




Safeguarding Data Integrity: On-Prem RAG Deployment with LLMware and Milvus
During our latest session from the Unstructured Data Meetup, we were privileged to host Darren Oberst, CEO of AI Blocks. He graduated from UC Berkeley with degrees in physics and philosophy and is currently focused on transforming the development of large language model (LLM) applications for financial and legal services. At this meetup, Darren discussed why Retrieval Augmented Generation (RAG) should be deployed on-premises for large financial and legal services companies.
In this blog, we’ll not only recap Darren’s key points but also provide a practical example of building RAG on a private cloud using LLMware and the Milvus vector database. This example is designed to inspire and motivate you to apply this knowledge to your projects. We also recommend watching the full session on YouTube.
Key Challenges with RAG Deployment
Large Language models can be inconsistent. Sometimes, they offer precise answers but can also produce irrelevant information. This inconsistency arises because LLMs understand statistical relationships between words without truly grasping their meanings. Additionally, LLMs are pre-trained on outdated and publicly available data, limiting their ability to provide accurate answers specific to your private data or the most recent information.
Retrieval Augmented Generation (RAG) is a popular technique to address this limitation by enhancing the LLM’s responses with external sources of knowledge stored in a vector database like Milvus, thus improving content quality. While RAG is an exceptional technique, deploying it presents challenges.
In the talk, Darren ****shared the common challenges many enterprises face.
Data Privacy and Security Concerns: Many enterprises, especially those in the finance and legal sectors, hesitate to use public cloud services due to privacy and security concerns. Many existing solutions also focus on public clouds rather than on-premise, which poses challenges for companies needing to ensure data security and compliance.
Elevated Costs: Public cloud infrastructure frequently using large-scale models can run up bills. Paying such a hefty bill while lacking full control and ownership of the infrastructure, data, and applications results in a lose-lose situation.
Neglecting Retrieval Strategies: One crucial aspect often overlooked is the importance of retrieval strategies in RAG deployment. While AI teams tend to focus on generative AI capabilities, the quality of retrieved documents is equally vital.
On-Prem RAG Deployment
The challenges discussed above can be addressed effectively with a common solution: deploying RAG on a private cloud. This approach addresses the issues in the following ways:
- Better Data Security: Sensitive business documents, regulatory information, and other proprietary data must remain within the secure confines of a private cloud to meet compliance and security standards. If everything is happening privately, there will be no breaches.
- Lower Cost: Deploying AI models on private cloud infrastructure can offer a more cost-effective solution than public cloud services, especially when frequent usage is required. The cost goes even lower when we use smaller models, as they achieve practical results more efficiently than larger and more resource-intensive models. Due to their rapid innovation and customization capabilities, open-source LLMs and technologies are a great option for your RAG.
- Enhancing Generation with Retrieval in a Private Cloud: A better retrieval engine can complement a smaller model with limited generative skills. Only by making a better retrieval system can the accuracy and efficiency of AI applications, such as document parsing, text chunking, and semantic querying, be improved significantly.
In summary, Darren advocates for adopting private cloud solutions for AI, particularly LLMs, to address concerns related to data privacy, cost, and results. Next, we will discuss Dragon models designed and optimized for RAG in the Huggingface Transformers library.
dRAGon (Delivering RAG On) Models🐉
Dragon is a series of models launched by AI Blocks designed specifically for Retrieval Augmented Generation (RAG). It’s a series of seven open-source models fine-tuned on proprietary datasets like contracts, regulatory documents, and complex financial information. There are three categories of models:
 Classes of models and their description
Classes of models and their description
Classes of models and their description
- Bling Models: Compact, instruct-tuned models optimized for rapid prototyping and capable of running on CPUs, making them ideal for initial testing and development phases. They are less stressful on the memory as they package only 1 to 3 billion parameters.
- Dragon RAG Models: Fine-tuned versions of leading 6 and 7-billion parameter foundation models like Llama, Mistral, Red-pajama, Falcon, and Deci. Tailored for tasks like fact-based question answering and regulatory document analysis.
- Industry ****BERT**** Models: Specialized for industry-specific applications, Industry BERT models are fine-tuned sentence transformers tailored to tasks such as contract analysis.
Furthermore, these models have been rigorously benchmarked using common sense RAG structure benchmarks. Unlike open-source models that rely on scientific metrics like MMLU and ARC, Dragon models are tested for real-world accuracy and practical use cases. This collection of models is available on HuggingFace as shown below:
 LLMware models hosted on HuggingFace
LLMware models hosted on HuggingFace
LLMware models hosted on HuggingFace
The key benefits of using these models are as follows:
Enhanced Accuracy: Fine-tuned on extensive datasets, these models deliver high precision in document parsing, text chunking, and semantic querying.
