suchprozess zu vereinfachen. Während sie in niedrigeren Dimensionen effektiv sind, nimmt ihre Leistung mit zunehmender Dimensionalität ab.
Hashing-Methoden: Locality-sensitive hashing (LSH) gruppiert ähnliche Datenpunkte in dieselben Hash-Buckets und reduziert so die Anzahl der während der Suche erforderlichen Vergleiche.
Graphbasierte Methoden: Algorithmen wie Navigable Small World (NSW)-Graphen und Hierarchical Navigable Small World (HNSW)-Graphen erstellen Netzwerke von Datenpunkten, um Nachbarschaftsabfragen zu beschleunigen.
Quantisierungsmethoden: Techniken wie Product Quantization (PQ) komprimieren die Daten in eine besser handhabbare Form und verbessern so die Sucheffizienz.
Durch die Nutzung dieser Methoden können ANNS-Algorithmen ein Gleichgewicht zwischen Suchgenauigkeit und Leistung herstellen, wodurch sie sich für groß angelegte Datensätze eignen.
ANN-Suche vs. KNN-Suche
Exakte K-nearest neighbor-Suche (KNN) und Approximate Nearest Neighbor Search (ANNS) sind zwei grundlegende Ansätze, die in der Vektorsuche verwendet werden, jeweils mit eigenen Vorteilen und Kompromissen.
Exaktes KNN liefert präzise Ergebnisse, indem die Distanz zwischen dem Abfragepunkt und jedem Datenpunkt im Datensatz bewertet wird, wodurch sichergestellt wird, dass die identifizierten Nachbarn die nächstmöglichen sind. Diese Methode kann jedoch aufgrund ihrer Brute-Force-Natur rechenintensiv und langsam sein, insbesondere bei großen Datensätzen oder hochdimensionalen Räumen. Dadurch eignet sich exaktes KNN für kleinere Datensätze oder Szenarien, in denen Präzision von größter Bedeutung ist und Rechenressourcen weniger problematisch sind.
Im Gegensatz dazu bietet ANNS eine praktische Lösung für den Umgang mit groß angelegten Daten, indem ein gewisser Grad an Genauigkeit zugunsten schnellerer Leistung geopfert wird. ANNS verwendet verschiedene Algorithmen und Techniken, wie baumbasierte Strukturen, Hashing-Methoden und graphbasierte Ansätze, um die nächsten Nachbarn effizient anzunähern. Dieser Ansatz reduziert die Rechenkosten erheblich und skaliert gut mit riesigen Datensätzen, wodurch er ideal für Echtzeitanwendungen wie Suchmaschinen und Empfehlungssysteme ist, bei denen Geschwindigkeit entscheidend ist. Obwohl ANNS nicht immer die exakt nächsten Nachbarn liefert, macht seine Fähigkeit, nahezu genaue Ergebnisse schnell bereitzustellen, es zu einem wertvollen Werkzeug in modernen Aufgaben der Datenabfrage und -analyse.
Weitere Informationen finden Sie auf unserer ANNS-Glossarseite.
Was ist ANN Benchmark?
Der ANN Benchmark ist ein umfassendes Evaluierungstool, das entwickelt wurde, um die Leistung verschiedener ANNS-Algorithmen zu messen und zu vergleichen. Gehostet auf ann-benchmarks.com, bietet es standardisierte Tests und Metriken zur Bewertung verschiedener Aspekte von ANNS-Methoden, darunter:
Suchgeschwindigkeit: Wie schnell der Algorithmus die nächsten Nachbarn finden kann.
Genauigkeit: Der Grad, in dem die Ergebnisse des Algorithmus die tatsächlichen nächsten Nachbarn annähern.
Skalierbarkeit: Wie gut der Algorithmus arbeitet, wenn die Größe oder Dimensionalität des Datensatzes zunimmt.
Dieser Benchmark bietet eine Reihe von Datensätzen und Evaluierungskriterien, die es Entwicklern ermöglichen, die Wirksamkeit verschiedener Algorithmen unter unterschiedlichen Bedingungen auf einer einheitlichen Vergleichsbasis einzuschätzen.
Wichtige Metriken in ANN-Benchmarks:
Recall: Der Prozentsatz der tatsächlichen nächsten Nachbarn, die vom Algorithmus erfolgreich abgerufen werden. Ein hoher Recall weist auf eine bessere Genauigkeit hin.
