




Von der Vektordatenbank zur Vector Lakebase
Heute starten wir die öffentliche Vorschau von Zilliz Vector Lakebase — dem nächsten Kapitel für Zilliz Cloud. Vector Lakebase ist der nächste Schritt über Vektordatenbanken hinaus. Es ist eine semantikzentrierte Datenplattform, auf der offener Speicher und elastische Rechenleistung für KI-Workloads zusammenlaufen.
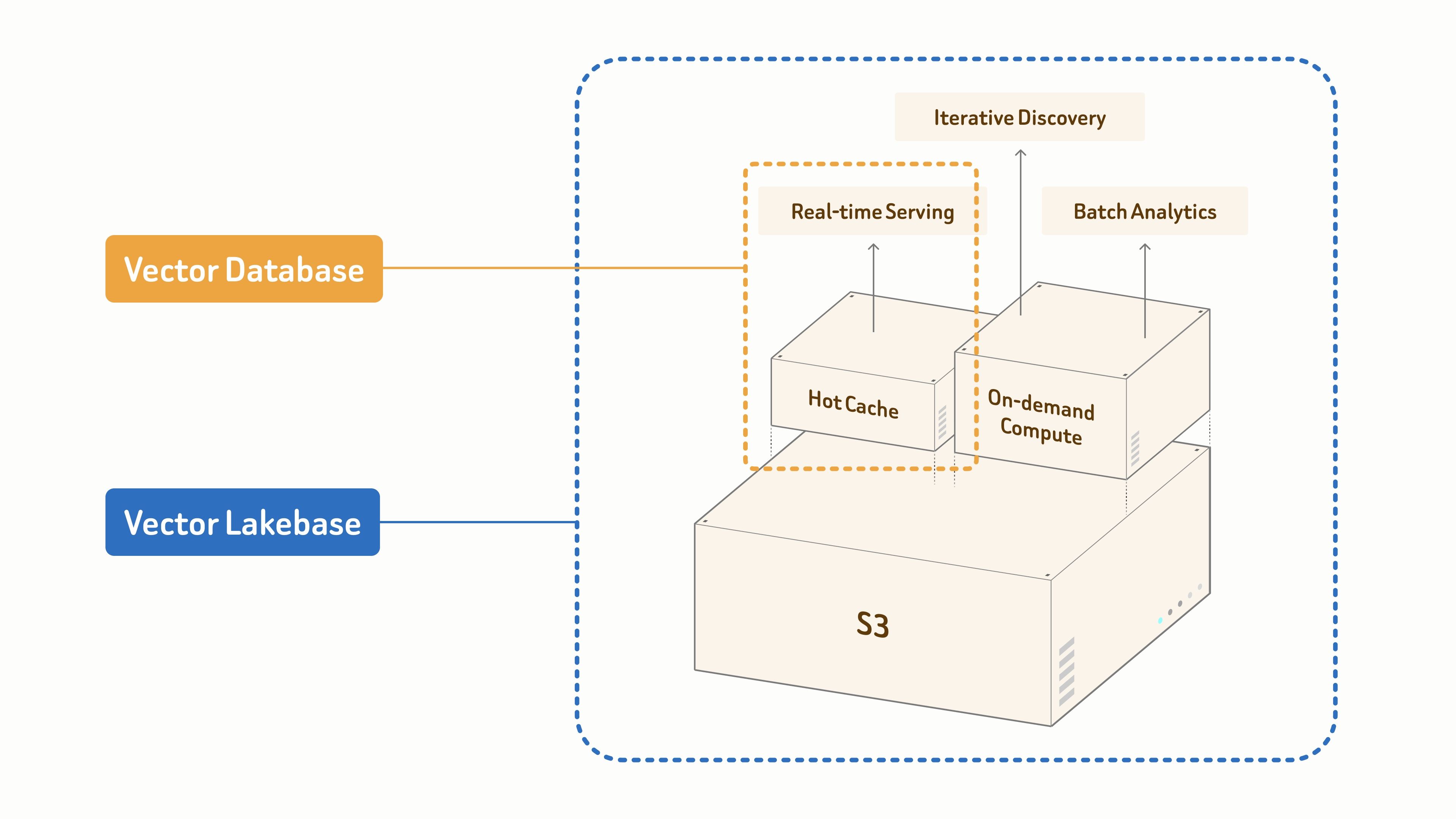
- Vektordatenbanken sind speziell für Echtzeit-Bereitstellung entwickelt.
- Vector Lakebase baut auf einer S3-basierten einheitlichen Datengrundlage auf, um KI und Agenten über drei Workload-Modi hinweg zu unterstützen:
- Echtzeit-Abruf für latenzkritische Produktionsbereitstellung,
- iterative Entdeckung für interaktive und mehrstufige Exploration,
- Batch-Analytik für Offline-Mining und Datensatzoptimierung.
Alles skalierbar von Gigabyte bis Petabyte.
Warum sind die einheitliche Datengrundlage und die drei Workload-Modi wirklich wichtig?
Kurz gesagt: weil KI-Systeme nicht mehr nur ein Abrufproblem mit einer einzelnen Abfrage sind. Sie funktionieren als kontinuierliche Schleife aus Bereitstellung, Lernen und Verbesserung.