Cost-Effective: Optimized for use on private cloud infrastructure, these models offer a cost-efficient solution compared to larger, resource-intensive models on public clouds.
Open Source and Customizable: Available on Hugging Face, these open-source models allow rapid innovation and customization to meet specific enterprise needs.
Production-Grade Performance: Benchmarked for reliability, these models provide consistent and dependable performance across various workflows.
Seamless Integration: With comprehensive support and easy-to-use generation scripts, integrating these models into existing workflows is straightforward.
Such models do not compromise cost, accuracy, or customizability; their integration in LLMware makes them easy to access.
A Glimpse into LLMware
LLMware is a library designed for enterprise-level LLM-based applications. It utilizes small, specialized models that can be privately deployed, securely integrated with enterprise knowledge sources, and cost-effectively adapted for any business process. This toolkit is comparable to LangChain ****or LlamaIndex but is tailored for high scalability and robust document management within enterprise environments.
Components of LLMware:
RAG Pipeline: Provides integrated components for the entire lifecycle of connecting knowledge sources to generative AI models.
Specialized Models: Includes over 50 small, fine-tuned models for enterprise tasks like fact-based question-answering, classification, summarization, and extraction. These models also include those discussed above; we will use one in our implementation in the following section.
Features of LLMware:
Massive Document Ingestion:
Scalability: Built to handle the ingestion of hundreds of thousands of documents, LLMware supports parallel processing and distribution across multiple workers.
Document Parsing: Implements full specifications for parsing PDFs, Word documents, PowerPoints, and Excel files using custom C-based parsers.
End-to-End Data Model:
Persistent Data Stores: Integrates with MongoDB for persistent data storage, allowing efficient chunking and indexing of text collections.
Enterprise Integration: Designed to integrate seamlessly into enterprise data workflows, ensuring secure and scalable data management.
Framework for LLM-Based Applications:
Open Source Compatibility: This feature prioritizes support for a wide range of open-source and Hugging Face models, making it easy to build and deploy LLM applications.
Feature-Rich Environment: Continuously developed to include new features and capabilities that support diverse use cases in enterprise settings.
Ease of Use:
Examples and Documentation: Provides comprehensive examples and documentation to help users get started quickly and efficiently.
Enterprise Focus: Specifically built to address the unique needs of enterprise-level LLM deployments, from document management to scalable processing.
Retrieval Augmented Generation in a Private Cloud Using Milvus and LLMware
This section will explain and implement a RAG solution on-premise. Let’s look at the architecture for RAG using LLMware and the Milvus vector database.
The Architecture
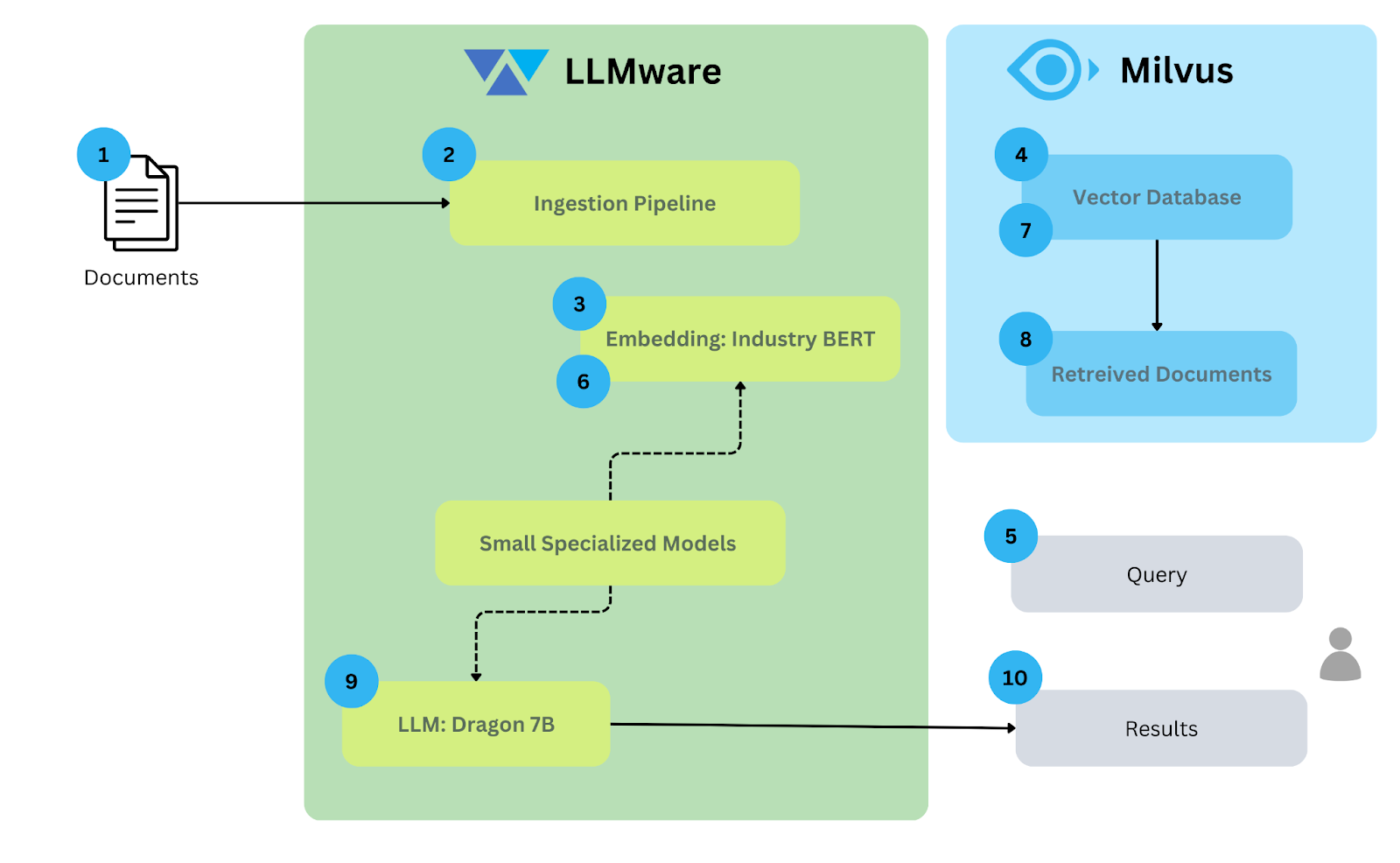
This architecture diagram illustrates RAG's workflow on premises using LLMware and Milvus.
 Architecture diagram for RAG on premises using LLMware and Milvus
Architecture diagram for RAG on premises using LLMware and Milvus