Suchzeit: Die Zeit, die der Algorithmus benötigt, um ein Ergebnis zurückzugeben. Schnellere Suchzeiten sind entscheidend für Anwendungen, die Echtzeitantworten erfordern.
Speichernutzung: Die Menge an Speicher, die der Algorithmus benötigt, um den Datensatz zu speichern und zu durchsuchen. Eine effiziente Speichernutzung ist wichtig für die Skalierbarkeit.
Skalierbarkeit: Die Fähigkeit des Algorithmus, die Leistung aufrechtzuerhalten, wenn die Größe des Datensatzes zunimmt. Skalierbarkeit ist ein kritischer Faktor in realen Anwendungen, in denen Datensätze schnell wachsen können.
Wichtige Datensätze, die in ANN Benchmarks verwendet werden
ANN Benchmark verwendet vielfältige Datensätze, um Algorithmen zu testen. Diese Datensätze decken eine Reihe von Bereichen ab, wie Bildmerkmale, Texteinbettungen und synthetische Daten. Zu den wichtigsten Datensätzen, die in den Benchmarks verwendet werden, gehören:
| Datensatz | Dimensionen | Trainingsgröße | Testgröße | Nachbarn | Distanz | Download |
|---|---|---|---|---|---|---|
| DEEP1B | 96 | 9,990,000 | 10,000 | 100 | Angular | HDF5 (3.6GB) |
| Fashion-MNIST | 784 | 60,000 | 10,000 | 100 | Euklidisch | HDF5 (217MB) |
| GIST | 960 | 1,000,000 | 1,000 | 100 | Euklidisch | HDF5 (3.6GB) |
| GloVe | 25 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (121MB) |
| GloVe | 50 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (235MB) |
| GloVe | 100 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (463MB) |
| GloVe | 200 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (918MB) |
| Kosarak | 27,983 | 74,962 | 500 | 100 | Jaccard | HDF5 (33MB) |
| MNIST | 784 | 60,000 | 10,000 | 100 | Euklidisch | HDF5 (217MB) |
| MovieLens-10M | 65,134 | 69,363 | 500 | 100 | Jaccard | HDF5 (63MB) |
| NYTimes | 256 | 290,000 | 10,000 | 100 | Angular | HDF5 (301MB) |
| SIFT | 128 | 1,000,000 | 10,000 | 100 | Euklidisch | HDF5 (501MB) |
| Last.fm | 65 | 292,385 | 50,000 | 100 | Angular | HDF5 (135MB) |
Getestete ANN-Algorithmen oder Vektorsuchmaschinen
Die ANN Benchmarks haben eine breite Palette von ANN-Algorithmen und Vektorsuchmaschinen evaluiert, darunter Annoy, Faiss, Knowhere (die Suchmaschine von Milvus) und Glass (die Legacy-Suchmaschine von Zilliz Cloud). Die Anzahl der getesteten Algorithmen wächst weiter. Unten finden Sie eine Liste der Algorithmen und Suchmaschinen, die bis September 2024 getestet wurden.
scikit-learn: LSHForest, KDTree, BallTree
NMSLIB (Non-Metric Space Library) : SWGraph, HNSW, BallTree, MPLSH
NGT : ONNG, PANNG, QG
Elasticsearch : HNSW
DiskANN : Vamana, Vamana-PQ
scipy: cKDTree
Hinweis: Zilliz Cloud hat eine neue Suchmaschine namens Cardinal eingeführt, die die dreifache Leistung der älteren Glass-Engine liefert und einen Suchdurchsatz (QPS) bietet, der bis zu zehnmal so hoch ist wie der von Milvus. Aufgrund von Zeitbeschränkungen und anderen Faktoren ist die Leistung von Cardinal jedoch nicht in den ANN-Benchmark-Ergebnissen enthalten. Im folgenden Abschnitt können Sie seine Leistung mit VectorDBBench untersuchen.
Benchmark-Ergebnisse
Die folgende Grafik zeigt die Ergebnisse der Tests zu Recall/Abfragen pro Sekunde verschiedener Algorithmen auf Basis des GIST1M-Datensatzes (1 Mio. Vektoren mit 960 Dimensionen). Sie stellt die Recall-Rate auf der x-Achse dem QPS-Wert auf der y-Achse gegenüber und veranschaulicht die Leistung jedes Algorithmus bei unterschiedlichen Stufen der Abrufgenauigkeit.