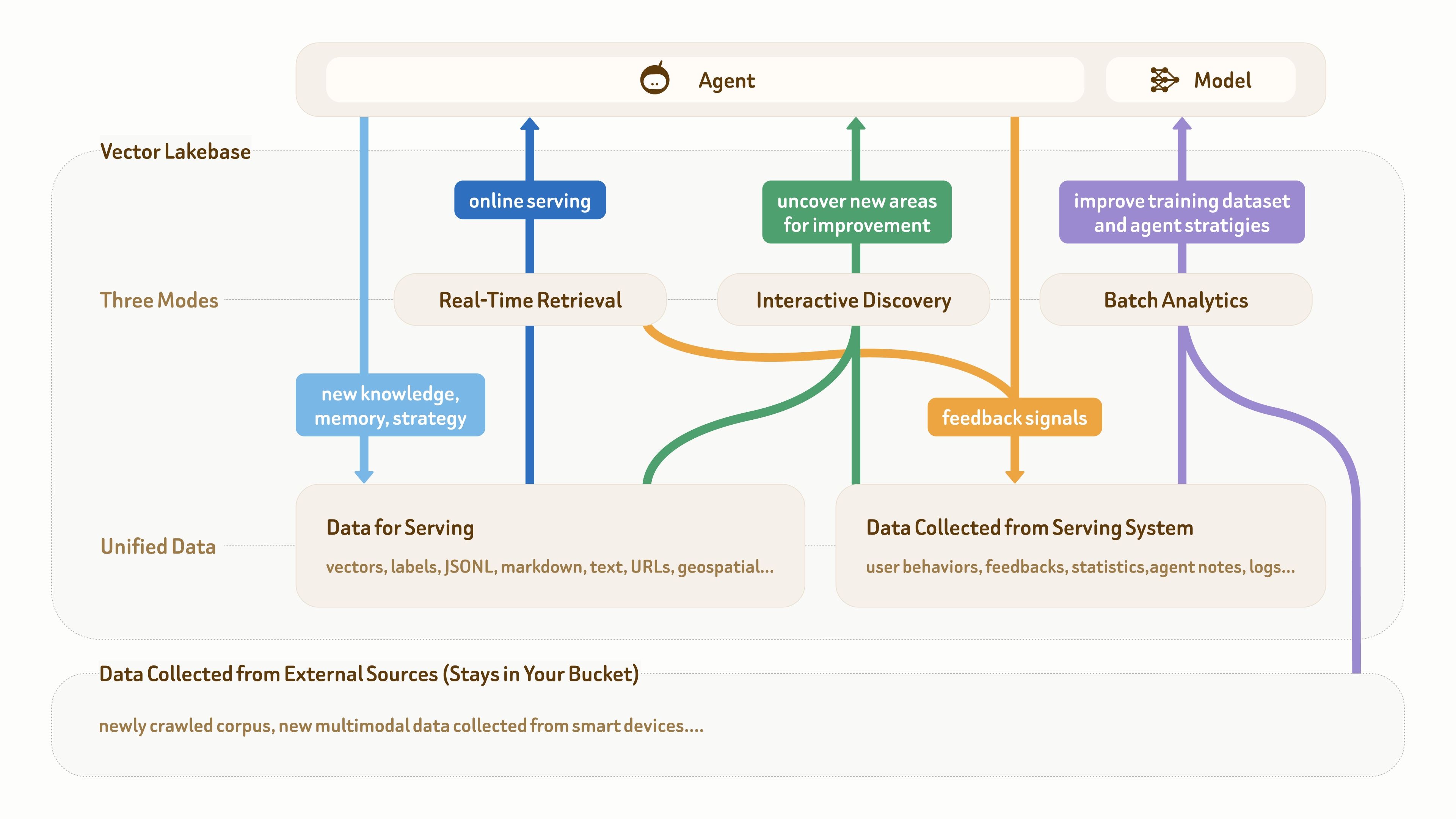
Wie diese Abbildung zeigt, besteht die Datengrundlage für KI- und Agentenanwendungen in der Regel aus drei Teilen: rohe multimodale Daten unten, semantische Daten für die Online-Bereitstellung (wie Text, Vektoren und Labels) und Feedback-Daten, die aus Produktionssystemen gesammelt werden (wie Nutzerverhalten, Logs, Agentennotizen und Statistiken).
Viele ausgereifte Agentenanwendungen verfügen bereits über eine solche Datengrundlage. Der eigentliche Schmerzpunkt ist, dass diese verschiedenen Datentypen häufig über mehrere Pipelines und Systeme verteilt sind, ohne eine einheitliche und strukturierte Datenebene zur Unterstützung der Workflow-Schleife:
Online-Bereitstellung (dunkelblau) → Wissens- und Feedback-Akkumulation (hellblau und orange) → Erkenntnisgewinnung (grün) → Datensatz- und Strategieverbesserung (lila) → bessere Online-Bereitstellung.
Wie die Abbildung ebenfalls zeigt, reicht eine Vektordatenbank allein nicht mehr aus, weil sie hauptsächlich Echtzeit-Abruf und bereitstellungsorientierte Datenschreibvorgänge unterstützt (die beiden blauen Pfade). In dieser Schleife sind die beiden anderen Zugriffsmodi — interaktive Entdeckung und Batch-Analytik — ebenso wichtig.
Zum Beispiel müssen KI-Entwickler (entweder manuell oder über agentische Systeme) häufig Feedback-Daten und den zugrunde liegenden Korpus untersuchen, um zu verstehen, warum die Bereitstellungsqualität schlecht ist. Sie können außerdem groß angelegte semantische Deduplizierung und Clusterbildung auf neu gecrawlten Daten ausführen und anschließend Edge-Cluster minen, um neue Kandidaten für Trainingsdaten zu entdecken.
Diese Workloads unterscheiden sich stark von traditioneller Big-Data-Verarbeitung. Die Kernberechnung ist semantisch statt numerisch. Die Daten bestehen hauptsächlich aus Vektoren, Text, Labels und semantischen Metadaten, während die Kernoperationen Vektorsuche, Volltextsuche, Reranking, semantische Clusterbildung und verwandte semantische Abrufaufgaben umfassen.
Aus diesem Grund sind interaktive Entdeckung und Batch-Analytik sowohl auf Daten- als auch auf Rechenebene natürlich auf Vektordatenbanken ausgerichtet. In vielen Fällen teilen sich Online-Bereitstellung und Offline-Verarbeitung sogar dieselbe zugrunde liegende Datengrundlage.
Zum Beispiel können Teams hochwertige Nutzeraufgaben offline clustern und analysieren und gleichzeitig prüfen, ob das unterstützende Wissen oder die Strategien im Bereitstellungssystem Sparsity- oder Qualitätsprobleme aufweisen.
Insgesamt verlangsamt jede fragmentierte Datenarchitektur oder jede isolierte Infrastrukturinsel diese Schleife — was im sich schnell entwickelnden Wettlauf um KI-Fähigkeiten fatal sein kann. Vector Lakebase beschleunigt diese Schleife durch einen unkomplizierten, aber effizienten Ansatz: die Bereitstellung einer semantischen Zero-Copy-Datenebene, auf die alle drei Workload-Modi — Echtzeit-Abruf, interaktive Entdeckung und Batch-Analytik — effizient zugreifen können.