Architecture diagram for RAG on premises using LLMware and Milvus
Here is an explanation of each component:
Documents: The input data consists of various documents to be processed. In this example, the ~80 sample documents are pulled from the S3 bucket.
Ingestion Pipeline: This is the initial step in which documents are ingested into the system. This pipeline prepares the documents for further processing by extracting relevant information and possibly performing pre-processing tasks like cleaning or formatting the data.
Generate Embeddings: After ingestion, the documents are passed to an embedding model. In this case, an Industry BERT model converts the documents into numerical representations (vector embeddings) that capture the semantic meaning of the text.
Vector Database: The embeddings generated by the Industry BERT model are stored in a vector database, Milvus, along with the documents. This specialized vector database is designed to handle and efficiently search through large-scale vector data.
Query: A user submits a query to the system.
Query Embeddings: This query is also converted into an embedding to compare it with the document embeddings stored in Milvus.
Search Documents: The similarity between query and document embeddings is calculated, with documents ranked higher based on greater similarity.
Retrieved Documents: Relevant documents with high similarity are retrieved. The number of documents retrieved and the similarity threshold can be customized.
LLM: The retrieved documents and the query will be sent to the LLM; in our case, the LLM is Bling 7B.
Result: The response from the LLM is provided to the user.
The next section will show the implementation of the RAG application in the private cloud.
Implementation
In this implementation, we will build the RAG application by ingesting ~80 legal documents into the Milvus vector database and asking questions using an LLM. We assume the user has already installed Milvus for this blog and can start the service.
Imports
We will first install the required libraries and import them into our environment. We will require llmware, and PyMilvus. Here’s how to install it:
pip install llmware
Pip install pymilvus>=2.4.2
After this step, let’s import the required modules from llmware.
import os
from llmware.library import Library
from llmware.retrieval import Query
from llmware.setup import Setup
from llmware.status import Status
from llmware.prompts import Prompt
from llmware.configs import LLMWareConfig, MilvusConfig
After importing the data, we will set up the configuration.
Configuration
The configuration step is pretty simple. In this step, we store the names of the embedding model, vector database, and LLM.
embedding_model = "industry-bert-contracts"
vector_db = "milvus"
llm = "llmware/bling-1b-0.1"
The setup includes the industry-bert-contracts embedding model, Milvus for the vector database, and the llmware/bling-1b-0.1 language model for optimized AI-driven document processing and analysis.
Setting up Milvus
Due to its integration, it's very simple to set up Milvus using llmware. After the PyMilvus installation, we need to set the vector_db as Milvus while active_db as sqlite as shown below:
LLMWareConfig().set_active_db("sqlite")
MilvusConfig().set_config("lite", True) # No dependency
LLMWareConfig().set_vector_db("milvus")
llmware supports Milvus-lite, which is self-contained and requires no other dependencies.