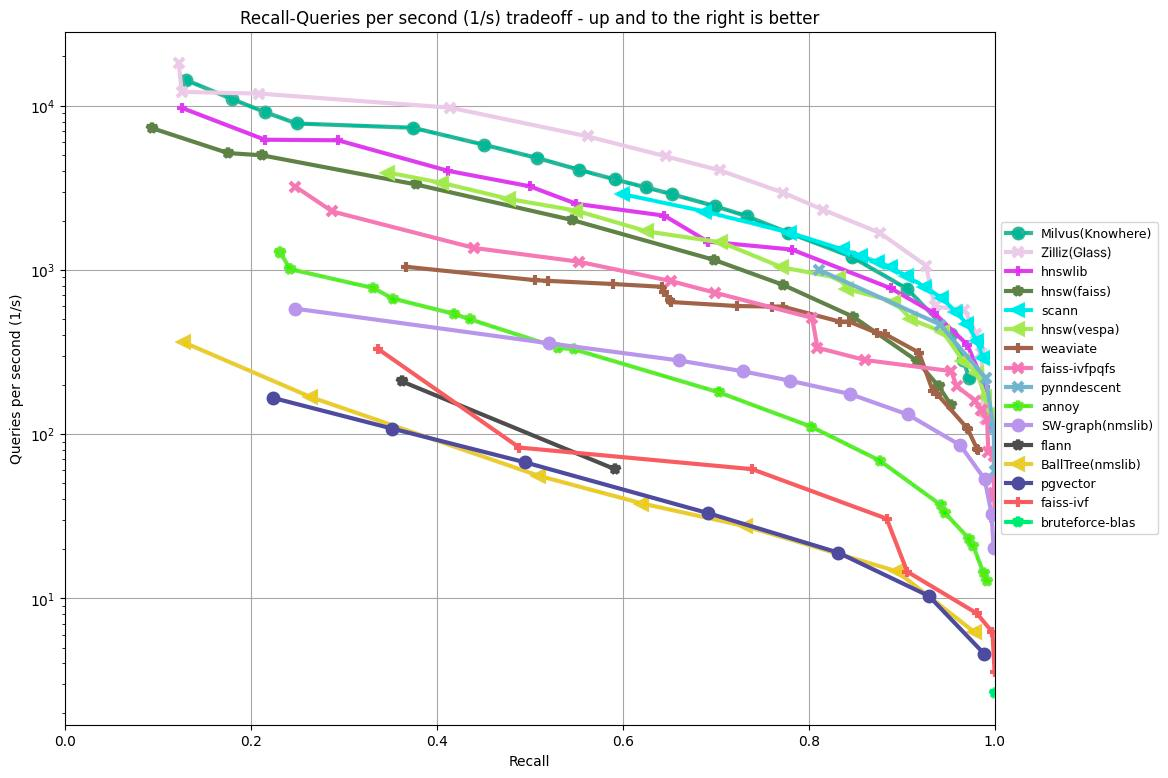 Abbildung 1: ANN-Benchmark-Ergebnisse auf dem GIST1M-Datensatz
Abbildung 1: ANN-Benchmark-Ergebnisse auf dem GIST1M-Datensatz
Abbildung 1: ANN-Benchmark-Ergebnisse auf dem GIST1M-Datensatz
Den in der obigen Grafik gezeigten Ergebnissen zufolge erzielten Knowhere (die Suchmaschine von Milvus), Glass (die ältere Suchmaschine von Zilliz Cloud) und HNSW-Bibliotheken die drei besten Ergebnisse bei der Verarbeitung von 1.000.000 Vektoren mit 960 Dimensionen.
Weitere Benchmarking-Ergebnisse finden Sie auf der Website von ANN-Benchmark.
VectorDBBench: Ein Open-Source-Benchmarking-Tool für Vektordatenbanken
Vektorsuche, oder Vektorähnlichkeitssuche, ist ein umfassenderes Konzept, das den Prozess bezeichnet, ähnliche Vektoren innerhalb eines Datensatzes zu finden. ANNS stellt eine Reihe von Algorithmen dar, die die Vektorsuche ermöglichen. Vektordatenbanken sind speziell entwickelte Lösungen für effiziente Vektorähnlichkeitssuchen.