Die wichtigsten Funktionen von Vector Lakebase
Zilliz Vector Lakebase unterstützt diese Workflow-Schleife durch fünf Kernfunktionen:
- Gestufte Serving-Lösungen
Flexible Serving-Stufen, optimiert für unterschiedliche Echtzeit-Workloads — sie liefern ultrahohe Performance, ausgewogene Effizienz und kosteneffektive Skalierung über riesige Datensätze hinweg. - On-Demand-Suche
Entwickelt für groß angelegte Workloads, bei denen Latenz weniger kritisch ist und Rechenressourcen die meiste Zeit im Leerlauf bleiben — einschließlich seltener Suche, Datenerkundung und Batch-Analysen. - Suche in externen Data Lakes
Fügen Sie modernste Indexierungs- und groß angelegte Suchfunktionen direkt zu Ihren bestehenden Lake-Daten hinzu. - Vollspektrum-Suche Von Vektoren und Text bis hin zu JSON und Geodaten—kombiniert mit hybrider Abfrage, Filterung und Reranking für ausdrucksstarke multimodale Abfragen.
- Einheitlicher Lake-Native-Speicher
Einheitlicher Speicher für Serving und Analysen, aufgebaut auf Vortex — einem offenen Format der nächsten Generation, das schnellere und günstigere zufällige Lesezugriffe als Lance und Parquet bietet, plus Flexibilität beim Format pro Spalte und umfassendere Datenmodellierungsfunktionen.
Gestufte Echtzeit-Serving-Lösungen
Die gestuften Serving-Lösungen von Zilliz Cloud bieten drei Serving-Stufen: Performance-Optimized, Capacity-Optimized und Tiered-Storage. Jede Stufe basiert auf dedizierten Indexierungsalgorithmen und Datenplatzierungsstrategien über die Speicherhierarchie hinweg und bietet eine breite Palette von Performance-Kosten-Kompromissen.
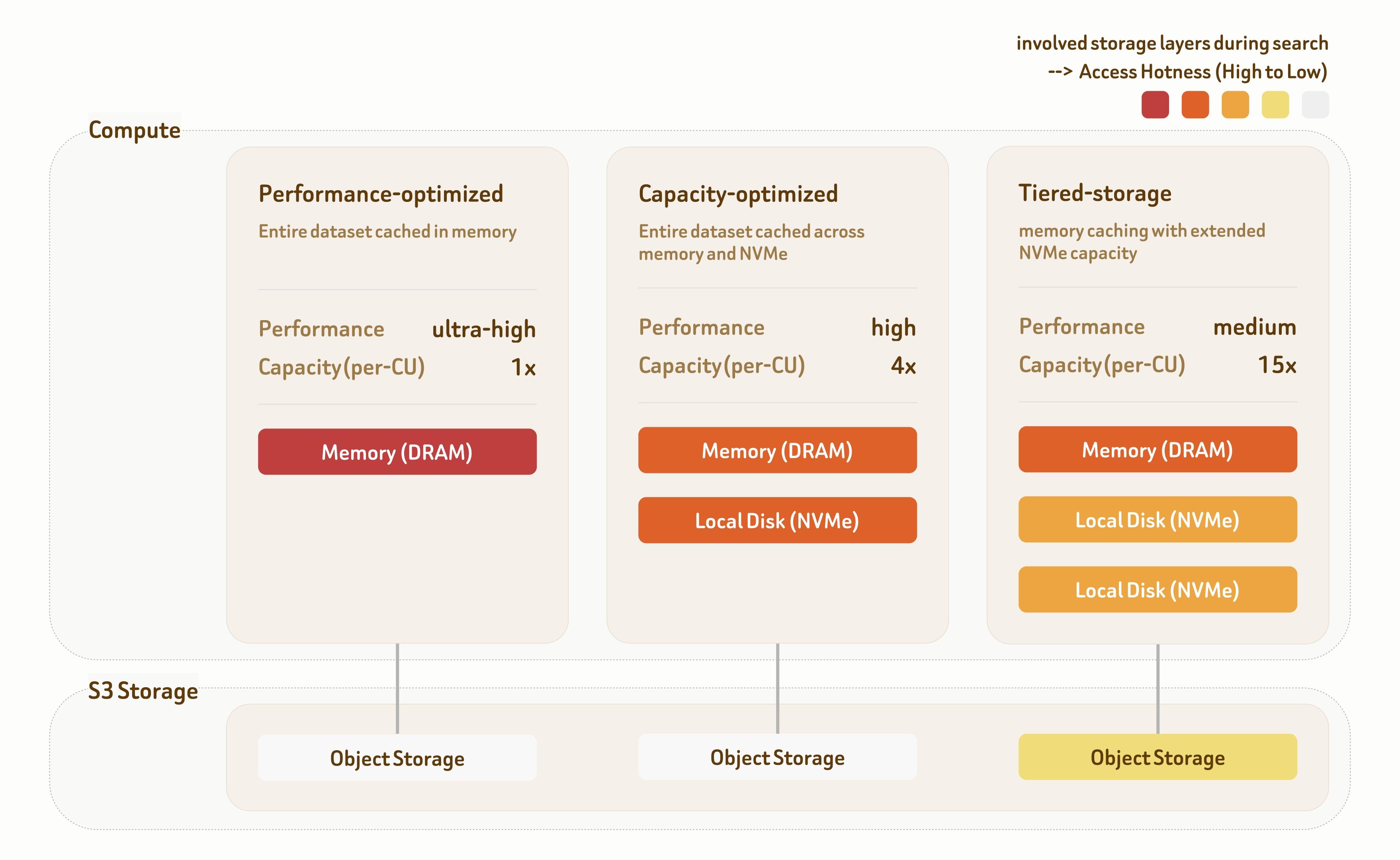
Die Stufe Performance-Optimized zielt auf Szenarien mit ultrahoher Performance ab. Alle Daten werden direkt aus dem Arbeitsspeicher bereitgestellt und liefern 1000+ QPS bei einstelliger Millisekundenlatenz. Der Durchsatz skaliert zusätzlich linear mit Multi-Replica-Bereitstellung.
Die Stufe Capacity-Optimized kombiniert Arbeitsspeicher und lokalen NVMe-Speicher, um Performance und Kapazität auszubalancieren. Sie liefert 100~500 QPS bei einer Latenz von unter 100 ms und eignet sich damit für die meisten Retrieval-Workloads.