Creating a Library
In llmware, a library is the main organizing construct for unstructured information. Users can create one large library with diverse content or multiple libraries, each dedicated to a specific subject, project, case, deal, account, user, or department.
To create a library, we can simply call the create_new_libraryfunction from the Library class, which requires an arbitrary name as an argument. Let’s take a look.
Library_name = "contracts-Rag"
library = Library().create_new_library(library_name)
Ingesting documents
The Setup class in LLMware downloads sample files from an AWS S3 bucket, including various sample documents like contracts, invoices, financial reports, etc. You can always get the latest version of these samples by using load_sample_files. In this example, we will upload the “Agreements”.
sample_files_path = Setup().load_sample_files(over_write=False)
contracts_path = os.path.join(sample_files_path, "Agreements")
Llmware has a useful function named add_files, a universal ingestion tool. Point it to a local folder containing mixed file types, and it will automatically route files by their extension to the appropriate parser. The files are then parsed, text chunked, and indexed in the text collection database.
library.add_files(input_folder_path=contracts_path)
The documents are loaded. Let’s create its embeddings.
Create Embeddings
Everything in this implementation is running privately. Therefore, the embedding model is downloaded on-prem. As mentioned, the embedding model is industry-bert-contracts, while Milvus is the vector database.
library.install_new_embedding(embedding_model_name=embedding_model, vector_db=vector_db)
After installing the embeddings in the library, you can check the embedding status to verify the updated embeddings and confirm that the model has been accurately captured.
Status().get_embedding_status(library_name, embedding_model)
Let’s see how to invoke a LLM call in the next sections.
Load the Large Language Model
We will use the load_model function to load the Bling model. These are small and good for quick testing.
prompter = Prompt().load_model(llm)
Search Documents
In Llmware, the Query class is used for search and retrieval, requiring a Library as a mandatory parameter. This approach allows retrievals to leverage the Library abstraction, supporting multiple distinct knowledge bases aligned with different use cases, users, accounts, and permissions.
This class allows many search functions, such as text search and semantic search. We will use semantic search for our example.
query = "what is the executive's base annual salary"
results = Query(library).semantic_query(query, result_count=50, embedding_distance_threshold=1.0)
Joining All of the Pieces Together
This section will loop over all the contracts, filter the relevant results, and generate the responses using LLM. Here’s the code snippet:
for i, contract in enumerate(os.listdir(contracts_path)):
qr = []
for j, entries in enumerate(results):
if entries["file_source"] == contract:
print("Top Retrieval: ", j, entries["distance"], entries["text"])
qr.append(entries)
source = prompter.add_source_query_results(query_results=qr)
response = prompter.prompt_with_source(query, prompt_name="default_with_context", temperature=0.3)
for resp in response:
if "llm_response" in resp:
print("\nupdate: llm answer - ", resp["llm_response"])
# start fresh for next document
prompter.clear_source_materials()
Here’s the guide for it.
Iterate Over Contracts: For each contract file in the directory, it initializes a list to store relevant query results.
Filter Relevant Results: It filters the results that match the current contract and prints the top retrievals.
Generate Responses: The filtered results generate a response with a language model and print the generated responses.
Reset for Next Contract: It clears the source materials to prepare for the next contract.
The result for the query is provided as follows:
>>> Contract Name: Rhea EXECUTIVE EMPLOYMENT AGREEMENT.pdf
Top Retrieval: 1 0.6237360223214722
The Board (or its compensation committee) will annually review the Executive's base salary following the Employer's standard compensation and performance review policies for senior executives. While the salary may be increased, it cannot be decreased. The specific amount of any yearly increase will be determined based on these policies. For the purposes of this Agreement, "Base Salary" refers to the Executive's base salary as periodically established in accordance with Section 2.2.
Note that only the first retrieval is displayed here.
Above, we have successfully created a RAG application for legal documents using Milvus and LLMware. The best part is that no data is sent to outside vendors; everything, including the vector database, embedding model, and LLM, is on-premises
Conclusion
With the growing adoption of AI, interacting with data has become easier than ever. However, many enterprises are still hesitant to send their data to the cloud, and rightly so. LLMware provides a solution for building AI systems on-premises rather than on the public cloud. This solution ensures data privacy, reduces costs, and offers more control.
Using LLMware and the Milvus vector database, we can combine the power of vector similarity search and LLMs to ask questions on our private documents. Milvus is a robust open-source vector database that stores, processes, and searches billion-scale vector data. Once Milvus retrieves the top-K most relevant results for the LLM, LLMs will have the context to answer your queries.

Keep Reading

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.