Obwohl der ANN-Benchmark äußerst nützlich ist, um verschiedene Vektorsuchalgorithmen auszuwählen und zu vergleichen, bietet er keinen umfassenden Überblick über Vektordatenbanken. Wir müssen auch Faktoren wie Ressourcenverbrauch, Datenladekapazität und Systemstabilität berücksichtigen. Darüber hinaus lässt der ANN Benchmark viele gängige Szenarien außer Acht, wie etwagefilterte Vektorsuchen.
Um solche Herausforderungen zu bewältigen, schlugen Zilliz-Entwickler VectorDBBench vor, ein Open-Source-Benchmarking-Tool, das für Open-Source-Vektordatenbanken wie Milvus and Weaviate und vollständig verwaltete Dienste wie Zilliz Cloud and Pinecone entwickelt wurde. Da viele vollständig verwaltete Vektorsuchdienste ihre Parameter nicht für die Benutzeroptimierung offenlegen, zeigt VectorDBBench QPS und Recall-Raten getrennt an.
Die folgenden Diagramme zeigen die Testergebnisse für QPS und die Recall-Rate verschiedener gängiger Vektordatenbanken bei der Verarbeitung von 1.000.000 Vektoren mit 768 Dimensionen.
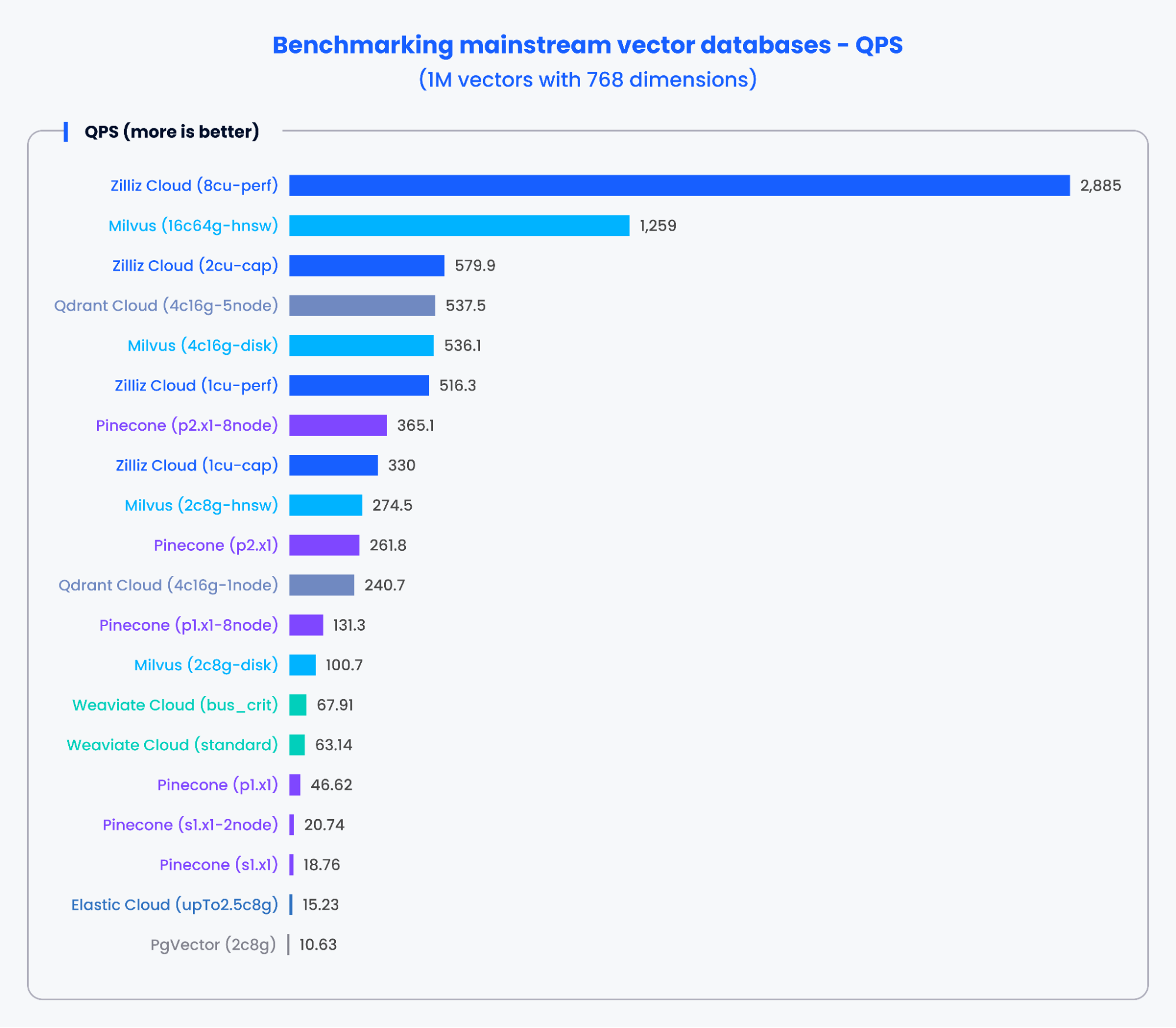 Abbildung 2: Benchmark-Ergebnisse für QPS
Abbildung 2: Benchmark-Ergebnisse für QPS
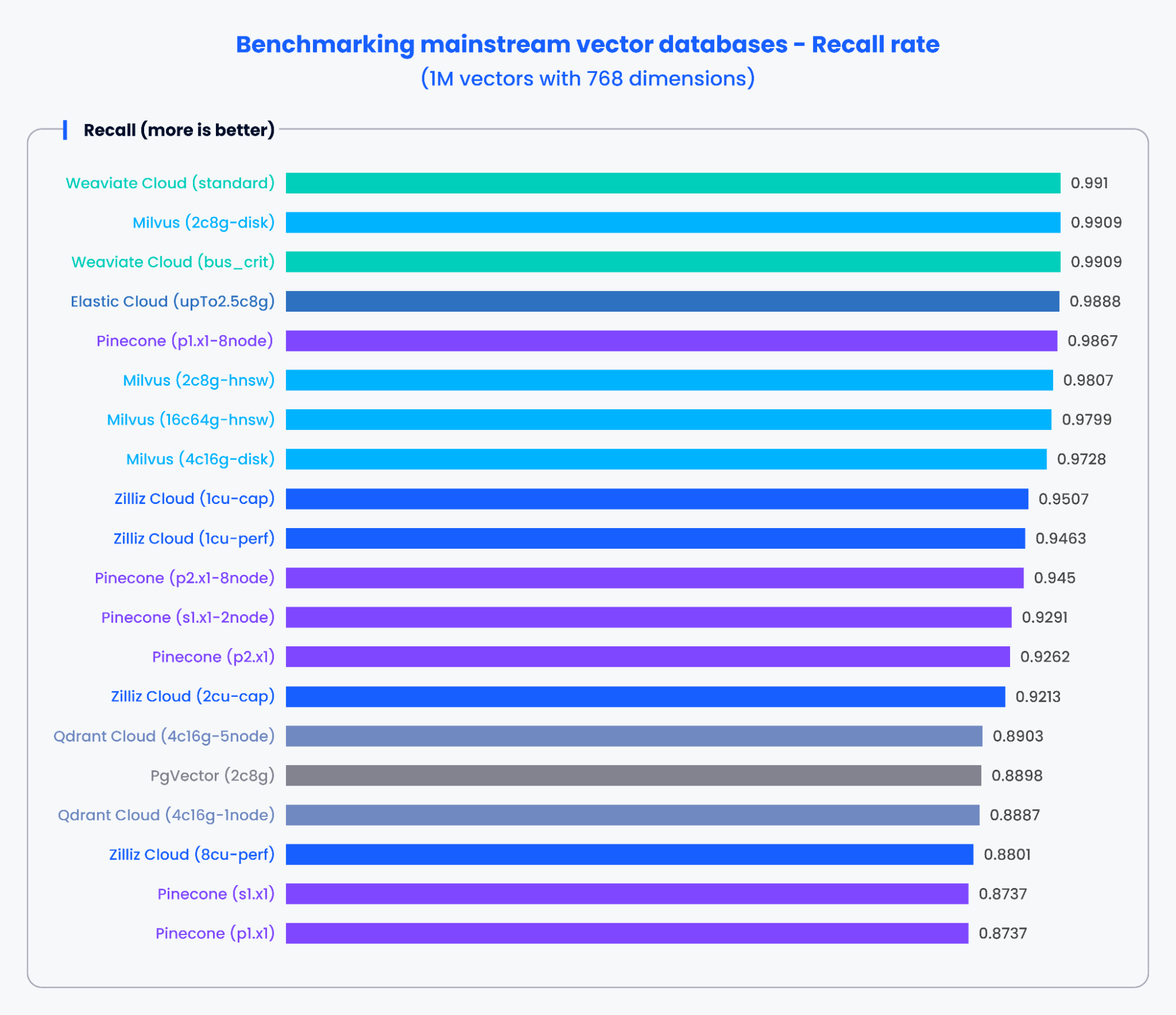 Abbildung 3: Benchmark-Ergebnisse für die Recall-Rate
Abbildung 3: Benchmark-Ergebnisse für die Recall-Rate
Basierend auf den Ergebnissen in den obigen Diagrammen zeigten speziell entwickelte Vektordatenbanken wie Milvus und Zilliz sowohl bei QPS als auch bei den Recall-Raten eine herausragende Leistung. Diese Ergebnisse zeigen, dass speziell entwickelte Vektordatenbanken enorme Datenmengen schnell verarbeiten und präzisere Ergebnisse abrufen können. Im Gegensatz dazu zeigten Vektorsuche-Add-ons auf Basis traditioneller Datenbanken eine schwächere Leistung.