Die Stufe Tiered-Storage umfasst Arbeitsspeicher, lokalen NVMe-Speicher und Objektspeicher. Dank hochoptimierter Prefetching- und Caching-Strategien greifen über 95 % der Datenzugriffe weiterhin auf Arbeitsspeicher oder lokale Festplatte zu und bieten 10~50 QPS bei etwa 100 ms Latenz zu deutlich geringeren Infrastrukturkosten.
Alle drei Stufen liefern standardmäßig 95 %–98 % Recall, mit flexibler Abstimmung über Indexierung und Suche hinweg—und unterstützen je nach Workload-Anforderungen 90 % bis 99 %+ Recall.
Diese Serving-Architekturen haben sich in einigen der weltweit anspruchsvollsten groß angelegten KI- und Internet-Workloads bewährt, darunter:
- Multi-Tenant-KI-Plattformen im Internetmaßstab,
- differenzierte Service-Stufen sowohl für Premium-Unternehmenskunden als auch für große Pools kostenloser Nutzer,
- leistungsstarke Wissensdatenbanken für Agenten,
- Empfehlungssysteme mit ultrahohem Durchsatz,
- KI-Suchmaschinen im Webmaßstab,
- dynamische Hot/Cold-Datenplanung auf Sekundenebene über Speicherstufen hinweg,
- Daten-Mining-Pipelines für autonomes Fahren im Maßstab von 100B+ unter extremen Kostenvorgaben.
Für Online-Serving bietet Zilliz Cloud außerdem Global Cluster-Funktionen für regionsübergreifende Hochverfügbarkeit und Disaster Recovery, gestützt durch ein 99,99 % Uptime-SLA.
On-Demand-Suche
Interaktive Exploration und Batch-Analysen arbeiten häufig mit Datenmengen, die ein bis drei Größenordnungen größer sind als beim Online-Serving, insbesondere wenn Feedback-Daten, von Agenten generierte Notizen, Logs und gecrawlte Korpora einbezogen werden. Diese Datensätze können leicht TB- oder sogar PB-Größenordnung erreichen. Der Einsatz von Hunderten oder sogar Tausenden von Vektordatenbankknoten zu ihrer Bereitstellung ist aus Kosten-Nutzen-Sicht jedoch oft schwer zu rechtfertigen.

Wichtiger noch: Diese Workloads sind in der Regel aufgabengetrieben. Im Gegensatz zur Online-Serving-Schicht von Agentenanwendungen benötigen sie keine rund um die Uhr aktive Infrastruktur. Rechenressourcen werden nur während aktiver Verarbeitungsaufgaben stark genutzt, während sie die meiste Zeit im Leerlauf bleiben, oft mit über 97 % Leerlaufzeit.
Serverless-Bereitstellungslösungen mögen attraktiv erscheinen, werden für diese Workloads jedoch oft deutlich teurer.
Auf der Compute-Ebene folgen sowohl serverlose Systeme als auch On-Demand Search einem Pay-as-you-go-Modell. Trotz Unterschieden in den detaillierten Preismodellen sind die zugrunde liegenden Compute-Kosten oft ähnlich. In einer serverlosen Architektur werden jedoch Pooling-Overhead, Indizierung und persistente Datenkosten in zusätzliche Aufschläge für Schreibvorgänge und Speicher eingebettet, anstatt die tatsächlichen Kosten der zugrunde liegenden Ressourcen direkt widerzuspiegeln.
Im Gegensatz dazu berechnet Zilliz On-Demand Search direkt Objektspeicher und On-Demand-Compute — ähnlich wie AWS Lambda, bei dem die Preisgestaltung hauptsächlich auf der zugewiesenen Ressourcengröße und der Ausführungszeit basiert, während die Speicherkosten nahe an den zugrunde liegenden S3-Kosten bleiben. Dadurch werden versteckter Infrastruktur-Overhead und Black-Box-Preismodelle vermieden.
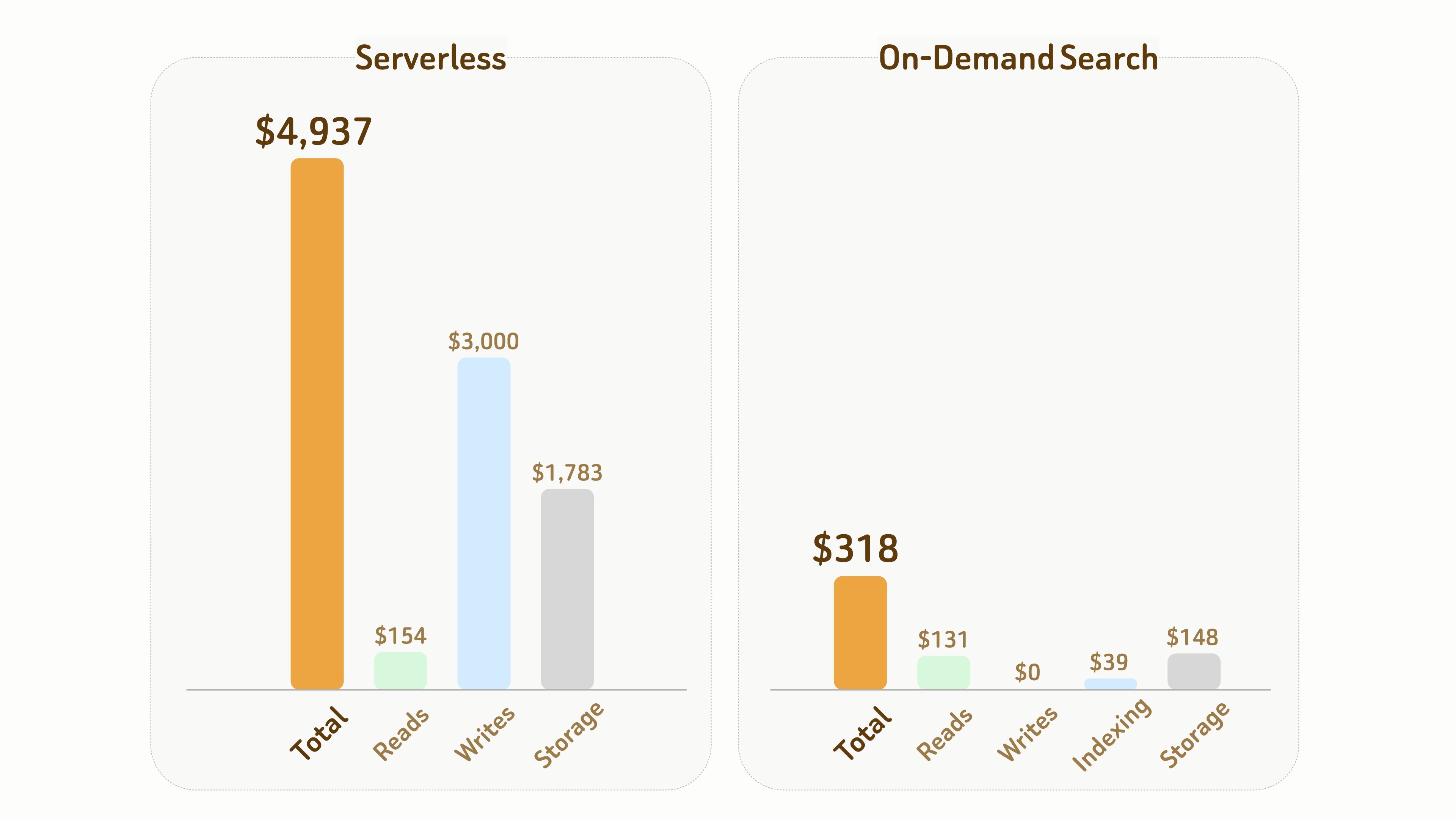
Der folgende Vergleich veranschaulicht den Kostenunterschied zwischen Serverless und On-Demand Search.