Laden Sie VectorDBBench aus seinem GitHub repository herunter, um unsere Benchmark-Ergebnisse zu reproduzieren oder Leistungsergebnisse für Ihre eigenen Datensätze zu erhalten.
VectorDBBench Leaderboard
VectorDBBench bietet außerdem eine spezielle Leaderboard-Seite, die darauf ausgelegt ist, die Präsentation von Testergebnissen zu optimieren und einen umfassenden Leistungsanalysebericht zu liefern. Dieses Leaderboard ermöglicht es uns, wichtige Kennzahlen wie Queries Per Second (QPS), Query Price ($)-Kennzahlen und Latenz für eine umfassende Leistungsbewertung auszuwählen.
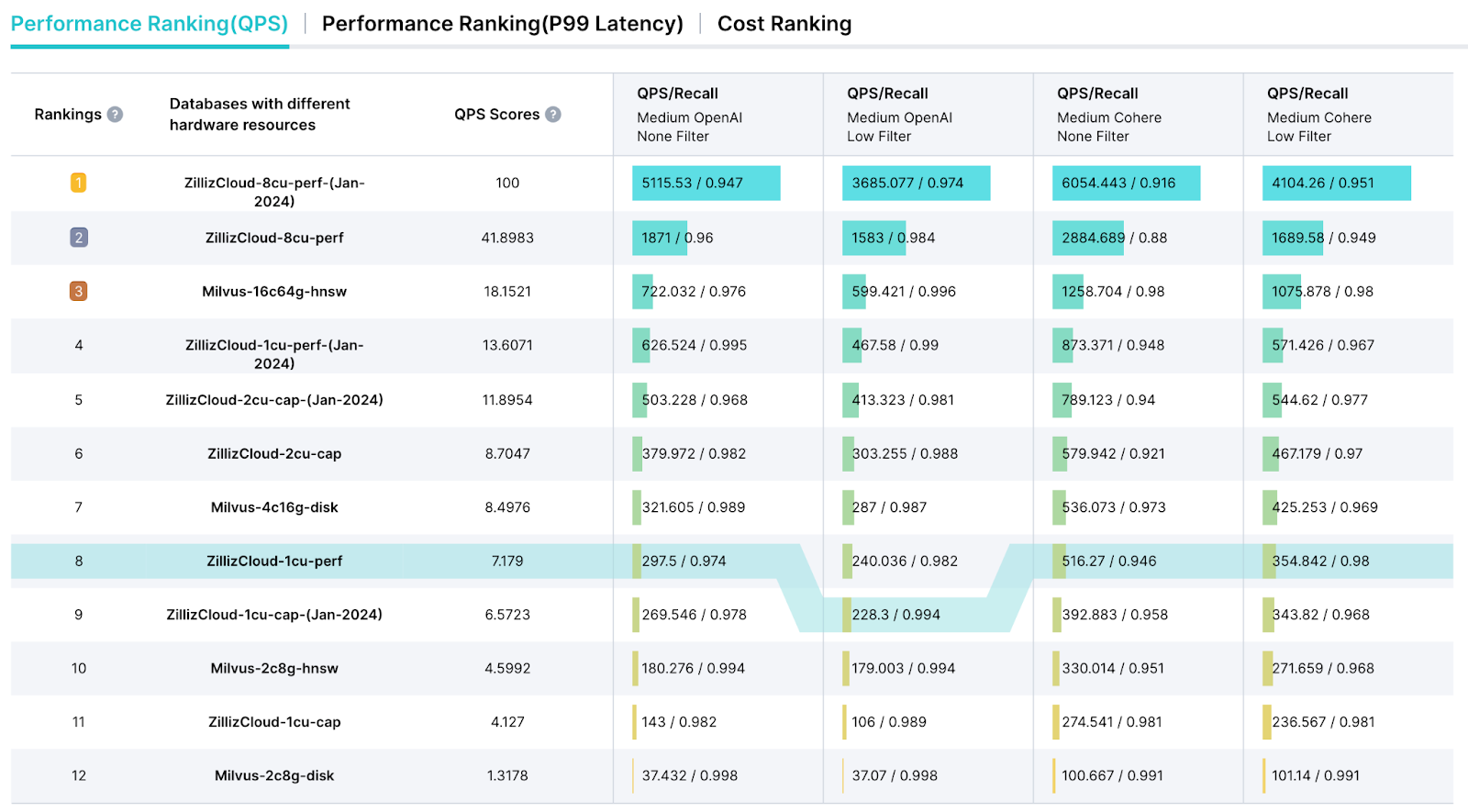 ein Screenshot des vectordbbench Leaderboards
ein Screenshot des vectordbbench Leaderboards
Abbildung 4: Ein Screenshot des VectorDBBench Leaderboard
ANN Benchmarks vs. VectorDBBench
ANN Benchmarks bewerten Vektorindex-Algorithmen und unterstützen die Auswahl und den Vergleich verschiedener Vektorsuchbibliotheken. Sie sind jedoch ungeeignet, um komplexe und ausgereifte Vektordatenbanken zu bewerten, und übersehen Situationen wie die gefilterte Vektorsuche.
Die Ingenieure bei Zilliz entwickelten VectorDB Bench, um es auf eine umfassende Bewertung von Vektordatenbanken zuzuschneiden. Es berücksichtigt wesentliche Faktoren wie Ressourcenverbrauch, Datenladekapazität und Systemstabilität. Durch die Trennung von Testclient und Vektordatenbank sowie die Sicherstellung einer unabhängigen Bereitstellung ermöglicht VectorDB Bench Tests, die realen Produktionsumgebungen sehr nahekommen.
Faktoren, die die Leistungsbewertung beeinflussen