Setup:
- 1B Vektoren mit 768 Dimensionen, die einschließlich Daten- und Indexdateien etwa 6 TB Speicher benötigen,
- 1 Monat Laufzeit mit 10 Stunden kumulierter aktiver Compute-Zeit.
Insgesamt betragen in diesem Experiment die Gesamtkosten von On-Demand Search nur etwa 1/15 ($318 vs $4,937) der Kosten von Serverless.
Externe Data-Lake-Suche
Zilliz Vector Lakebase bietet vollständig verwalteten Speicher und Query-Compute, sodass Benutzer ihre Daten direkt in Zilliz Cloud speichern und betreiben können. Einige Kunden verfügen jedoch bereits über ausgereifte Data-Lake-Infrastrukturen und Governance-Pipelines.
Für KI-Anwendungen besteht eine der zentralen Herausforderungen darin, effizientes Retrieval und semantische Exploration direkt auf bestehenden Lake-Daten zu ermöglichen. Traditionelle Big-Data-Systeme wie Spark und Ray sind für diese Workloads nicht optimiert, da sie grundlegend auf Full-Data-Scan- und Map-Reduce-Berechnung ausgelegt sind und nicht auf indexbeschleunigte Abfragen und semantisches Retrieval.
Um dies zu lösen, bietet Zilliz einen External Collection-Modus. Er erstellt eine Zero-Copy-logische Zuordnung von der Zilliz-Datenebene zu kundeneigenen Lake-Tabellen und ermöglicht gleichzeitig Hochleistungsindizes und Full-Spectrum Search auf Basis dieser Zuordnung.
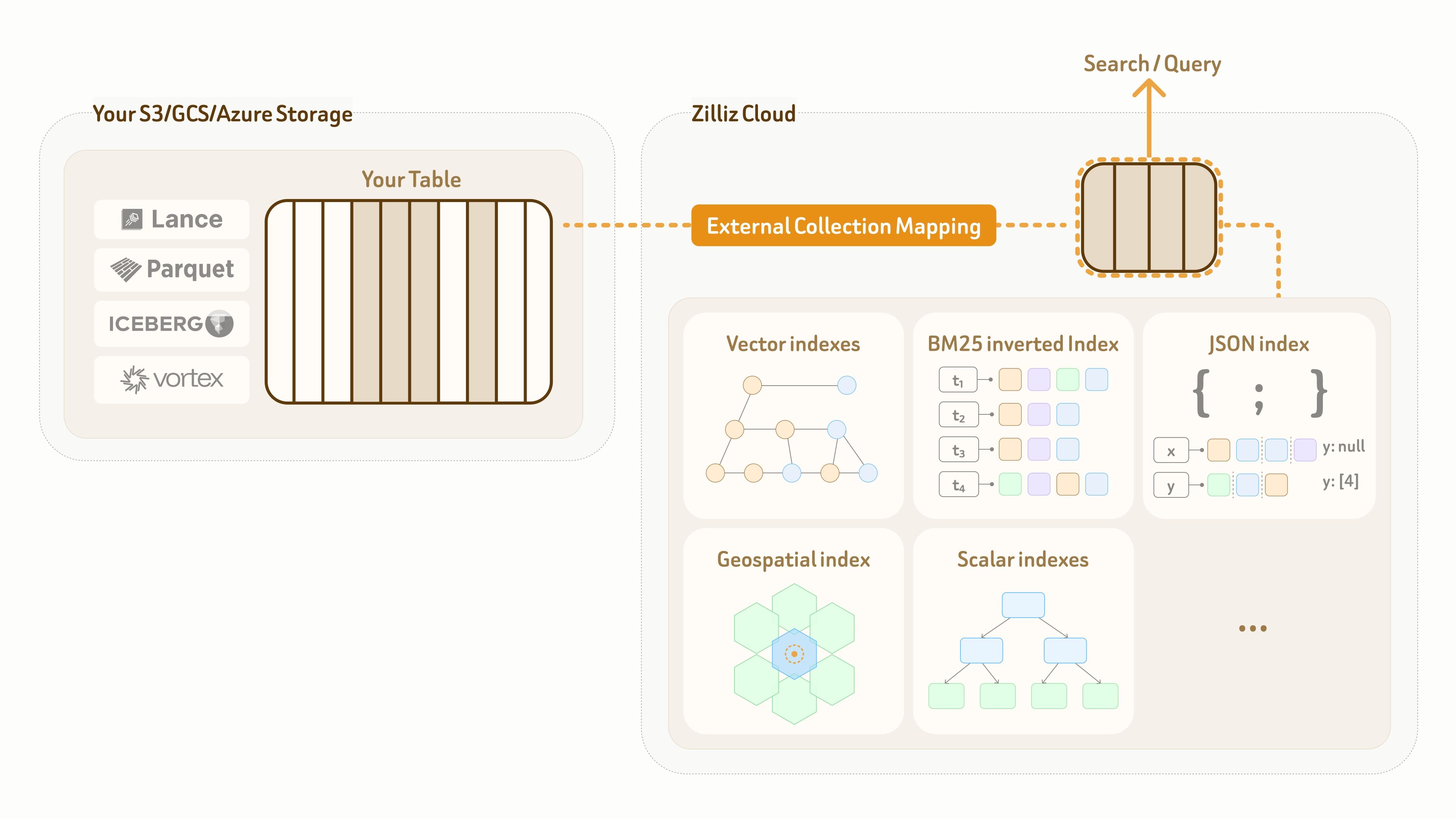
Derzeit unterstützt External Collection zwei Data-Lake-Tabellenformate — Lance und Iceberg — sowie zwei offene Datenformate — Parquet und Vortex.
Für Data-Lake-Aktualisierungen bietet Zilliz External Collection Funktionen zur inkrementellen Synchronisierung. Basierend auf dem Aktualisierungsmuster des Data Lake und den Anforderungen an die Abfragesichtbarkeit können Benutzer Daten jederzeit mit einem Refresh-Aufruf synchronisieren.
Full-Spectrum Search
KI-Anwendungen müssen zunehmend Daten aus verschiedenen Quellen und Modalitäten abrufen und analysieren — sowohl um komplementäre Informationen zu kombinieren als auch um mehrere Perspektiven aus demselben Rohinhalt zu extrahieren, um eine bessere Retrieval- und Analysequalität zu erzielen.
Zilliz Vector Lakebase unterstützt Wide-Table-Modellierung mit umfangreichen Datentypen, darunter dichte und sparse Vektoren, Text, JSON, Geodaten und primitive Typen, zusammen mit komplexen Strukturen wie Struct und Array — und ermöglicht so effiziente verschachtelte semantische Modellierung direkt innerhalb eines einheitlichen Tabellenlayouts.

Dies ermöglicht eine einheitliche Kontextmodellierung, indem jede Entität auf Anwendungsebene direkt einer einzelnen Zeile zugeordnet wird. Anstatt beispielsweise ein Dokument in Hunderte von Zeilen für Textabschnitte, Bilder und Tabellen aufzuteilen, kann Zilliz Vector Lakebase das gesamte Dokument als eine einzelne Zeile modellieren. Dies verbessert multimodales Retrieval und Analysen und vermeidet gleichzeitig den Performance- und Betriebs-Overhead von JOINs und Aggregationen.
Über die Datenmodellierung hinaus bietet Vector Lakebase außerdem modernste Indexierungs- und Suchfunktionen für alle unterstützten Datentypen. Die detaillierten Funktionen sind unten aufgeführt:
| Vector Search | Fortschrittliche Indexierungsalgorithmen, die HNSW, IVF und RaBitQ übertreffen, mit 10 Stufen zur Abstimmung von Recall und Latenz. |
|---|---|
| Full-Text Search | Volltextsuche mit BM25, Phrasen-, Präfix- und Fuzzy-Matching sowie einer breiten Palette von Analysatoren. |
| Grep | Integrierte Regex-Unterstützung, die die meisten grep-ähnlichen Matching-Muster abdeckt. |
| Hybrid Search | Hybride Suche mit dichten und spärlichen Vektoren für verbesserten Recall und höhere Relevanz. |
| Query on JSON | Integriertes JSON-Shredding und Indexierung für schnelles Filtern und Abfragen verschachtelter JSON-Felder. |
| Geospatial Search | Schnelle Geosuche mit Radius-, Nearest-Neighbor- und Flächenfilterung. |
| Multi-Vector Search | Suche über mehrere Einbettungen, die aus einer oder mehreren Modalitäten generiert wurden, mit einheitlichem Reranking. |
| Vector Search with Filtering | Vektorsuche mit Attributfilterung, optimiert für niedrige bis hohe Filterselektivität. |
| Range Search | Gibt alle Vektoren innerhalb eines angegebenen Distanzschwellenwerts zum Abfragevektor zurück. |
| Iterative Search | Iterative Suche mit schrittweiser Verfeinerung der Abfrage auf Basis von Zwischenergebnissen. |
| Multi-Path Retrieval | Multi-Path Retrieval mit mehreren Strategien, wobei jeder Pfad eine der oben genannten Suchmethoden verwenden kann. |
sowie Reranking-Funktionen, die zusammen mit Multi-Path Retrieval verwendet werden.
| Cohere Reranker | Ein Cross-Encoder-Reranking-Modell, das Abfrage-Dokument-Paare mit hoher semantischer Präzision bewertet, um Abrufresultate für maximale Relevanz neu zu ordnen. |
|---|---|
| Voyage AI Reranker | Ein leichtgewichtiges Reranking-Modell mit hohem Durchsatz, optimiert für schnelle, kosteneffiziente Relevanzbewertung in groß angelegten Retrieval-Pipelines. |
| Boost Reranker | Wendet bedingte Filter auf übereinstimmende Ergebnisse an und passt deren Scores mit einer angegebenen Gewichtung an, um Rankings zu fördern oder herabzustufen. |
| Decay Reranker | Passt Ergebnis-Scores an, indem eine Decay-Funktion basierend auf Faktoren wie Entfernung oder Zeit angewendet wird, wodurch die Relevanz schrittweise sinkt, wenn Werte von einem Ziel abweichen. |
| RRF Reranker | Führt mehrere Ergebnislisten zusammen, indem die Rangpositionen jedes Elements über Listen hinweg zu einem einzigen Ranking kombiniert werden. |
| Weighted Reranker | Kombiniert Scores aus mehreren Ergebnislisten mithilfe konfigurierbarer Gewichtungen, um ein einheitliches Ranking zu erzeugen. |
Einheitlicher Lake-nativer Speicher
Zilliz Cloud basiert auf einer vollständig entkoppelten Speicher-Compute-Architektur, bei der alles in Cloud-Objektspeicher persistiert wird.
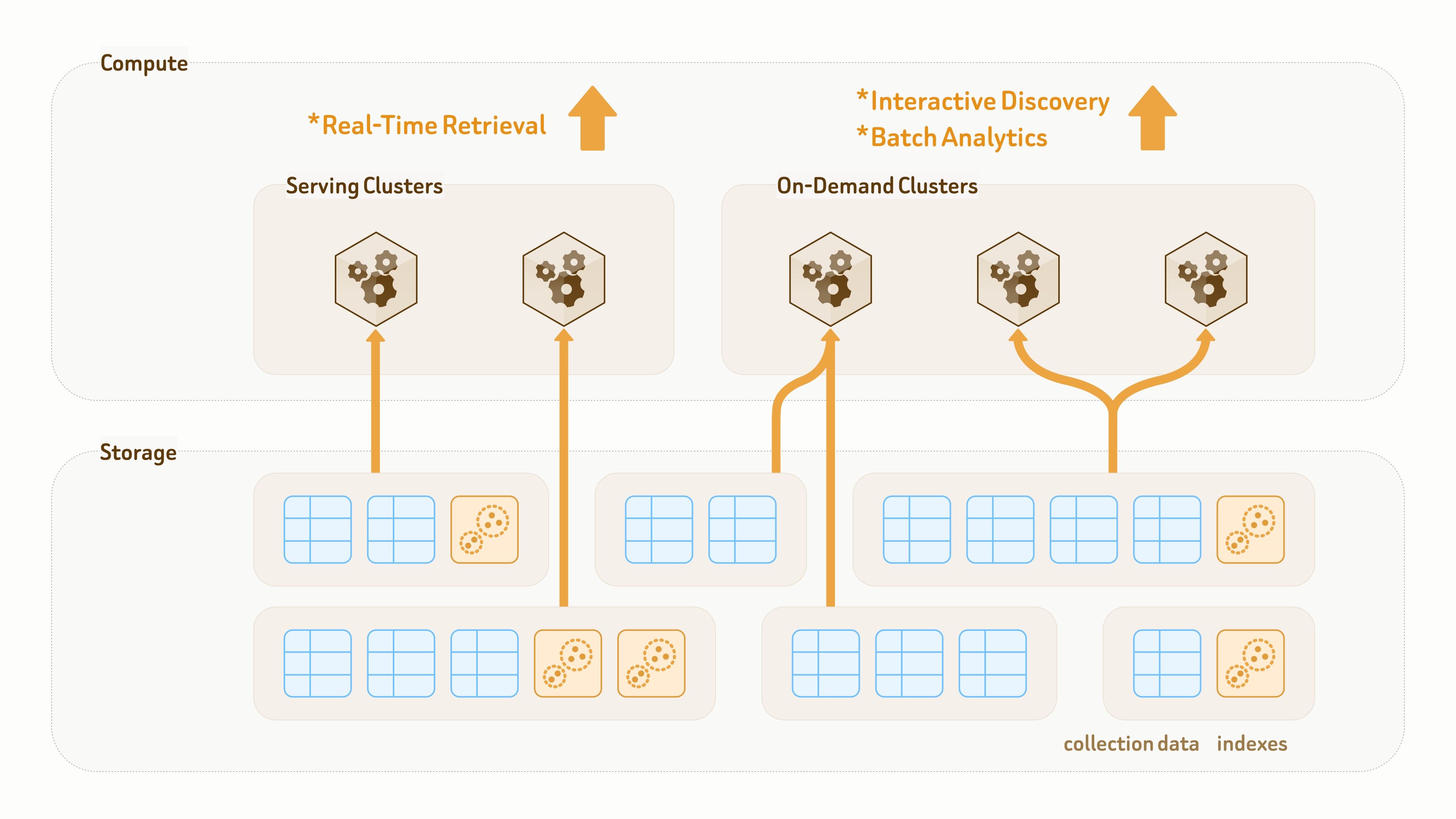
Im Gegensatz zu traditionellen Data Lakes, die hauptsächlich für die Speicherung konzipiert sind, ist die Datenschicht von Zilliz Vector Lakebase sowohl für Persistenz als auch für die Abfrageausführung ausgelegt. Collections und Indizes sind von Compute-Clustern entkoppelt, sodass dieselben Daten und Indizes über Zero-Copy-Zugriff von verschiedenen Clustern für unterschiedliche Abfrage- und Analyse-Workloads eingebunden werden können.
Für KI- und Agentenanwendungen mit sich kontinuierlich weiterentwickelnden Datenmodellen — wie dem häufigen Hinzufügen neuer Labels und Features oder dem Wechsel von Embedding-Modellen — bietet Zilliz einen nahtlosen und schnellen Mechanismus für Schemaentwicklung und Daten-Backfill.
Neue Felder werden durch gepoolte Compute-Ressourcen der Plattform backfilled und ausgerichtet und anschließend über Metadatenaktualisierungen für Abfragecluster bereitgestellt. Ein Backfill von 100 Millionen Zeilen kann typischerweise in einstelligen Minuten abgeschlossen werden.
Da der Großteil der Arbeit von plattformseitigen Compute-Ressourcen übernommen wird, bleiben bestehende Benutzercluster unbeeinträchtigt und können während des gesamten Prozesses weiterhin Lese- und Schreibverkehr bedienen.
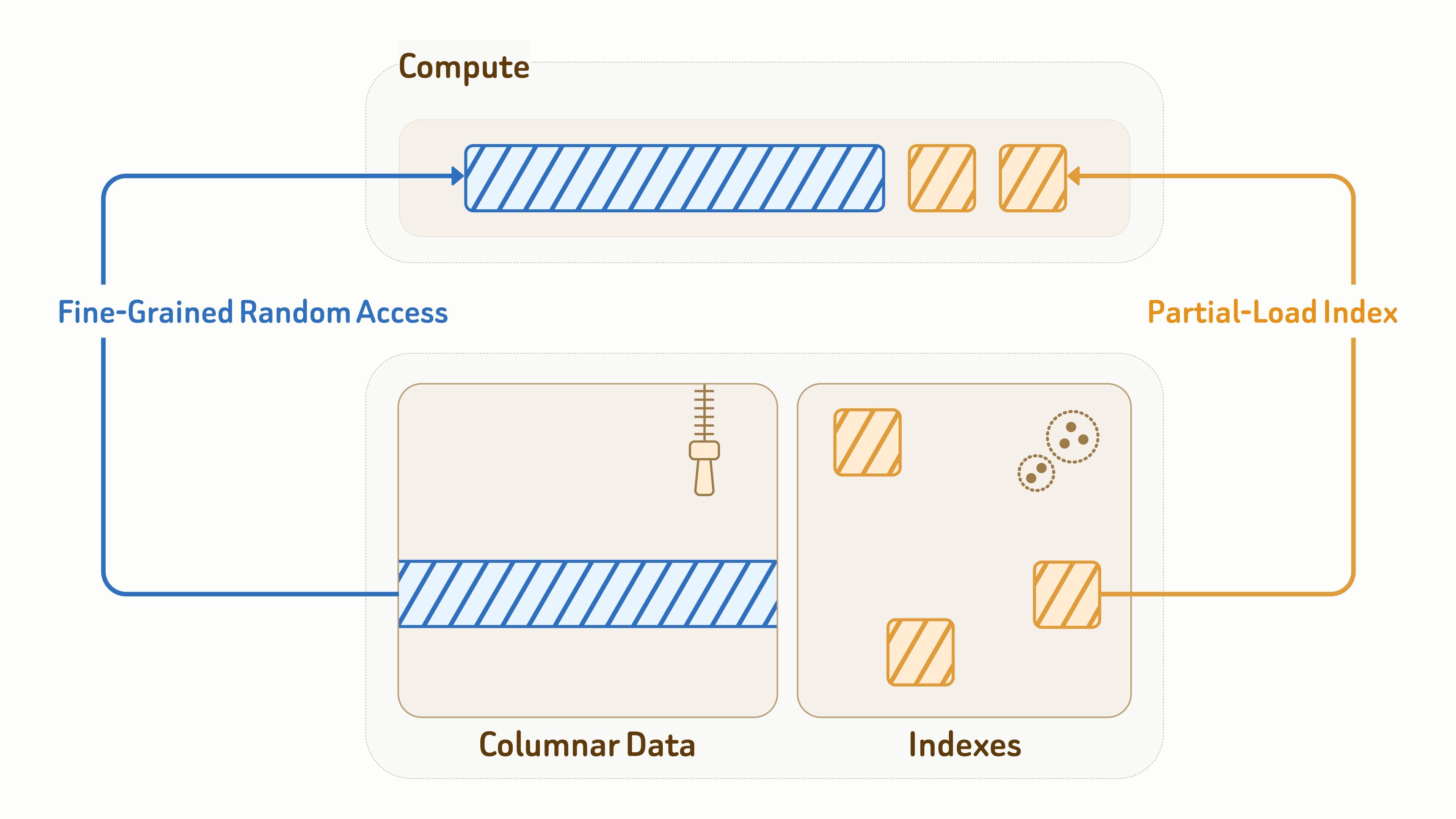
Da die Datenschicht auch direkt Abfrage-Workloads bedient, ist effizientes I/O sowohl für Latenz als auch für Durchsatz entscheidend.
Für Sammlungsdaten verwendet Zilliz das offene Vortex-Format für spaltenorientiertes Speicherlayout und kombiniert effiziente Kodierung mit feingranularem wahlfreiem Zugriff auf Datenfragmente — deutlich schneller als Lance und Parquet bei zufälligen Lesezugriffen.
Für Indizes bietet Zilliz objektspeicherbewusste Designs von Indexalgorithmen mit tiefgehend optimierten Layouts und Zugriffsmustern für effiziente I/O, einschließlich Vektorindizes, BM25-invertierter Indizes und JSON-Indizes.
Während der Abfrageausführung laden Compute-Knoten nur teilweise die Indexseiten und Datenentitäten, die von der Abfrage berührt werden. In Kombination mit Caching und Daten-Pruning reduziert dies die Leseverstärkung erheblich um über 90%.
Primäre Anwendungsfälle von Vector Lakebase
Typische Anwendungsszenarien für Vector Lakebase umfassen unter anderem:
Echtzeit-Serving-Workloads:
- Latenzkritischer Agentenspeicher und Strategieretrieval.
- Wissensdatenbanken für vertikale Domänen in Recht, Gesundheitswesen, Finanzwesen und anderen spezialisierten Branchen.
- KI-Suchmaschinen im Webmaßstab.
- Empfehlungssysteme mit ultrahohem Durchsatz.
- Dynamische Hot/Cold-Datenplanung auf Sekundenebene über Speicherebenen hinweg.
- Differenzierte Service-Ebenen sowohl für Premium-Unternehmenskunden als auch für große Pools kostenloser Nutzer.
Workloads für iterative Entdeckung:
- Analyse der Qualität von KI-Diensten und Problemerkennung über Feedback-Daten, agentengenerierte Notizen, Protokolle und andere Daten aus mehreren Quellen hinweg.
- Effiziente Erkundung groß angelegter Datensätze.
- Mehrstufige iterative Deep Research.
Batch-Analytics-Workloads:
- Deduplizierung und Clustering von Korpora in ultr großem Maßstab.
- Hinzufügen von Suchfunktionen über das gesamte Spektrum zu Spark und Ray für effizientes Filtern, Retrieval und zweistufige Abfragepipelines von Grobsuche bis Re-Ranking.
- Vorbereitung von Trainings- und Fine-Tuning-Datensätzen.
Hybride Fälle:
- Beschleunigte Indexierung und Retrieval auf bestehenden Data-Lake-Tabellen wie Lance und Iceberg.
- Sich kontinuierlich weiterentwickelnde Datenmodelle mit häufigen groß angelegten Backfills.
- Multimodale semantische Wide-Table-Modellierung, die Vektoren, Metadaten, LLM-generierte Zusammenfassungen und strukturierte Felder in entitätszentrierten Tabellen mit konsistenter Versionierung und Herkunftsverwaltung vereint.
Zilliz Vector Lakebase ausprobieren
Weitere Informationen über Vector Lakebase und die neuesten Updates finden Sie auf der Zilliz-Website oder in der Zilliz Cloud-Dokumentation. Wenn die Architektur oder die Anwendungsfälle in diesem Artikel für Ihre Arbeit relevant sind, kontaktieren Sie das Zilliz-Team für eine vertiefende technische Diskussion.

Weiterlesen

Migrating Self-Managed Milvus to Zilliz Cloud for >99% Latency Reduction
Step-by-step guide to migrating 50M vectors from self-managed Milvus to Zilliz Cloud using milvus-backup. Achieve >99% query latency reduction with zero data loss.

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.