Mehrere Faktoren beeinflussen die Leistung einer Vektordatenbank oder eines ANN-Algorithmus, darunter der Datensatz, Netzwerkbedingungen und die Datenbankkonfiguration.
Netzwerk
Netzwerkbedingungen sind entscheidend. Latenz kann Abfrageantworten verlangsamen, während begrenzte Bandbreite die Datenübertragungsraten beeinflusst. Netzwerkstabilität ist ebenfalls wichtig, da Schwankungen zu inkonsistenter Leistung führen können.
Datensätze
Die Datensatzgröße beeinflusst die Speicher- und Festplattennutzung—größere Datensätze erfordern mehr Ressourcen. Vektordimensionalität beeinflusst die Komplexität von Operationen und Abfragezeiten. Die Datenverteilung und Indexierungsstruktur (z. B. hierarchisch, flach) wirken sich ebenfalls auf Sucheffizienz und Genauigkeit aus.
Datenbankkonfiguration
Indexparameter (z. B. Anzahl der Bäume) und Sucheinstellungen (z. B. nächste Nachbarn) beeinflussen direkt die Abrufeffizienz und -geschwindigkeit. Caching kann die Antwortzeiten für häufig abgerufene Daten verbessern.
Umgebungsfaktoren
Das Betriebssystem und Hintergrundprozesse können die Ressourcenverfügbarkeit und Reaktionsfähigkeit des Systems beeinflussen und sich auf die Gesamtleistung auswirken.
Die Berücksichtigung dieser Faktoren hilft Ihnen, die Leistung Ihrer Vektordatenbank zu verstehen und zu optimieren.
Weitere Ressourcen
- Was ist ANN Search und wie funktioniert sie?
- Was ist ANN Benchmark?
- VectorDBBench: Ein Open-Source-Benchmarking-Tool für Vektordatenbanken
- ANN Benchmarks vs. VectorDBBench
- Faktoren, die die Leistungsbewertung beeinflussen
- Weitere Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren